AI Tax Map:当 AI 走进生产,13 种隐性成本浮出水面
Deep Research 报告 | 2026 年 4 月 | 面向 AI 工程师、架构师与技术决策者
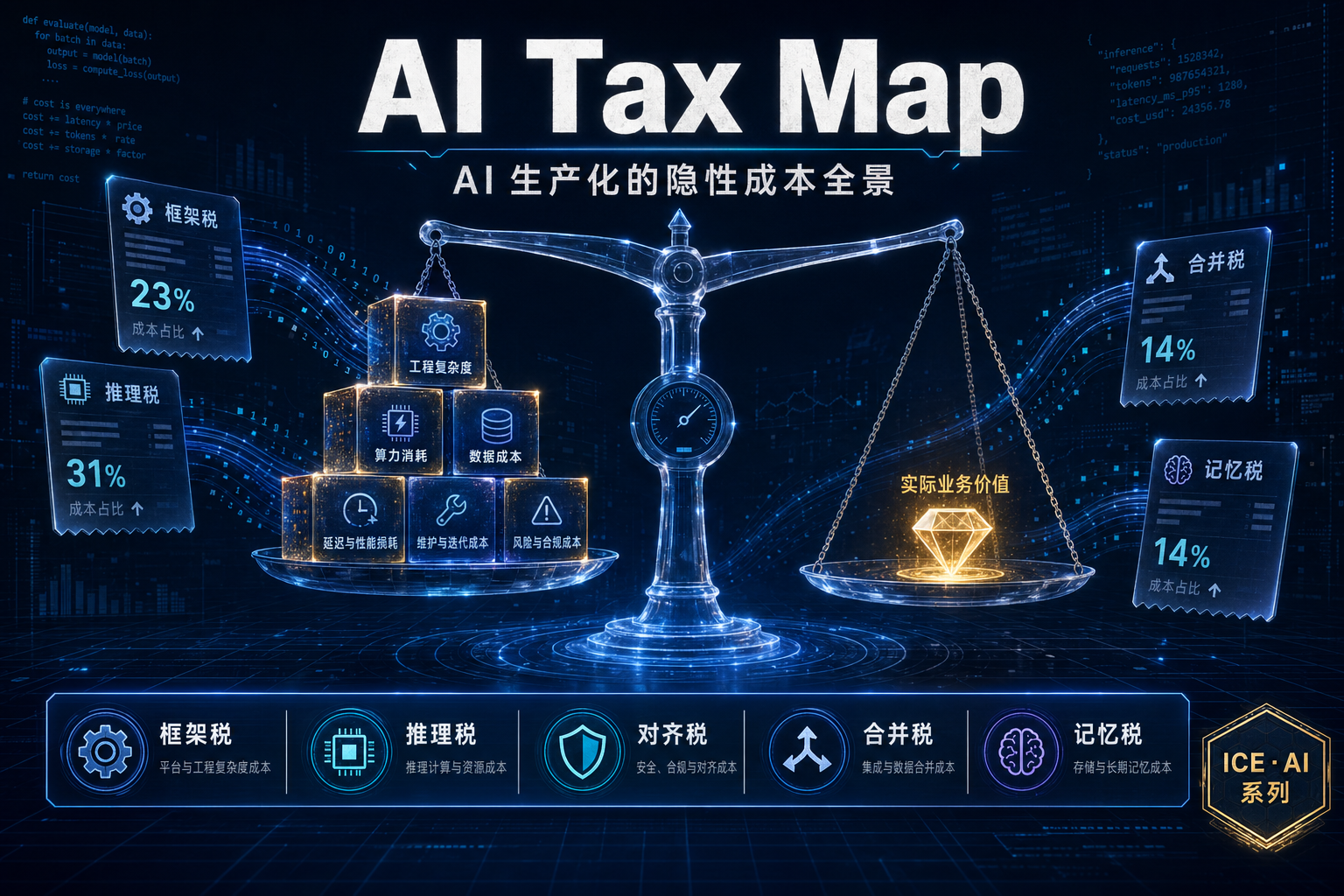
摘要
过去几个月,你有没有注意到一个现象——AI 圈突然开始用"税(tax)"来命名各种问题?
Databricks 说你在交 Builder's Tax,Autonoma 说你在交 Merge Tax,OneUptime 拿着账单告诉你 Observability Tax 已经比基础设施本身还贵了,ICML 把 Alignment Tax 写成了带数学证明的论文,独立工程师们不约而同记录下了 Scaffolding Tax、Token Tax、Coordination Tax。短短一个季度,至少 13 种"税"被正式命名。
巧合吗?不是。78% 的 Global 2000 企业已经把 AI 送进了生产环境,pilot 到 production 的中位周期从 11 个月压到了 4.2 个月。当 demo 变成日常,一系列之前完全感知不到的成本,突然变成了账单上的真实行项。就像一个人从学生变成上班族,直到拿到第一张工资条,才发现"税前"和"税后"之间的差距有多大。
本文做三件事:先画出完整的 AI Tax 地图(13 种税,6 个架构层),再回答为什么"税"在 2026 年集中爆发,最后给出判断——哪些税可以减免,哪些是结构性的。
一、先看全貌:AI 生产环境的隐性成本分层
一个 AI 生产系统从基础设施到业务运营共六层。下面这张架构图把 13 种税映射到了对应的层——没有任何一层是免税的。
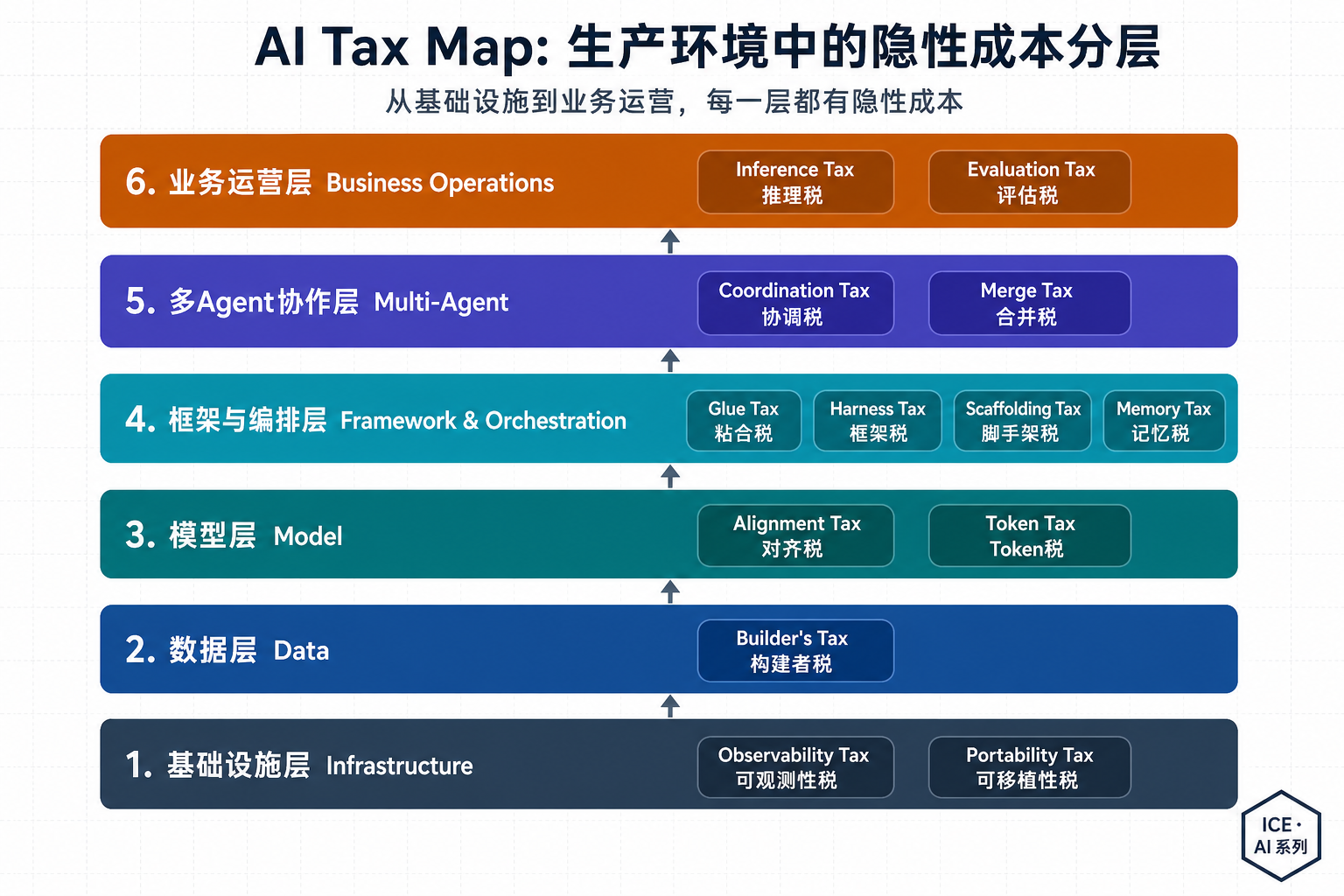
| 层 | 税种 | 核心成本 | 谁提出的 | 可否减免 |
|---|---|---|---|---|
| L1 基础设施 | Observability Tax | 监控成本超越被监控对象 | OneUptime, 2026 | 可优化——采样/压缩 |
| Portability Tax | 供应商迁移成本 | 工程社区, 2026 | 可减——抽象层/标准化 | |
| L2 数据 | Builder's Tax | 数据管道冗余 | Databricks, 2025 | 可减——统一 Lakehouse |
| L3 模型 | Alignment Tax | 安全对齐的能力代价 | AI 安全社区, 2023— | 结构性,不可消除 |
| Token Tax | 上下文窗口静默消耗 | 工程社区, 2026 | 可优化——动态工具加载/缓存 | |
| L4 框架与编排 | Glue Tax | 胶水代码 | 社区共识 | 可减——统一协议(MCP/A2A) |
| Harness Tax | 框架 Prompt 注入 | Agent 社区, 2026 | 可优化——Context Engineering | |
| Scaffolding Tax | 生产化基础设施 | 工程社区, 2026 Q1 | 部分可减——平台抽象 | |
| Memory Tax | 长程记忆运维开销 | Memanto, 2026 | 可替代——轻量化方案 | |
| L5 多 Agent | Coordination Tax | 多 Agent 同步开销 | Google/MIT, 2026 | 部分可减——减少 Agent 数量 |
| Merge Tax | 代码合并冲突 | Autonoma, 2026 | 部分可减——架构隔离 | |
| L6 业务运营 | Inference Tax | 推理边际成本 + 延迟成本 | 行业共识 | 可优化——路由/缓存/蒸馏 |
| Evaluation Tax | 人类验证瓶颈 | 学术界 (HKU), 2025 | 结构性,当前不可消除 |
有了全貌,接下来从底向上逐层拆解——每种税是什么、多大规模、为什么会发生。
二、13 种税逐层拆解
Layer 1 · 基础设施层
你还没写一行业务代码,账单就已经开始跑了。
Observability Tax(可观测性税)。 想象一下:你租了一间公寓,搬进去才发现物业费比房租还贵。这就是 AI 时代的监控成本。传统 SaaS 的监控占云支出 3%—7%,大家觉得能接受。但 AI 负载彻底改写了这个数字——Vector Search 和 LLM Tracing 产生的遥测数据量是传统服务的 10—50 倍,每次推理都要记录 tokens、embedding 向量、chain-of-thought 追踪、评估指标、重试日志。Datadog 等厂商最新财报显示,AI 客户的监控占比已冲击 15%—20%。这笔税从"附加费"变成了"燃油费"——车不加油跑不了,系统不监控就是裸奔。100 人工程团队的年度可观测性支出:$708,000—$1,080,000。
Portability Tax(可移植性税)。 换模型有多难?比你想象的难十倍。表面上看,各家 API 大同小异,一下午就能适配。实际上呢?Claude 偏好 XML 结构、GPT 偏好 Markdown 格式、Gemini 偏好显式结构化推理——仅 Prompt 格式变化就能导致精度波动 76 个百分点。再加上评估套件锁定(你的 Eval 是针对旧模型调的,换了模型全部失灵)、Tool Calling Schema 不兼容(跨供应商错误率 15%)、分词器差异导致分片策略绑定……一家医疗创业公司在同一供应商内部的模型迁移就花了 400+ 工程小时。实际迁移通常消耗原始开发时间的 20%—50%。
Layer 2 · 数据层
基础设施铺好了,该喂数据了。但数据管道本身就是一台"税收机器"。
Builder's Tax(构建者税)。 Databricks 推出 Lakebase 时给这笔账算了一遍:生产数据库(Postgres)和分析环境(Data Lake)分开跑,中间靠 ETL 管道搬运数据,搬完还要 Reverse ETL 搬回去。开发者 60%—80% 的精力花在搬运和同步上,而不是写业务逻辑。就好比你开了一家餐厅,八成时间不是在做菜,而是在仓库和厨房之间来回搬食材。Lakebase 的思路是让应用直接在 Lakehouse 里读写,通过 Unity Catalog 统一治理——把仓库和厨房打通,从根上消灭搬运这件事。
Layer 3 · 模型层
数据准备好了,模型该干活了。但模型不是听话的工具——它有自己的"体质",而这种体质自带两种税。
Alignment Tax(对齐税)。 你让模型更安全,模型就变得更笨。这不是 bug,是数学。ICML 2025 的 OR-Bench 用 32 个模型和 80,000 条提示词做了验证:安全有效性与误拒率的 Spearman 相关系数达 0.878。Claude-3-Opus 在困难场景下误拒了 91% 的安全提示词——十个正常请求,九个被拦住。arxiv 今年发表的数学框架论文更狠:对齐税由安全子空间与能力子空间的主角(principal angles)决定,存在不可消除的下限。把对齐 reward 从 0.16 推到 0.35,SQuAD F1 掉 16 个百分点、翻译 BLEU 掉 5.7。安全和能力之间不是此消彼长的权衡题,而是结构性的零和博弈。
Token Tax(Token 税)。 你以为 128k 的上下文窗口很大?等你把系统提示词、50 个工具的 schema、聊天历史、RAG 上下文、安全前置指令全塞进去,才发现用户的真正查询只剩下 40%—70% 的空间。50 个工具的 schema 就吃掉 128k 窗口的 45%(约 55,000 tokens),而这些工具大部分这次根本不会被调用。更要命的是 Agentic 工作流——每一步 tool call 的历史都追加到上下文里,成本增长不是 O(N),而是 O(N²)。实测:一个 10 步 Agent 循环,从 9,000 tokens 膨胀到 472,000 tokens。43 倍。
模型层的核心矛盾:Alignment Tax 是"安全越高,能力越低";Token Tax 是"功能越多,有效窗口越小"。两者都是模型的内在约束,应用层绕不过去。
Layer 4 · 框架与编排层
模型有能力了,但不能裸跑——你需要框架来编排它、脚手架来托住它、胶水来粘合它、记忆来延续它。这一层是整张税单上条目最多的一层,4 种税挤在一起,因为所有"让模型在生产环境中可用"的脏活累活都在这里发生。
Glue Tax(粘合税)。 你的 Agent 要调数据库,要调外部 API,要跟另一个 Agent 对话,还要把结果吐回前端。没有统一协议的时候,每接一个组件就多写一层适配器。MCP 和 A2A 协议的涌现,本质上是在尝试把粘合税从"每个团队自己交"变成"协议层统一减免"——就像 HTTP 当年让所有 Web 应用不再各写一套网络通信协议。
Harness Tax(框架税)。 同样写一个斐波那契脚本,重型 Agent 框架消耗 80k tokens(大部分是框架指令),轻量框架只需 8k。多出的 10 倍消耗就是框架税。但这笔账不能只看单次——没有 Harness 引导,Agent 上来先"东张西望"好几轮,纯粹浪费 token。就像你嫌导航 App 吃流量,结果不开导航绕了三倍的路。判断框架税的正确方式不是看绝对值,是看 ROI。
Scaffolding Tax(脚手架税)。 2026 年 Q1 讨论热度最高的税种。你以为加一个 AI 功能就是调个 API 的事?Token 计数与预算管控、多供应商抽象与故障切换、重试/熔断机制、Prompt 版本管理、非确定性输出的测试框架、安全审计日志——这些跟 AI "智能"一点关系都没有,但缺任何一个都上不了线。跟踪调查显示,团队 72% 的工程精力花在了这些脚手架上。Forrester 的调研更扎心:67% 的企业工程负责人说,生产 AI 的实际成本超出上线前预估 40% 以上。
Memory Tax(记忆税)。 让 Agent 拥有长程记忆,听起来很美好。现实是什么?向量库不够加图数据库,单路检索不够上多查询+反思循环,基础设施越堆越重。Mem0 的图增强版 Mem0g 相比基础版准确率只提升了 1.5 个百分点,但写入延迟从 500ms 涨到 2s,还多了一套 Neo4j 要维护。就像你为了"住得更好"不断加装修,到最后发现每月维护费已经超过了房租。真正的记忆税不是"记不住",而是"为了记住"所付出的延迟、成本和脆弱性。
Layer 5 · 多 Agent 协作层
一个 Agent 的税在前四层已经够多了。然后你说:要不多上几个 Agent,并行干活?恭喜,解锁新税种。
Coordination Tax(协调税)。 Google 和 MIT 的联合研究给出了冷水数据:在典型多 Agent 工作流中,42% 的时间花在协调而非实际工作——上下文序列化、能力发现与路由、冗余上下文传输。但更致命的是错误放大:独立多 Agent 系统将错误放大 17.2 倍,即便集中式架构也有 4.4 倍。就像一间会议室,3 个人讨论效率最高,10 个人坐进去,一半时间在听别人说话,另一半时间在重复自己说过的话。
Merge Tax(合并税)。 由 Autonoma 命名,刺穿了一个幻觉:"AI Agent 让开发更快了"。快的是单个任务,但多个 Agent 并行改同一个代码库时,集成冲突的修复成本按 N(N-1)/2 增长。73% 的工程负责人承认,采用 AI Agent 后交付延迟反而增加了。5 个并行 Agent,冲突开始级联;9 个时,Agent 花在解决冲突上的时间比写代码还多。
这两种税背后是同一条铁律:并行不免费,而且代价不是线性增长的——它是爆炸式的。
Layer 6 · 业务运营层
终于,系统上线了,用户来了。你以为可以开始数钱了?不好意思,最后两种税才刚开始收。
Inference Tax(推理税)。 传统 SaaS 的美妙之处在于:用户越多,边际成本越低,利润越高。AI 把这条曲线翻了个个儿——每一次用户交互都在烧 GPU。Token 单价两年内降了 50 倍,但企业 AI 支出同期增长了 320%。杰文斯悖论完美重现:油价越便宜,大家开得越多,总油费反而更高。 40% 的 AI Agent 项目预计将在 2027 年前因成本超支取消——注意,Gartner 说的是"经济性问题",不是"技术问题"。
但推理税不只是钱的问题。还有一层常被忽略的延迟税(Latency Tax):为了用更强的推理模型(比如从轻量模型升级到深度思考模型),每一次调用多花数百毫秒到数秒。对大多数应用这是体验问题;但在量化交易的世界里,每一毫秒的延迟都是在向"胜率"交税——更准的判断和更快的执行之间的张力,让推理税变成了"双重征税":既收钱,也收时间。
Evaluation Tax(评估税)。 AI 写一篇报告 30 秒,你验证一篇报告 30 分钟。这个速度差 60 倍的不对称,在规模化之后变成一堵墙。行业估算,与幻觉相关的验证成本约 $14,200/员工/年。而未经评估的 Agent 输出导致的 token 浪费(重试、循环、错误传播)通常是有效消耗的 5—20 倍。评估税不只是人力成本——它是整个 AI 系统的信任基础设施。没有它,其他 12 种税的优化都是沙上建塔。
三、为什么是"税",为什么是现在
13 种税已经逐层摊开。但有一个问题比"有哪些税"更重要:这些成本一直存在,为什么偏偏是 2026 年,大家突然开始叫它"税"?
因为在 demo 阶段,没有人管它叫税——那时候叫"投入"。
| 指标 | 2024 Q1 | 2026 Q1 | 变化 |
|---|---|---|---|
| Global 2000 中有 AI 生产工作负载的企业 | 41% | 78% | +90% |
| Pilot 到 Production 中位周期 | 11 个月 | 4.2 个月 | -62% |
| 企业 AI 年度支出 | ~$150B | $247B | +64% YoY |
| 报告成本超预期的企业 | — | 96% | — |
| 报告可量化 ROI 超过 TCO 的企业 | — | 23% | — |
团队小、请求少、账单低、没有 SLA 约束的时候,花在基础设施、监控、同步上的钱都叫"投资"。一旦进入生产——日活用户从 100 到 100,000,Agent 从单个到编排集群,数据从样本到全量——同样的支出变成了"税"。因为它们是持续的、非可选的、不直接产出业务价值的。就像个体户转企业,营收翻了十倍,但突然发现税务局也来了。
深挖下去,13 种税指向三个结构性断裂:
断裂一:边际成本不为零了。 传统软件的核心假设是"开发一次,服务千万人"——SaaS 的高毛利、per-seat 定价、"增长即盈利"都建立在边际成本趋于零之上。AI 把这条曲线翻了过来。每一次推理烧 GPU,每一轮 Agent 循环重读整个上下文,每一层护栏增加误拒率。per-seat 模型正在崩溃(份额从 21% 降至 15%),混合订阅+用量模型成为主流(从 27% 升至 41%)。Inference Tax、Token Tax、Evaluation Tax 都是这条曲线翻转的直接后果。
断裂二:复杂度是乘法,不是加法。 Coordination Tax 的 17.2 倍错误放大、Merge Tax 的 N(N-1)/2 冲突面、Token Tax 的 O(N²) 增长——传统软件工程靠"分治、解耦、并行"活了几十年,但这套直觉在 AI 系统中部分失效了。并行不总是更好,解耦不总是更便宜,加组件不总是加能力——有时候是加税。
断裂三:安全和能力互斥。 Alignment Tax 有数学证明的不可消除下限。Evaluation Tax 反映的是人类 30 分钟验证 vs AI 30 秒生成的速度不对称。这两种税不是工程问题,而是这一代 AI 技术的内生约束——就像热力学第二定律:你可以设计更好的引擎,但永远不可能消灭摩擦。
一句话总结:前两个断裂是"工程债",可以用更好的架构、协议和工具来减免;第三个是"物理定律",只能管理,不能消灭。
四、对从业者的三个判断
知道了从哪交税,下一步是怎么少交。
先分清哪些税能减,哪些不能。 Scaffolding Tax、Glue Tax、Builder's Tax 是架构选择题——换一种架构就能大幅减免,Databricks 的 Lakebase、MCP 协议、平台化 Agent 框架都在干这件事。但 Alignment Tax 和 Evaluation Tax 是物理定律级别的内生约束,别指望靠架构优化消灭。对这类税,正确的姿势不是"减免"而是"预算化"——像房租一样,提前算进 TCO,不要事后惊讶。
Token Tax 是当前最容易"退税"的一笔。 Prompt 缓存能砍掉 90% 的成本(Anthropic prefix caching: $3.00/M → $0.30/M),同时延迟降 75%—85%。动态工具加载把一个团队的工具开销从 134,000 tokens 干到 8,700(降 85%)。这些都是不改核心逻辑、纯基础设施层面的操作,投入产出比极高——如果你只能优化一种税,先从这里下手。
多 Agent 要克制。 Coordination Tax 的数据非常清醒:42% 的协调开销、17.2 倍的错误放大。在同一代码库内并行 5 个以上 Agent,冲突级联就开始失控。比起"堆更多 Agent",更聪明的做法是跨项目并行、单项目串行——或者干脆减少 Agent 数量,把单个 Agent 的能力上限拉高。
结论
"税"在 2026 年集中爆发,不是术语通胀,而是一个转折点的信号:AI 正在从"能不能做"过渡到"做得起不起"。
78% 的企业走进了 AI 生产环境,但只有 23% 看到了可量化的回报。中间这 55 个百分点的鸿沟,就是 13 种税的总和——你的账单在增长,你的 ROI 还在找。
传统软件时代,赢家是跑得最快的团队,因为边际成本为零,比的是谁先交付。AI 时代的游戏规则变了:边际成本不为零,赢家不再是跑最快的人,而是税交得最少的人。
参考资料
- Databricks. How leading tech companies are killing the builder's tax with Lakebase. Databricks Blog, 2025-2026. https://www.databricks.com/blog/how-leading-tech-companies-are-killing-builders-tax-lakebase
- Mamoor Ahmad. The AI Scaffolding Tax: The Hidden 70% Nobody Warns You About When Building with LLMs. dev.to, 2026. https://dev.to/mamoor_ahmad/the-ai-scaffolding-tax-the-hidden-70-nobody-warns-you-about-when-building-with-llms-4hfo
- Iris. The AI Eval Tax: The Hidden Cost Every Agent Team Is Paying. iris-eval.com, 2026. https://iris-eval.com/blog/the-ai-eval-tax
- Autonoma. The Merge Tax: What AI Agent Conflicts Cost You. getautonoma.com, 2026. https://getautonoma.com/blog/ai-agent-merge-tax
- Tian Pan. The Alignment Tax: When Safety Features Make Your AI Product Worse. tianpan.co, 2026-04-20. https://tianpan.co/blog/2026-04-20-alignment-tax-product-ai-safety-guardrails
- arxiv. What Is the Alignment Tax? arXiv:2603.00047v2, 2026. https://arxiv.org/html/2603.00047v2
- Tian Pan. The Hidden Token Tax: How Overhead Silently Drains Your LLM Context Window. tianpan.co, 2026-04-11. https://tianpan.co/blog/2026-04-11-hidden-token-tax-production-llm-pipelines
- George Thomas. The Multi-Agent Coordination Tax: Why Your AI Agents Are Slower Than You Think. Medium, 2026-02. https://medium.com/@georgethomasm_89397/the-multi-agent-coordination-tax-why-your-ai-agents-are-slower-than-you-think-1b88d7cd74ea
- OneUptime. The Observability Tax: When Monitoring Costs More Than Infrastructure. oneuptime.com, 2026-03-10. https://oneuptime.com/blog/post/2026-03-10-observability-tax-monitoring-costs-vs-cloud-spend/view
- Tian Pan. The Hidden Switching Costs of LLM Vendor Lock-In. tianpan.co, 2026-04-17. https://tianpan.co/blog/2026-04-17-llm-vendor-lock-in-hidden-switching-costs
- Presenc AI. Enterprise AI Adoption Statistics 2026. presenc.ai, 2026. https://presenc.ai/research/enterprise-ai-adoption-statistics-2026
- Seyed Moein Abtahi et al. Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents. arXiv:2604.22085, 2026-04-23. https://arxiv.org/abs/2604.22085
- Zylos Research. AI Agent Cost Optimization: Token Budgets, Model Routing, and Production FinOps. zylos.ai, 2026-04-12. https://zylos.ai/research/2026-04-12-ai-agent-cost-optimization-token-budget-model-routing
- TechAheadCorp. Inference Cost Explosion: Why AI Agent Economics Break At Scale. techaheadcorp.com, 2026. https://www.techaheadcorp.com/blog/inference-cost-explosion/
- Dave Paola. Stop parallelizing your AI agents. The Daily Developer, 2026. https://thedailydeveloper.substack.com/p/stop-parallelizing-your-ai-agents