数据不动,指针先行:Komprise TFT 与非结构化数据的“零搬迁”范式

Deep Research 报告 | 2026 年 6 月 | 面向数据工程师、AI 平台架构师与数据治理负责人
摘要
6 月 23 日,做了十年非结构化数据管理的 Komprise 发布了一个叫 Transparent File Tables(TFT,透明文件表) 的新能力。一句话概括它干的事:不搬动一个文件,就把企业散落各处的非结构化数据,变成一张能被 Snowflake、Databricks 直接查询的 Apache Iceberg 表。
这件事值得写,不是因为又多了一个数据产品,而是因为它给"非结构化数据怎么喂给 AI"这道题,给了一个和主流路线相反的答案。主流做法是"搬过去再加工"——把 PB 级文件拷进湖仓、解析、切块、嵌入;Komprise 的做法是"先别搬,把元数据和指针做成表"——数据留在原地,只有真正要用到原始文件时才按需搬运。
本文覆盖三件事:一是这套"零搬迁"范式到底怎么运转、和"全量 ETL 拷贝""湖仓外部表"差在哪;二是它能解决什么真问题、又有哪些自己没说的硬约束;三是它背后那条正在 2026 年成形的大趋势——data gravity(数据引力)下,行业正在集体转向"把 AI 带到数据身边",以及这对国内数据要素流通意味着什么。
一、80% 的数据非结构化,99% 对 AI 仍是“暗”的
先把问题钉死。几乎每家做企业 AI 的厂商现在都会引用 IDC 的同一组数字:企业数据里超过 80% 是非结构化的,但其中只有不到 1% 真正被 AI 用上了。 换句话说,约 99% 的非结构化数据对 AI 来说是"暗数据"(dark data)——存着,但用不上。
为什么用不上?Komprise 的 CTO、联合创始人 Krishna Subramanian 把原因讲得很直白,归纳起来是三条:
- 没有一致的 schema。文档、视频、音频、邮件、日志,每一种形态、每一个部门的命名和组织方式都不一样,没法像数据库表那样直接
SELECT。 - 质量参差。大量是重复、过期、低价值甚至含敏感信息的文件,直接喂给模型既污染结果又踩合规红线。
- 大且搬不动。跨多厂商 NAS、对象存储、公有云的 PB 级数据,真要集中搬运,"复杂、昂贵、费力,动辄要数周到数月"。
这三条里,最容易被低估的是第三条。"搬不动"不是一句抱怨,而是一道经济账。 把几个 PB 从本地 NAS 拷到云湖仓,光是出口带宽、对象存储落地、二次清洗的人力,就能让一个 AI 项目还没产出价值就先烧穿预算。这也是为什么 Subramanian 强调了一个容易被忽略的判断:当所有企业都能用上同样的基础模型时,真正的差异化来自企业自己的数据——可那批最有价值的数据,恰恰是搬不动的那批。
那现有的办法呢?业界其实有两条成熟路线,但都不舒服。
第一条是全量 ETL 拷贝:用批处理把文件从云存储里捞出来,落到对象存储暂存区,再加载进湖仓。问题是 ETL 这套工具是为结构化、半结构化数据设计的,它"只管把原始数据整体拷过来,不做 schema 抽取",数据落地后是一堆字符串、二进制 blob 或 JSON,还得再过一层层加工才能用。
第二条是湖仓的"外部表/原地查询"(query-in-place):Snowflake、Databricks 都支持用 external table 引用外部数据。听起来很美,但 Subramanian 的吐槽很实在——"用户得花好几个小时手工预处理,才能给这堆非结构化数据造出一个湖仓认得的结构化描述"。换句话说,外部表解决了"指过去",没解决"怎么先把 schema 整理出来"。
这就是 Komprise 切入的缝隙:schema 我帮你自动生成,文件我先不搬。
二、核心设计:把“元数据 + 指针”做成一张 Iceberg 表
Transparent File Tables 的核心设计,可以用一句话拆开理解:它给湖仓的不是文件本身,而是一张描述这些文件的表——表里装的是 Komprise 富化过的元数据,外加一个指向原始文件位置的指针。
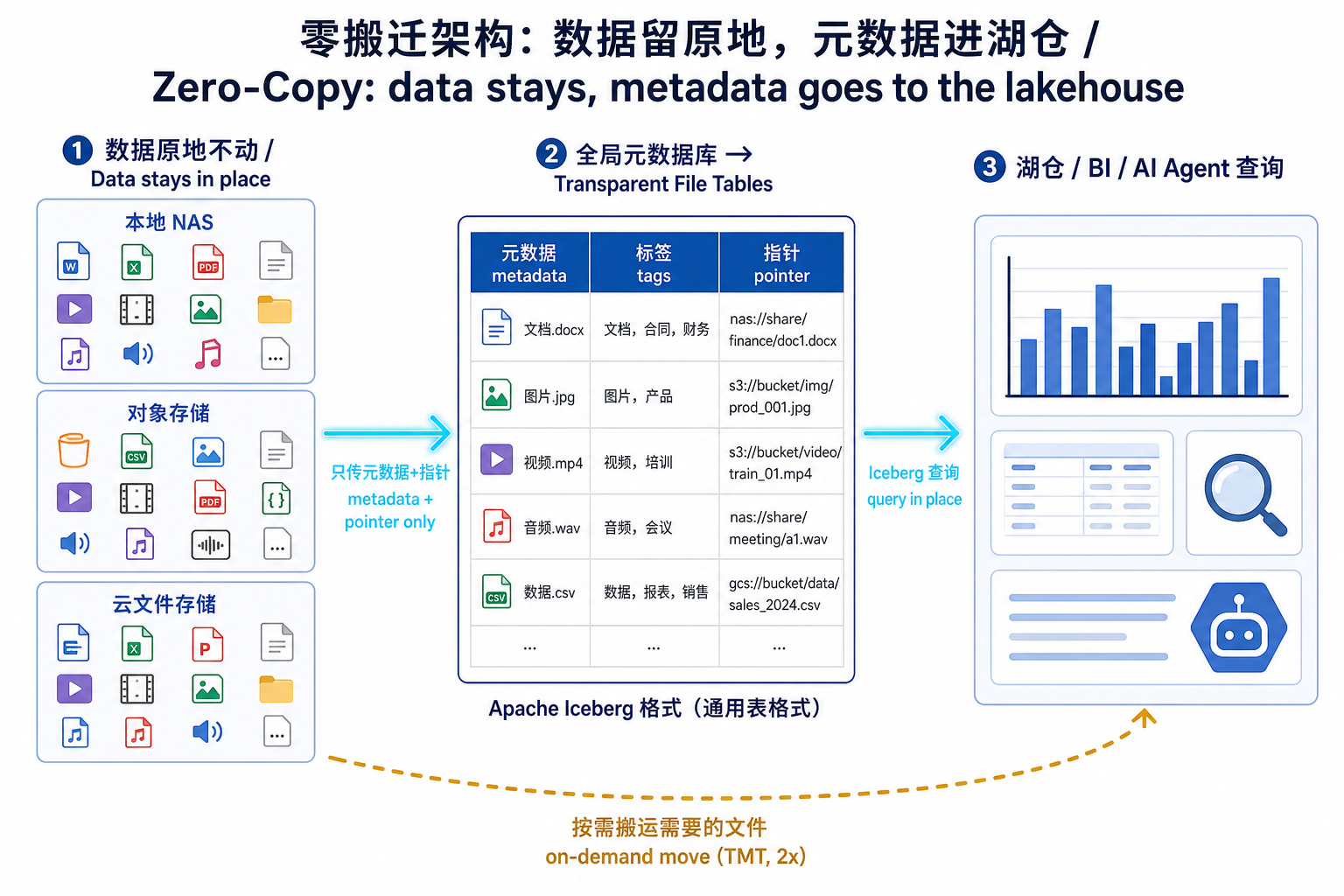
这张表用的是 Apache Iceberg 格式。这一步选型很关键:Iceberg 是当下湖仓事实上的通用开放表格式,Snowflake、Databricks 以及几乎所有主流分析引擎都原生认它。所以 Komprise 不需要去对接每一家湖仓的私有接口,只要导出标准 Iceberg 表,下游"用熟悉的 BI/分析工具写 Iceberg 查询就行,根本不需要知道 Komprise 的存在"。
表里的指针,靠的是 Komprise 那项已有专利的 Transparent Move Technology(TMT,透明移动技术)。TMT 的老本行是数据分层迁移——把文件从一处挪到另一处,同时在原位留下一个动态符号链接(Komprise Dynamic Links),应用和用户访问起来跟原文件一模一样,权限属性全保留。TFT 把这套"指针寻址"的能力复用过来:表里那一列指针,就是指向远端真实文件的链接,访问时数据才被动态加载,平时一个字节都不搬。
和上一篇《AI-Ready Assets》里讲的"双轨同步生成"(边切块嵌入、边抽元数据,原子写入向量库)对照着看会更清楚:那条路线是把数据加工成向量资产再用,本质仍要把内容拉过来;TFT 这条路线是先把数据的"目录与坐标"做出来,内容暂时不动。前者像是把整座图书馆的书都扫描进数据库,后者像是先做一套精确到页、带标签和借阅权限的总目录卡片——你大部分查询,看卡片就够了;真要读全文,再去书架上取那一本。
需要强调:TFT 当前定位是让非结构化数据"可被发现、可被联合查询",它本身不取代向量化/RAG。真正要做语义检索或微调时,仍要把命中的那批文件取出来做嵌入——但此时要搬的只是"筛选后的一小撮",而不是"全量 PB"。这正是它和全量 ingest 路线的互补点。
三、五步工作流:从全局索引到按需搬运
把 TFT 的运转拆成五步看,会比抽象描述清楚得多。
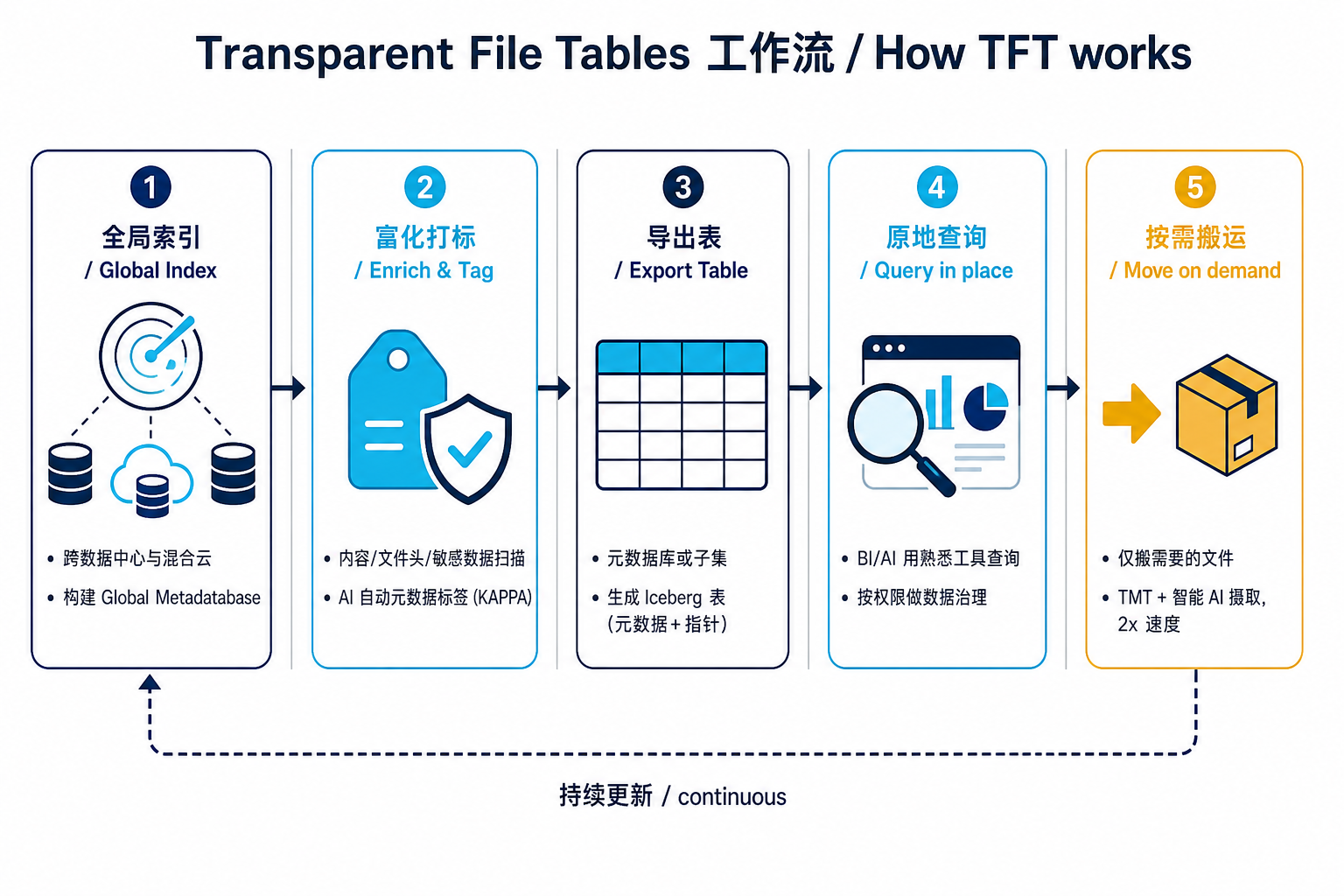
第一步,全局索引。Komprise 用它的分布式、横向扩展架构,扫描企业跨数据中心和混合云的全部文件与对象存储,把索引项汇聚成一个 Global Metadatabase(全局元数据库)。这是整套方案的地基——它一直在做的就是"全面看见"企业到底有哪些数据、在哪、归谁。
第二步,富化打标。光有系统元数据(路径、大小、时间)还不够。Komprise 通过它的 KAPPA(AI Preparation and Process Automation,AI 准备与流程自动化)数据服务和 Smart Data Workflows,对文件做内容扫描、文件头解析、敏感数据识别,并用 AI Agent 自动打元数据标签。这一步把"系统元数据"升级成"系统 + 内容 + 自定义元数据"的高质量 schema——也就是把混乱变成了表的列。
第三步,导出表。IT 把全局元数据库(或它的某个子集)导出成 Transparent File Tables,放进 Snowflake、Databricks 这类湖仓。导出的就是标准 Iceberg 表:元数据 + 指针。
第四步,原地查询。湖仓侧的数据专家用自己惯用的 BI/分析工具写 Iceberg 查询,把这张表和 ERP 财务表、业务系统表 JOIN 起来,结构化与非结构化数据第一次能在同一个界面里联合分析。治理则按用户访问权限来控制——谁能看到哪些行、哪些列,由权限决定。
第五步,按需搬运。如果某个 AI 或分析任务确实需要原始文件,TMT 调用 Intelligent AI Ingest 把"需要的那部分文件"搬过去。Komprise 给的数据是:因为采用大规模并行架构、并在摄取时用过滤器剔除低质量与敏感数据,这一步的速度是标准数据传输工具的 2 倍(其基准测试对标的是云厂商的标准数据同步工具)。
这五步里,第二步和第五步是 Komprise 区别于"纯外部表"的护城河:它不只是给湖仓一个指针,还顺手把 schema 自动整理好了,并且在真要搬时只搬精选后的高质量子集。 外部表方案要用户自己花几小时手工干的活,被压进了流水线。
四、三条路线的正面对比
理解一个新方案,最快的办法是把它和它要取代的东西摆在一起比。非结构化数据进 AI/分析,目前就这三条路线:
| 维度 | 全量 ETL 拷贝 | 湖仓外部表(原地查询) | Komprise TFT |
|---|---|---|---|
| 是否搬数据 | 全量搬 | 不搬(仅引用) | 默认不搬,按需搬子集 |
| schema 从哪来 | 落地后再加工 | 用户手工预处理(数小时) | 自动生成(KAPPA 富化) |
| 跨多厂商存储 | 每个源单独打通,复杂 | 受湖仓连接器限制 | 全局索引统一覆盖 |
| 首次见效时间 | 周~月级 | 慢(卡在手工建 schema) | 导出表即可查 |
| 治理/权限 | 落地后另建 | 依赖湖仓 | 按用户权限随表生效 |
| 主要成本 | 带宽 + 存储 + 人力 | 人力(建结构化描述) | 索引/富化算力 + 按需搬运 |
| 适合场景 | 确定要全量入湖的核心数据 | 已结构化、少量外部数据 | 海量、分散、不确定要不要全搬 |
把这张表读一遍,TFT 的定位就清楚了:它不是要干掉 ETL,而是要干掉"为了查一下、先把全量搬过来"这种浪费。 当你面对的是"几个 PB、横跨五套存储、其中真正要喂 AI 的可能只有 5%"这种局面时,前两条路线要么太贵、要么太慢,TFT 的"先建目录、按需取数"才是经济上成立的解。
反过来,如果你的数据已经规整、量也不大、而且确定要全部入湖深度加工,那老老实实 ETL 反而更直接——别为了"零搬迁"而零搬迁。
五、三个落地场景:药企看板、放射学微调、媒体 Agent
Komprise 和媒体给出了几个具体场景。按"证据规模 + 角度独特性"排序,挑三个有代表性的展开。
场景一:药企把"实验文件 + ERP + 电子实验记录"拼在一张看板里
这是 Komprise 自己给的旗舰案例。
| 要素 | 说明 |
|---|---|
| 角色 | 药企数据分析师 |
| 数据源 | 各仪器/实验室产生的项目文件(非结构化)+ ERP 财务表 + Benchling 实验记录 |
| 做法 | 在湖仓里查 TFT 拿到项目文件的结构化视图,再 JOIN 财务和实验数据 |
| 价值 | 结构化与非结构化数据在单一界面联合分析,做药物研发看板 |
过去这种分析几乎不可能轻量完成:实验文件散在仪器旁的文件服务器上,要先搬、先标注,分析师才碰得到。现在 TFT 把这些文件变成可 JOIN 的一列,分析师在熟悉的湖仓里就能把"哪个项目花了多少钱、产出了哪些实验数据、对应哪些原始文件"一次性看清。核心洞见:当非结构化数据能被 JOIN,它才第一次进入了"分析"的语境,而不只是"存储"的语境。
场景二:医疗 ML 工程师,curate 放射学微调数据集而不碰病历原文
这个案例的独特性在于它把"零搬迁"和"合规"绑在了一起。
一位医疗机构的 ML 工程师要微调一个放射学大模型。传统做法要把大量 DICOM 影像和报告搬进训练环境,敏感病历一路裸奔,合规风险极高。用 TFT 的做法是:先用 AI 从 DICOM 及其报告里抽出"模态、部位、检查类型、诊断结论"等标签,把这些标签和 EHR 里的结构化患者队列数据 JOIN,在元数据层就圈定出"正好需要的那一小批",最后只把这批导出成 Parquet 喂给 RAG 或微调流水线。
核心洞见:在元数据层做筛选和圈定,意味着大部分敏感原文从头到尾没有离开原地——"最小必要搬运"天然就是一种隐私保护。
场景三:媒体 Agent 做"叙事对齐",先查表再决定搬哪几个脚本
媒体娱乐行业有个 AI Agent 负责"叙事对齐"——给定一个任务,要从海量媒资里找出相关素材。它的做法是:先用结构化的项目数据,去 JOIN Komprise Transparent File Tables 里的媒资元数据,先在表里把候选范围缩到几个脚本,再决定把哪几个文件取来做摘要。
核心洞见:对 Agent 来说,TFT 提供的是一层"先看目录、再取全文"的检索中间层——这恰好是 Agent 最缺的"在动手搬运昂贵数据前,先低成本地想清楚要什么"。
六、这不是一家公司的产品,而是一次集体转向
如果只把 TFT 当成"Komprise 又出了个功能",会错过它真正的意义。把 2026 年 6 月这一两周的行业新闻摊开看,你会发现一堆厂商在用不同姿势讲同一句话:别再把数据搬到 AI 身边了,把 AI/计算带到数据身边去。
- 同一天,EDB 发布"agentic database",口号是"把主权 AI 带到企业数据已经在的地方"。
- Databricks 在 Data + AI Summit 上抛出 LTAP(湖仓事务分析处理),CEO Ali Ghodsi 的主题演讲标题是"AI 没有智能问题,它有上下文问题"——上下文从哪来?从企业那批没被用起来的数据来。
- 存储侧,Dell 在反复讲"data gravity(数据引力)不只是字节数";Zilliz/Milvus 推 Vector Lakebase,想把向量检索和数据湖合一。
这些动作指向同一个判断:当数据规模大到一定程度,"搬运"本身成了最大的成本和风险,于是引力反转——计算、模型、Agent 开始围着数据转。 Komprise TFT 是这股潮流在"非结构化数据 + 湖仓"这个具体接口上的一个落点。它的独特贡献是把"零搬迁"做到了连 schema 都不用你先整理的程度。
洞见一:AI 的瓶颈正在从"模型多强"转向"数据可达性多高"。
当大家用的基础模型趋同,胜负手就落在"你能不能低成本、合规地把自己独有的数据接进来"。TFT 这类产品本质是在卖"数据可达性",而不是卖存储或算力。
洞见二:"元数据先行"可能成为非结构化数据的默认工程姿势。
先建全局元数据 + 指针、按需再取原文,这套打法比"全量入湖"在成本曲线上友好得多。可以预期,未来一两年会有更多"目录层/元数据层"产品冒出来,dbt、Catalog 这类工具也会把"非结构化文件的 schema 与血缘"纳入管理范围。
七、几条没说出口的硬约束
厂商的发布稿永远是优点。这里替读者把"它没说、但你必须想清楚"的几条列出来。
- 早期访问,不是 GA。 TFT 当前是 early access。专利的 TMT 和 Global Metadatabase 是成熟件,但"导出 Iceberg 表 + 湖仓联合查询"这套组合的稳定性、规模上限、并发表现,还需要真实大客户跑过才能下结论。
- 元数据质量 = 这套方案的天花板。 TFT 的价值全押在"KAPPA 富化出来的元数据有多准"。如果标签抽错、敏感识别漏判,那
JOIN出来的就是错的,权限治理也会出洞。换句话说,你不是不做数据加工了,而是把加工从"全量内容"前移到了"元数据"——这层做不好,后面全垮。 - "指针失效"是新的运维面。 数据留在原地的代价是:原文件被移动、删除、改权限,指针就可能悬空。这套体系对底层存储的稳定性、对 Komprise 链接一致性的依赖,是传统"拷一份进湖仓"所没有的新风险。
- 它仍是又一层中间件。 你在湖仓和存储之间插了一个 Komprise 层。好处是统一了视图,代价是多了一个供应商锁定点和故障域。对已经用 Komprise 做数据管理的客户这是顺水推舟;对没用的客户,要为"零搬迁"先引入一整套数据管理平台,这笔账要单独算。
八、ICE 观察:本土与合规视角
合规视角:“最小必要搬运”天然贴合数据保护
TFT 最值得国内同行借鉴的,不是技术细节,而是它的默认姿势:数据不动、按权限查询、按需最小搬运。这套姿势和国内《数据安全法》《个人信息保护法》强调的"最小必要""数据不出域"高度同构。前面那个放射学案例就是活例子——敏感原文不离原地,只让筛选后的最小子集流动,这正是合规团队梦寐以求的工程形态。可以说,"零搬迁"在海外是省成本的工程优化,在国内还顺带是降合规风险的治理优势。
本土视角:可信数据空间的“目录层”缺口
这一点和我们一直在追的可信数据空间、数据要素流通直接相关。数据要素流通卡在哪?很大程度上卡在"数据持有方不敢把数据交出去"。TFT 这种"只交元数据和指针、原始数据留在持有方"的模式,恰恰是破解"不敢交"的一把钥匙——它在技术上实现了"数据可用不可见"的一个具体形态:使用方拿到的是结构化目录和按权限的查询结果,原始文件始终在持有方手里。
国内市场目前的现实是:向量库、湖仓这些"承载层"已经不缺,真正缺的是横跨多源、自动生成 schema、带治理血缘的"非结构化数据目录层",而且要能对接信创湖仓、满足数据不出域。谁能把 Komprise 这套"全局元数据库 + 指针寻址 + 按需搬运"在国产化栈上做扎实,并和可信数据空间的"使用控制"打通,谁就握住了数据要素流通里一块没人占住的高地。
结论
把这一长串收束成几个能带走的判断:
- 范式之争已经清晰:搬数据 vs 搬目录。 面对"海量、分散、不确定要不要全用"的非结构化数据,"先建元数据 + 指针、按需取原文"在成本和合规上,往往比"全量搬进湖仓再加工"更划算。Komprise TFT 是这条路线目前最完整的一个落点。
- 它和向量化不是替代,是上游。 TFT 解决"可发现、可联合查询、按需取数",RAG/微调解决"取来之后怎么用"。理性的架构是两者叠用:用 TFT 把全量收敛成高质量子集,再对子集做嵌入——别再为了一次查询把整片数据湖搬空。
- 真正的护城河在元数据质量,不在"零搬迁"这个口号。 谁的自动打标、敏感识别、schema 生成更准,谁的"零搬迁"才立得住。这层做不好,零搬迁就是把脏数据原地放着假装解决了问题。
- 对国内是双重利好。 "数据不动、按权限查、最小搬运"既省成本,又天然贴合"数据不出域、可用不可见"。可信数据空间最缺的"非结构化目录层",正是值得本土厂商重投的方向。
回到最朴素的那个问题:你手上那几个 PB 的文件,有多少是为了"偶尔查一下"而被整体搬来搬去、反复拷贝的?如果答案让你心里一紧,那"数据不动、指针先行"这八个字,可能就不只是 Komprise 的一句营销词,而是你下一个数据架构该认真考虑的默认选项——你准备先动数据,还是先动目录?
参考资料
- Komprise. Komprise Delivers Query-Ready Enterprise Unstructured Data to AI and Data Lakehouses Without Moving a Single File(新闻稿). 2026-06-23. 转载于 BigDATAwire. https://www.hpcwire.com/bigdatawire/this-just-in/komprise-delivers-query-ready-enterprise-unstructured-data-to-ai-and-data-lakehouses-without-moving-a-single-file/
- Chris Mellor. Komprise provides lakehouse access to petabytes of unstructured data. Blocks & Files. 2026-06-23. https://www.blocksandfiles.com/data-management/2026/06/23/komprise-provides-lakehouse-access-to-petabytes-of-unstructured-data/5260267
- Mike Wheatley. Komprise aims to make messy, unstructured data accessible without the hassle. SiliconANGLE. 2026-06-23. https://siliconangle.com/2026/06/23/komprise-takes-challenge-making-messy-unstructured-data-accessible-without-hassle/
- Komprise. Transparent Move Technology (TMT) 产品页与白皮书. https://www.komprise.com/product/transparent-move-technology/
- IDC. 关于企业非结构化数据占比(>80%)与 AI 利用率(<1%)的相关预测,转引自上述报道。
- BigDATAwire. AI Is Breaking Traditional Data Architectures. Databricks Thinks LTAP Is the Fix / Ali Ghodsi's Keynote: AI Doesn't Have an Intelligence Problem, It Has a Context Problem. 2026-06.