OpenScholar:可信的 AI,才是科学研究的真正助手
Deep Research 报告 | 2026 年 3 月 | 面向 AI 产品从业者、研究工程师、科研团队

摘要
"AI 幻觉"早已是老生常谈,但大多数讨论停留在"模型有时会犯错"的层面。当 AllenAI 研究团队系统测试 GPT-4o 时,他们得到了一个让人无法回避的数字:在学术问答场景中,GPT-4o 伪造引用的比例高达 78–90%。这不是偶发错误——这是通用大模型架构在科学领域的系统性失效。
OpenScholar 的回答是:用设计来解决架构问题。通过 4500 万篇开放获取论文构建的专用数据存储、检索增强生成(RAG)、以及独特的自反馈推理循环,它将引用准确性提升到与人类专家持平的水准,并让一个 8B 参数的开源小模型在科学问答基准上全面超越 GPT-4o。2026 年 2 月,这一成果正式发表于 Nature。
本文从"可信的 AI"这一视角,系统分析 OpenScholar 的设计哲学、关键技术决策、实测数据,以及它揭示的一条对所有 AI 垂直领域都适用的工程路径。
一、概念从哪里来
一次失败的早期实验
故事的起点不是成功,而是一次失败的尝试。OpenScholar 的第一作者、Ai2 研究科学家 Akari Asai 在博士期间,最初尝试用 Google 搜索数据来辅助 LLM 回答科学问题。结果令人失望:
"它会引用一些不那么相关的论文,或者只引用一篇,或者随机从博客文章中引用。我们意识到必须把它锚定在科学论文上。我们随后让系统变得灵活,使其能够通过结果融入最新研究。"
—— Akari Asai,OpenScholar 第一作者、Ai2 研究科学家
这次失败揭示了一个本质问题:通用网络内容和科学文献,是两种完全不同的信息生态。科学论文有严格的同行评审体系、精确的引用关系、规范的方法论描述——这些特征使它们成为与博客、新闻完全不同的知识来源,也因此需要完全不同的处理方式。
从量化失败到系统设计
在确定方向后,团队对 GPT-4o 做了系统性基准测试,结果为整个项目提供了明确的设计目标:
| 问题 | 测试结果 |
|---|---|
| GPT-4o 在科学问答中伪造引用的比例 | 78–90% |
| GPT-4o 被科学家偏好(vs 人类专家答案) | 仅 32% |
| 核心原因 | 预训练权重无法核查引用真实性;训练截止日期后的文献无法访问 |
这两个数据——"幻觉率 78–90%"和"专家偏好仅 32%"——成为了 OpenScholar 的双重设计靶标:既要解决可信度问题,也要解决综合能力问题。
2024 年 11 月提交 arXiv,2026 年 2 月正式发表 Nature。华盛顿大学与 Ai2 的联合团队,用约两年时间走完了从失败实验到 Nature 正刊的路程。
二、什么是 OpenScholar
"可信"的精确含义
OpenScholar 的官方定义是:专为科学文献合成设计的检索增强语言模型(Retrieval-Augmented LM)。但更准确的描述,是 BigDATAwire 给出的一句话:
"它不是从记忆中回答,而是先在庞大的语料库中搜索真实论文——约 4500 万篇文献——提取相关段落,然后用这些检索到的来源作为证据来撰写答案。"
这个"先检索,后生成"的顺序,是 OpenScholar 与通用 LLM 的根本区别。通用模型是"从知识中回忆,然后尝试找证据";OpenScholar 是"先找证据,再基于证据作答"。这一顺序的颠倒,从架构层面消除了幻觉引用的主要来源。
边界:它不是什么
| 对比对象 | 区别所在 |
|---|---|
| Google Scholar / Semantic Scholar | 只检索,不合成;给你列表,不给你答案 |
| 通用 LLM(GPT-4o、Claude) | 能合成,但引用不可查,知识有截止日期 |
| Elicit / Consensus | 偏向单篇提取,跨文献综合能力弱 |
| PaperQA2 | 专注单篇 QA,OpenScholar-8B 正确率超出 5.5% |
| OpenScholar | 跨 4500 万篇文献合成,每个结论有文献出处,持续更新 |
三、三个关键工程决策
OpenScholar 的成功,归根到底源于三个设计决策——每一个都值得垂直领域 AI 产品从业者深思。
决策一:先建数据存储,再想模型
大多数 AI 产品的思路是"选个好模型,再想怎么给它数据"。OpenScholar 反过来:先建数据存储(Datastore),再围绕它设计模型和检索。
OSDS(OpenScholar Datastore)是一个包含 4500 万篇开放获取学术论文的全文语料库,建立了片段级检索索引,并通过 Semantic Scholar API 向外开放。数据存储每周更新,确保新发表的论文能被持续纳入。
为什么这个决策如此重要?因为它决定了系统的上限。再好的模型,如果数据存储不够全、不够新、不够准,都会在边界处失效。OpenScholar 把"数据第一性"作为工程优先级,是它能突破通用模型限制的根本原因。
ScholarQA 后续将语料库进一步扩展至 800 万篇全文 + 1.08 亿篇摘要,通过 Vespa 向量数据库提供高效检索,每周更新一次。
决策二:证据优先管道,颠倒生成顺序
这是 OpenScholar 设计哲学的核心:evidence-first pipeline(证据优先管道)。
ScholarQA 团队明确描述了这一思路:不是"写一个好答案,然后找支撑它的证据",而是"先找证据,再基于证据构建答案"。这个顺序看似微小,实则根本不同:
- 传统方式:模型先生成答案框架,然后用检索结果来填充和验证 → 容易"倒推引用"
- OpenScholar 方式:先提取最相关的引用段落,再围绕这些引用来组织答案 → 引用天然真实
三步生成流程:
- 引用提取:从 Top-50 候选段落中精选最相关引用
- 提纲规划:根据引用生成章节结构(段落型 vs 列表型按内容自动区分)
- 分节生成:每节附带 TLDR 摘要和引用来源,按前节内容条件生成后节
值得注意的是,这一管道设计也有代价:ScholarQA 团队发现,"模型有时会稍微偏题——试图将证据融入答案时,即便只是外围相关,它也想把它纳入进来"。这是证据优先管道的内在张力:证据覆盖率和叙述连贯性之间的权衡。
决策三:自反馈而非单次生成
传统 RAG 系统的范式是:检索 → 拼接上下文 → 生成 → 输出。OpenScholar 在此基础上加入了自反馈推理循环(Self-Feedback Inference Loop)。
模型生成初版答案后,会对自身输出进行评估:引用是否充分?每个论断是否有据?然后根据评估结果进行迭代改善。这一机制类似于人类写作时的"自我审稿"——不是一次写完,而是写完后对照来源检查。
自反馈循环显著提升了引用准确性,也让 OpenScholar 的设计具备了一定的通用性:无论接入哪个骨干模型,这一推理框架都能带来改善。
四、谁在推动,效果如何
Ai2 × 华盛顿大学:产学合力的标杆案例
OpenScholar 是 AllenAI(Ai2)与华盛顿大学 Paul G. Allen 计算机科学与工程学院深度合作的产物。第一作者 Akari Asai 在 UW 完成博士研究后加入 Ai2,通讯作者 Hannaneh Hajishirzi 同时担任 UW 副教授和 Ai2 高级主任——这种"双身份"关系使产学合作从制度层面得到保障。
背景独特价值:Ai2 在学术 AI 基础设施上有长期积累——Semantic Scholar 是全球最大的学术搜索引擎之一,S2ORC 是重要的开放语料库。OpenScholar 直接继承了这些基础设施,使它从一开始就有数据层面的优势,而不是从零重建。
| 核心成果 | 数据 |
|---|---|
| 语料库规模 | 4500 万篇开放获取论文 |
| ScholarQABench | 2,967 条专家问题 + 208 篇长文答案 |
| 覆盖领域 | CS、物理、神经科学、生物医学 |
| vs GPT-4o 正确率 | OpenScholar-8B +6.1%,OpenScholar-GPT4o +12% |
| vs PaperQA2 | OpenScholar-8B 正确率 +5.5% |
| 引用幻觉率 | GPT-4o 78–90%,OpenScholar 与人类专家持平 |
关键叙述:Demo 上线后收到了远超预期的大量查询。Hajishirzi 坦言这出乎意料:
"当我们开始看这些回复时,我们意识到同事和其他科学家已经在主动使用 OpenScholar。这充分说明了对这种开源、透明、能合成研究的系统的迫切需求。"
这种"做出来被自发使用"的路径,验证了 OpenScholar 解决的是真实存在的痛点,而非实验室假设。
核心洞见:OpenScholar 的开源策略(代码、模型、数据存储全部公开)也产生了连锁效应。Asai 提到"其他人已经在我们结果基础上继续改进"——开放不只是姿态,而是加速整个生态演进的策略选择。
人类评估:数据背后的含义
16 位领域专家盲评 OpenScholar 与人类专家撰写的答案,结果如下:
| 对比组 | 专家偏好 AI 的比例 |
|---|---|
| OpenScholar-8B vs 人类专家 | 51% |
| OpenScholar-GPT4o vs 人类专家 | 70% |
| GPT-4o(无 OpenScholar 框架)vs 人类专家 | 仅 32% |
51% 和 70% 这两个数字需要放在一起理解:OpenScholar-8B 刚好超过一半,而 OpenScholar-GPT4o 达到 70%。这说明框架(数据存储 + 检索管道 + 自反馈)的贡献,远超骨干模型规模的贡献。GPT-4o 不加框架只有 32%,加上框架跳到 70%——框架贡献了 38 个百分点的提升。
ScholarQA → Asta:从研究到产品的完整路径
2025 年 1 月,Ai2 推出 ScholarQA,实现了从研究原型到可用产品的跨越:
- 自动文献对比表:将文献综述中常见的人工比对表自动化,分 Schema 生成(列名)和 Value 生成(单元格内容)两步实现,显著减少综述中最耗时的环节
- Claude Sonnet 3.7:骨干模型持续更新至最新闭源模型
- 开源代码库:
ai2-scholarqa-lib向社区开放,使任何团队都可以基于此构建自己的学术问答系统
ScholarQA 后演化为 Ai2 旗舰产品 Asta(asta.allen.ai)的核心能力模块,标志着学术 AI 正式从实验室工具走向生产级产品。
五、核心洞见
洞见一:架构缺陷不能靠模型升级解决
GPT-4o 的幻觉引用率 78–90% 不会因为参数更多或训练数据更好而显著改善——因为问题出在推理范式上:模型从静态权重中"回忆"信息,无法实时核查引用的真实存在性。OpenScholar 的解法不是更好的模型,而是不同的推理架构。这对所有 AI 垂直应用都是一个根本启示:当通用模型在你的场景持续失效时,先检查是不是架构问题,而不是模型选型问题。
洞见二:8B 打赢 GPT-4o 的关键是数据飞轮,不是参数
OpenScholar-8B 正确率超出 GPT-4o 6.1%,参数量却小得多。差距的来源是 OSDS——4500 万篇经过精心索引的学术全文。在特定领域,专用数据存储构建的护城河,比参数规模更难被复制。
洞见三:检索管道是可复用的"能力层"
OpenScholar 的数据存储 + 检索 + 自反馈框架,并不绑定特定骨干模型。它让 GPT-4o 的正确率提升了 12%,意味着这套框架可以作为独立的"能力增强层"插入任何 LLM。这为商业化提供了一条清晰路径:不卖模型,卖基础设施和框架。
洞见四:证据优先管道有代价,需要显式权衡
ScholarQA 团队诚实地指出了证据优先管道的副作用:答案可能"稍微偏题",因为模型想把找到的证据全部塞进去,即便部分证据只是间接相关。高引用覆盖率和叙述连贯性是一对内在矛盾,需要在产品设计中显式权衡,而不是默认两者都好。
六、对行业的深远影响
学术 AI 的"第三层":跨文献合成
OpenScholar 的出现,在现有工具生态中填补了一个空白层:
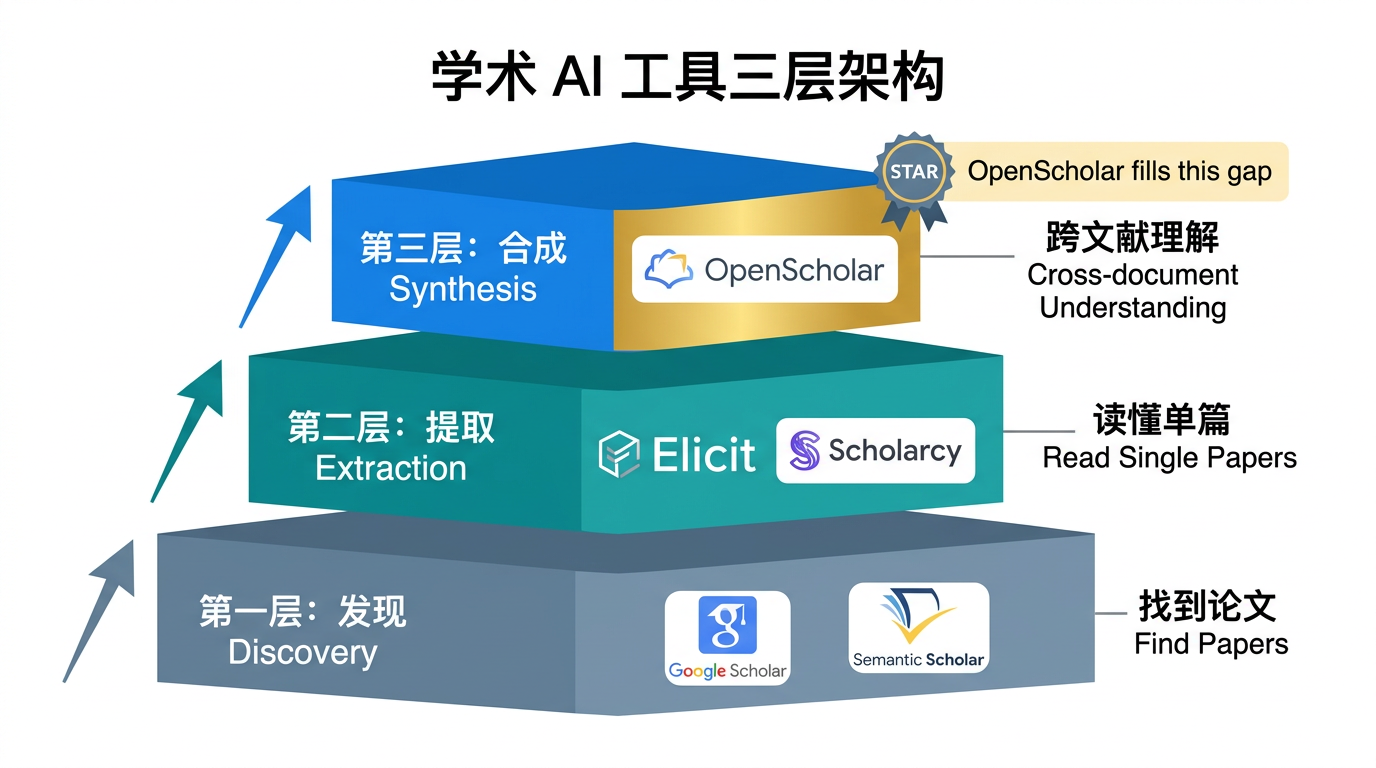
第三层的关键特征是:答案来自多篇文献的综合,而不是任何单一来源的摘录。这才是真正的文献综述能力,也是此前工具链最大的空白。
可信度成为学术 AI 的核心竞争维度
在 OpenScholar 之前,学术 AI 工具的评判维度主要是速度、覆盖范围、界面友好性。OpenScholar 用 ScholarQABench 引入了一个新的核心维度:引用可信度。
这一维度一旦被提出,就很难被忽视——因为它直接关乎科学研究的基本要求。ScholarQA-CS 子集被纳入 Ai2 的 AstaBench,成为评估下一代研究助手的标准之一,说明这一维度已经进入行业评估体系。
"可信"的工程路径,具有跨领域普适性
OpenScholar 解决的不只是学术搜索问题,而是提供了一个垂直领域 AI 可信化的工程模板:
- 先建领域专用数据存储(Domain-specific Datastore)
- 采用证据优先管道,而非答案优先
- 加入自反馈循环来提升可信度
- 完全开源以加速生态演进
这四步在法律、医疗、工程等其他需要高可信度的垂直领域,都有直接的借鉴价值。
七、实践入门
三种接入方式
| 方式 | 地址 | 适合场景 |
|---|---|---|
| OpenScholar Demo | openscholar.allen.ai | 直接体验,无需部署 |
| Asta 产品 | asta.allen.ai | 持续文献跟踪与综述生成 |
| OpenScholar 开源 | github.com/AkariAsai/OpenScholar | 自建学术问答系统 |
| ScholarQA 代码库 | github.com/allenai/ai2-scholarqa-lib | 构建自己的学术问答 API |
适用与不适用场景
适合用 OpenScholar / ScholarQA 的场景:
- 需要横跨多篇文献综合回答的研究问题("这个方法在哪些领域被验证过?")
- 对引用准确性要求高的文献综述工作
- 需要快速了解某个研究方向的技术全景
不适合的场景:
- 问题答案在单篇论文内完整存在 → 用 Elicit 或直接阅读原文更高效
- 需要最新 24 小时内预印本 → 语料库每周更新,有时差
- 非学术类内容生成 → 这不是它的设计目标
如果要构建类似系统
基于 OpenScholar 的工程经验,有三点实践建议:
1. 不要跳过数据存储建设:领域专用数据存储的建设成本,在初期看起来很重,但它是系统长期可信度的基础。拿通用互联网数据直接用,只是推迟了失败。
2. 先测基线幻觉率:在你的领域数据上,测量通用 LLM 的幻觉率。如果超过 30%,就必须考虑类似 OpenScholar 的架构,而不是继续做 prompt 优化。
3. 开源是加速器,不是竞争劣势:OpenScholar 完全开源后,社区已经在其基础上改进并超越了原始结果。对于科研机构和非营利组织,开源是获取外部研发力量的最高效方式。
八、未来展望
DR Tulu:多步搜索的下一代
OpenScholar 的直接继任者 Deep Research Tulu(DR Tulu)已在开发中。它将 OpenScholar 的单轮检索扩展为多步搜索和信息汇聚,能够执行类似人类研究者的迭代探索过程:先搜,发现需要更多信息,再搜,最后综合。这代表了学术 AI 从"单次问答"向"持续研究过程"的根本性演进。
科学 AI 的成熟期
2026 年 2 月,BigDATAwire 发表了一篇分析文章,标题是"Scientific AI Enters a More Mature Phase"(科学 AI 进入更成熟阶段)。这与 OpenScholar 的 Nature 发表在同一周。
成熟期的标志不是"AI 能做到什么",而是"AI 在可控边界内稳定地做到什么"。OpenScholar 的价值正在于此:它用明确的技术边界(4500 万篇论文、每周更新、引用可核查),换来了在这个边界内的高度可信。这种"划定边界、在边界内可信"的设计哲学,将成为科学 AI 下一阶段发展的主旋律。
结语
"科学家每天看到如此多的论文,跟上节奏是不可能的。但现有的 AI 系统并不是为科学家的具体需求而设计的。"
—— Akari Asai,OpenScholar 第一作者
OpenScholar 做的,不是让 AI 更聪明,而是让 AI 在科学场景下可以被信任。这是一个更难的目标,也是一个更正确的目标。
从"AI 幻觉 78–90%"到"与人类专家持平",从"专家偏好 32%"到"专家偏好 70%"——这组数字的背后,是一套明确的工程信念:可信度不是模型特性,而是系统设计的结果。
当你考虑在自己的领域引入 AI 时,先问一个问题:你的系统有多少比例的输出是可核查的?
参考资料
- Akari Asai et al., Ai2 & University of Washington (2024.11.21). OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs. arXiv:2411.14199. https://arxiv.org/abs/2411.14199
- Ai2 (2026.02.04). Now in Nature: Synthesizing scientific literature with retrieval-augmented LMs. https://allenai.org/blog/nature-openscilm
- Ai2 (2025.01.21). Introducing Ai2 ScholarQA. https://allenai.org/blog/ai2-scholarqa
- Ali Azhar, BigDATAwire (2026.02.05). OpenScholar Shows Why Grounded AI Matters for Scientific Research. https://www.hpcwire.com/bigdatawire/2026/02/05/openscholar-shows-why-grounded-ai-matters-for-scientific-research/
- University of Washington News (2026.02.04). In a study, AI model OpenScholar synthesizes scientific research and cites sources as accurately as human experts. https://www.washington.edu/news/2026/02/04/in-a-study-ai-model-openscholar-synthesizes-scientific-research-and-cites-sources-as-accurately-as-human-experts/
- Nature (2026.02.04). Synthesizing scientific literature with retrieval-augmented language models. https://www.nature.com/articles/s41586-025-10072-4