数据 × Token:智能体时代的价值释放与安全博弈
原创 | 2026 年 4 月 | 面向数据从业者、AI 安全研究者与产业决策者

摘要
数据被称为"21世纪的石油",但石油有期货交易所,数据没有。中国自 2014 年起先后成立超过 20 家数据交易机构,绝大多数已停止经营;规范交易市场冷清的同时,黑市交易规模已超 1500 亿元。数据交易的根本困境在于:数据是非竞争性的,一旦交付就失去控制,传统的"一口价买断"模式无法匹配数据价值的高度场景依赖性。
智能体(Agent)时代的到来正在打开一条全新的路径。数据不再以原始形态流通,而是通过训练、微调、RAG 等方式"溶解"在模型和智能体的能力中,价值通过 Token——大模型处理信息的最小计量单位——按用量释放。2026 年 3 月,国家数据局正式将 Token 定名为"词元",确立为"智能时代的价值锚点"。中国日均 Token 调用量已突破 140 万亿,较 2024 年初增长超千倍。
当然,这条路径并非没有代价——当数据从"资产交易"转向"能力服务",安全风险并未消失,而是从"数据层"迁移到了"模型层"和"推理层"。但这不妨碍一个基本判断:Token 正在成为数据价值流通的"一般等价物",正如货币之于商品。本文将从数据交易困局、Token 化范式、价值转化架构、行业影响到未来趋势,系统剖析这场从"卖矿石"到"卖电"的范式跃迁。
一、数据交易为什么这么难
要理解 Token 化变现的意义,必须先看清传统数据交易究竟困在了哪里。
1.1 一个尴尬的事实
中国数据要素市场建设推进多年,但截至 2025 年 9 月,2014-2017 年间成立的 20 家数据交易机构中绝大多数已停止经营,仅 7 家网站仍可访问。学术研究对此有一个精辟的总结:"数据交易中心需要数据交易,而数据交易不需要数据交易中心。"
国家数据局在 2026 年 2 月发布的《关于培育数据流通服务机构的意见》中也坦承,当前数据流通面临 "供不出、流不动、用不好" 的突出问题。
1.2 五个根本性矛盾
数据交易的困局并非执行层面的问题,而是源于数据的经济学特性与传统商品交易范式之间的根本冲突:
| 矛盾维度 | 核心问题 | 具体表现 |
|---|---|---|
| 非竞争性 | 数据可无限复制,一旦交付即失控 | 买方拿到数据后可无成本复制和转售,卖方无法持续获益 |
| 信息不对称 | 买方无法在购买前验证数据质量 | 缺乏统一标准和第三方认证,优质供给方被合规成本挤出 |
| 定价困难 | 数据价值高度依赖使用场景 | 同一份数据对不同买方的价值可能相差百倍 |
| 确权模糊 | 多方贡献导致权属难以界定 | 个人数据、企业加工数据、公共数据的权益边界不清 |
| 合规焦虑 | 数据直接流通带来隐私和法律风险 | 数据持有方面临"不共享怕错过机会,共享怕触碰红线"的两难 |
这些矛盾导致了一个怪象:规范的场内交易体量极小(超 50% 的交易机构年交易量低于 50 笔),而黑市交易异常活跃——规模已超 1500 亿元人民币。
二、Token:数据价值释放的新范式
智能体时代并没有"解决"数据交易的老问题,而是用一个全新的范式绕开了它。
2.1 从"卖数据"到"卖能力"
传统数据交易的核心动作是交付原始数据——一份 CSV、一个数据库副本、一组 API 返回的原始记录。买方拿到的是数据本身。
Token 化的数据服务模式彻底改变了这一逻辑:数据通过训练、微调、RAG 等方式融入模型和智能体的能力中,消费者获取的不是原始数据,而是基于数据产生的推理能力——以 Token 为单位计量、按调用量付费。
这不仅仅是商业模式的变化,而是数据价值实现方式的根本转向:
| 维度 | 传统数据交易 | Token 化数据服务 |
|---|---|---|
| 交付物 | 原始数据集 | API 调用 / 智能体响应 |
| 计价方式 | 一次性买断或包年 | 按 Token 用量(元/千 Tokens) |
| 隐私保护 | 弱——数据直接暴露 | 相对强——数据不以原始形态流出 |
| 价值验证 | 事前评估,风险大 | 事后验证,按效果付费 |
| 复用收益 | 数据可被无限转售,卖方失去控制 | 每次调用都产生收益,卖方持续获益 |
| 场景适配 | 买方自行加工适配 | 模型/智能体已完成场景适配 |
2.2 Token 经济的爆发式增长
这个转变正在以惊人的速度发生。中国日均 Token 调用量的增长轨迹描绘出一条指数曲线:
| 时间 | 日均 Token 调用量 | 增长倍数 |
|---|---|---|
| 2024 年初 | ~1000 亿 | 基线 |
| 2025 年底 | ~100 万亿 | 1000× |
| 2026 年 3 月 | >140 万亿 | 1400× |
2026 年 3 月,国家数据局局长刘烈宏正式将 Token 定名为 "词元",将其定义为"连接技术供给与商业需求的结算单位"——这是官方首次将 Token 确认为一种价值锚点,具有可计量、可定价、可交易的特征。
在商业层面,Agent 时代的 Token 消耗量级已经从 Chatbot 时代的"对话级"跳跃到"机器自循环执行级"。单轮对话消耗约 1000-3000 个 Token,而复杂 Agent 任务可达百万级。某头部模型企业创下了 20 天收入超越 2025 年全年总收入的纪录——Token 经济的"飞轮"已经转起来了。
2.3 为什么 Token 能绕开数据交易的死结
回到 1.2 节的五个根本矛盾,Token 化模式对每一个都给出了不同的回应:
- 非竞争性 → 数据融入模型后无法被直接提取和复制,每次调用都产生边际收益
- 信息不对称 → 消费者可以先小量调用测试效果,按质量后付费
- 定价困难 → Token 按用量自然定价,无需事先评估数据的"潜在价值"
- 确权模糊 → 数据的价值通过 Token 收入间接实现,不涉及数据本身的转让
- 合规焦虑 → 数据不以原始形态流出,大幅降低直接泄露风险
用一个类比来说:传统数据交易像卖矿石——买家拿走了石头,卖家就没有了。Token 化数据服务像卖电——煤炭(数据)在电厂(模型)中燃烧,消费者按度(Token)付费,原材料从未离开卖方。
三、核心架构:数据如何变成 Token
理解价值转化的具体路径,需要拆解数据从"静态资产"到"动态能力"的三条主要通道。
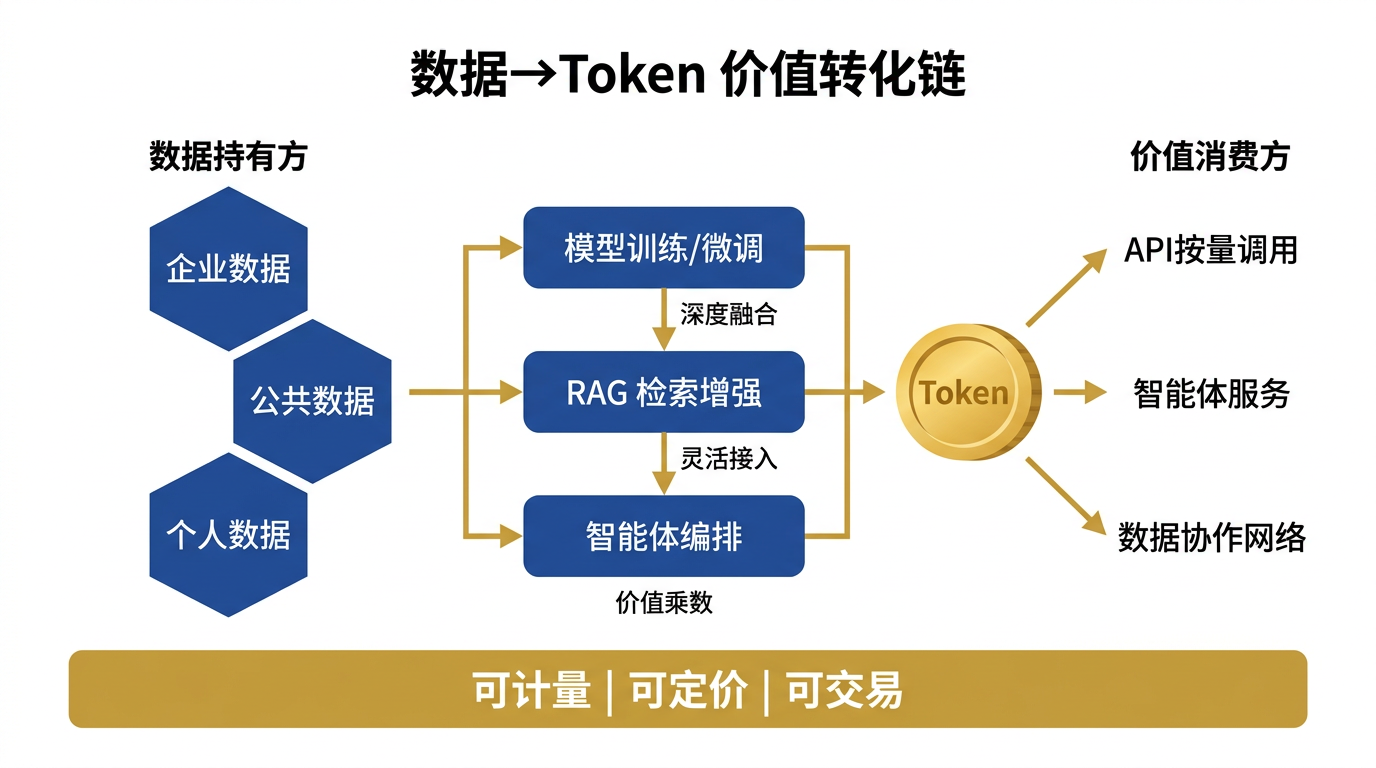
3.1 通道一:模型训练与微调
数据通过预训练或领域微调"固化"到模型权重中。这是最深度的融合方式——数据的统计模式被模型参数永久吸收。
价值释放方式:模型以 API 形式对外提供推理服务,按 Token 计费。阿里云 Qwen-Turbo 的定价为输入 0.0003 元/千 Tokens、输出 0.0006 元/千 Tokens。
典型场景:Bloomberg 将金融数据注入专用模型,通过 Snowflake Marketplace 以 API 形式提供给 600+ 资管客户。
3.2 通道二:RAG 检索增强
数据不进入模型权重,而是存储在向量数据库中,在推理时被检索和注入上下文。这是最灵活的方式——数据可以实时更新,无需重新训练。
价值释放方式:每次检索 + 推理消耗的 Token 量远大于纯模型调用(因为上下文窗口被检索文档占据),数据提供方可按检索命中次数或 Token 增量分成。
典型场景:企业知识库智能体,将内部文档、合同、规章制度通过 RAG 接入,按员工查询次数计费。
3.3 通道三:智能体编排
多个数据源通过智能体间的协作实现价值组合。A 企业的行业知识 + B 企业的用户画像 + C 企业的实时数据,在 Agent 编排中交叉调用。
价值释放方式:Token 流转链路本身记录了各数据源的贡献比例,理论上可实现自动化的收益分配。
典型场景:国家数据局提出的"数据换数据""数据换服务""数据换模型"等多元交换方式,本质上就是智能体编排时代的数据协作模式。
四、不可忽视的安全维度
Token 化模式大幅降低了原始数据直接暴露的风险,但安全问题并没有消失——它从"数据层"迁移到了"模型层"和"推理层"。在全力拥抱 Token 经济的同时,需要对新风险保持清醒认知:
| 风险类型 | 攻击原理 | 关键数据 |
|---|---|---|
| 模型反演 | 从模型输出逆向还原训练数据 | 2025 年在 Llama 3.2 上成功提取 PII |
| 成员推断 | 判断某条数据是否用于训练 | ICLR 2026 提出 Membership Decoding,检测率提升 2-3× |
| 向量反演 | 从 Embedding 重构原始文本 | Vec2Text 对 32-token 输入实现 92% 精确恢复 |
| 提示注入 | 在外部数据中嵌入恶意指令 | 商业智能体端到端窃取成功率 85%,人类检测率 0% |
| 供应链传播 | 多智能体链路中逐级渗透 | Databricks DASF v3.0 新增 35 项智能体安全控制项 |
| 聚合推断 | 大量调用拼凑完整画像 | 类似差分隐私中的"隐私预算"耗尽 |
核心判断是:"数据不出域"并不等于安全。模型本身就是数据的一种"有损压缩",压缩率不够高时原始信息就会泄露。但这些风险是可管理的——差分隐私、输出审计、RBAC、TEE 可信执行等技术路径已经存在,关键是在 Token 经济的商业模式设计中将安全成本内化,而非事后补救。
五、核心洞见
洞见1:Token 是数据价值的"一般等价物"
传统数据交易试图给数据本身定价,但数据的价值高度依赖使用场景——同一份数据在不同买方手中的价值可能相差百倍。Token 通过"按用量后付费"的方式,让市场自动发现数据在每个具体场景中的真实价值。正如货币是商品价值的一般等价物,Token 正在成为数据价值流通的一般等价物。国家数据局将其定名为"词元"并赋予"价值锚点"的定位,标志着这一认知已进入政策层面。
洞见2:从"卖矿石"到"卖电"是经济模型的根本跃迁
这不仅是技术路径的变化,而是数据经济学的范式转换。传统数据交易遵循"一次性交付"的矿产逻辑——买方拿走石头,卖方就没有了。Token 化服务遵循"持续供能"的电力逻辑——数据(煤炭)在模型(电厂)中持续转化,消费者按度(Token)付费,卖方从每一度消费中持续获益。这从根本上解决了数据的非竞争性困境。
洞见3:多智能体编排正在创造数据价值的乘数效应
单个数据源的价值是线性的,但多数据源通过智能体编排进行组合时,产生的价值远超各自之和。A 企业的行业知识 × B 企业的用户画像 × C 企业的实时数据 = 任何单一数据源都无法独立提供的决策能力。Token 流转链路本身记录了各数据源的贡献比例,为自动化的收益分配提供了基础设施。这可能催生一个"数据协作网络",类似于电网——每个参与者既是生产者也是消费者。
洞见4:安全风险发生了相变而非消失
Token 化模式大幅降低了原始数据直接暴露的风险,但风险从"一次性泄露"变成了"持续性渗漏"——模型反演、向量反演、提示注入等新攻击向量更隐蔽、更难检测。这不应成为拒绝 Token 化的理由,而是意味着安全成本需要内化到 Token 经济的定价和治理体系中。
六、行业影响:谁的角色在变化
Token 化数据服务的兴起正在重塑数据产业的角色分工。
6.1 数据交易所:从撮合平台到价值枢纽
国家数据局明确要求严控数据交易所数量,并从"撮合交易"的简单功能转向"价格发现、产品开发、生态培育"的综合服务功能。在 Token 经济的语境下,数据交易所的核心价值不再是促成原始数据的买卖,而是:
- 建立 Token 收入在数据贡献方之间的分配规则
- 提供数据质量到模型能力的映射评估
- 运营数据协作网络,促成多方数据的智能体编排
6.2 数据商:从"持有数据"到"炼化能力"
国家数据局的新文件中首次明确了"数据商"的定位——深入行业开发高质量数据集,提供采集、加工、流通服务。在 Token 经济中,数据商的核心竞争力从"持有数据"转向"将数据转化为高质量 Token 能力"。面向 AI 的高质量训练数据集开发、领域微调服务、RAG 知识库构建成为重点赛道。数据商正在变成"数据炼化厂"——输入原始数据,输出模型能力。
6.3 模型/智能体开发者:新一代"数据中间商"
在传统数据交易中,数据中间商负责撮合供需。在 Token 经济中,模型和智能体开发者实际上承担了这个角色——他们吸纳数据(通过训练、微调或 RAG),转化为能力(通过模型推理),再以 Token 为单位输出给消费者。这个角色的崛起也带来了新的产业结构问题:大模型厂商是否会成为新的数据价值"中间商",挤压原始数据持有者的收益空间?Token 收入在"数据方 - 模型方 - 应用方"之间如何合理分配?这将是 Token 经济下一阶段的核心博弈。
七、实践入门:不同阶段该做什么
7.1 成熟度分级
| 阶段 | 特征 | 关键行动 |
|---|---|---|
| L1 观察期 | 企业数据仍以传统方式管理 | 梳理数据资产目录,识别可 Token 化的高价值数据 |
| L2 试验期 | 小范围试点 RAG 或微调 | 选择 1-2 个场景构建 POC,验证"数据→Token→收入"闭环 |
| L3 规模化 | 多数据源接入智能体服务 | 建立 Token 收入分配机制,接入数据质量→能力质量评估体系 |
| L4 生态期 | 参与多智能体协作网络 | 运营数据协作网络,探索"数据换数据""数据换模型"等交换方式 |
7.2 常见陷阱
- 用传统思维定价:用"一口价买断"思维给 Token 服务定价,忽视按用量弹性定价的核心优势
- 忽视数据到能力的转化质量:只关注数据量,不关注数据在模型中的转化效果——垃圾进、垃圾出
- Token 收入分配不透明:多数据源共同贡献一次推理结果时,缺乏可追溯的贡献度量和分配机制
- 安全投入滞后于商业扩张:先跑量再补安全,而非将差分隐私、输出审计等成本内化到 Token 定价中
八、未来展望
8.1 Token 定价从"成本驱动"走向"价值驱动"
当前 Token 定价主要基于计算成本(输入/输出 Token 单价),但未来将向价值定价演进——同样消耗 1000 个 Token,基于稀缺金融数据的推理和基于公开网页数据的推理,应有不同的价格。这需要在 Token 计费体系中引入"数据价值系数",让数据持有方从高价值推理中获得更高的分成。
8.2 数据协作网络的形成
随着多智能体编排的成熟,数据提供方之间将从单点交易走向网络化协作。就像电网中每个节点既可以发电也可以用电,数据协作网络中每个参与者既是数据的提供者也是 Token 能力的消费者。国家数据局提出的"数据换数据""数据换模型""数据换场景"等交换方式,就是这个网络的雏形。Token 流转链路将成为这个网络的"结算总线"。
8.3 监管框架扩展到"管推理"
当前的数据保护法规主要围绕数据的收集、存储、传输和删除。Token 化时代需要新的监管维度:模型推理输出是否算"数据处理"?跨境 Token 调用是否构成"数据出境"?Token 收入分配的公平性由谁监管?同时,差分隐私、机器遗忘等安全技术需要从学术成果走向工程化部署,嵌入主流 AI 基础设施。这些问题的答案将决定 Token 经济的边界和速度。
结语
"数据是新石油"这个比喻的真正问题不在于数据不值钱,而在于我们一直试图用卖石油的方式来卖数据。Token 经济给出了一个更自然的答案:不卖石油,卖电。
从 2014 年第一家数据交易所成立,到 2026 年 Token 被官方确立为"价值锚点",数据变现的范式用了 12 年完成一次质的跃迁。安全风险当然存在,但它不应成为拒绝变革的理由——正如电力的普及伴随着触电风险,但人类选择了建设电网而非回到蜡烛时代。
真正的问题不是"Token 能否成为数据变现的方式"——这已经在发生。真正的问题是:当数据的价值不再通过"卖石头"而是通过"卖电"来实现时,谁将成为这个新电网的建设者、运营者和受益者?
参考资料
- 凤凰网财经,《Token 为王,如何打赢 AI 时代"新大宗商品"争夺战?》,2026年3月,https://finance.ifeng.com/c/8rvpxJYri5z
- 国家数据局,《关于培育数据流通服务机构 加快推进数据要素市场化价值化的意见》,2026年2月,https://www.nda.gov.cn/sjj/zwgk/zcfb/0205/20260205185635251370340_pc.html
- 国家数据局,《专家解读 | 强化数据交易所(中心)综合服务功能 推动数据要素价值释放》,2026年2月,https://www.nda.gov.cn/sjj/zwgk/zjjd/0210/20260210161431089609400_pc.html
- 新浪财经,《Token 定名"词元",统一 AI 度量衡》,2026年3月,https://finance.sina.com.cn/roll/2026-03-28/doc-inhspfkw4611001.shtml
- 付熙雯、郑磊,《"场内"数据交易机构缘何成效不佳?——基于"不成熟性"市场失灵视角的实证研究》,WeChat,2025年
- 第一财经,《回到市场找答案:探究数据交易所模式之困》,https://www.yicai.com/news/102507194.html
- Arxiv,《The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis》,2026年2月,https://arxiv.org/abs/2602.10453v1
- Arxiv,《You Told Me to Do It: Measuring Instructional Text-induced Private Data Leakage in LLM Agents》,2026年3月,https://arxiv.org/abs/2603.11862v1
- Arxiv,《Agentic AI as a Cybersecurity Attack Surface: Threats, Exploits, and Defenses in Runtime Supply Chains》,2026年2月,https://arxiv.org/abs/2602.19555v1
- Databricks,《Agentic AI Security: New Risks and Controls in DASF v3.0》,2026年,https://www.databricks.com/blog/agentic-ai-security-new-risks-and-controls-databricks-ai-security-framework-dasf-v30
- Cloud Security Alliance,《The Agentic Trust Framework: Zero Trust Governance for AI Agents》,2026年2月,https://cloudsecurityalliance.org/blog/2026/02/02/the-agentic-trust-framework-zero-trust-governance-for-ai-agents
- Vec2Text,《Inverting Dense Text Embeddings》,https://github.com/vec2text/vec2text
- ICLR 2026,《LLMs Leak Training Data Beyond Verbatim Memorization via Membership Decoding》,https://openreview.net/forum?id=ULqzEEkyxk
- Nature Scientific Reports,《Optimization of cross-institutional medical federated learning framework driven by confidential computing》,2026年,https://www.nature.com/articles/s41598-026-44843-4
- Fraunhofer Institute & Fujitsu,《Removing Corporate Data from AI Models》,2025年,https://www.ien.eu/article/removing-corporate-data-from-ai-models/
- DEV Community,《Your RAG Pipeline is Leaking — 4 Data Leak Points Nobody Talks About》,2026年,https://dev.to/rohansx/your-rag-pipeline-is-leaking-4-data-leak-points-nobody-talks-aboutpublished-false-1obm