Snowflake Horizon Context:把"业务语义"做成治理层
产品解读 · 语义层 × 数据治理 × 企业 AI | 2026 年 6 月

摘要
2026 年 6 月 2 日,Snowflake Summit 2026 上,一个容易被淹没在"智能体(Agent)"叙事里的发布,其实是本届最被分析师点名的重点——Horizon Context。它不是又一个 Agent,也不是又一个模型,而是一层"地基":把企业散落在各个系统里的元数据,变成统一、受治理的业务语义(business semantics)。
它要解决的问题非常具体:同一个问题、同一份数据,销售看到的收入是 1420 万美元,CFO 看到的是 1280 万美元。 当业务逻辑散落在不同 BI 模型、仪表板和 prompt 里,AI 给出的答案就会"看起来可信、实则用错口径"。
本文用竞品调研的视角拆这款产品:它是什么、三层能力怎么搭、最关键的差异化在哪、和 Unity Catalog / dbt Semantic Layer / AtScale / Cube / Collibra / Alation 比各有什么取舍,以及作为采购方该怎么选、它还差在哪。结论先放这里:Horizon Context 真正的卖点不在功能清单,而在一句话——治理强制执行在"含义层",而不是"表层"。
一、问题定义:企业 AI 为何需要统一的上下文层
先把问题定义清楚,否则容易把它当成"又一个数据目录"。
当模型本身变得越来越便宜、越来越聪明,企业 AI 最难的问题就不再是"模型够不够强",而是"模型推理时依据的业务定义准不准"。一个会写 SQL、会调试代码、会分析数据的 Agent,如果在被问到"什么叫营收"时只能靠猜,那它再聪明也没用。Snowflake 把这个症结拆成了三个层面:
| 问题 | 含义 | 后果 |
|---|---|---|
| Context is scattered(散落) | 关键上下文分布在数据库、BI、管道等不同系统,没有任何一个系统握有完整画面 | Agent 拿不到全貌,答案不可信 |
| Context is raw(原始) | 原始元数据没有更高层含义:这些资产怎么关联?哪个权威?这一列什么意思?指标怎么算? | Agent 面对裸表"裸奔",容易误读 |
| Context is inactive(不活跃) | 上下文只有被用上才有价值,但它常常依赖用户"知道找哪个 Agent、怎么 prompt" | 绝大多数交互根本没用上已有上下文 |
这三句话其实是整个产品的"问题陈述"。一个真正有用的上下文层,必须同时把这三件事做掉:采集(让画面完整)、富化(让原始元数据有业务含义)、激活(让上下文自动被用上)。这恰好就是 Horizon Context 的三层能力主线。
二、产品定义:Horizon Context 是什么与能力边界
一句话定义:Horizon Context 是内置于 Snowflake Horizon Catalog 中的"受治理上下文层(Governed Context Layer)"——它把元数据转化成统一、可治理的业务语义,让每个 AI 智能体、BI 工具和应用都基于同一套可信定义来回答问题。
要理解它的位置,先理清几个容易混淆的名字层级:
| 名称 | 角色 | 一句话 |
|---|---|---|
| Horizon Catalog | 治理/安全/发现服务(目录层) | 管访问控制、血缘、搜索的底座 |
| Horizon Context | Catalog 之上的"上下文/语义"能力 | 把元数据变成受治理的业务含义 |
| Semantic Views | 语义的载体 | "营收"这一指标到底怎么定义、查哪张表 |
| CoCo / CoWork | 消费方(Agent) | 自动发现并查询语义视图来回答问题 |
理解它的边界,最好的方式是看它不是什么:
| 它容易被误认为是… | 但实际上 Horizon Context… |
|---|---|
| 又一个数据目录(Data Catalog) | 不止登记元数据,而是把元数据"富化成业务含义"并强制治理 |
| 一个独立的语义层产品(如 Cube / AtScale) | 不在引擎外面"贴一层",而是原生长在查询引擎里 |
| 一个 BI 工具的语义模型 | 不属于某一个 BI 工具,而是让所有 BI / Agent 共享同一份定义 |
| dbt 那样的转换层 | 不定义"数据怎么构建",而定义"数据怎么被解读" |
官方反复出现的关键词是 trusted(可信)——它的每一项能力,都是为了让"人、BI、Agent"工作在同一个事实版本之上。
三、能力拆解:采集、富化、激活三层
Horizon Context 的设计主线,是把 Snowflake 从"记录系统(system of record)"变成"理解系统(system of understanding)"。整条链分三步:
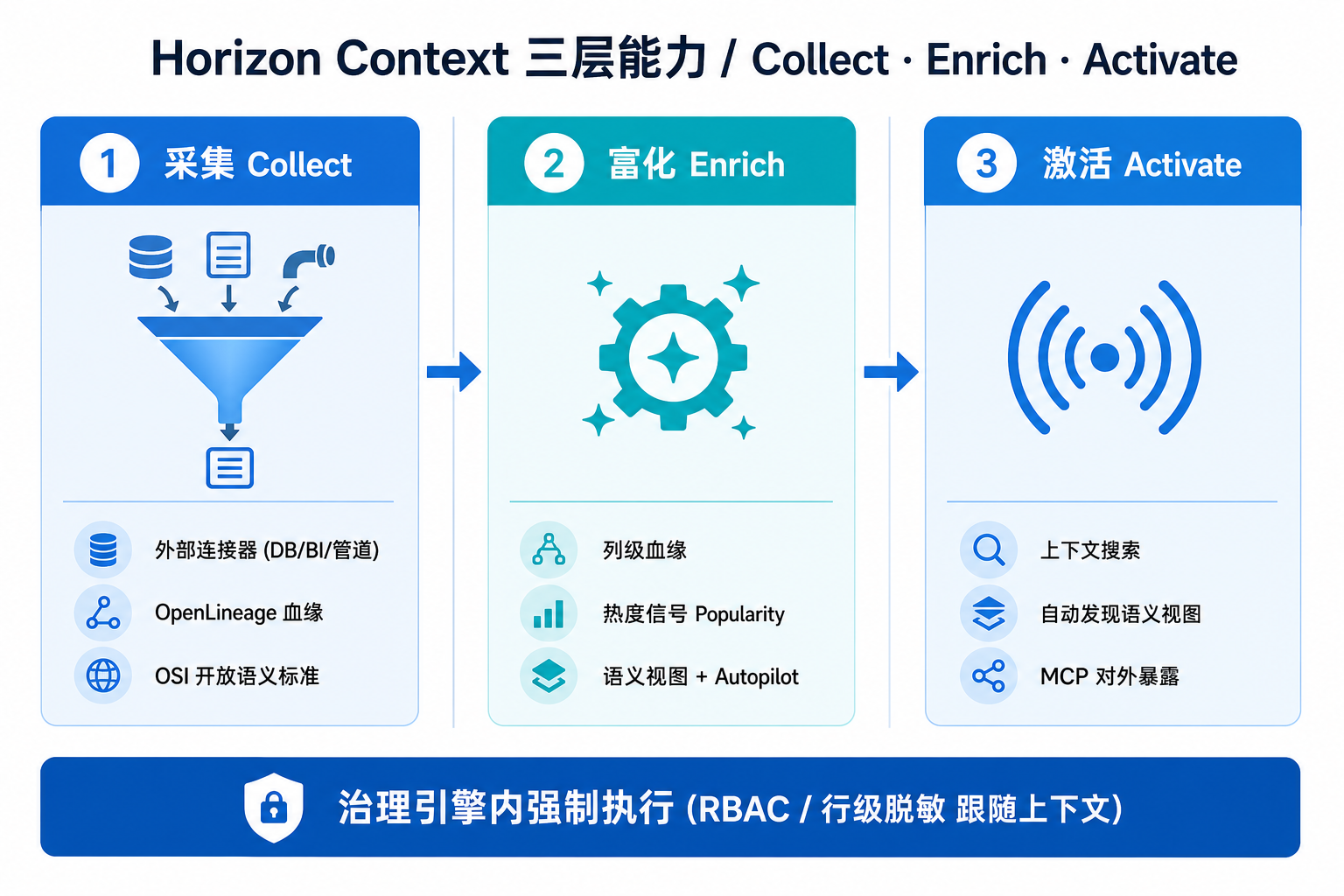 ▲ Collect 把内外部元数据汇聚进来,Enrich 自动赋予业务含义,Activate 让上下文在 Agent/BI 交互中被自动用上
▲ Collect 把内外部元数据汇聚进来,Enrich 自动赋予业务含义,Activate 让上下文在 Agent/BI 交互中被自动用上
1. 采集(Collect):打通 Snowflake 内外的数据资产
目标是让 AI 拿到"完整画面",而不只是 Snowflake 自己的那部分。
- Metadata Connectors(私有预览):把 Horizon Catalog 从"Snowflake 的目录"扩展成"全量数据的目录",连接 PostgreSQL、Microsoft SQL Server、Tableau、Power BI、dbt 等,采集库表结构、查询日志、仪表板定义。
- OpenLineage API(公开预览):让 Apache Airflow 等血缘生产者直接把血缘信息发给 Horizon Catalog。
- Open Semantic Interchange(OSI):Snowflake 牵头的开放语义交换标准,目标是统一各系统之间交换语义元数据的方式,目前已有 54 家厂商参与并发布了规范。
这一步的连接器能力,很大程度来自 Snowflake 在 2025 年 11 月收购的 Select Star——一个成立于 2020 年的元数据上下文平台,擅长把 PostgreSQL/MySQL、Tableau/Power BI、dbt/Airflow 等异构源整合成统一模型。
2. 富化(Enrich):把原始元数据转化为业务语义
采集只是开始,原始元数据需要被赋予"更高层含义",而且要尽量自动化:
- 端到端列级血缘:把 Snowflake、外部查询日志、BI 系统、OpenLineage 的血缘拼接成完整血缘图谱。
- Popularity(热度):用查询/访问日志算"热度",作为"哪个资产更权威可信"的信号——当一堆长得很像的表摆在面前,热度帮你判断该信哪个。
- AI 自动生成文档:用 AI(结合元数据,可选采样数据)自动生成表和列的描述。
- Semantic Views 增强(本届重点):
- Advanced Semantics(私有预览):支持 LOD(level-of-detail)计算、可组合定义、用户自定义物化 + 自动查询重写。
- Semantic Studio(私有预览):Workspaces 里一个完整的、AI 辅助的语义建模 IDE,集成 CoCo 和 Git 版本管理。
- Semantic View Autopilot:直接吃进你现有的 SQL、Tableau、Power BI 文件,自动生成语义视图——把"建语义层"这件传统上极重的手工活自动化掉。
3. 激活(Activate):让上下文在 AI 交互中自动生效
最后一公里是"确保它真的被用上",而不是躺在目录里吃灰:
- Context Search:CoCo 通过 Universal Search(关键词 + 语义的混合检索,用热度排序、用访问控制策略过滤)自动检索相关上下文。
- 自动语义视图发现:问数据问题时,CoCo 自动搜索并查询相关语义视图,没有就回退到底层表。
- 语义视图互操作:通过 MCP(Model Context Protocol) 暴露语义视图(由 Horizon Catalog 治理),可从 Claude、Cursor、Antigravity CLI 等任意 Agent 连接;BI 生态扩展到 Power BI、Excel、ThoughtSpot、Looker 等。
把这三步连起来看:它采集的上下文信号其实覆盖了四个层次——结构(有什么、怎么连)、运营(在发生什么)、语义(意味着什么)、行为(怎么被用)。这四层叠加,才是"完整上下文"的真正含义。
四、核心差异化:治理强制执行于"含义层"而非"表层"
如果只能记住一句话,就是这句。这是 Horizon Context 与几乎所有第三方语义层最本质的区别。
第三方语义层(无论 Cube、AtScale 还是某个 BI 的语义模型)通常"坐在查询引擎外面"。这带来两个结构性问题:
- 治理可被绕过:语义层在引擎外,用户只要直接查底层表,就能跳过语义层定义的口径和权限。
- 双系统漂移:语义层和治理引擎是两套系统,每次查询都要协调;一旦定义漂移,Agent 就会跟错那个。
Horizon Context 的做法反过来:因为它原生于 Snowflake 引擎,治理在"含义层级"强制执行,而不只是表层级。
- 你的 RBAC 权限策略、行级脱敏会跟随上下文走——每个工具、每条查询、每个 AI 回答都生效。
- 一个对财务团队受限的定义,在 Power BI、在 Salesforce、在任何查询它的 Agent 里,始终保持受限。
- 语义"活在治理引擎内部,在查询时强制执行,不复制、不缓存",从根上避免同步和漂移。
用官方那句精炼的话总结这条护城河:
没有上下文,Agent 靠猜(an agent guesses);有了原生的上下文,Agent 能行动(an agent acts);有了原生且受治理的上下文,Agent 才能被信任(an agent can be trusted)。
这就是为什么分析师把 Horizon Context 评为本届最有价值的发布——它解决的不是"模型强不强",而是"答案敢不敢信"。
五、竞品对比:五类方案的横向分析
把 Horizon Context 放进真实的选型语境里,它要面对的不是一个对手,而是四五类形态各异的方案。先用一张象限图看清各家的相对位置,再逐类拆解。
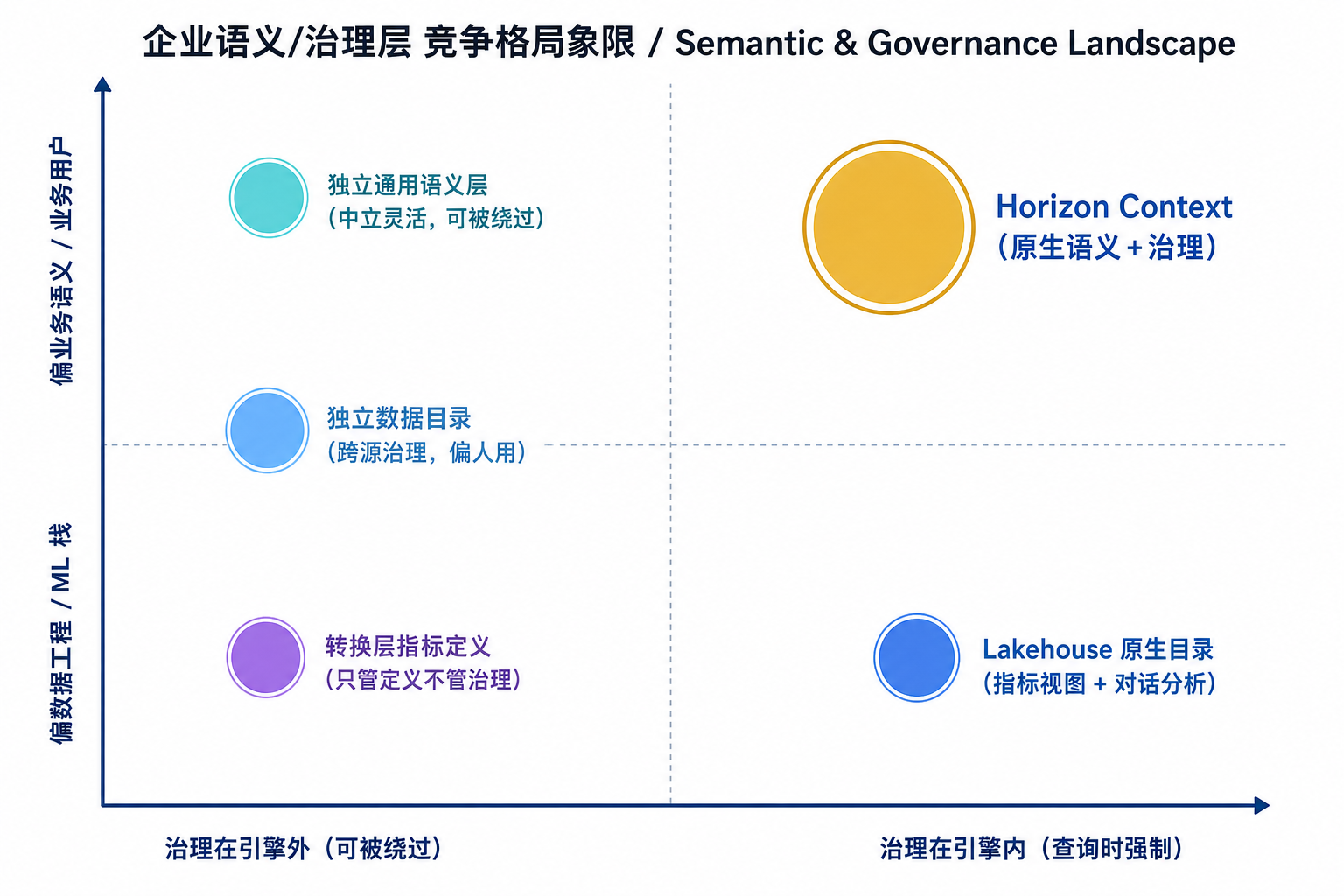 ▲ 两个判断轴:横轴是"治理强制执行的位置"(引擎外可被绕过 ↔ 引擎内查询时强制),纵轴是"产品重心"(偏数据工程/ML ↔ 偏业务语义/业务用户)。Horizon Context 押在"引擎内 + 业务语义"的右上象限——这正是它区别于其余四类方案的卡位
▲ 两个判断轴:横轴是"治理强制执行的位置"(引擎外可被绕过 ↔ 引擎内查询时强制),纵轴是"产品重心"(偏数据工程/ML ↔ 偏业务语义/业务用户)。Horizon Context 押在"引擎内 + 业务语义"的右上象限——这正是它区别于其余四类方案的卡位
5.1 总览对比
| 方案 | 形态 | 治理位置 | 跨源能力 | 与 AI Agent 的耦合 | 主要短板 |
|---|---|---|---|---|---|
| Snowflake Horizon Context | 原生于数据引擎的上下文/语义层 | 引擎内(含义层强制) | 连接器 + OpenLineage + OSI | 原生(CoCo/CoWork 自动发现语义视图,MCP 对外) | 价值最大化需数据在 Snowflake;多能力仍预览 |
| Databricks Unity Catalog(+ Metric Views / Genie) | Lakehouse 原生目录 + 指标视图 | 引擎内(Lakehouse 范围) | Lakehouse 内强,外部偏弱 | 与 Genie / Mosaic AI 耦合 | 语义/指标层相对年轻,偏数据科学家 |
| dbt Semantic Layer(MetricFlow) | 转换层之上的指标定义 | 无(不做访问控制) | 依赖 dbt 接的仓库 | 通过 API/连接器对接,非 Agent 原生 | 只管"指标定义",不管治理与发现 |
| AtScale / Cube(独立语义层) | 引擎外的通用语义层 | 引擎外(可被绕过) | 多引擎中立、灵活 | 需自行接入 Agent | 治理靠自觉、双系统漂移风险 |
| Collibra / Alation(数据目录/治理) | 独立元数据目录 | 策略编排,非查询时强制 | 连接器丰富、跨源强 | 偏人用,AI 原生较弱 | 不直接定义"可执行的查询语义" |
5.2 对比 Databricks Unity Catalog
这是最直接的同量级对手。两家都把"目录/治理"做进了引擎内,差异在重心:
- Databricks 的 Unity Catalog 起家于 Lakehouse 的统一治理,近年补上 Metric Views,配合 Genie/AI-BI 做对话式分析,整体仍偏数据科学 / ML 工程栈,业务用户门槛较高。
- Snowflake Horizon Context 的重心是"让业务语义统一、并让 Agent 自动用上",更靠近业务用户 + 治理优先。它的 Semantic View Autopilot、自动语义视图发现,都是在压低"业务侧用起来"的门槛。
一句话:Unity Catalog 偏"帮你管好 Lakehouse 并构建 AI",Horizon Context 偏"帮你统一业务语义并治理 Agent 的每一次回答"。
5.3 对比 dbt Semantic Layer
很多团队会问:"我已经在 dbt 里定义了指标,还需要 Horizon Context 吗?"官方 FAQ 给了明确回答——不冲突,是互补:
dbt 定义转换逻辑(数据怎么被构建),语义视图定义业务含义(数据怎么被解读)。用 dbt 来转换,用 Horizon Context 来治理含义。
更关键的是:dbt Semantic Layer 不做访问控制。它能保证"指标定义一致",但不能保证"谁能看哪个指标、行级脱敏跟不跟得上"。治理这一块,正是 Horizon Context 的强项。
5.4 对比独立语义层(AtScale / Cube)
独立语义层的优势是引擎中立、灵活,适合多数据源、不想被单一仓库绑定的团队。但代价就是第四节讲的两个结构性问题:治理可被绕过、双系统漂移。
值得注意的是,Snowflake 并没有把它们当纯粹敌人——AtScale 已经宣布与 Horizon Context 集成,理念是"无论你在 AtScale 还是 Snowflake 定义语义,都能被同一套治理框架管起来"。这透露了 Snowflake 的生态策略:用开放标准(OSI)把第三方语义层"收编"进自己的治理边界。
5.5 对比数据目录(Collibra / Alation)
Collibra、Alation 是传统数据目录/治理的代表,连接器丰富、跨源能力强,但它们偏"给人看的治理",而非"查询时强制执行的可计算语义"。两者现在的关系也更多是互补集成——Collibra 强调与 Horizon Context"元数据双向流动",Alation 把"受治理的语义定义"接进自己的目录。换句话说,它们负责更广义的企业元数据治理,Horizon Context 负责"让 Agent 在查询那一刻用对口径"。
六、开放生态:OSI、OpenLineage 与 MCP 三个标准位
Horizon Context 的另一个看点,是它没走封闭路线,而是用三个"标准位"去对接生态:
- OSI(Open Semantic Interchange):语义元数据交换的开放标准,54 家厂商参与。意图很明显——让"语义"像数据格式一样可互换,避免锁死在某一家。
- OpenLineage:血缘采集的开放标准,让 Airflow 等工具的血缘直接喂进来。
- MCP(Model Context Protocol):对外暴露语义视图的协议,让 Claude、Cursor 等外部 Agent 也能"带治理地"访问企业语义。
这套组合拳的潜台词是:Snowflake 不指望你所有数据和工具都在它家,但它想成为"语义和治理"的那个汇聚点——你的语义可以在别处定义,但最好"过一遍"它的治理引擎。
结语
把这篇调研浓缩成几句判断:
- Horizon Context 不是数据目录,也不是又一个语义层产品,而是 Snowflake 把"业务语义"做成了一层原生、受治理的地基。 它的卖点是一句话——治理强制执行在含义层,而非表层。
- 对比竞品,它的差异不在功能多寡,而在"治理位置":Unity Catalog 偏 Lakehouse 与 ML,dbt 只管定义不管治理,独立语义层灵活但可被绕过,数据目录偏给人看。Horizon Context 押的是"查询那一刻就把口径和权限钉死"。
- 它的生态策略是开放收编:用 OSI / OpenLineage / MCP 三个标准位,把第三方语义层和 Agent 都拉进自己的治理边界。
- 风险也清楚:太多私有预览、跨源价值打折、迁移有成本。它"能不能用"取决于这些预览能否如期 GA。
当模型变成大路货,企业 AI 的胜负手正在从"谁的模型更强"转向"谁能让所有人、所有工具、所有 Agent 基于同一个业务事实工作"。Horizon Context 赌的就是后者。
留一个问题给你:如果你的企业明天就要给 100 个 Agent 放权去查数据、做动作,你更担心的是"模型不够聪明",还是"它们各自用着不一样的口径、还绕过了你的权限"? 你的答案,基本决定了这层"上下文"对你值多少钱。
参考资料
- Snowflake,"Snowflake Horizon Context: The Governed Context Layer for AI, BI and Apps",2026-06-02,https://www.snowflake.com/en/blog/horizon-context-governed-context/
- Snowflake,"Snowflake Horizon Context 产品页",2026,https://www.snowflake.com/en/product/features/horizon-context/
- Snowflake,"Snowflake Advances Trusted AI with Snowflake Horizon Catalog",2026-06-02,https://www.snowflake.com/en/news/press-releases/snowflake-advances-trusted-ai-with-snowflake-horizon-catalog-centralizing-governance-context-and-security-across-the-enterprise/
- Snowflake,"Snowflake Pioneers New Open Framework for Interoperable Enterprise Data and AI",2026-06-02,https://www.snowflake.com/en/news/press-releases/snowflake-pioneers-new-open-framework-for-interoperable-enterprise-data-and-ai/
- Snowflake,"Snowflake to Acquire Select Star to Expand Horizon Catalog's View of Enterprise Data",2025-11-24,https://www.snowflake.com/en/blog/snowflake-acquire-select-star/
- SiliconANGLE,"AI agents, open data and governance take center stage at Snowflake Summit",2026-06-02,https://siliconangle.com/2026/06/02/ai-agents-open-data-governance-take-center-stage-snowflake-summit/
- Constellation Research,"Snowflake Summit 2026: Context, custom model training, Iceberg V3",2026-06-02,https://www.constellationr.com/insights/news/snowflake-summit-2026-context-custom-model-training-iceberg-v3
- Techzine,"Snowflake acquires Select Star for broader data context",2025,https://www.techzine.eu/news/analytics/136690/snowflake-acquires-select-star-for-broader-data-context/