多模态零样本自我进化:MM-Zero 框架解析
自主进化的关键转折
传统观念认为,AI 模型的进步离不开人工标注数据和精心设计的微调过程。但随着大型多模态模型的基础能力达到临界点,一个反直觉的可能性浮现:模型是否能在零样本场景下,通过观察自身的理解偏差来持续改进?这就是 MM-Zero 框架要探索的核心问题。
自我进化的三阶段机制
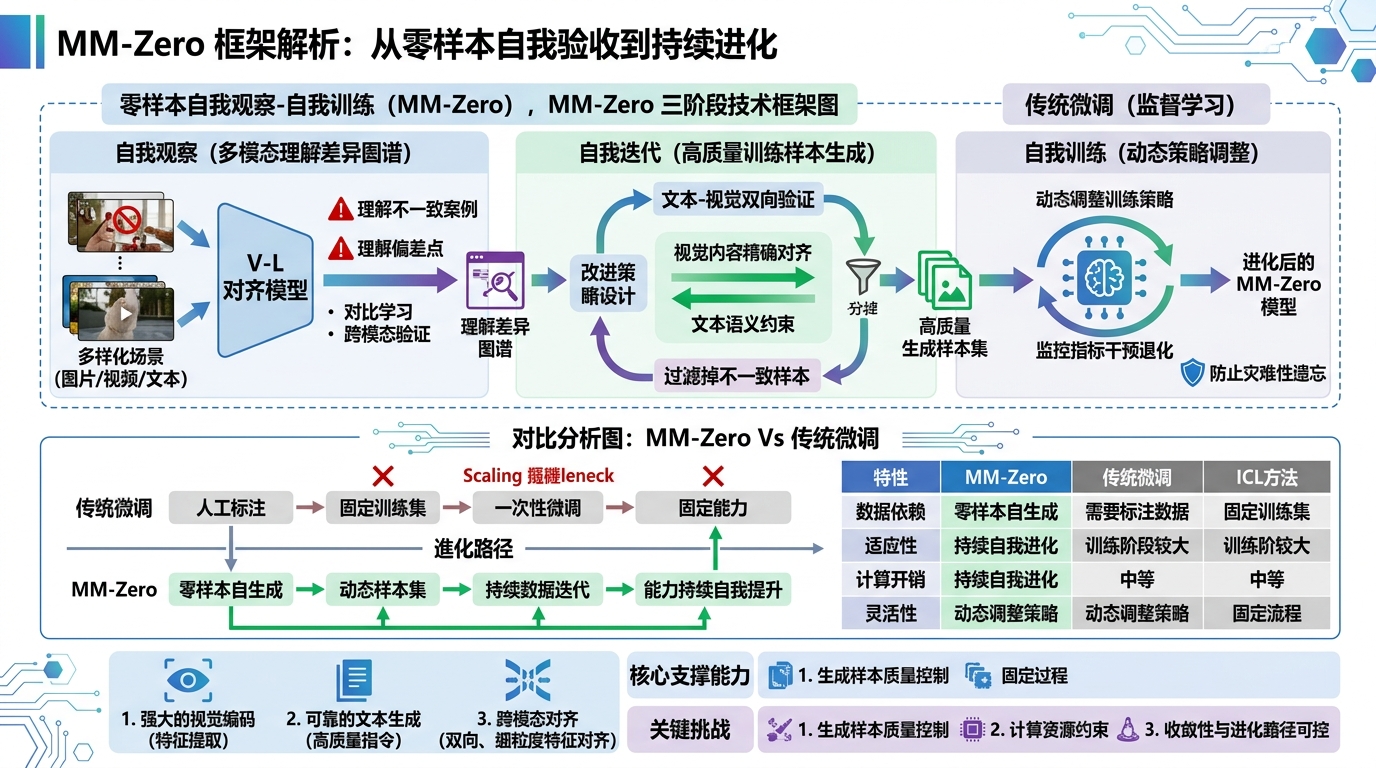
MM-Zero 提出了一个三阶段的自我进化框架,每个阶段都有其独特的技术挑战:
自我观察:发现认知盲点
第一阶段的核心是让模型分析自身对多模态输入的理解偏差。具体包括:
- 使用对比学习识别模型在视觉-语言对齐上的弱点
- 通过跨模态验证发现理解不一致的案例
- 构建理解差异图谱,为后续改进提供方向
这个阶段最关键的技术挑战是:如何设计可靠的评估机制,让模型能准确识别出自身的认知盲区,而不是陷入确认偏差。
反思与总结:生成改进策略
第二阶段是框架的核心,模型需要基于第一阶段的观察结果:
- 生成针对性的训练样本
- 设计改进策略
- 确保生成内容的质量
这里的关键是多模态交叉验证机制:
- 文本生成的描述必须与视觉内容精确对齐
- 生成的视觉内容要符合文本描述的语义约束
- 通过双向验证过滤掉不一致的样本
迭代优化:自我训练循环
最后一个阶段将生成的高质量样本用于模型的自我训练:
- 动态调整训练策略
- 监控性能指标变化
- 及时干预可能的能力退化
这个阶段最大的挑战是防止灾难性遗忘:模型在改进某些能力时,不能显著损害已掌握的其他能力。
技术实现的关键要素
要支撑这套自我进化框架,底层模型需要具备以下核心能力:
- 强大的视觉编码能力
- 需要理解复杂场景和细节特征
- 支持跨视角和跨尺度的特征提取
- 具备良好的迁移性
- 可靠的文本生成能力
- 准确描述视觉内容
- 生成高质量的训练指令
- 支持多样化的表达方式
- 跨模态对齐机制
- 视觉-语言的双向映射
- 语义级别的一致性验证
- 支持细粒度的特征对齐
与现有方法的对比
MM-Zero 框架与传统方法有显著区别:
| 特性 | MM-Zero | 传统微调 | ICL方法 |
|---|---|---|---|
| 数据依赖 | 零样本自生成 | 需要标注数据 | 需要示例 |
| 适应性 | 持续自我进化 | 固定训练集 | 上下文相关 |
| 计算开销 | 训练阶段较大 | 中等 | 推理阶段大 |
| 灵活性 | 动态调整策略 | 固定流程 | 受示例限制 |
局限与挑战
尽管 MM-Zero 展现了令人兴奋的可能性,但仍面临几个关键挑战:
- 生成样本的质量控制
- 如何确保自生成样本的准确性
- 防止错误样本的累积效应
- 平衡样本多样性和质量
- 计算资源约束
- 自我进化过程计算密集
- 需要大量存储空间
- 训练效率优化困难
- 收敛性问题
- 进化路径的可预测性
- 避免能力退化
- 确定合适的停止条件
技术展望
MM-Zero 框架的意义不仅在于其技术创新,更重要的是开启了 AI 系统自主进化的新范式:
- 降低数据依赖:通过自我观察和改进,减少对人工标注数据的需求
- 动态适应:模型可以根据实际应用场景持续优化
- 成本效益:长期来看,自我进化可能比持续的人工干预更经济
关键是要在保证模型可控性的前提下,最大化发挥自主进化的潜力。这需要在技术实现、资源效率和安全性之间找到平衡点。
本文部分内容由 AI 辅助生成,经人工审校和补充后发布。