深度调研|拆解 IndustryOR:LLM4OR 的 100 道工业优化试金石

本文是 LLM4OR:当大语言模型遇上运筹优化 的延伸篇,聚焦 LLM4OR Leaderboard 的核心测试集 IndustryOR 的前世今生。
TL;DR
- IndustryOR 是第一个工业级优化建模基准,100 道题来自 8 个行业,覆盖 5 种题型 × 3 级难度
- 题目源自 686 个真实工业案例,经 OR-Instruct 框架扩展和增强,手动挑选 100 道作为测试集
- 11 位专家逐条审查后发现错误率 ≥54%——超过一半的标注有问题
- ORThought 团队独立清洗:移除 17 道、修正 23 道,保留 83 道
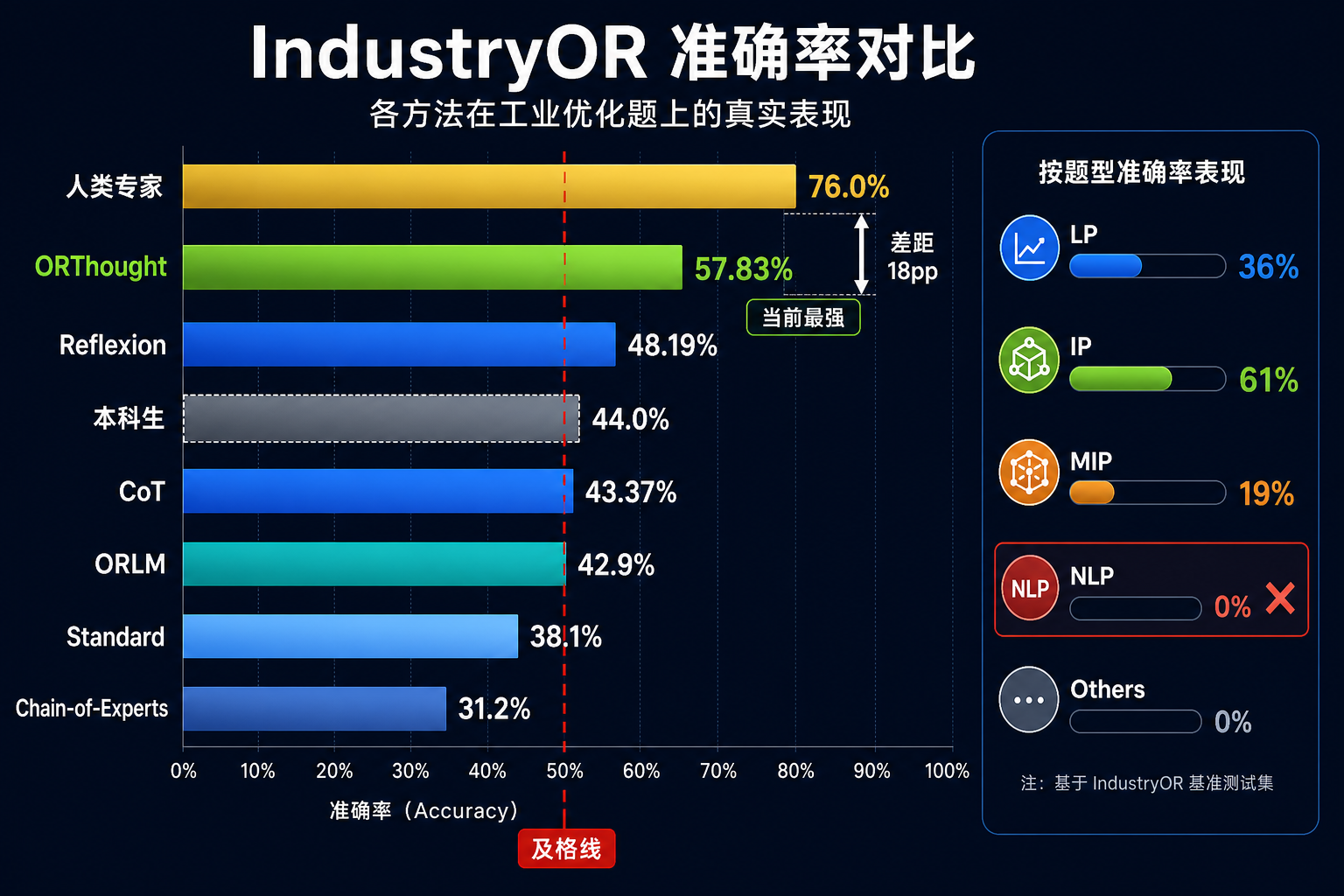
- 清洗后排名:ORLM 42.9%、ORThought 57.83%——最强方法也只做对约一半
- 按题型拆解:NLP(非线性规划)准确率 0%,所有模型全军覆没;LP/IP 基本及格
- 人类专家 76%、本科生 44%——当前最好的 LLM 方法刚刚超过本科生水平
一、为什么要做 IndustryOR
在 IndustryOR 出现之前(2024 年中),LLM4OR 领域只有一类基准可用:学术级的简单题目。
| 已有基准 | 来源 | 问题 |
|---|---|---|
| NL4Opt (NeurIPS 2022) | 竞赛题 | 289 道,几乎全是简单线性规划 |
| MAMO | 教材题 | 652 道 Easy + 211 道 Complex,但仍以 LP 为主 |
| ComplexOR | 学术论文 | 仅 37 道 |
这些基准有三个共同缺陷:
- 题目太简单——复杂度指标均值只有 5-7(变量+约束数),真实工业问题的复杂度是它们的 2-3 倍
- 题型单一——以线性规划为主,缺少混合整数规划、非线性规划等工业常见类型
- 与真实场景脱节——题目来自教材或学术论文,不反映工业问题特有的模糊描述、隐含约束、跨领域知识等挑战
华为 & 杉数科技团队(ORLM 论文作者)因此构建了 IndustryOR:用真实工业案例构建的第一个工业级基准,目的是测试 LLM 在"真正的优化建模"上能走多远。
二、100 道题是怎么来的
2.1 种子数据:686 个真实工业案例
IndustryOR 的起点是团队从运筹学教材和自身工业项目中收集的 686 个真实案例,经过抽象和脱敏处理。这些案例覆盖了运输调度、生产排程、资源分配等典型运筹场景。
2.2 OR-Instruct 框架扩展
团队设计了 OR-Instruct——一个半自动化的数据合成框架,通过两轮迭代将 686 个种子扩展为 32,481 个训练样本:
扩展策略(Expansion):用 GPT-4 生成新场景。先让 GPT-4 列出 100 个运筹优化的应用场景,然后每次从数据池中抽 3 个示例作为 few-shot 参考,在随机选定的场景下生成新题目。
增强策略(Augmentation):对种子数据做三种变换——
| 增强方式 | 做什么 | 解决什么问题 |
|---|---|---|
| 改约束/目标 | 添加、删除或替换约束条件 | 增强环境适应性 |
| 改措辞 | 用不同表述描述同一个优化模型 | 增强语言鲁棒性 |
| 换建模技巧 | 用 Big-M、辅助变量等不同方法建模同一约束 | 增强技巧多样性 |
过滤:每轮迭代后,自动过滤不可执行的程序(约 39% 被淘汰),并去重、排除与测试集重叠的样本。合成数据的准确率约 70-75%。
2.3 从 32K 中挑出 100 道
IndustryOR 的 100 道测试题并非随机抽样,而是从种子数据和工业项目中手动挑选,确保覆盖:
- 8 个行业:教育、交通运输、金融、制造、物流、能源、零售、医疗
- 5 种题型:LP、IP、MIP、NLP、Others
- 3 级难度:Easy (40 道)、Medium (40 道)、Hard (20 道)
三、100 道题长什么样
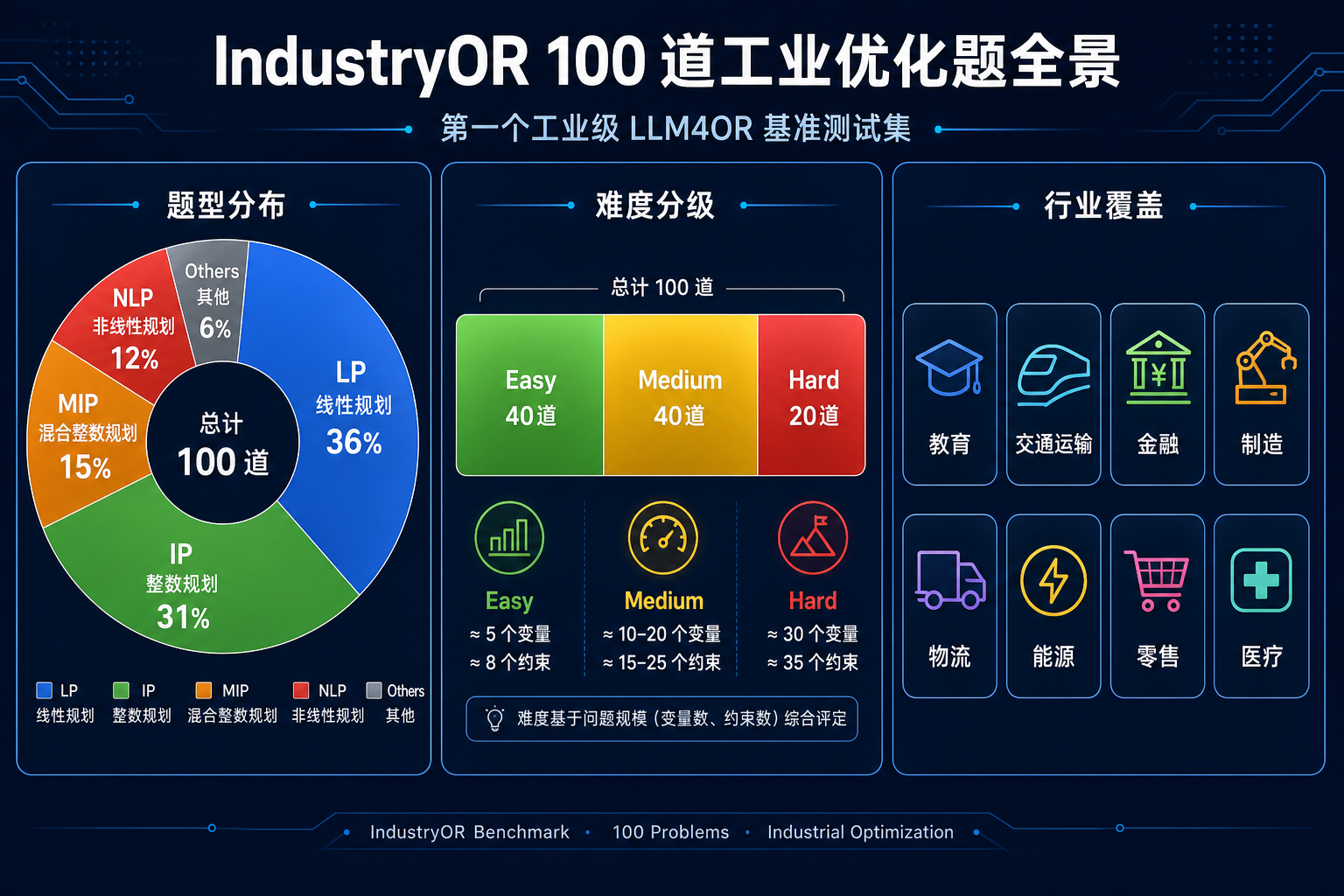
3.1 题型构成
| 类型 | 全称 | 占比 | 典型场景 |
|---|---|---|---|
| IP | 整数规划 | ~31% | 选址、排班、0-1 决策 |
| MIP | 混合整数规划 | ~15% | 生产调度、车辆路径 |
| LP | 线性规划 | ~36% | 资源分配、混合配比 |
| NLP | 非线性规划 | ~12% | 定价优化、非线性工艺控制 |
| Others | 含二次规划、随机规划等 | ~6% | 投资组合、多目标规划 |
3.2 难度分级标准
IndustryOR 的难度不是拍脑袋定的,而是基于 4 个维度综合评估:
| 维度 | Easy | Hard |
|---|---|---|
| 问题规模 | 变量和约束少 | 变量和约束多 |
| 逻辑复杂度 | 线性关系为主 | 含 if-then、互斥、非线性 |
| 语言模糊度 | 描述清晰直接 | 含隐含约束、歧义表述 |
| 跨领域知识 | 不需要 | 需要金融/工程/医学等领域知识 |
统计数据印证了这一点:Easy 题平均约 5 个变量 + 8 个约束,Hard 题平均约 30 个变量 + 35 个约束。
3.3 一道典型的 Easy 题(MIP)
一家公司要运输 25 吨货物,有卡车($100/吨,容量 10 吨)、飞机($120/吨,容量 20 吨)、轮船($130/吨,容量 30 吨)三种方式。约束:卡车和轮船不能同时选用。求最小化总成本的运输方案。
题型:MIP(混合整数规划)——包含 0-1 二元变量(是否选用)和连续变量(运输量)的混合。
建模要点:需要引入 0-1 二元变量表示"是否选用该方式",用容量约束将二元变量和连续变量关联,用互斥约束表达"不能同时选用"。看似简单,但已超出纯 LP 的范畴。
3.4 一道典型的 Hard 题(IP + 逻辑约束)
一家玩具制造商可以生产卡车、飞机、轮船和火车四种玩具,利润分别为 $5/$10/$8/$7。约束:(1) 如果生产卡车就不能生产火车;(2) 如果生产轮船就必须生产飞机;(3) 轮船产量不能超过火车产量。求最大化利润的生产方案。
题型:IP(整数规划)+ 多重逻辑约束——需要引入指示变量处理 if-then 和互斥关系。
建模难点:
- 约束 (1) 是互斥逻辑约束,需要 Big-M 方法或指示变量
- 约束 (2) 是蕴含约束(if P then Q),需要用不等式 x_boat ≤ x_airplane 表达
- 约束 (3) 看似简单,但和约束 (1) 的交互使可行域变得复杂
GPT-4 在这道题上的表现:引入了非线性项,且误解了逻辑关系——答案错误。ORLM 通过 OR-Instruct 训练后学会了使用指示变量和 Big-M 方法,正确求解。
3.5 一道典型的 NLP 题(非线性规划)
一家农业公司希望优化温室内的气候条件,以提高番茄和黄瓜两种作物的产量。需要精确控制温室内的温度 T(°C)、湿度 H(%)和 CO₂ 浓度 C(ppm)。两种作物对这三个环境因素有不同的需求曲线——番茄产量 Y₁ = f₁(T, H, C)、黄瓜产量 Y₂ = f₂(T, H, C) 均为二次函数。约束:温度 15-35°C、湿度 40-90%、CO₂ 300-1200 ppm、总能耗不超过预算。求最大化总产量 Y₁ + Y₂ 的环境参数设置。
题型:NLP(非线性规划)——目标函数是决策变量的二次函数,不能用线性规划求解。
建模难点:
- 产量函数是多元二次函数,包含交叉项(如 T×H)和平方项(如 T²),目标函数非线性
- 能耗约束也可能是非线性的(如制冷/加热功率与温差的非线性关系)
- 需要判断问题凸性——如果产量函数是凹函数,最大化凹函数是凸优化,全局最优可求;否则可能陷入局部最优
- 求解器接口不同:Gurobi 支持二次约束(QCP),但更复杂的非线性需要 IPOPT、BARON 等专用求解器
所有模型在 NLP 上的准确率为 0%——GPT-4 和 ORLM 全军覆没。原因有二:
- 训练数据稀缺:OR-Instruct 的 686 个种子案例中非线性问题占比极低(训练集中 NLP 仅占 5%),GPT-4 扩展出的数据也以 LP/IP 为主
- 固有建模难度:非线性优化需要处理凸/非凸判断、局部最优陷阱、特殊求解器接口——这些远超"翻译自然语言→数学公式"的范畴
四、超半数标注是错的——错在哪、怎么修
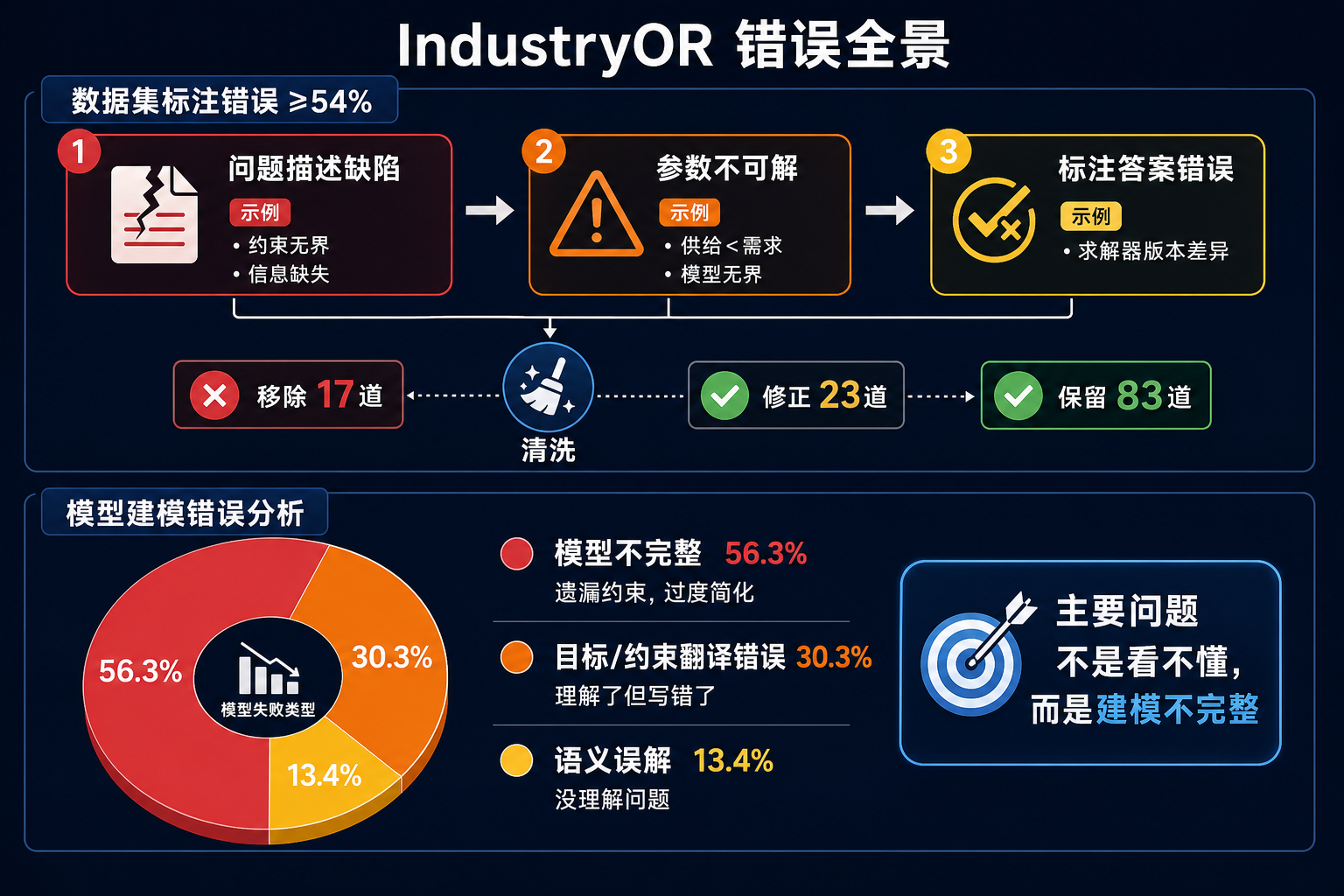
4.1 错误率全景
2025 年,浙大 & 华为团队组织 11 位人工专家对所有主流基准逐条审查,每条错误至少 3 人交叉验证:
| 数据集 | 实例数 | 复杂度 | 错误率 |
|---|---|---|---|
| IndustryOR | 100 | 14.06 | ≥54.0% |
| NL4Opt | 289 | 5.59 | ≥26.4% |
| ComplexLP | 211 | 13.35 | ≥23.7% |
| ComplexOR | 37 | 5.98 | ≥24.3% |
| NLP4LP | 269 | 5.58 | ≥21.7% |
| ReSocratic | 605 | 7.45 | ≥16.0% |
| EasyLP | 652 | 7.12 | ≥8.13% |
IndustryOR 复杂度最高(14.06,是 NL4Opt 的 2.5 倍),错误率也最高。复杂度越高,标注越容易出错——这是结构性问题。
4.2 三类错误
| 类型 | 说明 | 示例 |
|---|---|---|
| 问题描述缺陷 | 约束无界、信息缺失、条件矛盾 | 运输问题未指定车辆容量上限 |
| 参数不可解 | 参数取值导致无可行解或无界 | 供给量 < 需求量的运输问题 |
| 标注答案错误 | 最优值或变量取值有误 | 求解器版本不同导致精度差异 |
4.3 两次独立清洗
第一次:浙大 & 华为 LLM4OR 团队
- 11 位专家交叉验证
- 给错误样本打
error标签 - 提供清洗前后两版数据集下载
- 在清洗版上建立统一 Leaderboard
第二次:浙大 ORThought 团队(独立工作)
- 移除 17 道信息不足的问题
- 修正 23 道标注错误
- 为所有保留题目补充:数学公式 + Gurobi 可执行代码 + 问题特征标签
- 清洗后保留 83 道
两次独立清洗的结论一致:原始 100 道中,至少 40 道存在不同程度的问题。
五、各方法在 IndustryOR 上的表现
5.1 LLM4OR 官方排行榜(100 道,排除错误标签后评测)
统一使用 GPT-4o 作为基座。官方做法是保留全部 100 道题,但给错误样本打 error 标签,评测时排除这些样本:
| 方法 | IndustryOR | 最佳数据集 |
|---|---|---|
| Standard | 38.1% | NLP4LP 73.6% |
| CoT | 40.5% | NLP4LP 74.7% |
| CAFA | 41.1% | NL4Opt 68.1% |
| Chain-of-Experts | 31.2% | EasyLP 94.4% |
| ORLM-LLaMA-3 8B | 42.9% | EasyLP 90.4% |
Chain-of-Experts 在简单题上碾压(EasyLP 94.4%),但在 IndustryOR 上只有 31.2%——多 Agent 框架在简单问题上的优势无法迁移到复杂工业问题,级联错误反而拖后腿。
5.2 ORThought 最新结果(清洗至 83 道后评测)
ORThought 团队采取了更激进的清洗策略:直接移除 17 道信息不足的问题、修正 23 道标注错误,在剩余的 83 道上使用 GPT-4.1-nano 评测:
| 方法 | IndustryOR (83) | 比 Standard 提升 |
|---|---|---|
| Standard | 42.17% | — |
| ORLM-LLaMA-3 8B | 32.13% | ↓10.04 |
| CoE | 40.96% | ↓1.21 |
| CoT | 43.37% | ↑1.20 |
| Reflexion | 48.19% | ↑6.02 |
| ORThought | 57.83% | ↑15.66 |
ORLM 在更强的 GPT-4.1-nano 基座面前反而更差了(↓10 pp)——8B 微调模型的能力上限已被新一代基座模型超越,微调的投入产出比在快速下降。
5.3 按难度和题型拆解
ORLM 论文在原始 100 道(清洗前)上报告了按难度和题型的详细数据:
| Easy (40) | Medium (40) | Hard (20) | |
|---|---|---|---|
| GPT-4 | 45.0% | 17.5% | 15.0% |
| ORLM | 57.5% | 20.0% | 35.0% |
| LP | IP | MIP | NLP | Others | |
|---|---|---|---|---|---|
| GPT-4 | 33.3% | 38.7% | 12.9% | 0% | 0% |
| ORLM | 36.1% | 61.2% | 19.3% | 0% | 0% |
五个关键发现:
- Easy ≠ 做得对:最简单的题也只有 57.5%
- Medium 断崖式下跌:从 Easy 到 Medium,GPT-4 准确率从 45% 掉到 17.5%
- Hard 题 ORLM 反超:35% vs 15%——微调在困难问题上的提升最显著
- NLP 和 Others 全零:所有模型对非线性优化和特殊类型完全无能为力
- IP 是 ORLM 的强项:61.2%——OR-Instruct 训练数据中 IP 占比最高(30%),训练分布直接决定了表现
5.4 对比人类
| 评测者 | IndustryOR |
|---|---|
| 本科高年级学生 (平均) | 44.0% |
| 领域专家 (平均) | 76.0% |
| ORLM-LLaMA-3 8B | 38.0% |
| ORThought (GPT-4.1-nano) | 57.83% |
当前最强方法(ORThought)刚刚超过本科生水平,距离专家还有 18 个百分点。而且专家面对的是原始 100 道(含错误标注),他们的 76% 是在"题目可能有坑"的情况下取得的。
5.5 错误长什么样
ORLM 团队对 100 个失败案例的手动分析:
| 错误类型 | 占比 | 说明 |
|---|---|---|
| 模型不完整 | 56.3% | 遗漏约束或隐含条件,将复杂问题过度简化 |
| 目标/约束翻译错误 | 30.3% | 理解了要求,但数学表达写错了 |
| 语义误解 | 13.4% | 根本没理解问题在问什么 |
最主要的问题不是"看不懂题",而是**"看懂了但建模不完整"**——8B 模型的表达和学习能力不够,倾向于输出过度简化的模型。ORThought 的错误分析也印证了这一点:约束建模是最容易出错的环节,LLM 更倾向于"建错"而不是"漏掉"。
六、跨模型和跨方法的全景对比
6.1 不同基座模型的影响
ORThought 团队测试了三个基座模型(全数据集汇总):
| 方法 | GPT-4.1-nano | DeepSeek-V3 | Qwen3-32B |
|---|---|---|---|
| Standard | 58.35% | 58.75% | 64.55% |
| ORThought | 74.25% | 71.01% | 73.38% |
| 提升 | +15.90 | +12.26 | +8.83 |
两个结论:
- 好的推理框架可以弥补模型差距:ORThought 将三个模型的差异从 6+ pp 压缩到 3 pp 以内
- 推理模型(o3/R1)提升有限:ORThought 对 GPT-o3 和 DeepSeek-R1 只提升约 3 pp——这些模型的内置推理能力已经覆盖了 ORThought 的引导策略
6.2 问题规模的普遍性衰减
| 方法 | Toy (<5 变量) | Small | Medium |
|---|---|---|---|
| Standard | 68.93% | 36.66% | 26.42% |
| ORThought | 85.39% | 49.59% | 43.40% |
从 Toy 到 Medium,所有方法的准确率都腰斩。这不是某个方法的问题,而是 LLM 建模能力的系统性瓶颈。
6.3 评测方法本身的陷阱
以上所有结果都基于"目标值评测"——只比较最优值是否一致。但这种方法有盲区:
- 假阳性:两个结构完全不同的模型可能恰好产生相同目标值("答案对了但模型错了")
- 假阴性:数学等价但形式不同的模型被判错(
x + y ≤ 10vsy ≤ 10 - x)
更可靠的替代方案是 ORGEval 的图同构评测——将模型表示为图结构,用 Weisfeiler-Lehman 检测判断等价性,在随机参数下保持 100% 一致性。
七、总结:100 道题告诉我们什么
IndustryOR 这 100 道题暴露了 LLM4OR 的真实水位线:
| 维度 | 现状 | 说明 |
|---|---|---|
| 整体能力 | ~42-58% | 最强方法也只做对约一半 |
| 简单问题 | ~60-85% | LP/IP 基本可用 |
| 复杂问题 | ~15-35% | MIP/Hard 题远未及格 |
| 非线性问题 | 0% | 完全超出当前能力边界 |
| vs 人类专家 | 差 18+ pp | 远未达到专家水平 |
| 数据质量 | ≥54% 错误 | 基准本身就不可靠 |
三个值得关注的方向:
- NLP/MIP 建模能力——当前的零分区和低分区,是最大的提升空间
- 训练数据质量 > 数量——OR-Instruct 的 32K 数据准确率只有 70-75%,清洗后的小数据可能比大量含噪数据更有效
- 微调 vs 推理框架的此消彼长——随着基座模型快速进化,8B 微调模型的优势窗口在缩短;好的推理框架(如 ORThought)是更持久的投资
参考资料
- Huang, Z. et al. (华为 & 杉数). "ORLM: Training LLMs for Optimization Modeling." arXiv:2405.17743, 2024.
- Xiao, Z. et al. (浙大 & 华为). "A Survey of Optimization Modeling Meets LLMs." arXiv:2508.10047, 2025.
- Yang, B. et al. (浙大). "ORThought: Automated Optimization Modeling through Expert-Guided LLM Reasoning." arXiv:2508.14410, 2025.
- Wang, Z. et al. "ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling." arXiv:2510.27610, 2025.
- LLM4OR Portal. https://llm4or.github.io/LLM4OR
- IndustryOR Dataset. https://huggingface.co/datasets/CardinalOperations/IndustryOR
- LogiOR Dataset. https://huggingface.co/datasets/LabMem012/LogiOR