当知识溶进权重:AI 时代知识产权的范式之问
产业洞察 · 知识产权 × AI × 工业软件 | 2026 年 5 月 | 约 14 分钟阅读

上一篇 《工业克苏鲁》 写完之后,有一个问题一直没放下:
如果工业基座要从"软件 + 硬件"翻成"数据 + 模型 + AI"——那保护这些资产的 知识产权制度,是不是也得跟着翻一遍?
越想越觉得,这不是一个"修修补补就能应付"的问题。更像是 知识本身换了容器,而我们还在用旧容器的尺子去量新容器。
这篇不下结论——因为全世界都还没有答案。只想把问题摆出来,看看能不能帮自己想清楚一点。
一、旧框架:三把锁够用了吗?
传统软件的知识产权,大体靠 三把锁:
| 锁 | 保护的对象 | 核心逻辑 |
|---|---|---|
| 著作权(版权) | 代码的"文字表达" | 你写的代码是你的"作品",别人不能抄 |
| 专利权 | 算法 / 方法 / 装置 | 你发明了一种新方法,20 年内别人不能用 |
| 商业秘密 | 未公开的 know-how | 你的配方、工艺参数没公开,别人偷了要赔 |
这三把锁在传统软件时代跑了几十年,大体够用。原因很简单:价值的载体是代码——代码是人写的、可以文字化的、有明确归属的。
但 AI 时代,价值的重心漂移了。漂到哪儿了?
二、三次漂移:价值不再住在代码里
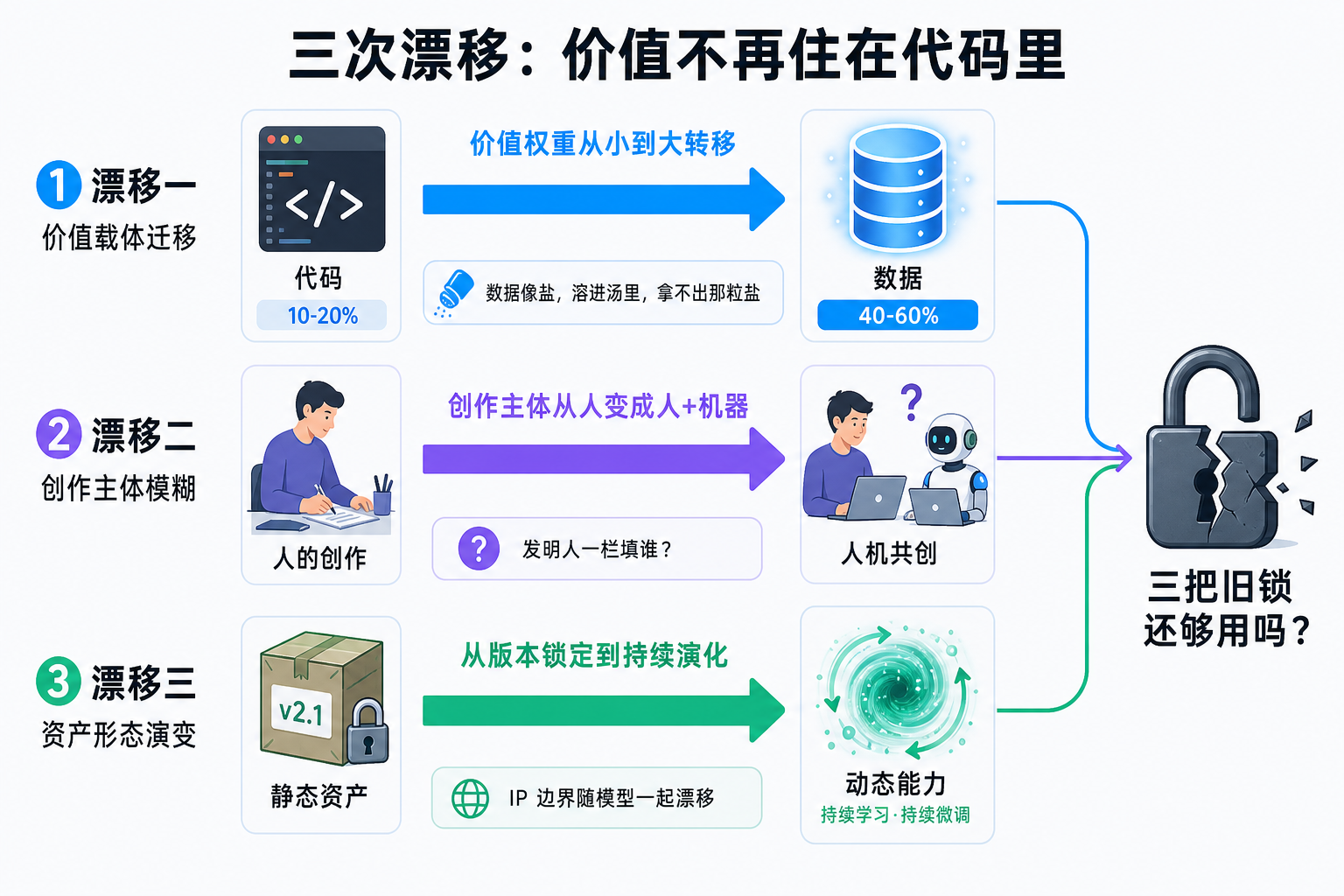
漂移一 | 从"代码"到"数据"
传统工业软件的价值链很清晰:写代码 → 打包成软件 → 卖 license。代码就是资产,保护代码就是保护资产。
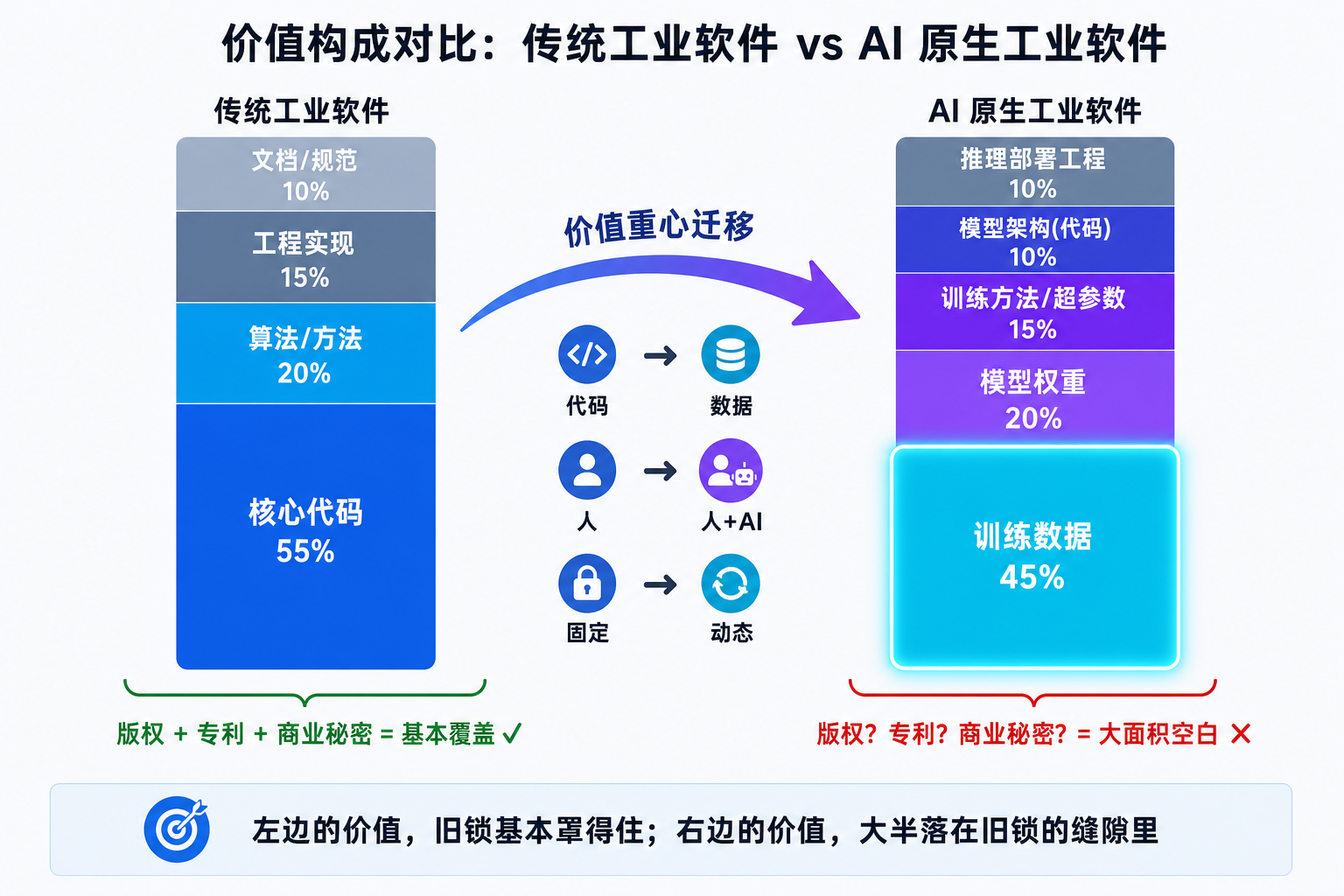
但现在,一个工业 AI 模型的价值可能是这样构成的:
| 构成 | 价值占比(直觉估计) | 现有 IP 保护 |
|---|---|---|
| 模型架构(代码) | 10–20% | 版权 + 专利(勉强覆盖) |
| 训练数据 | 40–60% | 几乎空白 |
| 训练方法 / 超参数 | 10–20% | 商业秘密(但难举证) |
| 推理部署工程 | 10% | 商业秘密 |
价值的大头已经从代码搬到了数据上,但数据恰恰是三把锁最锁不住的东西:
- 版权:原始数据通常不构成"作品"(一组温度传感器读数,很难说有"独创性");
- 专利:数据不是"技术方案";
- 商业秘密:能保护,但数据一旦喂进模型训练,know-how 就 溶解在了权重里——你很难证明对方模型里"含有"你的数据。
这让我想到一个比喻:数据像盐,溶进了汤里。你知道汤是咸的,但你拿不出那粒盐。
漂移二 | 从"人的创作"到"人机共创"
版权法和专利法有一个共同的底层假设:创作 / 发明的主体是自然人。
这个假设在 AI 时代开始松动:
- AI 生成代码:GitHub Copilot 写的代码,版权归谁?程序员?微软?OpenAI?还是训练数据的原始作者?
- AI 辅助发明:如果一个 AI 模型在做 CFD 仿真时"发现"了一种新的翼型设计,专利申请表上"发明人"一栏填谁?
- AI 生成工业设计:大模型根据工艺约束自动生成的模具方案,算不算"作品"?
目前各国的态度不一样,但都很尴尬:
| 司法管辖 | 对"AI 能否做发明人/作者"的态度 | 实际效果 |
|---|---|---|
| 美国 USPTO / 版权局 | 明确拒绝:只有自然人能做发明人和作者 | AI 生成的内容 = 公共领域? |
| 欧洲 EPO | 拒绝 AI 发明人(DABUS 案) | 同上 |
| 中国 | 态度相对开放:北京互联网法院 2023 年判决认定 AI 生成图片可受版权保护(需有人的智力投入) | 但边界仍模糊 |
| 英国 | 现行法允许"计算机生成作品"有版权(1988 年 CDPA) | 全球少数例外 |
有意思的是,越是拒绝 AI 做作者/发明人的司法体系,反而越可能让 AI 生成的成果落入公共领域——这对投入大量资源训练模型的企业来说,恰恰是一种反激励。
漂移三 | 从"静态资产"到"动态能力"
传统软件是 静态资产:写完了就固定了,版本号锁死,IP 边界清晰。
但 AI 模型是 动态能力:它在持续学习、持续微调、持续被新数据改变。一个工业大模型今天和三个月后可能已经是"不同的模型"——但它的 IP 归属并没有跟着变。
更有意思的问题是:如果模型在使用过程中通过用户反馈变得更好了,新增的价值归谁?
- SaaS 模式下,用户的使用数据反哺了模型 → 模型变好 → 服务所有用户。
- 用户有没有对"自己贡献的那部分改进"主张权利的基础?
这个问题目前没有任何法律框架能回答。
三、矛盾在哪里爆发?三个视角
三次漂移还停留在抽象层面。把镜头拉近到具体场景,就能看到矛盾正在 三个不同主体身上同时爆发——巨头、散户、防御策略——三者加起来,才是这个范式之问的完整切片。
视角一 | 巨头视角:知识层的悖论
先看 《工业克苏鲁》 里那个判断:
下半场要做的,是把知识从外资软件里拆出来,装进中国数据 + 模型。
理论上很美好。但落到三一重工这种企业身上,这是一道死循环:
- 它 30 年的工艺数据是最宝贵的资产;
- 要让这些数据发挥价值,就得拿出来训练工业大模型;
- 模型一旦训练完成,数据里的 know-how 就溶进了权重——拿不出来,也证不了;
- 如果这个模型又被用来服务其他客户,三一的知识就在 无形中被稀释。
更糟的是,这种稀释会沿着 《工业克苏鲁》 里的"设计 ↔ 制造 ↔ 运营 ↔ 服务"闭环不断放大:每一次数据跨越组织边界,IP 归属就模糊一层。车厂的行驶数据喂给 AI 优化下一版设计,模型 IP 归车厂还是 AI 供应商?供应商的工艺数据通过平台共享给整车厂的模型吸收,谁能主张什么权利?
商业层的换挡也在加剧这个问题。《从"流量"到"词元"》 里讲过模式正从"卖 license"转向"按词元计费"——但用户买的不再是软件拷贝(版权能罩住),而是模型的推理能力(没有任何 IP 类别能罩住)。整个"词元经济"的价值链上,几乎每个环节都落在现有 IP 框架的缝隙里。
一句话收口:没有一套可信的产权框架,谁敢把自己的核心工艺数据拿出来? 这或许是"二次重构"最大的隐性障碍——不是技术问题,不是商业问题,是 制度问题。
视角二 | 散户视角:"智力佃农"问题
巨头的困境只是故事的一半。如果只看到三一重工,视角还不够深——被溶进权重的,远不止巨头的工艺数据。
想想另一端:
- 数百万程序员写的开源代码,被抓去训练了 Copilot;
- 几十万画师的作品,被 Stable Diffusion 学了个遍;
- 工厂里的老师傅,一辈子的工艺手感被录成操作视频,喂给了工业大模型。
这些人贡献了"盐",但他们连"汤"的味道都分不到。
表面上看,"知识溶进权重"是知识的平民化——AI 让人人都能用上过去只有专家才有的能力。但硬币的背面是 产权的中心化:知识从千万个分散的个体手中流向几个大模型平台,变成了平台的资产。
这不是新故事。互联网时代,用户数据喂肥了平台;AI 时代,用户的 智力成果 在喂肥模型。只不过这一次,被收割的不是注意力,而是 创造力本身。
如果新的 IP 制度只保护"有能力训练大模型的一方"——也就是有算力、有数据管线、有工程团队的巨头——那些贡献了原始知识的个体和中小企业,就会变成 AI 时代的 "智力佃农":在别人的模型上耕种,但永远拿不到地契。
任何新制度如果不回答"散户的盐怎么定价",就只是在帮大厂修围墙。
视角三 | 策略视角:防御性专利库的终结?
巨头守不住自己的数据,散户分不到自己的果实——还有第三个被搅动的,是过去几十年大公司赖以生存的 防御性 IP 策略。
工业领域的专利,主要不是为了进攻,而是为了 互换授权——"你不告我,我不告你"。这套博弈之所以成立,前提是 专利边界清晰、侵权可以指认。
但在 AI 时代,"盐溶于水"让这个前提塌了:
- 你的算法专利被 AI 模型"学"走了,但模型的权重矩阵里 找不到任何一段代码能和你的专利权利要求一一对应;
- 你的工艺 know-how 被训练数据吸收了,但你 无法证明对方模型的输出"源于"你的数据;
- 对方甚至可以说模型是自己"独立发现"的——而你无法反驳。
如果防御性专利库的威慑力大幅衰减,那未来的 IP 护城河可能不再是"我有多少专利",而是 "我有多少无法被离线复制的实时动态数据流"。
换句话说,IP 竞争可能从 "静态资产库的比拼" 转向 "动态系统准入的争夺"——谁能持续接入最丰富的实时数据管道,谁的模型就能持续领先,而这种领先 不需要专利来保护,因为它根本无法被静态地"偷走"。
这或许能解释为什么那些 AI 领先的公司并不急于申请海量专利,而是拼命在做 数据飞轮和生态锁定——它们可能已经直觉地感知到:旧的防御武器不好使了,新的护城河长在别处。
三视角合一
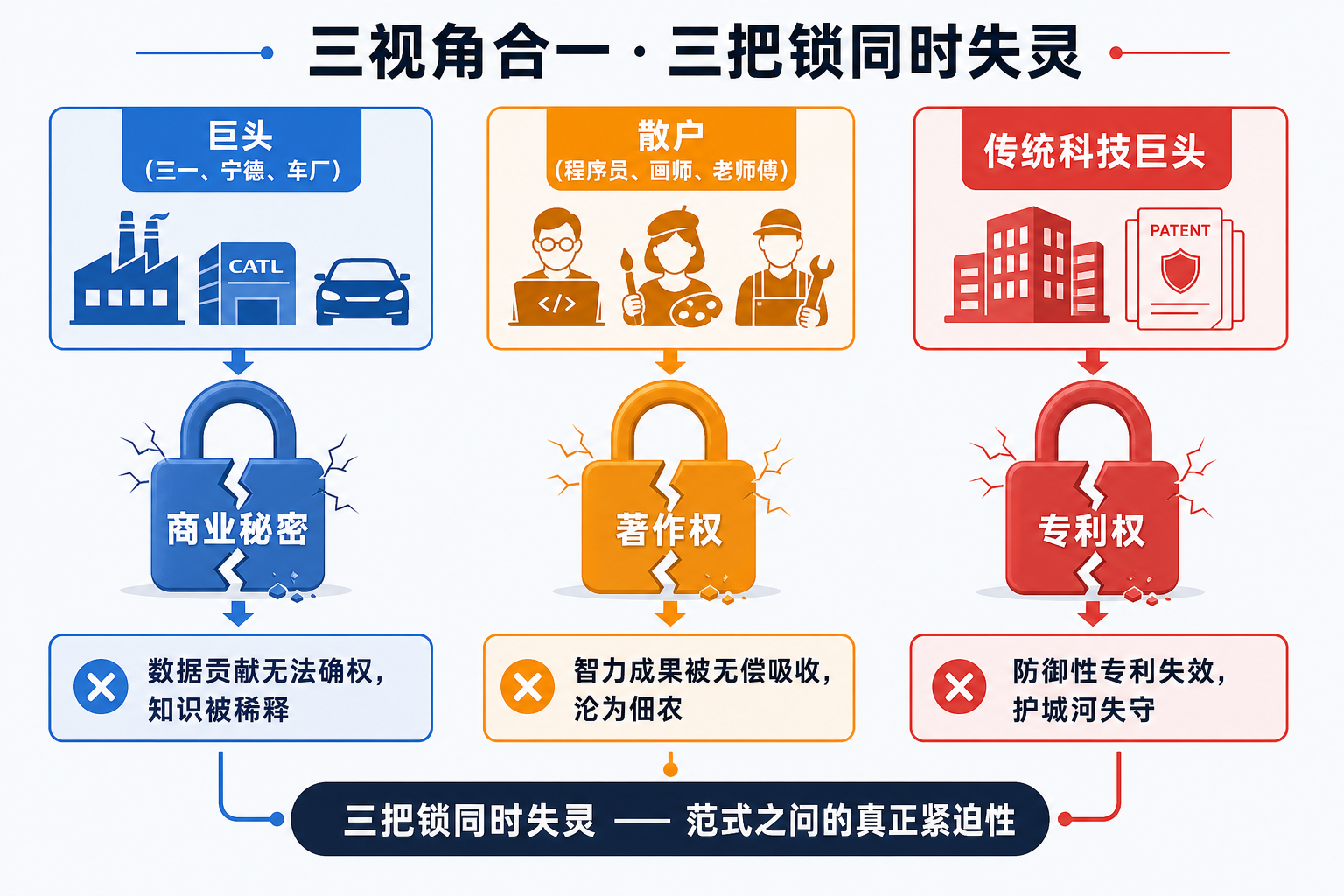
把三个视角叠在一起,能看到一幅完整的图景:
| 视角 | 谁在受冲击 | 旧框架的失灵点 |
|---|---|---|
| 巨头视角 | 三一、宁德、车厂等数据持有方 | 数据贡献无法确权,模型被稀释 |
| 散户视角 | 程序员、画师、老师傅、中小企业 | 智力成果被无偿吸收,沦为"佃农" |
| 策略视角 | 拥有专利库的传统科技巨头 | 防御性专利失效,护城河失守 |
这三类主体,过去依靠的恰好是版权、商业秘密、专利这三把旧锁。三把锁同时失灵——这才是范式之问的真正紧迫性所在。
四、有人在探路:几个值得观察的方向
矛盾这么集中、这么多,谁在尝试解决?答案是——没有一个统一的解,但已经有几条不同方向的探路。每一条都不完整,但拼起来能看出一个模糊的轮廓。
方向一 | 中国的"数据产权三权分置"
国家数据局推的 "数据资源持有权 + 数据加工使用权 + 数据产品经营权" 三权分置,是全球范围内最早试图给数据建立独立产权框架的尝试之一。
它的思路是:不再硬套版权或专利,而是承认数据是一种新型资产,需要新型产权。
这个方向如果走通,至少能解决"谁有权用这份数据训练模型"和"训练出来的模型里谁有多少份额"这两个基础问题。
但挑战也很大:三权分置在法律层面还停留在政策文件,缺乏司法实践和判例支撑。概念有了,牙齿还没长出来。
方向二 | 模型卡 + 数据溯源
技术社区在推的 Model Card(模型卡)和 Data Provenance(数据溯源)机制,试图用技术手段解决一部分 IP 问题:
- 每个模型附一张"成分表":用了哪些数据集、什么许可证、训练了多少步;
- 数据溯源技术(水印、指纹、membership inference)试图回答"这个模型是不是用了我的数据"。
这不是法律方案,但它可能成为未来法律方案的 技术基础设施——就像区块链之于数据确权,不是制度本身,但是制度运行的底层。
方向三 | "贡献度定价"机制
《贝壳模式启示录》 里讨论过 ACN(经纪人合作网络)的分润逻辑——把一笔交易拆成 10 个角色,按贡献度分润。
AI 模型的 IP 分配,或许也需要类似的"贡献度定价"机制:
- 数据提供方贡献了多少?(Shapley Value 等方法已经在学术界讨论)
- 算力提供方贡献了多少?
- 模型架构设计方贡献了多少?
- 精调和部署方贡献了多少?
这个思路把 IP 从 "非此即彼的归属问题" 转化成了 "多方按比例分润的商业问题"——也许比在法律层面争论"谁是作者"更务实。
方向四 | 开源作为一种 IP 策略
一个有意思的现象是:越来越多的 AI 公司选择开源模型权重。
这表面上是在"放弃 IP",但实际可能是一种更高维的 IP 策略:
- 开源模型权重 → 锁定生态 → 靠推理服务和企业版赚钱;
- 开源基础模型 → 让社区帮你做行业微调 → 反哺自己的数据飞轮;
- 开源 = 让 IP 保护从"排他权"变成"生态位"。
DeepSeek、Meta LLaMA、Mistral 都在走这条路。当知识产权的"排他性"变得越来越难维持,"开放 + 生态 + 服务"可能成为一种替代性的护城河。
五、一个不成熟的猜想:权利束
把上面四个方向拼在一起,我有一个不成熟的猜想:
AI 时代的知识产权,可能不会是一个"统一的新制度",而是会分化成 一组权利束(bundle of rights)——不同类型的资产用不同的保护机制,靠合同和技术手段串起来。
大概长这样:
| 资产层 | 可能的保护机制 | 成熟度 |
|---|---|---|
| 训练数据 | 数据产权(三权分置)+ 合同 + 技术溯源 | 探索中 |
| 模型权重 | 商业秘密(最实际)+ 可能的新型"模型权" | 概念阶段 |
| 模型架构 / 训练方法 | 专利(可行但描述困难)+ 论文优先权 | 部分可用 |
| AI 生成内容 | 版权(有条件承认,要求人的实质参与) | 各国分裂 |
| 推理能力 | 服务协议 + 使用限制 + 生态壁垒 | 商业实践先行 |
这不是一把锁,而是 五把不同的锁,锁在不同的抽屉上。它不优雅,但也许比寻找一个"大一统理论"更现实。
回头对照一下第三节那张三视角的表,能看出一个有意思的对应:
- 巨头视角——主要靠"训练数据 + 模型权重"两把锁;
- 散户视角——主要靠"AI 生成内容"那把锁(这恰恰是各国分裂最严重的一把);
- 策略视角——直接绕过专利那把旧锁,转向"推理能力"的生态壁垒。
旧的三把锁要不要保留?保留,但只够罩住一部分;剩下的部分,得用新锁补。
六、地缘维度:制度本身就是产业竞争工具
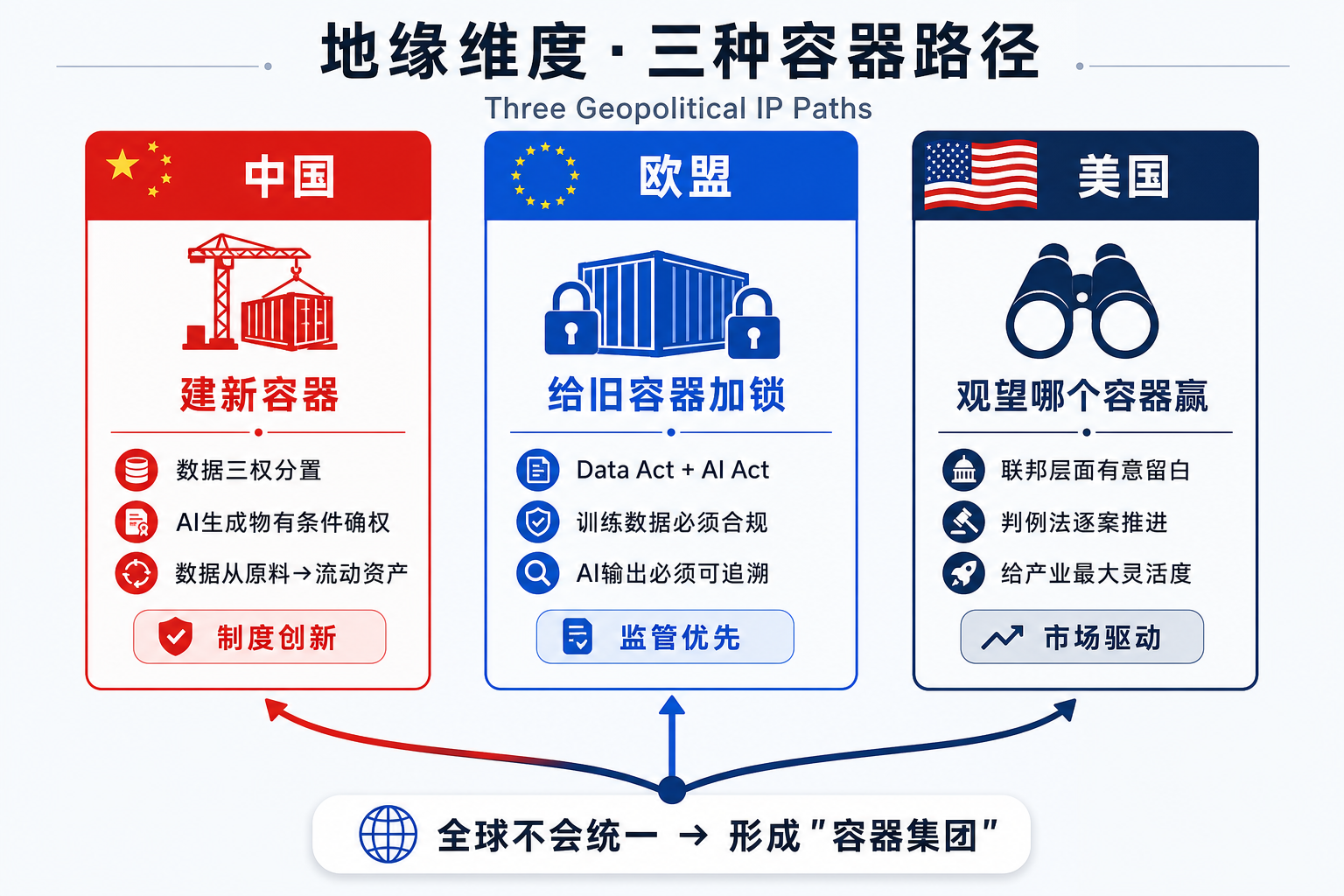
权利束的猜想还只是国内视角。镜头拉到国际,会发现一个更关键的事实:"用什么锁"这件事本身,就是大国竞争的一部分。
前面第二节提到各国对"AI 能否做发明人/作者"的态度分化——美国拒绝、欧洲拒绝、中国有条件接受、英国早期立法允许。这通常被解读为"法律理念差异",但如果再想一层,它本质上是产业保护主义的变体。
逻辑很简单:
- 率先承认 AI 生成物可以拥有 IP 的法域,等于给 AI 企业发了一张"资产化通行证"——模型的产出可以确权、可以交易、可以作为资产负债表上的无形资产。这对吸引 AI 公司注册、落地、融资来说,效果堪比税收优惠。
- 拒绝承认 的法域,等于说"AI 产出不是财产"——这保护了传统创作者的利益,但也可能把 AI 产业的资产化逼到别的司法管辖区去做。
更深一层:数据产权制度本身也在变成地缘竞争工具。
- 中国推数据三权分置,意图很明确——让数据要素在国内 可确权、可定价、可流通,把数据从"沉睡的原料"变成"流动的资产";
- 欧盟推 Data Act + AI Act,核心是 设置门槛——你的模型要在欧洲跑,你的训练数据必须合规,你的 AI 输出必须可追溯;
- 美国目前联邦层面 有意留白——没有统一的数据产权法,也没有统一的 AI IP 法,靠判例法逐案推进,给产业最大灵活度。
三种路径、三种"容器":中国在建新容器,欧盟在给旧容器加锁,美国在观望哪个容器跑得赢。
最终的结果可能是:全球不会有一套统一的 AI 知识产权制度,而是形成几个"容器集团"——就像今天的数据跨境流动已经分化成"美国圈""欧盟圈""中国圈"一样,AI 时代的 IP 制度也会沿着地缘线裂开。
对中国的工业重构来说,这既是风险也是窗口:如果中国能率先跑通"数据产权 + 模型产权 + AI 生成物产权"的完整制度链,这本身就是一种产业基础设施——吸引全球 AI 企业来这里做资产化,就像当年开曼群岛靠公司法吸引全球企业注册一样。
当然,这只是一种可能性。制度竞争的结果从来不取决于谁的设计更精巧,而取决于 谁的市场足够大、让制度跑出了真正的判例和实践。
七、回到工业基座:少了哪一层?
地缘的镜头收回来,再回到我们最初的问题——这一切对中国工业的"二次重构"意味着什么?
回头看 《工业克苏鲁》 里的四层重构框架——工具层、知识层、组织层、商业层——我越来越觉得,它可能缺了一个底座:
制度层:知识产权的二次重构。
如果知识的容器从"软件代码"变成了"数据 + 模型",但 IP 框架还停留在保护"代码"和"方法"的阶段,那 知识层的重构就会被卡住——因为没有人愿意把 30 年的核心工艺数据拿出来喂模型,如果分不清楚这个模型里自己的知识值多少钱、归谁。
换句话说:数据不敢流动,模型就训不好;模型训不好,工具层和知识层的重构就跑不动;跑不动,克苏鲁就长不上去。
制度层或许才是四层重构下面那块 看不见但最先会塌的地基。
八、写在最后
这篇没有结论,因为我确实没有答案。全世界都还在摸着石头过河——中国的数据产权三权分置在试,欧盟的 AI Act 在试,美国的版权局在一个案子一个案子地试。
唯一比较确定的一件事是:旧框架不够用了。
当知识溶进了权重,当发明人可能不是人,当数据像盐一样融入了汤里——我们需要的也许不是更精致的旧锁,而是承认:容器变了,锁也该换了。
至于换成什么样——这大概是未来十年,技术界、法律界、产业界需要一起回答的问题。
本文为探索性思考,不构成任何法律建议。涉及各国司法态度的描述基于公开判例和官方文件(美国 Thaler v. Vidal / USCO AI 政策声明、欧洲 EPO DABUS 案、北京互联网法院 AI 生成图片案、英国 CDPA 1988),具体以最新司法实践为准。欢迎讨论。