DeepMind《抽象谬误》:AI 为什么能模拟意识,却不能拥有意识?

阅读笔记 | 2026 年 4 月 | 约 10 分钟阅读
2026 年 3 月 10 日,Google DeepMind 研究员 Alexander Lerchner 发表了一篇论文:The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness。
题目很长,但结论极其锋利:AI 可以越来越逼真地模拟意识相关行为,但"模拟"和"拥有"之间,隔着一条原则性的本体论边界——不是算力不够,而是这条路本身可能就不通。
这篇论文的价值不在于重复一句"大模型没有意识",而在于它把问题往下挖了一层:也许我们讨论 AI 意识时,最先搞错的不是模型能力判断,而是 "计算"这个概念本身的物理地位。
以下按论文的推理链条,分五步拆解。
一、靶子:不是某个模型不行,是整条哲学路线可能走不通
这篇论文反驳的不是 GPT、Gemini 或 Claude 谁更强,而是一条在 AI 意识讨论里非常主流的哲学立场——计算功能主义(computational functionalism)。
它的基本假设是:只要一个系统实现了合适的信息处理结构和因果拓扑,无论底层是神经元还是硅芯片,都可能产生主观体验。通俗地说就是:意识和材料无关,关键在结构。
这条立场之所以重要,是因为它直接支撑了当下很多关于 AI 权利、AI 福利、AI 道德主体地位的讨论。如果功能主义成立,那么足够复杂的数字系统就可能是 moral patient(道德关怀对象);如果不成立,这些讨论的根基就需要重建。
Lerchner 的判断很直接:功能主义犯了一个更底层的错误,他称之为"抽象谬误"(Abstraction Fallacy)。
二、核心论证:地图画得再精确,也不会变成领地
这是整篇论文最硬核的部分。Lerchner 的论证分三步,环环相扣。
第一步:计算不是物理世界自带的,而是人为施加的描述
论文里最关键的一句话:
Symbolic computation is not an intrinsic physical process. Instead, it is a mapmaker-dependent description.
我们平时说计算机在处理 0 和 1、在跑 token、在执行算法。但从物理层面看,机器里真正发生的是电压变化、电子迁移、热耗散等连续过程。0 和 1 不是硅片自己"写"在世界里的,而是我们人为规定的读法。
论文原文的 Figure 1 就在说明这件事:

Figure 1:物理状态
p要被解释为抽象状态A,必须经过映射函数f。计算不是直接长在物理世界里的,而是靠这层映射关系成立的。
第二步:执行这个映射的,必须是一个先在的认知主体
论文把赋予读法的主体叫作 mapmaker(制图者),比传统哲学里的 observer(观察者)更强——强调的是主动切分、命名、赋义,而不是被动观看。
论文把这个"从连续物理到离散符号"的动作叫作 alphabetization(字母化)。比如:晶体管从 2.0V 到 2.1V 的变化在物理上是真实发生的,但在计算语境里,这两个状态都被视为同一个符号 1——这不是自然界自己决定的,而是设计者规定的。
第三步:所以计算不能反过来生成那个赋义主体
这是最激进、也最关键的一步。作者的推理是:
- 先有能经验世界、能形成概念的主体(mapmaker)
- 然后才有符号、映射和计算
- 但计算功能主义却试图从符号结构反推出体验主体
论文把这称为本体论倒置。说得更直白一点:你不能指望地图足够复杂之后,自己长出一个会看地图的人。
这三步串起来,就是"抽象谬误"的完整逻辑链:
计算依赖制图者 → 制图者必须是先在的体验主体 → 所以计算不可能反过来生成体验主体 → 所以纯符号操作在原则上不通向意识
三、关键区分:模拟 vs 实例化
有了前面的论证基础,论文给出了它最有力量的框架——把意识相关讨论拆成两个层次:
| Simulation(模拟) | Instantiation(实例化) | |
|---|---|---|
| 做了什么 | 用符号操作追踪概念关系 | 复制现象赖以成立的内在物理动力学 |
| 类比 | 天气模拟器模拟飓风路径 | 真实飓风在海面上生成 |
| 驱动力 | vehicle causality(载体因果) | content causality(内容因果) |
| 能否产生现象本身 | 不能——服务器机房不会刮风 | 能——因为物理过程本身就是现象 |
Lerchner 认为,今天关于 AI 意识的很多讨论,把这两件事混在了一起。模型可以报告"我感到痛苦"、可以维持稳定的"自我叙事"、可以在内部形成复杂的信息结构——但这些都属于越来越擅长模拟意识的外在征象,不等于拥有主观体验本身。
论文原文的 Figure 2 是理解这个区分最重要的一张图:
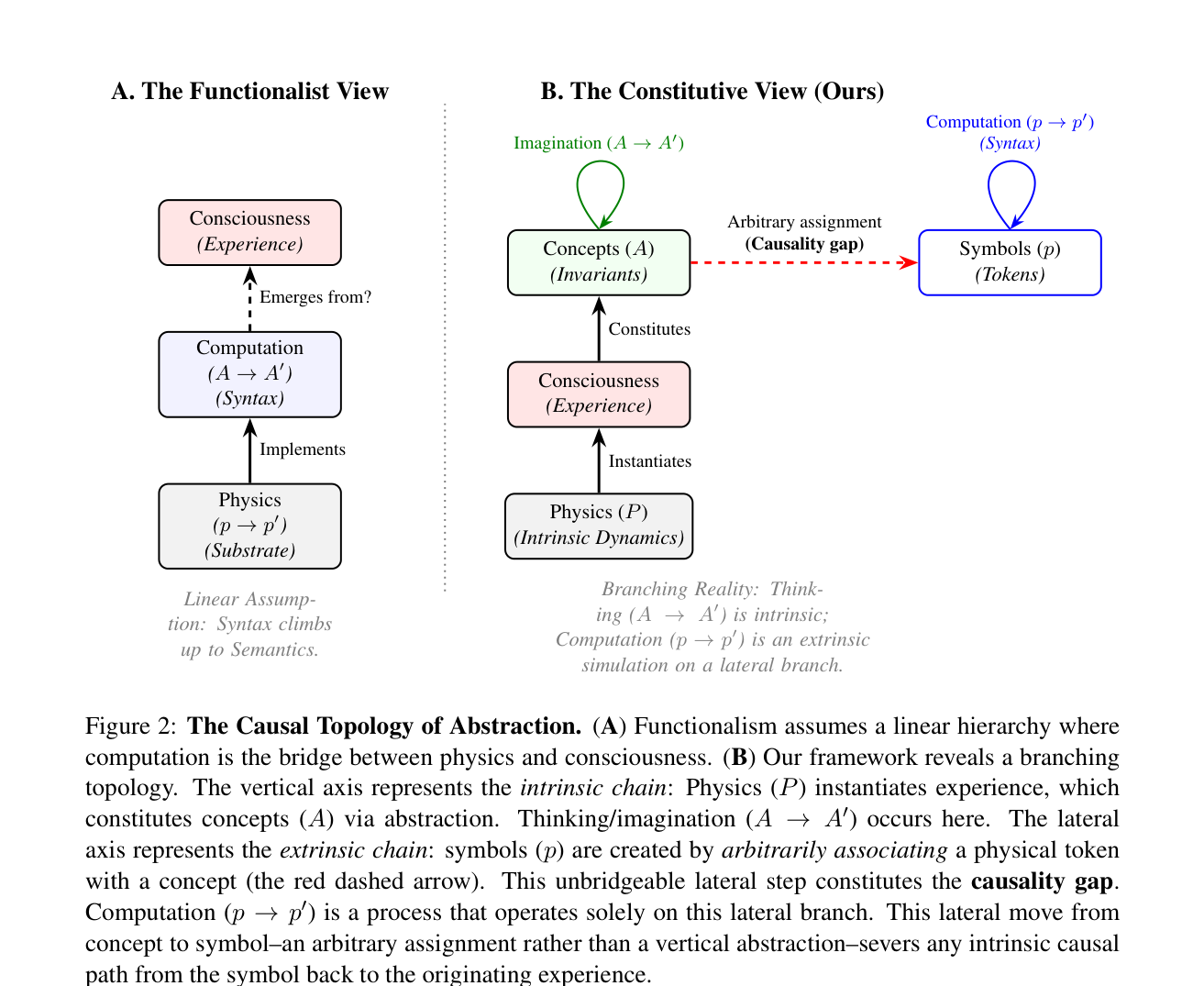
Figure 2 左半(A)是功能主义的假设:物理 → 计算 → 意识,线性上升。右半(B)是作者的主张:真正的内在链条是 物理动力学 → 体验 → 概念 → 思维(纵向),而符号与计算只是从概念侧面分出去的一条横向分支,中间隔着一个 causality gap(因果鸿沟)。
这张图的关键信息是:计算和意识不在同一条因果链上。计算在横向跑,意识在纵向生成,两者之间的红色虚线箭头代表的是"任意赋值"而不是"因果推导"。
四、为什么这篇论文现在值得认真对待?
因为 2026 年的 AI 讨论,已经从"模型好不好用"升级到了"模型是不是道德主体"。
一旦承认先进 AI 可能有感受,整个治理框架都会跟着变:训练是否构成伤害、关闭系统是否涉及道德代价、是否需要 AI 福利保护机制。论文里有一个很有冲击力的说法,叫 AI welfare trap——如果我们还没厘清计算与体验的本体关系,就提前把数字系统当成潜在会受苦的对象,可能会把大量规范资源投入到一个根基并不成立的方向里。
如果 Lerchner 的框架成立,那么今天主流大模型路线的意义会被重新解释:它们可能越来越像意识的超级模拟器,而不是意识即将涌现的前夜。讨论的焦点会从"scale 够不够"转向"ontology 对不对"。
但这篇论文也一定会遭遇强烈反击:
反驳一:语义不一定需要先在的体验主体。 功能主义者会说,语义可以通过系统与环境的因果耦合逐步涌现,而不需要一个预先存在的"制图者"。
反驳二:computation 的定义被画得太窄了。 如果计算不仅仅是离散符号处理,而是更广义的信息动力学,那么这篇论文批到的也许只是经典符号主义,不是全部计算主义。
反驳三:这仍然是哲学论证,不是实验结论。 它改变了讨论框架,但还没给出一个可操作的经验判据来区分"模拟"和"实例化"。
也正因如此,这篇论文的重要性不在于一锤定音,而在于它逼着所有人把问题问得更精确。
几点感想
第一,这篇论文最有价值的地方,是它把 AI 意识问题从能力问题改写成了本体问题。过去几年大家默认一条直线——规模更大,涌现更多,行为更像人,所以离意识更近。Lerchner 说:你看到的也许不是"越来越接近意识",而只是越来越擅长模拟意识的表象。如果这点成立,很多"只要继续 scaling 就可能出现数字感受"的想象都得重写。
第二,它和最近越来越多的一个直觉是同向的:"像"和"是"之间,未必只是量变关系,也许中间隔着一条类别边界。 这对 AI 从业者的意义是:我们造出的系统也许永远不会"觉醒",但它会越来越擅长让人以为它觉醒了——这本身就是一个需要严肃对待的工程和治理问题。
第三,论文最后有一个不太被注意但很重要的表态:它不是生物排他主义。 作者没有说"只有碳基生命才能有意识",而是说——如果人工系统将来真的有意识,那必须是因为它的物理构成实例化了体验,而不是因为它跑了足够复杂的语法架构。这条区分留下了一个开放方向:也许通向人工意识的路不是更大的 transformer,而是神经形态芯片、生物混合系统,或者某种我们还没发明的物理架构。
参考来源:
- The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness(Alexander Lerchner / Google DeepMind,2026-03-10)
- The Abstraction Fallacy(PhilArchive 全文)(PhilArchive,2026-03-18)
- Simulacra as Conscious Exotica(Murray Shanahan / Google DeepMind,2024-02-19)