AI 时代的商业模式:从数据视角出发
产业观察 · 商业模式 × 数据要素 × 数据工程 × AI 原生 | 2026 年 5 月 | 约 15 分钟阅读

序:理智的尽头是智能
人类社会的发展,本质上是一个不断"理智化"的过程——越来越少地依赖直觉、习俗、权威,越来越多地依赖观察、数据、逻辑。理智带来效率,效率带来生产力,生产力定义了文明的阶段。
而理智的底层,是数据驱动决策的不断完善。回望人类几次关键跃迁,每一次都对应着"数据驱动决策"能力的一次飞跃:
| 时代 | 数据驱动决策的飞跃 | 释放出的生产力 |
|---|---|---|
| 农业革命 | 天文历法、节气记录 | 从随机狩猎到稳定耕作 |
| 科学革命(17 世纪) | 实验、观测、可重复数据 | 从经验/权威 → 假说-验证 |
| 第一次工业革命 | 精确测量与工程化(瓦特测算热效率) | 蒸汽机、机械化大生产 |
| 第二次工业革命 | 泰勒科学管理、统计学 | 流水线、规模化制造 |
| 信息革命 | 数字化 + 互联网,决策周期从月到秒 | 全球协同、即时商业 |
| AI 时代 | 数据从"辅助决策"升级为"本体智能" | 智能本身成为可生产、可计价的产品 |
每一次跃迁的本质都是同一件事——让更多的决策、更复杂的决策、更高频的决策,建立在数据之上。
AI 时代是这条路径的最新一站,但也是质变的一站:之前数据是辅助人做决策,现在数据被炼成了能独立做决策的智能。这也是我大力提倡 "数据即智力" 的原因——它不是一个新概念,而是人类理智化进程走到了"数据本身具备认知能力"的临界点。
也正因为如此,AI 时代的商业模式必然围绕数据展开。下文从这个起点出发,按六步展开:AI 在卖什么 → 智力的底层结构 → 钱在哪一层 → 怎么针对不同客户做生意 → 未来格局 → 入局自检。
一、AI 时代到底卖什么
本节要点:从互联网到 AI,商业模式的核心从"卖连接"变成了"卖智能"——而智能的本质是数据。
1.1 互联网时代卖的是"连接"
互联网时代的商业逻辑围绕 流量 → 用户 → 变现 展开:
| 模式 | 代表公司 | 核心逻辑 |
|---|---|---|
| 广告 | Google、Meta | 免费服务换注意力 |
| 平台/佣金 | 淘宝、Uber、美团 | 连接供需,抽佣 |
| 订阅 | Netflix、Spotify | 基础免费 + 高级付费 |
| 电商 | Amazon、京东 | 低价获客 + 物流履约 |
关键特征:边际成本趋近于零、网络效应护城河、赢者通吃。
1.2 AI 时代卖的不是 Token,是"数据驱动的智能"
很多人看到 OpenAI 卖 API 赚钱,就以为 AI 时代的商业模式就是"训模型 + 卖 Token"。这是误判。
Token 只是计价单位,不是商业模式。纯 Token 服务正在快速沦为基础设施薄利赛道:
- 主流模型 API 单价两年内下降一个数量级,仍在下行
- OpenAI、Anthropic、Google、DeepSeek、Qwen 的能力差距在收窄
- 切换供应商成本极低,几行代码的事
- 推理有真实 GPU 成本,不像互联网边际成本趋零
它能赚钱,但赚不到超额利润,也形成不了壁垒——这是寡头薄利的电力/云计算式生意。
真正的卖点是数据驱动的智能:你的数据让模型对某个场景有多懂,决定了用户为什么持续付钱给你。
1.3 一句话核心:数据即智力
数据即智力——但这里的"数据"是泛数据,是一个广义概念。
把它展开就是:数据即智力 = 数据原料 × 数据工程 × 反馈闭环
三轮齿合,缺一不可。赢家不是数据原料最多的,也不是 Token 最便宜的,而是把这三个齿轮整合得最好的玩家。
下一章我们就把这三个齿轮拆开看。
二、智力的底层框架:三轮齿合
本节要点:把"数据即智力"中的"数据"拆成三个相互齿合的齿轮——原料、工程、反馈。用 Google vs OpenAI 的真实案例说明:单一齿轮再强也不够,三轮齐备才能赢。
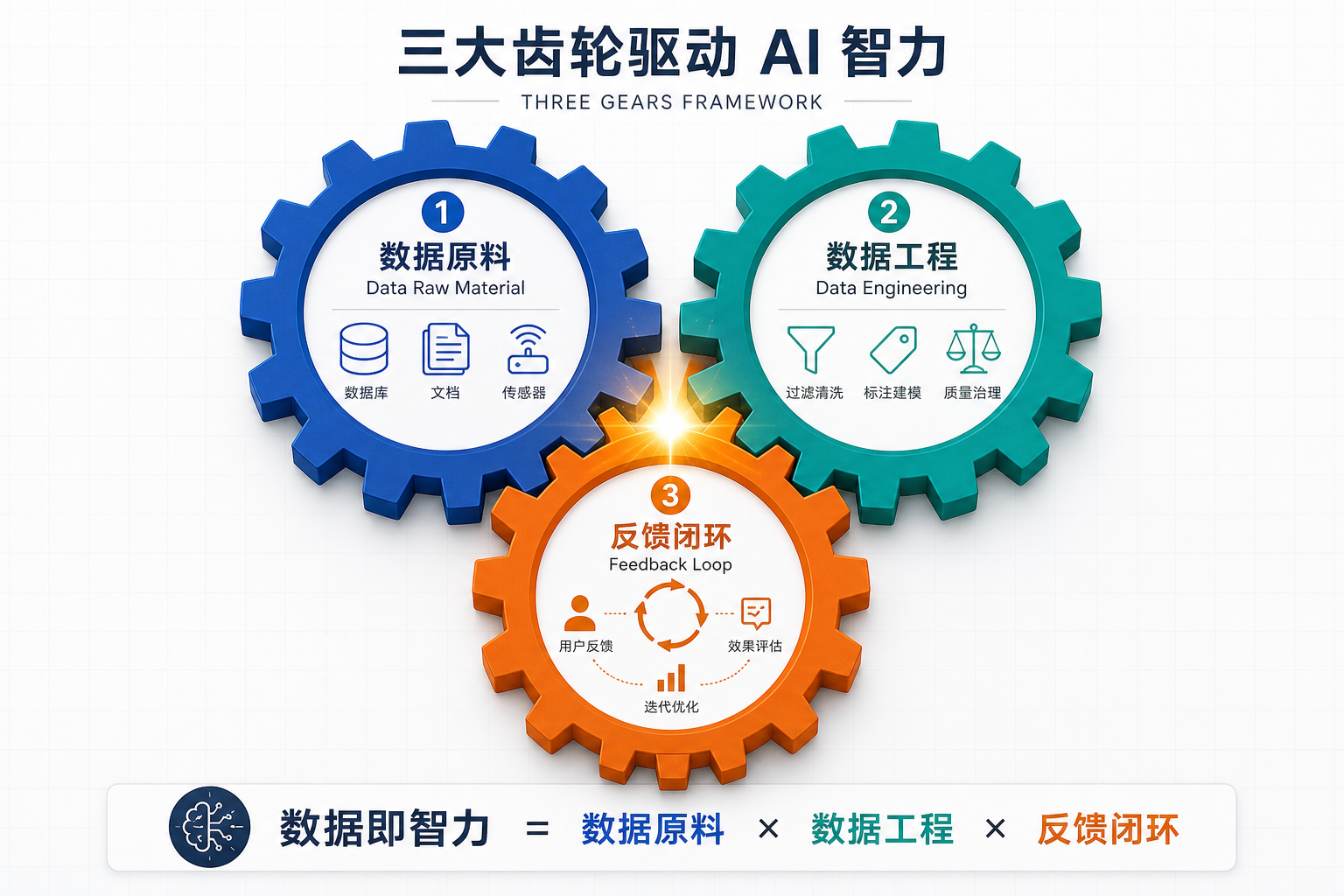
2.1 三个齿轮分别是什么
| 齿轮 | 含义 | 例子 |
|---|---|---|
| ① 数据原料 | 可获取的原始数据 | 网页、书籍、用户日志、行业私有数据、专家知识 |
| ② 数据工程 | 把原料变成可训练资产的能力 | 清洗、标注、配比、对齐、合成数据 |
| ③ 反馈闭环 | 让数据持续更新与改进的机制 | 用户交互回流、A/B 测试、模型在线学习 |
用一个炼油的比喻能更直观:
数据原料是原油,数据工程是炼油厂,反馈闭环是加油站 + 回收管道。原油再多,没有炼油厂只是黑水;炼油厂再大,没有持续的回收管道也会停摆。
2.2 一个案例:Google vs OpenAI 为什么是 OpenAI 赢
三轮齐备的重要性,用一个典型案例就能看清。
如果只看数据原料,Google 应该碾压所有人——它拥有搜索、YouTube、Gmail、Books、Android 这个全球最大的数据帝国。但 2022–2024 年,OpenAI 在大模型能力上一度全面领先 Google。
为什么?把它放到三轮框架里看:
| 维度 | OpenAI | |
|---|---|---|
| 数据原料 | 极强(全球最大数据帝国) | 中等(公开数据 + 采购) |
| 数据工程 | 中(早期被 GPT 路线超越,组织协同较慢) | 强(RLHF 投入早、合成数据领先、配比工程化) |
| 反馈闭环 | 弱(搜索不是对话式反馈) | 极强(ChatGPT 每天数亿次交互回流) |
小贴士:RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是让模型学会"听人话"的关键工程,OpenAI 在 2022 年通过它把 GPT-3 训成了 ChatGPT。
Google 在 ① 上断层领先,但 ② 和 ③ 上一度落后,综合智力被 OpenAI 反超。后来 Google 整合资源做 Gemini,本质就是补齐 ② 和 ③ 的短板。
结论:数据即智力,但数据是泛数据,三轮齐备才是真正的护城河。
2.3 数据原料:不是所有数据都等价
即便在"数据原料"这一个齿轮内部,价值也分层。互联网公开数据已被各家充分爬取吸收,价值趋近于零;真正构成壁垒的,是金字塔上层那些无法从公开渠道获取的数据:
| 层级 | 数据类型 | 商业价值 |
|---|---|---|
| 顶层 | 稀缺的专家决策数据(顶级医生诊断思路、资深律师判断、老工程师工艺参数) | 极高,无法复制 |
| 中层 | 领域私有数据(企业内部流程、行业 know-how、产线数据) | 高,构成壁垒 |
| 底层 | 公开互联网数据(网页、书籍、代码) | 已商品化,无壁垒 |
Tesla 卖车,本质是用户付费帮它采集驾驶数据——这就是典型的"用产品形态把顶层数据采集做成无感"。这种"无感数据采集"能力,比单纯爬数据要珍贵得多。
2.4 数据工程:被严重低估的隐形护城河
如果说数据原料是"原油",数据工程就是"炼油厂"。它至少包含五个关键环节:
| 环节 | 关键能力 | 决定什么 |
|---|---|---|
| 数据清洗与去重 | 大规模文本质量过滤 | 模型基础能力下限 |
| 数据标注 | 大规模人工标注(分类、抽取、问答对、推理链构造) | SFT 阶段模型能学到什么 |
| 数据配比与课程 | 不同数据按什么比例、什么阶段引入 | 模型能力的均衡度 |
| 对齐与 RLHF | 偏好数据集 + 人类反馈强化学习 | 模型的可用性与安全性 |
| 合成数据生成 | 用强模型造数据训弱模型 | 突破数据稀缺瓶颈 |
小贴士:SFT(Supervised Fine-Tuning,监督微调)是预训练之后第一步"教模型听指令"的微调阶段。
数据标注是个被严重低估的独立产业——Scale AI 估值超百亿美金,主营就是给大模型公司提供标注数据;国内的海天瑞声、龙猫数据也都在数十亿规模。这证明:数据工程不是模型公司的"内部杂事",而是一个能独立成生意的护城河环节。
Anthropic 的 Constitutional AI、OpenAI 的 RLHF、DeepSeek 的强化学习路线——这些被外界视为"算法创新"的东西,本质上都是数据工程的创新。
对企业的启示:就算你拥有海量数据,没有数据工程能力,那些数据就是死的。这也是为什么很多坐拥数据的传统行业,反而做不出像样的 AI 应用——他们守着金矿在挨饿。
2.5 反馈闭环:从"产品"到"飞轮"的临界跨越
反馈闭环让前两个齿轮"活起来"。一个 AI 产品有没有反馈闭环,是两个完全不同的物种:
- 没有反馈闭环:交付即终点,模型从发布那一刻起就在贬值
- 有反馈闭环:交付即起点,模型从发布那一刻起越用越好
Cursor、Notion AI、ChatGPT 之所以越用越聪明,不是因为它们模型本身在偷偷升级,而是因为每一次用户的接受/拒绝、每一次修改,都成了下一版模型的训练信号。真正的数据飞轮,本质就是这三个齿轮在持续齿合运转。
三、谁在哪一层赚钱:AI 产业的四层分工
本节要点:把三轮框架投射到产业链,会看到清晰的四层分工。利润最高的不是大众以为的"基础模型层",而是数据工程层和反馈闭环层。
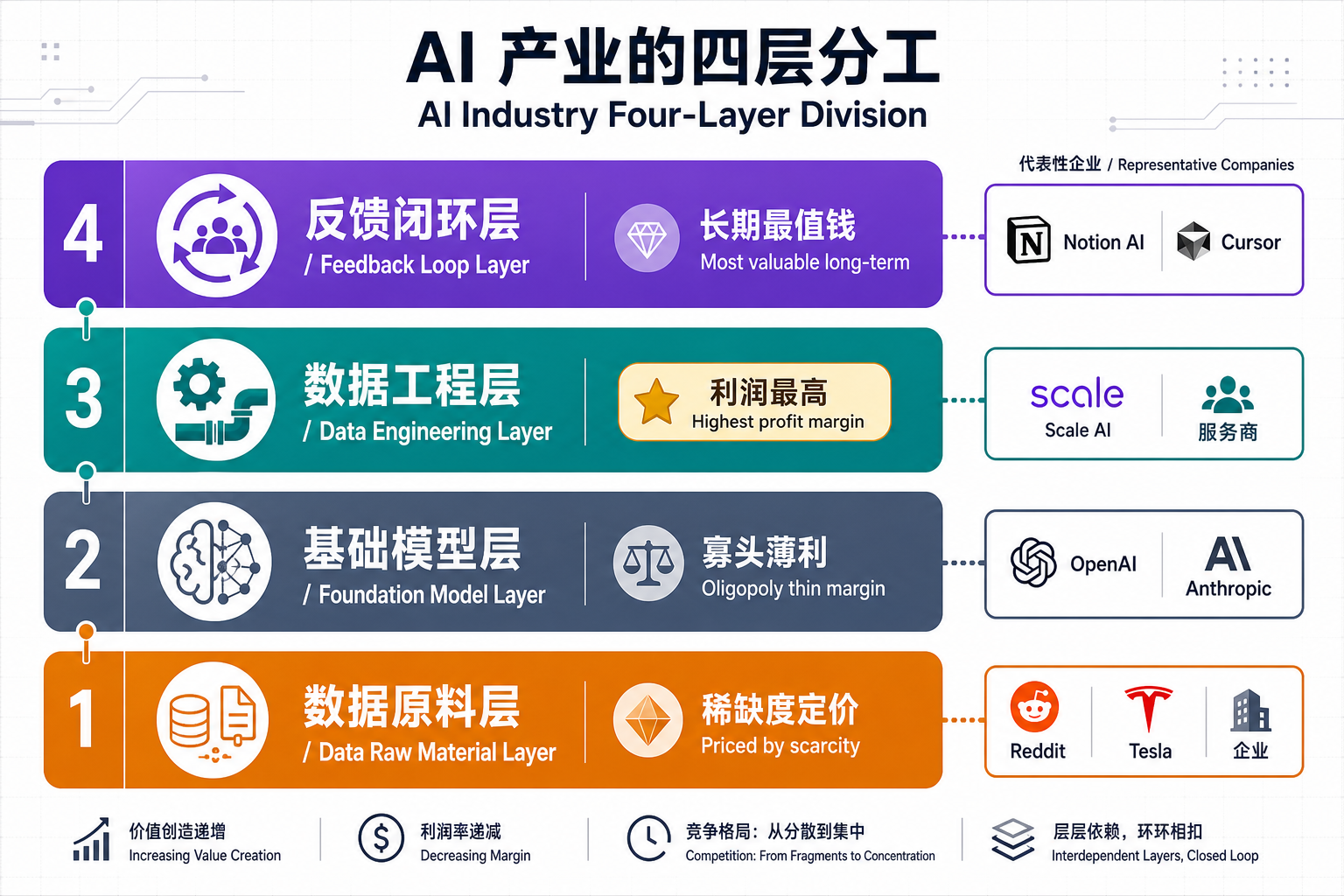
3.1 AI 产业的四层结构
| 层级 | 主要玩家 | 商业模式 | 利润特征 |
|---|---|---|---|
| 数据原料层 | 数据所有者(Reddit、Tesla、医院、企业) | 数据授权、数据交易、数据贡献分润 | 视稀缺度而定 |
| 基础模型层 | 通用大模型公司(OpenAI、Anthropic、Google) | API、订阅、私有化授权 | 同质化、利润被压 |
| 数据工程层 | AI 服务商、模型公司、垂直 AI 创业公司 | 模型微调、RLHF 即服务、数据标注、行业适配 | 利润最高的环节 |
| 反馈闭环层 | 拥有用户入口的产品方 | 数据飞轮型 SaaS、Agent 产品、行业一体机 | 长期最值钱 |
3.2 关键洞察:钱在数据工程层 + 反馈闭环层
传统说法是"应用层赚钱",更准确的说法是 数据工程层和反馈闭环层赚钱——一个是炼油厂,一个是加油站,都比卖原油和卖通用模型更值钱。
为什么?
- 数据原料层:原料本身不稀缺(公开数据已饱和),稀缺的是上层的私有数据,但其所有者往往不擅长直接变现
- 基础模型层:寡头薄利赛道,利润被价格战压缩
- 数据工程层:把原料炼成可用智能的能力极度稀缺,议价能力强(参考 Scale AI 的估值)
- 反馈闭环层:一旦飞轮转起来,护城河近乎不可复制(参考 ChatGPT 的领先地位)
对中小企业的启示:中小企业和行业服务商真正的卖点,不是"卖个 AI 应用",而是替客户搭建数据工程能力 + 反馈闭环。
3.3 数据飞轮怎么转
把三轮齿合做成一个持续运转的系统,就是 AI 时代的"网络效应替代品":
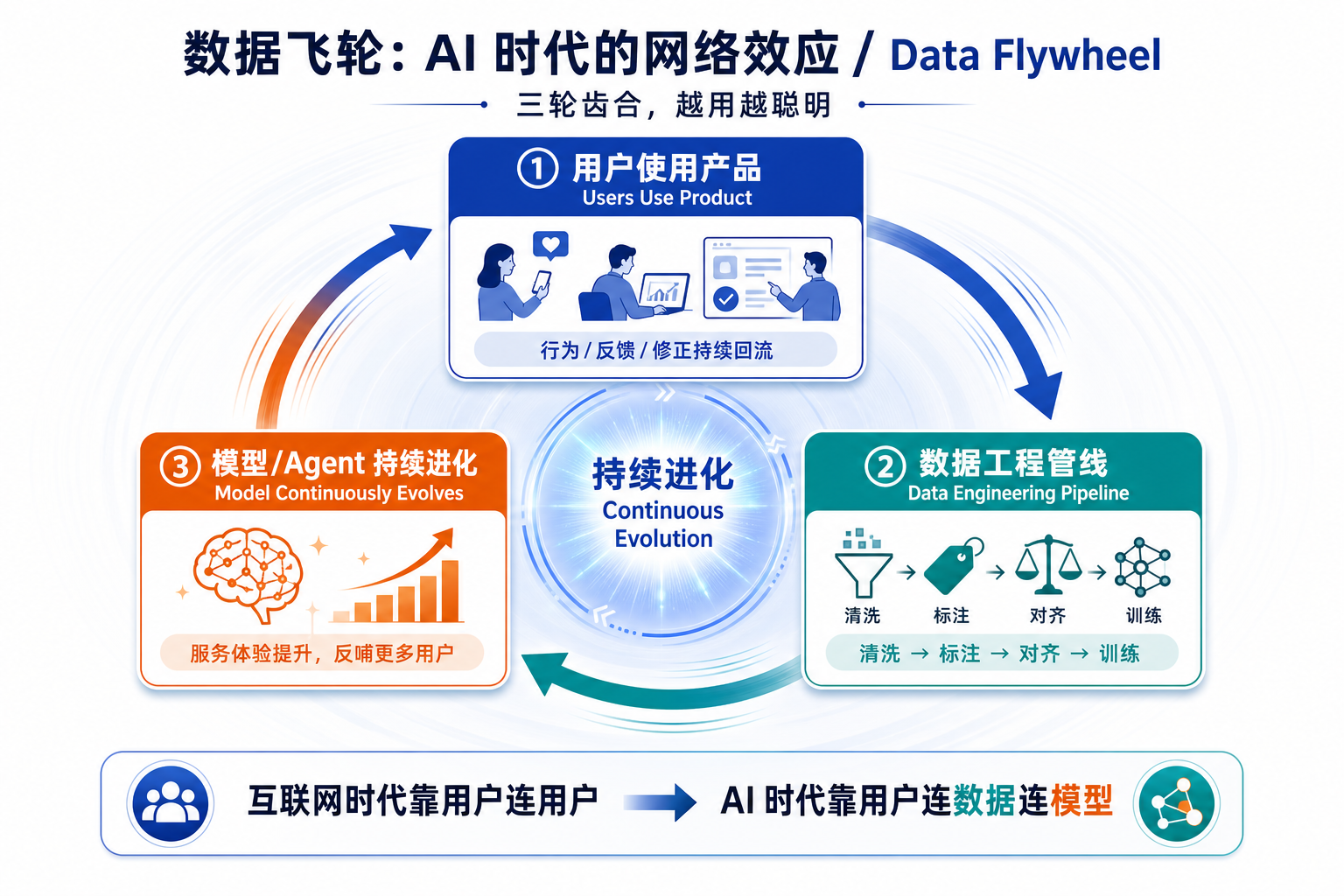
这就是 AI 时代的"网络效应"——互联网时代靠用户连用户产生规模效应,AI 时代靠用户连数据连模型产生认知效应。
3.4 飞轮的两类冷启动
但飞轮启动门槛极高,而且冷启动其实有两类,常被混为一谈:
| 冷启动类型 | 卡点 | 破局方式 |
|---|---|---|
| 原料冷启动 | 没有足够初始数据 | 专家标注硬启动 / 数据合作伙伴 / 设计"无感数据采集"产品 |
| 工程冷启动 | 没有把数据变成智能的能力 | 引入数据工程团队 / 用通用模型 + RAG 临时替代 / 与模型公司深度合作 |
小贴士:RAG(Retrieval-Augmented Generation,检索增强生成)是不微调模型、靠"现查现答"快速给模型"外挂知识库"的轻量方案。
很多创业公司死在工程冷启动上——他们以为搞到数据就能做出 AI,结果数据躺在硬盘里训不出有效模型。这也是为什么"懂数据工程的团队"在当前阶段非常稀缺且值钱。
四、商业模式分层:大客户 / 中小客户 / 行业客户的差异化打法
本节要点:同一套三轮逻辑,对不同客户要用完全不同的交付方式。一刀切的产品形态会同时丢掉大客户的深度和中小客户的广度。这是本文最具落地价值的一章。
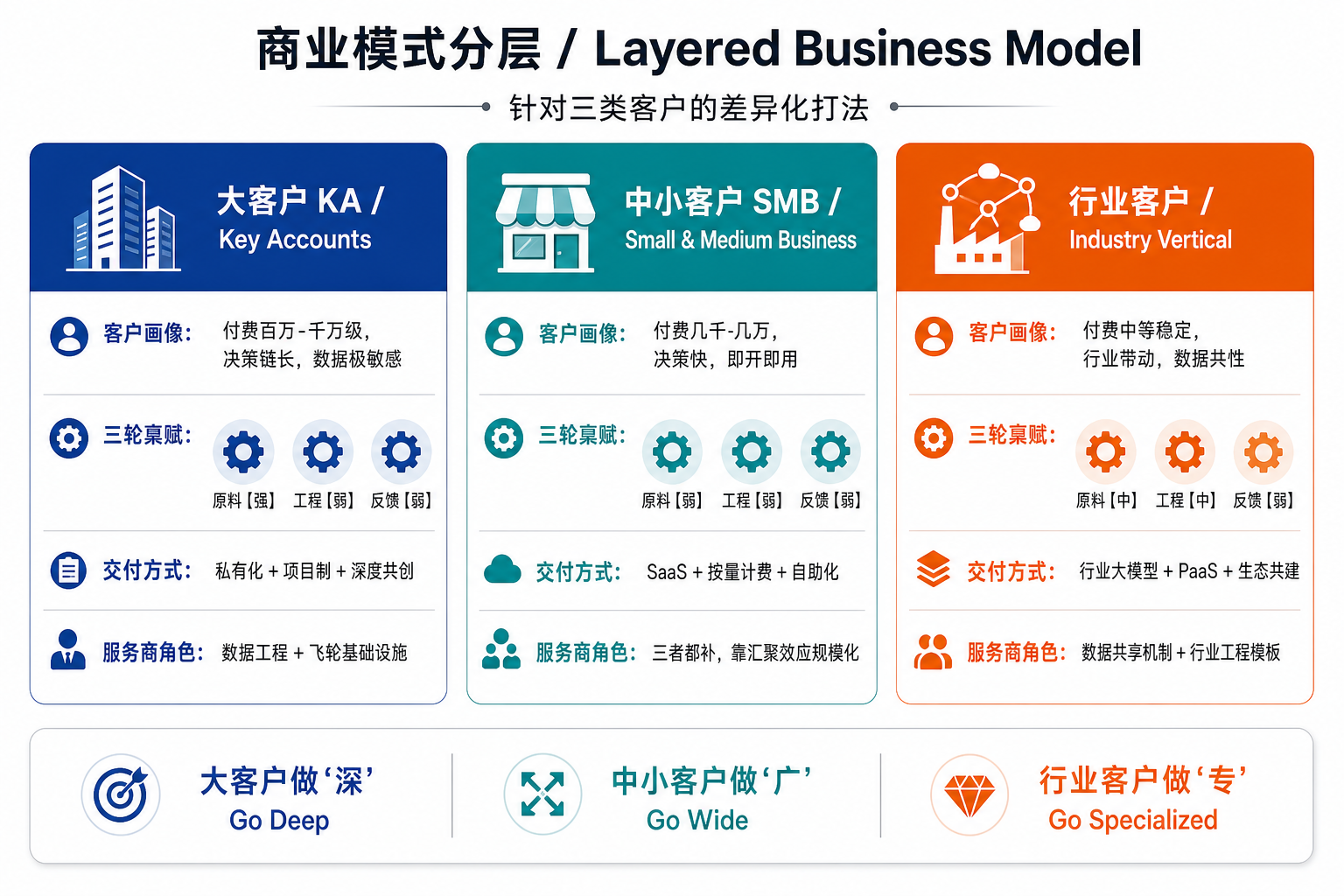
4.1 为什么必须分层:客户在三轮上的禀赋不同
服务商的本质工作,是替客户补齐他缺的那个齿轮——不同客户缺的齿轮不一样:
| 客户类型 | 数据原料 | 数据工程 | 反馈闭环 | 服务商主要补什么 |
|---|---|---|---|---|
| 大客户 KA | 强 | 弱 | 弱 | 数据工程 + 飞轮基础设施 |
| 中小客户 SMB | 弱 | 弱 | 弱 | 三者都补,靠汇聚效应做规模 |
| 行业客户(垂直群体) | 中(分散) | 中 | 弱 | 数据共享机制 + 行业工程模板 |
4.2 大客户:私有化 + 项目制 + 深度共创
典型画像:付费能力百万到千万级,有海量私有数据但极度敏感不可外泄,决策链长(IT/法务/采购多角色),关键诉求是安全合规、专属能力、可控可解释。
服务设计:
| 维度 | 设计 |
|---|---|
| 部署方式 | 私有化、专属云、混合云 |
| 模型形态 | 基础模型 + 客户私有数据微调,飞轮在客户内部转 |
| 定价方式 | 项目制 + 年度服务费 + 数据工程服务包 |
| 服务模式 | 专属客户成功团队、SLA 保障、定期共创 |
| 服务商角色 | 提供数据工程能力 + 飞轮基础设施 |
小贴士:SLA(Service Level Agreement,服务等级协议)是大客户合同中"达不到这个标准就赔钱"的硬指标,比如可用性 99.95%、响应时间 ≤ 200ms。
核心逻辑:大客户买的不是产品,是 "我的数据原料 × 你的工程能力 × 我们共建的反馈闭环 = 我的智能资产" 的共建权。
4.3 中小客户:SaaS + 按量计费 + 自助化
典型画像:付费能力几千到几万,数据少且分散,决策快(老板或部门拍板),关键诉求是开箱即用、低门槛、即时见效。
服务设计:
| 维度 | 设计 |
|---|---|
| 部署方式 | 纯 SaaS、即开即用 |
| 模型形态 | 共用基础模型 + 轻量化场景(Prompt 工程、RAG、Agent 模板) |
| 定价方式 | 订阅 + Token/任务量阶梯定价 + 免费试用 |
| 服务模式 | 自助式、文档社区、模板市场、AI 客服支持 |
| 服务商角色 | 替所有客户统一搭建数据工程管线 + 反馈闭环,汇聚脱敏数据形成"行业小飞轮" |
核心逻辑:单个中小客户的数据没价值,但 1 万个同类客户的脱敏数据 + 服务商的数据工程能力 + 共享反馈闭环 = 一座金矿。Notion AI、Cursor 都是这个套路——千万级用户的使用数据汇聚后,反哺出来的产品体验,单个企业自研永远做不到。
4.4 行业客户:行业大模型 + PaaS + 生态共建
典型画像:付费能力中等但稳定,有行业共性数据但分散在多家企业,决策受行业协会/龙头带动,关键诉求是行业 know-how、合规适配。
服务设计:
| 维度 | 设计 |
|---|---|
| 部署方式 | 行业云、行业 PaaS、与 ISV 联合交付 |
| 模型形态 | 行业大模型 + 行业知识图谱 + 行业 Agent 模板库 |
| 定价方式 | 行业版订阅 + 生态分润 + 数据工程增值服务 |
| 服务模式 | 与行业协会、龙头企业、ISV 共建标准与生态 |
| 服务商角色 | 搭建行业级三轮齿合飞轮,解决数据共享机制、行业工程模板、跨企业反馈闭环 |
小贴士:ISV(Independent Software Vendor,独立软件开发商)和 PaaS(Platform as a Service,平台即服务)共同构成行业生态的关键角色——PaaS 提供底座,ISV 在底座上开发行业应用。
核心逻辑:行业客户的飞轮转不起来,不只是技术问题,更是数据共享机制 + 行业级数据工程标准问题。能把行业里散落的数据拉到一张桌上、并配套通用工程能力的玩家,才能赢。
4.5 三层飞轮的形态对比
不同客户层级的数据飞轮,"形状"是完全不一样的:
| 飞轮类型 | 半径 | 转速 | 壁垒类型 | 形态 |
|---|---|---|---|---|
| 大客户飞轮 | 小(单客户内部) | 快(数据完全可控) | 客户绑定 + 切换成本 | 封闭式 |
| 中小客户飞轮 | 大(覆盖海量客户) | 慢(数据脱敏后汇聚) | 规模效应 + 网络效应 | 汇聚式 |
| 行业客户飞轮 | 中(行业内联盟) | 中(依赖共享机制) | 行业标准 + 准入壁垒 | 联盟式 |
4.6 分层运营三条铁律
- 大客户做"深":用数据深度构建能力护城河,关键是续约与上量
- 中小客户做"广":用汇聚效应形成数据规模,关键是获客效率与产品自驱
- 行业客户做"专":用行业知识构成准入壁垒,关键是标杆与生态卡位
一个常见的踩坑:很多 AI 公司想"通吃三层",结果三层都做不好。大客户嫌你不够专业,中小客户嫌你太贵太重,行业客户嫌你不懂行。起步阶段必须选一层做深,再用现金流和数据资产横向扩展。
4.7 创业进入顺序建议
| 团队基因 | 推荐路径 |
|---|---|
| 有行业背景的团队 | 行业客户 → 行业 PaaS → 横向扩展 SMB |
| 技术驱动(数据工程能力强)的团队 | SMB → 数据汇聚形成壁垒 → 反攻 KA |
| 有大客户资源的团队 | KA → 沉淀方法论 → 产品化下沉 SMB |
五、付费模式:从"卖 Token"到"卖懂你的智能"
本节要点:定价方式正在从单一的"按用量收费"分化为六种主流形态。看懂这张表,能更准确地给你的产品定价。
用户付费买的不是"调用了多少 Token",而是 "你的数据 + 你的工程能力 + 你的反馈闭环,让模型对我这个场景有多懂"。
定价方式因此分化为六种:
| 定价方式 | 适用场景 | 典型案例 |
|---|---|---|
| 按 Token / 调用量 | 基础设施层、API 服务 | OpenAI、Anthropic API |
| 按订阅 + 数据增值 | 通用 SaaS 化 AI 工具 | ChatGPT Plus、Notion AI |
| 按任务 / 按结果 | Agent 替代人力 | Cursor 按代码补全、Devin 按任务 |
| 按业务结果分成 | 深度场景嵌入 | AI 销售按成交额、AI 投顾按收益 |
| 数据工程服务费 | 帮客户搭建数据管线 / RLHF | Scale AI、Surge AI、垂直 AI 服务商 |
| 数据授权 + 模型订阅 | 行业模型 | 医疗影像、金融风控、工业 SaaS |
选择原则:
- 离基础设施越近,越倾向"按用量"
- 离业务结果越近,越倾向"按结果分成"
- 数据工程能力越强,越能收"服务费溢价"
- 飞轮越成熟,越能收"订阅溢价"
六、产业格局推演:寡头 × 百花
本节要点:通用模型层正在寡头化,但下游应用层是百花齐放。中小企业的真正机会在哪?

6.1 通用模型层为什么寡头化
当前格局:OpenAI、Anthropic、Google、字节、阿里、DeepSeek 等少数玩家占据通用大模型。寡头化的真正原因不是单一维度的"原料多",而是三轮齐备 + 算力门槛:
- 数据工程能力(RLHF、合成数据、配比 know-how)有显著工程门槛
- 用户飞轮已经转起来——亿级用户每天反哺,后来者追不上反馈速度
- 算力成本是规模门槛——动辄数十亿美金的训练投入
但格局正在被三股力量松动:
- 开源模型崛起(工程能力扩散):Llama、Qwen、DeepSeek 让数据工程方法开源
- 行业专用模型反扑(行业数据 + 行业 know-how):小而精的模型在垂直场景效果可能超过通用大模型
- 推理成本下降(算力门槛降低):让中小玩家也能跑得起像样的模型
6.2 真正的机会在数据应用层
核心判断:通用模型赛道被头部占据,海量中小企业和行业服务商,在数据应用层迎来真正的发展机遇(参见上方产业格局图)。这一层的利润率甚至可能高于上层——因为它直接对接业务结果,且具备数据工程 + 反馈飞轮带来的强护城河。
6.3 各行业的"三轮"难度对比
不同行业的差异,本质上是三个齿轮难度的不同组合:
| 行业 | 数据原料 | 数据工程 | 反馈闭环 | 综合飞轮启动速度 |
|---|---|---|---|---|
| 工业 | 极高(设备数据私有) | 难(数据异构) | 慢(依赖硬件部署) | 慢但壁垒最高 |
| 医疗 | 极高(病历影像) | 难(合规约束严重) | 慢(伦理审查长) | 极慢但价值极高 |
| 金融 | 中(已结构化) | 中(监管约束) | 快(交易高频) | 快 |
| 教育 | 中 | 易 | 快(学生交互密集) | 快 |
| 法律 | 高(判例+策略) | 难(专家经验难结构化) | 中 | 中 |
七、入局自检:5 个判断问题
工具卡片:想下场做 AI 应用?先用这 5 个问题自检一遍。
你切入的行业,数据原料是否仍处于未数字化或分散状态? 越分散、越未沉淀 → 机会越大(如工业、农业、传统服务业)。
你或合作方是否具备把这些原料变成可训练资产的工程能力? 有数据无工程 = 守着金矿挨饿。这是当前阶段最被低估的能力。
你的产品是否能让用户在使用过程中"不知不觉"贡献数据? 这是反馈闭环能否启动的关键。Tesla 卖车采集驾驶数据是经典样板。
你能扛过多长时间的双重冷启动期? 原料冷启动 + 工程冷启动,两者都要熬。决定你需要多少资本和耐心。
你打算从哪一层客户切入? KA / SMB / 行业,三条路径起点、节奏、能力要求完全不同,不可同时进。
八、速查表:互联网 vs AI 商业模式
工具卡片:一张表理解两个时代的根本差异。
| 维度 | 互联网时代 | AI 时代 |
|---|---|---|
| 核心资产 | 用户数据 + 流量 | 数据原料 × 数据工程 × 反馈闭环 |
| 边际成本 | 趋近于零 | 推理成本不可忽略 |
| 护城河 | 网络效应、转换成本 | 三轮齿合的飞轮、领域工程能力 |
| 定价逻辑 | 免费+广告 / 订阅 | Token / 任务 / 业务结果 / 工程服务 |
| 价值创造 | 连接信息、匹配供需 | 替代认知劳动、生成新内容 |
| 竞争焦点 | 谁有更多用户 | 谁的三轮齿合得更紧 |
| 入口 | 搜索引擎、App Store | 对话界面、Agent 编排层 |
| 格局 | 平台型赢者通吃 | 上层寡头 + 下层百花 |
| 关键稀缺资源 | 流量与注意力 | 数据工程人才 + 私有认知数据 |
结语
互联网时代的石油是注意力。AI 时代的石油是 泛数据——它不是单指数据原料,而是 "认知数据 + 把它炼成智能的工程能力 + 让它越用越聪明的反馈闭环" 三位一体。
商业模式从"你来我的平台"变成了"我替你把事做了"。能不能做好,取决于一件事:
你能不能把数据原料、数据工程、反馈闭环这三个齿轮齿合起来,让它持续转动。
赢家不是数据原料最多的,也不是 Token 最便宜的,而是把三个齿轮齿合得最紧的玩家。
这就是 AI 时代商业竞争的终极答案。