星环与易华录的冷启示:前 AI 时代的数据公司怎么活
产业观察 · 数据基础软件 × 生存路径 × 价值边界 | 2026 年 5 月 | 约 15 分钟阅读

TL;DR · 3 句话读完本文
- 星环与易华录撞墙的根本原因 绝大部分不是"被 AI 抛弃"——是项目制现金流、to-G 收缩、重资产折旧与治理事故的复合事故。
- 它们的真实身份是 "前 AI 时代的数据技术公司"——这个身份在 AI 时代仍有真实空间,不需要、也不应该硬把自己改造成 AI 公司。
- 这类公司有 5 种现实生存路径(专精化 / 价值上移 / AI 嵌入 / 生态切换 / 战略收缩)。最大的风险不是 AI 本身,而是 被 AI 焦虑绑架的错误自我定位。
序:先放下"AI 公司"这把尺子
2026 年的春天,国内两家"数据明星"同期撞墙。
- 星环科技(688031.SH):陷入"失血换增长"的泥潭。4 月 30 日披露的 Q1 财报虽录得 8124 万营收(同比 +26.24%),但代价是高达 5599 万的归母净亏损,"增收不增利"彻底暴露了其重交付模式的脆弱。比亏损更致命的是资金链与合规的双重红灯:3 月 25 日迫于现金流压力二度递表港交所求血;5 月 9 日更因围标串标被国防科技大学暂停全军采购资格,法定代表人孙元浩名下关联企业一并被牵连,直接动摇了其政企信创市场的信任基石。
- *ST 易录(300212.SZ,原易华录):到了"资不抵债"的临界点。2025 年录得 27.36 亿巨额净亏、净资产已为负值——这是十年智慧城市重资产铺张的总账单。4 月 28 日因涉嫌信披违法违规被证监会立案,4 月 30 日触发 ST 风险警示;5 月 19 日,北京一中院在债权人申请后仅 4 天即决定启动预重整——这不是简单的"濒临退市",而是 A 股极为罕见的、被司法程序加持的"系统重启"窗口被强制打开。
把两家撞墙的根本原因拆开看:
| 困境来源 | 星环科技 | 易华录 |
|---|---|---|
| 项目制 + 私有化部署的现金流陷阱 | 应收 2.65 亿、信用减值同比 +231%、围标串标被暂停军采 | to-G 项目周期拉长、应收雪崩、流动负债高于流动资产 37 亿 |
| 主营市场需求降速 | 数据库 / 大数据平台的预算增速放缓,新设国企突然成第一大客户 | 智慧城市集成项目预算被压缩、地方政府新建意愿下降 |
| 重资产 + to-G 周期错配 | 不重资产但 to-G 客户回款拉长 | 蓝光数据中心折旧 + 政府客户回款 + 地方债务三重错配 |
| 价值锚点位移 | 卖工具 / 卖项目的模式天花板低,每客户 ARPU 上不去 | 数据"存得多"的价值锚点过气,"用得活"才是新主流 |
| 公司治理与合规事故 | 围标串标 + 信披问询 | 信披违法被立案 |
那么这类"前 AI 时代基因的数据技术公司"——数据基础软件商、数据集成商、智慧城市集成商、数据治理服务商——在 AI 时代真正该怎么活?
一、它们到底是什么公司:放下 AI 滤镜重新看
本节要点:去掉"AI"标签后,这些公司在前 AI 时代到底解决什么问题、提供什么价值、服务什么客户——这些价值在 AI 时代会消失吗?大部分不会。
1.1 五类"前 AI 时代的数据技术公司"
放下"AI"滤镜,国内常见的传统数据技术公司大致是这五类:
| 公司类型 | 真实定位 | 代表公司 | 在前 AI 时代解决什么 |
|---|---|---|---|
| 数据基础软件 | 数据库 / 大数据平台 / 数据治理工具 | 星环、达梦、海量数据、PingCAP、亚信 | 让企业能存、能查、能管自己的数据 |
| 数据集成 / 智慧城市 | 行业总集成商 + 智慧城市 PaaS | 易华录、太极、东软、神州数码 | 把分散数据、系统、流程整合进政府/企业的数字化平台 |
| 数据治理 / 数据中台 | 行业数据模型 + 治理流程 + 中台 | 拓尔思、用友 BIP、亚信 | 把杂乱数据治理为可用资产 |
| 数据标注 / 工程服务 | AI 产业链上游的数据加工服务商(劳动密集型) | 海天瑞声、龙猫、Scale AI | 给模型公司提供训练 / 评测 / 偏好数据 |
| 数据存储 / 物理基础设施 | 蓝光 / 磁带 / IDC / 数据物理归集 | 易华录蓝光、数据港、宝信软件 | 大规模冷数据 / 政府归档数据存储 |
关于"数据标注"的精确定位:它确实直接服务 AI——客户全是模型公司、自动驾驶公司、CV / NLP 公司,从产业链位置看属于 AI 上游。但它的商业模式不是 AI-Native——内核仍是众包人工 + 流程管理 + 质检流水线,按"标注小时"或"标注条数"结算,更接近 BPO(业务流程外包)的数据加工版本。所以它的位置是"离 AI 最近的非 AI 公司"——这种身份让它处境特殊:客户预算波动会最先传导过来,而被 OpenAI / Anthropic / DeepSeek 等下游甲方"内化"的风险也最大。Scale AI 这两年拼命往"行业数据资产 + RLHF 即服务"上爬,正是想摆脱这个尴尬身份。
1.2 它们的真实价值并没有消失
仔细看上面这张表,会发现一个反直觉的结论:这些价值在 AI 时代大部分依然成立。
- 企业仍然需要数据库——AI 应用本身就要读数据库
- 政府仍然需要数据中心 + 集成——智慧城市不会因为 DeepSeek 出现就消失
- 数据仍然需要治理——AI 反而让数据治理更重要("垃圾进、垃圾出"在 AI 时代被放大)
- 模型训练仍然需要标注——只是从"全人工"过渡到"AI 辅助 + 人审"
- 政府数据仍然需要冷归档——合规要求只增不减
也就是说,这些公司承载的产业角色并没有过期。他们的痛苦不来自"被 AI 抛弃",而是来自三件别的事:
- 客户预算结构的位移——客户预算从"数据基础设施 / 集成"转向了"AI 应用",传统数据预算被挤压
- 细分子领域的部分替代——LLM + RAG 部分蚕食了传统数据治理 / BI 工具的市场
- 重资产 / 项目制基因的现金流压力——这跟 AI 关系不大,是宏观周期 + 地方债务 + to-G 收缩的复合结果
注意第三点最关键:易华录的预重整本质上不是"被 AI 杀死",而是 to-G 项目制 + 地方债务 + 重资产折旧的复合事故;星环的现金流问题也类似,是"项目制 + 应收账款 + 高研发投入"的结构性病灶。把这些问题都归到"AI 时代落伍",是一种舒服但不准确的叙事——它让人觉得"只要追上 AI 就好了",但真正需要处理的是更复杂的现金流、客户结构、商业模式问题。
1.3 重新校准:AI 既不是救命稻草,也不是死亡判决
在继续往下走之前,需要先校准两个常见认知:
| 错觉 | 真实情况 |
|---|---|
| "AI 会把这类公司全部颠覆掉" | 部分子领域确实被替代,但大多数主业仍有空间 |
| "只要拥抱 AI 就能起死回生" | AI 不能修复项目制现金流、不能修复 to-G 需求收缩、不能修复重资产折旧 |
| "他们应该都转型成 AI-Native" | 大多数公司既不该转也转不了——基因和现金流都不允许 |
| "他们应该完全不碰 AI" | 完全不碰 = 主动放弃客户预算位移带来的新机会 |
正确的姿态是 "承认 AI 改变了边界,但不被 AI 焦虑绑架"。
二、AI 时代给这类公司带来的真实变化:是边界位移,不是颠覆
本节要点:AI 不是把这些公司一夜推倒,而是在它们生意的边界上做了 4 个具体位移。看清边界,才能选对生存策略。
2.1 变化 ①:客户预算结构的位移
这是最直接的变化。
前 AI 时代:企业 IT 预算大致按"基础设施 / 数据 / 应用 / 安全"分配,数据相关预算占 IT 总预算 15%-25%。
AI 时代:客户 CIO / CDO 面前多了一个"AI 应用 / 大模型 / Agent"预算项,且这个项的预算来源不全是新增——一部分是从原有数据预算切出来的。
具体的位移:
| 预算项 | 前 AI 时代 | AI 时代 | 谁受益 / 受损 |
|---|---|---|---|
| 数据库 / 数据平台 License | 主线 | 仍是主线但增速放缓 | 老玩家略受压 |
| 数据治理 / 中台建设 | 大项 | 部分被 RAG 知识库吸收 | 部分老玩家受损 |
| 智慧城市集成项目 | 大项 | 项目周期拉长 + 单价压力 | 集成商受损 |
| 大模型 / AI Agent | 0 | 新大项 | 新玩家受益 |
| 算力 / GPU | 小项 | 新大项 | 云厂商受益 |
对传统数据公司的实际影响:客户的"总数据预算"没缩水太多,但结构发生了倾斜——数据基础设施稳定、数据治理被部分替代、智慧城市集成承压。
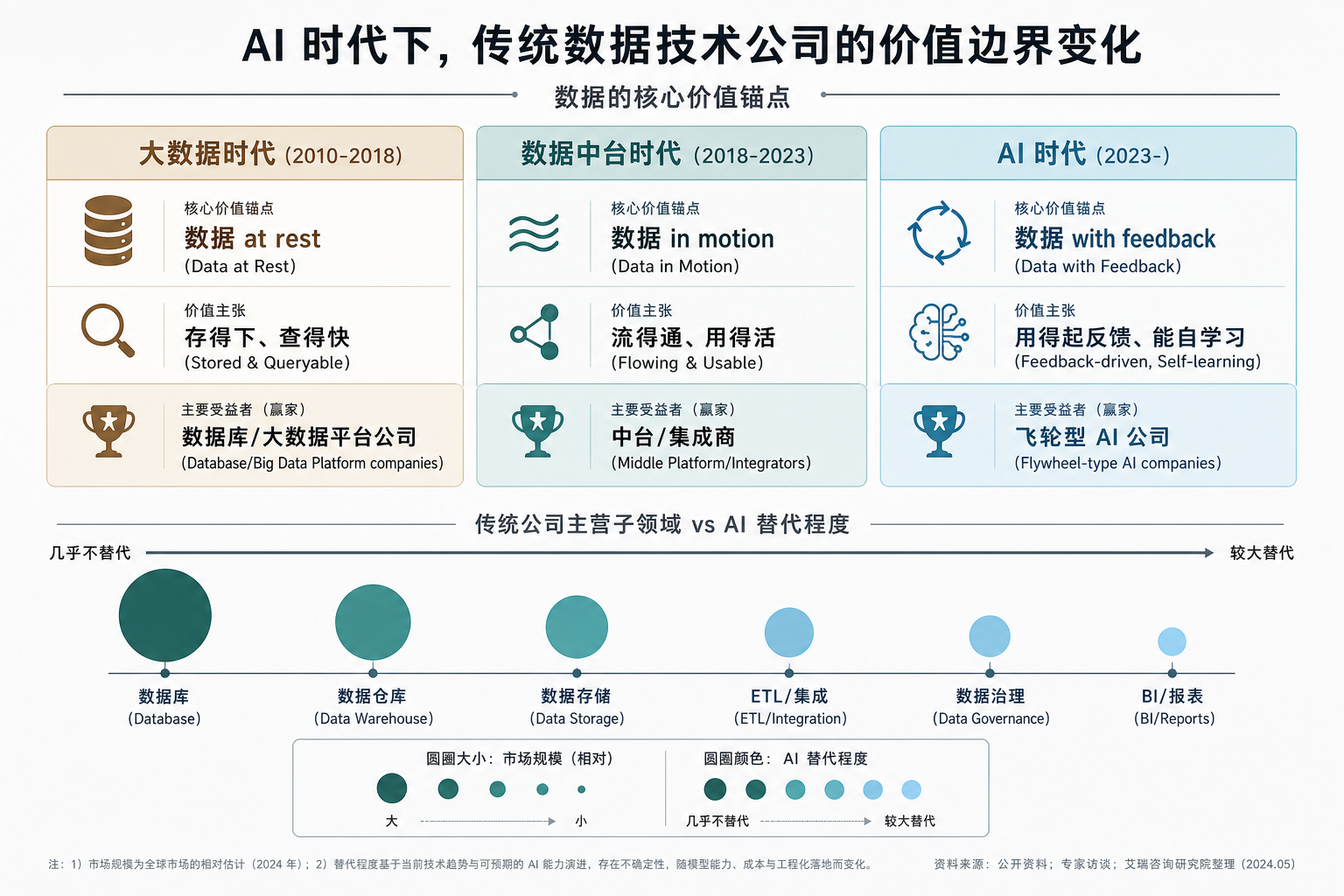
2.2 变化 ②:价值锚点位移(数据 at rest → in motion → with feedback)
这是更深层的变化。
| 时代 | 数据的核心价值锚点 | 谁赢 |
|---|---|---|
| 大数据时代(2010-2018) | 存得下、查得快(数据 at rest) | 数据库 / 大数据平台公司 |
| 数据中台时代(2018-2023) | 流得通、用得活(数据 in motion) | 中台 / 集成商 |
| AI 时代(2023-) | 用得起反馈、能自学习(数据 with feedback) | 飞轮型 AI 公司 |
这意味着什么:
- 卖"数据存储 + 检索"的公司(如易华录蓝光),主营所对位的价值锚点在 2018 年就已经过气了——AI 时代只是加速了这个过气
- 卖"数据流动 + 治理 + 中台"的公司(如星环、亚信),主营所对位的价值锚点在 2023 年开始过气——AI 时代是直接打击
- 但这不等于这些价值完全消失——只是不再是"价值之巅"——它们仍然是新价值层的底层支撑
2.3 变化 ③:子领域的部分替代
具体到子领域,AI 真正替代了什么、没有替代什么:
| 子领域 | 是否被 AI 替代 | 解释 |
|---|---|---|
| 数据库(OLTP / OLAP) | 几乎不替代 | AI 应用还要读数据库,反而更需要向量化扩展 |
| 数据仓库 | 几乎不替代 | 仍是数据分析底座,AI 不能替代结构化查询 |
| ETL / 数据集成 | 部分替代 | LLM 能做轻量数据清洗 + 转换,但大规模 / 复杂数据集成仍要传统工具 |
| 数据治理(元数据 / 质量) | 部分替代 | RAG + Agent 能做部分自动化治理,但合规审计仍要传统流程 |
| BI / 报表 | 较大替代 | "对话式 BI"在显著蚕食传统报表市场 |
| 数据标注 | 被改造而非替代 | 从全人工转向"LLM 辅助 + 人审",市场规模可能扩大 |
| 数据冷存储 | 几乎不替代 | 合规归档刚需,但单位价格在下降 |
| 智慧城市集成 | 被重塑 | 项目预算转向"AI 城市",但集成需求仍在 |
核心判断:AI 对传统数据技术公司的杀伤是结构性的不均匀——某些子领域(BI、轻量数据治理)受冲击大,某些子领域(数据库、数据仓库、冷归档)受冲击小,某些子领域(数据标注、集成)被重塑但市场未必缩小。
2.4 变化 ④:新机会窗口的打开
不只是"被冲击",AI 也确实给这类公司带来了一些新机会,但不是"做 AI 公司"那种机会:
- AI 应用的底层依赖:所有 AI 应用都要数据库(向量数据库、传统数据库)、要数据治理、要数据流动——传统公司可以做"AI 应用的基础设施供应商"
- 行业大模型的数据资产化:手里有行业数据的公司可以参与行业大模型训练,以"数据股东"身份分润,而不是自己训模型
- 数据合规与可信 AI:AI 时代的合规需求暴增——数据脱敏、模型审计、合规追溯——传统数据治理公司天然适配
- AI 推理基础设施的本地化:私有化 AI 部署 + 模型管理 + Token 计量——传统私有化部署能力可以复用
关键认识:这些机会的本质不是"变成 AI 公司",而是 "做 AI 公司没法做的那些事"——它们是 AI 浪潮的"卖水卖铲"角色,不是淘金者。
三、五种现实生存路径
本节要点:不是只有"转 AI-Native"一条路,且大多数公司不该走那条路。这里列 5 种现实可行的路径——它们彼此不互斥,但需要看清各自的代价和适用条件。
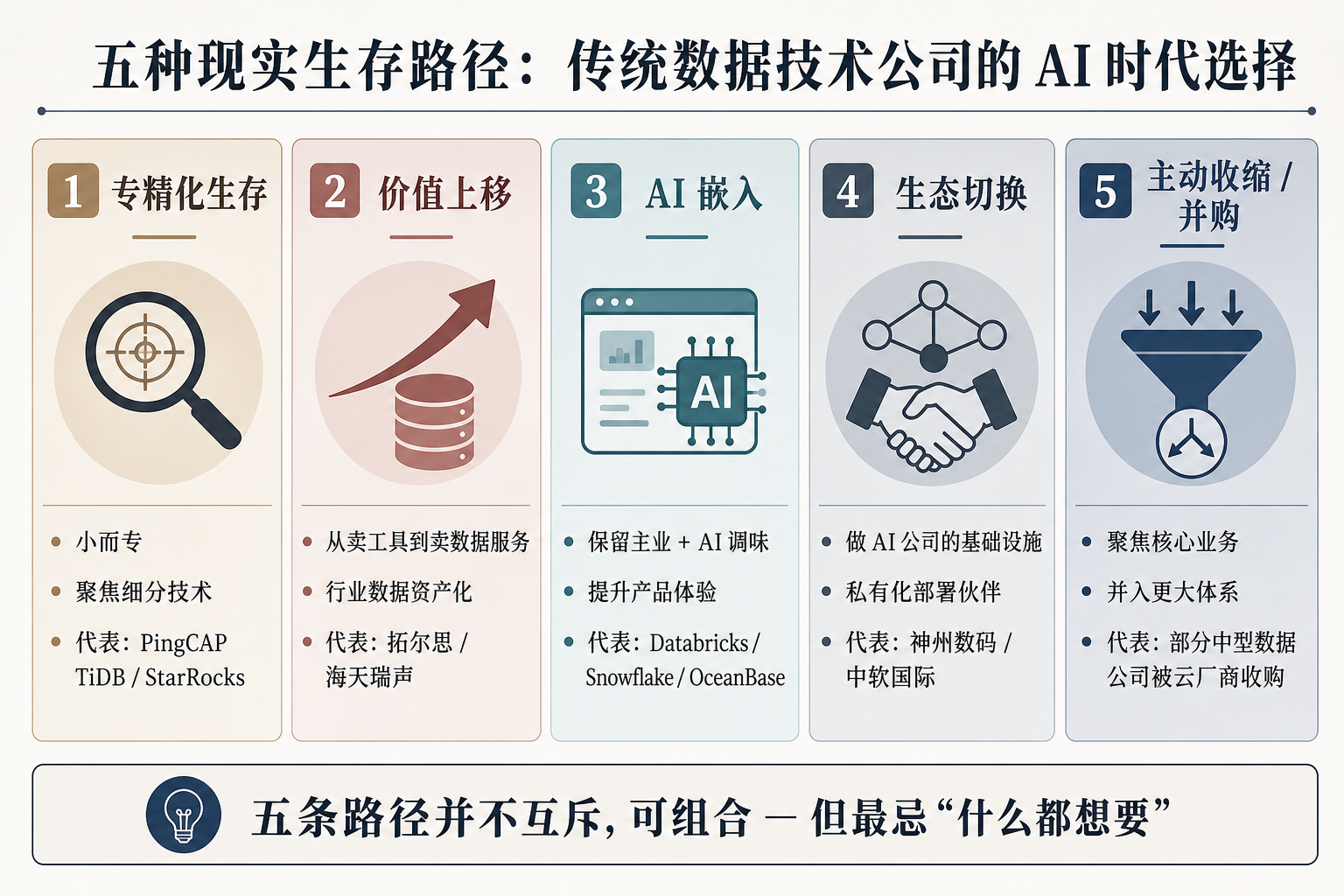
3.1 路径一:专精化生存——做"小而专"的细分基础设施
核心动作:放弃"全栈数据平台"的野心,聚焦一个垂直领域 / 一个细分技术,把它做到不可替代。
适用条件:
- 公司在某一个细分领域有技术深度(如时序数据库、图数据库、向量数据库、流处理)
- 现金流允许"主动收缩"——舍弃部分客户和业务线
- 团队不大,决策灵活
典型动作:
- 从"全平台"砍掉低毛利业务,聚焦 1-2 个核心模块
- 把核心模块做成"API + 文档 + 开源社区"形态,让 AI 开发者用得起来
- 在细分领域做到 Top 3,被 AI 公司 / 大客户主动找上门
真实案例:PingCAP 长期聚焦分布式数据库(TiDB);StarRocks 聚焦实时 OLAP;TimePlus 聚焦流式数据库——这些都是"专精化"路径的典型。
代价:放弃增长野心,承认自己不会成为"巨头",只做"重要的螺丝"。
3.2 路径二:价值上移——从卖工具到卖数据服务
核心动作:从"卖软件 License"上移到"卖数据相关的运营服务"——数据资产化、行业数据集授权、合规咨询、AI-Ready 数据服务。
适用条件:
- 公司手里积累了行业数据 / 行业 know-how(不是公开数据)
- 客户对"数据资产"和"合规服务"有付费意愿
- 有项目交付以外的服务化能力
典型动作:
- 把客户做项目过程中沉淀的行业知识 / 模板 / 基准——打包成"行业数据资产"反向授权
- 提供"数据合规审计""数据资产估值""数据交易撮合"等高毛利服务
- 与数据交易所合作,做行业级数据流通
真实案例:拓尔思的"政务数据 + 知识库 + 行业模型"组合;亚信向"运营商数据资产化"方向延伸;海天瑞声把标注业务升级为"行业数据集 + RLHF 服务"。
代价:业务结构调整,部分员工 / 销售队伍需要换技能。
3.3 路径三:AI 嵌入——保留主业,在产品里嵌入 AI 能力
核心动作:不变成 AI 公司,但在现有产品里嵌入 AI 能力作为体验增强——让现有客户的工作流更顺、价值感更高。
适用条件:
- 公司有清晰的产品形态(不是纯项目交付)
- 老产品有持续用户 / 持续付费
- 想要保住基本盘,不希望大幅折腾
典型动作:
- 在数据库 / 数据治理产品里嵌入"自然语言查询"
- 在数据集成工具里嵌入"自动数据建模 / 自动清洗规则推荐"
- 在 BI / 报表工具里嵌入"对话式分析 / 智能洞察"
- 重点:AI 是体验提升,不是商业模式重构——还是按 License / 订阅收费,只是产品力提升了
真实案例:Databricks 在 SQL 编辑器里嵌入 AI Copilot;Snowflake 加入 Cortex AI;国内的 OceanBase、TiDB 都在嵌入 LLM 辅助查询——他们没把自己变成 AI 公司,但产品越来越好用。
代价:研发投入加重,需要建一支懂 LLM 的小团队(5-15 人),但不需要全公司转型。
这条路径其实最适合大多数公司——它承认 AI 是"调味料",不是"主菜"。
3.4 路径四:生态切换——做 AI 公司的基础设施 / 行业接口
核心动作:主动把自己定位为 AI 公司的"基础设施供应商"或"行业接口"——为 AI 应用提供它们做不了 / 不愿做的底层能力。
适用条件:
- 公司有 AI 公司缺的东西:合规通道、私有化部署能力、行业 KA 关系、本地化服务
- 愿意接受"配角"定位
- 不在意品牌从"独立厂商"变成"生态伙伴"
典型动作:
- 与大模型公司(DeepSeek、月之暗面、智谱、阿里 / 百度 / 字节)签战略合作,做"行业落地伙伴"
- 把现有的私有化部署能力包装成"大模型私有化部署服务",赚交付服务费
- 把现有的数据治理能力包装成"AI-Ready 数据服务",给大模型公司做行业数据准备
- 把现有的行业 KA 关系作为"渠道资源",做大模型公司的金融 / 政府 / 能源行业代理
真实案例:神州数码定位"数云融合",做 AI 落地伙伴;中软国际转型 AI Outsourcing 服务商;很多区域型集成商在做"大模型私有化部署"代理。
代价:议价能力变弱——大模型公司是"上游",你是"下游"。需要在生态里找到自己的"卡位",否则会被替代。
3.5 路径五:战略收缩——主动重整、聚焦、并入更大体系
核心动作:把战略收缩当作一项清醒的资本配置决策——通过资产剥离、业务聚焦、债务重整、并购整合等手段,把被历史包袱掩盖的核心价值释放出来。这不是退场,是一次主动的"系统重启"。
先校准一个常见误解:在成熟资本市场,战略收缩和预重整是与扩张并列的、被高度专业化运用的工具——达美航空 2005 年用 Chapter 11 重整三年后涅槃;通用汽车 2009 年用同样的工具甩掉冗余产能后重回盈利;柯达、塞拉斯都做过类似动作。它们之后都没有"消失",反而是更轻、更专、更值钱。把"主动收缩 = 失败"的污名摘掉,是国内市场走向成熟的一部分。
这条路径真正考验的,不是认输的勇气,而是判断力——什么时候该收、收哪些、留哪些、卖给谁、按什么估值。这往往比"再撑一年看看"难得多。
适用条件(满足任意 2 个就值得严肃考虑):
- 核心赛道增速放缓,新业务在 1-2 年内难以独立支撑增长
- 资产负债表上有"历史包袱"——长账期应收、低毛利项目、过时重资产
- 公司里有真正值钱的核心能力被庞杂的业务结构掩盖
- 估值仍处于合理区间,整合方愿意为核心资产付溢价
- 存在自然的战略接盘方(云厂商、龙头 AI 公司、央企集团、行业整合者)
典型动作:
- 资产断舍离:把非核心、低毛利、重资产、长账期的业务剥离 / 出售——让公司变小反而变值钱
- 债务重整:通过预重整 / 庭外和解清理历史债务,让资产负债表回到健康状态
- 业务聚焦:保留 1-2 个真正有沉淀的核心赛道(哪怕不再讲"全栈"故事),让团队和资源集中投放
- 战略并购:作为整体或核心模块并入云厂商、龙头 AI 公司、央企集团——成为更大体系里的"高价值组件"
- 私有化退市:脱离公开市场的舆论 / 估值压力,在更安静的环境里完成结构重塑(参考分众传媒、爱奇艺的私有化思路)
真实案例:
- 国际:达美航空 / 通用汽车 / 克莱斯勒的预重整后重生;IBM 卖掉 PC 给联想后聚焦企业服务;HP 拆分为 HPE + HPI 释放估值
- 国内:分众传媒从美股退市后回 A 估值放大数倍;2026 年 H1 已有数家中型数据公司被云厂商以核心资产估值收购;部分智慧城市集成商被央企整合后业务质量显著改善
- 数据领域:当数据基础设施 + AI 应用层的边界重新洗牌时,"被收购"往往不是结束、而是核心团队和技术资产在更大体系里换一种活法
取舍:独立上市公司身份会让渡,但换回来的是资产负债表的清洁、战略选择的纯粹、核心团队的解放。对老股东而言,在合理估值区间内主动结构化远比"陪着公司熬到估值塌陷"更对得起信托责任——后者是被动失败,前者是主动配置。
3.6 五条路径不是单选题,但也不是自助餐
讲完 5 条路径,必须立刻校准一个常见误读:它们不是互斥的单选题,但更不是可以全部勾选的自助餐。
- 可以组合:现金流允许、组织能力到位时,"专精化 + AI 嵌入""价值上移 + 生态切换""AI 嵌入 + 部分业务剥离"都是真实可行的组合
- 不能贪多:什么都想要——既要保住老业务、又要变 AI 公司、还要进入新赛道——就是 资源稀释 + 战略分裂,几乎注定失败
关键问题是:到底哪类公司适合哪种组合?这就需要把 5 条路径和 §1.1 的 5 类公司做一次叠加——下一节用一张热力图和一张四象限图,给出系统答案。
四、五类公司类型的现实选择
本节要点:把 5 类公司 × 5 条路径做一个矩阵,看哪些组合最现实——然后再用一张四象限图,把这 5 类公司在 AI 时代的处境一眼定位出来。
4.1 适配度热力图:哪些组合最亮
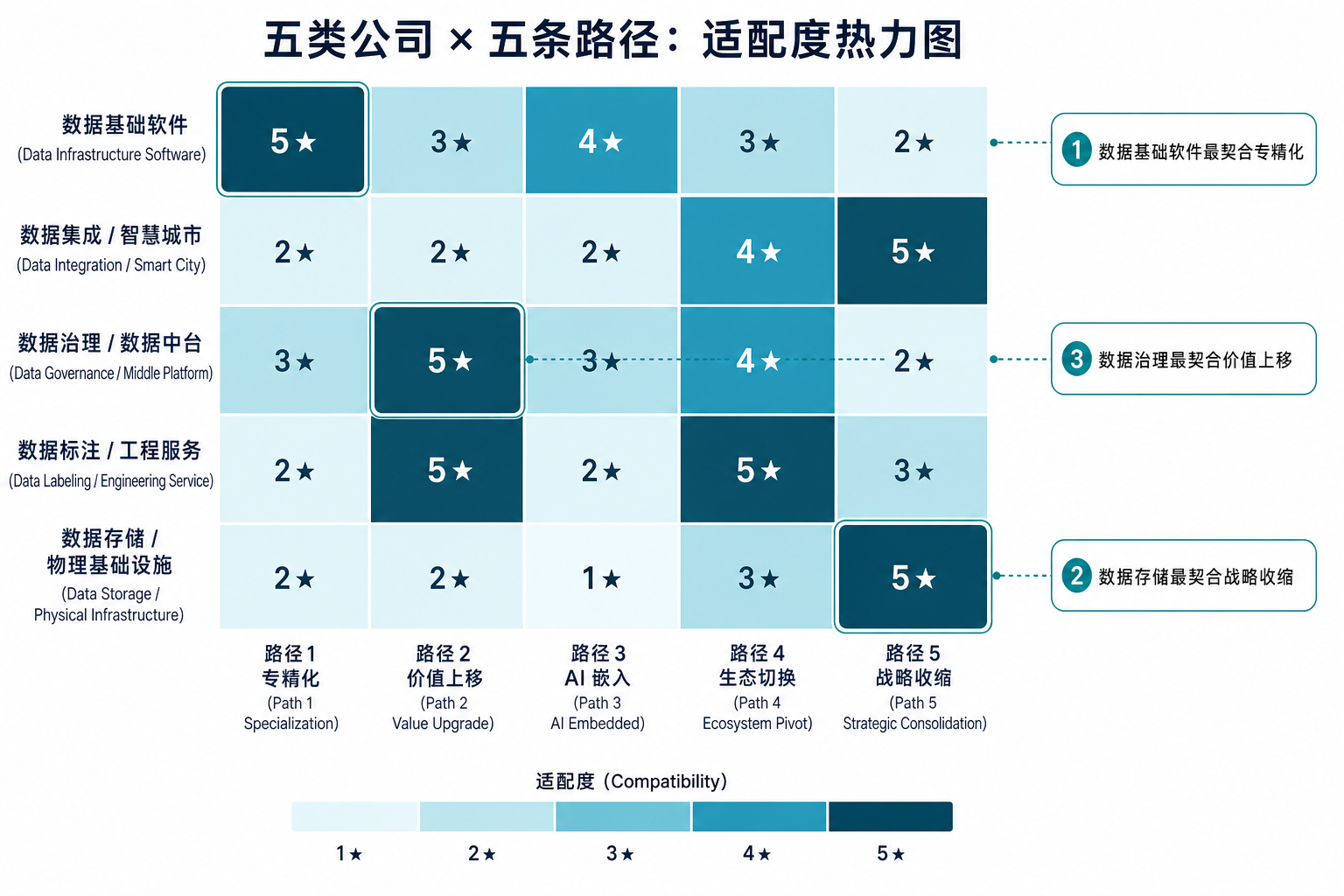
热力图里颜色最深的五格,正是每类公司的"最优锚点"——数据基础软件 × 专精化、数据治理 × 价值上移、数据集成 × 战略收缩、数据标注 × 价值上移 / 生态切换、数据存储 × 战略收缩。读图比读表快得多——视觉上能立刻看到:"靠技术深度活的公司"集中在左上角,"靠资产规模活的公司"集中在右下角,中间地带的公司必须靠"价值上移 + 生态切换"组合才有戏。
下面是同一信息的矩阵版本,方便逐格对照——
| 公司类型 | 路径一 专精化 | 路径二 价值上移 | 路径三 AI 嵌入 | 路径四 生态切换 | 路径五 战略收缩 |
|---|---|---|---|---|---|
| 数据基础软件(数据库 / 平台) | ★★★★★ | ★★★ | ★★★★ | ★★★ | ★★ |
| 数据集成 / 智慧城市 | ★★ | ★★ | ★★ | ★★★★ | ★★★★★ |
| 数据治理 / 数据中台 | ★★★ | ★★★★★ | ★★★ | ★★★★ | ★★ |
| 数据标注 / 工程服务 | ★★ | ★★★★★ | ★★ | ★★★★★ | ★★★ |
| 数据存储 / 物理基础设施 | ★★ | ★★ | ★ | ★★★ | ★★★★★ |
读法:星越多 = 这条路径对这类公司越合适。
4.2 四象限定位:跳出路径推荐看处境
热力图回答的是"每类公司该走哪条路径"。但更本质的问题是:这 5 类公司在 AI 时代的整体处境到底有什么不同? 把它们放在两个最关键的维度上——主营业务的 AI 关联度(远 ↔ 近)× 商业模式弹性 / 独立扩张潜力(弱 ↔ 强)——四象限会直接告诉你每类公司的战略命运。
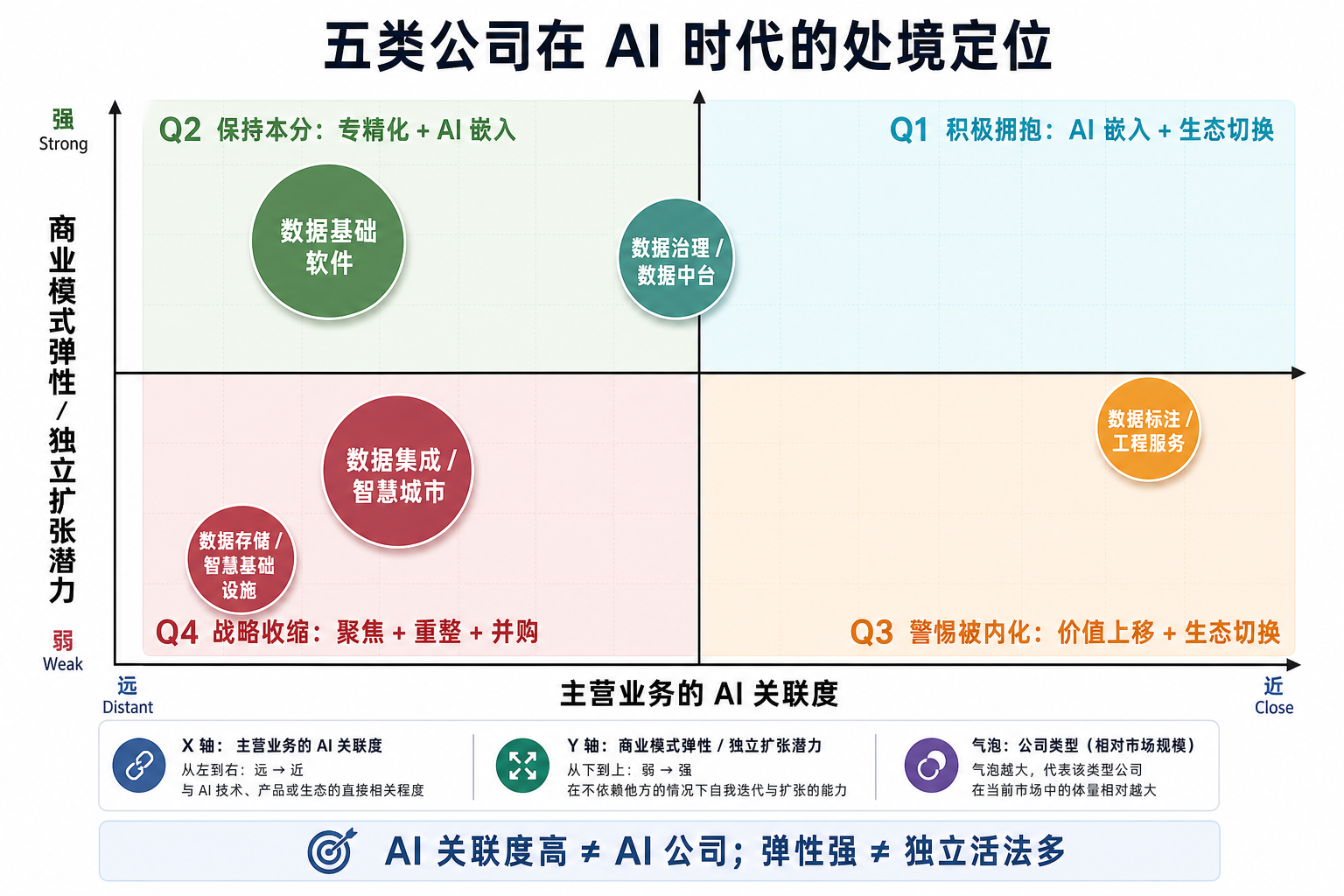
四个象限对应四种命运:
- Q1 积极拥抱(AI 关联近 + 弹性强):处在最大的机会区——但这个象限其实没有"前 AI 时代的数据公司",它属于真正的 AI-Native 玩家。这反过来印证了一个判断:传统数据公司的现实出路不在 Q1,强行往这里靠会落入 §6 的"假装 AI 公司"陷阱
- Q2 保持本分(AI 关联远 + 弹性强):数据基础软件、数据治理位于此象限——主业有技术深度、客户预算有粘性,AI 是体验调味料而非身份重塑。这是大多数中型软件公司最舒服的位置
- Q3 警惕被内化(AI 关联近 + 弹性弱):数据标注是这个象限的典型——离 AI 最近但商业模式最被动,最大的风险不是被 AI 替代,而是被 AI 公司"垂直整合"内化掉(OpenAI 自建标注、Anthropic 自建评测)。唯一的活法是快速完成"价值上移"+"生态切换"——从卖小时升级到卖数据资产 + RLHF 服务
- Q4 战略收缩(AI 关联远 + 弹性弱):数据集成 / 智慧城市、数据存储 / 物理基础设施位于此象限——重资产 + to-G + 项目制三重锁死,独立扩张的空间在 AI 之前就已经收窄。承认这一点、用好"重整 + 并购"工具,反而是把价值留住的最专业选择
这张图的关键启示:AI 关联度高不代表活法多(数据标注就是反例);弹性强也不代表能独立扩张(数据治理的弹性主要释放在"价值上移"路径里,不在做 AI 平台)。真正的战略动作要看你在四象限里的位置,而不是你嘴上贴的标签。
4.3 几个具体判断
数据基础软件最适合"专精化 + AI 嵌入"——技术深度是它们的优势,做小而专 + AI 调味,能保持独立。星环、达梦、PingCAP 都在这条路径上。
数据集成 / 智慧城市最适合"生态切换 + 战略收缩"——它们的项目制基因和 to-G 依赖让全栈式独立扩张越来越吃力,最有商业判断力的选择往往是主动聚焦核心、剥离非核心,或作为高价值组件并入更高效的运营体系。易华录、太极、东软部分业务都在这条路径上做不同程度的尝试。
数据治理 / 数据中台最适合"价值上移 + 生态切换"——它们的行业 know-how 是真资产,能上移到"数据资产化 + 合规服务"。拓尔思、亚信都在尝试。
数据标注 / 工程服务最适合"价值上移 + 生态切换"——必须从"卖小时"升级到"卖数据资产 + RLHF 服务",否则会被大模型公司内化。
数据存储 / 物理基础设施最适合"战略收缩 + 并购整合"——重资产模型在新一轮价值锚点位移下不再具备独立扩张优势,作为核心模块并入云厂商或数据基础设施大平台,反而能最大化原有资产价值。
五、把星环、易华录放进这张地图
本节要点:不是评价它们"该不该转 AI",而是问它们最现实的生存路径在哪里。
5.1 星环科技:路径一 + 路径三 + 半个路径四
把星环放进上一节的矩阵,它属于"数据基础软件"——最适合"专精化 + AI 嵌入"。
实际可走的组合:
- 专精化(路径一):聚焦最有技术深度的 1-2 个产品——比如 ArgoDB(分析型分布式数据库)或 KunDB(交易型分布式数据库)+ 数据治理 Agent。砍掉低毛利、非核心模块。
- AI 嵌入(路径三):现在做的 Sophon LLMOps + Astro 其实就是这个方向——在数据库 / 治理工具里嵌入 AI 能力。这条路径是对的,但不需要被定位为"AI 平台公司"——它就是"加了 AI 调味的数据基础软件"。
- 半个路径四(生态切换):所谓"半个"——不是把自己整体定位为某家大模型公司的"行业落地伙伴",而是只在大模型集成 / 部署 / 数据准备这些边缘场景里和开源大模型生态(Qwen、DeepSeek)、云厂商建立稳定合作。主业仍然是"数据基础软件",不让生态合作稀释独立产品身份。
应该避开的:
- 不要假装是 AI 公司去港股融资——招股书里讲 AI 故事可以,但商业模式描述要诚实是"数据基础软件 + AI 嵌入"
- 不要再扩大客户结构异常的项目(如新设国企 1 年内成第一大客户)——监管层和市场都会持续追问
- 不要碰任何让自己再被处罚的项目——5 月 9 日的军采暂停已经是非常严厉的警告
现实路径总结:星环不是"没摸到 AI 门",是"在数据基础软件这条路上还没完全做扎实,又被现金流追赶被迫赶 AI 故事"。最好的活法是回到"数据基础软件公司"这个本分,AI 是调味料不是主菜。
5.2 易华录:把预重整用好,是一次稀缺的"系统重启"机会
把易华录放进矩阵,它跨"数据集成 / 智慧城市"和"数据存储 / 物理基础设施"两类——这两类的星图都指向 路径五(战略收缩 / 重整 / 整合)+ 路径四(生态切换)。
重新理解预重整:5 月 19 日北京一中院启动的预重整,市场上有不少声音用"濒临退市""保壳战"来定性。但从战略管理视角看,这其实是一次极为稀缺的、被司法程序加持的"系统重启"机会——
- 它提供了一次合法、有序、有时间窗口的资产负债表清算机会,处理多年累积的应收账款、低效资产、历史包袱——这些事在正常经营状态下几乎无法系统化推进
- 它强制全公司在债权人监督下做业务结构再审视,这种"被迫的诚实"比内部决议有效得多
- 它客观上为引入战略投资人 / 新管理层 / 新治理结构打开了一个谈判窗口——很多正常经营状态下做不到的整合,在预重整里反而能完成
成熟市场对这件事有不同的语义系统:达美航空 2005 年的预重整不被称为"濒临退市",而是"Chapter 11 Restructuring"——一个被基金经理、信用分析师、战略顾问公认的、与并购同等量级的资本运作工具。易华录现在拿到的是同一把刀,关键看怎么用。
当前可以做的事:
- 资产端做减法:蓝光存储重资产业务、低毛利集成项目、长账期 to-G 应收——这些都是预重整最适合处理的"历史包袱"。处理掉之后,公司会变小,但每一个剩下的业务质量都更高
- 聚焦真正有沉淀的赛道:交通主业不是"老本行",是它过去十年里真正建立了行业壁垒的地方——车路云一体化、智慧公路、智能交通是 AI 时代正在扩张的市场,把资源完全压到这条线,反而是把"被掩盖的核心价值"释放出来
- 数据业务做轻:从重资产数据底座转型为应用层 + 生态合作角色——和大模型公司 / 云厂商合作做"智慧文旅 / 智慧医疗"的行业接口,这类业务现金流模型完全不同
- 引入战略投资人:预重整窗口期是央企集团 / 产业资本 / 战略买家最容易入场的时点——以核心资产估值的合理对价,置换公司未来发展所需的资金 + 治理结构 + 协同资源
真正要避开的反而是机会的浪费:
- 不要用 AI 故事粉饰预重整的真实诉求——市场和重整投资人看得很清楚,反而会损害定价
- 不要试图保留所有原有业务——预重整的窗口期很短,不做减法等于错失最有价值的工具
- 不要做"再撑一年看看"的延迟决策——拖延会让本来还有谈判价值的核心资产持续贬值
重新框定:易华录现在的处境,对管理层来说不是"被推进了 ST 名单",而是被推到了一个绝大多数 A 股公司终其一生都进不来的战略窗口里——把它用好,三年后这家公司可能比 2020 年的自己更轻、更专、更值钱。把它用错,才是真正的失败。
这件事的关键不在 AI,在于有没有把战略收缩当成主动工具来使用的判断力。
5.3 两家公司的对比
| 维度 | 星环科技 | 易华录 |
|---|---|---|
| 真实身份 | 数据基础软件商 | 智慧城市集成商 + 数据存储商 |
| 四象限位置(§4.2) | Q2 保持本分 | Q4 战略收缩 |
| AI 时代受影响程度 | 中(边际承压) | 大(价值锚点过气) |
| 最现实路径 | 专精化 + AI 嵌入 | 战略收缩 + 生态切换 |
| 该做什么 | 回到基础软件本分 | 用好预重整窗口完成系统重启 |
| 不该做什么 | 假装 AI 平台公司去融资 | 强行讲 AI 翻身故事 |
两家公司的真正问题不是"没拥抱 AI"——是 "在被 AI 焦虑绑架之前,主业本身就有结构性问题没解决"。AI 既不是它们的救命稻草,也不是它们的死亡判决——是一个客观存在的边界变化,要冷静应对。
六、三个"AI 焦虑陷阱"要避开
本节要点:这类公司最大的风险不是 AI 本身,而是被 AI 焦虑逼着做错的事。
6.1 陷阱一:假装自己是 AI 公司
症状:年报、招股书、路演 PPT、官网首页——把所有"数据库""数据治理""集成项目"前面都加上"AI"。把产品名改成"AI XXX"。CEO 演讲里"大模型""智能体""数据要素"出现频率从每分钟 3 次升到 8 次。
为什么是陷阱:
- 监管层不傻——证监会、交易所对"AI 概念套壳"的审视越来越严
- 资本市场不傻——A 股 / 港股投资者已经被"AI 套壳股"教育过几轮,估值打折
- 客户不傻——客户买的是产品力,不是话术
- 最重要的:假装久了自己也会信——内部组织会按"AI 公司"的标准搞资源配置,反而把基本盘弄丢
正确姿态:诚实承认自己是"数据基础软件 / 数据集成 / 数据治理"公司,AI 是产品能力升级的工具——不是身份重塑的话术。
6.2 陷阱二:强行 all-in AI
症状:CEO 看到 OpenAI / DeepSeek 火,决定"我们也要训大模型""我们要做 AI 平台""我们要 ALL IN AI"。投几千万 GPU、招 50 人模型团队、把老业务的资源砍掉给新业务。
为什么是陷阱:
- 通用大模型是寡头薄利赛道——开源模型够用,自训没必要也没胜算
- 行业大模型有空间,但需要"行业数据 + 行业 know-how + 行业客户"三件套——只有大模型团队没用
- 老业务被砍 = 现金流被砍 = 新业务也撑不到看见结果
正确姿态:AI 是调味料不是主菜——把它嵌入现有产品提升体验,而不是另起炉灶搞 AI 公司。
6.3 陷阱三:全盘否认 AI 影响
症状:CEO 说"AI 是泡沫""我们这行 AI 影响不大""大模型搞不定企业场景"。继续按 2020 年的姿势做项目、签私有化、卖 License、看 ARPU。
为什么是陷阱:
- 客户预算结构在位移——不参与就是放弃
- 子领域有真实替代发生——BI、轻量数据治理、文档处理——这些都是真金白银的市场损失
- 5 年后回头看,没碰 AI 的公司会从"基础设施提供商"被边缘化为"非主流玩家"
正确姿态:承认 AI 改变了边界——不必转身成 AI 公司,但要在自己的产品里、自己的服务里、自己的商业模式里反映这个变化。
6.4 避坑总原则:清醒认知自己 + 选择性回应 AI
把三个陷阱合并成一句:
承认 AI 改变了什么,但更要承认 AI 没改变什么。你是什么样的公司,决定了你该怎么回应 AI——而不是 AI 决定你是什么样的公司。
七、给老板 / 产品 / 员工的冷思考
本节要点:不是"指南",是"问题清单"——帮你想清楚自己在 AI 时代是谁、要去哪。
7.1 给老板 / 决策层:先回答"我是谁"
不是"我要成为谁"——而是 "我现在到底是谁"。
5 个问题:
- 去掉 AI 标签后,我的公司过去 3 年靠什么吃饭? 数据库?集成?治理?标注?存储?——这是你的真实身份
- 这个身份在 AI 时代的价值锚点位移到了哪里?(回看本文 §2.2)
- 我有没有别人没有的稀缺资产? 行业 know-how?KA 关系?合规通道?数据资产?——这些是你的真实护城河
- 我现在的现金流、组织、品牌——能支撑哪种路径?(专精化?价值上移?AI 嵌入?生态切换?收缩?)
- 如果不做选择会怎样? 现金流多久会爆?市场份额多久会被替代?——这是你的最后期限
7.2 给产品负责人:你的产品需要哪种 AI 嵌入?
不是"要不要加 AI"——而是 "什么样的 AI 真的能让用户体验变好"。
5 个问题:
- 我的用户在产品里最痛的 3 个场景是什么? AI 能让其中几个不那么痛?
- 嵌入 AI 后,用户付费意愿会真实提高吗,还是只是"功能上看起来更新"?
- AI 嵌入需要哪些数据回流,客户愿意提供吗? 不愿意 = 别强求
- 我的研发节奏能支撑"持续调优 + 灰度评测"吗? 不能 = 先建评测体系
- 如果我不嵌入 AI,3 年后会被哪个对手用 AI 嵌入打败? 想不出来 = 不急着加
7.3 给员工 / 工程师:你的下一步在哪
不是"要不要焦虑 AI"——而是 "我自己的技能价值地图怎么变"。
5 个问题:
- 我现在做的事,5 年后大概率被 AI 替代多少? 如果 80%+,主动学习其他技能
- 我的核心能力里,哪些是"AI 难以替代的"? 比如复杂系统设计、行业判断、跨团队协调
- 我所在的公司选择了哪条路径? 不同路径对应不同的成长曲线和窗口期——比如战略收缩 / 整合路径里,重组后的新主体往往为留下来的核心团队提供更聚焦的舞台,而被剥离的板块则需要更早评估自己在新归属里的位置
- 我有没有数据 / 模型 / Agent 相关的"AI 邻接技能"? 不需要变成算法工程师,但要懂得用 AI 工具放大自己
- 我能不能从公司的"AI 嵌入"项目里找到自己的成长机会? 比如成为 "数据 + 算法 + 业务"复合人才
结语:先回答"我在 AI 时代是谁"
回到本文开头。
星环科技和易华录都不是"没摸到 AI 门"的失败者——它们就不是 AI 公司,从来不是、未来也不需要是。它们的真实身份是 "前 AI 时代的数据技术公司"——这个身份有它的尊严、它的客户、它的现金流(即使现在紧张),也有它在 AI 时代继续存在的真实空间。
它们目前的困境,并不是"被 AI 抛弃",而是 三件互相纠缠的事:
- 主业本身的结构性问题(项目制 / 应收账款 / 重资产 / to-G 收缩)——这些跟 AI 关系不大
- AI 时代的边界位移(预算结构、价值锚点、子领域替代)——是真实的,但不致命
- 被 AI 焦虑绑架的错误自我定位——这才是真正的危险
不被 AI 焦虑绑架,并不意味着对 AI 视而不见——而是 冷静选择适合自己的回应方式。本文给的 5 条路径(专精化、价值上移、AI 嵌入、生态切换、收缩并购)就是 5 种可能的回应。
最后留 4 句话给所有读到这里的传统数据技术公司从业者:
AI 既不是你们的救命稻草,也不是你们的死亡判决。
你们是 2010 年代数据浪潮里幸存下来的真公司,不是 2026 年 AI 浪潮里突然出现的虚拟概念。
你们的尊严不来自"是不是 AI 公司",来自"在自己的赛道里有没有真本事"。
先回答清楚"我在 AI 时代是谁",再决定要去哪里。
不是所有公司都要走 AI-Native,但所有公司都要做好自己。
参考资料
- 新浪财经,《星环科技因围标串标被暂停全军采购资格》,2026-05-19。
- 每日经济新闻,《4 天"火速"获批!*ST 易录预重整启动》,2026-05-20。
- 每日经济新闻,《星环科技二度递表港交所:现金流困局、客户结构异常与资产质量承压》,2026-03-27。
- Ice,《AI 时代的商业模式:从数据视角出发》,2026-05-21。本文引用其"三轮齿合"框架(数据原料 × 数据工程 × 反馈闭环)作为价值锚点位移的理论参考。
- Ice,《FPT Flezi Foundry 发布:当 IT 外包行业第一次把"按结果付费"写进合同》,2026-05-22。IT 服务行业商业模式重构的对照案例。
- IDC,《IDC 中国大数据软件市场跟踪报告,2025》。
- Gartner,《Magic Quadrant for Cloud Database Management Systems, 2025》。
- 中国信息通信研究院,《2025 年数据基础设施发展白皮书》。