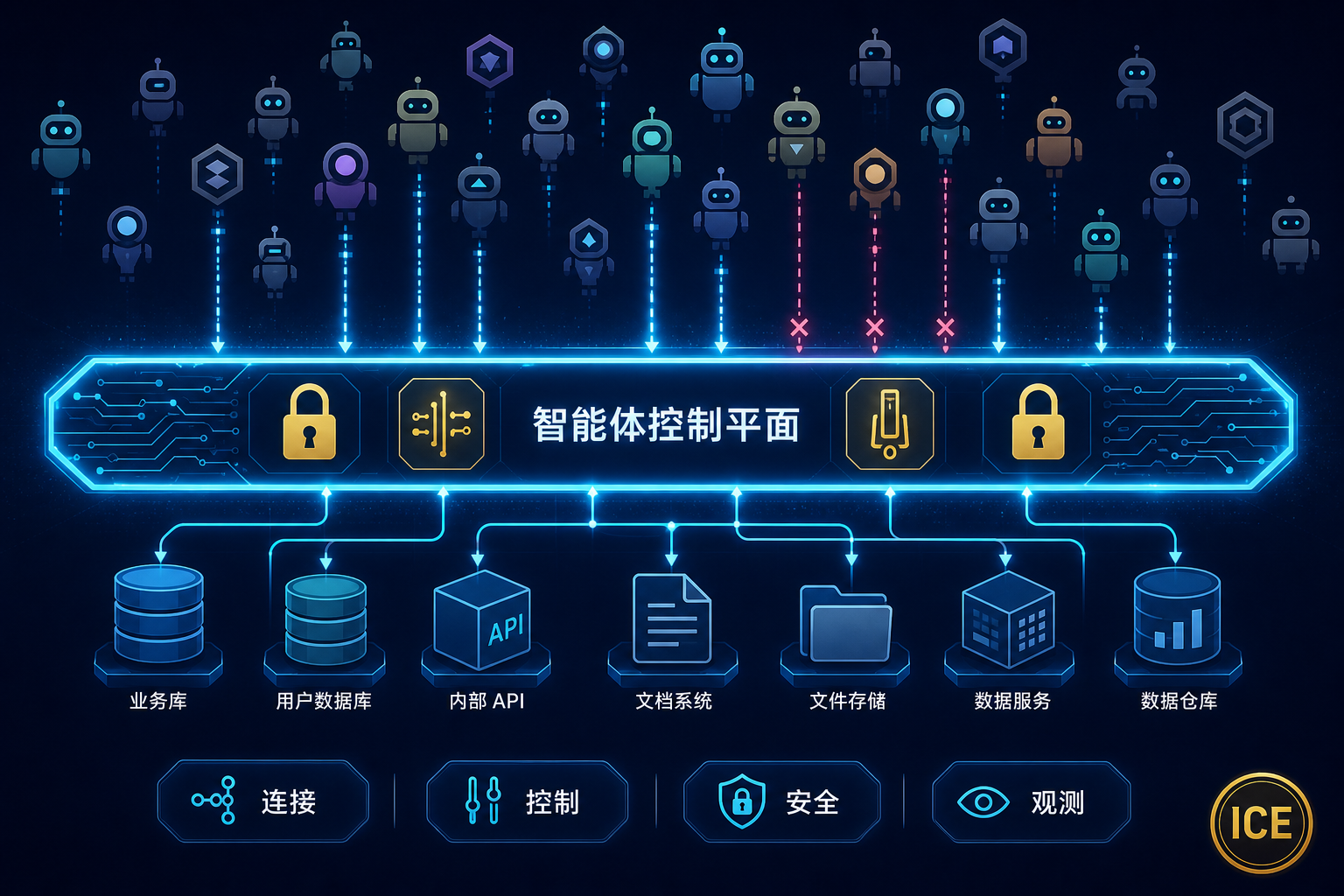
智能体控制平面:当"管不住的同事"越来越多,企业需要一个总开关
Deep Research 报告 · 企业智能体 × 治理架构 × 平台层 | 2026 年 6 月 | 约 14 分钟阅读
摘要
2026 年的企业里正在发生一件事:AI 智能体(Agent)涌进来的速度,远远快过 IT 部门能管住它们的速度。工程师在用 Cursor 和 Copilot,销售在用 ChatGPT,财务跑着一个不知谁搭的内部 Agent,没人说得清到底有多少个、连了哪些数据、把什么发给了外部模型。IBM 商业价值研究院的调研显示,96% 的企业已经在以某种方式使用 AI 智能体,而 94% 的企业承认这种"智能体蔓延(Agent Sprawl)"正在抬高安全风险和复杂度。
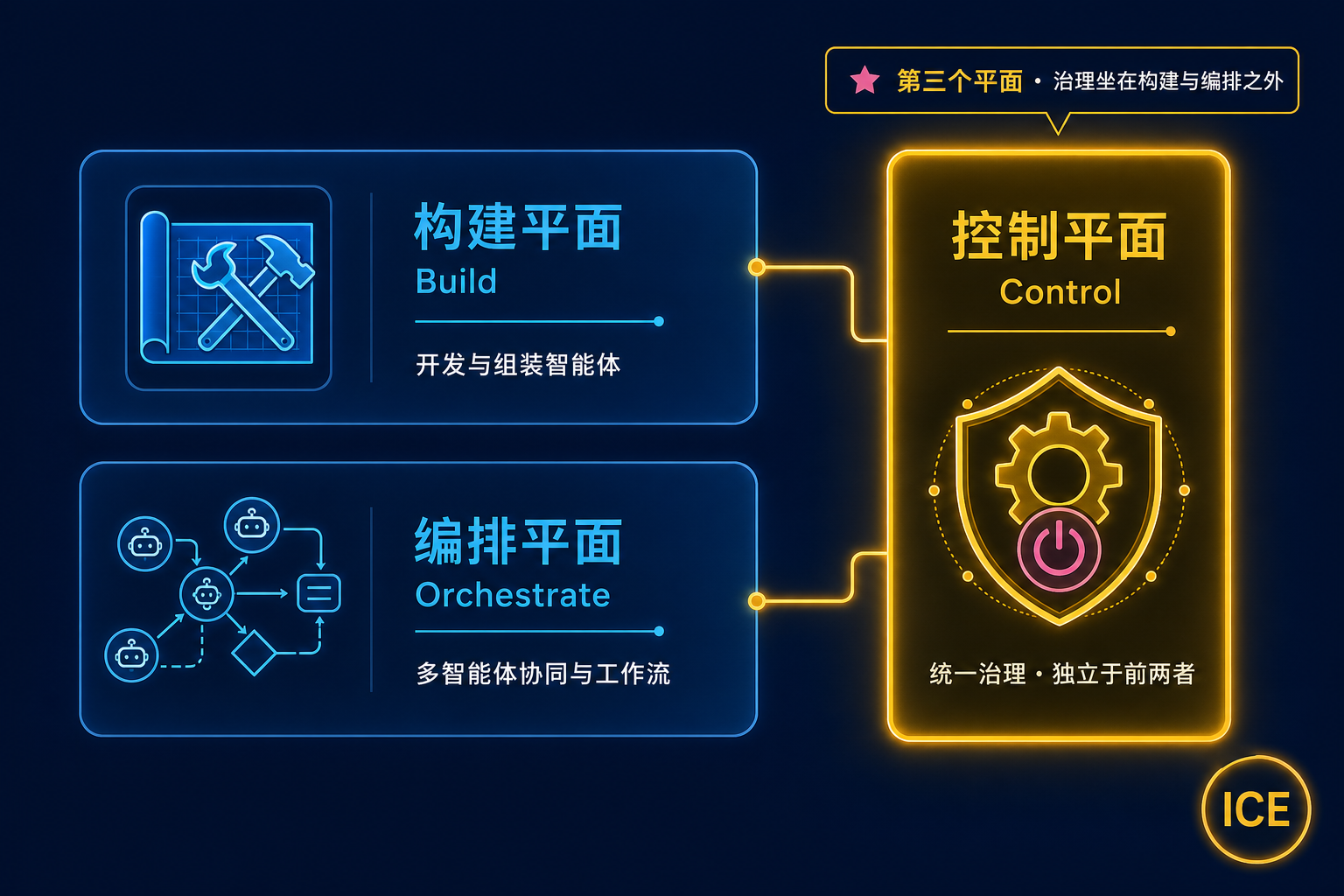
为了收住这个局面,一个新的架构层正在被叫出名字——智能体控制平面(Agent Control Plane,下文简称 ACP)。2025 年 12 月,Forrester 分析师 Leslie Joseph 把它正式定义为企业智能体架构里的第三个平面,与"构建平面(Build)"和"编排平面(Orchestrate)"并列。一句话概括它的职责:横在所有智能体和它们能够触达的所有系统之间,做统一的连接、鉴权、策略执行与观测——必要时,还能一把拉闸。
这篇文章不讲某一家厂商的产品,而是把"智能体控制平面"作为一个正在成形的品类来拆:它从哪来、和数据平面如何分工、四大核心职能是什么、它和 MCP / 编排层 / AI 网关的边界在哪、现在谁在做,以及——为什么它在架构上"绝对正确",落地却还卡在三道没补上的标准缺口上。
一、这个词从哪来:一个借自网络工程的概念
"控制平面"这个词不是 AI 圈发明的,而是从网络工程借来的:在 Kubernetes、服务网格、Cloudflare 里,系统都被切成两层——数据平面干活(转发流量、跑任务),控制平面定规矩(谁能进、流量怎么走)。一句话:用一个专门的部分,去治理系统的其余部分。
把这套思路平移到智能体身上严丝合缝:单个 Agent 在数据平面里跑任务、调工具、读数据;当它从 1 个变成 100 个、散落在各部门、用着不同框架时,你就需要一个控制平面站在它们之上统一监管。
真正把这个类比"封装成一个品类"的,是 Forrester。2025 年 12 月,分析师 Leslie Joseph 提出了三平面模型(Three-Plane Model),把企业智能体技术栈拆成三块:构建(Build)、编排(Orchestrate)、控制(Control)。他的核心论点很尖锐:
当企业要跨厂商、跨业务域部署各式各样的异构 Agent 时,治理必须坐在构建环境和编排环境之外——它不能依附于某一个开发框架或某一个编排引擎,否则就谈不上"统一治理"。
这个判断很快得到了市场印证。2026 年 2 月底,Forrester 调研了 47 家技术厂商,结果是:
- 79% 的厂商认为"智能体控制平面"是一个有意义且独立的产品品类;
- 92% 已经为"智能体治理 / 控制平面"指派了专门的产品经理或团队;
- 40% 报告说,已经有客户在 RFP(招标)里明确点名要"控制平面或等价能力"。
用 Leslie Joseph 自己的话说,今天我们还处在"智能体时代的拨号上网阶段(dial-up internet phase)"——架构的雏形已经清晰,但让它在企业级规模下干净运转所需的标准,还远远没跟上。
二、到底是什么:数据平面 vs 控制平面
IBM 给出的定义可能是目前最干净的一个:
智能体控制平面,是在一个组织内部署、运行、监控并治理所有 AI 智能体的那套系统。
换句话说,控制平面像一个中央指挥室:它不关心"某一个 Agent 内部怎么想",只关心"这一群 Agent 作为一个系统,该怎么协同、守什么规矩"。它充当 Agent 与各系统之间的中间人——动作执行前路由请求、校验权限、施加策略,执行后留下可观测的痕迹(谁、何时、用了什么数据、产生了什么结果)。
这里有一个容易被忽略、但极其关键的张力,CIO 杂志的一篇文章(作者是 Wipro 的 AI 架构师 Hari Om Garg)讲得很透:控制平面要做的,本质是给"概率世界"和"确定性世界"之间架一座桥。
| 确定性世界(业务) | 概率世界(智能体) | |
|---|---|---|
| 行为方式 | A 库的数据搬到 B 库,每次结果都一样 | 预测下一个 token,每次都可能不同 |
| 判断标准 | 合同要么合规,要么不合规;预算要么批,要么不批 | 用置信度(confidence score)说话,活在灰度里 |
| 出错处理 | 脚本报错就 debug;员工违规就培训 | "你没法开除一个算法(We cannot fire an algorithm)" |
一个自主的采购 Agent,因为"觉得这是个战略折扣"而签下了一份违反公司政策的合同——这不是一个技术 bug,而是一个责任事故。
控制平面的存在意义,就是不指望那个概率内核(LLM)自己守规矩,而是在它的输出真正触碰企业系统之前,用一层确定性的、硬编码的逻辑把它拦下来。用那篇文章的原话:
"提示词(Prompt)是在指挥大脑,架构才是在捆住双手。我们没法靠 prompt 把自己从责任问题里救出来。"
三、为什么是现在:智能体在"蔓延",而治理跟不上
为什么"控制平面"这个词在 2025 年底、2026 年初突然被反复叫起来?因为三股力量同时撞到了一起。
第一股:智能体蔓延(Agent Sprawl)。 AI 工具像当年的 SaaS 一样自下而上、绕过 IT 涌进来。Speakeasy 的观察很扎心:大多数企业一做审计才发现,组织里已有几十个在用的 AI 工具,绝大多数从没被批准过、没有一个被集中管理。
第二股:概率系统带来的新型风险。 传统软件确定、可复现;Agent 是随机的,偶尔会一本正经地犯错。于是冒出一整类过去没有的风险:数据泄露(敏感数据被丢进消费级工具)、提示注入(文档里埋指令劫持 Agent)、失控消耗(递归循环一夜烧掉五位数账单)、影子工具(没人知道却连着生产数据的 MCP)。
第三股:自上而下的合规与董事会压力。 一边是董事会下达"必须交付 AI 转型"的硬指标,一边是 EU AI Act 这类监管落地。于是问题从"要不要治理 AI"变成了"怎么治理 AI"。
把门全部锁死,会扼杀采用;把门全部敞开,会不断累积事故。两条路都走不通——这正是控制平面要解的结构性矛盾。一位财富 500 强零售商的 CIO 说得很直白:
"我们推 AI 的速度,快过我们治理它的速度。我不觉得这行里有谁不是这样。"
这里要厘清一个常见的混淆:"智能体控制平面"和"AI 治理(AI Governance)"不是一回事。AI 治理是纲领——是政策、是 NIST AI RMF / ISO 42001 这类框架、是定义"AI 该怎么用"的流程;而控制平面是让纲领在运行时真正生效的那套运行时架构:它在调用发生的那一刻执行策略、产出审计依赖的痕迹、给治理团队一份实时的 Agent/工具清单。框架定义"应该发生什么",控制平面负责"让它真的发生"。
四、核心架构:连接 · 控制 · 安全 · 观测
把各家的说法收拢一下,一个成熟的控制平面在架构上做的事情可以归成四大职能(Speakeasy 的"连接·控制·安全·观测"框架最为清晰),它们横在"调用方"和"目的地"之间,让每一次提示、每一次响应、每一次工具调用都走同一条受控通道:
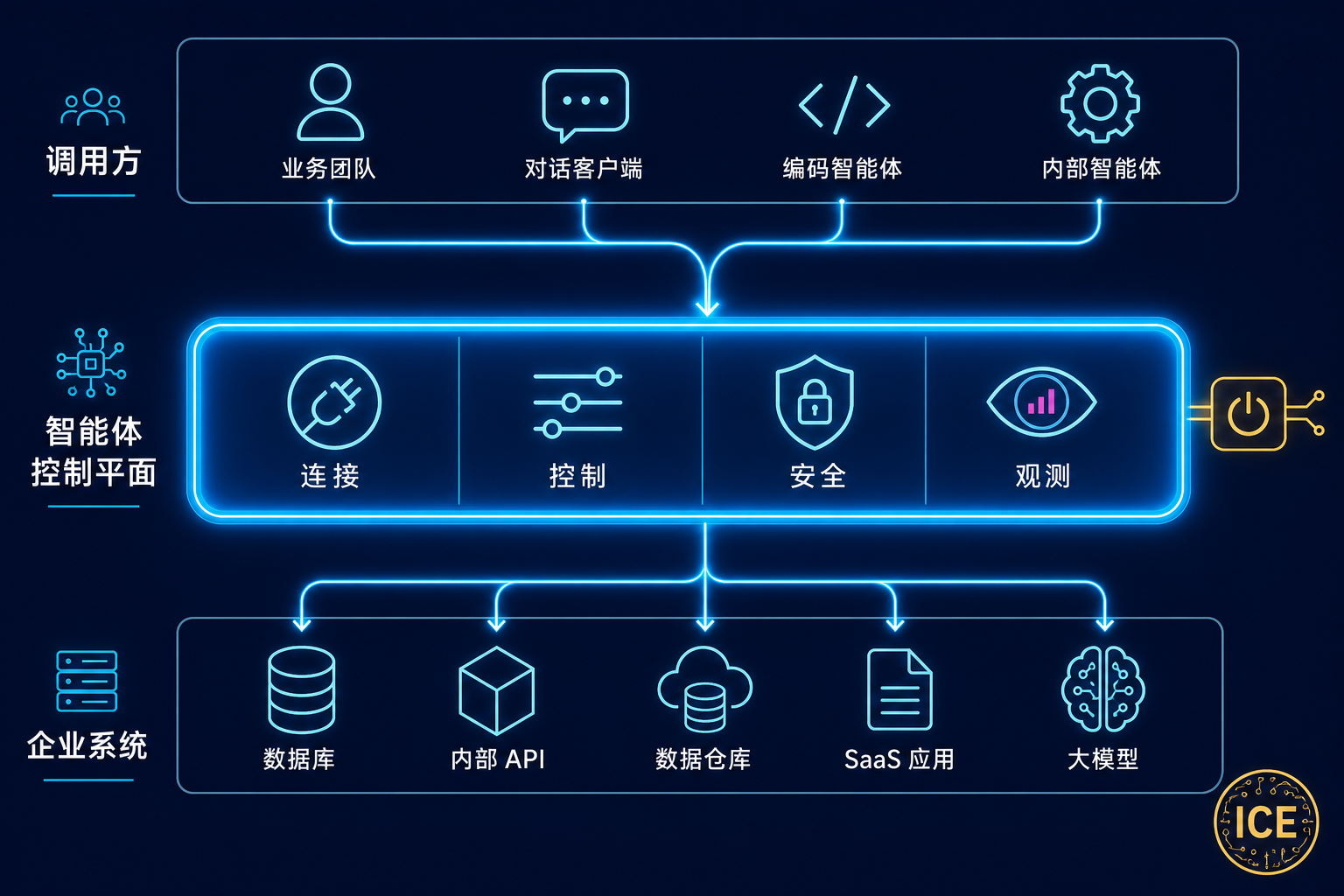
- 连接(Connect):把每一个 Agent(Claude、ChatGPT、Cursor、Copilot、内部 Agent……)和每一个值得连的系统(SaaS、内部 API、数据库、技能/工具)都拉到同一个平面上,配上按团队划分的注册表(Registry)和与 SSO 打通的身份。目标是让新能力几天内就能下放到对的团队,而不是几个月。
- 控制(Control):用可版本化、可测试、可执行的规则,约束"谁能在什么条件下用什么"。它在每一次请求上评估策略——这和一份"靠人自觉遵守"的 wiki 文档有本质区别。纸面上的策略,变成了运行时的策略。
- 安全(Secure):实时巡检每一次提示、响应和工具调用,主动拦截 PII 泄露与数据外泄,被动检测提示注入与影子 MCP,并接入已有的 SIEM 安全体系而不是取而代之。
- 观测(Observe):记录"到底发生了什么"——按团队、Agent、工具、用户统计 token 用量,对照组织目标,用真实数字证明这笔 AI 投资到底有没有效果,而不是靠传闻。
如果把这四个职能再拆细,IBM 列出的是一份更具体的能力清单:访问控制、Agent 与工具注册表、执行管理、生命周期管理(版本/测试/部署)、策略执行、请求路由、状态管理、遥测。它们在文档里常被归到"编排 / 治理 / 观测"几个层,但实际运转时是拧成一股绳的一套系统。
这里要单独拎出两个最有"控制平面气质"的设计,因为它们最能说明这一层和普通"Agent 管理面板"的区别:
① 确定性外壳 + 急停开关(Kill Switch)。 在好的设计里,LLM 大脑坐在中间,它可以自由推理、起草,但没有任何对外的直接权限——它碰不到 API、发不出邮件、跑不了 SQL。它只能"输出一个请求",这个请求撞上控制平面这层硬编码的逻辑闸门:
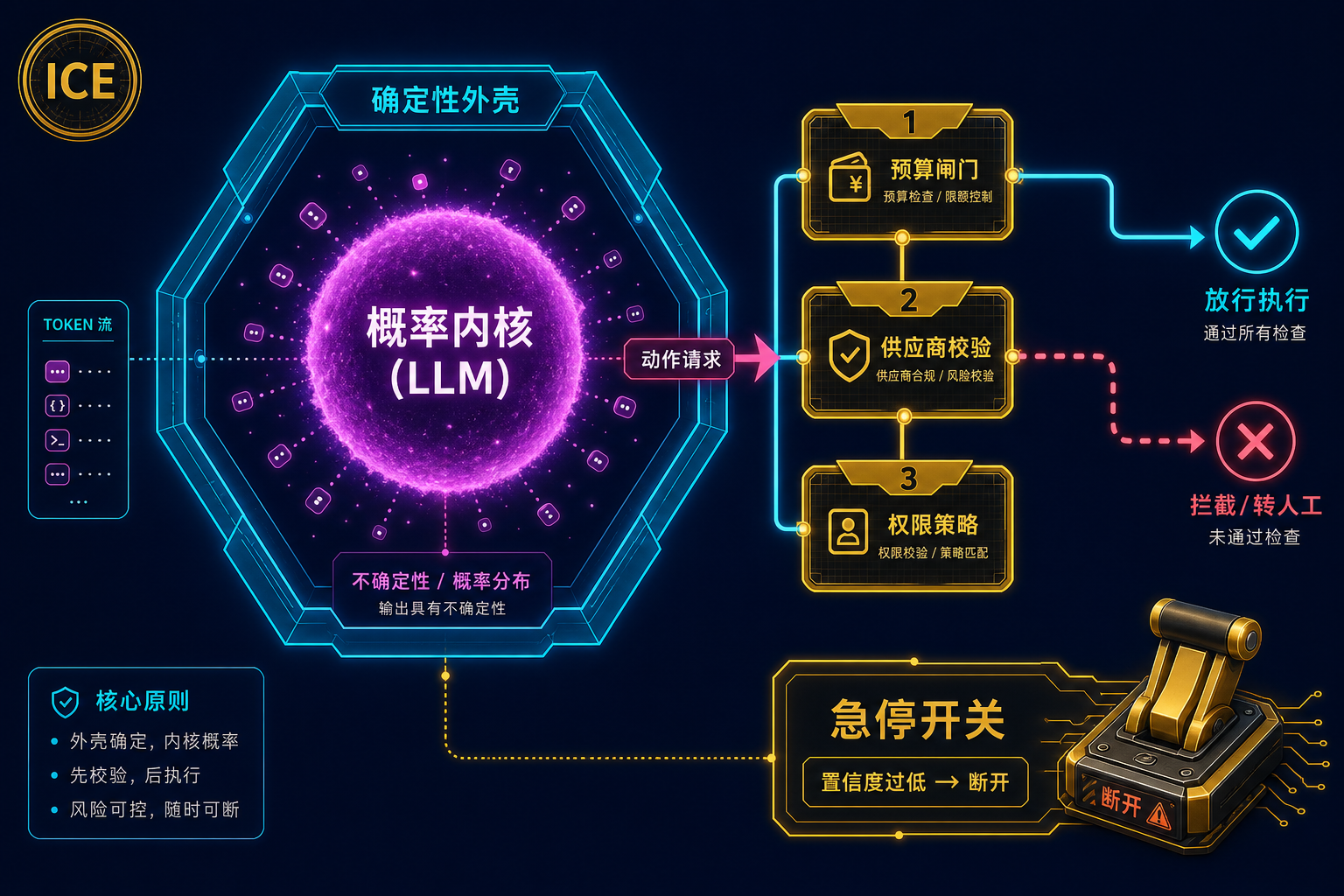
借用工程里的"断路器(Circuit Breaker)"思路:当一个客服 Agent 对自己答案的置信度跌破阈值,电路直接断开,把请求转交人工。最关键的能力,永远是"能一把拔掉电源"。
② 给 Agent 发"服务护照"(非人类身份管理)。 我们花了几十年把人的身份与访问管理(IAM)做好,但怎么"入职"一个 Agent?在这套思路里,每个 Agent 都被发一张服务护照,回答几个超出"权限"范畴的问题:谁是它的负责人(出事谁背锅、谁收告警)?它的预算是多少(token 上限、API 花费上限,防止那张五位数的账单)?它处于什么试用状态(先在"草稿模式 / 见习期"里只生成意图、由控制平面压住执行,让你能审计它的决策而不承担风险)?
五、和 MCP、编排层、AI 网关有什么区别
"控制平面"很容易和几个相邻概念搞混,尤其是 MCP、编排层和 AI 网关。它们不是竞争关系,而是不同的层——控制平面恰恰是把它们统起来的那一层。
| 概念 | 它管什么 | 和控制平面的关系 |
|---|---|---|
| MCP(模型上下文协议) | 单次交互中,上下文、工具、数据怎么结构化地喂给模型 | MCP 解决"一次调用"里模型怎么连工具;控制平面是系统级的协调与治理,MCP 网关只是它内部的一个组件 |
| 编排层(Orchestration) | 多个 Agent / 多步工作流怎么串起来、按什么顺序跑 | 编排是"把活派下去";控制平面坐在编排之外,负责跨编排引擎的统一治理(这正是 Forrester 三平面把它们分开的原因) |
| LLM 网关 / AI 网关 | 应用和模型之间的代理:多供应商路由、API key、限流、缓存 | 网关只看得见"提示和补全";控制平面更宽,把 LLM 网关、MCP 网关、身份、策略、观测统一到一套架构下 |
用 IBM 的话区分得最简洁:
控制平面编排和治理的是跨 Agent 的系统级协调、控制与生命周期管理;MCP 定义的是单次交互中上下文、工具和数据如何被传入模型。前者关心 Agent 在更大系统里怎么运转,后者关心模型怎么处理一个具体请求。
换句话说:MCP 是"插头标准",编排层是"流水线调度",AI 网关是"模型路由器"——而控制平面,是那条把它们全部串成一条受控通道、并施加统一身份与策略的主干。一次完整的事故(用户经 SSO 认证 → 走 LLM 网关 → 触发 MCP 工具调用 → 响应里泄了数据)会在五个不同系统里各留一段痕迹,只有控制平面能把这五段拼成一条线。
六、谁在做:一张正在成形的厂商地图
这个品类还很年轻(不到两年),玩家来自完全不同的出身,各自占着一层往外扩。大致可以分成五类:
| 类别 | 代表玩家 | 出身/强项 | 短板 |
|---|---|---|---|
| LLM 网关 | Portkey、LiteLLM | 模型调用层:多供应商路由、限流、缓存、成本 | 看得见模型调用,却不知道是谁触发的、用的什么工具 |
| MCP 网关 / 安全 | Speakeasy、Runlayer、MintMCP | 工具调用层:MCP 鉴权、授权、巡检 | 看不见上面的模型层和背后的身份层 |
| 身份与访问 | Okta、Azure AD、Google Workspace | 知道"用户是谁",企业大多已部署 | 不知道用户在跑哪些 AI 工具、它们在拿数据干什么 |
| 观测 / 评估 | Langfuse、Arize、Galileo | 记录"发生了什么" | 只能记录,不能实时执行策略 |
| 策略 / 威胁检测 | Lakera、Fiddler | 实时巡检提示、响应、工具调用 | 能拦能查,却无法发放访问、管理身份 |
这张表暴露了核心难题:没有任何一个工具拥有跨所有层的关联视角。每个玩家都只看到同一次交互的一个切片。
往上还有两类"重量级选手",但都各有结构性局限:
- 超大云厂(Hyperscalers):AWS Bedrock、Azure AI Studio、Google Vertex 都有真实的治理能力,但它们的管控只覆盖经过自家平台的流量。一旦企业同时用 Anthropic、Mistral 和开源模型,就会得到三份互不关联的治理视图;不走云平台的内部 Agent 和 MCP 工具,则直接隐形。
- 企业平台/GRC 厂商:ServiceNow、CrowdStrike 这类玩家掌握着策略与风险层,但它们坐在流量之上、不在流量之中——能定义策略,却没法对每一次提示和工具调用做实时执行,除非从零搭一层新的。
还有一类是平台原生(Platform-native)的打法:数据/应用平台把控制平面直接长在自己的地基上。比如 Snowflake 在 Summit 2026 上把自己重新定位成"智能体控制平面",用 CoWork / CoCo 作为业务用户和开发者的入口(这一案例我们在《Snowflake CoWork:当"数据云"改名"工作智能体"》里单独拆过);IBM 则用 watsonx Orchestrate 主打同一块。它们的优势是数据和治理同源,短板是天然偏向自家生态。
一句话总结厂商图景:每一家都是为"拥有某一层"而生的,而控制平面要拥有的是"层与层之间的那条路"——目前没有谁不重写一大块架构就能直接拿下它。
七、最大的拦路虎:三道还没补上的标准缺口
架构上"绝对正确",不代表今天就能干净落地。Forrester 的 Leslie Joseph 把横在路上的障碍讲得很清楚:三平面之间的"连接组织"——也就是让一个平面的治理决策可靠地传到另一个平面的标准与协议——还很不成熟。他点出了三道缺口。
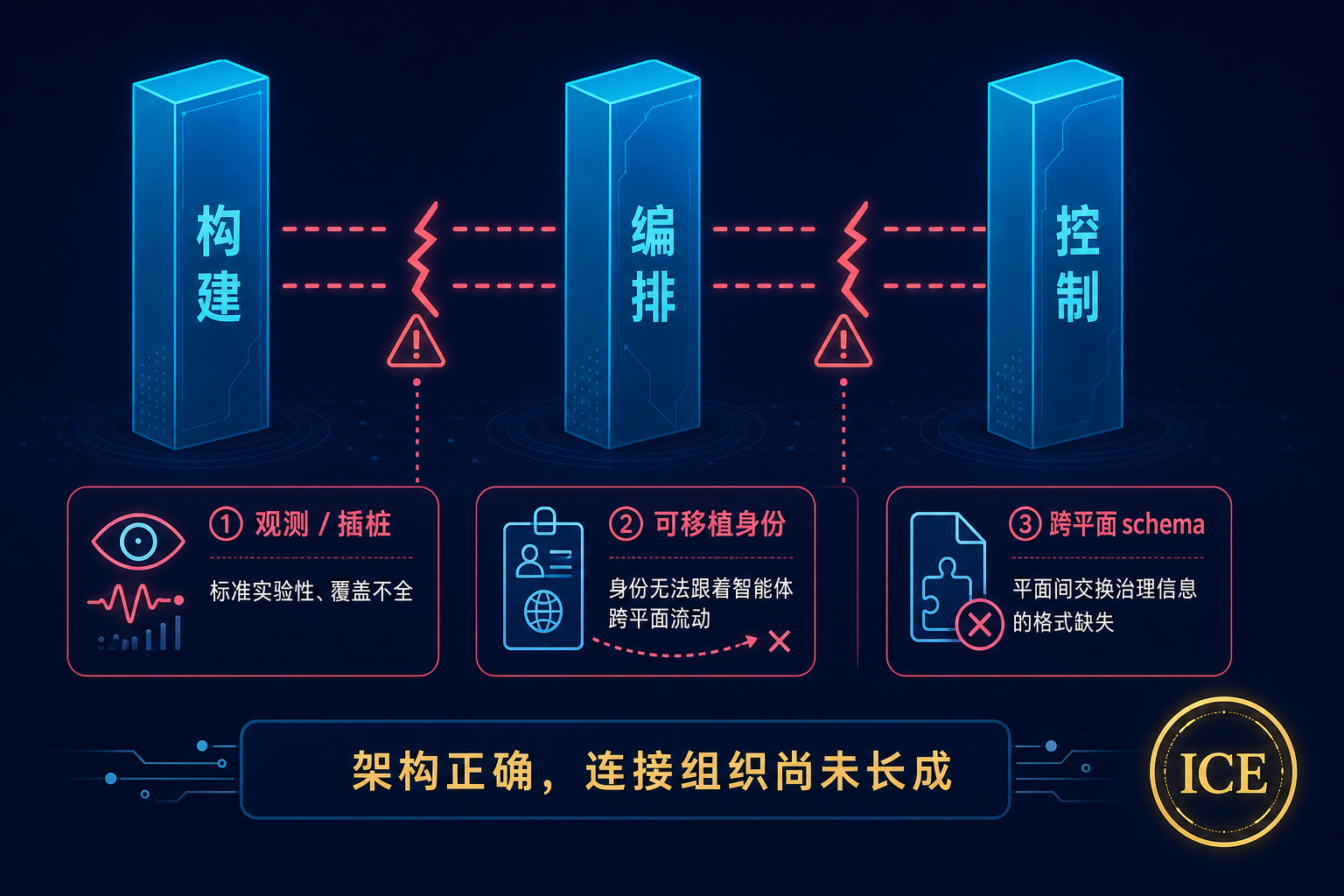
缺口一:观测/插桩标准不全。 一句话:控制平面治不了它看不见的东西。 目前 Agent 遥测的主要标准是 OpenTelemetry 的 genAI 语义约定,已经覆盖模型操作、Agent 创建与调用、工具执行 span 等,Datadog 等也开始原生支持。但它仍是实验性的、还在变;而且它能告诉你"Agent 内部发生了什么",却还说不清"在治理意义上它是谁、该套用哪条业务策略、干预该怎么跨平台传播"。财务侧的 FinOps FOCUS 规范解决的是另一个维度——成本遥测——两者都得收敛,控制平面才转得起来。
缺口二:Agent 身份与策略传播缺乏可移植标准。 这是最要命、也是其他两道缺口都依赖的一道。当开发者把一个 Agent 绑定模型、授予工具、定下权限和成本上限,这个 Agent 就背上了一个复合身份。要在运行时治理它,这个身份必须以标准化的格式,跟着 Agent 从构建走到部署再到生产。但今天还没有这样成熟的标准。协议层一片繁荣却各管一段:MCP(已归 Linux 基金会下的 Agentic AI Foundation 托管,2.1 版加入了服务端身份)管 Agent 到工具的连接,Google 的 A2A 管多 Agent 协作,IBM BeeAI 的 ACP 用 Agent 清单,微软 Entra Agent Registry 在自家身份体系里做发现——没有一个是为"跨三个平面的可移植身份"设计的。NIST 已经注意到这个空白,2026 年 2 月启动了 AI Agent 标准计划;W3C 的去中心化标识符(DID)是目前最接近"可移植身份原语"的东西,但落地尚早。
缺口三:跨平面治理 schema 还不存在。 就算前两道都补上,仍缺一层标准:构建、编排、控制三个平面之间,到底用什么格式交换"治理相关信息"。比如控制平面要撤销某个 Agent 的工具权限、调低它的成本上限,这个变更需要以一种机器可读、任何编排平台或 CI/CD 都能消费的"策略传播对象"传下去;编排层发现 Agent 行为漂移时,要发出一个控制平面能据此"挂起/改道/限流/升级"的治理级信号;构建工具发布新 Agent 时,要产出一份描述其模型绑定、工具访问、权限范围的"能力清单(Capability Manifest)"。这些 schema 现在都还没有。
Forrester 给企业的建议因此很务实:别等标准齐了再动——现在就按"构建/编排/控制"三平面分离来设计,先把观测插桩铺上(哪怕标准还在变),主动跟踪身份标准的走向。把这些缺口看成"边界在哪里需要标准"的路标,而不是否定这套架构的理由。
八、落地建议:先搭骨架,别急着上锁
如果你是要落地这件事的平台或安全负责人,下面几条是从各家实践里能提炼出的、相对靠谱的动作:
先画架构,再决定买什么。 把"连接·控制·安全·观测"四层摊开,盘一遍自己已经有了哪些(多半你已经有了 Okta、有了某个 LLM 网关、有了一点观测),再决定哪些缺口用专门厂商补、哪些自建。
从"连接与身份"这一层开始切。 这是大多数企业从"散养式采用"往上走时第一个卡住的地方,也是控制平面的地基——身份没统一,后面的策略和审计都是空中楼阁。
把"治理"和"使能"放进同一层,别拆成两个团队。 一个常见的失败模式是:安全团队管治理、平台团队管使能,结果治理团队因为看不见业务真实需求而把最有用的能力一刀切掉,使能团队则绕开管控、私下开例外——最后要么策略只活在纸面、员工照用个人 ChatGPT,要么跑得飞快、事故在复盘里才被发现。当同一层既路由流量、又执行策略,这对矛盾才消解。 Kubernetes 不会为"让负载跑起来"和"让负载安全跑"各设一个团队,控制平面本就该一手包办。
给高风险动作留人工回路 + 草稿模式。 新 Agent 不要直接上生产,先在"见习期"里只产出意图、由控制平面压住执行,审计够了再放行。
认真对待两笔"隐形成本"——延迟与锁定。
- 延迟:每多一层控制平面,就多一跳网络;交互式场景影响不大,但串了 20 多步调用的 Agent 工作流会把延迟累积成好几秒,同步做内容巡检还会再加在关键路径上。可以用异步巡检换延迟,代价是部分流量不能实时拦截。
- 锁定:这个品类不到两年、架构还没定型,厂商可能被收购、方向可能突变。缓解之道是在集成点上坚持开放标准——身份用 OAuth 2.1、观测用 OpenTelemetry、工具连接用 MCP,让组件可以替换而不必推倒重来。
结语:先造笼子,再放野兽
过去几年我们一直在比"模型够不够聪明",2026 年的主题悄悄换了——比的是"你的护栏够不够强"。
智能体控制平面之所以是个真命题,不是因为它新潮,而是因为它对应了一个不可逆的现实:企业正在迎来一支数字劳动力,而你没法开除一个算法。 你能做的,是在它动手之前,用一层确定性的逻辑替你守住边界;在它跑偏时,保证伤害是可控的、可审计的、能一把拉闸的。
从 ICE 的视角看,这件事有三层值得记住:
- 概念上,它把"控制平面"这个网络工程的老智慧,干净地平移到了智能体时代——治理必须独立于构建和编排,成为第三个平面。
- 架构上,它的价值不在于发明新组件,而在于把已经存在的网关、身份、策略、观测拧成一条能互相看见的受控通道——拥有"层与层之间那条路",比拥有任何单独一层都更难,也更值钱。
- 现实上,它今天仍处在"拨号上网阶段":架构正确,但身份可移植、跨平面 schema、统一观测这三道标准缺口没补上之前,"厂商无关的统一治理"还得靠大量手工胶水。
所以这一年最务实的姿势,也许就是那句话:别只顾着造更聪明的机器人,先把它干活的那个笼子造好。 等标准这层"连接组织"长出来,你已经站在了对的架构上。
参考资料
- Forrester, Leslie Joseph:《Agent Control Planes Still Need A Robust Standards Stack》(2026-03,含三平面模型、47 家厂商调研数据、三道标准缺口) — https://www.forrester.com/blogs/agent-control-planes-still-need-a-robust-standards-stack/
- IBM Think:《What is an Agent Control Plane?》(2026-05,定义、数据平面 vs 控制平面、八大能力、ACP vs MCP) — https://www.ibm.com/think/topics/agent-control-plane
- Speakeasy:《AI control plane: architecture and vendors》(2026-04,连接·控制·安全·观测四职能、参考架构与厂商图景) — https://www.speakeasy.com/resources/ai-control-plane
- CIO(Hari Om Garg):《The agent control plane: Architecting guardrails for a new digital workforce》(2026-02,概率世界 vs 确定性世界、急停开关、服务护照) — https://www.cio.com/article/4130922/
- NIST CAISI:AI Agent Standards Initiative(2026-02 启动) — https://www.nist.gov/caisi/ai-agent-standards-initiative
- OpenTelemetry:GenAI 语义约定 — https://opentelemetry.io/docs/specs/semconv/gen-ai/
- 延伸阅读 · 本站:《Snowflake CoWork:当"数据云"改名"工作智能体"》 — /posts/2026/06/260602-snowflake-cowork-agentic-control-plane
本文为 ICE 技术栈原创解读,基于公开资料整理与分析,不构成任何投资或采购建议。文中观点仅代表作者个人立场。