Agentic 数据工程:钻进数据栈的 Upriver 拿到了钱
信息分析 | 2026 年 6 月 | 面向数据工程师与企业 AI 落地负责人

1400 万美元在 2026 年的 AI 融资里几乎不值一提——隔壁同一天,贝佐斯的 Prometheus 拿了 120 亿、Helix 开局就是 100 亿。但这周我盯上的偏偏是这笔小钱:以色列公司 Upriver 完成 1400 万美元种子轮,领投是 Valley Capital Partners 和 Hetz Ventures。它做的事一句话能说清——替企业把烂数据自动修好,让 AI 能真正跑起来。
值得写它,不是因为钱多,而是因为这笔钱是一个信号:过去两年企业把预算砸在模型和芯片上,现在开始算账,反复算出来的答案是“卡在数据上”。当资本开始给“修数据的 agent”开支票,说明 agentic 数据工程已经从 PPT 概念,走到了有人愿意为它的产能付费的阶段。这篇就从这笔融资切进去,聊聊这条赛道到底在赌什么、技术上难在哪、对数据工程师又意味着什么。
一、AI 落地的瓶颈,早就从模型挪到了数据
先把背景钉死。模型这两年卷得飞起,但企业真正部署时,绊倒它们的几乎从来不是“模型不够聪明”,而是喂给模型的数据是一团乱麻:管道断了、系统对不上、关键口径只存在某个工程师的脑子里。
Gartner 的两组数据把这件事量化得很清楚。2026 年 1 月,Gartner 发现至少 50% 的生成式 AI 项目在 PoC 阶段之后被放弃,数据质量是主因之一;同年 4 月的报告里,38% 的技术领导者直接把“数据质量差或数据不可用”列为 AI 项目失败的直接原因。换句话说,一半的 AI 项目死在了上线前,而压死它们的不是算法,是数据地基。
| 维度 | 行业现状(2026) | 含义 |
|---|---|---|
| 生成式 AI 项目存活率 | ≥50% 在 PoC 后被放弃 | 大多数 AI 试点根本到不了生产 |
| 失败归因 | 38% 直接归因于数据质量/可用性 | 问题在“输入”而非“模型” |
| 典型企业数据现状 | 多套 CRM、孤岛数据库、years 累积的断裂管道 | 没有统一架构,数据“散、乱、不可信” |
这就是为什么 Upriver 的 CEO Ido Bronstein 会说,他们要做的是“让数据基础设施变得隐形”——让企业不必再为数据团队的救火买单,直接从乱数据里把组织知识提出来,拿到 AI 当初承诺的那个“力量倍增器”。这句话听着像营销,但背后是个很实在的痛点:数据工程已经成了企业 AI 转型里最大的瓶颈工种,每个业务部门都在等数据团队把数据准备好,而数据团队淹没在重复劳动里抬不起头。
二、Upriver 是谁,凭什么拿这笔钱
Upriver Data 成立于 2024 年,两位创始人——CEO Ido Bronstein 和 CTO Omri Lifshitz——此前花了十年构建大规模情报系统(据 Business Insider 报道是为以色列军方做的)。这个出身很关键:情报系统天然要在海量、异构、互相矛盾的数据源里做出可被追责的判断,这跟“企业数据栈”的问题结构高度同构。两人后来发现,每一家跑在现代云栈上的公司,本质上都在经历他们当年同样的痛苦,于是把这套能力产品化。
更值得看的是它的天使投资人名单,几乎是一份“数据工具圈点将录”:
| 投资人 | 身份 | 信号 |
|---|---|---|
| Valley Capital Partners + Hetz Ventures | 联合领投 | 机构对 agentic 数据工程下注 |
| Lew Cirne | 可观测性巨头 New Relic 创始人 | “监控数据”一派背书 |
| Abe Gong | 数据质量项目 Great Expectations 创始人 | “数据校验”一派背书 |
| Yotam Segev、Tamar Bar-Ilan | 数据安全独角兽 Cyera 创始人 | “数据安全”一派背书 |
可观测、数据质量、数据安全三个方向的开创者同时下注,本身就说明:这帮最懂数据基础设施的人,认为“用 agent 自动接管数据工程”是下一个值得押的位置。客户侧,Upriver 已经被 Unity 和每日邮报集团(DMGT)采用,合作伙伴包括 Databricks 和 Snowflake;网络搜索基础设施公司 Nimble 报告部署后生产力提升 60%——这个数字虽是单一客户口径,但至少给“能用”提供了一个锚点。
三、解法拆解:钻进栈里,而不是坐在栈上
Upriver 反复强调一句话:它不是“在模型/数据栈之上再糊一层薄壳”。Hetz 的合伙人 Guy Fighel 把差异说得很直白——多数平台坐在数据栈“上面”(sit on top),产出的是更干净的仪表盘;Upriver 是钻进栈“里面”(go into it),这才是“漂亮仪表盘”和“能真正投产的 AI”之间的区别。 这句话是理解整条赛道的钥匙。
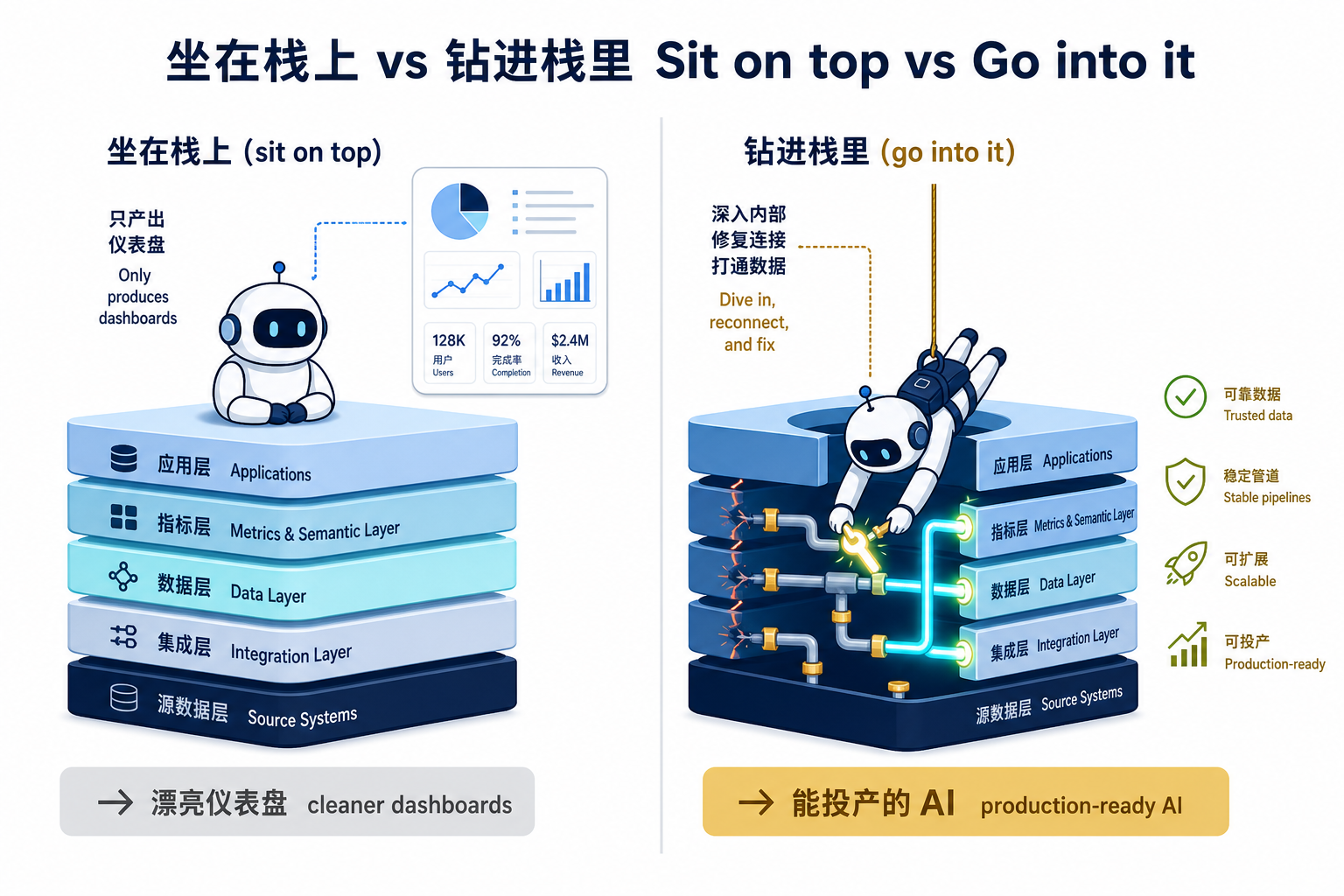
技术上,它把能力拆成两层引擎,对应数据工程里两件机器一直做不好的事:
Context Engine(上下文引擎):绘制企业整个数据生态的本体(ontology)——哪些表是什么、字段口径怎么定义、管道之间如何依赖、哪些是“部落知识”(tribal knowledge,那些只存在老工程师脑子里、从不写进文档的规则)。这层解决的是“AI 看不懂这家公司的数据”的问题。没有它,再强的模型面对一张陌生的宽表也只能瞎猜。
Reasoning Engine(推理引擎):一组协同的 agent,做可验证推理(verifiable reasoning)——把每个决策锚定在 context engine 给出的上下文上,并在割裂的数据栈之间交叉校验结果,而不是凭语言模型的“感觉”直接改数据。
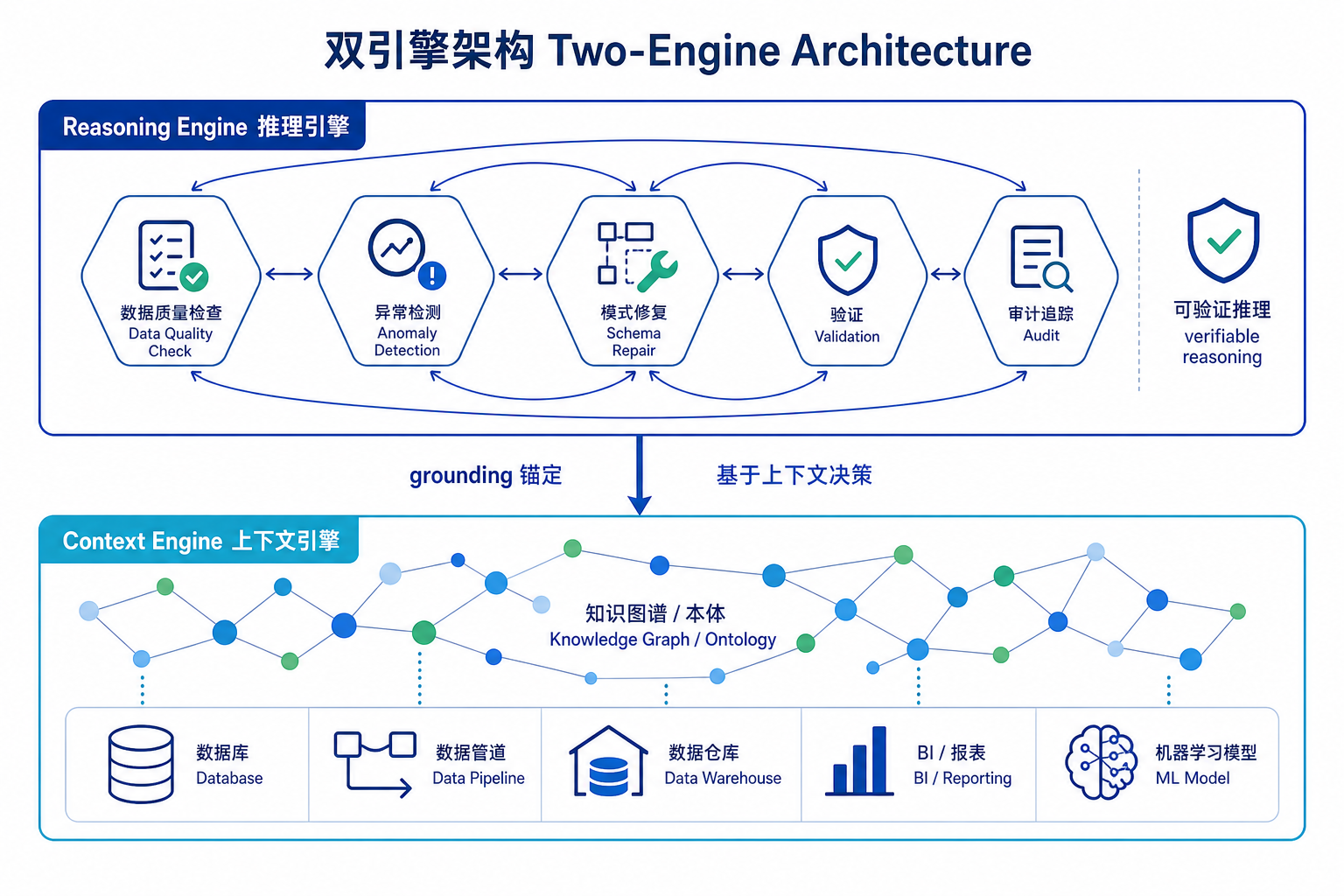
为什么“可验证”是这里的命门?因为数据工程是不能容忍幻觉的场景。聊天机器人答错一句,用户笑笑就过去了;但一个 agent 在生产管道里把字段映射错了、把脏数据当成干净数据放行,错误会顺着下游所有报表、模型、决策一路放大,而且往往很久才被发现。这也是为什么市面上大量“self-healing pipeline(自愈管道)”其实只做到了第一层——失败重试加退避,真正能自主改 schema、补数据集还敢放进生产的极少。Upriver 的赌注就是:把上下文(知道这家公司数据长什么样)和可验证推理(每步都能交叉核对)绑在一起,才配得上“自主接管数据工程”这句话。
落地形态上还有个细节值得注意:它能直接通过 Claude 和 Cursor 调用,把数据工程能力塞进工程师本来就在用的开发环境里。这意味着它不强迫团队换平台,而是嵌进现有工作流——这往往是 to B 工具能不能真正被用起来的关键。
洞见一:上下文是新的护城河
谁能把一家企业“数据到底意味着什么”的本体建得更准、更新得更勤,谁的 agent 就更不容易出错。模型是公共品,上下文是私有资产——竞争正在从“谁的模型强”转向“谁更懂你的数据”。
四、数据工程师会失业吗:不是消失,是上移
每次“自动化某工种”的工具拿到钱,最先被问的都是“那人怎么办”。这里要分清两件事。
Upriver 自动化掉的,是数据工程里最磨人、最不增值的那部分:查为什么管道又断了、把一堆压根没打算互相通信的工具缝起来、一遍遍处理重复的技术杂活。把这些拿走之后,工程师的精力理论上会上移——从“让数据能用”上移到“决定数据到底意味着什么”:定义口径、设计语义、判断哪些数据值得信任、为业务问题选对数据。这部分恰恰是最需要人、也最难被自动化的。
但这里有个不必粉饰的现实:上移是“理论上”的。当一个数据团队的产能被 agent 放大几倍,企业未必会让人去做更高阶的事,也可能直接选择用更少的人干同样的活。工具能创造“上移”的空间,但要不要、能不能上移,取决于组织怎么用它——这是管理决策,不是技术决策。对个人来说,能给出确定答案的只有一条:把自己的价值压在“查管道、缝工具”这类会被接管的活上,风险只会越来越高。
五、赛道与风险:AI-native 新秀 vs 数据老厂
把视野拉开,Upriver 不是孤例,而是一波浪潮里的一朵。私募领域有 Capsa,数据栈本身有 Upriver,它们卖的是同一个底层判断:地基比模型更重要(the foundation matters more than the model)。这条赛道的竞争格局大致是两股力量在掰手腕:
| 阵营 | 代表打法 | 优势 | 软肋 |
|---|---|---|---|
| 数据老厂(可观测/质量/治理) | 在成熟产品上加 AI 功能 | 客户基础、稳定、合规背书厚 | 架构是“坐在栈上”,难深入改数据 |
| AI-native 新秀(如 Upriver) | 从第一天就以 agent 为核心 | 能“钻进栈里”自主执行 | seed 阶段早、未经规模验证 |
| 云数据平台(Databricks/Snowflake 等) | 平台内置 agent 能力 | 离数据最近、生态闭环 | 跨栈、跨厂商场景是天然短板 |
要冷静地看 Upriver 的风险:1400 万美元是种子轮,金额小、阶段早、远未经过规模验证。它面对的企业环境是出了名的难啃——多年沉淀的割裂遗留系统,往往需要大量定制,集成周期长、ROI 兑现慢。同时,数据管理老厂和其他 AI 数据准备创业公司都在抢同一个“帮 AI 解决数据问题”的故事。它能不能把“钻进栈里”的技术优势,转化成可规模复制的产品,而不是一单一单的重定制,才是这笔种子轮真正要回答的问题。
洞见二:小融资,大拐点
值得关注的不是 1400 万这个数字,而是“修数据”这件最不性感的脏活,正在被资本重新定价为一门有产能、可投资的生意。这通常是一个品类要起来的早期信号。
六、本土视角:国内的 agentic 数据工程走到哪了
国内这条线其实并不落后,只是叙事不同。过去一年,云厂商和数据平台都在把 agent 往数据治理、数据开发里塞——从“数智化”到“数据智能体”,方向和 Upriver 高度一致:让 agent 接管取数、建模、质量校验这类重复劳动。差别在于约束条件。
国内企业的数据环境同样割裂,但叠加了更强的合规与数据安全硬约束:数据分类分级、跨域流通、个人信息保护,让“agent 自主改生产数据”这件事的门槛更高——可验证推理在这里不只是质量问题,更是合规问题,每一步自动操作都可能需要留痕、可审计、可回滚。另一个本土特点是,很多企业的“部落知识”深埋在历史项目和外包团队里,context engine 要建本体,面对的不只是技术债,还有组织债。所以国内更现实的路径,大概率不是“全自动接管”,而是“agent 干杂活、关键决策仍由人把关”的人机协作形态——这也呼应了之前聊数据契约、意图驱动治理时的判断:自动化要往前走,但生产环境的双门禁不能省。
结论
把这笔融资读完,能带走的判断有四条:
- AI 落地的主战场已经从模型转到数据。一半 genAI 项目死在 PoC 之后,数据质量是头号杀手;谁先把数据地基修好,谁才有资格谈 AI 投产。
- “钻进栈里”是这一代数据工具的分水岭。坐在栈上做仪表盘的时代在退潮,能自主进入数据栈、做可验证修复的 agent 才是新故事;而可验证推理(不容幻觉)是它的命门。
- 上下文正在成为新的护城河。模型是公共品,企业数据的本体是私有资产;竞争从“谁的模型强”转向“谁更懂你的数据”。
- 数据工程师的价值会上移,但要靠组织兑现。工具能把人从查管道、缝工具里解放出来,但“上移”还是“裁员”是管理选择;个人能做的,是把价值压到“决定数据意味着什么”这一侧。
最后留一个问题给你:如果有一个 agent 已经能自主修复你的数据管道、还敢把结果放进生产,你会先让它接管哪一段最脏的活——又有哪一段,你说什么都不敢撒手交给它?
参考资料
- Duncan Riley. 《Upriver raises $14M to automate enterprise data engineering for AI》. SiliconANGLE, 2026-06-11.
- 《Upriver raises $14M to fix AI's enterprise data problem》. The Next Web (TNW), 2026-06-11.
- 《Upriver Raises $14M to Automate the Enterprise Data Foundation for AI》. ACCESS Newswire / Yahoo Finance, 2026-06-08.
- 《Upriver Raises $14M to Automate Enterprise Data》. AIPressRoom, 2026-06-12.
- Gartner. 《AI projects in infrastructure and operations stall ahead of meaningful ROI returns》, 2026-04-07;《Why GenAI projects fail》, 2026-01.