Diagram as Code:用 JSON 生成架构图的 AI 工作流
AI 应用 · Diagram as Code · 工作流 | 2026 年 5 月 | 约 8 分钟阅读 · 含可运行 demo
如果你最近让 AI 帮你画过一张架构图,大概率经历过这种循环:
写一段 prompt → 等模型出图 → 不太对 → 换个说法再来一遍 → 还是不对 → 再换……
每次以为“这次能行了”,结果模型把 3 个节点画成 5 个、连线方向反了、左侧的模块莫名其妙跑到了右侧。画一张严谨结构图所花的时间,常常比想清楚这张图要表达什么还要长。
而最近画图的方式,正在被另一种链路替换:
写一段 JSON,把它扔给 AI,一次性生成整张图;要改,就只改 JSON,再生成一次。
听起来像是一个“小工具上的小变化”,但我相信它其实是个范式问题:图,从此不是“提示出来的”,而是“被定义出来的”。
下面这篇是我的整理,也带一个最小可用 demo——文末那几张图,全部是用本文描述的方式真实生成的。
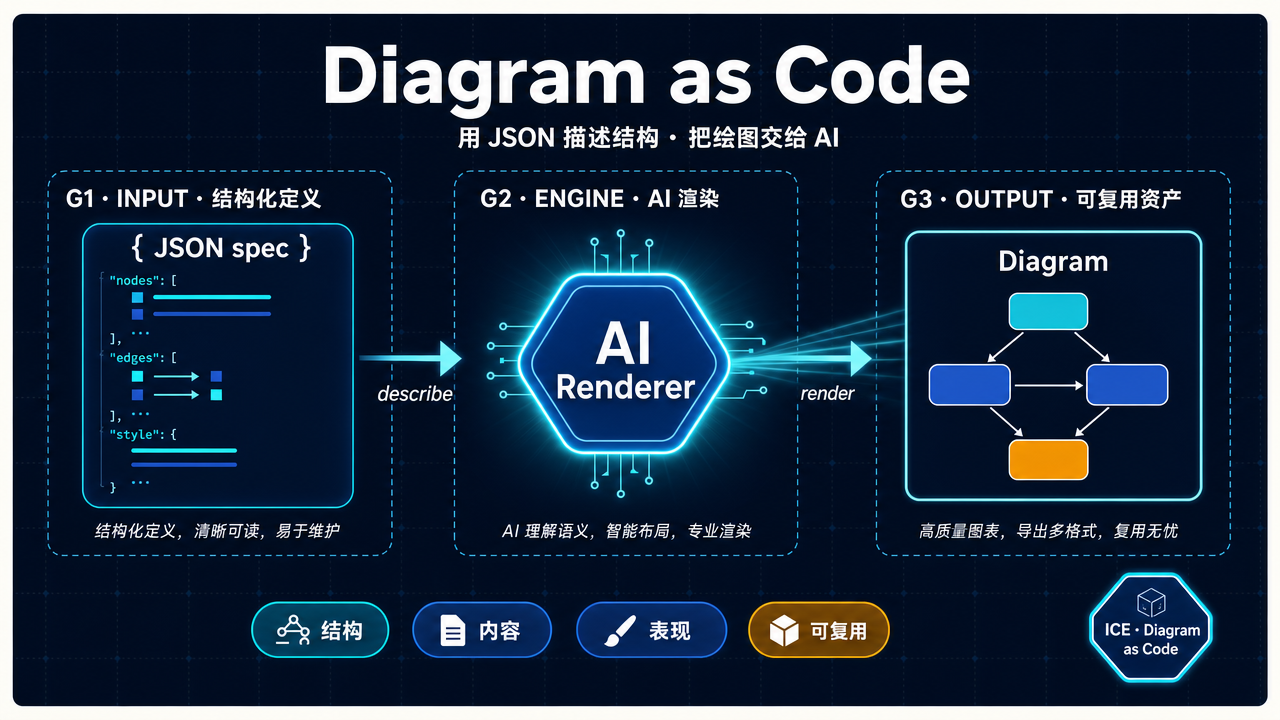
一、从“AI 提示词画图”到“Diagram as Code”
真正有趣的对照,是“用一段自然语言提示模型画图” vs “用一份结构化 spec 让模型渲染图”。 把它们摆到一起,差别一眼就看到了。
如果你已经在用 AI 画图,那你大概率正在用第一种。问题来了——它够好吗?
现状 · AI 提示词画图
构思 → 写一段自然语言 prompt → 等图像模型出图 → 不对 → 换种说法 → 再出工具代表:Midjourney / Stable Diffusion / DALL·E / GPT image / Gemini Flash Image。
这一代解决了“画”的体力,但同时暴露了一个新短板——
自然语言对结构的描述,天然不稳定。
“左边 3 个节点连到中间 1 个节点,右边再分出 2 条” 这句话, 模型可能给你画 5 个节点、箭头方向反了、连线对象错了。
对海报、插画、概念图,这种“飘”是可以接受的——甚至是优点。 但对架构图、流程图、层次图这类严谨的结构图——它远远不够。
演进 · Diagram as Code
抽象结构 → 写 JSON → AI 渲染 → 改 JSON → 再生成关键差别:用一个机器友好的中间格式(JSON / DSL)代替模糊的自然语言,把“图的拓扑”变成可被精确描述、可被 diff、可被一致复现的结构。
把两种方式摆到一张表里:
| 维度 | AI 提示词画图 | Diagram as Code |
|---|---|---|
| 表达介质 | 一段自然语言 | 结构化 JSON / DSL |
| 输出可控性 | 不稳定,容易“飘” | 高度可控,可重复复现 |
| 修改成本 | 重写 prompt,再碰运气 | 改几行 JSON,再跑一次 |
| 复用方式 | 攒 prompt 模板 | schema + 参数化模板 |
| 协作方式 | prompt 版本管理麻烦 | 可走 Git、可 diff、可 review |
| 一致性 | 靠模型当天心情 | 靠 schema 与色板天然约束 |
| 适合场景 | 海报、插画、概念图 | 架构图、流程图、层次图 |
一句话总结:
图,不再是“随便提示一下生成的”——它是被精确定义、然后渲染出来的。
接受这一点,后面的所有变化才能讲得通。
二、JSON:设计的“中间语言”
在这个工作流里,JSON 不只是数据格式——它是一种设计表达语言。
它把“一张图”拆成了三个机器可懂的维度:结构、内容、表现。

1. 结构 Structure
定义“图是怎么组织的”:
- 有哪些节点
- 节点之间是什么关系
- 层级和流向是什么
最简单的一段 JSON,只需要 8 行:
{
"nodes": [
{"id": "A", "label": "输入"},
{"id": "B", "label": "处理"}
],
"edges": [
{"from": "A", "to": "B"}
]
}把这段 JSON 直接交给图像模型,得到的图就是下面这张——这一节的所有原理,在这张图里压成了一组“输入 → 处理”:
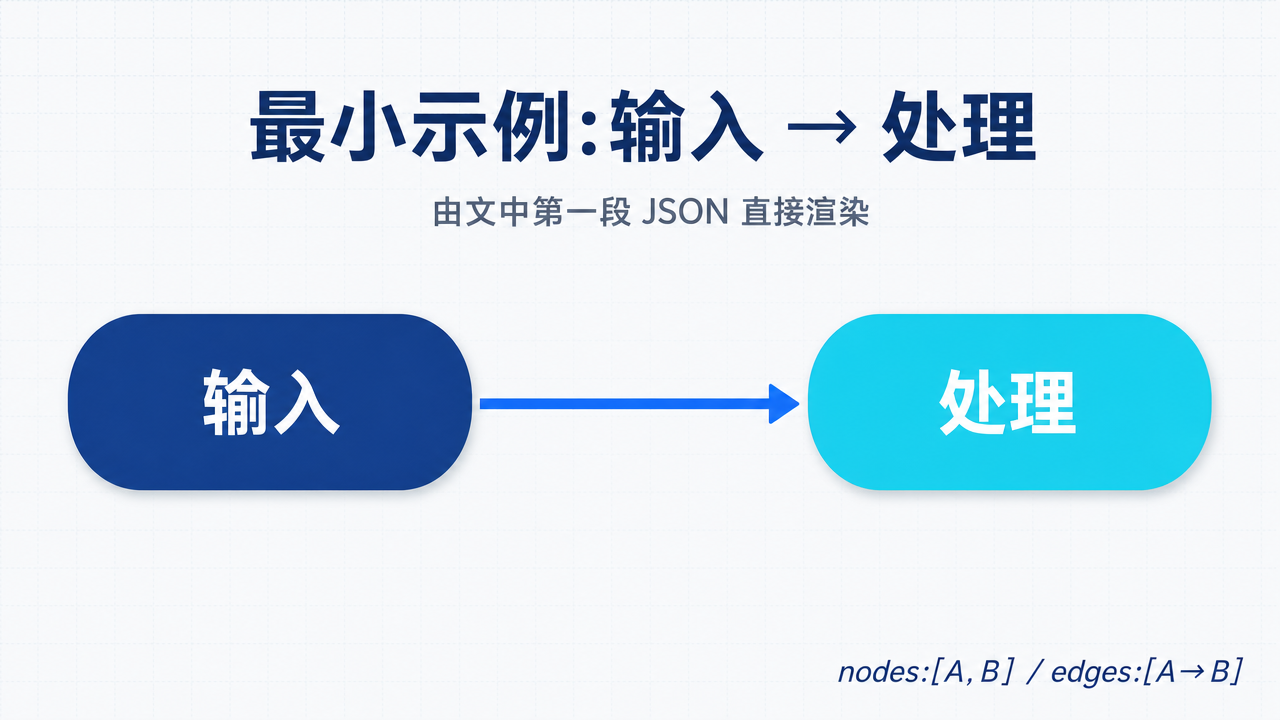
✅ 这张图是真渲染出来的,不是事先备好截图。生成方式见本文最后的“实现验证”。
2. 内容 Content
定义“图里写了什么”:标题、文案、注释、说明。 内容层是“图说了什么”,是给读者看的部分。
3. 表现 Style
定义“图长什么样”:色板、布局、字体、强调风格。 表现层只有一个目的——让结构与内容被一眼看懂。
三者组合在一起,就是一张图的“完整定义”。 把这三层各自独立、再组合,你已经在做“设计的工程化”。
4. 进阶 · 当 spec 长到生产级
到这里你可能会问:真要把这套工作流用进生产,JSON 不会太单薄吗?
不会。简单的 nodes / edges 只是入门;一份要进 CTO 汇报、要进白皮书、要给监管/合规看的图,spec 会自然演化出几个“对模型友好、对协作友好”的工程模式。下面是反复用过、最关键的 5 个:
① canvas:把画布显式写出来
"canvas": {
"aspect_ratio": "16:9",
"orientation": "horizontal",
"background": "#F5F6F8",
"margin": "medium"
}不要让模型猜横版还是竖版。一句 aspect_ratio: "16:9" 比 prompt 里堆三句形容词稳定 10 倍。
② reference:用参考品代替形容词
"reference": [
"麦肯锡战略架构汇报页",
"华为企业级技术 PPT",
"政府白皮书的体系结构图"
]对图像模型而言,“具体参考品”比“抽象形容词”更有指向性。 “我要现代科技感” ≠ “我要某厂蓝白栅格风”。前者模型靠猜,后者模型有锚。
③ design_rules + avoid:正反并举,别只说“要什么”
"design_rules": ["strict grid", "flat 2D only", "rounded rectangles", "thin borders"],
"avoid": ["glow", "cyberpunk", "gradient overload", "3D effects", "marketing illustration"]经验之谈:avoid 列表往往比 design_rules 列表更重要。 你常常不是“知道自己要什么”,而是“清楚自己不要什么”——这是工程版本的 negative prompt。
④ color_system:命名色板,而不是到处写色值
"color_system": {
"primary": "#0067C5",
"accent": "#F4B400",
"muted": "#EEF2F5",
"border": "#1573C9"
}之后所有节点引用 primary / accent,而不是直接写 #0067C5。 改主题色只需改一处 —— 这就是设计 token,是 IaC 里“环境变量”那一套思路,搬到了图里。
⑤ 横切关注点 + 结构化注释
不是所有内容都属于某一“层”。安全、治理、可观测性、合规审查这类横切关注点,在 spec 里的优雅做法是单独成列(右侧整列 / 下方整带),而不是硬塞进某一层。
同时,在关键节点 / 块上挂一个结构化注释——叫 callout、badge、innovation_tag 都行——用来突出本图的叙事重点:
"layers": [
{ "id": "L1", "title": "数据接入", "callout": "★ 创新点 1" },
{ "id": "L2", "title": "计算编排", "callout": "★ 创新点 2" }
],
"crosscutting": {
"title": "全链路安全",
"position": "right_column",
"items": ["业务安全", "模型安全", "数据安全", "合规审查"]
}这样叙事可以独立调整(今年汇报强调创新一,明年强调创新三),而图本身不需要重画。
把这 5 个模式叠在一起,你的 spec 就从“2 节点示意图”升级为“一份能进汇报材料的架构图”。 而这次升级背后——你完全没有换工具,只是 JSON 多写了几个字段。
这是 Diagram as Code 真正的杠杆:复杂度可以线性增加,但工作流和工具栈始终不变。
三、为什么这不是简单提效?
如果只是“画得更快”,那这件事其实没那么重要。 真正重要的是:它换掉了你修改图的方式,也换掉了你和图的关系。
1. 从“撞运气改” → 语义级修改
过去你改图,做的是:重写 prompt、换措辞、再 roll 一次、祈祷模型这回能听懂。
现在你做的只是:
- "layout": "vertical",
+ "layout": "horizontal",
- "theme": "light",
+ "theme": "dark",你不再操作“图形”,而是在操作意图。
这一字之差,本质上是把图纳入了和代码同样的修改层级:修改的是约束,不是结果。
2. 从“祈祷者” → 规则定义者
在 prompt 工作流里,你做的事情更像“求模型”——求它别画错、求它色调别飘、求它别把节点摆乱。 在 Diagram as Code 里,角色彻底变了:
- 你定义规则(JSON / 模板 / 色板)
- AI 负责执行(把规则渲染成像素)
你从“求 AI 画图的人”,变成了“定义图的人”。
这不是话术。它意味着你的产出可以被复用、被参数化、被批量生成——这恰恰就是工程化的入口。
3. 从一次性产物 → 可复用资产
一张图,过去是“最终结果”;现在,它变成了“可复用的结构”。
JSON 可以:
- 像代码一样做版本管理(Git diff 看得到改了什么)
- 沉淀成模板(同一个团队的图自然风格一致)
- 批量生成不同变体(同一份 spec,跑出 4 种主题色板,只需替换
palette)
图第一次具备了“工程属性”。
四、这个工作流适合什么场景?
不是所有图都适合用这种方式做。先承认边界,再讲优势。
适合的场景有一个共性:信息结构清晰、视觉创意要求不高。
| 场景类型 | 例子 | 为什么适合 |
|---|---|---|
| 技术架构图 | 系统模块、服务调用、数据流向 | 本身就是节点 + 边 |
| 方法论 / 概念图 | 认知模型、转化路径、思考框架 | 强结构、弱视觉创意 |
| 产品 / 业务流程图 | 用户路径、功能拆解、业务闭环 | 信息结构稳定 |
| 状态机 / 决策树 | 审批流、风控规则、对话流 | 拓扑天然适合 JSON |
不适合的也很明确:品牌海报、艺术插图、情绪表达型视觉。这些靠“感觉”,不靠“结构”。再好的 prompt,也不能替代设计师对张力、节奏、情绪的判断。
把这条边界提炼成一句话:
过度结构化,会损失表达的“感觉”。
记住它,这个工作流就只会增益,不会反噬。
五、它真正改变的三件事
提效只是表象。真正改变的是协作方式和组织产出。
1. 降低表达门槛
你不再需要掌握复杂的设计工具。 你只需要一件事——能够清晰地结构化表达。
如果你能把一个想法说成“它有 3 个阶段、每个阶段有 2 个输入、最后汇合到 1 个输出”, 那这张图你已经会画了——你只是还没把它写成 JSON 而已。
2. 提高团队一致性
当团队共享同一套模板:
- 风格天然统一(色板写在 spec 里)
- 输出自动标准化(一份 schema 约束所有图)
- 不再依赖“某个人的审美”(图可以 review,可以 PR)
3. 极大提升迭代速度
需求变了:不需要重画,只需要 git diff 一下 JSON,再跑一次脚本。
尤其在快速试错、频繁调整的场景——比如内部技术分享、产品早期方案、博客配图——速度差不止一个量级。
六、本质:Diagram as Code
一句话总结:这是一次“基础设施级别”的视觉表达升级。
你应该熟悉这两个名字:
- Infrastructure as Code(IaC) — 把基础设施写成代码,Terraform 一类
- Configuration as Code — 把配置写成代码,GitOps 一类
它们都做了同一件事:把“原本靠人手工维护的东西”塞进版本管理与自动化流水线。
现在,轮到“图”自己被纳入这套体系了——这就是 Diagram as Code。
它不是一个工具,而是一种生产姿态: 你画图时的输入是 JSON、输出是 PNG,中间是一段可重复执行的脚本。
七、它还会演化到哪里?
这个方向才刚刚开始。下一步的想象空间集中在三处。
1. 从 JSON 到 DSL(领域语言)
未来不一定还要写完整 JSON。把高频结构折叠成 DSL,可能更顺手:
flow:
- 焦虑 → 分析 → 重构 → 增长一行 DSL,语义已经够 AI 渲染:
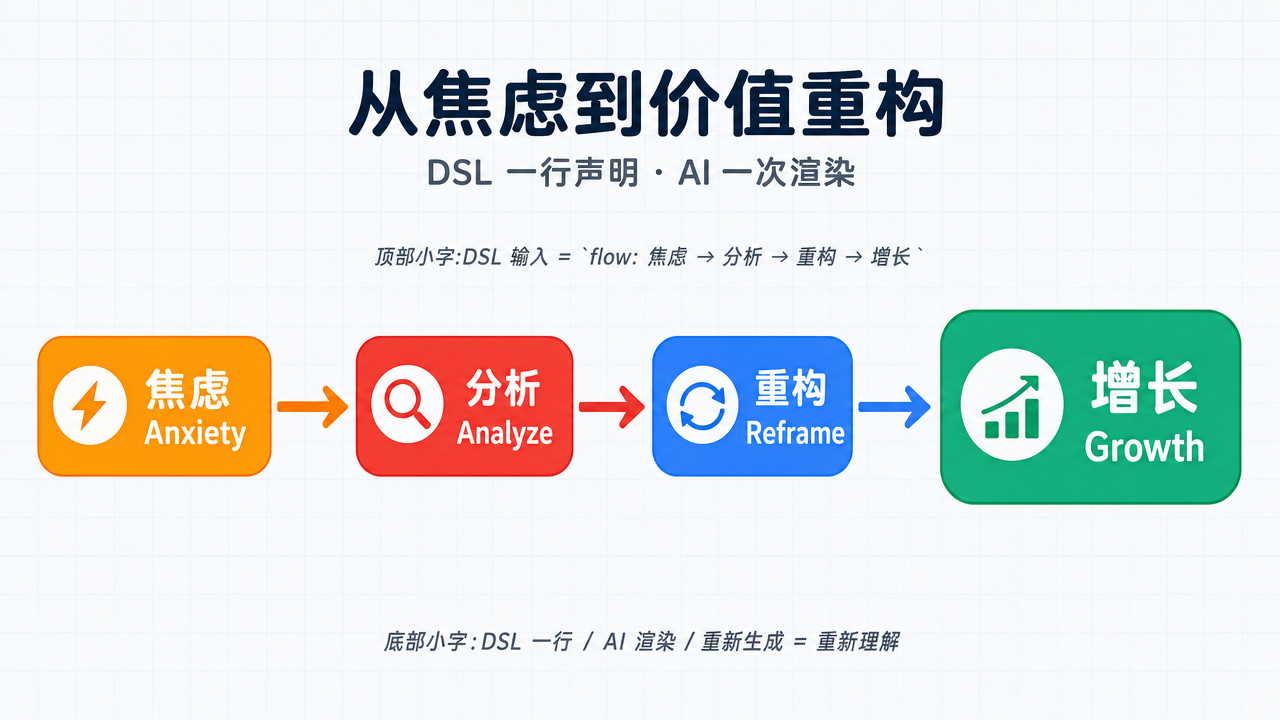
这张图不是 prompt 蒙出来的——它是上面那一行 DSL,经过文末的脚本生成的。
2. 从“写结构”到“生成结构”
再往前一步,JSON 自己也不需要你写——你只需要描述意图:
“描述一个从焦虑到价值重构的过程,4 个阶段,横向布局。”
链路就变成:自然语言 → LLM 生成 JSON → 图像模型渲染图。
这条链路,现在已经能跑了。短板只在两处:JSON schema 的稳定性 和 图像模型对 schema 的服从度。
3. 从静态图到动态图
把 JSON 接到实时数据上,图就不再是“快照”,而是“界面”:
- 架构图实时反映服务拓扑
- 流程图随流量自动高亮关键路径
- 指标卡片自动刷新数字
那一刻,Diagram as Code 就和可观测性合并了。
八、实现验证 · 一个最小可用的端到端 demo
这一节是文章的“工程闭环”:前面所有的论点,都用一段真实代码兑现一次。
我用一个 100 多行的 Python 脚本把这条链路跑通:
JSON spec ──→ 自然语言 prompt(由脚本翻译) ──→ 图像生成 API ──→ PNG脚本只做三件事:
- 解析 JSON——把
nodes / edges / style / canvas / reference / avoid / color_system这些字段读出来; - 翻译成图像 prompt——按一套固定模板把字段拼成约束严格的自然语言(标题、画布、布局、色板、节点列表、edge 列表、设计规则、避免项……);
- 调一次图像 API,写出 PNG——OpenAI 直连走
/v1/images/generations;OpenRouter 走/v1/chat/completions,并声明图像 modalities。
怎么跑
把脚本和示例 JSON 放在任意目录里,配一个 .env,然后:
# 单图渲染
python json_to_diagram.py render \
--input examples/simple-flow.json \
--output out/simple-flow.png
# 批量(目录里所有 *.json 都会跑一遍)
python json_to_diagram.py batch \
--in-dir examples \
--out-dir out后端选择由 .env 控制——脚本同时支持两条路径:
| 路径 | 模型示例 | API 端点 | 何时启用 |
|---|---|---|---|
| OpenRouter | openai/gpt-5.4-image-2 | /v1/chat/completions | 配置 LLM_API_KEY,IMAGE_MODEL 含 / |
| OpenAI 直连 | gpt-image-1 | /v1/images/generations | 配置 OPENAI_API_KEY,IMAGE_MODEL 不含 / |
本文配图由 OpenRouter 调用
openai/gpt-5.4-image-2生成。换google/gemini-3.1-flash-image-preview等其它提供商/模型同理。
一份完整 JSON spec 长什么样
下面是文末那张“焦虑 → 增长”图对应的完整 spec(节选):
{
"title": "从焦虑到价值重构",
"subtitle": "DSL 一行声明 · AI 一次渲染",
"type": "flow",
"style": {
"layout": "horizontal",
"theme": "light",
"palette": ["#F59E0B", "#EF4444", "#3B82F6", "#10B981"]
},
"nodes": [
{"id": "S1", "label": "焦虑 Anxiety"},
{"id": "S2", "label": "分析 Analyze"},
{"id": "S3", "label": "重构 Reframe"},
{"id": "S4", "label": "增长 Growth"}
],
"edges": [
{"from": "S1", "to": "S2"},
{"from": "S2", "to": "S3"},
{"from": "S3", "to": "S4"}
]
}这份 spec 被脚本翻译成一段约束严格的图像 prompt,然后交给图像模型,最终输出 PNG。
整条链路加起来:1 份 JSON · 1 个脚本 · 一次调用 · 1 张图。本地读 JSON、拼 prompt、写盘通常只要几秒;云端生图单次常见 约 1~3 分钟。
想自己复现? 把上面这段 JSON 存成文件,执行
python json_to_diagram.py render --input <你的 json> --output out.png,就完成了一次“Diagram as Code”。
结语
这个工作流的真正意义,不在于“画图更快”,而在于:
把视觉表达,从一段不稳定的提示词,转化为可被精确定义、被一致复现的结构。
当图可以被描述、被修改、被复用,它就不再只是“展示工具”,而成为一种可编排资源——和代码、配置、数据一样,可以进 Git、进流水线、进自动化。
这才是 AI 真正介入之后,最值得关注的变化。