论文解读|Interleaved Head Attention:打破注意力头的「信息孤岛」
论文信息
- 标题:Interleaved Head Attention
- 作者:Sai Surya Duvvuri, Chanakya Ekbote, Rachit Bansal, Rishabh Tiwari, Devvrit Khatri, David Brandfonbrener, Paul Liang, Inderjit Dhillon, Manzil Zaheer
- 机构:Meta FAIR / UT Austin / UC Berkeley / Harvard / MIT
- 发表时间:2026 年 2 月 | arXiv: 2602.21371
TL;DR
大模型回答"《霍比特人》的作者出生在哪?"这类问题时,需要先找到"作者是托尔金",再找到"托尔金出生于南非"——这是一个两步推理。但 Transformer 的核心组件——多头注意力(MHA)有一个根本缺陷:每个注意力头只能学一种关注模式。一个头要么学"找作者",要么学"找出生地",没法在一个头里完成两步。想处理 k 步推理?就得堆 k 个头,成本线性增长。
本文提出的 Interleaved Head Attention(IHA,交错头注意力) 解决了这个问题。核心做法是:在计算注意力之前,先把所有头的 Q、K、V 互相混合,生成一组"伪头"。由于伪 Query 和伪 Key 来自不同头的混搭,它们的交叉组合能在一个头内产生多种关注模式——P 个伪头可以组合出 P² 种模式,而不是原来的 1 种。举个例子:要同时处理 9 种不同步数的推理链,MHA 需要 9 个头各管一种;而 IHA 只需要 3 个头——因为 3 个伪 Query × 3 个伪 Key 交叉组合,恰好产生 9 种模式,一一覆盖。整个过程只加了很少的参数,而且完全兼容 FlashAttention,不需要改底层 CUDA 代码。
实测效果(2.4B 模型,FLOP 对齐对比):在 RULER 长上下文基准的 Multi-Key Retrieval(从长文本中同时找到多个散布的关键值)任务上,准确率提升 10-20%(4K-16K 上下文);在 GSM8K 小学数学推理上,多数投票准确率提升 5.8%。
一、问题:MHA 的「头间隔离」瓶颈
Multi-Head Attention(MHA)是当代大模型的核心计算原语。但它有一个常被忽略的根本性限制:
H 个注意力头 → 恰好 H 个独立的注意力矩阵,头间零通信。
一个具体的例子
为了理解这个限制为什么重要,先看一个简单的多步推理问题:
"《霍比特人》的作者出生在哪里?"
上下文中散布着若干事实:
- 事实 ①:"J.R.R. 托尔金写了《霍比特人》"
- 事实 ②:"J.R.R. 托尔金出生于南非"
模型需要做两步:
- 第一步:从"《霍比特人》"关注到事实 ①,找到"托尔金"(这是一个直接关联)
- 第二步:从"托尔金"关注到事实 ②,找到"南非"(这是在第一步结果上的二次关联)
现在问题来了:在 MHA 中,每个注意力头只有一个 Query-Key 点积矩阵,它只能学习一种 attention pattern——要么学"作品→作者"的关系,要么学"人物→出生地"的关系,不能在一个头内同时做两步。
那要同时完成两步怎么办?只能用两个不同的头,各负责一步。如果推理链更长(三步、四步...),就需要更多的头。
把直觉形式化:多项式图滤波器
论文用多项式图滤波器(Polynomial Graph Filters)精确刻画了这个问题。
把上面的例子抽象成一张图:每条事实是一个节点,两条事实如果共享实体(比如都提到"托尔金")就连一条边,邻接矩阵记为 A。那么:
- AX(一跳聚合)= 每个节点收集直接邻居的信息 → 对应一步推理("霍比特人"找到"托尔金")
- A²X(两跳聚合)= 信息再传播一轮 → 对应两步推理("霍比特人"经由"托尔金"找到"南非")
- A^{k-1}X(k-1 跳聚合)→ 对应 k-1 步推理
要让模型在单层注意力中同时捕获 1 跳、2 跳、...、k-1 跳的信息(即同时处理不同长度的推理链),就需要并行计算 [X, AX, A²X, ..., A^{k-1}X]。
而 MHA 的瓶颈在于:一个注意力头只能实现一个矩阵幂 A^i——因为每个头只有一对 Q/K 投影,只能产生一个 attention 矩阵,对应一种固定的跳数。要表示从 A⁰ 到 A^{k-1} 共 k 种不同幂次,就必须用 k 个独立的头。
定理 1:用单层线性 MHA 表示 k 阶多项式滤波器,至少需要 k 个注意力头,参数复杂度为 Θ(kn²)。
回到霍比特人的例子:如果上下文中同时存在需要 1 步、2 步、3 步才能回答的问题,MHA 至少需要 3 个头分别处理——参数需求随推理步数线性增长。
二、IHA:让注意力头「交叉对话」
2.1 核心思想
MHA 的根源问题在于:每个头的 Query 只能与自己的 Key 交互,产生一种 attention pattern。那如果允许一个头的 Query 与其他头的 Key 也交互呢?
这正是 IHA 的做法:在注意力计算之前引入跨头混合(cross-head mixing),为每个头构建 P 个"伪头"(pseudo-heads),每个伪头的 Q/K/V 都是所有 H 个原始头的 Q/K/V 的学习线性组合。
回到霍比特人的例子:假设头 1 学到了"作品→作者"的 Q/K 投影,头 2 学到了"人物→出生地"的 Q/K 投影。在 MHA 中,它们各干各的。但在 IHA 中,一个伪头可以把头 1 的 Query 和头 2 的 Key 混合在一起,从而在单个伪头内实现两步推理的组合——"作品→作者→出生地"。P 个伪 Query × P 个伪 Key = P² 种组合,一个头就能覆盖多种推理链。
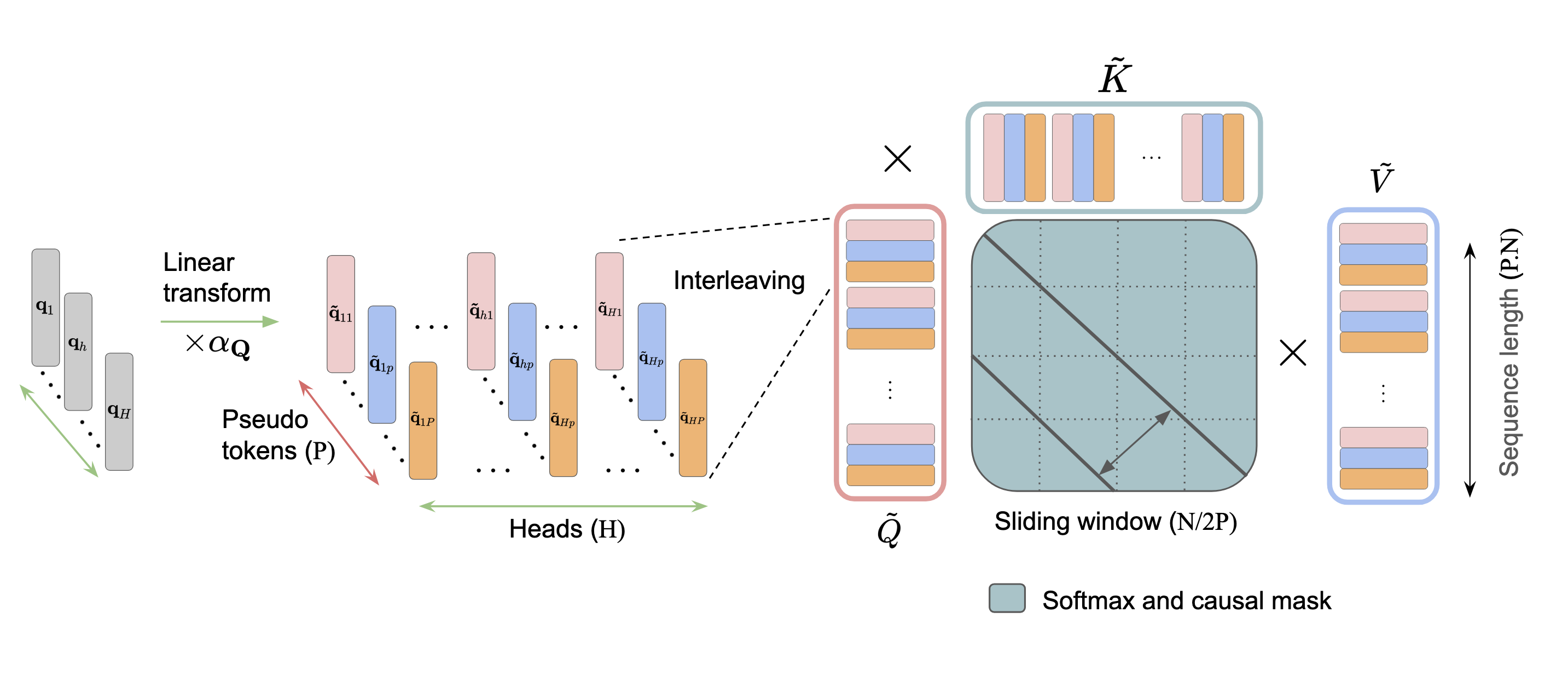
图 1:IHA 架构。首先通过可学习的线性变换(×α_Q)在头轴(绿色)上为每个头生成 P 个伪 token,然后交错排列形成长度为 P·N 的扩展序列,最后在扩展序列上执行标准因果自注意力(使用滑动窗口控制计算复杂度)。
2.2 算法六步走
Step 1:标准投影 — 和 MHA 一样,将输入 X 通过 W_Q, W_K, W_V 投影得到 Q, K, V,形状 [N, H, d]。
Step 2:伪头混合(核心创新) — 为每个头 h 构建 P 个伪头。以 Query 为例:
其中 α^Q ∈ R^{H×H×P} 是可学习的混合权重。K、V 同理。通常设 P = H。
直觉上,每个伪 Query 不再只"看"自己头的 Key,而是看到了所有头的 Key 的混合版本。
Step 3:交错排列(Interleave) — 将伪头维度合并到序列维度,形成长度为 N·P 的扩展序列:
(token₁, pseudo₁), (token₁, pseudo₂), ..., (token₁, pseudo_P),
(token₂, pseudo₁), ..., (token_N, pseudo_P)这种交错设计与 RoPE 天然兼容——每个伪头 token 获得独立的位置编码相位。
Step 4:标准注意力 — 在扩展后的序列上执行标准 scaled dot-product attention。
这是 IHA 的关键工程优势:完全兼容 FlashAttention——不像 Talking Heads 那样需要在 softmax 前后加额外的线性层。
Step 5-6:拆分与折叠 — 将输出 reshape 回来,通过可学习的折叠矩阵 R ∈ R^{H×P} 合并伪头结果,拼接所有头并通过输出投影。
2.3 为什么是「二次扩展」?
这是 IHA 最重要的数学洞察:
| MHA | IHA | |
|---|---|---|
| 每头注意力模式数 | 1 | P² |
| H 个头总共 | H | H·P² |
| 表示 k 种模式需要的头数 | Θ(k) | Θ(√k) |
原因:P 个伪 Query 与 P 个伪 Key 之间形成 P×P 的交叉交互矩阵,每个组合 (伪Q_i, 伪K_j) 对应一种独立的注意力模式。
打个比方:MHA 就像你有 H 把钥匙和 H 把锁,每把钥匙只能开自己的锁,H 把钥匙开 H 把锁。IHA 则是把这些钥匙和锁"混搭"出 P 把新钥匙和 P 把新锁——任意一把新钥匙都可以尝试任意一把新锁,P×P = P² 种开锁方式。所以表达 k 种模式,MHA 需要 k 个头,IHA 只需要 √k 个。
三、理论保证
3.1 严格泛化 MHA
定理 2(IHA 超集性质):对于任意 P ≥ 2,MHA 可表示的函数类是 IHA 的严格子集。
M ⊊ P_P
额外参数开销仅为 4H²P(3H²P 来自 α^Q, α^K, α^V 混合权重 + H²P 来自折叠矩阵 R),相对于模型总参数量微不足道。
为什么是严格超集? 论文用了一个精妙的构造性证明:在"所有 token 相同"的特殊输入上,MHA 的每个头的 attention score 矩阵各行完全相同(因为所有 Q、K 都一样),softmax 后变成均匀分布,因此输出必然是输入的线性函数。但 IHA 可以通过设置正负伪头(α = +1 和 α = -1),使 softmax 矩阵出现非均匀的结构,从而产生输入的非线性函数。
3.2 多项式滤波器效率
表示 k 阶多项式图滤波器所需资源:
| 参数量 | 头数 | |
|---|---|---|
| MHA | Θ(k·n²) | k |
| IHA | Θ(√k·n²) | ⌈√k⌉ |
参数效率提升了 √k 倍。
直觉:假设需要实现 9 种推理步数(k=9),MHA 需要 9 个头,每个头专门负责一种(A⁰, A¹, ..., A⁸)。而 IHA 只需要 3 个头(⌈√9⌉ = 3),因为它能把每个步数 t 分解为两个因子的乘积:
| 步数 t | 分解为 (h, j) | 伪Q 用 A^ | 伪K 用 A^ | 乘积 = A^t |
|---|---|---|---|---|
| 0 | (1,1) | A⁰ | A⁰ | A⁰ |
| 1 | (1,2) | A⁰ | A¹ | A¹ |
| 2 | (1,3) | A⁰ | A² | A² |
| 3 | (2,1) | A³ | A⁰ | A³ |
| ... | ... | ... | ... | ... |
| 8 | (3,3) | A⁶ | A² | A⁸ |
3 个 Query 基底 × 3 个 Key 基底 = 9 种组合,恰好覆盖所有 9 种推理步数。这就是"二次扩展"在多项式滤波器上的具体体现:用 √k 个基底的交叉组合替代 k 个独立的头。
3.3 CPM-3 任务(有序计数匹配)
对于需要处理所有有序 token 对的 CPM-3 任务:
| 所需头数 | 注意力计算量 | |
|---|---|---|
| MHA | N_max | Θ(N³_max) |
| IHA | ⌈√N_max⌉ | Θ(N^{2.5}_max) |
头数从 N_max 降到 √N_max,背后的原理与多项式滤波器相同——分解乘法结构。
四、实验结果
所有实验基于 2.4B 参数的 decoder-only Transformer,在 128 张 H200 GPU 上训练 240B tokens,严格 FLOP 匹配对比。
4.1 长上下文检索
在 64K 上下文窗口下微调后,用 RULER 基准评测:
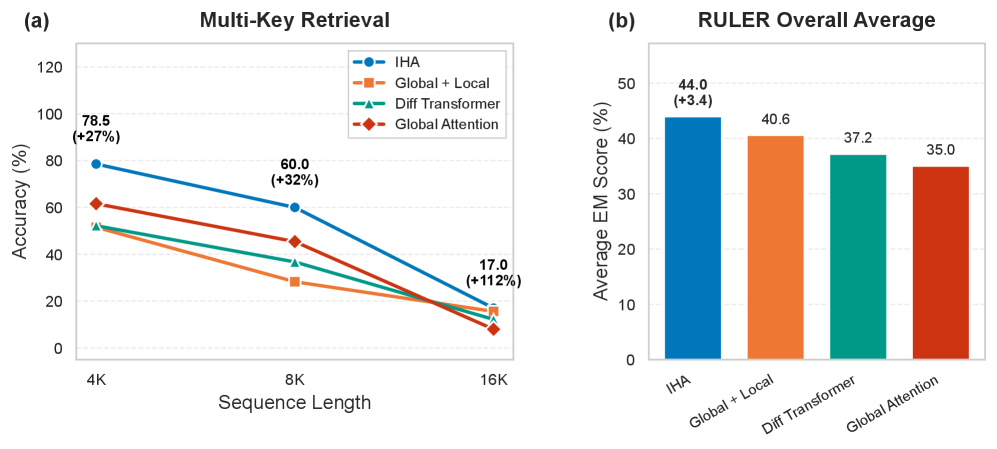
图 2:(a) Multi-Key Retrieval 准确率,橙色标注 IHA 相对提升;(b) RULER 整体精确匹配得分。
IHA 在 Multi-Key Retrieval 任务上的提升非常显著:
| 上下文长度 | IHA 相对 Global Attention 提升 |
|---|---|
| 4K | +27% |
| 8K | +32% |
| 16K | +112% |
RULER 整体精确匹配得分:IHA 44.0% vs Global+Local 40.6% vs Diff Transformer 37.2% vs Global Attention 35.0%。
这个结果非常有说服力——上下文越长,IHA 的优势越大。Multi-Key Retrieval 需要从上下文中同时定位多个散布的关键信息并聚合,恰好是 IHA 的跨头混合最擅长的场景。
4.2 推理评估
预训练模型(5-shot)
| 模型 | GSM8K EM | GSM8K Maj@5 | MATH-500 EM | MBPP P@1 | HumanEval P@1 | 平均排名↓ |
|---|---|---|---|---|---|---|
| IHA | 8.34% (+2.73) | 8.42% (+2.81) | 3.54% (+0.66) | 24.5% (+1.1) | 17.1% (–0.1) | 1.4 |
| Global Attention | 5.61% | 5.61% | 2.88% | 23.4% | 17.2% | 2.9 |
| Global+Local | 6.82% (+1.21) | 6.90% (+1.29) | 2.26% (–0.62) | 23.6% (+0.2) | 16.0% (–1.2) | 2.9 |
| Talking Heads | 5.46% (–0.15) | 5.38% (–0.23) | – | 23.8% (+0.4) | 16.0% (–1.2) | 4.0 |
| Diff Transformer | 5.46% (–0.15) | 5.61% (±0) | – | 25.0% (+1.6) | 15.4% (–1.8) | 3.5 |
表 1:预训练模型 5-shot 评测。IHA 在推理指标上一致领先,平均排名最优。
IHA 在数学推理任务上已经展现了优势——GSM8K 提升近 50%,而这还只是预训练阶段。
SFT 后(OpenThoughts 微调)
| 模型 | GSM8K P@1 | GSM8K Maj@16 | MATH-500 P@1 | MATH-500 Maj@16 | MBPP P@1 | MBPP P@10 | 平均排名↓ |
|---|---|---|---|---|---|---|---|
| IHA | 34.3% (+4.8) | 54.2% (+5.8) | 10.0% (+1.2) | 18.4% (+2.8) | 15.5% (+0.8) | 41.6% (+0.4) | 1.5 |
| Global Attention | 29.5% | 48.4% | 8.8% | 15.6% | 14.7% | 41.2% | 3.8 |
| Global+Local | 26.5% (–3.0) | 46.9% (–1.5) | 7.6% (–1.2) | 15.0% (–0.6) | 15.0% (+0.3) | 41.9% (+0.7) | 4.3 |
| Talking Heads | 29.3% (–0.2) | 49.4% (+1.0) | 7.8% (–1.0) | 18.2% (+2.6) | 15.9% (+1.2) | 43.1% (+1.9) | 2.5 |
| Diff Transformer | 31.6% (+2.1) | 53.5% (+5.1) | 9.0% (+0.2) | 18.0% (+2.4) | 15.3% (+0.6) | 39.2% (–2.0) | 2.8 |
表 2:OpenThoughts SFT 后评测。IHA 在所有推理指标上排名第一。
SFT 后 IHA 的优势进一步放大:GSM8K Maj@16 达到 54.2%(+5.8%),MATH-500 Maj@16 达到 18.4%(+2.8%)。
4.3 合成推理任务
前面的理论分析预测了:IHA 在需要组合多步关系的任务上应该表现更好。论文用 Binary / Ternary Relation Composition 合成任务直接验证了这一点。
这些任务要求模型给定两个(或三个)关系表,把它们组合起来——本质上就是"A→B"+"B→C"="A→C" 的多步关系链接,与霍比特人例子中的推理结构完全一致,只是规模更大、更受控。
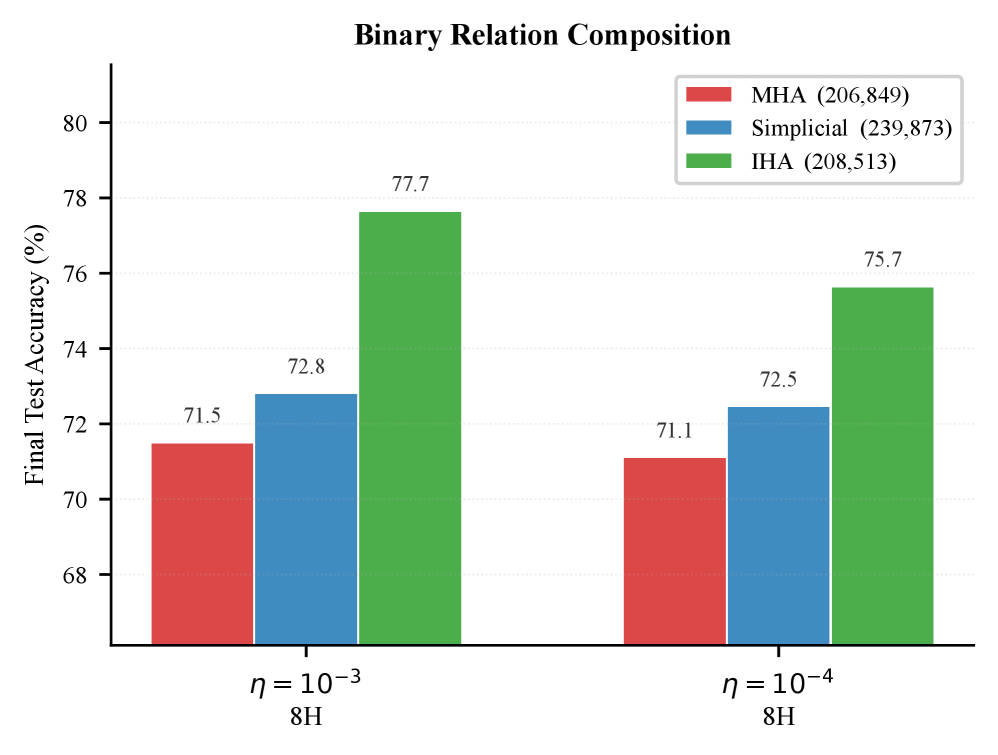
图 3:二元关系组合(两步推理)。IHA(绿色)在相近参数量下(208K vs MHA 的 207K)大幅领先,测试准确率 77.7% vs MHA 71.5%(η=10⁻³),提升 6.2 个百分点。
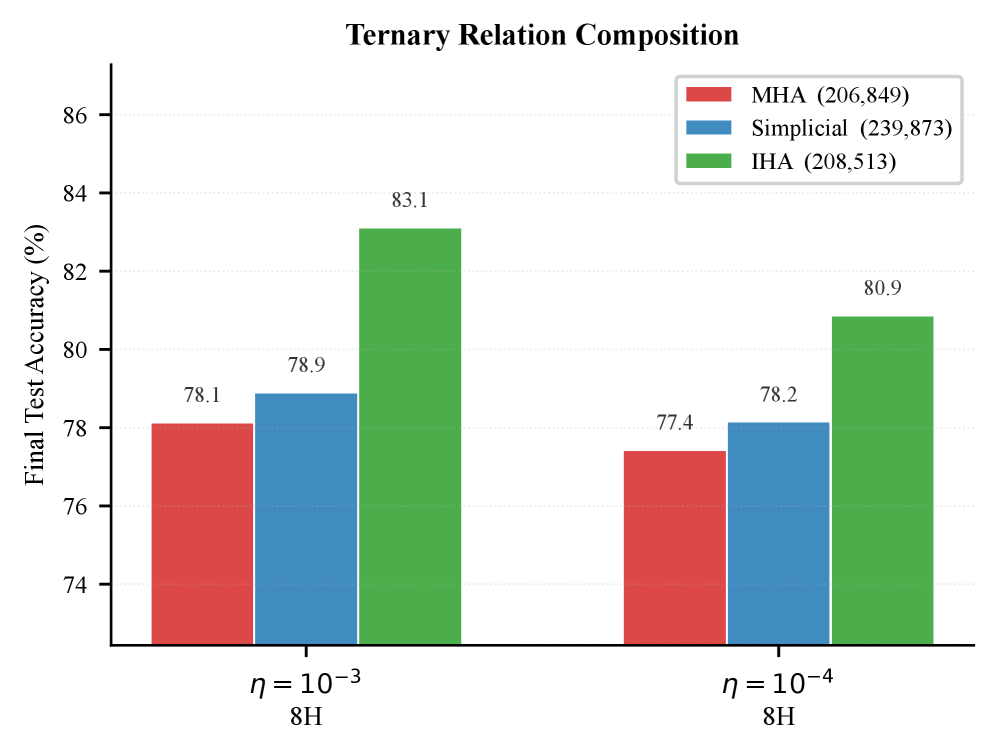
图 4:三元关系组合(三步推理)。推理步数增加后 IHA 优势更加明显:83.1% vs MHA 78.1%(η=10⁻³),提升约 5 个百分点。这符合理论预测——推理链越长(k 越大),IHA 的 √k 优势越显著。
五、计算开销与工程设计
全局 IHA 的计算复杂度为 O(P²·N²·d),是标准注意力的 P² 倍——这看起来代价很大,但论文通过混合调度策略解决了这个问题:
4 层滑动窗口 IHA(窗口大小 W = N/(2P²))+ 1 层全局 IHA,交替执行。
这使得平均计算量与全局注意力基线严格匹配(FLOP-matched),确保实验对比的公平性。
与其他方法的对比
| 方法 | 混合层级 | FlashAttention 兼容 | 交互模式数 |
|---|---|---|---|
| Talking Heads | 注意力 logits/weights | ✗ | H |
| Knocking Heads | 注意力权重 | ✗ | H |
| Diff Transformer | 注意力 map 差分 | ✓ | 2H |
| IHA | Q/K/V 投影层(注意力前) | ✓ | H·P² |
IHA 的独特优势:在注意力算子之前做混合,保留了标准 softmax(QK^T)V 的形式,因此可以直接调用 FlashAttention 等高效 kernel,无需任何自定义 CUDA 代码。
六、关键洞察与讨论
一句话串起来
再回到开头的问题——"《霍比特人》的作者出生在哪里?":
- MHA 的困境:头 1 学会了"作品→作者"(A¹),头 2 学会了"人物→出生地"(A¹),但要在单层内完成"作品→作者→出生地"(A²),还需要第三个头专门学习两跳组合。推理步数每多一步,就需要多一个头。
- IHA 的解法:不需要第三个头。IHA 构造一个伪 Query(混合了头 1 的 Query 投影)和一个伪 Key(混合了头 2 的 Key 投影),它们交互后自然实现了 A¹·A¹ = A²——两步推理在一个伪头的一次 attention 中完成。2 个头的 2×2 = 4 种伪头组合就能覆盖 A⁰ 到 A³ 共 4 种推理步数。
- 实验验证:这个理论预测在实验中得到了验证——IHA 在需要从长上下文中聚合多条分散线索的 Multi-Key Retrieval 任务上提升了 27%-112%,在需要多步数学推理的 GSM8K 上提升了 5.8%。
从线性到二次:乘法的力量
IHA 的效率提升源自一个简单但深刻的数学原理:乘法比加法高效。
MHA 的 H 个头各自独立工作 → H 种模式(加法式扩展)。IHA 的 P 个伪 Query × P 个伪 Key → P² 种模式(乘法式扩展)。这就像十进制用两位数能表示 100 个数(10×10),而不是只有 20 个(10+10)。
局限性:速度到底慢不慢?论文没说
这是本文最值得注意的缺失:论文没有报告任何实际的时间开销数据——没有 wall-clock time、没有 tokens/second、没有训练/推理延迟对比。
论文只做了理论 FLOP 匹配:通过滑动窗口调度,把 IHA 的平均理论计算量拉到和标准注意力大致相当。但 FLOP 匹配不等于实际速度相同,至少有三个被回避的问题:
- 伪头混合本身的开销:虽然额外参数只有 4H²P,但每一层都要做一次跨头的 einsum 操作,这部分的实际耗时没有量化
- 内存访问模式变化:序列从 N 扩展到 N·P 后,FlashAttention 的分块效率、KV cache 的大小都会受影响
- 滑动窗口的实现效率:理论上 FLOP 对齐了,但滑动窗口在不同硬件上的实际吞吐量差异很大
对于想在工程中落地的团队来说,这些缺失的数据可能比准确率提升更关键。
其他局限性:
- 当前仅验证了 2.4B 规模,更大模型上的表现有待验证
- 尚未扩展到非自回归架构(encoder-decoder 和 vision 场景)
七、总结
IHA 的贡献可以用一句话概括:
通过在注意力计算前引入跨头线性混合,将注意力模式从 H 种提升到 H·P²种,以 O(H²P) 的微小参数代价换取了二次级别的表达能力提升。
这篇论文的优雅之处在于:它没有发明新的注意力算子,没有引入复杂的架构,只是在 Q/K/V 投影和标准注意力之间插入了一步轻量级的线性混合——就这么简单的一步,就打破了 MHA 自 2017 年提出以来的"头间隔离"范式。
对于关注 Transformer 架构演进的研究者和工程师来说,IHA 提供了一个清晰的信号:注意力头的独立性不是不可触碰的原则,适度的跨头通信可以带来实质性的能力提升。