模型越来越便宜,AI 创业反而更难:一道绕不开的推理经济学题

Deep Research 报告 | 2026 年 6 月 | 面向 AI 创业者、产品与平台负责人、数据/AI 工程团队
摘要
有一件事,逻辑上"应该"让 AI 创业越来越容易,现实里却在让它越来越难:模型越来越便宜了。
token 单价确实在暴跌:同一个模型在降价(GPT-4 输入价约 30 美元/百万,一年多后 GPT-4o 降到 5 美元/百万,约 83%);若按"达到同一能力的成本"算(a16z 称之为 "LLMflation"),降幅更夸张——大约每年降 10×,具体倍数随锁定的能力档位而变,从几十倍到上千倍不等。按朴素直觉,原料降价这么狠,做这门生意的人日子应该好过才对。
但 2026 年发生的事正好相反:微软上个月开始取消内部大量 Claude Code 许可,因为编码工具烧的算力已经超过它要"增效"的那些工程师的工资;Uber 四个月就烧光了全年 AI 预算,被迫把每人每月 AI 花费砍到 1500 美元封顶;连英伟达自己的应用深度学习副总裁都承认,"我团队的算力成本,远超员工成本"。token 越来越便宜,账单却越烧越旺。
这不是哪家公司算错了账,而是一道结构性的、绕不开的推理经济学题。本文拆四件事:第一,这个"越便宜越贵"的机制到底怎么来的(答案是一位 19 世纪经济学家),以及为什么它是结构性的、而非等降价就能熬过去的临时现象;第二,为什么 agentic 让便宜的 token 救不了你;第三,创业公司头上那笔躲不掉的"token tax",以及它如何把 AI 原生产品的毛利锁死在 SaaS 之下整整 30 个点;第四,目前市场上跑出来的两条逃生路,以及它们各自的代价。
一、悖论本身:单价跌 90%,账单却翻倍
这套机制本身不新鲜——懂行的人一听"杰文斯悖论"就明白了。值得讲的不是它有多出人意料,而是它是结构性的,而不是"再等等就好"的临时现象。先把现象摆清楚。
token 单价在暴跌——这是事实。但与此同时,企业花在大模型上的钱不降反增:据 Silicon Data 的 token 支出指数,LLM 总支出自去年底以来翻了一倍。Bain 的一份简报把这组对比量化得更狠:从 2024 年 12 月到 2025 年 12 月,token 单价砍了一半,但 token 消耗量涨了 450%。 一句话——"模型更便宜,用量更重,账单依旧居高不下"。
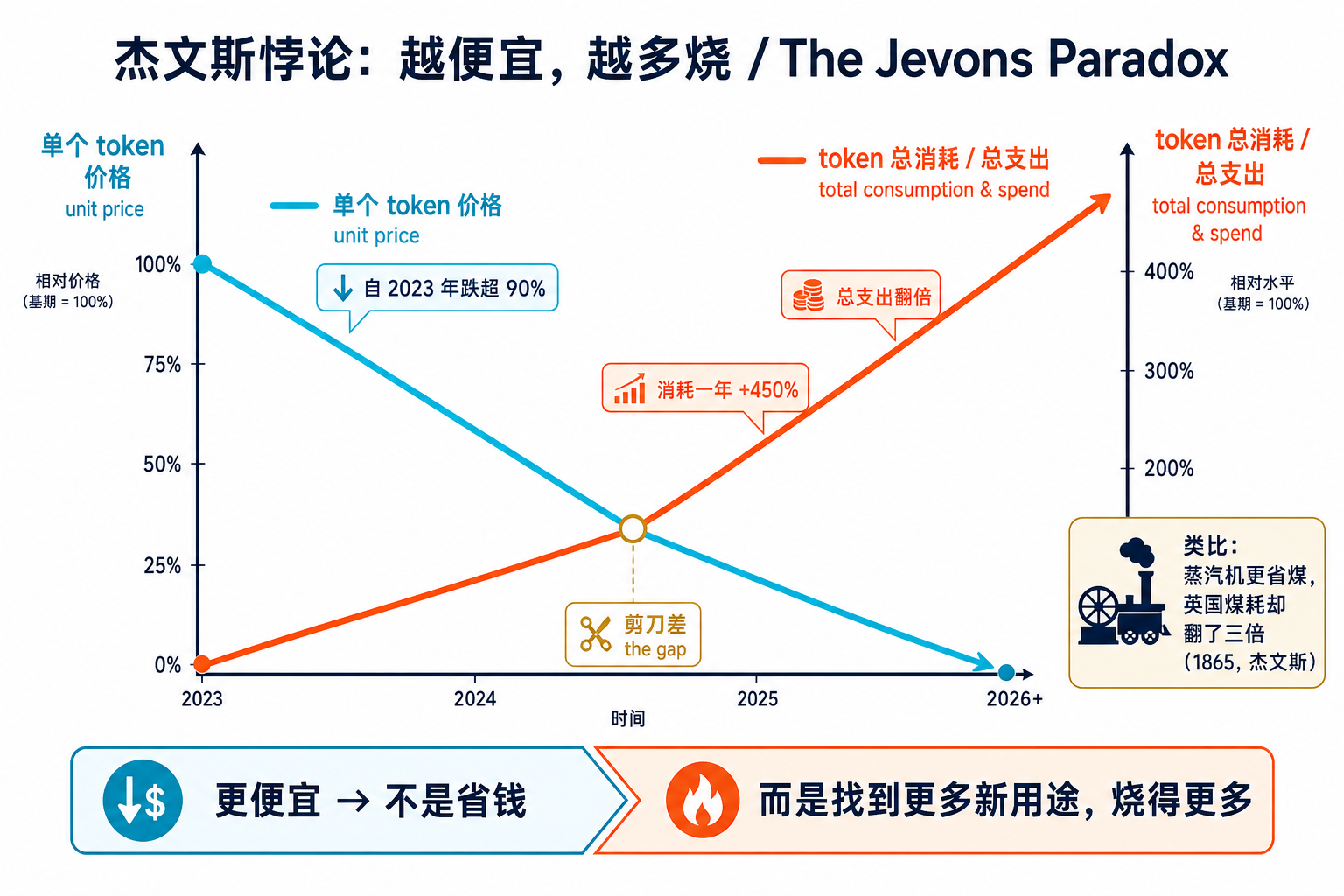
这件事 160 年前就有人讲过。1865 年,英国经济学家威廉·斯坦利·杰文斯发现:当瓦特改良蒸汽机让烧煤效率大幅提升、单位任务耗煤减少时,英国的煤炭总消耗不但没降,反而到 1900 年翻了三倍。这就是杰文斯悖论——当一样东西变得更便宜、更高效,我们不会"用同样的量、花更少的钱",而是会找出全新的用途,让总消耗涨得比效率提升还快。
阿波罗首席经济学家 Torsten Slok 直接点名:这就是"杰文斯悖论在 AI 上的重演"。他写道:"token 越便宜,公司不会少花钱,而是跑更多 agent、自动化更多流程、生成更多代码,于是总支出被推得更高——哪怕智能的单位成本在崩塌。"
这个机制在科技史上一再上演:算力便宜了百万倍,我们在计算上花得更多了;存储成本降了 99.9%,数据量爆炸了;网速更快了,账单没降,因为我们开始看 4K 流媒体。现在轮到 AI 推理。所以"等推理再便宜点,单位经济模型自然就跑通了"这句硅谷流行的安慰,方向就错了——便宜本身不会救你,它只会让你烧得更多。
二、为什么便宜没用:agentic 把 token 当柴烧
杰文斯悖论解释了"为什么会多用",而 agentic(智能体)则解释了"为什么会多到失控"。
普通的一问一答,消耗是线性的:用户给个任务,模型推理,输出答案,结束。但 agent 不是这样工作的——它读任务、拿到一次响应,然后把原始提示加上这次响应全部重读一遍再决定下一步动作;下一步又要把前面所有内容加上新响应再读一遍……上下文像滚雪球一样越滚越大,每滚一圈都要重新为整个上下文付费。
斯坦福数字经济实验室(Brynjolfsson 等人)今年的一篇论文把这个量级测了出来:agentic 任务"异常昂贵,消耗的 token 是代码推理和代码对话的 1000 倍",而且大头在输入 token(重读上下文),不是输出。更麻烦的是,成本几乎无法预测:同一个 agent 跑同一个任务,成本能差出 30 倍,因为 agent 事先不知道自己会累积多少上下文,轨迹本身是随机的。论文作者裴嘉鑫一句话点破了它的杀伤力:"agent 没法预测自己的 token 成本,这是按结果计费的根本瓶颈——你只有等它全跑完,才看得到账单。"
把这个微观机制放大到行业,就得到两个让人清醒的数字:
- 高盛研究预测,随着 agentic 工作流取代单轮调用,到 2030 年 token 消耗将增长 24 倍。
- Gartner 给出一个结构性警告:即便推理成本再降 90%,也不会自动带来更便宜的企业 AI——因为 agentic 系统每个任务消耗的 token,远多于单轮补全。
这两条合起来,把第一节的悖论钉死了:单价下降和用量上升大致在并行赛跑,而 agentic 让用量这条腿越跑越快。 结果就是微软和 Uber 这个月用真金白银验证的那句话——降价省下的钱,全被涨上去的用量吃光,还倒贴。便宜的 token 不是解药,它是让你敢把 agent 放出去"探索式狂奔"的诱因,而狂奔的尽头是一张你预测不了的账单。
三、Token Tax:你用零售价的智能,对手用成本价
如果说前两节是"用量为什么压不住",这一节是更扎心的一层:就算你把用量控制得很好,你和模型厂商之间,还隔着一道结构性的成本鸿沟。 这道鸿沟有个名字——token tax(token 税),即任何"在别人模型上盖楼"的公司,都要为它不拥有的推理交的一笔结构性税。

理解它,先看谁付什么价。模型厂商(Anthropic、OpenAI、Google)服务自己的订阅用户时,推理的边际成本是一个内部数字:自有数据中心里的电费、硬件折旧、运维;它可以用轻度用户补贴重度用户、可以设限速、可以把整件事当获客成本摊销。可一旦它把 API 卖给第三方,价格就是一个已经含了厂商利润的零售挂牌价。创业公司永远买不到真实成本价,它买的是零售价,每个 token 里都嵌着供应商的加价。
这道差有多宽?AI 编码工具 Cursor 自己的估算给了一个直观数字:一个 200 美元/月的订阅,背后可能对应约 5000 美元的算力成本——第一方能吃下的补贴,第三方花多少钱都买不到。(这是 Cursor 自己的估算、非审计数据,但方向就是故事本身。)
这道差直接体现在毛利上。软件做了二十年好生意,靠的是"边际成本趋近于零"——代码写好后多服务一个客户几乎不花钱,于是 75%–85% 的毛利自动成立。AI 推理从根上打破了这个前提:每一次交互都触发一次模型调用,agentic 产品更是一个请求扇出成一长串推理、工具调用和重试,推理成了销货成本里最大的可变项,而且随用量上升、不随规模下降。
| 业务类型 | 典型毛利 | 说明 |
|---|---|---|
| 成熟 SaaS | 75%–85% | 边际成本趋零的经典软件经济学 |
| AI 原生产品(2026) | 约 52% | ICONIQ 对约 300 家软件公司的调研;较 2024 年 41%、2025 年 45% 在改善 |
| 早期、未优化推理的 AI 公司 | 低至 25% | Bessemer 数据 |
| 推理架构高效的 AI 公司 | 趋近 60% | 最优运营者能做到的上限 |
注意中间那行:哪怕做到 52%,AI 原生产品仍比成熟 SaaS 低 23–33 个百分点。ICONIQ 还给了一个更刺眼的拆解:光是推理,就吃掉规模化阶段 AI 公司约 23% 的营收——每做成 100 万美元收入,约 23 万在工程师、销售、市场拿到钱之前,就先作为推理成本流出了门。这 30 个点的差距,约等于二三十年累积下来的 SaaS 经济学预期,被"建立在租来的智能之上"这一件事抹掉了。
还有一层更险的——当卖你 token 的厂商,自己也在你的赛道里卖一款打磨好的垂直产品时。Anthropic 的 Claude Code 到 2026 年初已做到约 25 亿美元年化收入、超 30 万企业客户,和 Cursor 抢同一批工程团队。供应商既是你的房东,又是你的同行,而且它的成本结构你永远够不着。 这时候"自己掌握推理"就不再是毛利优化,而是生存必需。
四、两条逃生路,都不轻松
市场上跑出来的成功者,给出的答案高度一致地指向两个方向。但要说清楚:这两条路都不是免费午餐。
| 逃生路 | 原理 | 代表打法 | 代价 / 边界 |
|---|---|---|---|
| 自研推理 | 把最大的成本项从"买"变成"产",绕开零售加价 | Cursor 2025 年 11 月上线自研 Composer 模型,后续 Composer 2 基于开源的 Moonshot Kimi 续训 | 要有模型与算力工程能力;自研基座若来自特定司法管辖区的开源模型,会引入合规与供应链考量 |
| 按结果计费 | 不卖过程(token),卖可验证的结果,把成本波动从客户转移到自己 | Intercom Fin 按"每解决一张工单 0.99 美元",Sierra 从第一天就按结果定价,HubSpot 客服 agent 降到 0.50 美元/单 | 只在结果"机械可验证"时成立;且把用量风险压到厂商自己头上 |
第一条,自研推理。 Cursor 是最好的案例:在自研 Composer 之前,它的销货成本被付给 Anthropic、OpenAI 的推理费主导,每个重度用户都是一笔超过订阅价的直接成本,TechCrunch 报道它一度毛利为负——做这门生意比收上来的订阅费还贵。转机正是把推理从"租"变成"产":自研模型让它在大型企业销售上做到了"略微的毛利转正"(尽管个人开发者订阅仍不赚钱)。结构性教训很清楚——对垂直 AI agent 公司,真正的毛利拐点不来自调价或分层,而来自把全公司最重的成本,从"买来的"变成"自己产的"。
第二条,按结果计费。 它换了个思路:既然过程成本不可控、又让客户紧张,那就别卖过程,卖结果。Intercom 把产品重构成 Fin,按"每解决一张工单 0.99 美元"收钱;前 Salesforce 联席 CEO Bret Taylor 创办的 Sierra 从第一天就内建结果定价,约 21 个月做到 1 亿美元年化、年初过 1.5 亿。但要点很重要:按结果计费不会让推理成本消失,它只是把用量风险从客户转移到厂商身上。 如果一张工单的推理成本是 1.5 美元、却只卖 0.99 美元,厂商只是换了种货币在亏钱。它是一种纪律,不是免费午餐——只有底层推理工程也做扎实了,它才划算。
而且它有个天花板:只在结果"机械可验证"时才成立。 工单解决了、测试过了、销售成了,这些有干净的二元触发;可一旦交付物是"判断题"——这篇文章写得好不好、这份研究够不够深——就没有防篡改的答案,产品只能被打回去按过程收费。再叠加上一节斯坦福那条结论:agent 连自己花多少都预测不了,按结果定价的厂商更得把推理效率压到极致,否则每"成交"一单就亏一单。
五、ICE 观察:技术、商业与本土视角
技术视角:下一波降本来自“执行效率层”,而非等单价再跌
如果单价下降救不了毛利(杰文斯),用量又压不住(agentic),那工程上的发力点在哪?答案不是"等模型再便宜",而是专门为 agentic 工作负载做的执行效率层:上下文压缩与缓存(KV cache 复用、prompt 缓存,直接砍掉"上下文滚雪球"里重复付费的部分)、按难度路由模型(简单任务走小模型/小参数,难任务才上前沿模型)、给 agent 设硬性 token 预算与步数上限、用确定性程序替代能用规则解决的环节。一句话:当便宜的是 token、贵的是"一次决策"时,省钱的关键从"挑更便宜的模型"变成了"让每一步都不浪费"。
商业视角:opex 正在从“人头”转向“token”
Bain 给了一个值得所有公司记住的判断:未来企业的运营开支可能 70% 来自人力、30% 来自 token,而这"不是预算问题,是结构性转型"。它的含义是:AI 时代的财务纪律,不再是"给 AI 划一笔预算"就完事,而是要算清每一类 token 花出去到底换回了多少财务回报——也就是把问题从"token 多少钱"升级成"每个 token 买回来的智能值不值这个价(return on intelligence per token)"。对创业者,这意味着两件事先想清楚:你的产品有没有一条"自研推理或可验证结果"的收敛路径?如果两条都没有,你赚的就只是别人 token 上的差价——而这道差,结构上永远偏向供应商。
本土视角:自研推理与开源基座,对中国 AI 应用商是“被动”也是“主动”
这道题对中国团队有一层额外含义。一方面,国内丰富的开源模型生态(以及自研推理的工程传统)天然契合"把推理从租变成产"这条逃生路——Cursor 的 Composer 2 正是基于国产开源模型 Kimi 续训,侧面印证了开源基座在降本上的价值。另一方面要诚实地留两句保留:第一,自研推理是有门槛的护城河,不是人人能挖,它要求模型训练、推理优化、算力调度的硬能力,多数应用层团队并不具备,盲目"造模型"可能是另一种烧钱;第二,国产算力与开源模型能在多大程度上把"token tax"真正抹平,取决于算力供给、模型能力与单位成本能不能持续追平甚至反超,这一点不该用一句口号带过,要靠实打实的工程和时间去验证。降本的方向是对的,但"国产 = 自动便宜"是危险的想当然。
结论
把这道反直觉的经济学题收束成几句:
- 便宜救不了你。 token 单价跌 90%,但杰文斯悖论意味着越便宜越多烧——用量涨 450%,总支出翻倍。等单价再降来修复毛利,方向就错了。
- agentic 让用量失控。 单个 agent 任务比普通对话多烧约 1000 倍 token,成本同任务能差 30 倍且无法预测;到 2030 年 token 消耗预计涨 24 倍。
- token tax 是结构性的。 你用零售价的智能,厂商用成本价;这把 AI 原生产品毛利锁在 SaaS 之下 30 个点,光推理就吃掉约 23% 的营收。
- 逃生路只有两条,且都要交学费。 要么自研推理把最重的成本从"买"变成"产",要么按可验证结果计费把用量风险自己扛——两条都吃硬工程,没有捷径。
回到标题那句话:模型越来越便宜,AI 创业反而更难。这句话不出人意料,但它是结构性的、绕不开的——难就难在——当智能本身变成水电一样的大宗商品,靠"倒卖别人 token 的差价"是不成立的生意;能活下来的,要么自己发电,要么卖的是用电点亮的那盏灯,而不是电本身。 你的产品,是在卖电,还是在卖灯?
参考资料
- Richard L. Wells. AI Agent Economics: Token Tax Locks Gross Margins 30 Points Below SaaS Baseline. Tech Times. 2026-06-01. https://www.techtimes.com/articles/317542/20260601/ai-agent-economics-token-tax-locks-gross-margins-30-points-below-saas-baseline.htm
- Sasha Rogelberg. Tokens are getting cheaper, but companies are spending even more on AI as a result(杰文斯悖论 / Slok / Bain). Fortune. 2026-06-17. https://fortune.com/2026/06/17/why-is-ai-spending-increasing-as-tokens-get-cheaper-jevons-paradox/
- Matty Smith / Longju Bai et al. How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks. Stanford Digital Economy Lab. 2026-05. https://digitaleconomy.stanford.edu/news/how-are-ai-agents-spending-your-tokens/ ; arXiv:2604.22750
- Dave Friedman. The More AI Costs Fall, The More You'll Spend. 2026-01. https://davefriedman.substack.com/p/the-more-ai-costs-fall-the-more-youll
- ICONIQ Capital. 2026 State of AI(毛利与推理占营收比). 2026-01.
- Bain & Company. How Token Economics Will Change Opex(70/30 与结构性转型). 2026-06.
- Goldman Sachs Research / Gartner(token 消耗 24 倍、推理降 90% 也不够);Silicon Data Token Expenditure Index(LLM 支出翻倍)。
- Guido Appenzeller (a16z). Welcome to LLMflation – LLM inference cost is going down fast(恒定质量成本每年降约 10×、三年约 1000×). 2024-11. https://a16z.com/llmflation-llm-inference-cost/
- Epoch AI. LLM inference prices have fallen rapidly but unequally across tasks(按任务 9×–900×/年). https://epoch.ai/data-insights/llm-inference-price-trends