AI-Ready Assets:把 92% 的非结构化数据点亮

调研报告 | 2026 年 4 月 | 面向数据工程师、AI 平台架构师与 CTO
摘要
IDC 在 2026 年 FutureScape 中给出了一个看似平淡、实则要命的判断:"AI 的成败,将由非结构化数据管理能力决定。" 这句话之所以有力,不是因为它谈 AI,而是因为它把"AI 的瓶颈"从模型、算力、数据量,第一次明确扔到了数据形态上。
92% 的企业数据是非结构化的,74% 的企业已经存到 PB 级,但 62% 承认没人会管,数据的平均"保鲜期"只有 3.3 天。所谓"非结构化数据爆发",爆发的不是数据量——数据量从 2018 年起就一直在涨——爆发的是一种新做法:用大模型在一条流水线里,把散乱的文档和视频直接变成"向量 + 结构化元数据 + 治理标签"的 AI-Ready 资产。
本文按下面这条主线展开:
- IDC 究竟说了什么 —— 一组互相印证的数据点
- 什么叫 AI-Ready 资产 —— 一个新型数据单元的四种属性
- 2026 年的新做法:双轨同步生成 —— 技术原理 + 文档/视频两个场景
- 厂商选型:四种场景驱动的组合 —— Lakehouse / 视频专用 / 国内合规 / 低预算 PoC
- ICE 观察 —— 技术契约、团队 KPI、国内机会
一、IDC 的几个不容忽视的数字
先把 IDC 这次预测拆开看。它不是一句口号,是一组互相印证的数据点。
| 维度 | 关键数据 | 含义 |
|---|---|---|
| 数据规模 | 2025 年全球 213.56ZB,非结构化占 92% | 结构化数据库只是冰山一角 |
| 中国市场 | 2025 年 51.78ZB,2029 年 136.12ZB,CAGR 26.9% | 增速显著高于全球 |
| 企业存量 | 74% 企业 ≥ 5PB,40% ≥ 10PB(比 2024 年增长 57%) | 已经从 TB 时代彻底跨入 PB 时代 |
| 治理短板 | 62% 企业缺 AI 数据管理人才 | 第一次超过云存储与安全合规,成为头号能力短板 |
| 数据时效 | 数据平均"保鲜期" 3.3 天;54% 企业数据流不稳定 | 数据腐败比硬盘故障更致命 |
| AI 落地 | 仅 15% G5000 企业能在 2026 年对齐数据智能与模型智能 | 真正"用得起 GenAI"的极少 |
| 业务价值 | AI-Ready 数据架构带来 营收 1.2x、效率 1.5x、利润 1.6x、客户留存 5x | 经营指标,不是技术指标 |
把这张表读两遍,你会得到一个朴素结论:所谓"非结构化数据爆发",本质是"非结构化数据从存储成本变成 AI 燃料"。过去十年企业花了不少钱建对象存储、建数据湖,把这些数据"存起来"了;但只要它们仍然是 PDF、MP4、MP3 的原生形态,对模型来说就是一片黑盒——你既无法语义检索,也无法精确过滤,更无法做治理与审计。
IDC 把"该做什么"明确成了"建 AI-Ready 数据架构"。这正是接下来要展开的概念。
二、AI-Ready 资产到底是什么
很多人听到"AI-Ready"会下意识理解成"清洗干净、放进数据湖"——这是 2018 年的语境,不是 2026 年的。
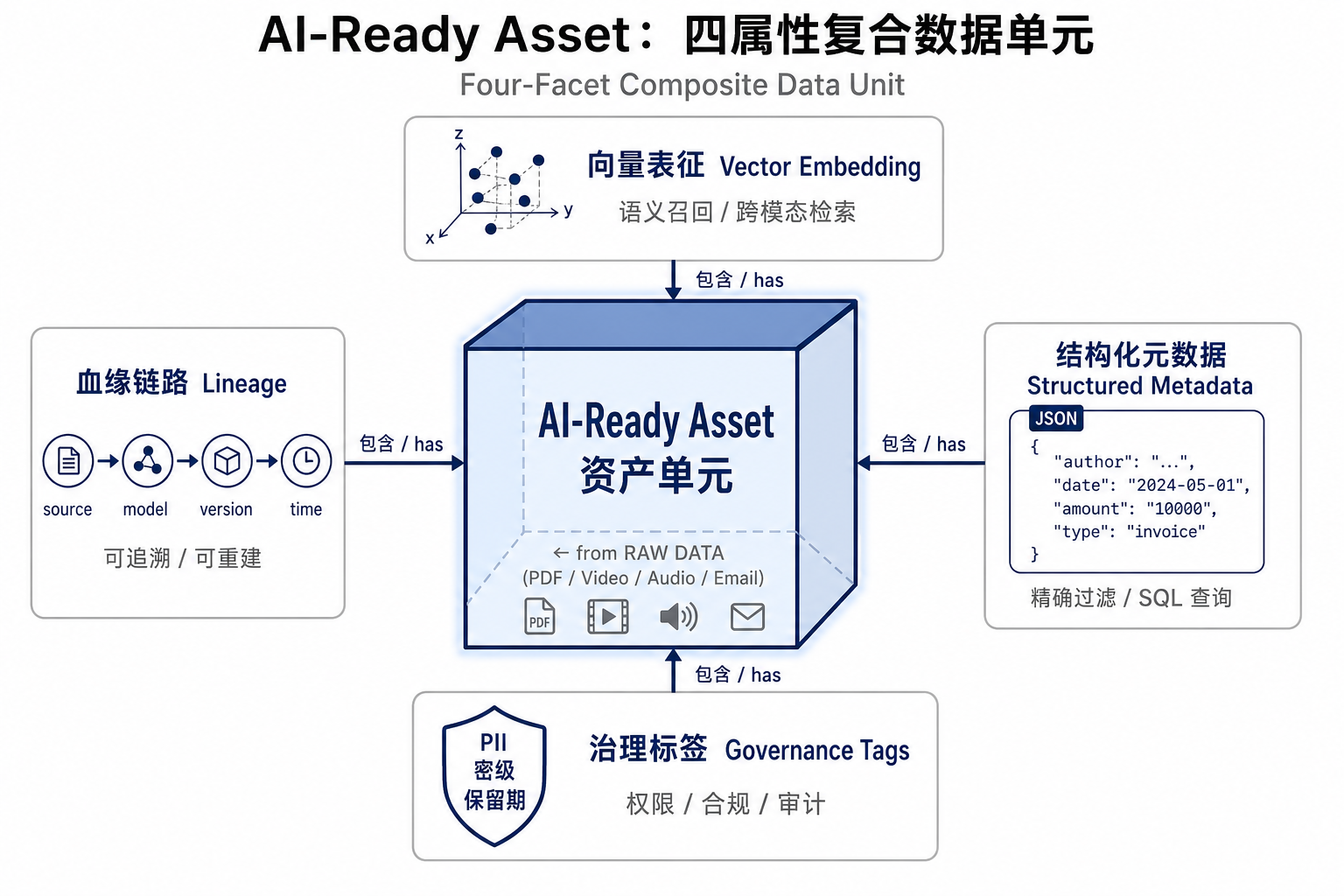
2026 年的 AI-Ready 资产,按 IDC 的分层模型,至少同时具备四种属性:
| 属性 | 作用 | 缺了会怎样 |
|---|---|---|
| 向量表征(Embedding) | 语义召回、跨模态检索 | 退化为传统数据湖,只能 SQL 查 |
| 结构化元数据(Metadata) | 精确过滤:"金额>5 万的发票"、"销售部签的合同" | 退化为无脑塞向量库的 RAG,召回精度低 |
| 治理标签(Governance Tags) | PII、密级、保留期、访问策略自动绑定 | 合规事故温床,模型能看到不该看的数据 |
| 血缘链路(Lineage) | 来源 → 模型 → 版本 → 时间可追溯 | 模型升级想重新嵌入时,全库重跑、零回溯 |
四者缺一不可。把它们合起来看,AI-Ready 资产其实是个复合数据单元:一份原始的 PDF 报告、一段 30 分钟的视频、一封邮件,被加工成"原文 + 向量列 + JSON 元数据 + 治理标签 + 血缘记录"的多面体。这个多面体可以被 RAG 系统调用、被 Agent 推理、被分析师过滤、被合规系统审计——它是一种新型的数据资产。
理解了这一点,再看 IDC 的预测就豁然开朗:所谓"由数据管理能力决定 AI 成败",决定的不是"你有没有数据",而是"你的数据有没有变成这种多面体"。数据再多,仍然是 PDF/MP4,对 AI 来说就是不存在。
下一个问题自然是:这种多面体,怎么造出来?
三、2026 年的新做法:双轨同步生成
为什么以前做不到
如果你 2024 年做过一个企业 RAG,工作流大概是这样:先用 Unstructured 解析 PDF,再调 OpenAI Embedding 嵌入,写到 Pinecone;想加元数据?再单独跑一个 LangChain 脚本调 LLM 抽取,更新到一张 Postgres 表里;想做治理?等业务方提需求再补。
这种"分步组装"的做法有三个无法回避的硬伤:
- 漂移 —— 向量库和元数据库不同步,原始文档改了,向量更新了,元数据没跟上。
- 断点 —— 任何一步失败,重跑只能整链路重来;调试时不知道是嵌入挂了还是抽取挂了。
- 治理后置 —— PII、密级永远在最后才补,往往业务跑了一年才发现合规问题。
2026 年的突破点不在于哪个具体模型,而在于工具链终于把这五步压成了一条原子流水线。这就是我说的"双轨同步生成"。
双轨同步生成的架构
一句话概括:用 VLM/LLM 在同一条流水线里,"一边切块嵌入、一边抽取结构化元数据",原子地写入向量库与目录。
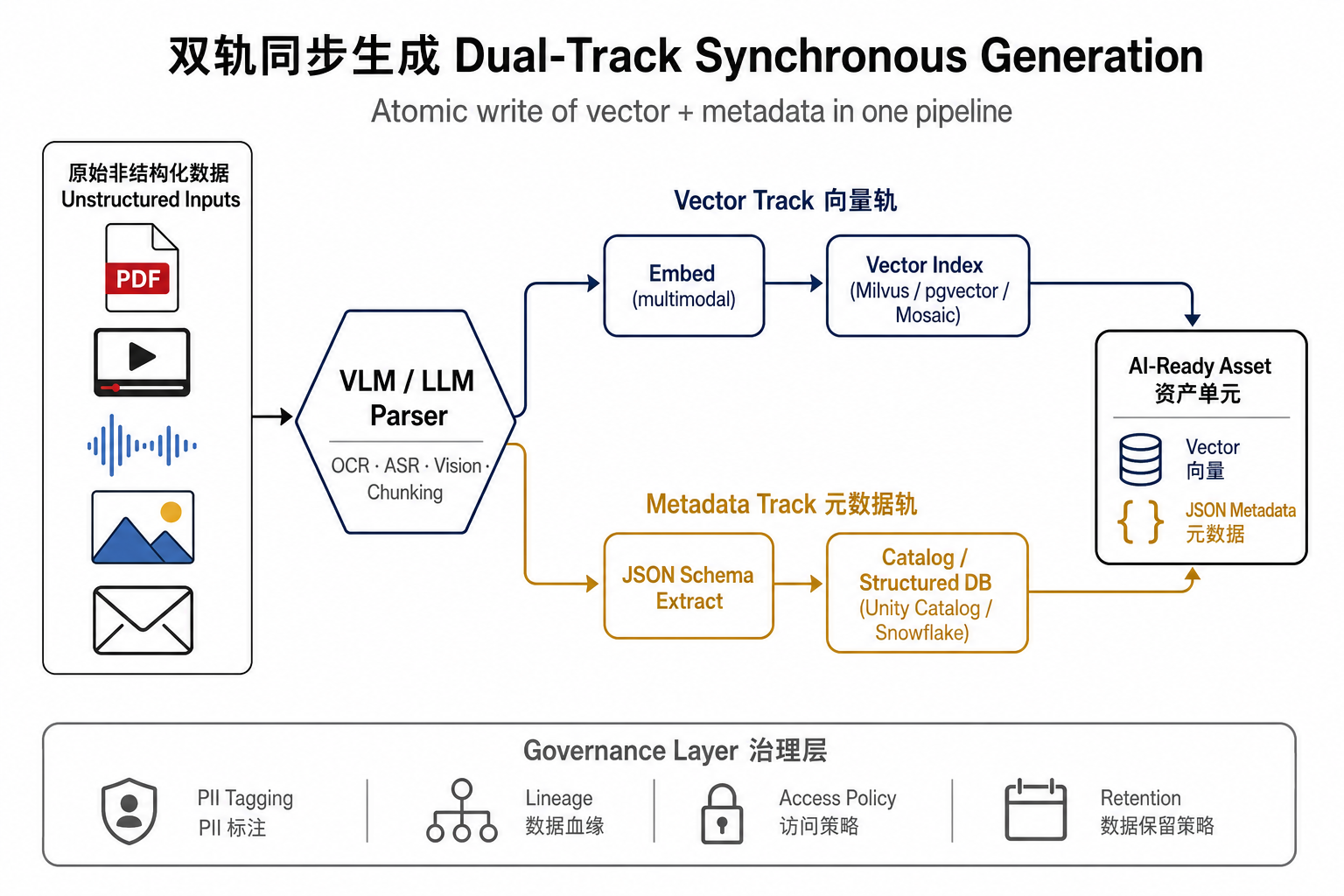
用伪代码表示就是:
原始非结构化数据
↓ ① 多模态解析(VLM / OCR / ASR / 视频抽帧)
↓ ② 智能切块(语义分块 / 递归分块 / 时间戳分段)
↓ ③ 双轨同步:
· 向量轨:统一多模态 embedding
· 元数据轨:LLM 按预设 JSON Schema 抽取字段
↓ ④ 原子写入:向量库(向量列)+ 目录/数据库(元数据列)
↓ ⑤ 治理同步:血缘、权限、PII 标签自动绑定
→ AI-Ready 资产三个关键词值得记:并行(向量和元数据是同一次 LLM 调用的两个产物,不是先后跑)、原子(要么都写进去、要么都回滚,不存在向量进了元数据没进的中间态)、治理同步(标签随数据进库,不是事后补丁)。
下面分文档和视频两类,看具体怎么做。
文档场景:双层元数据是 RAG 系统的分水岭
文档(合同、工单、邮件、PDF)是最成熟的部分。三家典型实现:
- Vectorize.io / LangChain RAG 流水线:在 chunk 阶段同时抽取双层元数据——文档级(作者、日期、文档类型)和段落级(条款编号、金额、产品号)。2026 年 IEEE CAI 的论文实测,metadata-enriched 检索精度可达 82.5%,P95 < 30ms。
- Databricks
ai_parse_document+ Mosaic AI Vector Search:SQL 函数层调用 VLM 直接解析 PDF 中的图表与扫描件,输出结构化字段;向量索引与底层 Delta 表自动同步。 - Snowflake Cortex AI Functions:直接在 SQL 里调用
EXTRACT_ANSWER、SUMMARIZE、EMBED_TEXT_*、AI_CLASSIFY、AI_FILTER,把非结构化转成结构化列 + 向量列,数据零搬迁。
这里双层元数据是一个值得记住的设计:文档级做粗粒度过滤,段落级做精确召回。它能解决纯向量 RAG 最痛的"语义近似但实际不符合"问题——比如下面这个真实场景。

同样查"金额 > 5 万的发票",左边纯向量召回的 5 条结果里,混着采购合同、模板说明、报销单、邮件草稿,只有 1 条是真发票(精度 20%);右边加上 type='invoice' AND amount>50000 的元数据过滤,3 条全对(精度 100%)。同一个嵌入模型、同一个向量库、同一份数据——差距全在元数据上。
这就是为什么我要把这条单独拎出来讲:对绝大多数 RAG 项目而言,做对元数据的投入产出比,远高于继续调向量模型或 chunking 参数。
视频场景:单 API 输入原始视频,输出结构化资产
视频是 2026 年最有突破的方向,因为它"既最大、又最难 AI-Ready"。一年前要把视频做成可检索资产,团队需要拼装 ASR、视频抽帧、VLM 描述、嵌入、入库五个组件;现在有了下面这三类工具,工程门槛塌方式下降。
- TwelveLabs Pegasus 1.5(2026 年 4 月发布)。Time-Based Metadata Extraction (TBM) 是个重要工程突破:用户给一段最长 2 小时的视频和一份自定义 JSON Schema,单次 API 调用就能拿到带时间戳的结构化元数据 + 视频嵌入,不需要先做切片、不需要预先打标。在分段质量上比 Gemini 3.1 Pro 高 13.1%。
- Google Gemini Embedding 2(2026 年 3 月发布)。原生多模态嵌入:文本/图像/视频/音频/文档同空间编码,3072 维,Matryoshka 表征可截断到 768 维而几乎不损精度。它最大的工程价值是消灭多套嵌入流水线——以前要为文本、图像、视频各维护一个 embedding 服务,现在一个就够。
- Mixpeek / Orbifold AI。多模态索引基础设施,从视频中抽取场景、人脸、品牌、对象、语音,按用户自定义 schema 输出,用 Ray 做 PB 级分布式处理。
把这三家的能力放在一起看,结论很清晰:"输入原始视频、输出 AI-Ready 资产"已经从一个工程难题变成一次 API 调用。这才是视频侧"非结构化数据爆发"的真正含义。
四、厂商选型:四种场景驱动的组合
技术原理讲完了,下一步是落到选型。市面上的方案多到让人眼花,但其实按场景反推就很清楚——你不是在选"最好的平台",你是在选"最匹配你场景的组合"。
场景 A:已经在 Lakehouse 上 + 数据治理优先
推荐组合:Databricks 或 Snowflake,外挂 TwelveLabs / Whisper 处理视频音频。
这是金融、医疗、运营商等强治理行业的默认选择。优势是治理与血缘原生、向量索引随表自动同步、数据零搬迁;短板是视频/音频偏弱,需要外挂专用模型。
场景 B:视频/音频是核心资产
推荐组合:TwelveLabs Pegasus 1.5 + Mixpeek + Gemini Embedding 2。
适合媒资、安防、电商直播、教育录播。核心理念是"原始视频一次进入,结构化结果一次产出",不要再自己拼 ASR + 抽帧 + VLM 这种五件套。代价是治理和血缘需要自己补。
场景 C:中国本土 / 数据合规
推荐组合:腾讯云数据智能 + 向量数据库 / 阿里云 PAI + Hologres 向量 / 华为云 ModelArts + GaussDB。
专有云路径成熟,配套通义听悟、读光 OCR、华为 DataArts 这些为国内合规与行业定制的工具,避免数据出境合规问题。这是政企、金融、能源、医疗等强监管行业的现实最优解。
场景 D:低预算 / 快速 PoC
推荐组合:Postgres + pgvector + LLM 元数据抽取。
JSONB 存元数据,vector 列存嵌入,单库搞定向量召回 + 结构化过滤。先验证场景跑得通,再决定是否升级到专业平台。数据量 < 100GB 的内部工具基本不用考虑别的。
一个跨场景的建议:先选嵌入模型,再选向量库
Gemini Embedding 2、Cohere Embed v4、BGE-M3 都已经是商品级(commodity)的统一多模态嵌入底座,可以配合任意向量库使用。不要把自己锁死在某家的"全家桶"里——嵌入模型这一层在 2026 年起会持续演进,底座可换、嵌入模型不可锁死。
完整 12 家方案 × 8 维度的对比表附在文末。
五、ICE 观察:技术契约、团队 KPI、国内机会
技术视角:AI-Ready 是一种新型"数据契约"
对数据工程师来说,过去十年的"数据契约"是 schema:你定义表结构,下游按这个 schema 消费。2026 年的 AI-Ready 资产化,本质上引入了一种新的数据契约:除了 schema,你还要定义 chunking 策略、embedding 模型版本、元数据 JSON Schema、治理标签语义。
这件事的工程意义被严重低估。它意味着 dbt、Airflow、Dagster 这些数据编排工具,未来都要支持"嵌入版本管理"和"元数据 schema 演进"——就像今天的"列演进(schema evolution)"一样。模型升级一次(比如从 BGE-M3 升到下一代),整库要重新嵌入;元数据 schema 变更一次(增加一个抽取字段),历史数据要回填。这些都需要工具链原生支持,而不是手工脚本。
我个人的预测:未来两年最值钱的工程岗位之一,是"AI-Ready 数据架构师"——既懂传统数据建模,又懂 embedding 版本管理、元数据 schema 设计、治理一体化。这个岗位现在还没有标准称呼,但市场需求在 IDC 数据里已经显形了:62% 企业缺这类人。
落地视角:数据团队应该立的 3 个 KPI
如果你在带一个数据团队,今年想真的把"AI-Ready 资产化"落下去,比起讨论"用哪家平台",更该立的是 3 个可量化 KPI:
- AI-Ready 资产覆盖率 = 已变成"向量+元数据+治理标签"的数据 / 全量非结构化数据。这个数字在大多数公司是个位数;目标先做到 30%。
- 元数据召回提升率 = 用元数据过滤后的 RAG 召回精度 / 纯向量 RAG 精度。如果还没拉开 2 倍以上的差距,说明元数据 schema 设计得不够细。
- 嵌入血缘可追溯比例 = 在 Catalog 里登记了"模型名 + 版本 + 维度 + 时间戳"的资产 / 全部资产。这个数字今天接近 0%,但模型升级一次它就决定你是"重新嵌入一次"还是"全库重跑一周"。
这三个 KPI 的好处是完全可观测、可拉时间序列、可绑定到 OKR——它把"AI-Ready"这件抽象的事,变成了团队每周看的看板数据。
本土视角:国内的真正机会在"专有云 + 多模态 + 治理一体化"
IDC 2025 年的中国数据智能生态图谱里,腾讯云、阿里云、华为云都进了代表厂商。从产品形态看,国内厂商比海外有两个差异化优势:第一,专有云路径成熟,可以在客户机房落地,避免出境合规问题;第二,多模态模型 + 治理工具更接地气——通义听悟、读光 OCR、腾讯云数据智能平台、华为 DataArts 都是为国内合规和行业定制的。
国内市场的真正空白,不在向量库本身(这一层产品已经过剩),而在**"专有云 + 多模态 AI-Ready 流水线 + 行业 schema 模板"**这种端到端解决方案。一个能直接给金融客户提供"合同 PDF → 双层元数据 + 多模态向量 + 治理标签 + 国产 GPU"全链路的方案商,未来三年的市场窗口很大。
结论
把上面这一长串收束一下,留给读者三个判断:
- 2026 年的"非结构化数据爆发",爆发的不是数据量,是数据形态——从 PDF/MP4 变成"向量 + 结构化元数据 + 治理标签 + 血缘"的复合资产。
- 新技术范式叫双轨同步生成:用 VLM/LLM 在同一条流水线里同时产出向量和元数据,原子写入。文档侧的代表是 Databricks
ai_parse_document和 Snowflake Cortex AI;视频侧是 TwelveLabs Pegasus 1.5。 - 底座可换、资产模型不可换。先把"向量 + 元数据 + 治理"作为最小数据单元设计好,再选承载它的平台。
别再花时间继续调向量模型和 chunking 参数了。今年最值得投入的工作,是把"双层元数据 + 嵌入血缘"这两件事在你的数据流水线里做实。
你团队当下处理的 PDF、视频、聊天记录,有多少比例真的变成了 AI-Ready 资产?如果答案是 0%,那 IDC 的那句"AI 成败由数据管理能力决定",对你而言就不只是一句预测。
附录:12 家方案横向对比
| 方案 | 类别 | 文档解析 | 视频/音频 | 向量+元数据同步 | 治理/血缘 | 部署形态 | 起步成本 |
|---|---|---|---|---|---|---|---|
| Databricks (Mosaic AI + ai_parse_document) | 一体化 Lakehouse | VLM 解析图表/扫描件 | 需配 Pegasus / Whisper | Delta 自动同步向量索引 | Unity Catalog 原生 | 云托管 | 中-高 |
| Snowflake (Cortex AI Functions) | 一体化 Lakehouse | SQL 内 EXTRACT / SUMMARIZE | 音频较弱 | EMBED_TEXT 列同表 | Horizon 治理 | 云托管 | 中-高 |
| AWS Bedrock + S3 Vectors + Knowledge Bases | 云厂商套件 | Textract + Bedrock VLM | Transcribe + Rekognition | KB 自动 chunk + embed | Lake Formation | 云托管 | 中(按量) |
| Google Vertex AI + Gemini Embedding 2 | 云厂商套件 | Document AI | 原生多模态 embedding | Vector Search 同步 | Dataplex | 云托管 | 中(按量) |
| 腾讯云数据智能平台 + 向量数据库 | 云厂商套件(CN) | OCR + 通用大模型 | 智能视频分析 | 数据湖仓 + 向量库联动 | DataInLong 血缘 | 云托管/专有云 | 中 |
| 阿里云 PAI + Hologres 向量 + 通义 | 云厂商套件(CN) | 通义文档/读光 OCR | 通义听悟 + 视频理解 | PAI 流水线一站式 | DataWorks 治理 | 云托管/专有云 | 中 |
| TwelveLabs Pegasus 1.5 | 视频专用 | — | TBM 时间戳元数据 + 嵌入 | 单 API 同步产出 | 弱(自建) | SaaS API | 低-中 |
| Mixpeek | 多模态索引基建 | PDF/图像 | 场景/人脸/品牌/语音 | Ray 分布式同写 | 命名空间隔离 | SaaS / 自托管 | 中 |
| Orbifold AI | 多模态数据策展 | 文档 → schema | 视频/音频 → schema | 自定义 schema 输出 | 弱(自建) | SaaS API | 中 |
| Vectorize.io | RAG 流水线 SaaS | 强(含双层元数据) | — | 原生双层元数据 + 嵌入 | 弱(依赖向量库) | SaaS | 低 |
| Unstructured.io + LlamaIndex + Milvus | 自建组合栈 | Unstructured 解析 | 需自接 ASR/VLM | 代码层手工编排 | 无(自建 Catalog) | 自托管/云 | 低(人力高) |
| Postgres + pgvector + LLM 元数据抽取 | 自建轻量栈 | DIY | DIY | JSONB + vector 同表 | 无 | 自托管 | 极低 |
参考资料
- IDC. FutureScape 2026: Worldwide AI and Data Predictions. 2026.
- IDC. Worldwide Global DataSphere Structured and Unstructured Data Forecast, 2025–2029. 2025.
- IDC. Office of the CDO Survey 2024(n=848).
- ZL Tech. In 2026, AI Success Will Be Decided by Unstructured Data Management. 2026-02.
- arXiv:2512.05411. A Systematic Framework for Enterprise Knowledge Retrieval: Leveraging LLM-Generated Metadata to Enhance RAG Systems. IEEE CAI 2026.
- TwelveLabs. Pegasus 1.5: Time-Based Metadata Extraction for Long-Form Video. 2026-04.
- Google. Gemini Embedding 2: Native Multimodal Embeddings. 2026-03.
- Databricks Blog. Beyond Text: Extracting Deep Insights from Document Images with Databricks. 2026-02.
- Snowflake. Structuring the Unstructured Data: Powered by Snowflake Cortex AI Functions. 2026.
- 腾讯云开发者社区. 2025 IDC 数据智能与 AI-Ready 数据架构研究报告. 2026-04.