LLM 垂直工作流:从 Anthropic 黑客松六强看范式切换
Anthropic 黑客松六强作品速览
Anthropic 2026年4月公布的 Build with Claude 黑客松六强作品,每一个都直接切入具体行业场景,没有一个是通用聊天机器人。先快速过一遍这六个项目:
虚拟诊室(土耳其,医疗) — 一位土耳其医生用 Claude Opus 4.7 搭建的医学生训练平台,让医学生在 AI 模拟病人身上练习问诊和诊断。系统会自动记录问诊过程、生成 ICD-10 编码、给出诊断评分。
PCB 维修助手(法国,工业维修) — 法国工程师团队做的电路板维修工具,能把 80 页的设备原理图两分钟编译成知识图谱,维修师傅拿着电路板拍张照,AI 就能自动定位故障点、标出相关电路图区域、给出维修步骤。
编程教学平台(智利,教育) — 智利大学老师开发的编程教学系统,学生不写清楚需求规格,代码编辑器就处于锁定状态。系统会强制学生先想清楚「要做什么」再动手写代码,写完后自动评测代码质量、给出针对性反馈。
墙体损伤评估工具(美国,建筑施工) — 那个被社区热议的「木匠儿子修墙 AI」,开发者把父亲三十年的墙体维修经验整理成 prompt,配合 AR 测距,能现场评估墙体损伤程度、估算材料用量和人工成本,普通装修工人拿着手机就能用。
另外两个获奖项目分别是实验室数据自动整理系统(自动解析实验记录、生成合规报告)和手语翻译辅助工具(多模态识别手语并实时转写),同样都是面向具体工作流的垂直工具。
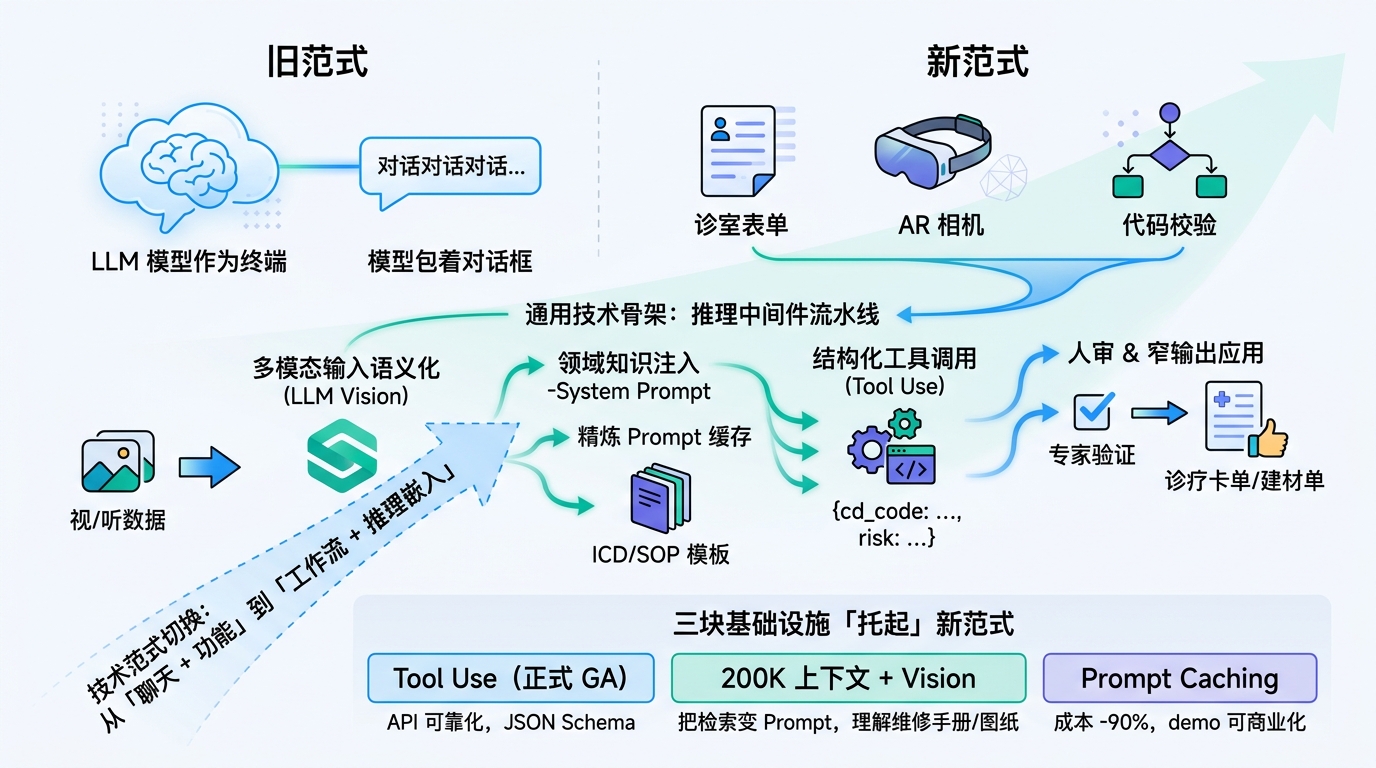
这六个项目共同的特点是:你几乎看不到 Claude 在哪里,它被藏在诊室表单、AR 相机、代码评测回路、PCB 画布背后,干的是推理中间件的活。
下面从机制、工程取舍、以及这类项目为什么现在能做出来,逐层拆。
为什么是现在:三件事在 2024 年同时成立
同样的创意,放到 2023 年的黑客松基本做不出来——不是想不到,而是跑不动、或者贵到没法演示。真正把这批垂直工作流项目「托」起来的,是 Claude 这一年补齐的三块基础设施。
第一块是 Tool Use 的 GA。Anthropic 在 2024-05-30 把 Tool Use(function calling)从实验特性推到正式可用。这件事表面看只是一个接口稳定,本质是结构化外部调用从「能用但别上生产」变成可靠协议。模型可以用 JSON schema 调 record_diagnosis()、highlight_pcb_region(x, y, w, h)、estimate_materials(wall_area) 这类领域函数,schema 本身就是边界约束——这是这些项目不退化成聊天机器人的技术根因。
第二块是 Vision 加 200K 上下文。Claude 3 系列默认 200K token 窗口,同时原生支持图像输入。200K 是什么概念?一本中等厚度的维修手册、完整 ICD-10 编码表、一个诊所的问诊模板库,这类过去必须靠 RAG 检索拼接的东西,现在可以直接塞进 system prompt 一次性喂进去。这不是说 RAG 没用了,而是**「先把知识塞满再推理」第一次在成本上可行**,对 48 小时黑客松尤其关键——团队不用再花半天搭向量库。
第三块是 Prompt Caching。2024-08-14 发布,官方数据是成本降低最高 90%、延迟降低最高 85%。对于这些垂直应用,system prompt 里那几万 token 的领域模板是固定的,只有用户输入的几百 token 会变。开了 cache 之后,单次调用成本从几毛钱降到几分钱,demo 直接能 pitch 商业化——这一点太关键了,黑客松作品过去最大的尴尬不是不能跑,而是「跑一次两美金,怎么给评委多试几轮」。
再加上 10 月发布的 Computer Use(OSWorld 基准 22%,对比 GPT-4o 的 7.8%),整个 2024 年 Claude 把「模型作为推理中间件」所需的工具链补齐了。六强作品是这套基础设施落在工程师手里后的第一批产出。
共通的机制骨架
把六个项目拆开看,场景天差地别,但技术骨架高度一致。可以画成一条流水线:
领域输入(语音/图像/传感器)
→ 多模态预处理(Whisper / Claude Vision / OCR)
→ 结构化上下文构造(领域模板 + RAG 片段)
→ Claude 推理(tool_use / structured output)
→ 领域动作(写病历 / 标记故障点 / 评测代码 / 计算材料)
→ 人类专家确认闭环这条骨架上有四个组件值得展开讲,因为它们决定了项目是落地工具还是 demo 玩具。
输入层:多模态打底,但不指望模型一步到位
医生场景用 Whisper 做语音转文字,问诊过程就是自然对话,医生不用去点表单;PCB 和墙体损伤场景直接把图传给 Claude 3.5 Sonnet Vision;编程教学场景把学生代码跑在沙箱里,执行结果连同代码一起喂给模型。
关键取舍是:领域工程师知道 Claude Vision 精细坐标不稳,所以不让它干这件事。PCB 项目的做法很典型——让 Claude 只输出「左上象限靠近 USB 接口那颗电容看起来烧了」这类相对区域描述,再用传统 OpenCV 做边缘检测精修坐标。这是把 LLM 当语义层、把 CV 当几何层的分工,比硬让 Claude 吐像素坐标靠谱得多。木匠项目类似:AR 测距拿几何数据,Claude 只做「这是承重墙裂缝还是表面掉漆」的判断。
上下文构造:200K 窗口撑出的新范式
过去做医疗应用要 fine-tune,或者至少上 RAG。这批项目几乎都没走这条路,而是把领域知识以 system prompt + 少量 few-shot 的形式直接注入。土耳其诊室项目把常见主诉模板、当地医保代码规则、ICD-10 子集一起塞进 system prompt;PCB 项目把对应设备的电路图要点和常见故障模式塞进去。
为什么这么做?不是 RAG 不好,而是任务域足够窄时,静态 prompt 比动态检索更稳——没有检索 miss、没有 top-k 排序抖动、配合 prompt caching 成本也压得住。这是窗口大了之后才成立的工程选择,值得记一笔:200K 不只是让长文档能读,它实际上把一部分原本属于 retrieval 的活拉回了 prompt 本身。
Tool Use:把「自由文本」锁成「确定动作」
这是整条流水线最工程化的环节。六个项目每一个都定义了自己的一小组工具函数,Claude 的输出不是段落,而是对这些函数的结构化调用。医生项目里 Claude 产出的是 record_diagnosis(icd_code, confidence, notes),不是「根据您的症状,建议考虑以下几种可能……」这种自由文本;墙体项目里是 estimate_materials(area_sqm, surface_type, damage_level),直接接到建材清单生成器。
输出一旦锁成 schema,整个系统的行为就可预测了。分布外输入?模型会 refuse 或者走兜底工具,不会自由发挥出一段让医生哭笑不得的建议。这也是这些项目敢放在真实工作流里的原因——失败模式是显式的,不是静默的。
结构化输出 vs 推理质量:两阶段 prompt 的取舍
但强 schema 约束有代价:会压缩 Claude 的 chain-of-thought 空间。你让它直接填 JSON,它就没地方「想」了,质量会掉。主流解法是两阶段 prompt——先让模型在一个 <thinking> 标签里自由思考,推完结论之后再让它把最终答案填进 tool call 的 schema。
这个技巧在六强作品里是标配。说白了就是「先让模型写草稿,再让它自己誊到表格里」,牺牲一点 token 和延迟,换来输出质量和可解析性兼得。这种小工程细节在黑客松 demo 和真实产品之间的区别,其实比模型选型还关键。
为什么是「收敛任务 + 专家在环」才跑得通
有一个容易被情怀叙事盖住的事实:这批项目能赢不是因为故事动人,而是因为它们选中了「LLM 恰好擅长」的任务形态。墙体损伤评估之所以好做,不是因为 Claude 懂土木工程,而是因为这个任务几何约束强、输出空间小、专家(木匠本人)验证成本极低——看一眼就知道模型对不对。
把这个形态抽出来,大概是三个条件同时满足:
- 任务边界收敛:一个诊室流程、一块 PCB、一堵墙。不是「帮我规划一次旅行」这种开放式任务,Claude 对这类任务稳定性天差地别。
- 输出空间小:要么是枚举(ICD 代码、故障类型),要么是带约束的数值(材料用量、置信度),不是自由叙事。
- 专家在环成本低:医生、电工、木匠、老师自己就是 domain expert,review 一次模型输出只要几秒——这是兜底机制,也是法律责任的承担者。
这三条合起来,解释了为什么这类项目能在 48 小时做出有生产价值的东西,而开放式 Agent(AutoGPT、CrewAI 那种)做了两年还在 demo 阶段。开放任务的问题不在模型不够强,而在没有专家可以廉价地 review 每一步输出——任务越开放,review 成本越逼近「自己从头做一遍」。
反过来也解释了天花板:专家在环是落地的原因,也是规模化的瓶颈。诊室 AI 最终医疗责任仍在医生身上,这是产品能过合规的前提,也意味着它没法像纯 SaaS 那样「无人值守」。六强里没有一个项目的 TAM 看起来像独角兽,但每一个都有非常实在的落地路径——这种范式天然倾向于「很多小而稳的垂直工具」,不是「一个吃掉一切的 agent」。
维度化对比:和相邻方案到底差在哪
把这批作品和两类邻居放一起看,差异会更清楚。
| 维度 | 黑客松垂直工作流 | 传统垂直 AI SaaS | 通用 Agent 框架 |
|---|---|---|---|
| 模型投入 | 仅 prompt + tool,0 训练 | fine-tune 或自训小模型 | 同为 prompt,但任务开放 |
| 开发周期 | 48 小时 | 6–18 个月 | 数天,但难收敛到可用 |
| 领域知识来源 | system prompt + 专家在环 | 标注数据集 | 网络搜索 + 模型先验 |
| 失败模式 | 分布外直接 refuse 或兜底 | 静默错误(最危险) | 任务漂移、死循环 |
| 适用规模 | 单一诊所 / 小作坊 / 单班级 | 企业级部署 | 演示级 |
和传统 AI SaaS 比,这批项目最大的优势是没有数据冷启动。一家诊所就能开用,不需要先收集两年病历去训模型。最大的劣势是过度依赖基模能力——Claude 降智或者 API 涨价,整个产品链直接抖动。
和通用 Agent 比,差异是方向性的。Agent 框架试图用开放推理覆盖所有任务,结果是没一个任务做得特别好;这批项目反向走,把任务切窄到 Claude 一次推理就能搞定的粒度,把 Agent 的「多步自主」退化成「单步推理 + 工具调用 + 人审」。退化不是贬义——在当前模型能力下,这种退化是让系统可用的工程选择。
工程坑:demo 和产品之间的那些细节
六强作品都是 48 小时产出,但能看出哪些是未来能生产化的、哪些还停在 demo。几个共性工程问题值得记一下,对做 LLM 应用的工程师都有参考价值。
Vision 精细坐标的失稳问题,前面提过,解法是 LLM 出语义、CV 出几何。
术语漂移特别值得说。土耳其诊室这种多语言叠加场景——土耳其语 prompt、英语医学术语、数字化的 ICD-10 编码混在一起——Claude 偶尔会把 ICD 编码写成临近编码(比如该是 J44.1 写成 J44.0)。这种错误不是幻觉那种「编个不存在的东西」,而是「选了相邻的正确编码」,非常难查。解法是在 tool_use 的参数层做后置校验:收到 ICD 码后查一次本地字典,不匹配就让模型重出。这种事在黑客松 demo 里可能没暴露,真上生产就是医保拒付。
成本曲线前面也算过。200K 上下文塞满一次调用约 $0.60(Sonnet 输入 $3/M tokens)。高频场景如果不开 prompt caching,单用户月成本就能做到几十刀。Cache 开起来以后降一个量级,但要注意 cache 的 5 分钟 TTL——如果你的流量是稀疏的,cache 命中率可能远低于官方 demo 数据。
延迟 2–8 秒在医生问诊场景是可接受的(医生也在思考),但在 PCB 维修这种「师傅拿着探头等答案」的场景就有点紧。加 Haiku 做前置路由、Sonnet 只处理关键决策,是常见优化。
合规的坑是最大的坑。六强里好几个项目场景上要碰 HIPAA、GDPR、CE 认证——黑客松 demo 可以绕,产品化不行。这也是为什么我说这种范式偏向「很多小而稳的工具」:一个小诊所自己用,合规压力远小于跨国 SaaS;一个木匠工作室用,压根不涉及个人数据。规模扩上去之后,合规成本的增长往往是非线性的,模型本身反而成了最便宜的那部分。
Computer Use 会不会把这批项目吞掉
最后一个值得讨论的问题:Anthropic 自己在推 Computer Use,让模型直接操作界面。这会不会让这批「垂直工作流嵌入」项目在 12–24 个月内被通用 agent 吞掉?
我的判断是不会,至少在可预见周期内不会,原因还是专家在环。Computer Use 目前在 OSWorld 22%,听起来比 GPT-4o 强一倍,但绝对值还是一个「五次里错四次」的水平。在消费者场景(订个机票)错了可以重来,在医疗、工业维修、建筑施工这些专家场景,错一次的代价高到必须有人在环。
更可能的演化路径是:Computer Use 会吃掉「通用白领工作流」(帮我在 Salesforce 里更新客户信息这种),但垂直专家工作流会反过来用 Computer Use 作为底层能力,继续按领域切分。土耳其医生项目未来可能用 Computer Use 去操作医院的 HIS 系统,但诊断逻辑、ICD 编码、问诊结构仍然要由领域工程师用 prompt + tool 精心设计。这两层分工,我觉得会长期并存。
落点:给做 AI 产品的同行
回到开头那个中心论点。六强作品真正传递的信号是:LLM 应用开发的默认形态变了。过去两年大家的直觉是「做个聊天机器人然后加能力」,现在应该反过来——先想清楚领域工作流长什么样,再决定在哪一步嵌入一次模型推理。聊天界面不是默认选项,是在「用户需要自由表达、任务边界模糊」的条件下才应该选的一种 UI。
对国内做 AI 落地的团队,这件事有两个直接推论。一是垂直工作流嵌入的机会窗口正在打开——不是做大而全的行业 SaaS,而是做「诊所能当天上手的问诊助手」「班级老师能当天用的代码反馈工具」这种颗粒度的东西,技术门槛已经被 Claude/GPT-4 级模型拉得很低,竞争壁垒反而在领域 know-how 和工具函数设计上。二是评估 LLM 应用的尺子得换。还在按「对话流畅度」「知识广度」打分的产品评估框架,已经跟不上这批应用的真实价值——应该换成「任务完成率」「输出可解析率」「专家 review 的 merge 率」这类更工程化的指标。
六个项目不是六个 demo,是一个范式切换的六个样本。聊天机器人这个形态不会消失,但它从 2025 年起就不再是 LLM 应用的默认答案了。
本文部分内容由 AI 辅助生成,经人工审校和补充后发布。