深度调研|LLM4OR:当大语言模型遇上运筹优化

Deep Research 报告 | 2026 年 5 月 | 面向技术决策者、AI/OR 工程师与研究者
摘要
运筹优化(OR)是复杂系统决策的核心方法论,但建模过程长期依赖高度专业化人才——据 Gurobi 2023 年调查,81% 的求解器用户拥有硕博学位。这一"专家壁垒"严重制约了优化技术的规模化落地。
LLM4OR(Large Language Models for Operations Research)正在打破这道壁垒。从 NeurIPS 2022 的 NL4Opt 竞赛起步,到 2026 年 OptimAI 在基准上达到 88.1% 准确率(错误率降低 58%),LLM 正在实现"自然语言→数学模型→求解器代码"的端到端自动化。
本文梳理 LLM4OR 的起源、技术架构、代表性系统、落地案例与未来走向。
一、起源与发展脉络
2022:起点。 NeurIPS 举办首届 NL4Opt 竞赛,289 个测试实例,首次将"自然语言→优化建模"定义为独立 NLP 任务。关键发现:LLM 在理解领域术语(如"兆瓦时"、"启动成本")和推断隐式约束方面,能力超出预期。
2023:探索。 Stanford 的 OptiMUS V0.1 首次构建"LLM 即优化 Agent"的闭环——建模→生成代码→执行→反馈修正。OptiChat、OptiGuide 等对话式系统开始探索人机协作建模。
2024:爆发。 浙大与华为诺亚方舟实验室推出 ORLM、Chain-of-Experts 框架及 IndustryOR 工业基准。OptiMUS 升级至 V0.3,引入 RAG。多篇综述论文发表,LLM4OR 从零散探索走向系统化。
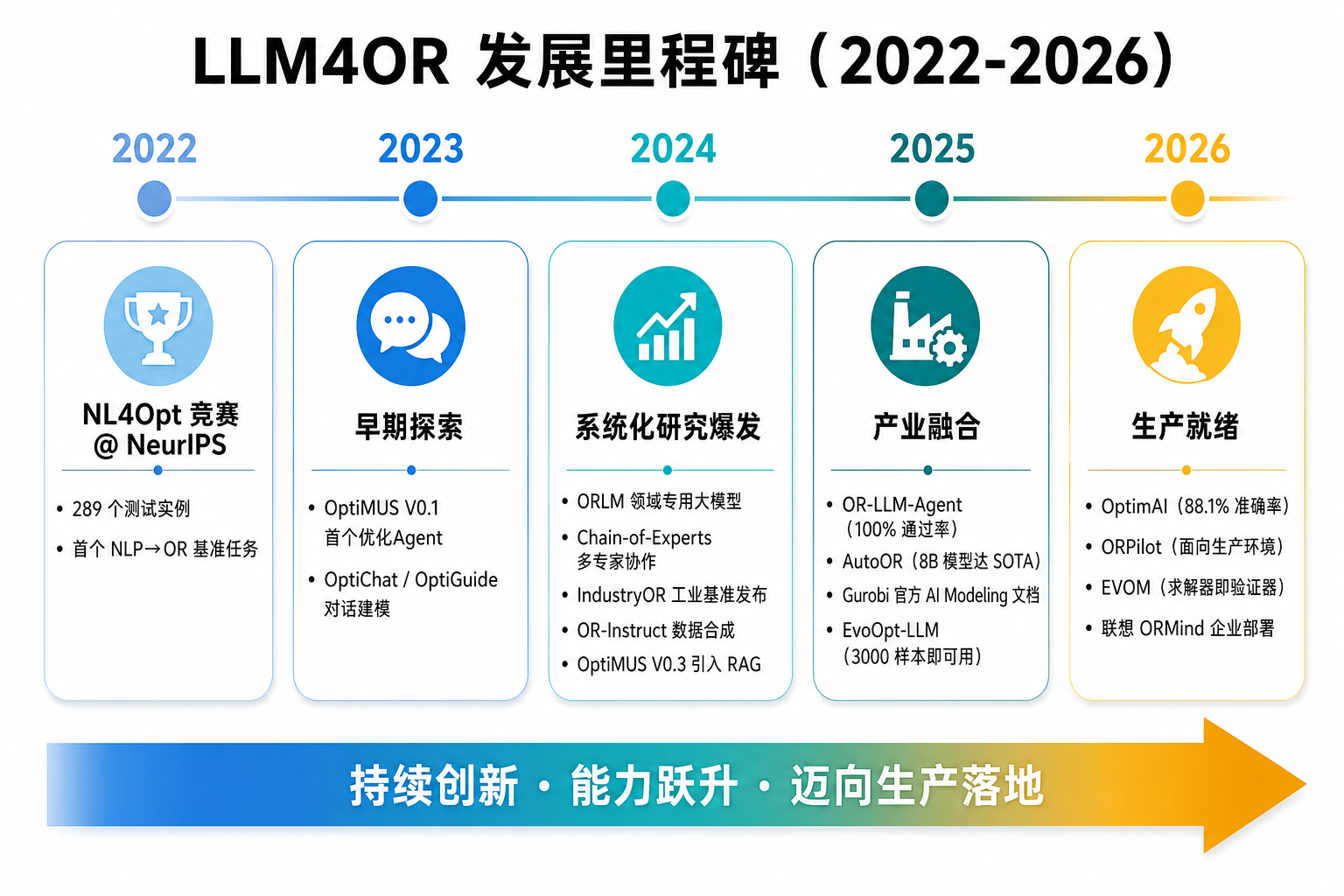
2025-2026:产业化前夜。 OR-LLM-Agent 在 83 个真实问题上达 100% 代码通过率和 85% 求解准确率;OptimAI 多 Agent 架构刷新基准;ORPilot 面向生产环境设计。Gurobi 官方发布 AI Modeling 文档和 Custom GPT——工业界正式入场。
二、定义与研究方向
2.1 什么是 LLM4OR
LLM4OR 是利用大语言模型将自然语言描述的优化问题,自动转化为数学求解器可执行的形式化模型(数学公式或代码)的技术范式。简言之:用户说人话,系统出模型。
2.2 与相邻概念的对比
| 维度 | LLM4OR | AI 组合优化 | AutoML | 传统 OR |
|---|---|---|---|---|
| 输入 | 自然语言 | 结构化实例 | 数据集 + 任务 | 人工分析 |
| 输出 | 模型/代码 | 可行解 | 模型配置 | 数学模型 |
| 专家依赖 | 低 | 中 | 低 | 极高 |
| 成熟度 | 研究→早期产品 | 研究+部分生产 | 成熟 | 工业标准 |
2.3 三大研究方向
- 自动建模(Automatic Modeling):LLM 将自然语言翻译为数学模型或代码——最核心方向
- 辅助优化(Auxiliary Optimization):LLM 生成启发式策略、算法算子,与传统算法协作
- 直接求解(Direct Solving):LLM 作为独立优化器直接产出解——仍处早期
三、核心架构与技术栈
一个完整的 LLM4OR 系统遵循如下端到端流程:
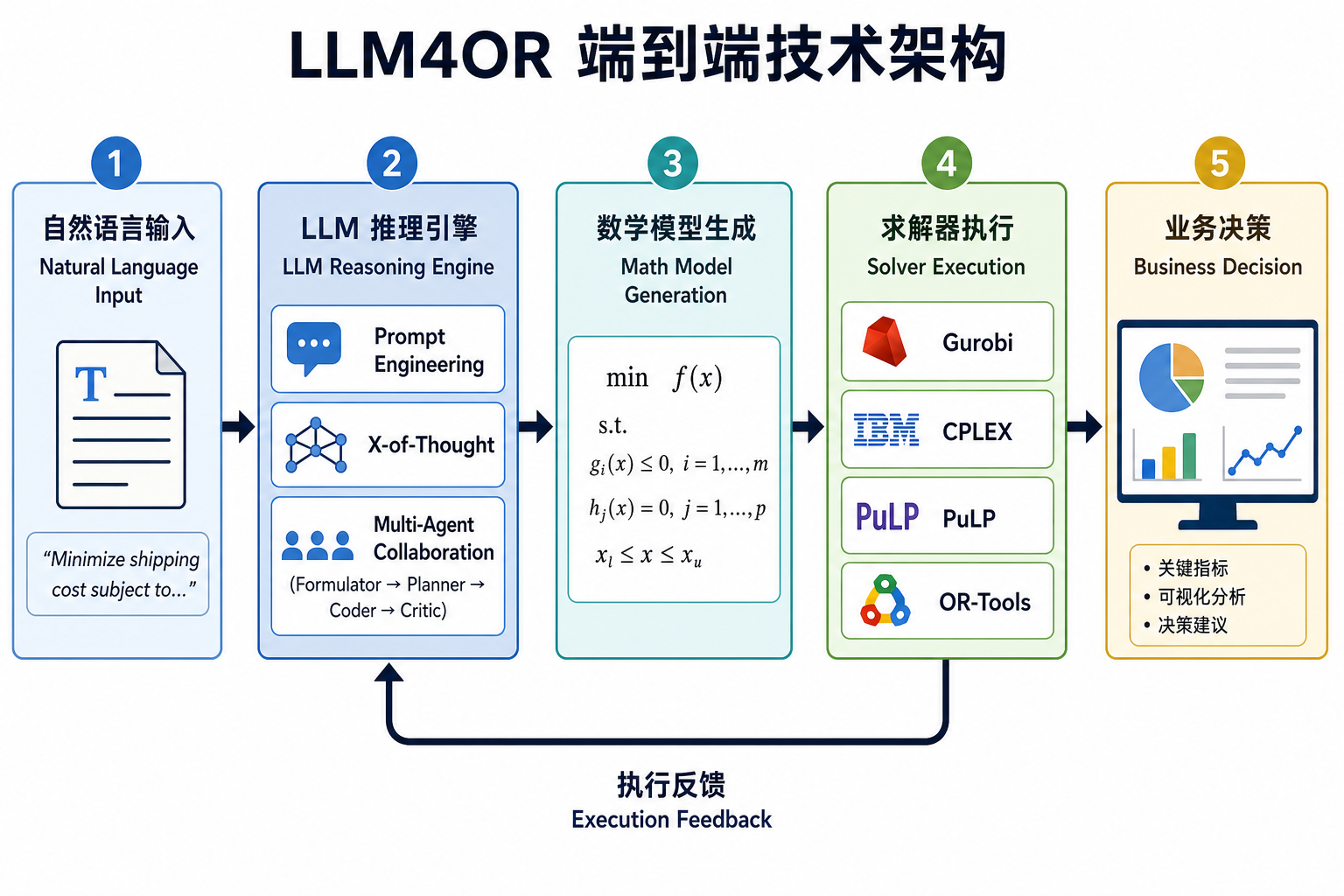
自然语言 → LLM 推理 → 数学模型 → 求解器执行 → 业务决策,求解器执行结果反馈回 LLM 迭代修正,形成闭环。支撑这条链路的是四大技术模块。
3.1 数据合成与模型微调
高质量训练数据稀缺且标注昂贵,当前有两条合成路线:
- 问题中心:以已有问题为种子,变换约束、改写场景来生成新题。代表:OR-Instruct、LLMOPT
- 模型中心:先生成数学模型/代码,再反向撰写问题描述,对难度和类型有更精细的控制。代表:OptiBench、ReSocratic
微调方面,主流用监督微调(SFT)。2025-2026 年的新趋势是强化学习驱动:AutoOR 用 RL 后训练 8B 模型,EVOM 把求解器当确定性验证器构建闭环训练——模型生成答案、求解器判对错、奖励信号回传。
3.2 推理框架
| 范式 | 代表 | 优势 |
|---|---|---|
| 简单 Prompt | NL4Opt baseline | 快速上手 |
| X-of-Thought | CAFA, Autoformulation | 复杂逻辑推理 |
| 多 Agent 协作 | Chain-of-Experts, OptimAI | 可解释、容错高 |
| Prompt + 微调 | ORLM, AutoOR | 泛化与精度兼顾 |
| 产业级 Agent | ORPilot | 面向真实业务 |
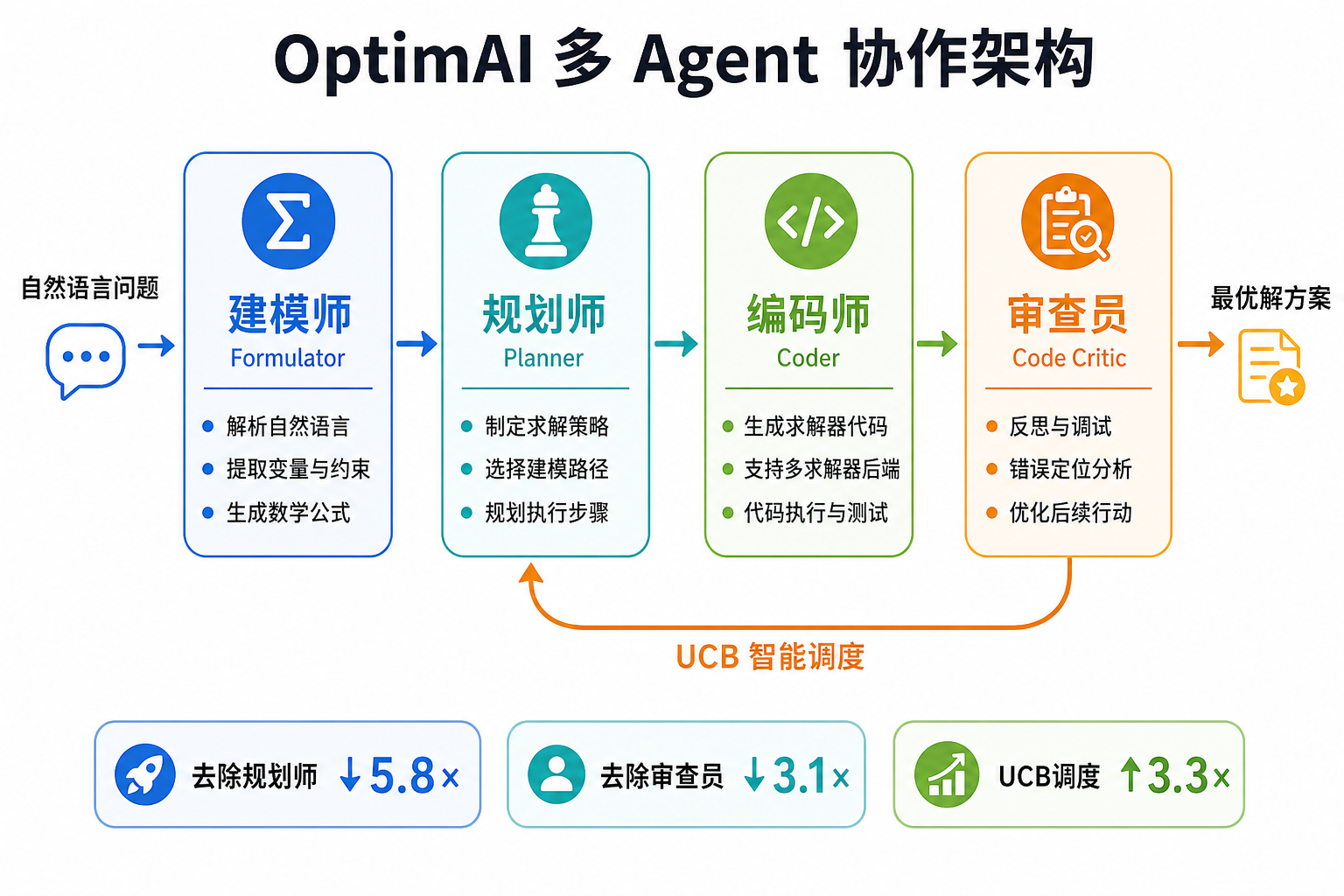
多 Agent 架构是当前最有潜力的方向。以 OptimAI 为例,四个角色各司其职:
- 建模师(Formulator):自然语言 → 数学公式
- 规划师(Planner):制定求解策略
- 编码师(Coder):生成求解器代码
- 审查员(Code Critic):调试与修正
消融实验证实每个角色不可或缺:去掉规划师性能降 5.8 倍,去掉审查员降 3.1 倍。系统还引入 UCB(Upper Confidence Bound,上置信界)调度——一种源自多臂老虎机的策略,在"沿用已知最优修复路径"和"探索新路径"之间动态平衡,额外贡献 3.3 倍提升。
3.3 基准数据集
当前数据集质量堪忧。浙大团队对主流基准做了人工审查,发现错误率惊人:
| 数据集 | 实例数 | 错误率 | 类型 |
|---|---|---|---|
| NL4Opt | 289 | ≥26.4% | 具体建模 |
| IndustryOR | 100 | ≥54.0% | 工业级 |
| EasyLP | 652 | ≥8.13% | 具体建模 |
| ComplexLP | 211 | ≥23.7% | 具体建模 |
| NLP4LP | 269 | — | 抽象建模 |
| OptiBench | 816 | — | 抽象建模 |
IndustryOR 超半数标注有错——在此基础上评估出的"SOTA"不可信。浙大团队清洗了全部数据集,建立了统一的 LLM4OR Leaderboard。关于这 100 道工业题的构建过程、清洗始末和各模型详细排名,见延伸篇:拆解 IndustryOR:LLM4OR 的 100 道工业优化试金石。
3.4 求解器集成
- 直接生成代码:输出 Gurobi / PuLP / Pyomo 的 Python 代码
- 求解器无关 IR:ORPilot 的中间表示可编译到 Gurobi、CPLEX、PuLP、Pyomo、OR-Tools
- 官方支持:Gurobi 已发布 AI Modeling 文档和 Custom GPT
- RAG 增强:CHORUS 让开源 LLM 在 Gurobi 代码生成上追平 GPT-4
四、代表性系统与落地案例
4.1 OptimAI:多 Agent 架构刷新基准
2026 年 1 月发表,代表 LLM4OR 多 Agent 协作的最高水平。
| 指标 | 数值 |
|---|---|
| NLP4LP 准确率 | 88.1%(错误率降低 58%) |
| OptiBench 准确率 | 82.3%(错误率降低 52%) |
| 去除规划师 | 性能降 5.8× |
| 去除审查员 | 性能降 3.1× |
| UCB 调度增益 | +3.3× |
关键创新:在编码前先由规划师制定求解策略;UCB 调度实现多修复路径的智能切换。
4.2 OR-LLM-Agent:推理模型的端到端验证
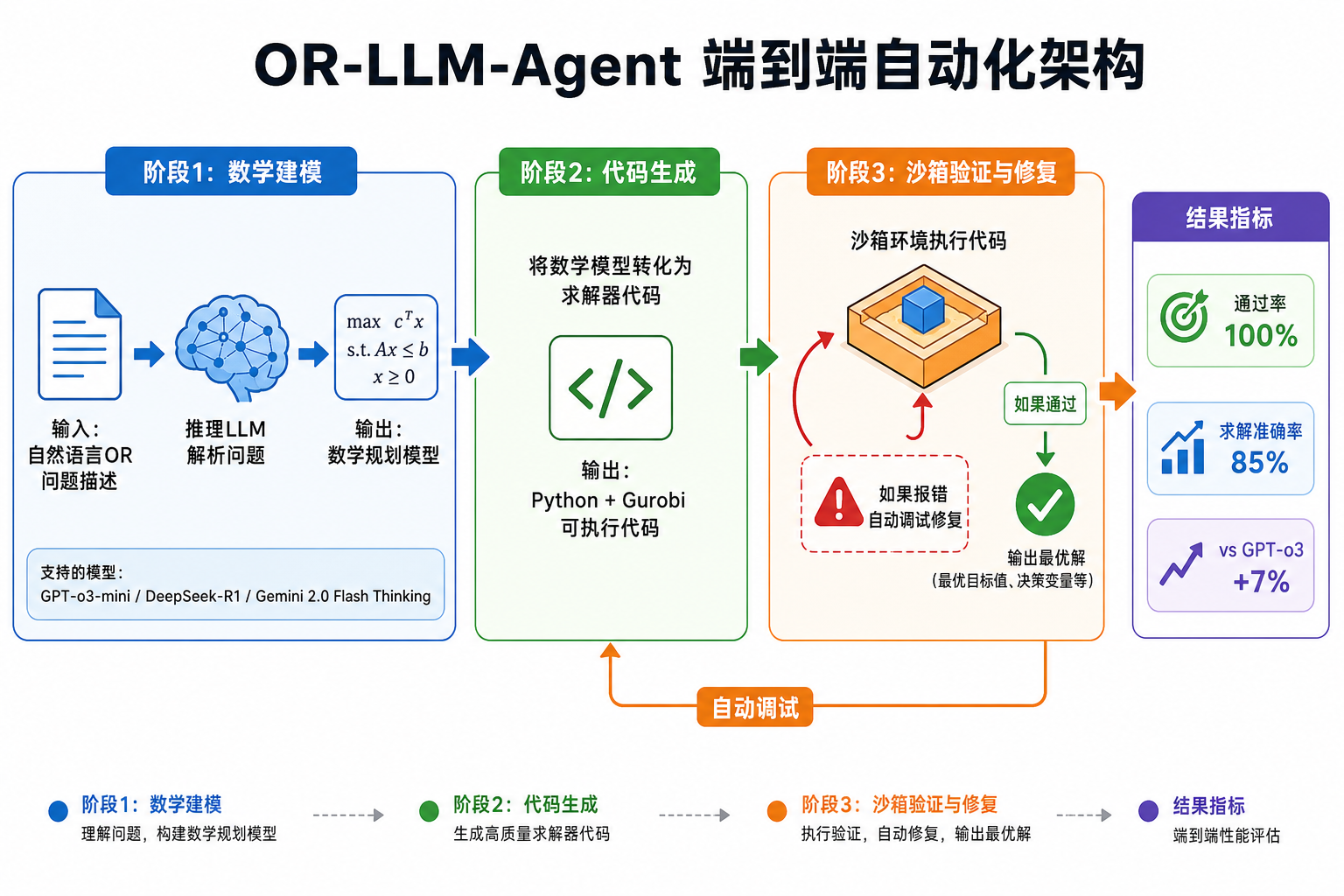
首个系统评估推理 LLM(GPT-o3-mini、DeepSeek-R1、Gemini 2.0 Flash Thinking)在真实 OR 问题上的框架。
| 指标 | 数值 |
|---|---|
| 真实问题数 | 83 |
| 代码通过率 | 100% |
| 求解准确率 | 85% |
| vs GPT-o3 | +7% |
采用"建模→生成代码→沙箱验证→自动修复"流程。100% 代码通过率说明推理 LLM 在代码生成环节已接近可靠,真正的瓶颈在数学建模本身。
4.3 ORPilot:面向生产环境的 Agent 工具
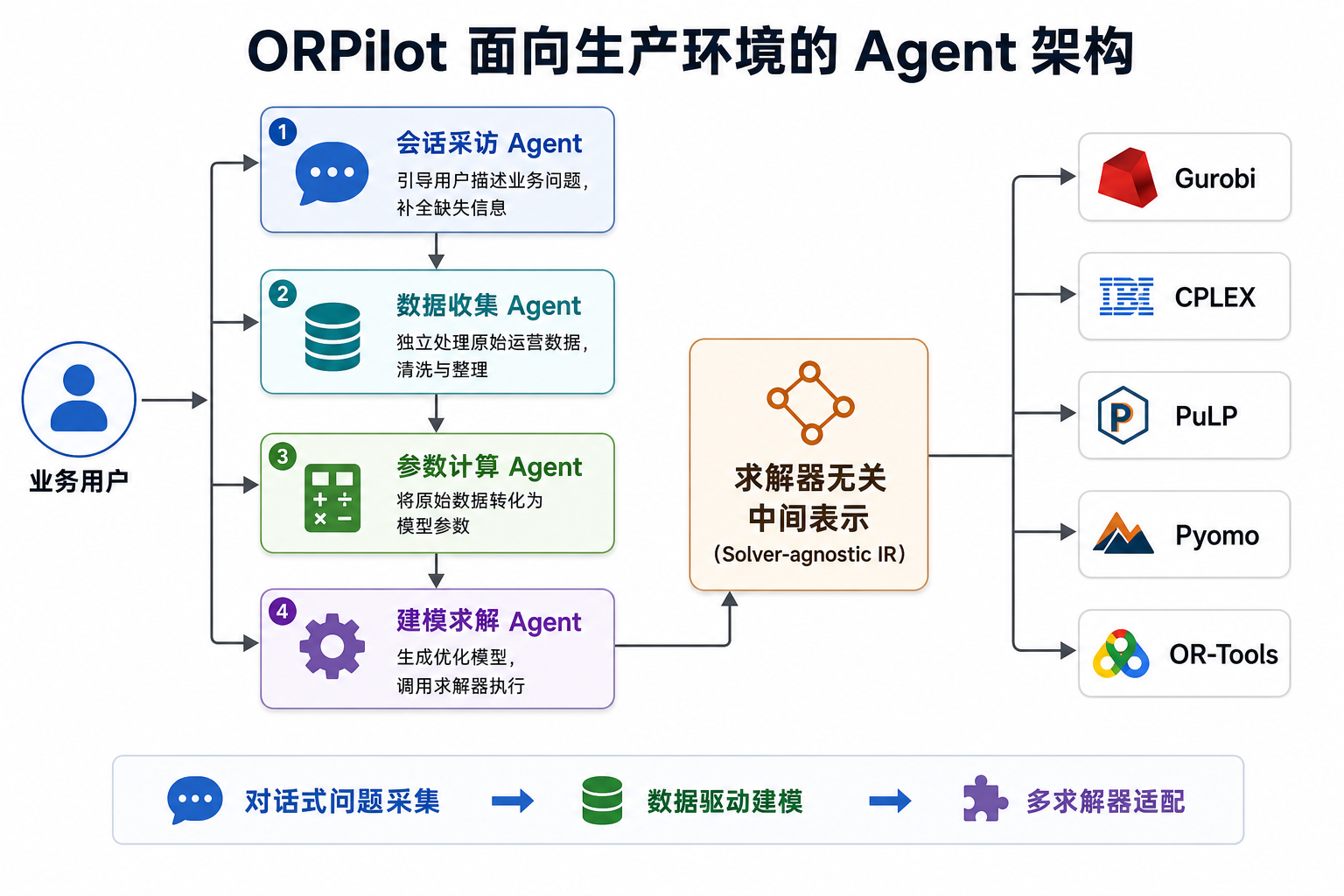
2026 年 5 月发表,专为真实业务场景设计。
| 指标 | 数值 |
|---|---|
| IndustryOR 表现 | 超越现有 SOTA |
| 支持求解器 | Gurobi / CPLEX / PuLP / Pyomo / OR-Tools |
| 核心模块 | 会话采访 → 数据收集 → 参数计算 → 建模求解 |
核心差异化:对话式问题采集。用户不必一次写清所有需求,会话 Agent 逐步引导补全;数据收集 Agent 独立处理原始运营数据。解决的是"用户只说'帮我排个班',系统如何补全所有缺失信息"的真实痛点。
4.4 AutoOR 与 EvoOpt-LLM:小模型高效训练
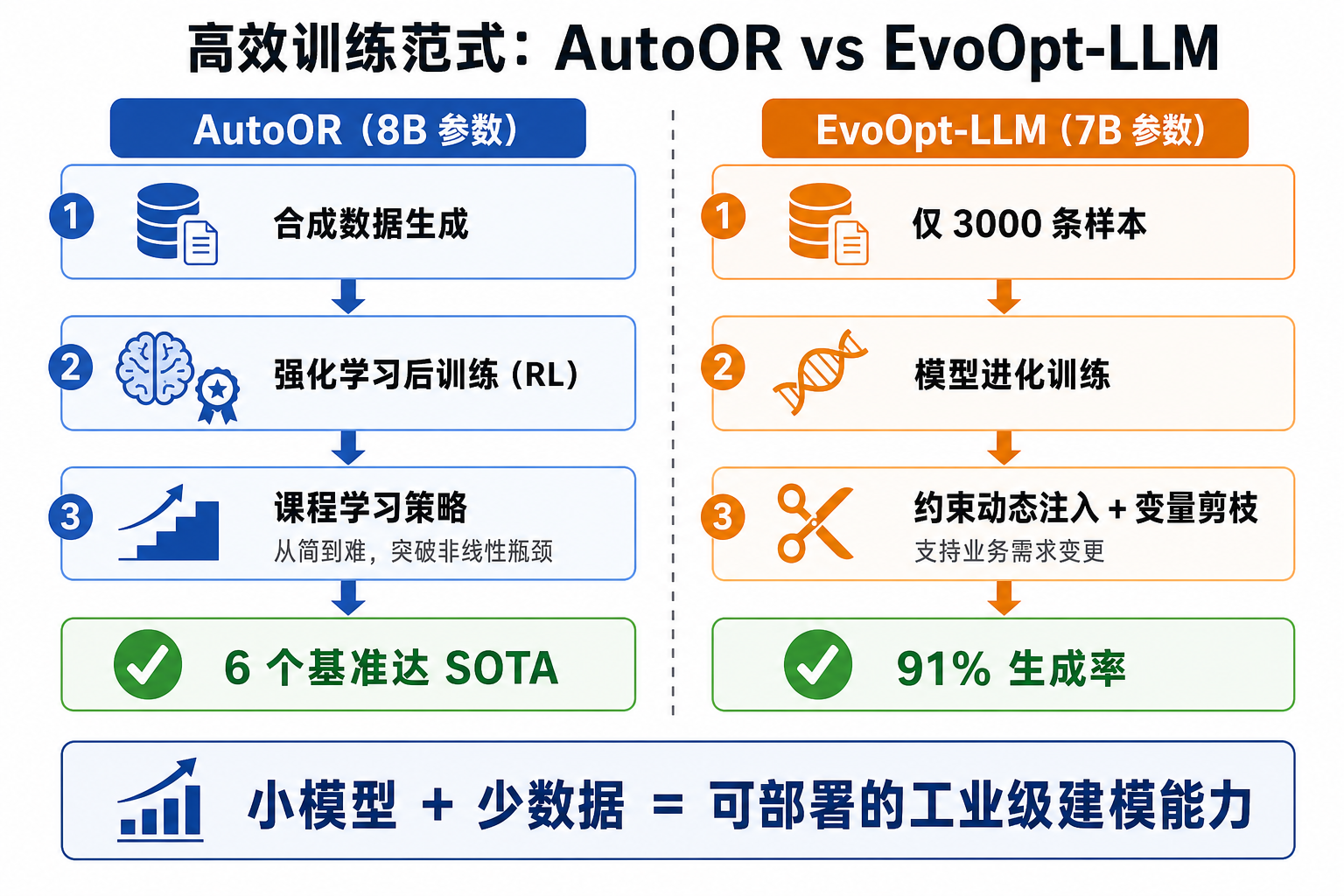
证明了不依赖 GPT-4 级大模型也能达到竞争力。
| 系统 | 规模 | 数据量 | 核心成果 |
|---|---|---|---|
| AutoOR | 8B | 合成数据 | 6 个基准达 SOTA,含非线性问题 |
| EvoOpt-LLM | 7B | 3,000 条 | 91% 生成率 |
| OR-Toolformer | 8B | 半自动合成 | 80.1% 执行准确率,零样本迁移 +21pp |
AutoOR 的课程学习(从简到难排列非线性问题)突破了传统瓶颈;EvoOpt-LLM 证明 3,000 条数据就够用。对关注数据安全和成本的企业而言,本地部署已在技术上可行。
4.5 Gurobi:求解器巨头官方入场
Gurobi 的 gurobi-ai-modeling 开源项目提供了 LLM 建模最佳实践、面向各类工程师的 prompt 示例、三款 Custom GPT,以及详细的 LLM 建模陷阱清单(供需假设偏差、时序复杂性盲区、三维空间推理弱点等)。求解器厂商的官方背书,标志着 LLM4OR 已从实验走向工具化。
4.6 联想 ORMind 与 KLM CrewVision
- 联想 ORMind:内部 AI 助手中测试,NL4Opt 提升 9.5%,ComplexOR 提升 14.6%,展示企业级落地路径
- KLM CrewVision:与 BCG 合作,基于 Gurobi 的五年机组规划工具,规划时间从一周缩短至数小时
五、关键发现与洞察
洞见1:多 Agent 协作是架构共识。 从 Chain-of-Experts 到 OptimAI 再到 ORPilot,多 Agent 在可解释性、容错性和模块化上全面胜出。单 LLM + prompt 在复杂问题上已触天花板。
洞见2:数据质量是被低估的瓶颈。 IndustryOR 54% 的错误率意味着,基于它训练或评测的系统结论都不可靠。我们需要求解器驱动的自动化评测,而非人工标注。
洞见3:小模型 + 少数据已可用。 8B 模型 + RL 后训练(AutoOR)、7B 模型 + 3000 条数据(EvoOpt-LLM)均达到竞争力水平。本地部署不再是空想。
洞见4:求解器反馈闭环是可靠性基石。 LLM 生成的模型必须经求解器实际执行验证,形成"生成→执行→反馈→修正"闭环,才能达到生产可用水平。
六、行业影响与未来展望
6.1 角色变迁
LLM4OR 不会消灭 OR 专家,但会重塑其角色——从"亲手建模"转向"审核模型"。自动化覆盖需求理解、模型构建、代码生成后,专家的核心价值在于:问题定义审核、模型正确性验证、解方案的业务解读、边界案例处理。
6.2 民主化效应
81% 的求解器用户持有高级学位——这意味着大量企业被挡在优化技术门外。当工程师可以用自然语言描述排班、调度、配送问题时,潜在用户群将扩大数个数量级。
6.3 治理挑战
- 可解释性:LLM 推理是黑箱,生成模型的可审计性如何保障?
- 责任归属:自动生成的模型驱动航班排班或医疗资源分配时,谁为正确性负责?
- 偏差传播:LLM 训练数据中的不完善建模范式,可能被自动化放大
6.4 推理模型驱动建模
OpenAI o1、DeepSeek R1 等推理模型在数学任务上表现强劲,但尚未充分迁移至优化建模。DeepSeek R1 的纯 RL 路线提供了方向——将建模过程建模为 MDP,以求解器反馈为奖励信号。
6.5 人机协同建模(Human-in-the-Loop)
完全自动化是远期目标,近期更务实的是人机协同:系统识别何时需要人类干预(术语模糊、约束矛盾、规模超限),主动请求输入。ORPilot 的对话式采访是早期尝试。
6.6 领域知识图谱注入
优化建模高度依赖行业知识(约束条件、经验参数、建模范式)。将这些知识结构化为知识图谱并与 LLM 融合,是提升建模质量的关键路径。
6.7 可验证的安全建模
进入医疗、航空、金融等关键领域后,需要形式化验证确保模型正确性——结合约束传播、模型检查与 LLM 生成能力,构建"生成→验证→证明"三层架构。
结语
"The goal is not to replace the optimization expert, but to give every decision-maker an optimization expert."
LLM4OR 用不到四年完成了从概念验证到产业化前夜的跨越。多 Agent 协作已成共识,小模型路线已被验证,求解器厂商已入场,企业部署正在发生。
但挑战同样清晰:基准数据质量堪忧、建模缺乏可解释性、跨领域泛化有限、生产可靠性保障尚未成熟。下一个里程碑不是更高的基准分数,而是第一个被真正信任、驱动关键业务决策的生产系统。
当你的团队下次说"我们需要一个优化方案"时,你会等 OR 专家三周的排期,还是让 AI Agent 三分钟给出第一版模型?
附录:关键资源
| 资源 | 类型 | 链接 |
|---|---|---|
| LLM4OR Portal | 统一门户 | https://llm4or.github.io/LLM4OR |
| Gurobi AI Modeling | 官方实践指南 | https://gurobi-ai-modeling.readthedocs.io |
| OptiMUS | 开源框架 | https://github.com/teshnizi/optimus |
| ORLM | 领域专用 LLM | Tang et al. 2024 (Hugging Face) |
| OptiBench | 基准数据集 | Wang et al. 2024 (Hugging Face) |
| OR-LLM-Agent | 端到端 Agent | arXiv:2503.10009 |
| OptimAI | 多 Agent 框架 | arXiv:2504.16918 |
| ORPilot | 产业级工具 | arXiv:2605.02728 |
参考资料
- Xiao, Z. et al. (浙大 & 华为). "A Survey of Optimization Modeling Meets LLMs." arXiv:2508.10047, 2025.
- Wang, Y. & Li, K. "Large Language Models and Operations Research: A Structured Survey." arXiv:2509.18180, 2025.
- Ramamonjison, R. et al. "NL4Opt Competition." NeurIPS 2022. arXiv:2303.08233.
- AhmadiTeshnizi, A. et al. "OptiMUS: Scalable Optimization Modeling with LLMs." ICML 2024.
- Tang, Z. et al. "ORLM: Training LLMs for Optimization Modeling." arXiv:2405.17743, 2024.
- Xiao, Z. et al. "Chain-of-Experts: When LLMs Meet Complex OR Problems." ICLR 2024.
- OptimAI Team. "OptimAI: Optimization from Natural Language Using LLM-Powered AI Agents." arXiv:2504.16918, 2026.
- Zhang, J. et al. "OR-LLM-Agent." arXiv:2503.10009, 2025.
- ORPilot Team. "ORPilot: A Production-Oriented Agentic LLM-for-OR Tool." arXiv:2605.02728, 2026.
- AutoOR Team. "AutoOR: Scalably Post-training LLMs to Autoformalize OR Problems." arXiv:2604.16804, 2026.
- Gurobi Optimization. "Gurobi AI Modeling Documentation." https://gurobi-ai-modeling.readthedocs.io
- Gurobi Optimization. "2023 State of Mathematical Optimization Report."
- Deix AI. "LLM4OR: The Generative AI That Translates Problems into Solutions." 2025.
- Jiang, C. et al. "LLMOPT." arXiv:2410.13213, 2024.
- EvoOpt-LLM Team. arXiv:2602.01082, 2026.
- OR-Toolformer Team. arXiv:2510.01253, 2025.
- LEAN-LLM-OPT Team. arXiv:2601.09635, 2026.
- EVOM Team. arXiv:2604.00442, 2026.
- KLM & BCG. "Using Optimization to Navigate a Turbulent Planning Horizon." Gurobi Case Study.
- Zhang, Y. et al. "Explainable Operations Research." ICLR 2025.