从 219 个单词到 GDSII 版图:Verkor Design Conductor 的全自主芯片设计闭环
深度调研 · 半导体 × Agentic EDA × RISC-V | 2026 年 5 月 | 约 15 分钟阅读
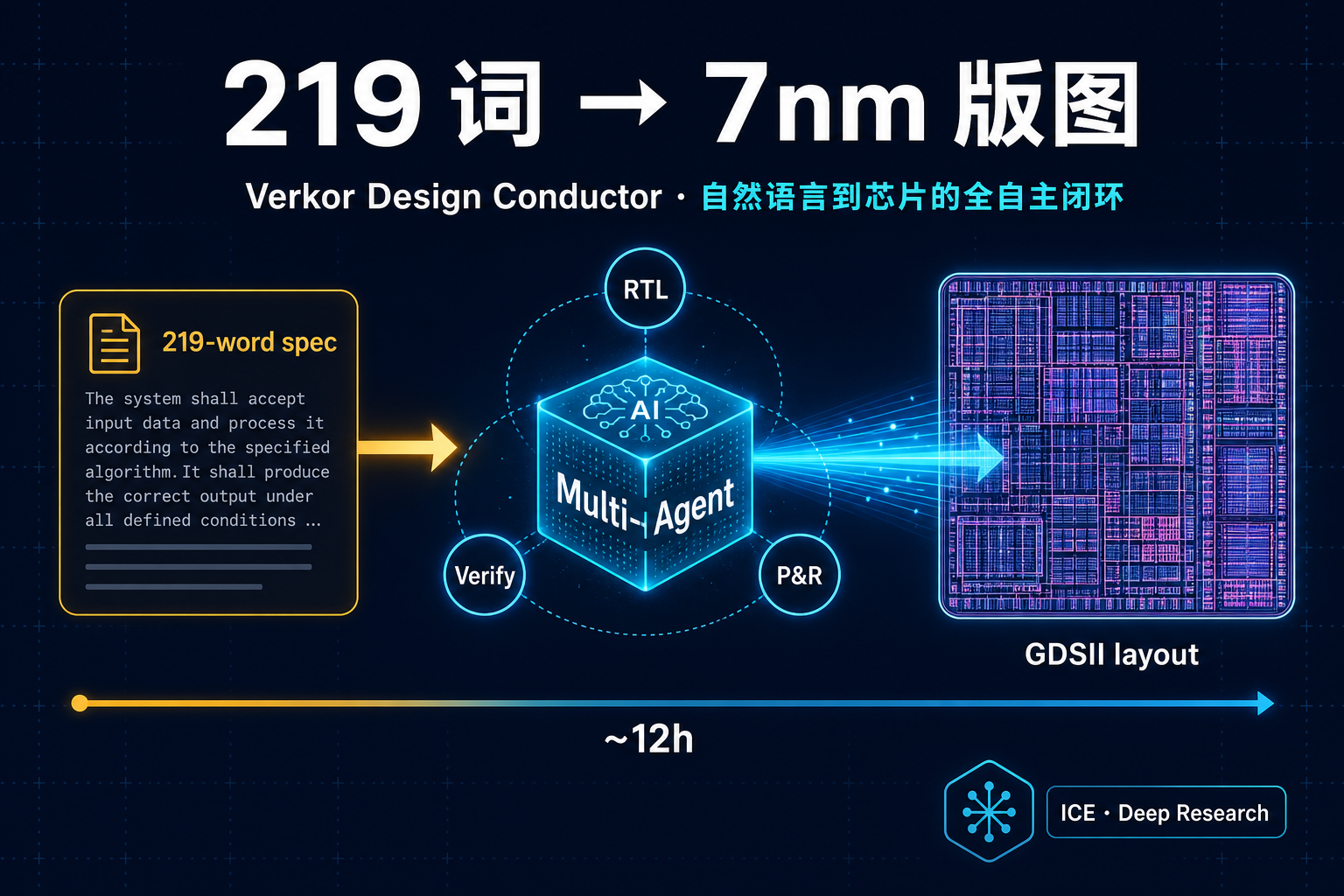
造一块芯片有多难?按行业惯例,这是一支上百人的团队、花 18 到 36 个月、烧掉几亿美元才能走完的流程:定架构、写代码、做验证、布局布线,最后交出一份能送进工厂流片的版图文件(GDSII)。
2026 年初,一家叫 Verkor 的公司宣布:他们的 AI 系统 Design Conductor,把这条流程压缩到了 12 小时——全程没有人插手,唯一的输入,是一份用普通英文写成的 219 词需求文档。
先看看那份文档长什么样。它是整个故事里唯一由人类写下的东西(论文 §3.1,原文照录):
VerCore RISC-V Design
Requirements Overview
Your task is to build VerCore, a RISC-V CPU core that supports RV32I and ZMMUL, with the following
hardware interfaces, all synchronous to a master clock:
* Instruction cache interface (32-bit datapath)
* Data cache interface (32-bit datapath)
* Other interface signals: clock input to core, reset_n input to core, asserted low.
VerCore should implement a simple 5-stage pipelined design, in-order, single-issue of course.
DO NOT support compressed instructions.
Implement the register file as flip flops. This allows register reads to happen any time during the
cycle, but writes happen at the next rising clock edge.
You need to achieve a CPI <= 1.5. Your overall goal is to maximize your design's score on CoreMark.
Aim for a clock rate of 1.6 GHz.
You are responsible for both the RTL and the physical design. You should use the OpenROAD flow scripts
to generate final GDSII output, along with area and timing information for this design. You should use
the ASAP7 platform/PDK.
Assume that input signals will be valid 70% into the clock cycle. Make sure output signals are valid
20% into the clock cycle.
Testing
You have access to Spike, the RISC-V ISA simulator. Use this to build a cycle-by-cycle integration test
and verify that the behavior of your module matches that of Spike.翻成中文,它说的是这些事:
VerCore RISC-V 设计 · 需求概述
构建 VerCore——一个支持 RV32I 与 ZMMUL 指令集的 RISC-V CPU 核,所有硬件接口都同步于主时钟:
- 指令 cache 接口(32 位数据通路)
- 数据 cache 接口(32 位数据通路)
- 其他接口信号:时钟输入、低有效的 reset_n 复位输入。
实现一个简单的五级流水线、顺序执行、单发射设计;不支持压缩指令;寄存器堆用**触发器(flip-flop)**实现(读可在周期内任意时刻发生,写在下一个时钟上升沿)。
需达到 CPI ≤ 1.5,总目标是最大化 CoreMark 跑分,主频目标 1.6 GHz。
RTL 与物理设计都由你负责:用 OpenROAD 流程脚本生成最终 GDSII,并给出面积与时序信息;工艺用 ASAP7 PDK。假设输入信号在时钟周期 70% 处有效,输出信号需在 20% 处有效。
验证:你可以使用 RISC-V ISA 模拟器 Spike,据此构建一个 cycle-by-cycle 的集成测试,确认你的模块行为与 Spike 一致。
数一数,219 个英文单词。这就是全部的人类输入。
12 小时后,Design Conductor 交出的,是一块完整的 RISC-V CPU——它给这块芯片取名 VerCore,从寄存器传输级代码(RTL)、功能验证,一路做到了可以送去流片的 GDSII 物理版图,主频 1.48 GHz,面积 2809 μm²。全程没有人插手。
Verkor 把这套成果写成技术报告挂上了 arXiv:2603.08716,并在第一页给了自己一句相当大的评价:
据我们所知,这是自主 Agent 第一次从规格书做出一块完整、可工作的 CPU,一直做到 GDSII。
我把论文从头到尾读了一遍,下面想说清楚三件事——它真正做成了什么、它没做成什么、以及为什么它依然重要。
一、它真正做成了什么:一个会自己 debug 的设计师
最容易被忽略的细节,恰恰是最有意思的:Design Conductor 不是“一个大模型一次性吐出版图”,而是一套像人类设计团队一样分工协作的多 Agent 系统。
它的工作流几乎照搬了人类芯片工程师的流程:先读需求、定微架构,再写 RTL、逐模块做 testbench,然后系统集成、跑测试程序,最后做时序收敛、布局布线,出版图。论文 Figure 3 完整画出了这条流程——注意左侧的输入(产品特性、PPA 目标、ISA 规格),以及右侧那几条标红的 RTL Edits 反馈线,正是“前后端联动”的体现:
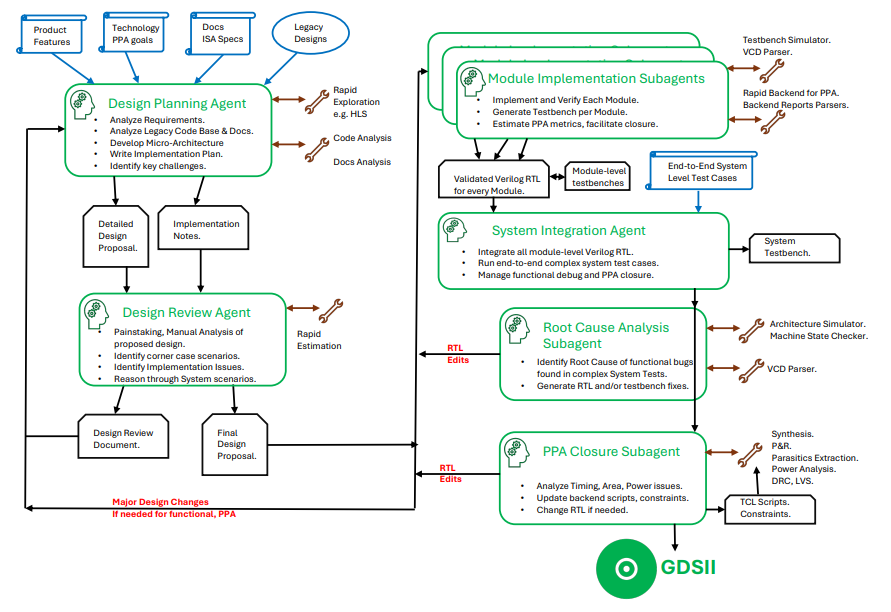
图 1:Design Conductor 典型设计流程(来源:论文 arXiv:2603.08716, Figure 3)
每个环节由不同角色的子 Agent 负责:规划 Agent 出微架构方案,评审 Agent 像老工程师一样“逐个场景手推”验证设计(论文里那份 ZMMUL 乘法器评审,老老实实列了 7 类测试场景、cycle-by-cycle 地走流水线),实现 Agent 写每个模块的 RTL,集成 Agent 把它们拼起来跑 CoreMark,后端的 PPA Closure Agent 读时序报告、回头改 RTL。
但真正让我觉得“这东西不一样”的,是它调试 bug 的方式。
当仿真结果和参考模型 Spike 对不上时,它不是瞎改,而是——自己写 Python 脚本来查。论文 Listing 1 直接贴了它写的代码:把波形文件 VCD 转成 CSV,用 pandas 把每一次寄存器写回拉出来,和 Spike 的期望轨迹逐条比对。然后它锁定了一个真实的 bug:
PC=0x2008 处有一条 JAL 跳转指令……流水线 flush 没生效,跳转后本不该执行的指令继续跑了,导致 x5 被错误写入。
这是一个经典的流水线冒险 bug。一个 AI 不只是“生成了代码”,而是像工程师一样,写工具、看波形、定位根因、提出修复、再验证。这才是“闭环”二字真正的分量。
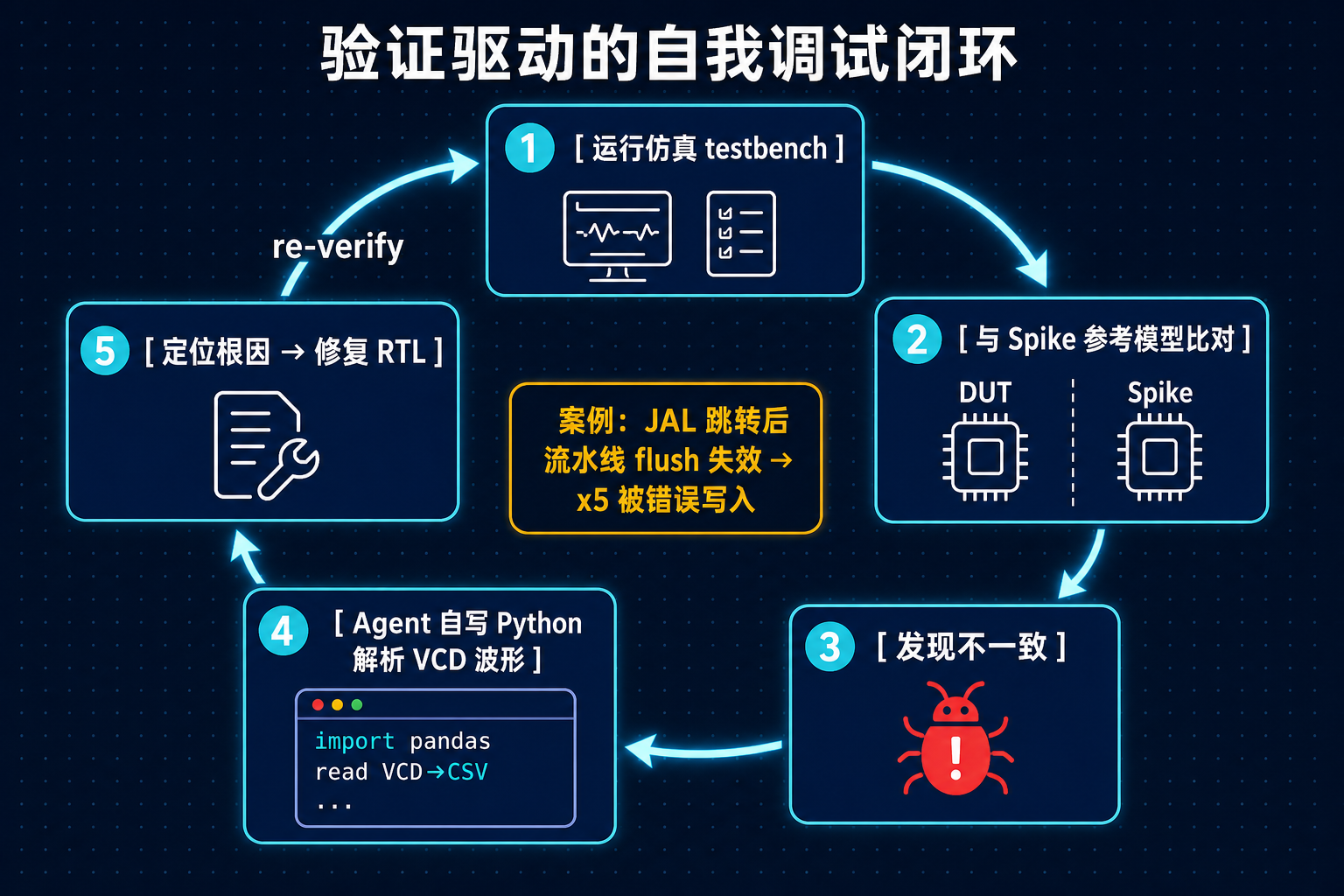
图 2:验证驱动的自我调试闭环(依据论文 §3 调试过程绘制)
更有意思的是它在过程中自己发现的一些优化——这些都没写在那 219 个词里:
- ID 阶段的 early branch resolution(1 周期分支延迟);
- ID 阶段的 early forwarding;
- 一个 4 级 Booth-Wallace 乘法器,单独跑能到 2.57 GHz。
而且它不是拍脑袋选的。论文说得很清楚:1 周期和 2 周期分支延迟两套方案,它都完整实现到了 GDSII,再根据实测时序选了 1 周期那条——尽管它的关键路径更长。论文作者忍不住感慨:它等于是重新发现了当年经典 MIPS 五级流水线的关键路径设计。
下面是它最终交出的那条流水线(论文 Figure 4)。可以看到 ID 阶段的 early branch resolution、贯穿各级的 forwarding 蓝色虚线,以及 EX 阶段那个 32×32 的 Booth-Wallace 乘法器——这些都不是人写在 spec 里的,是它自己长出来的:
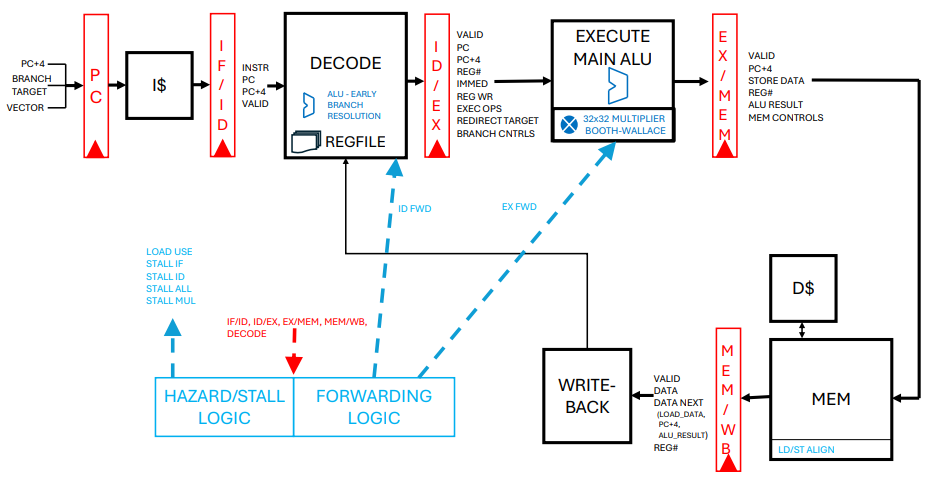
图 3:DC 最终生成的 VerCore 流水线(来源:论文 arXiv:2603.08716, Figure 4)
把整套流程跑到底,VerCore 最终交出的成绩单是这样的:
| VerCore 关键指标 | 数值 | 说明 |
|---|---|---|
| 墙钟时间 | ~12 小时 | 达到设定 token 上限后终止 |
| 主频 | 1.48 GHz | 目标 1.6 GHz,差约 7.5% |
| 面积(不含 cache) | 2809 μm² | GDS 画布约 70×70 μm |
| CoreMark | 3261 | 约等于 2011 年 Intel Celeron SU2300(1.2 GHz) |
| ISA | RV32I + ZMMUL | 无压缩指令 |
| 工艺 | ASAP7 | ASU + ARM 的预测性 7nm PDK |
一句话总结这一节:这不是一个会写 Verilog 的模型,而是一个会做工程的 Agent。 它的能力上限,决定了这件事值不值得认真对待。
二、它没做成什么:四个被标题悄悄省略的星号
越是惊艳的标题,越需要把脚注读完。Verkor 这篇报告本身相当克制,但传播过程中有四个关键限定词被磨平了,这里逐一钉回去。
星号一:“7nm”不是台积电的 7nm。 VerCore 用的是 ASAP7——亚利桑那州立大学和 ARM 合作的预测性学术 PDK。它的官网原话是 designs are not manufacturable(这些设计无法被制造)。整条物理流程跑在开源的 OpenROAD 上,和工业界 Synopsys/Cadence + 台积电 N7 那套要做完整签核(sign-off)的成熟度,根本不在一个量级。准确的说法应该是:在公开的 7nm 学术工艺上,完成了 RTL→GDSII 的物理实现闭环。
星号二:它“没有流片”。 GDSII 是“可以拿去流片”的文件格式,但 VerCore 从未被造成真正的硅片,也没在硅片上测过。所有验证都停留在 Spike 参考模型 + 仿真。IEEE Spectrum 和 RCR Wireless 都点了这一条。从“版图就绪”到“硅片上能跑”,中间隔着的恰恰是芯片行业最贵、最痛的那段路。
星号三:“Linux-capable”不等于“跑通了 Linux”。 论文标题里的 “Linux-capable” 指的是这套 ISA / 微架构理论上能支撑 Linux 这类负载,而不是真的启动过内核。实际验证用的是 CoreMark、MD5 这些程序,在 testbench 里和 Spike 对齐。这是“具备能力”,不是“已经演示”。
星号四:“零人工”里那 219 个词,含金量极高。 “全程零人工干预”说的是设计执行过程。但那份 219 词的输入本身,是一份被刻意写紧、每一条都可度量、可验证的工程规格书,不是随口一句 prompt。论文 §5 自己承认:如果不写上 “CPI ≤ 1.5” 这一条,Agent 就会做出分支和转发性能明显更差的设计。换句话说,输出质量被输入质量牢牢钉住——而写出这样一份输入,本身就是资深架构师的活。IEEE Spectrum 引述团队的话更直接:现阶段要做出 production-ready 的复杂芯片,仍然需要 5 到 10 名不同领域的专家。
把这四个星号合起来看,更诚实的一句话是:
在一个边界清晰、规格严格、工艺简化的问题上,一个长程 Agent 第一次走完了从规格到版图的全程——这件事本身已经足够新。
三、为什么它依然重要:芯片行业的“可外包边界”被推动了
读到这里你可能会想:又是学术 demo,加了这么多限定,是不是该打个折?
恰恰相反。把那些限定都算上之后,剩下的东西反而更值钱。因为它证明的不是“AI 能画版图”,而是几件更结构性的事:
第一,验证驱动的闭环是真的跑通了。 它不是“生成 RTL 就交差”,而是发现 bug → 写脚本 → 看波形 → 定位 → 修复 → 再验证。这套循环,正是芯片设计里占总成本一半以上、也最难自动化的部分。
第二,物理反馈能回流到架构决策。 它根据布局布线之后的真实时序,回头去改微架构(early forwarding、乘法器结构)。这种“前后端联动”,在人类团队里往往是 tape-out 前最后一刻最痛苦、最容易引入新 bug 的环节。
第三,设计空间探索被自动化了。 同一份规格,它并行尝试多种流水线变体、每种都做到版图级别再比较。这是人类团队因为成本而几乎不会做的事。
第四,它和整个行业的节奏对上了。2026 年 GTC 前后,NVIDIA 联手三大 EDA 厂商集体转向 Agentic EDA——而 Verkor 用一个公开、可复现的 CPU 案例,把“规格 → GDSII”这条线从 PPT 变成了论文附录。放在一起看坐标更清楚:
| 路线 | 代表 | 覆盖范围 | 和 Design Conductor 的差别 |
|---|---|---|---|
| 强化学习布局 | Google AlphaChip | 主要做 floorplan / 宏布局 | 已用于多代 TPU,但不是“自然语言→整芯片” |
| 领域大模型 | NVIDIA ChipNeMo | 脚本生成、bug 分析 | 偏 copilot,不是 12 小时自主出版图 |
| Agentic EDA 平台 | Cadence ChipStack、Synopsys AgentEngineer、Siemens Fuse EDA AI Agent | 多工具编排、验证、DRC | 厂商生态级;Verkor 押的是“单一 Agent 端到端” |
| 开源物理流 | OpenROAD | RTL→GDS 自动化 | Design Conductor 调用它,而不是它本身 |
Verkor 的赌注,是 AlphaChip 解决“一个环节”,而 Design Conductor 想接管“整条链”。论文里那句愿景说得很大:今天 100 人、18–36 个月才能做一颗 leading-edge 芯片的团队,未来或许能并行探索多个架构、每个都做到 GDSII,3–6 个月就 tape-out。届时资深工程师不再当“工具操作员”,而是退到架构判断和规格设计上。
这话该信几分见仁见智。但它真正在推动的,是芯片设计这个行业的**“可外包边界”**——哪些活可以交给 Agent,哪些活必须留给人。VerCore 把这条线,往“可以交出去”的方向挪了一截。
值得盯着的几个时间点:Verkor 称已在和多家全球 Top 10 无晶圆厂合作部署,计划开源 VerCore 的 RTL 和重建脚本,并在 DAC 展示 FPGA 实现。这些会是社区独立复现、独立审计这套说法的关键节点。
四、一个诚实的脚注:它现在更像“实习生中的天才”,还不是“总师”
论文最让我欣赏的,是它的 §5——作者把这套系统的“翻车现场”也写了进去:
- 架构直觉不足:初版 forwarding 的关键路径过长,它只有在看到时序报告之后才反应过来;有一次为了凑时序,竟然想去“加深流水线”这种重活,白白烧了很多 token,而其实有更简单的解法。
- 对 RTL 的理解偏软件:它会把事件驱动的 Verilog 当成顺序执行的代码来推理,一度以为“代码行数少 = 关键路径短”。
- 算力换经验:用团队自己的话说,这是 “trading experience for compute”——人类靠经验一眼避开的坑,它要靠烧算力去填,而且设计越复杂,算力需求增长越是非线性。
后来 Verkor 自己也承认了另一个质疑:开源 RISC-V 核很可能早就进了前沿模型的预训练数据,这让 VerCore 这个任务对模型来说“相对简单”。在他们 5 月的后续报告 Design Conductor 2.0 里,系统花 ~80 小时,从一篇 TurboQuant 论文出发设计了一个 LLM 推理加速器——这是往“更大、更没有现成答案”的方向走。但复杂度和签核要求,也远不是 VerCore 能比的。
所以对今天的 Design Conductor,一个公道的定位是:它是个不知疲倦、技艺精湛的“实现者”,但还不是能定方向的“架构总师”。 它把工程师从“工具操作”里解放了出来,却也把“判断力”这件事,更醒目地推回到了人这一侧。
写在最后
回到开头那 219 个词。
这条新闻真正的信号,不在“12 小时”有多快,也不在“7nm”有多先进——这两个数字都打了折扣。它真正告诉我们的是:当一个工程问题的规格足够清晰、验证足够可度量时,从需求到交付物的整条链,正在变得可以端到端地交给 Agent。
芯片只是第一个被这么验证的硬骨头。对做数据、做 IP、做任何“高价值交付物”的人来说,值得提前想清楚的问题或许是:当生成本身的成本和周期被压到极低,协作、信任与交付的边界——谁定规格、谁担责任、谁验收、价值在哪一环结算——会不会比“谁来动手做”更早成为真正的竞争焦点?
那 219 个词写得有多好,结果就有多好。这句话,可能比“12 小时造芯片”更值得记住。
参考资料
- Verkor Team, Design Conductor: An agent autonomously builds a 1.5 GHz Linux-capable RISC-V CPU, arXiv:2603.08716, 2026 — https://arxiv.org/abs/2603.08716
- Verkor 官网 — https://verkor.io/
- IEEE Spectrum, How Agentic AI Chip Design Built a Full RISC-V Core — https://spectrum.ieee.org/ai-chip-design
- RCR Wireless, Verkor claims its AI agent designed a chip from scratch — https://rcrtech.com/semiconductor-news/verkor-ai-agent-chip-design/
- ASAP7 PDK(ASU)— https://asap.asu.edu/
- OpenROAD 项目 — https://openroad.readthedocs.io/
- Google DeepMind, How AlphaChip transformed computer chip design — https://deepmind.google/blog/how-alphachip-transformed-computer-chip-design/
- Verkor Team, Design Conductor 2.0(TurboQuant 加速器), arXiv:2605.05170 — https://arxiv.org/abs/2605.05170