Demo 惊艳,上线翻车:为什么大多数 Agentic AI 项目死在生产环境
行业观察 · 务实复盘 · Agentic AI 的生产落地鸿沟 | 2026 年 6 月 | 约 15 分钟阅读
导语:那个让全场沉默的问题
企业 AI 的推介,几乎都按同一套剧本走:销售或内部团队推来一个 demo,agent 当场表演——从三个系统里取出记录、综合出一个判断、把一条原本要耗掉大半个下午的流程自动跑完。高管点头,工程师交换眼神,有人说出那个词:"有前途"。
然后,一个真正干活的人问出那个要命的问题:要是上游某个系统挂了,它怎么办?任务跑到一半卡住,那条没干完的活归谁?出了岔子谁来兜底?
这个问题,在过去两年大量企业 AI 项目里,可靠地引来一阵沉默。"在受控环境里能跑"和"在真实运行条件下扛得住"之间的那道沟,正是大多数 agentic AI 项目悄悄散架的地方。 这是 Coditation CEO Chetan Saundankar 在 2026 年 6 月一篇复盘里的判断,也是本文想讲清楚的一件事:
一个惊艳的概念验证(PoC)和一个生产级 agentic 系统之间的差距,不是模型问题,而是基础设施和编排问题。
换句话说——大多数项目不是栽在"模型不够聪明",而是栽在模型周围那一圈没人认真搭的东西:编排、状态、可观测、治理、责任。下面先看这不是个例,而是一个有数据支撑的结构性现象,再走进两个真实的翻车现场。
一、先看数字:这是结构性现象,不是个例
把几家机构的数字摆在一起,会发现"翻车"不是偶发,而是当前 agentic AI 的常态:
| 来源 / 口径 | 数字 | 说的是什么 |
|---|---|---|
| Gartner(2025-06 预测) | >40% | 到 2027 年底,超四成 agentic AI 项目会被直接取消 |
| MIT(2025 报告) | 95% | GenAI 试点项目未能成功 |
| McKinsey(2025 AI 现状) | <20% | AI 试点能在 18 个月内规模化进生产 |
| 行业复盘(2024–2025 跨数百项目) | 88% | agent 项目根本到不了生产,不到 1/8 能上线 |
| 同上 | $340,000 | 单个失败项目的平均直接成本(不含机会成本) |
Gartner 给取消的三个理由很朴素:成本失控、业务价值不清、风险管控不到位。 它还点了一个很扎心的现象——"agent washing(智能体洗白)":大量厂商把原来的 AI 助手、RPA、聊天机器人重新贴个 "agentic" 标签就拿出来卖,Gartner 估计数千家号称做 agent 的厂商里,真正名副其实的只有约 130 家。换句话说,市面上的热闹,相当一部分是包装。
为什么 agent 比普通 AI 更容易死?因为它触碰更多系统、需要更多组织协同、引入更复杂的安全考量、对数据质量的要求也更高。一个分类模型遇到脏数据,顶多分错一条;而一个 agent 遇到脏数据,会基于错误结论连续做出好几个错误动作、污染下游系统,等你发现时已经错了一长串。错误在 agent 里是会链式放大的——这是它的复杂度天花板,也是大多数组织低估的地方。
二、两个真实的翻车现场
抽象的数字不如具体的尸检。下面是两个被复盘过的真实案例,它们的共同点是:AI 逻辑本身几乎没问题,问题全在周围。
2.1 物流异常处理 agent:三周后退回人工
一家物流公司花了六个月,做了一个"货运异常端到端处理" agent:自动标记配送异常、触发升级、更新承运商记录、闭环关单,全程不用人插手。在测试环境里,它的表现和设计得一模一样。
上了生产,画面就变了。运营团队每天早上没有任何可靠办法判断:昨晚那批异常到底是全处理完了、处理了一半、还是中途卡住却没报错。没有审计轨迹,没有针对"半成品工作流状态"的恢复路径,agent 交接之间掉下去的活也没有归属模型。三周后,团队退回了手工流程。
重做这套系统时,AI 部分几乎没动。变的是它周围的一切:每个工作流转换点上的确定性状态持久化、防止重复执行的幂等控制、对超过重试阈值任务的死信处理(dead-letter),以及一个让运营能清楚看到"agent 在什么时间做了什么"的可观测层。改完之后,agent 重新上线,此后稳定运行。那次绕路的信誉代价很大,而且完全可以避免。
2.2 B2B 客户成功 copilot:一个月后无人再用
一家 B2B 软件公司给客户成功团队做了个 AI copilot,自动聚合 CRM、未结工单、近期账户活动,生成"通话前简报"。概念很强,日常价值也显而易见。
问题出在:底层数据源的响应快慢不一,而没有人定义过——当某个数据源拖慢时,agent 该等、该用部分数据先出、还是该明确告诉用户"这份简报可能不全"。结果简报有时新鲜完整、有时已经过期好几天,而客户经理无从分辨自己看到的是哪一种。
一个月内,采用率就崩了。 不是因为工具"经常错",而是因为用户没法判断它什么时候是对的。终端用户根本不区分"模型表现不佳"和"系统编排糟糕"——这两者在他们眼里是同一件事:一个靠不住的工具。 这里藏着一个常被当成性能指标、其实是信任变量的东西——延迟:一个时快时慢、还不告诉你它处于哪种状态的系统,会先丢掉信任,再丢掉用户。
两个案例指向同一句话:maker(写 agent 逻辑的那部分)往往不是问题,maker 周围那个没人搭的编排层才是。 这也呼应了本站之前在 Loop Engineering 实战里反复强调的——可观测性、熔断、状态,是循环能稳定跑起来的前提,而不是锦上添花。
三、七种失败模式:61% 死在最前面两类
把数百个 agent 项目的失败做聚类,会发现它们并不随机,而是高度集中在七个可识别的模式上——这七类合起来解释了约 94% 的上线前停滞。按频率排序如下:
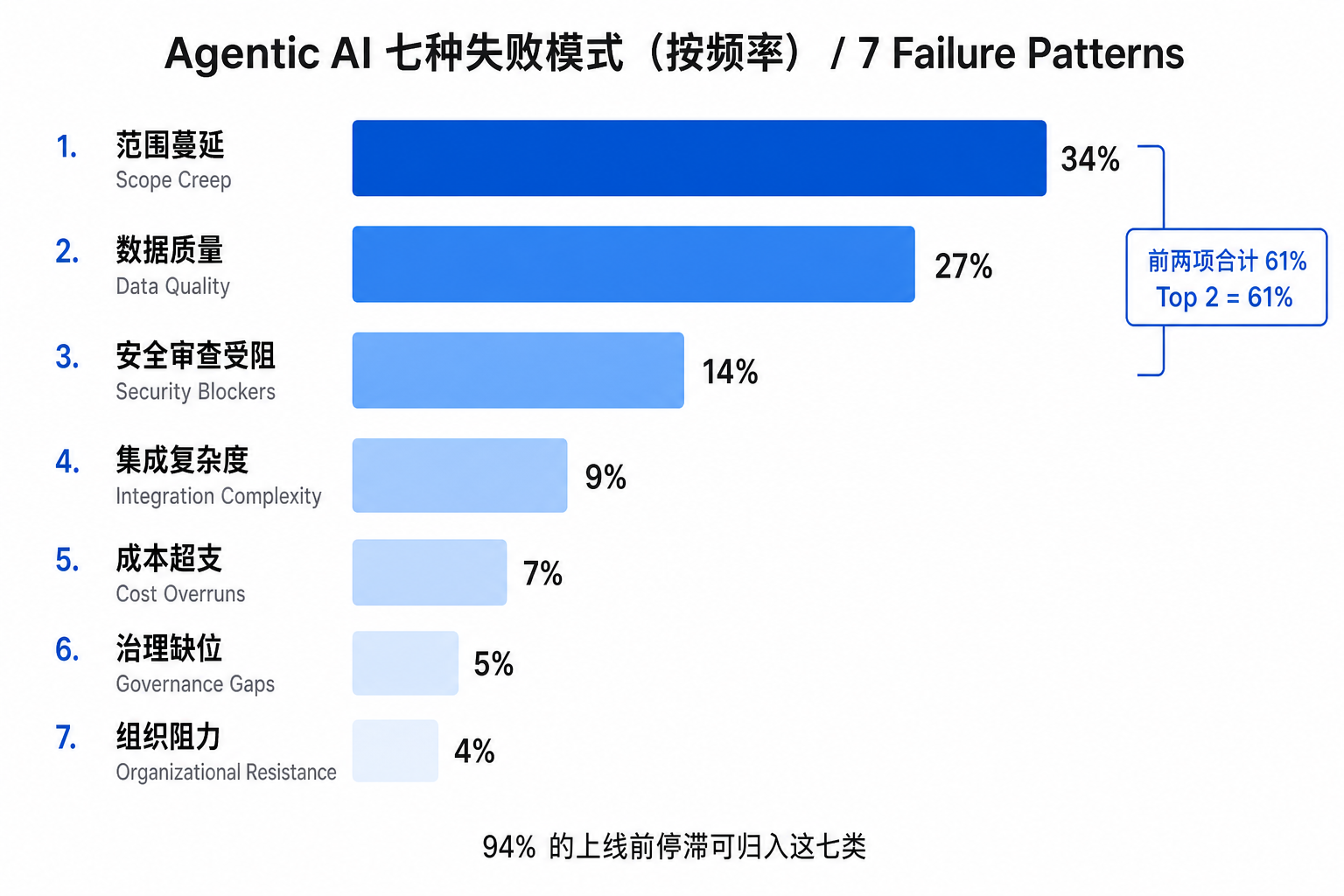 ▲ 七种失败模式按频率排序,前两类(范围蔓延 + 数据质量)合计占 61%——这意味着大多数失败在写第一行代码之前就已注定
▲ 七种失败模式按频率排序,前两类(范围蔓延 + 数据质量)合计占 61%——这意味着大多数失败在写第一行代码之前就已注定
最值得展开的是前两名,因为它俩合占 61%,而且都发生在开发开始之前:
范围蔓延(34%,第一杀手)。 它几乎总是从一个边界清晰的好概念起步——比如"监控某个数据流、给特定人群生成结构化摘要"。然后干系人开始加需求:"能不能顺便在越过阈值时发告警?"能。"能不能交叉比对一下 CRM?"能。"能不能基于摘要给点建议?"行。每一条增量看着都不大,合起来却把一个有界的自动化变成了一个开放式推理系统:要接更多数据源、更多集成、更复杂的错误处理和评测。于是 agent 复杂到测不全、依赖多到难调试,上线被无限期推迟。最稳的解法很反直觉——用"明确不做什么"来定义范围:每加一个能力,就同时写下一个"本期明确不做"的相邻能力;1.0 只把一个工作流做好,2.0 再扩。
数据质量(27%,第二杀手)。 agent 在干净、精挑的数据集上测试时表现良好,一进生产撞上残缺记录、格式不一、过期信息、重复条目、缺失字段,行为就急剧退化。前面说过,agent 的错误会链式放大,所以数据问题对它格外致命。务实的规矩是:写任何 agent 代码之前,先对所有输入源做一次数据就绪审计;如果超过 10% 的记录过不了完整性或新鲜度要求,先修数据管道,再建 agent——把数据质量处理塞进 agent 自己身上,是常见但昂贵的错误,等于让 agent 去背本该上游解决的锅。这一点也正好接上本站 Databricks Summit 复盘里那条主线:智能体缺的不是智商,是被治理好的上下文。
后面五类同样值得记一笔:
- 安全审查受阻(14%)——注意,它和"安全漏洞"是两码事。大多数被安全团队卡住的 agent 代码本身没漏洞,卡住是因为缺审计日志、缺最小权限的访问控制框架、缺数据处理规范,过不了企业安全评审。把安全当成"最后一道审批关"的项目最容易栽;把安全架构当成与开发并行的工作流来做,过审不延期的概率高 4 倍。
- 集成复杂度(9%)——API 文档承诺的和生产里真实交付的之间有巨大落差,认证边界、限流行为、版本不一致能让集成工期膨胀 2–5 倍,接老旧/内部系统时尤甚。解药是上线前对每个非平凡系统做一次 2 天的集成 spike,用真实认证打一次样例调用,胜过任何文档评审。
- 成本超支(7%)——几乎全来自低估生产规模下的推理成本。测试期每次调用 0.02 美元、总额可忽略;生产期月跑 5 万次、上下文更长,每月就多出几千美元没进商业测算的账单,ROI 模型当场崩掉。务必按 1×/5×/10× 真实量级建模,并把多步工具调用(一次请求常触发 3–8 次 LLM 调用)算进去。
- 治理缺位(5%) 和 组织阻力(4%)——前者让 agent 上了线却在"第一次出事"后被关停,因为没人定义谁来负责、怎么监控、什么算越界、出事怎么响应;后者表现为被自动化的团队消极配合(交接不全、不认真参与验收、反馈低质),而恰恰是这些一线团队握着没写进文档的边界知识。
四、把"能跑 demo"和"能上生产"分开
贯穿所有失败的那个结构性错误,是把"模型评估"当成了"基础设施就绪"。这是两个不同的问题,做完一个不能替代另一个:
| 模型评估(Model Evaluation) | 基础设施就绪(Infrastructure Readiness) |
|---|---|
| 模型能不能以可接受的准确率完成任务 | 模型周围的系统能不能扛住生产的全部工况 |
| 在理想/干净数据上验证 | 在依赖降级、峰值负载、并发、部分失败下验证 |
| "它答得对吗?" | "它坏了之后怎么办?" |
| demo 的及格线 | 上线的及格线 |
光做完左边就上线,就是 88% 项目的死法。上线前真正该向工程团队拷问的,是右边这些问题:工作流状态存在哪、意外中断后怎么恢复?组件中途失败时,半成品任务怎么处理?谁会收到告警、期望多久响应?
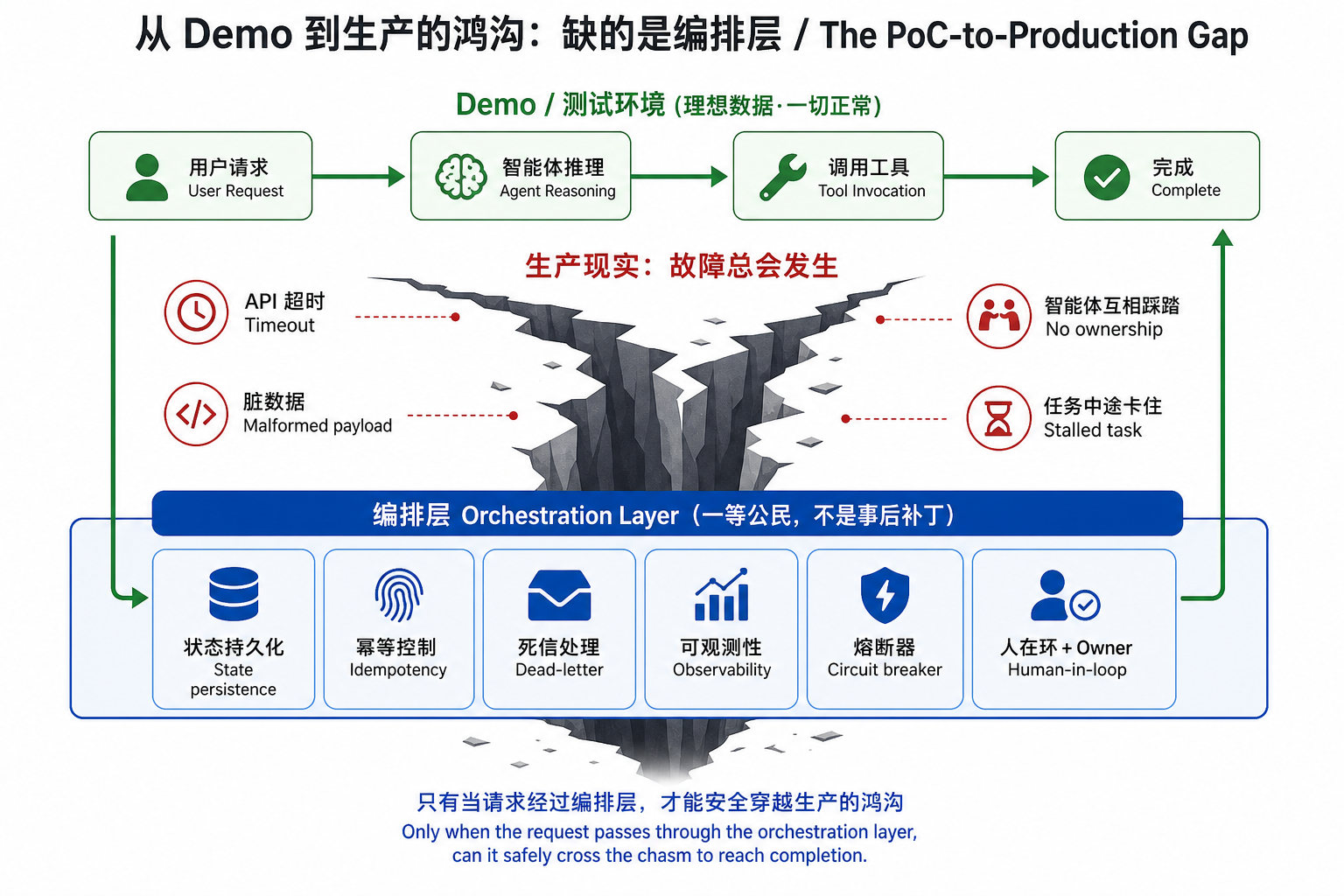 ▲ Demo 是一条理想数据下的绿色通路;生产里超时、脏数据、任务卡死、智能体互相踩踏总会发生。能不能跨过这道鸿沟,取决于有没有把编排层当成"一等公民"
▲ Demo 是一条理想数据下的绿色通路;生产里超时、脏数据、任务卡死、智能体互相踩踏总会发生。能不能跨过这道鸿沟,取决于有没有把编排层当成"一等公民"
把它落成一份生产就绪清单,本质上就是给 agent 套一个编排层(这也正是上面两个案例"重做"时补的东西):
- 状态持久化:每个工作流转换点都把状态落盘,中断后能恢复,而不是从头再来或卡在半路。
- 幂等控制:同一步重试不会产生重复副作用(重复扣款、重复关单)。
- 死信处理:超过重试阈值的任务进死信队列、触发人工,而不是静默消失。
- 可观测性:每一步的输入、输出、耗时、成本、失败原因留痕,能一眼看出"卡在第几步、为什么"。
- 熔断与边界:成本上限、最大步数、异常行为告警阈值,防止 agent 跑飞或烧账单。
- 人在环 + 明确 owner:高风险动作有人工复核,且有一个被点名、有权暂停/修改 agent 的负责人。
这套东西没有一个是"AI 突破",全是组织与工程纪律。行业复盘给出的数据也佐证了这一点:在开发前认真跑一遍失败模式评估的组织,能把失败率从 88% 压到 15% 以下。能上生产的那 12%,不是技术更强,而是在开发开始前的那几周更自律。
五、对我们意味着什么(ICE 观察)
🔧 技术视角:编排层是一等公民,不是事后补丁。 对数据工程师和平台团队来说,这篇最实在的提醒是——别再把状态、可观测、幂等、死信当成"上线后再补"的运维细节。它们决定了一个 agent 能不能从 demo 跨到生产。一个可操作的顺序是:数据就绪审计前置(脏数据不过 10% 这条线先卡住),再谈 agent;同时把 maker 和 checker 拆开、给循环装上熔断和 trace——这正是 Loop Engineering 那套循环六要素在"单个 agent 生产化"上的直接应用。
🏢 落地视角:别拿 demo 立项,要拿"坏了怎么办"立项。 给管理者的话只有两句。第一,评估 agent 时,把可靠性问题和能力问题摆到同样重要的位置——"它能做什么"之外,先问"它坏了怎么办、谁负责、多久恢复",答不上来就别上线。第二,警惕 agent washing 和"为了 agent 而 agent":Gartner 说得直白,很多被包装成 agentic 的场景根本不需要 agent,能用确定性自动化就别上自主推理;价值要挂到成本、质量、速度、规模这些能进财报的东西上,而不是 demo 炫不炫。
🇨🇳 本土视角:热潮一样,坑也一样。 国内这一年同样是 agent 热——高考填报智能体、各家抢 agent 入口,信通院刚发布的《2026 智能体十大关键词》也把它推成产业共识。但 Gartner 那组投入数字(约六成组织只是保守投入或观望)提醒我们:热度不等于上线率。 海外这 88%/$340K 的教训,对国内团队几乎可以平移。更务实的路径是:先挑一个窄到不能再窄的场景,配一个确定性的 checker(哪怕只是几行规则校验),把编排层和可观测先搭好,跑通一个能进生产、能算清 ROI 的小闭环,再谈扩张——而不是一上来就做"什么都能干"的全能 agent。
结论
如果只带走几句话:
- 大多数 agent 死在生产,不是模型问题,是工程与治理问题。 Gartner 预测 40% 被取消,行业复盘 88% 到不了生产、单个失败平均烧 34 万美元——这是结构性现象,不是个例。
- 失败高度可预测:七种模式覆盖 94%,其中范围蔓延(34%)+ 数据质量(27%)两类就占 61%,而且都在写代码之前就埋下。
- 能跑 demo ≠ 能上生产:模型评估回答"它答得对吗",基础设施就绪回答"它坏了怎么办"。把状态持久化、幂等、死信、可观测、熔断、人在环、明确 owner 这套编排层当成一等公民,是从 12% 成功组那里能学到的、最高杠杆的纪律。
- 解药是纪律,不是新模型:把失败模式评估前置到开发前几周,失败率能从 88% 压到 15% 以下。
留个问题给你:在你手上那个 agent 项目里,如果现在就有人问"上游挂了它怎么办、任务卡一半归谁、出事谁兜底",你答得上来吗?答不上来,它大概率还停在"demo 惊艳"那一侧,离"上线扛得住"还隔着一整个编排层。
参考资料
- Chetan Saundankar(BigDATAwire), "Why Most Agentic AI Projects Fail in Production", 2026-06-15, https://www.hpcwire.com/bigdatawire/2026/06/15/why-most-agentic-ai-projects-fail-in-production/
- Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027", 2025-06-25, https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- Digital Applied, "Why 88% of AI Agents Fail Production: Analysis Guide"(含七种失败模式分布、$340K 成本、Gartner/McKinsey/MIT 数据综合), 2026, https://www.digitalapplied.com/blog/88-percent-ai-agents-never-reach-production-failure-framework
- ICE's Tech Stack, "Loop Engineering 实战:从写 Prompt 到设计循环", 2026-06-16, /posts/2026/06/260616-loop-engineering
- ICE's Tech Stack, "Databricks Summit 2026 复盘:智能体缺的不是智商,是上下文", 2026-06-19, /posts/2026/06/260619-databricks-summit26-recap