拆解 YC 的 AI 学习系统:6000 个创始人画像背后的实现细节
本文是 Thin Harness, Fat Skills:YC CEO Garry Tan 的 AI 架构心法 的延展阅读。建议先读原文,再看本篇。
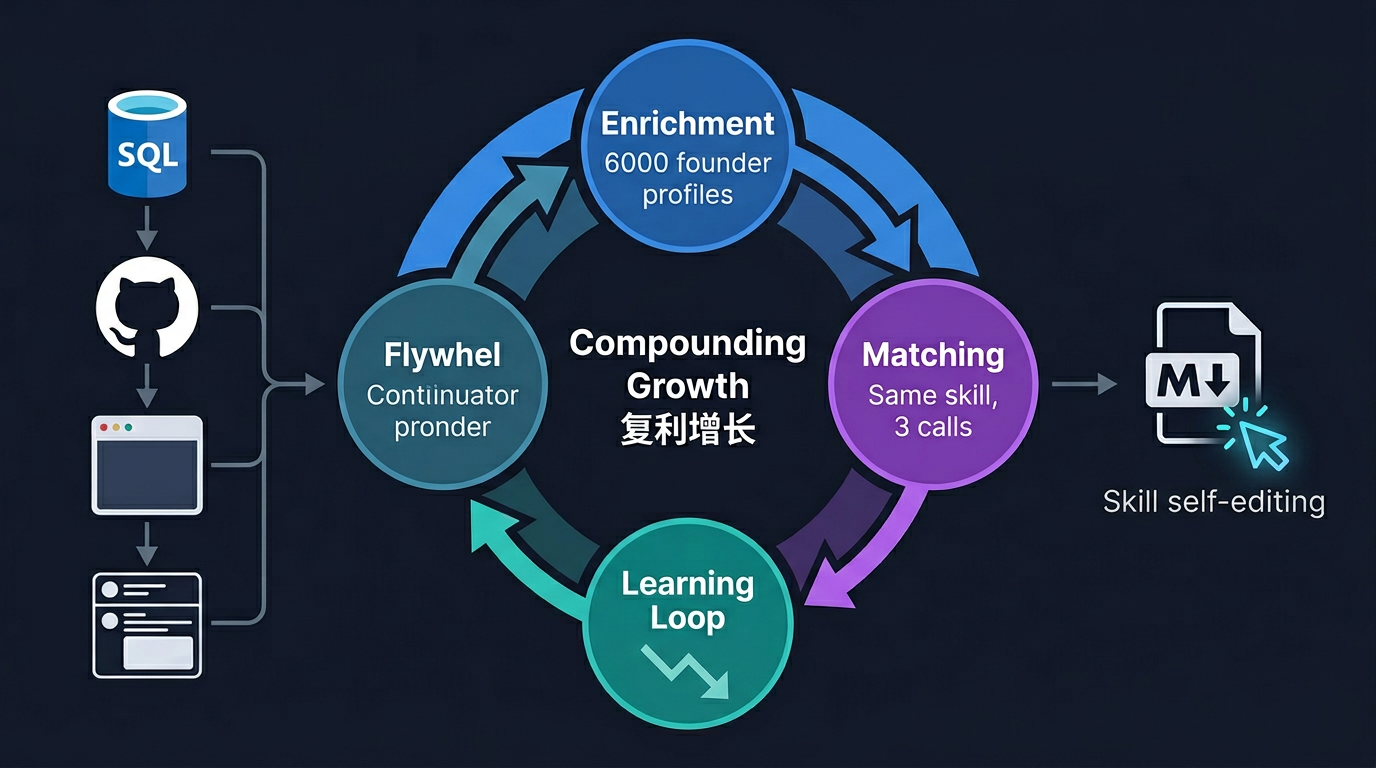
在 Garry Tan 的原文中,YC Startup School 案例只用了几百字——Enrichment、Matching、Learning Loop,一笔带过。但这几百字描述的,其实是一个完整的数据飞轮系统。它不仅是 Thin Harness, Fat Skills 的应用示例,更是 Garry 开源的 GBrain 项目在生产环境的实战映射。
本文尝试从工程视角还原这个系统的实现细节:数据从哪来、怎么存、怎么流动、Skill 文件到底长什么样、学习循环如何闭合。
先回顾场景
2026 年 7 月,YC Startup School,Chase Center,6000 名创始人。每人有:
| 数据源 | 类型 | 特征 |
|---|---|---|
| 结构化申请表 | 表单数据 | 字段固定,可 SQL 查询 |
| 问卷回答 | 半结构化文本 | 开放问题,需理解语义 |
| 导师 1:1 对话转录 | 非结构化文本 | 最有价值,但最难处理 |
| X/Twitter 发帖 | 社交信号 | 实时变化,需定期抓取 |
| GitHub 提交记录 | 行为数据 | 反映实际在做什么 |
| Claude Code 使用记录 | 行为数据 | 反映开发速度和模式 |
传统做法:15 人团队逐份看申请。200 人还行,6000 人彻底失效。
核心矛盾:数据量超出人类认知带宽,但判断本身需要的是综合分析能力,不是简单的关键词过滤。
第一层:Enrichment——把散落的信号变成一页画像
数据管道:确定性基础设施
在 Garry 的架构中,底层是确定性工具。针对 6000 个创始人,数据管道大致如下:
数据源 拉取方式 输出格式
─────────────────────────────────────────────────────────
申请表 → SQL 查询 PostgreSQL → JSON
GitHub → GitHub API + commit log → JSON
Demo URL → Playwright CLI 自动化测试 → 截图 + 状态码
X/Twitter → API 抓取最近30天发帖 → 文本列表
Claude Code → 使用量 API → 统计数据
1:1 对话转录 → 已有文本(Whisper转录) → Markdown注意这里用的是 Playwright CLI(100ms/操作),不是 Chrome MCP(15s/操作)——这就是 Thin Harness 的原则:底层工具要快、要窄、要确定性。
Skill 文件:/enrich-founder
数据管道拉回来的是原始信号。把这些信号变成一页结构化画像,是 Skill 的工作。
GBrain 的 enrich skill 遵循 Compiled Truth + Timeline 模式。每个创始人的画像是一个 Markdown 文件,分为两部分:
---
type: person
title: Alex Chen
tags: [AI infra, developer tools, YC SS26]
sector: AI Infrastructure
stage: Pre-seed
---
## Compiled Truth(编译事实——当前最优判断)
AI 基础设施方向创始人。申请时定位"开发者工具",
但 GitHub 提交 80% 集中在计费模块,
1:1 对话中反复提及 SOC2 合规自动化。
**实际方向更接近 FinTech/RegTech,而非 AI Infra。**
技术执行力强:过去30天 GitHub 提交 247 次,
Claude Code 日均使用 4.2 小时。
Demo URL 可访问,核心功能可用。
Open threads:
- 待确认:是否有合规行业经验?
- 待跟进:与 Kim(FinTech 方向)可能互补
---
## Timeline(时间线——只追加,不修改)
- 2026-06-15: 申请提交,自我定位"AI developer tools"
- 2026-06-20: GitHub 分析完成,80% 提交在 billing/ 目录
- 2026-06-22: 1:1 对话,提到"最大的痛点是企业合规"
- 2026-06-25: X 发帖讨论 SOC2 自动化,获 200+ 互动
- 2026-07-01: Demo 测试通过,landing page 加载 1.2s这个结构的关键设计:
- Compiled Truth 是可覆盖的:当新证据到来时,AI 重写上半部分。"申请时写的是开发者工具,但实际在做合规"——这个判断就是 rewrite 的产物。
- Timeline 是只追加的:所有原始证据保留,不可修改。这保证了判断可追溯。
- 判断在 Latent Space 完成:发现"说的"和"做的"之间的差异,需要模型同时阅读 GitHub 提交记录、申请表和对话转录,然后做出综合判断。没有任何 SQL 查询能完成这件事。
定时任务:每日运行
GBrain 的 cron 调度体系中,enrichment 不是一次性任务,而是每天凌晨自动运行的 dream cycle 的一部分:
| 任务 | 频率 | 作用 |
|---|---|---|
| 社交信号抓取 | 每 30 分钟 | 拉取 X 发帖、GitHub 活动 |
| 会议转录同步 | 每日 3 次 | 导入新的 1:1 对话 |
| Enrichment | 每晚 | 更新所有创始人画像 |
| 引用修复 | 每晚 | 修复断裂的交叉引用 |
| 矛盾检测 | 每周 | 发现画像间的信息冲突 |
6000 个画像,始终保持最新。你睡觉时,系统在变聪明。
第二层:Matching——同一个 Skill,三种调用
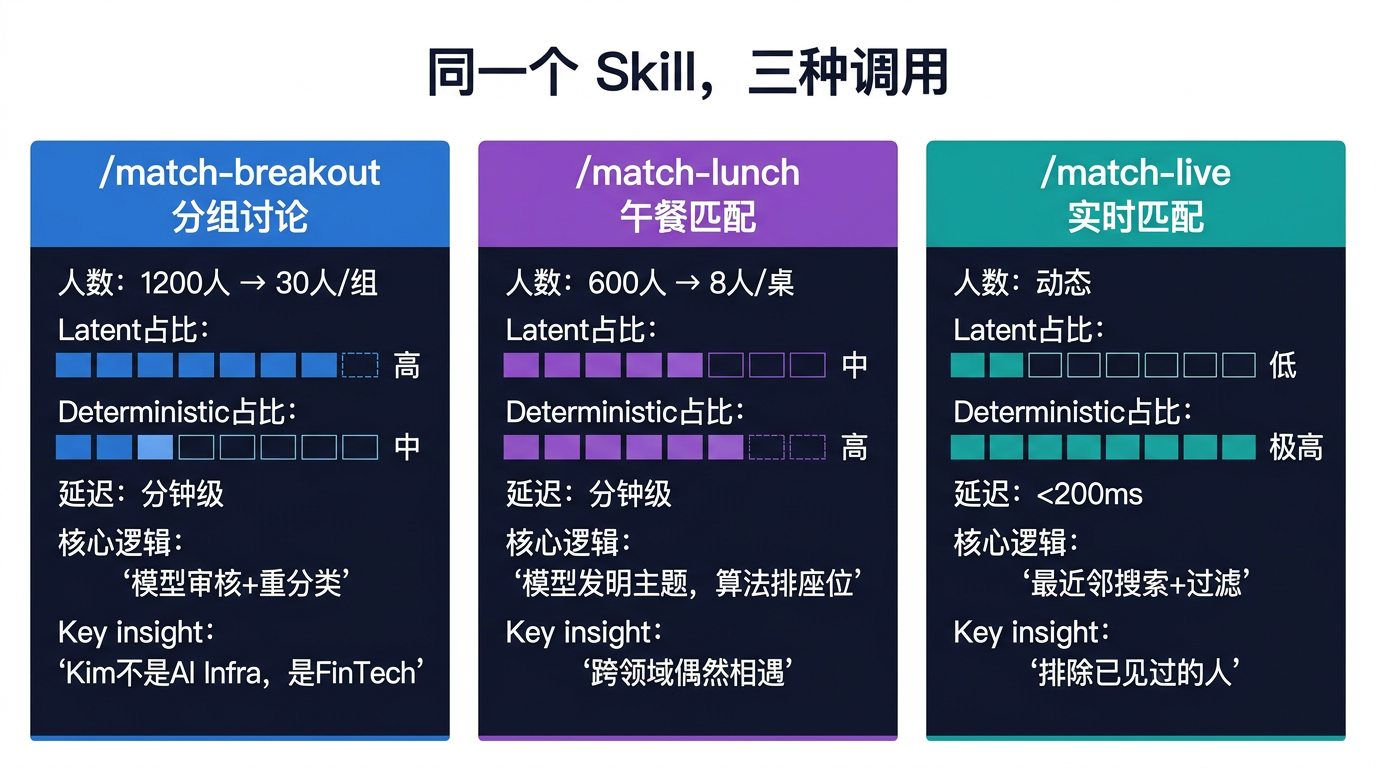
这是"Skill = 方法调用"最精彩的体现。同一个匹配技能,传入不同参数,输出完全不同的策略。
调用一:/match-breakout
参数:
MODE = breakout
POOL = 1200人(已确认参加分组讨论)
GROUP_SIZE = 30
STRATEGY = 按领域聚类
执行流程:
1. [Deterministic] 对1200人做 embedding 向量化
2. [Deterministic] K-means 聚类,分成 40 组
3. [Latent] 模型审核每组,做"软调整":
- "Santos 和 Oram 都属于 AI 基础设施,
但不是竞争关系——Santos 做成本归因,
Oram 做编排。应该放在同一组。"
- "Kim 申请时写的是开发者工具,
但画像显示他在做 SOC2 合规。
应重新归类到 FinTech。"
4. [Deterministic] 输出最终分组 JSON关键在第 3 步:模型读完整个画像后做出的重新分类,是 embedding 相似度完全无法捕捉的。Kim 的 embedding 和其他"开发者工具"创始人很近,但他实际在做 FinTech。只有读完 Compiled Truth 才能发现这一点。
调用二:/match-lunch
参数:
MODE = lunch
POOL = 600人(午餐参与者)
TABLE_SIZE = 8
STRATEGY = 跨领域偶然匹配,不重复
执行流程:
1. [Latent] 模型生成 15 个午餐主题
("AI + 教育"、"开源商业化"、"从大厂到创业"...)
2. [Latent] 为每个创始人标注 1-3 个兴趣主题
3. [Deterministic] 约束求解器分配座位:
- 每桌 8 人
- 每桌覆盖 ≥3 个不同领域
- 同桌不能有直接竞争关系
- 已经认识的人降低同桌权重
4. [Deterministic] 输出座位表这里的 Latent/Deterministic 边界非常清晰:模型负责"发明主题"和"理解人",算法负责"排座位"。让模型给 600 人排座位,它会"一本正经地胡编";让约束求解器理解"从大厂到创业"的微妙含义,它做不到。各司其职。
调用三:/match-live
参数:
MODE = live
POOL = 当前在场参与者(动态变化)
MATCH_TYPE = 1v1
LATENCY = <200ms
CONSTRAINT = 排除已见过的人
执行流程:
1. [Deterministic] 实时维护"在场"向量索引
2. [Deterministic] 最近邻搜索,200ms 内返回候选
3. [Deterministic] 过滤:排除已匹配过的组合
4. [Latent] 可选:模型对 top-3 候选做 re-rank
5. [Deterministic] 推送匹配结果这个调用几乎全在确定性空间,因为实时场景对延迟要求极高。模型只在可选的 re-rank 步骤中轻度介入。同一个 Skill 框架,因为参数不同,Latent 和 Deterministic 的比例完全不同。
三次调用的对比
| /match-breakout | /match-lunch | /match-live | |
|---|---|---|---|
| 人数 | 1200 | 600 | 动态 |
| 输出 | 30人/组 | 8人/桌 | 1v1 |
| Latent 占比 | 高(审核+重分类) | 中(主题+兴趣) | 低(可选 re-rank) |
| Deterministic 占比 | 中(聚类) | 高(约束求解) | 高(最近邻+过滤) |
| 延迟要求 | 分钟级 | 分钟级 | <200ms |
第三层:Learning Loop——技能的自我改写
这是整个系统最有意思的部分。活动结束后,系统如何变得更好?
/improve Skill 的执行流程
输入:NPS 调研结果(6000份)
Step 1 [Deterministic]: 按评分分桶
- "很好" (9-10分) → 跳过
- "还行" (6-8分) → 重点分析目标
- "不好" (1-5分) → 单独归类
Step 2 [Latent]: Diarization
模型读取所有"还行"评分的开放式反馈,
做主题画像——不是关键词统计,而是理解:
- "组里有两个我已经认识的人" → 重复匹配问题
- "话题太泛了,聊不深" → 聚类颗粒度不够
- "我其实不是做 AI 的" → 分类错误
Step 3 [Latent]: 提取模式,生成规则候选
"当参与者说 AI infrastructure,
但其代码 80%+ 为计费模块:
→ 分类为 FinTech,而非 AI Infra"
"当同组两人已经认识:
→ 降低匹配权重,优先引入新关系"
Step 4 [Deterministic]: 规则写回 Skill 文件
将新规则追加到 /match-breakout 的
constraint 部分,格式化为标准条件语句
Step 5 [Deterministic]: 版本控制
git commit → 规则变更可追溯、可回滚关键机制:Compiled Truth 的级联更新
新规则写入 Skill 文件后,下一次 Enrichment 运行时,Kim 的画像会被自动更新——从 "AI developer tools" 重新分类为 "FinTech/RegTech"。这个分类变更又会影响下一次 Matching 的结果。
这就是飞轮:
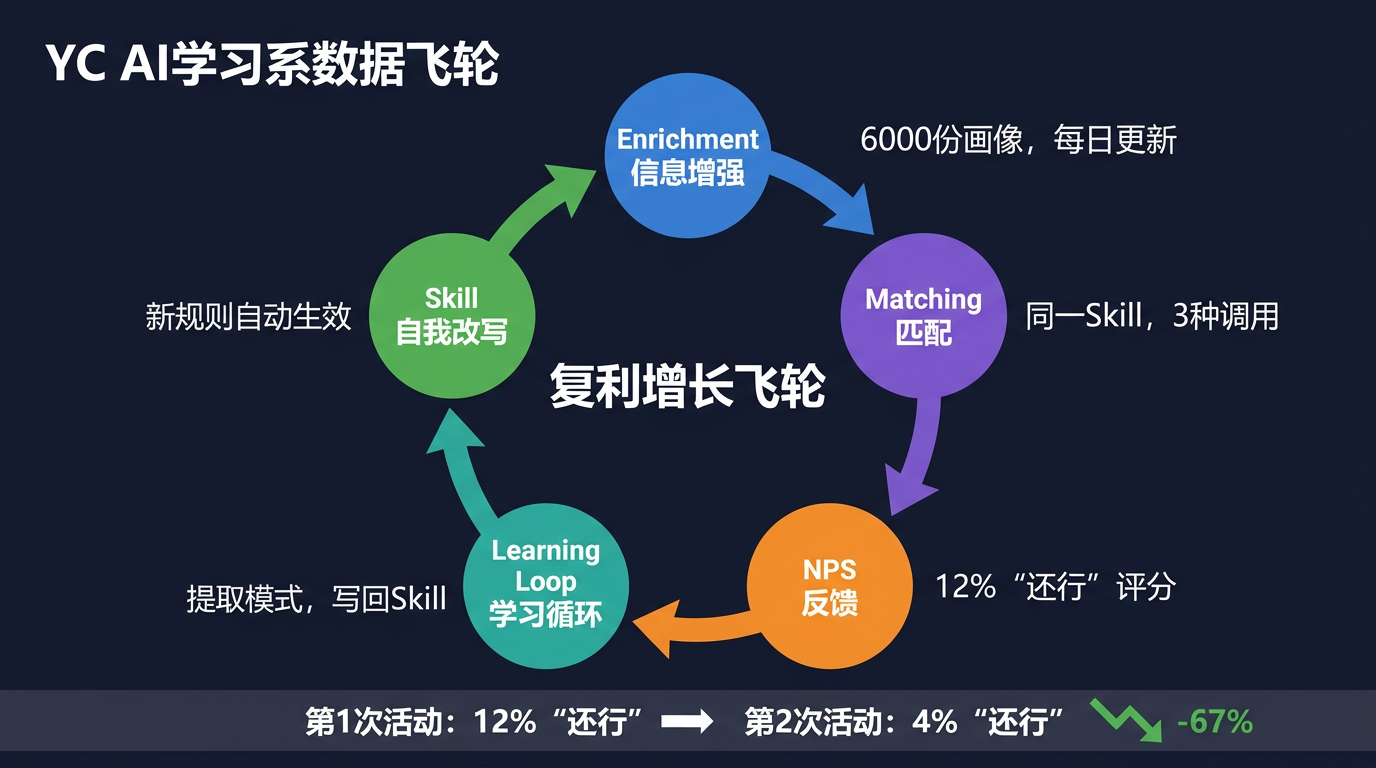
Enrichment(更准的画像)
↓
Matching(更好的分组)
↓
NPS 反馈(更精确的信号)
↓
Learning Loop(更聪明的规则)
↓
Skill 自我改写
↓
Enrichment(再次更准的画像)
↓
......循环7 月活动,"还行"评分占 12%。规则写回后,下一场活动降到 4%。没有人重写代码,系统自己变好了。
底层基础设施:GBrain 的工程实现
上面是业务视角。从工程视角看,这个系统跑在 GBrain 的基础设施上:
存储层
| 组件 | 作用 | 规模 |
|---|---|---|
| Git 仓库(Markdown 文件) | 系统 of record,人可读可编辑 | 10,000+ 文件 |
| PostgreSQL + pgvector | 检索层,向量 + 关键词混合搜索 | ~750MB |
| 内容分块 | 三种策略:递归(300词)、语义、LLM引导 | 1536维 embedding |
搜索层
GBrain 的搜索不是简单的 SELECT,而是一个多阶段管道:
- 查询扩展:Claude Haiku 生成 3-5 个同义改写
- 并行搜索:向量搜索(HNSW 余弦距离)+ 关键词搜索(tsvector)
- RRF 融合:
score = Σ(1/(60 + rank)),合并两路结果 - 四层去重:每页最优块 → 余弦相似度 > 0.85 过滤 → 类型多样性 → 每页块数上限
- 过期警告:当 Compiled Truth 比最新 Timeline 条目旧时,标记为 stale
为什么要两路搜索?关键词搜索找不到概念匹配("打破常规"搜不到"Bus Ticket Theory of Genius");向量搜索找不到精确短语。RRF 兼得两者。
Skill 调度
GBrain 的所有 Skill 通过一个 Resolver 自动路由。Resolver 是一个分发表:
用户意图 → 触发 Skill
─────────────────────────────
创建/丰富人物页面 → /enrich
导入会议/文档/文章 → /ingest
搜索并综合 → /query
维护(矛盾/过期) → /maintain
会议准备 → /briefing
匹配分组 → /match
事后改进 → /improve模型不需要记住有哪些 Skill。Resolver 根据意图自动匹配——这就是 Garry 把 CLAUDE.md 从 20000 行砍到 200 行指针的原因。
这个系统的本质:三个设计决策
回头看整个系统,核心其实就是三个决策:
1. 画像用 Markdown,不用数据库字段
创始人画像不是一行行数据库记录,而是一个个 Markdown 文件。为什么?
- 非结构化判断无法塞进字段:"申请时说做 AI 工具,实际在做合规"——这个判断放在哪个字段?
- 人可读可编辑:YC 合伙人可以直接打开文件读、直接改,
gbrain sync自动同步。 - Git 版本控制:每次 rewrite 都有 diff,判断的演变完全可追溯。
2. 判断和计算严格分离
整个系统中,没有一个步骤是"模糊地"调用模型。每一步要么明确在 Latent Space(模型判断),要么明确在 Deterministic Space(算法执行):
- Latent:读画像、发现差异、生成主题、提取模式、写规则
- Deterministic:SQL 查询、embedding 聚类、约束求解、最近邻搜索、git commit
边界冷酷清晰,没有含糊地带。
3. Skill 是资产,不是代码
/enrich-founder、/match-breakout、/improve ——这些不是 Python 脚本,而是 Markdown 文件。它们描述的是判断流程,不是执行步骤。当 Claude 升级到下一个版本,这些 Skill 的 Latent 部分会自动变强,而 Deterministic 部分不受影响。
更重要的是:Skill 可以自我改写。/improve 的输出会修改 /match-breakout 的约束条件。系统在运行过程中积累能力,这才是 Garry 说的"复利增长"。
能复制吗?
Garry 的案例虽然发生在 YC 的特定场景里(6000 个创始人、多数据源、大规模匹配),但核心模式是通用的:
检索 → 阅读 → Diarize → 判断 → 写回
↑ |
└──── 反馈 → 提取模式 ─────────┘任何涉及多源数据 + 综合判断 + 持续迭代的知识工作场景,都可以套用这个模式:
- 投资研究:多份招股书 + 行业报告 + 管理层访谈 → 一页投资备忘录
- 招聘筛选:简历 + GitHub + 面试反馈 → 候选人画像 + 团队匹配
- 竞品分析:产品文档 + 用户评价 + 定价页面 → 竞争格局画像
- 客户成功:工单记录 + 使用数据 + 会议纪要 → 客户健康度评估
关键不在于你是否有 6000 个创始人,而在于你是否愿意把判断流程写成 Skill,把每次改进写回系统。
GBrain 的 README 上有一句话说得好:"If you have to ask your agent for something twice, it should already be a skill running on a cron."
如果你向 Agent 要过两次同样的东西,它就应该已经是一个自动运行的 Skill 了。
本文是 Thin Harness, Fat Skills:YC CEO Garry Tan 的 AI 架构心法 的延展阅读。GBrain 开源地址:github.com/garrytan/gbrain