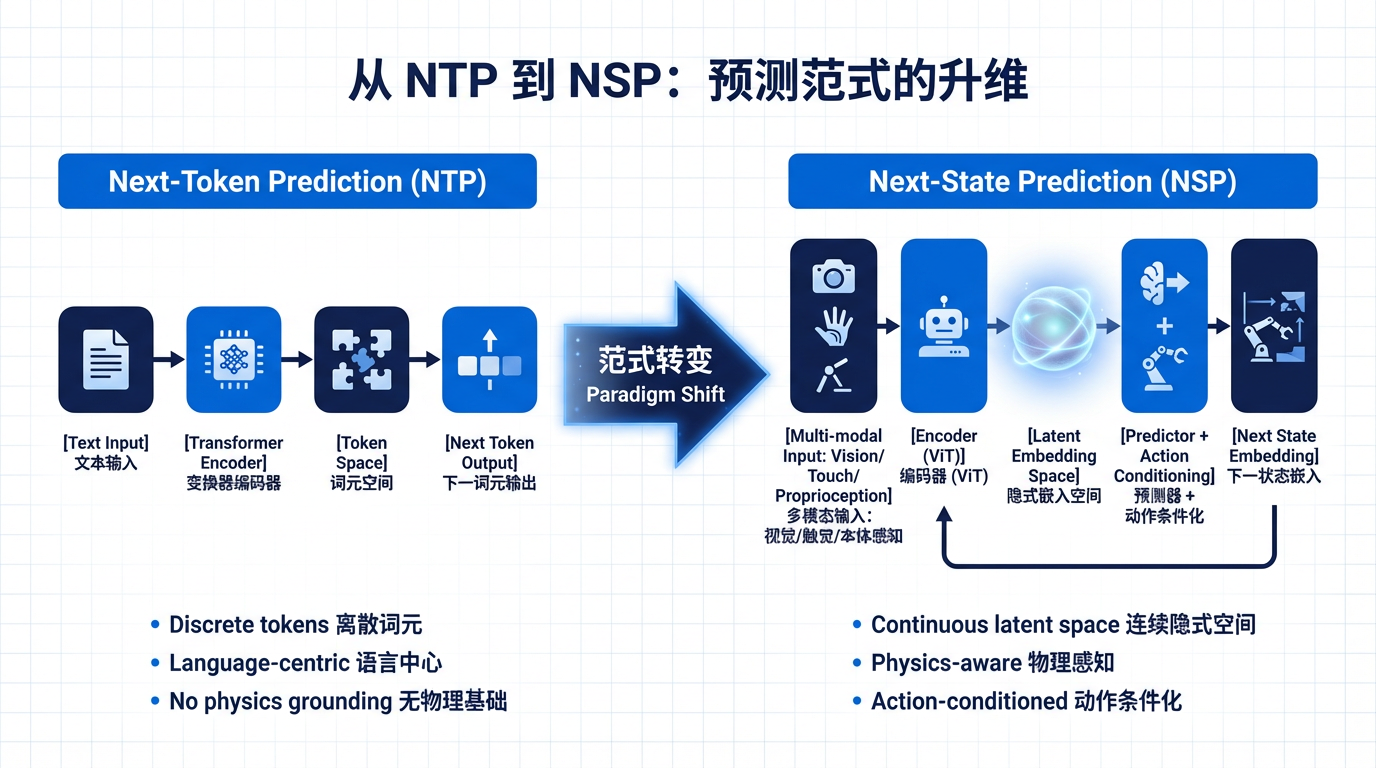
Next-State Prediction(NSP):从预测下一个词到预测世界的下一状态

过去十年,人工智能的核心范式是 Next-Token Prediction——给定上文,预测下一个词。从 GPT-3 到 Claude 4,这一范式将 AI 从"能聊天"推进到"能推理"。然而,语言终究只是世界的投影,不是世界本身。当我们让 AI 走出文本、走进物理现实时,一个根本性的问题暴露无遗:预测下一个词不等于理解下一秒会发生什么。
2025—2026 年间,一场静悄悄的范式转换正在发生。英伟达机器人主管 Jim Fan 宣称"世界建模是新一代预训练范式";Yann LeCun 离开 Meta、创立 AMI Labs,押注世界模型将超越 LLM 抵达 AGI;OpenAI 的 Sora 2 从"视频生成器"蜕变为"可学习的物理引擎";Google DeepMind 的 Genie 3 首次实现文字到可交互 3D 世界的实时流式渲染。这些看似不同赛道的进展,汇聚到同一个核心概念——Next-State Prediction(下一状态预测)。
本文将深入解析 NSP 范式的起源、核心原理、关键推动者与落地案例,并探讨它对机器人、自动驾驶、科学发现乃至整个 AI 产业的深远影响。
一、概念从哪里来
从 "预测下一个词" 到 "预测世界的下一状态",这条思想脉络并非凭空出现,而是在三股力量交汇处诞生的。
1.1 LLM 的辉煌与天花板
2017 年 Transformer 问世以来,Next-Token Prediction 一路狂飙:GPT-3(2020)证明了 scaling law 的威力,GPT-4(2023)展现出多模态推理能力,Claude 3.5(2024)、GPT-4o(2024)进一步模糊了"工具"与"助手"的边界。然而 LeCun 反复指出,LLM 存在三个结构性缺陷:
- 幻觉难以根除:生成式模型在 token 空间枚举所有可能,不可避免地产生合理但错误的输出;
- 物理世界盲区:模型参数主要编码语言知识("这一团像素是可口可乐"),而非物理规律("倾倒可乐瓶会洒出棕色液体");
- 数据效率低下:人类婴儿在学会说话之前就已具备物体恒常性、重力直觉,而 LLM 需要数万亿 token 却仍无法可靠推断物理因果。
1.2 世界模型思想的学术源头
"世界模型"并非新概念。1989 年,Jürgen Schmidhuber 提出在循环神经网络中学习环境动力学的思想。2018 年,David Ha 与 Schmidhuber 合作发表 World Models 论文,首次在强化学习中明确使用 VAE + RNN 构建环境的潜在表征,让智能体在"梦境"中规划。但受限于当时的算力与模型规模,这些工作停留在简单游戏环境。
真正的转折点是 Yann LeCun 在 2022 年提出的 JEPA(Joint-Embedding Predictive Architecture)蓝图。LeCun 在一篇 62 页的 position paper A Path Towards Autonomous Machine Intelligence 中,系统性地论证了为什么生成式模型走不通,以及为什么应该在嵌入空间(latent space)而非像素/token 空间做预测。他描绘了一个由六大模块组成的认知架构:感知、世界模型、代价、记忆、执行器和配置器,其中世界模型居于核心——负责预测环境的下一状态。
1.3 产业力量的汇聚(2024—2026)
学术思想在 2024—2026 年间被产业力量急速放大:
| 时间 | 事件 | 意义 |
|---|---|---|
| 2024.02 | Meta 发布 V-JEPA | 首个基于视频的 JEPA 世界模型 |
| 2024.09 | 李飞飞创立 World Labs,融资 $2.3 亿,估值 $10 亿+ | 空间智能(Spatial Intelligence)概念起步 |
| 2024.12 | Google DeepMind 发布 Genie 2 | 单张图片生成可玩 3D 世界 |
| 2025.01 | NVIDIA CES 发布 Cosmos 世界基础模型 | 物理 AI 基础设施民主化 |
| 2025.06 | Meta 发布 V-JEPA 2(12 亿参数) | 首次实现零样本机器人规划 |
| 2025.08 | Google DeepMind 发布 Genie 3 | 文字→可交互 3D 世界,24 FPS 实时流式 |
| 2025.09 | OpenAI 发布 Sora 2 | 物理精度飞跃,堪称"可学习的物理引擎" |
| 2026.01 | Yann LeCun 离开 Meta,创立 AMI Labs,估值 $35—50 亿 | 世界模型路线的最大资本押注 |
| 2026.01 | NVIDIA CES 2026 发布 Cosmos Reason 2、Predict 2.5 等 | 物理 AI 完整工具链 |
| 2026.03 | LeWorldModel (LeWM) 论文发布 | 首个端到端从像素训练的稳定 JEPA,~15M 参数 |
| 2026.03 | V-JEPA 2.1 发布 | 全局动态 + 精细空间细节的统一 |
Jim Fan 在 2026 年 2 月的长文中做出定性判断:
"下一个词预测是第一个预训练范式,而现在我们正在经历第二次范式转变:世界建模,或者说下一个物理状态预测。"
二、NSP 是什么
2.1 定义
Next-State Prediction(NSP) 是在给定当前观测和动作的条件下,预测环境下一时刻的状态表征的学习范式。
与 Next-Token Prediction 的关键区别在于:
- 预测对象从离散 token 变为连续的、多模态的世界状态(视觉帧、3D 运动、力觉信号等);
- 预测空间从 token 空间升维到潜在嵌入空间(latent embedding space);
- 条件变量从上文文本变为动作/干预(action-conditioned);
- 目标函数从交叉熵/困惑度变为嵌入空间的预测误差 + 防塌缩正则化。
2.2 NSP vs. 相关概念对照
| 维度 | Next-Token Prediction | Next-State Prediction(NSP) | 传统物理仿真 |
|---|---|---|---|
| 预测对象 | 文本 token | 世界状态的潜在表征 | 物理量(力、速度、位移) |
| 输入模态 | 文本(部分多模态) | 视觉、触觉、本体感觉、动作 | 精确初始条件 + 方程 |
| 学习方式 | 自回归、监督 | 自监督嵌入预测 | 数值求解 |
| 对不确定性的处理 | 枚举所有可能 token | 丢弃不可预测细节,保留语义 | 确定性(混沌除外) |
| 训练效率 | 数据饥渴 | 1.5—6× 更高效(JEPA vs 生成式) | N/A |
| 幻觉问题 | 常见 | 架构层面减少 | 无(但模型误差存在) |
| 物理因果 | 隐式、脆弱 | 显式、可反事实推理 | 精确但人工建模 |
| 通向 AGI | LLM 路线 | 世界模型路线 | 非 AI 路线 |
2.3 为什么是嵌入空间而非像素空间?
这是 NSP 范式中最关键的设计决策。考虑一个简单场景:预测"关灯后房间会怎样"。
- 在 token 空间:"灯被关掉了"和"房间变暗了"是完全不同的字符序列;
- 在像素空间:需要重建每一个像素的亮度变化,树叶的阴影、水面的反光——大量计算花在不可预测的噪声细节上;
- 在嵌入空间:两种描述映射到邻近的向量,模型只需预测语义层面的状态转移,自动忽略不可预测的高频细节。
LeCun 将此比喻为人脑的工作方式:我们并不在脑中逐像素渲染未来画面,而是在抽象层面"想象"下一步会发生什么——物体会掉落、门会打开、球会弹回。这种抽象预测既高效又鲁棒,正是 JEPA 架构的设计哲学。
三、核心架构与原理
NSP 范式的技术实现围绕一个核心问题展开:如何让模型学到一个有用的、稳定的潜在空间,使得在其中做"下一状态预测"既准确又高效?
3.1 JEPA:统一框架
LeCun 提出的 Joint-Embedding Predictive Architecture(JEPA) 是 NSP 范式的理论框架。其核心思想可概括为三步:
- 编码器(Encoder):将原始观测(图像、视频帧、传感器数据)映射到紧凑的潜在表征
- 预测器(Predictor):在潜在空间中,根据当前状态和动作预测下一状态
- 防塌缩机制(Anti-collapse):防止编码器将所有输入映射到同一个点("表征坍塌"),确保潜在空间保持信息丰富
与生成式模型(如 GPT、扩散模型)的根本区别是:JEPA 不需要解码器——它不重建像素,只预测嵌入。这带来了 1.5—6× 的训练效率提升。
3.2 关键技术演进
I-JEPA → V-JEPA → V-JEPA 2 → V-JEPA 2.1 → LeWM
| 模型 | 年份 | 模态 | 参数量 | 关键突破 |
|---|---|---|---|---|
| I-JEPA | 2023 | 图像 | — | 首个图像 JEPA,验证嵌入预测可行性 |
| V-JEPA | 2024 | 视频 | — | 扩展到时序视频理解 |
| V-JEPA 2 | 2025 | 视频+动作 | 12 亿 | 零样本机器人规划,SOTA 动作预测 |
| VL-JEPA | 2025 | 视觉-语言 | — | 比同规模 VLM 减少 50% 参数 |
| V-JEPA 2.1 | 2026 | 视频+动作 | — | 全局动态与精细空间细节统一 |
| LeWM | 2026 | 像素+动作 | ~1500 万 | 首个端到端稳定训练的 JEPA,单 GPU 可训 |
3.3 LeWM:极简 JEPA 的突破
LeWorldModel(LeWM)代表了 NSP 范式在工程简洁性上的重要里程碑。
架构:
- 编码器:ViT-Tiny(~500 万参数),将像素帧映射为 192 维单 token 表征
- 预测器:Transformer(~1000 万参数),接受当前嵌入和动作,输出下一状态嵌入
损失函数仅两项:嵌入预测损失 + SIGReg(Sketched-Isotropic-Gaussian Regularizer),后者强制潜在表征服从高斯分布,以单参数 λ 防止表征坍塌。相比此前端到端替代方案需要六个超参数,LeWM 只需调一个。
规划性能:
- 比 DINO-WM(基于基础模型预训练的世界模型)快 48×
- 在 Push-T(积木操作)、Reacher(关节控制)等任务上性能持平甚至超越
- 物理探针实验证明:潜在空间确实编码了有意义的物理量(智能体位置、物体位置、物体角度)
- 违反预期测试:模型能可靠检测物理不合理事件(如物体瞬移、颜色突变)
3.4 其他技术路线
NSP 范式并非只有 JEPA 一条路。多种架构在不同应用场景中展现竞争力:
NE-Dreamer:用时间 Transformer 预测下一步编码器嵌入,以 Barlow Twins 冗余削减度量对齐,完全无需解码器。
NextLat(Next-Latent Prediction Transformers):扩展 Transformer 训练范式,自监督地在潜在空间做预测,理论证明可收敛到信念状态(belief state)——即预测未来所需的最小压缩历史。
HCLSM(Hierarchical Causal Latent State Machines):结合基于 Slot Attention 的对象级分解、选择性状态空间模型的层次时序动力学、图神经网络的因果结构学习,在机器人操作任务中实现 0.008 MSE 的下一状态预测精度。
四、谁在推动,效果如何
NSP 范式已从论文走向产品。以下是最具代表性的推动者及其成果。
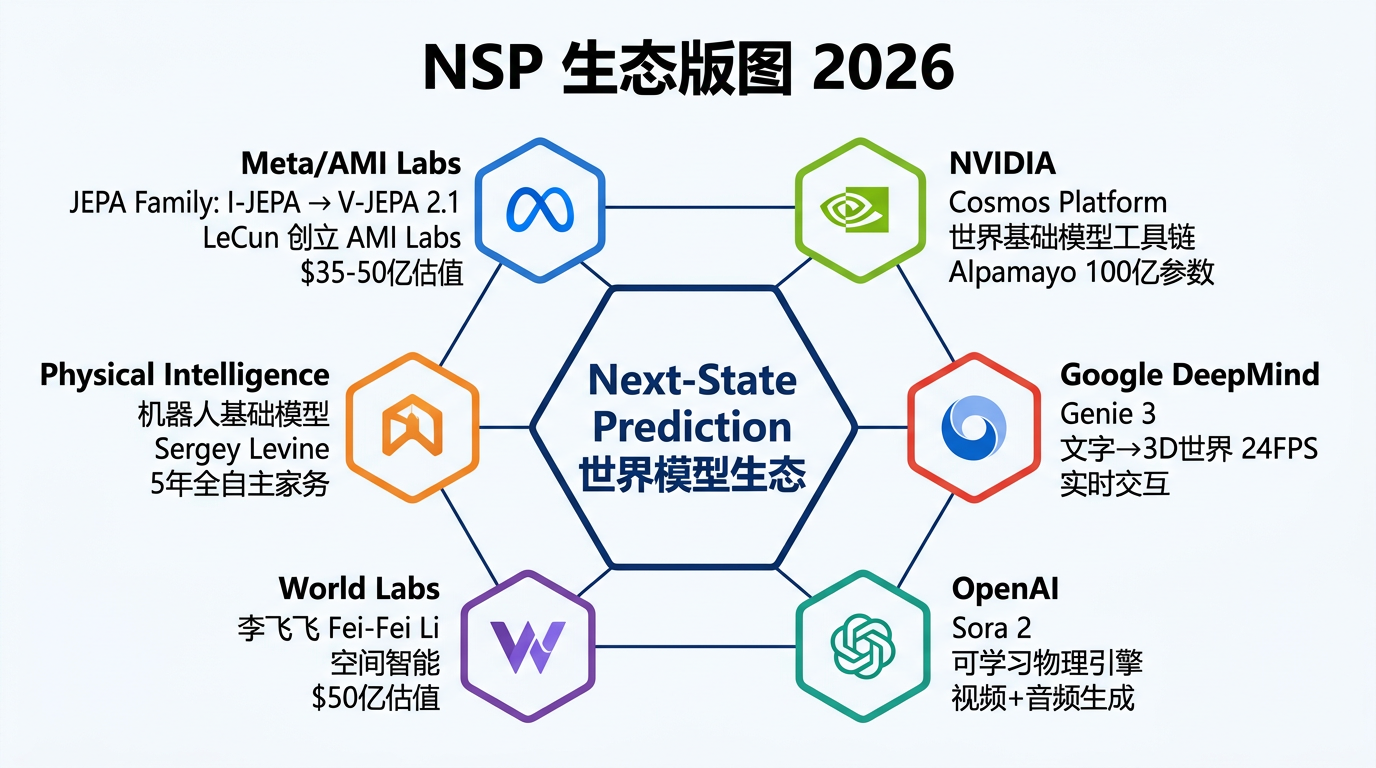
4.1 Meta / AMI Labs:JEPA 的摇篮与分裂
Meta 是 JEPA 技术的发源地,也因路线之争经历了戏剧性的分裂。
| 指标 | 详情 |
|---|---|
| 技术系列 | I-JEPA → V-JEPA → V-JEPA 2 → VL-JEPA → V-JEPA 2.1 |
| 关键数据 | V-JEPA 2:12 亿参数,100 万+小时视频训练 |
| 机器人零样本成功率 | 65%—80%(新环境中的拾取与放置) |
| 训练第二阶段所需数据 | 仅 62 小时机器人数据 |
| 基准测试 | Something-Something v2 SOTA、Epic-Kitchens-100 SOTA |
V-JEPA 2 的训练分两阶段:第一阶段在 100 万+小时多源视频上无动作自监督预训练,学习"世界如何运转";第二阶段仅用 62 小时机器人数据进行动作条件训练,让预测器学会"动作如何改变世界"。结果是模型可以在从未见过的环境中零样本控制机器人完成拾取和放置任务。
Meta 同时发布了三个物理推理基准:IntPhys 2(区分物理合理/不合理视频)、MVPBench(抗捷径的视频理解问答)和 CausalVQA(因果推理问答)。人类在这些基准上准确率 85%—95%,而当前最好的模型仍有显著差距——揭示了 NSP 的巨大改进空间。
2026 年 1 月,Yann LeCun 因与 Zuckerberg 在 LLM 路线上的分歧离开 Meta,在巴黎创立 AMI Labs(Advanced Machine Intelligence)。他公开表示:"硅谷完全被生成式模型催眠了。" AMI Labs 寻求 5 亿欧元融资、估值 30—50 亿美元,目标是在 1 年内推出"婴儿版"世界模型,2—3 年内实现完整系统。
62 小时的机器人数据加上 100 万小时的视频预训练,就能实现零样本机器人控制——这证明了 NSP 范式的核心承诺:世界知识可迁移。
4.2 NVIDIA:物理 AI 的基础设施供应商
NVIDIA 的角色不是做单个世界模型,而是构建让所有人都能做世界模型的平台。
| 指标 | 详情 |
|---|---|
| 平台名称 | Cosmos World Foundation Models |
| CES 2026 发布 | Cosmos Reason 2、Predict 2.5、Transfer 2.5、GR00T N1.6 |
| 自动驾驶模型 | Alpamayo(100 亿参数,推理+决策) |
| 合作伙伴 | 1X、Figure AI、Uber、小鹏、Agility 等 |
| Jensen Huang 原话 | "物理 AI 的 ChatGPT 时刻已经到来" |
Cosmos 平台提供了世界基础模型(WFM)的完整工具链:视频 tokenizer → 世界预测模型 → 迁移模型 → 推理模型。开发者可以用 Cosmos 生成符合物理规律的合成训练数据,大幅降低自动驾驶和机器人的真实数据采集成本。
据 Frost & Sullivan 数据,80%+ 的自动驾驶算法已使用世界模型进行辅助训练,成本降低约 50%,效率提升约 70%。
NVIDIA 正在将世界模型从"前沿研究"降维为"开发者工具"——正如 CUDA 之于深度学习,Cosmos 可能成为物理 AI 的基础设施标准。
4.3 Google DeepMind:从 Genie 到可交互世界
| 指标 | 详情 |
|---|---|
| Genie 2(2024.12) | 单张图片 → 可玩 3D 世界,支持键鼠控制,持续 ~1 分钟 |
| Genie 3(2025.08) | 文本 → 可交互 3D 世界,24 FPS @ 720p,持续数分钟 |
| 关键能力 | 水流物理、光照、风力、物体交互、可提示事件 |
| 当前状态 | 限量研究预览(学术 + 创意合作伙伴) |
Genie 3 的突破在于实时性——24 FPS 的流式 3D 世界生成意味着"下一状态预测"已快到足以支持人类交互式探索。Google DeepMind 的 Genie 3 负责人 Jack Parker-Holder 表示:
"世界模型本身就是一类全新的基础模型。它们既服务于交互式媒体,也服务于具身 AGI。世界模型是连接虚拟与物理两个领域的桥梁。"
当世界模型的推理速度追上人类的感知速度(~24 FPS),它就不再是"仿真工具",而是"可体验的平行现实"——这将重新定义游戏、教育和设计行业。
4.4 OpenAI Sora 2:视频生成 = 物理引擎
| 指标 | 详情 |
|---|---|
| 发布时间 | 2025.09 |
| 物理改进 | 篮球反弹轨迹真实、体操动作物理精确、浮力动态正确 |
| 新能力 | 同步对话 + 音效、真人嵌入生成场景(Cameo) |
| 定位 | "视频领域的 GPT-3.5 时刻" |
Sora 2 表面上是视频生成工具,本质上是一个通过 NSP 驱动的物理引擎。当它生成"一个玻璃杯掉落"的视频时,不是在"动画化"一张图片,而是在计算轨迹、撞击和碎裂——这些都基于从海量视频中学到的物理规律。
4.5 Physical Intelligence:机器人基础模型
| 指标 | 详情 |
|---|---|
| 联合创始人 | Sergey Levine(UC Berkeley 教授,强化学习顶级研究者) |
| 已演示能力 | 折叠衣物、清洁厨房、冲泡咖啡 |
| 时间表预测 | 1—2 年:窄场景有用部署;5 年:全自主家务 |
| 核心概念 | "飞轮效应"——部署→收集数据→改进→更广泛部署 |
Levine 强调了物理任务相对于语言任务的一个独特优势:"如果你折 T 恤折歪了,这很明显——你可以反思、修正。而如果你回答了一个错误答案,对方甚至不知道错了。" 这种清晰的物理反馈信号使得 NSP 的飞轮效应可能比 LLM 更快旋转。
五、核心洞见
| 编号 | 洞见 | 支撑证据 | 产业影响 |
|---|---|---|---|
| 1 | 嵌入空间预测 >> 像素/token 预测 | JEPA 训练效率 1.5—6× 提升;LeWM 15M 参数单 GPU 可训 | 大幅降低世界模型的算力门槛 |
| 2 | 世界知识可迁移 | V-JEPA 2 仅需 62 小时机器人数据即实现零样本控制 | 机器人不再需要海量标注数据 |
| 3 | 物理 AI 的 ChatGPT 时刻已到 | 80%+ 自动驾驶算法已使用世界模型辅助训练 | 自动驾驶开发成本/时间减半 |
| 4 | 视觉推理将补充甚至替代语言推理 | 猿类无语言能力但具备高超物理操作;Genie 3 纯视觉交互 | AI 推理将从"思维链"扩展到"视觉链" |
洞见 1:从像素到嵌入——效率的飞跃
LeWM 用 ~15M 参数在单 GPU 上几小时内完成训练,规划速度比基础模型方案快 48×。这证明 NSP 不需要万亿参数和千卡集群——嵌入空间预测天然压缩了问题的复杂度。
洞见 2:62 小时的启示——迁移学习的终极形态
V-JEPA 2 在 100 万+小时视频上预训练后,仅需 62 小时机器人数据就能控制从未见过的机器人在新环境中完成任务。这暗示了一种新的 AI 开发范式:用互联网规模的视频学"世界是什么样的",用少量交互数据学"我该怎么做"。
洞见 3:80% 的自动驾驶已在用世界模型
这不是未来时——根据 Frost & Sullivan 数据,世界模型已是自动驾驶开发的标配工具,带来 50% 成本降低和 70% 效率提升。NVIDIA 的 Cosmos 平台正在将这一能力从头部车企扩展到整个产业。
洞见 4:语言不是推理的基础,而是脚手架
Jim Fan 指出:你可以通过模拟几何关系和接触来解决物理谜题,想象物体如何移动和碰撞,而无需翻译成字符串。这意味着未来 AI 将发展出"视觉思维链"(visual chain-of-thought),在视觉空间中直接推理,语言仅作为与人类沟通的接口。
六、行业影响
6.1 角色变迁
NSP 范式正在重塑 AI 产业的人才结构和工作流程。
机器人工程师:从"编写控制脚本"转向"设计世界模型的预训练策略和动作空间"。传统机器人需要针对每个场景硬编码逻辑;NSP 机器人通过观察学习,工程重心从编程转向数据管道和模型调优。
自动驾驶开发者:世界模型使得"数字孪生"测试的保真度大幅提升。一个完整的路测场景可以在世界模型中生成无数变体进行验证,极大加速了长尾场景的覆盖速度。
AI 研究者:学术界的关注点从"更大的语言模型"转向"多模态世界理解"。2026 年最热门的论文方向不再是 scaling law,而是表征学习、物理推理基准、和高效潜在空间建模。
6.2 产业结构变化
视频生成 → 世界仿真:Sora、Genie 等系统模糊了"内容生成"和"物理仿真"的边界。游戏、影视、建筑设计行业将率先感受到冲击——交互式世界的生成成本从数百万美元降至 API 调用。
机器人 → 通用物理劳动:如果 Physical Intelligence 的时间表成立,5 年内全自主家务机器人意味着家政、清洁、餐饮等劳动密集型行业面临变革。
投资地理的转移:LeCun 选择巴黎而非硅谷创立 AMI Labs,称"硅谷被生成式模型催眠了"。世界模型研究的重心正在向欧洲(巴黎、蒙特利尔)和亚洲(中国、日本)分散。
6.3 资本市场信号
| 公司/实验室 | 估值/融资 | 押注方向 |
|---|---|---|
| AMI Labs(LeCun) | $35—50 亿(目标) | V-JEPA 世界模型 → AGI |
| World Labs(李飞飞) | ~$50 亿(新一轮) | 空间智能 / 大世界模型 |
| Physical Intelligence | 头部机器人独角兽 | 机器人基础模型 |
| 机器人行业整体 | 2025 年 VC 投资 $222 亿(YoY +69%) | 通用物理 AI |
6.4 治理与伦理
世界模型能"想象"尚未发生的场景——这是一把双刃剑。反事实仿真可以用于安全测试(自动驾驶碰撞模拟),也可能被滥用(深度伪造的物理升级版)。未来的 AI 治理框架需要覆盖:
- 世界模型生成内容的真实性标注
- 物理 AI 系统的安全认证标准
- 家用机器人的长期自主运行监管
七、未来展望
趋势 1:层次化世界模型
当前模型在单一时间尺度上预测。但真实任务需要多尺度规划——"做一顿晚餐"需要分解为"煮米饭→炒菜→摆盘",每个子步骤又包含精细的运动控制。Meta 已宣布层次化 JEPA 是下一步方向,能跨多个时间和空间尺度进行学习与规划。
趋势 2:多模态融合预测
未来的"下一状态"不仅是 RGB 像素,还包括 3D 空间运动、本体感觉(关节角度、力矩)和触觉信号。多模态预训练将使世界模型真正理解"摸起来什么感觉"、"推过去需要多大力"。
趋势 3:视觉空间的推理
Jim Fan 预言的"视觉思维链"正在从概念变为实验。未来的 AI 将在脑海中"模拟"几何关系和物体碰撞来解决物理问题,而不是将其翻译为文字再推理。这可能是对 Chain-of-Thought 范式的根本性扩展。
趋势 4:世界模型作为科学工具
NSP 在药物发现(预测分子构型稳定性)、气候建模(预测天气系统演化)、材料科学(预测合金性能)等领域的应用正在起步。Science Foundation Models 将 NSP 应用于基因组序列、粒子物理数据和地球系统模型,有望将数十年的实验压缩到数周。
结语
"AGI 尚未收敛。我们又回到了研究时代。" —— Ilya Sutskever
从 Next-Token 到 Next-State,AI 正在经历一次认知维度的跃升:从"理解语言"走向"理解世界"。这不是对 LLM 的否定,而是补全了 AI 能力拼图中最关键的一块——物理因果推理。当机器不仅能"说"还能"想象下一秒世界会变成什么样",通用人工智能的轮廓才真正开始显现。
对于每一位 AI 从业者,此刻的问题不再是"要不要关注世界模型",而是——
在你的领域中,"下一个状态"是什么?
参考资料
- GPT Proto Official. Next-State Prediction: The Future of AGI & World Models. Medium, 2026.03
- Meta AI. Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning. 2025.06
- Zylos Research. AI World Models 2026: The Next Frontier Beyond LLMs. 2026.01
- Maes, L. et al. LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels. 2026.03
- Jim Fan. 英伟达 Jim Fan:「世界建模」是新一代预训练范式. 量子位, 2026.02
- Insight Distillery. The Physical Intelligence Revolution. 2026.01
- MarktechPost. Yann LeCun's New LeWorldModel (LeWM). 2026.03
- Google DeepMind. Genie 3: A new frontier for world models. 2025.08
- OpenAI. Sora 2 is here. 2025.09
- NVIDIA. Cosmos World Foundation Models. CES 2025 & 2026
- LeCun, Y. A Path Towards Autonomous Machine Intelligence. 2022.06
- bdtechtalks. Inside V-JEPA 2.1. 2026.03
- Frost & Sullivan. Autonomous driving world model adoption data. 2025