高质量数据集的七个明确观点
观点笔记 · 写给数据/AI 团队负责人 | 2026 年 5 月 | 约 18 分钟阅读

写在前面:为什么不再罗列维度
我之前写过一篇 《数据工程实战:高质量数据集系统化指南》,把准确性、一致性、完整性、多样性、代表性、平衡性、去重、合规、无污染……所有维度都摆了一遍。系统是系统,但读完总让人觉得没有立场——好像这些维度同时优化就能拿到一个完美数据集。
事实根本不是这样。
太多团队按"维度清单"去做数据集,最后做出来的东西是个"什么都做了一点、但什么都不顶用"的鸡肋。问题不在他们不努力,而在于他们误以为质量是一个客观属性。它不是。质量是一个被任务、目标、约束反复重塑的主观结构。
观点一:不存在"普世的高质量","高质量 = 高度匹配你的训练目标"
这是我最想强调的一条。
业界谈数据质量,喜欢列十几个维度,看起来很专业,但这些维度互相打架。举两个最直觉的例子:
- 你追求"多样性",就会牺牲"一致性"——样本风格越广,规范越难统一;
- 你追求"完整性"(保留所有字段),就和"合规性"(PII 脱敏)正面冲突。
这类冲突远不止两对——准确性 vs 时效性、代表性 vs 平衡性等等,详细分析见姊妹篇《系统化指南》第一节。关键结论是:这些冲突是结构性的,无法靠"做得更好"绕过。 任何宣称"我的数据集在所有维度上都很高"的人,要么在撒谎,要么没真的做过数据集。
那么判断质量的唯一标准是什么?
是这一条:这批数据加入训练后,目标指标是否提升。
就这么简单。如果数据加进去模型变好了,它对你的任务就是高质量;如果加进去模型变差了或者没变化,无论它在维度表上得了多少分,对你都是垃圾。
举两个具体例子:
- 同一份网页爬取数据:对预训练,它是核心燃料(提供海量 token 和多样性);但直接喂给 SFT,模型会被网页里的口水话、广告语、低质问答严重带偏,效果反而不如规模小一个数量级的精标数据。
- 同一份高质量代码数据:对代码模型预训练是宝;对一个客服对话模型,反而会让它说话越来越像 Stack Overflow 答案,丧失对话感。
所以——任何脱离训练目标谈数据质量的人,都是在卖课。 包括那些在咨询报告里画维度雷达图的,包括那些动不动就讲"全维度高质量"的厂商。真正的工程师只问一个问题:你的下游任务是什么?
落地建议:拿到任何一份"高质量数据集"先做一件事——用一个小模型跑一次 ablation。加进去看指标变化。变好就是高质量,没变化就是中性,变差就是负担。维度表不重要,A/B 数字才重要。
观点二:质量 >> 数量,但"质量"必须包含多样性
LIMA 用 1000 条数据打败 52k 条 Alpaca,Phi 系列用"教科书级"数据让小模型大能力,Alpagasus 把 Alpaca 筛剩 9k 反而效果更好——这些工作已经把"质量 >> 数量"这件事说清楚了。
但是很多团队学歪了。
他们看到"质量 >> 数量"的结论,就理解成"每条数据都要精雕细琢"。然后开始做这种事:
- 让博士级标注员用 8 小时打磨 100 条数学题;
- 每条 SFT 样本经过三轮人工审校、五次重写;
- 最终交付一份 1 万条的 SFT 集,全是高难度数学题,每条都"完美"。
结果呢?模型数学能力突飞猛进,但其他能力全崩——日常对话生硬、写作风格诡异、代码能力下降、多语言能力退化。这叫"灾难性遗忘",但根因不是模型,是数据集偏科。
我的判断是:
真正的质量 = 单条样本质量 × 样本之间的多样性。两者是乘法关系,不是加法。
任何一项是 0,整个数据集就是 0。

- 单条质量高、多样性 0 → 制造一个偏科生(前面那个数学题例子);
- 多样性高、单条质量 0 → 制造一个胡说八道的杂家(你懂的,很多早期 SFT 的尴尬产物);
- 两者都高 → 真正有用的数据集;
- 两者都低 → 别浪费时间。
所以什么叫"多样性"? 不是话题数量,而是更立体的东西:
- 任务多样性:问答、改写、总结、推理、创作、代码……都要有;
- 难度多样性:从入门到困难都要有梯度;
- 风格多样性:正式、口语、幽默、严谨等多种语气;
- 指令多样性:同一类任务用不同方式表述;
- 回答长度多样性:短答、长答、列表、Markdown、纯文本都要有。
落地建议:在数据集做完之后,强制做一次"多样性审计"——按任务、难度、风格、长度做交叉分布统计,发现某个维度高度集中(比如 80% 的样本都在某个任务类型上),立刻做减法或补样。只优化单条质量、不审计多样性的团队,是在认真地制造一个偏科模型。
观点三:建设高质量数据集是建设"数据 Pipeline + 组织能力",不是"做一次数据"
这是大多数团队最大的认知误区。
我见过太多公司把"建设数据集"当成一个项目:
- 立项;
- 组建团队(或外包);
- 标注三个月;
- 交付一份 csv;
- 项目结题。
然后呢?没有然后了。这种数据集 6 个月内必然过时,且无法被下一个项目复用。原因很简单:
- 业务变了:新场景、新意图、新规则不断出现,旧数据无法覆盖;
- 模型升级了:新一代模型对数据格式、难度、多样性的要求都变了;
- 合规变了:去年合规的数据,今年可能就违规(数据安全法、生成式 AI 服务管理办法这两年一直在加码);
- 评测涨了:当年好的数据,按现在的标准看可能已经不够好。
真正的高质量数据集,是一套可持续生产的能力。这套能力包含四个东西:
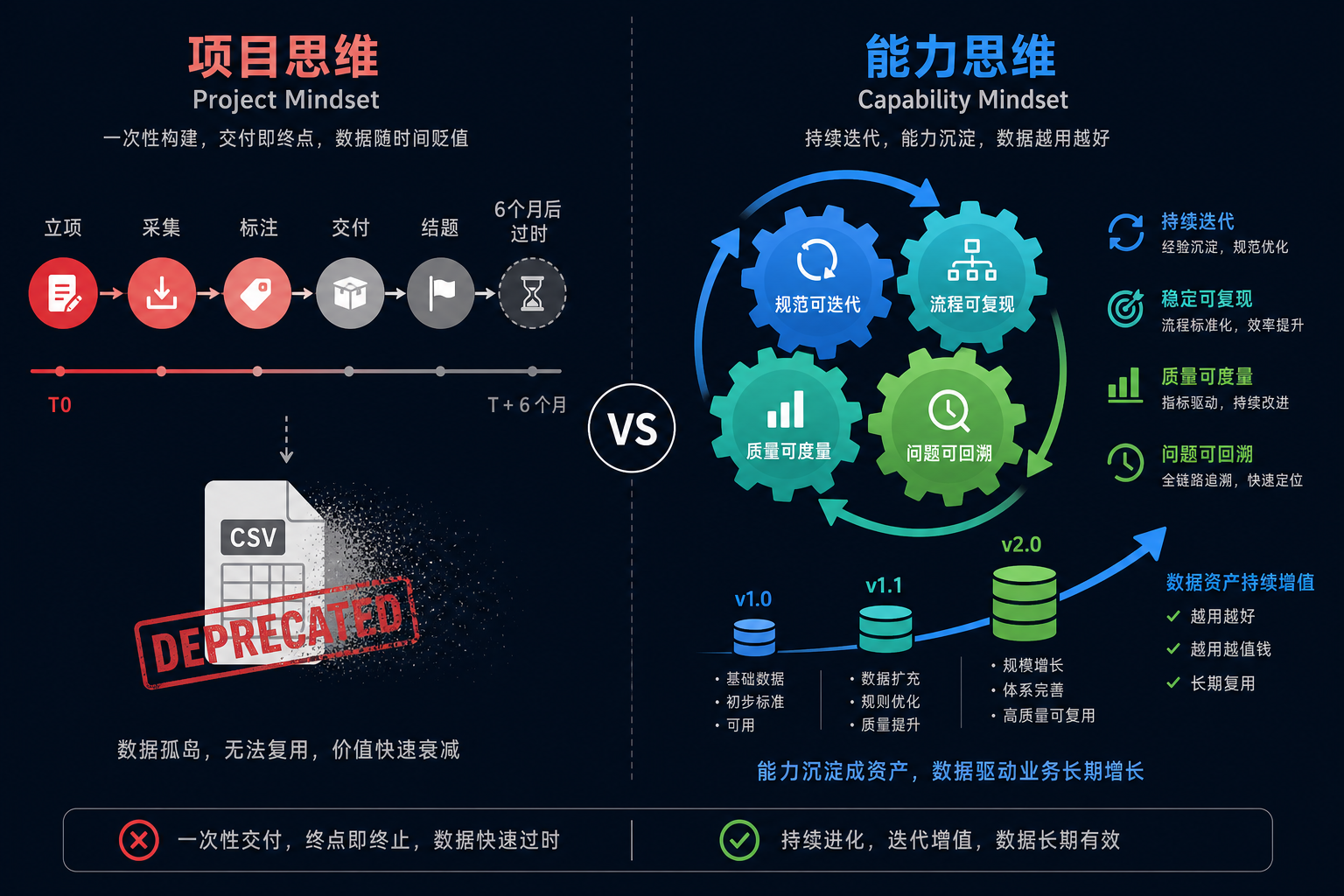
| 能力维度 | 具体含义 | 典型反例 |
|---|---|---|
| 规范可迭代 | 标注手册有版本号,规范升级有 changelog | "规范文档"是一份过时半年的 Word |
| 流程可复现 | 清洗、标注、评估都是代码,有 commit hash | 关键步骤是"某某用 Excel 手动跑了一遍" |
| 质量可度量 | 每批数据都有自动质检报告 | 质量靠"领导抽查 100 条" |
| 问题可回溯 | 任何一条样本可追到来源、标注员、规则版本 | 出了 badcase 不知道是哪一步引入的 |
OpenAI、Anthropic 这些头部团队的护城河,不在某一个数据集,而在它们的"数据工厂"——一套能持续生产、持续优化、持续审计的工程系统。这种系统不是一次性项目能产出的,需要 1~2 年的持续投入和组织能力建设。
很多公司羡慕 OpenAI 的数据,想"花钱买一份"。这是 100% 错的方向——你买到的是过时的快照,而它们持有的是会自我演化的生命体。
落地建议:把"数据集建设"从一个 PRD 项目升级成一个长期组织能力建设项目。配置专职数据工程师团队、规范化的工具链、明确的版本与血缘管理,并且把"数据-模型闭环"作为长期 KPI。没有这套能力,所有的数据集都是消耗品。
观点四:90% 的失败发生在第一步——规范定义没做好
我反对"先采集后定义"的做法,但这恰恰是业界最常见的做法。
业界默认流程是这样的:
采集 → 清洗 → 标注 → 评估听起来没毛病。但实际经验是:前三步的所有问题,都源于第 0 步——你没把"什么算合格"定义清楚。
举一个我亲眼见过的真实案例。某公司要做一个客服对话 SFT 数据集,立项时大家都觉得"这没什么难的,多采点对话、找标注员标一标就行"。结果呢?
标注三个月,做出来 2 万条数据。第一次内部评测,发现:
- 同一个问题,三个标注员给出的"理想回答"完全不一样;
- 标注员之间的 Cohen's Kappa 低到 0.3(行业可用门槛通常是 0.7);
- 模型用这份数据训练完,回答风格漂移、自相矛盾。
复盘的时候才发现根本问题——没人把"高质量客服回答"定义清楚。
- 是要"准确"还是要"友好"?两者冲突时怎么取舍?
- 多轮对话里,是要保持人设一致还是允许灵活变化?
- 用户问了产品没有的功能,应该委婉拒绝、推荐替代品、还是直接说"做不到"?
- 用户带情绪了,要先安抚情绪还是直接解决问题?
这些问题不在 schema 阶段想清楚,到标注阶段一定爆炸。
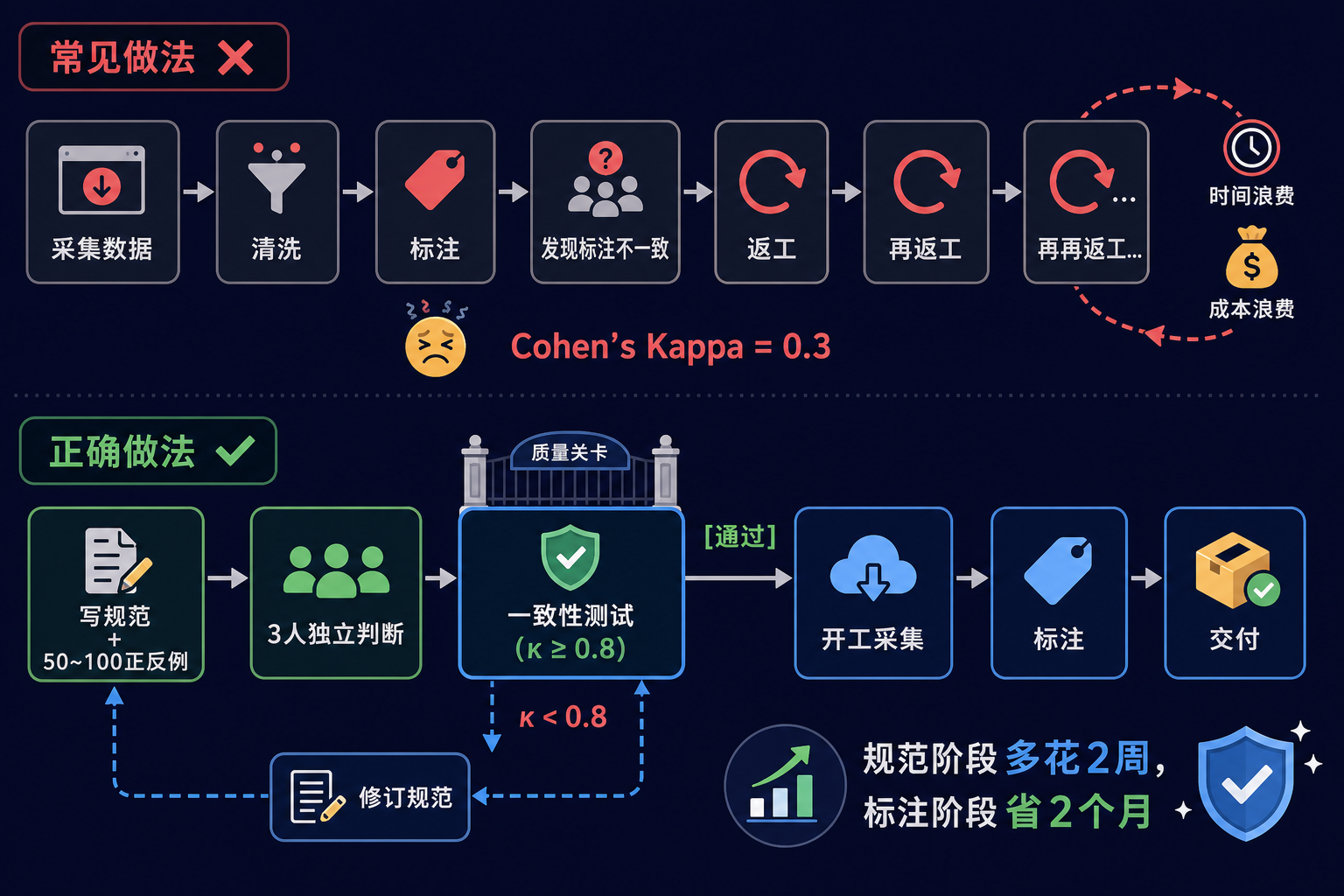
我的建议非常激进:
在你写第一行采集代码之前,先做这件事——写 50~100 个"带边界的正反例",让团队里 3 个人独立判断"这条数据合格吗",统计一致性。Cohen's Kappa 低于 0.8 之前,禁止开工。
为什么是 0.8 而不是 0.7?因为标注规范在大规模标注下会被稀释——开工前 3 人达到 0.8,到了 30 人规模通常会跌到 0.6~0.7,刚好是可用门槛。如果开工前就只有 0.7,规模化后必然崩盘。
这个建议听起来"慢",但实际上能让整个项目快 3 倍。规范阶段多花两周,标注阶段能省两个月的返工。
落地建议:把"标注规范一致性测试"作为项目立项的前置条件,写进流程。规范不达标不开工。这件事比任何工具、任何模型都更能决定数据集的最终质量。
观点五:警惕"合成数据万能论",它正在让一批团队走向 Model Collapse
2024 年以来,"用 GPT-4 蒸馏一切"成了显学。
逻辑很诱人:标注成本太高、人工慢、规模上不去,那就让强模型当标注员——成本几乎为零、速度极快、规模无限。Self-Instruct、Evol-Instruct、Magpie、UltraFeedback……一连串方法都在告诉你:你不需要标注员了,模型自己就能造数据。
但我的立场很明确:合成数据是工具,不是银弹。把它当主菜的团队,模型能力会肉眼可见地塌缩。
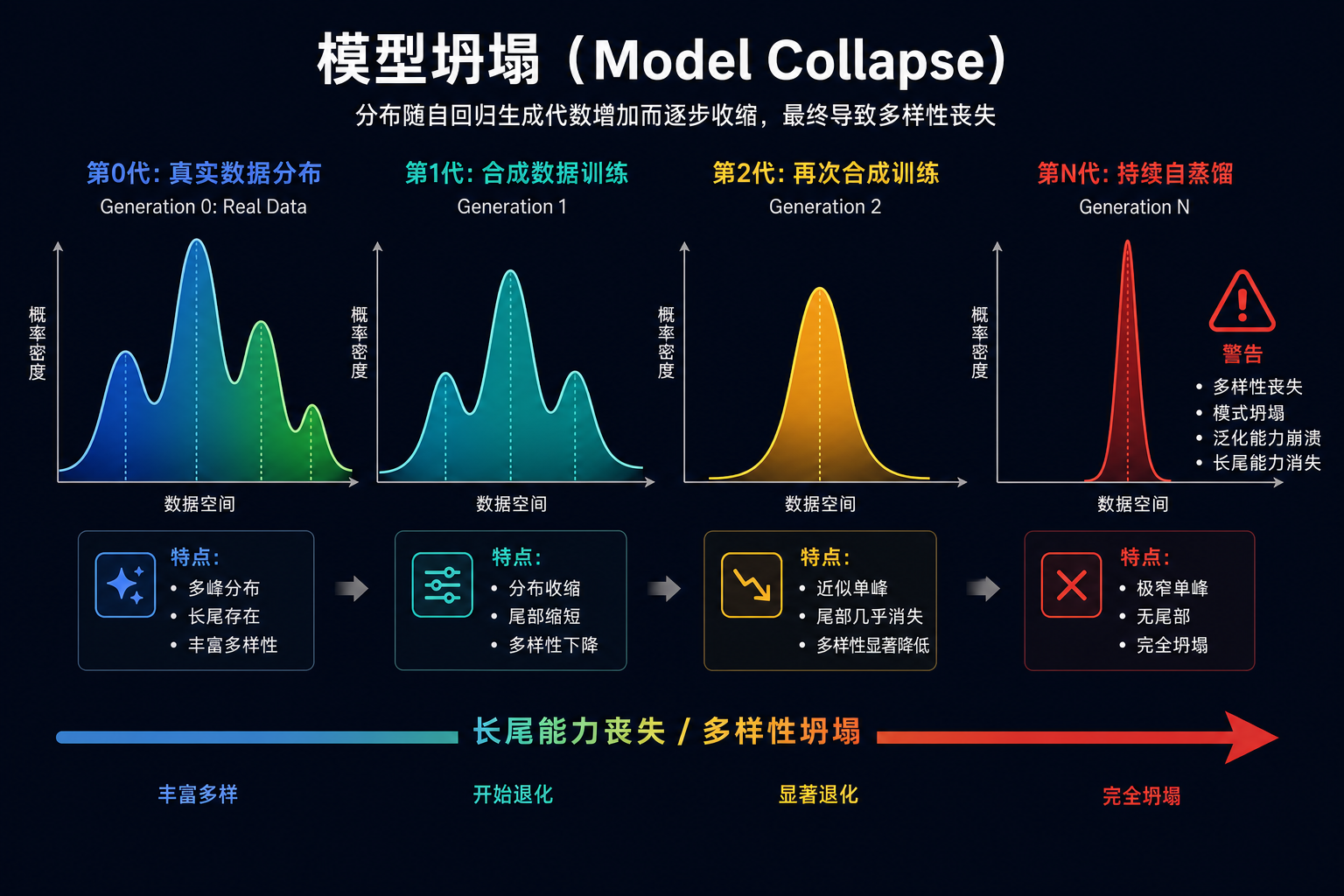
这不是危言耸听。Nature 2024 年发了一篇标志性论文 《AI models collapse when trained on recursively generated data》,明确证明了:纯合成数据训练的模型,能力分布会越来越窄、越来越平均化、长尾能力快速丧失。这就是 Model Collapse(模型坍塌)。
直觉上的解释是这样的:
- 强模型的输出,本质上是它训练分布的"中心区域"——高频、高确定性、高一致性;
- 用这种输出去训下一代模型,下一代会学到一个更"中心化"的分布——长尾能力丢失;
- 反复迭代之后,模型只会说几种"安全的话",遇到边界 case 就傻掉。
我的立场是这样的:
合成数据可以用,但必须满足两个硬条件:1. 混入足够比例真实数据(一般建议合成 ≤ 50%,特别是对齐阶段);2. 必须经过拒绝采样或奖励模型筛选,不能照单全收。
更激进一条:
永远不要用自己模型的输出训练自己的下一代模型,除非你能保证多样性注入。
这条听起来反直觉——很多公司不就是这么做"自我迭代"的吗?是的,但他们要么有奖励模型严格筛选(OpenAI、Anthropic 那一套),要么有大量真实数据兜底(Meta 的开源模型)。普通团队没有这两个条件,玩自蒸馏只会加速塌缩。
我特别想提醒一个普遍现象:很多团队用 GPT-4o 合成数据训练 7B 小模型,初期评测分数飙升,半年后产品上线发现模型在真实场景里"什么都会一点,但都不深"。这就是典型的 Model Collapse 早期症状——能力分布被压平了。
落地建议:合成数据流程里必须有两道闸——质量闸(拒绝采样/奖励模型)和多样性闸(真实数据兜底)。任何只用合成数据、没有这两道闸的团队,建议立刻停下来评估。这事不是技术选择,是生存问题。
观点六:数据卡(Data Card)不是文档负担,是工程纪律
很多人觉得写 Data Card 是 Google 那种大厂的形式主义,"小团队不需要"。
我完全不同意。
写 Data Card 的真正价值,不在于交付文档本身,而在于它逼你在动手之前回答清楚 7 个问题:
- 这份数据为谁服务? 目标任务、目标模型、目标场景是什么?
- 来源是什么、合规吗? 自有/采购/合成/爬虫?license 是什么?
- 已知偏差是什么? 哪些群体被多采、哪些被少采、为什么?
- 不适用于哪些场景? 这份数据明确不能用在什么任务上?
- 怎么评估它是否合格? 通过什么指标、什么方法验证质量?
- 版本和血缘怎么管? 谁是 owner?怎么追溯?怎么升级?
- 什么时候应该被淘汰? 过期条件是什么?什么场景下需要重做?
这 7 个问题答不出来,就别开始建设。 答得出来,你的数据集质量天花板就已经被锁定在一个合格线之上。
为什么这 7 个问题如此重要?因为它们覆盖了数据集全生命周期最容易出问题的所有节点:
- 问题 1 锁定目标——避免做一份"什么都能用、什么都不顶用"的鸡肋;
- 问题 2 锁定合规——避免一年后被要求下架、删数据、重建;
- 问题 3 锁定偏差——避免上线后被舆论 attack 模型偏见;
- 问题 4 锁定边界——避免数据集被滥用到不适合的场景;
- 问题 5 锁定评估——避免"做完了不知道好不好";
- 问题 6 锁定治理——避免做完没人维护变成黑盒;
- 问题 7 锁定淘汰——避免无效数据长期占用资源。
我见过很多"质量翻车"的项目,复盘时几乎都能映射到这 7 个问题里某一两个没答清。
最讽刺的是,很多团队不是答不出来这些问题,而是从来没问过自己。他们一上来就开始采数据、谈预算、找外包,把"想清楚"这件事跳过了。然后用接下来的半年付出代价。
落地建议:把"提交 Data Card"作为数据集项目立项的硬卡点。Card 写不出来的项目不批立项、不批预算、不批人力。这条规则坚持半年,团队的数据集质量会有质变。
模板可以参考 Datasheets for Datasets (Gebru et al., 2018) 或 HuggingFace Dataset Card,不需要自己造轮子。
观点七:在中国,"高质量"已是国家战略——但警惕"政策打卡式建设"
如果你在中国做数据集,2026 年这个时间点上有一件事绝不能假装没看见——国家数据局牵头编制的《高质量数据集建设指引》已经把"高质量数据集"提升到国家战略基础设施的层面。从早期"民间自发清洗"到今天的顶层设计,国内对高质量数据集的提法已经完成了一次范式转移。
我先把官方框架的要点过一遍,再讲我的判断。
一、官方框架要点——与工程共识高度一致
姊妹篇《系统化指南》第三节已经完整拆解了国家数据局的定义、"三高"特征(高价值应用、高知识密度、高技术含量)和三大演进趋势(多模态主流化、跨领域融合化、规模与语料本土化),这里不再复述。我只想指出一件事:这个框架几乎和我前面六个观点一一对应:
| 官方提法 | 对应本文观点 |
|---|---|
| "高价值应用"(紧扣实体经济、解决产业痛点) | 观点一(任务锚定,不存在普世高质量) |
| "高知识密度"(拒绝 AI 代生的"通胀数据") | 观点二(多样性 × 单条质量)+ 观点五(警惕合成数据反噬) |
| "动态战略资产"(持续投资、管理、监控、优化) | 观点三(数据集是能力,不是项目) |
| "全链路质量检测 + 隐私安全治理" | 观点四(规范定义先行)+ 观点六(Data Card 是工程纪律) |
某种程度上,官方用政策语言把工程界这两年的共识做了一次正式背书。这件事值得肯定——它意味着合规侧、产业侧和工程侧第一次在"高质量"这件事上对齐了语言。
二、但我真正担忧的是——政策定义清晰之后的"打卡式建设"
政策导向越清晰,越会引发一种典型走样:为了"达标"而做数据集,而不是为了"训出好模型"而做数据集。我已经在 2026 年看到至少三种走样:
走样一:为了"高知识密度",造出一份只能查不能训的资料库。
有些团队把"行业专家知识沉淀"理解成"把行业百科 / 教材 / 标准文件全文搬进数据集",做出来的是一份精美的知识库——但完全不是 SFT/RLHF 可用的训练数据格式。专家知识 ≠ 训练数据:前者是输入素材,后者必须经过"指令-回答"或"偏好对"等任务化构造。把知识库直接喂给微调,模型会"学到很多名词,但不会用"。
走样二:为了"多模态主流化"硬凑模态。
公开案例里多模态占比超 60% 这条数字一出,立刻有团队为了报案例硬凑——明明业务核心是文本,强行加几张无关图片、几段无关音频,每个模态都浅、各模态之间没有真正对齐。这种"伪多模态数据集"训出来的模型,多模态能力反而比纯文本基线更差,因为引入了大量噪声且没有跨模态信号。
走样三:为了"三高"凑指标,下游模型却用不上。
最让人头疼的是这种——数据集报告写得花团锦簇,规模过亿、模态齐全、覆盖三个行业、合规审查通过,但放到实际训练里,下游模型指标毫无变化甚至下降。回到观点一的判断:没有 ablation 验证的"高质量",就是 PPT 上的高质量。 任何把申报材料写得很好但拿不出训练增益数据的项目,都需要被严肃质疑。
三、对国内做数据集的团队——四条具体建议
1. 政策导向是路标,不是终点。 三高、动态资产、典型案例这些导向都对,它们能帮你判断"方向是否大体正确"。但**"单个数据集是否真正可用"只能靠下游 ablation**,这个动作政策不会替你做。
2. 典型案例是参考,不是模板。 国家数据局遴选的北斗一体化、交通+能源、中国移动 3500TB 等政企协同超大规模案例,对绝大多数民间团队没有复制价值——你既没有数据源,也没有协同能力。别照着抄案例的产物,要看背后的方法论:跨域 schema 对齐、时空融合、本土语料配比、合规前置——这些方法论是可以学的。
3. "中文与本土化"是真正的结构性机会。 我反复强调——预训练阶段的中文语料质量,是中国 AI 在 2026–2028 年最大的供给侧短板,也是最大的工程机会。别去和北斗、中国移动卷超大规模,去做行业内、领域内、专家深度参与的中等规模高密度中文语料——这是民间团队真正能赢的赛道。
4. 政策合规是底线,不是上线。 隐私安全治理、数据安全法、生成式 AI 服务管理办法——这些是任何数据集必须满足的硬约束,但满足了它们只代表"合法",不代表"高质量"。两件事别混淆:合规是入场券,可用是真本事。
四、送给所有在国内做数据集的团队一句话
政策给你定方向、给你定标准、给你定典型案例的奖项;但模型最终好不好,只取决于你有没有把"高质量"变成你自己团队的工程能力。
奖项可以申报,能力不能申报,能力只能建设。
这一条,比前面任何一个观点都更适合贴在数据团队的墙上。
收束:一句话总结我的立场
把七个观点拧在一起,可以得到一个一句话定义:
高质量数据集 = 围绕明确训练目标,由可复现 pipeline 持续生产、带规范和血缘的数据资产。它不是一份文件,是一种能力;在中国语境下,还是一个国家战略问题——但能否真正"用得上",仍然取决于团队自己的工程能力。
这个定义里每一个词都对应一个工程观点:
- 明确训练目标 → 观点一(没有普世的高质量)
- 持续生产 → 观点三(建设能力,不是做一次数据)
- 可复现 pipeline → 观点四(规范定义先行)+ 观点五(合成数据可控)
- 带规范 → 观点二(多样性 + 单条质量)+ 观点六(Data Card 锁定边界)
- 血缘 → 观点三(治理)+ 观点六(可回溯)
- 国家战略 × 工程能力 → 观点七(警惕政策打卡式建设)
写在最后
如果你只想要一份系统化的方法论,可以去看姊妹篇 《数据工程实战:高质量数据集系统化指南》——那篇有完整的七步流程、维度对比、工具链全景。
但如果你已经做过几个数据集项目,被这些问题反复折磨过,欢迎来这一篇里再读一次——看看哪一条戳中了你曾经踩过的坑。态度比方法论更稀缺,立场比清单更重要。
本文是 ICE 数据系列的观点笔记,不构成投资或决策建议。所有判断来自一线工程教训,欢迎讨论、欢迎反驳。