Agent 查数的准确率悬崖:语义层 vs Text-to-SQL

Deep Research 报告 | 2026 年 6 月 | 面向数据工程、数据平台与 AI 应用负责人、关注 Agent 查数与语义治理的从业者
摘要
有一个判断这两年被反复证伪:"等模型再强一点,自然语言查数据这件事就解决了。"
模型确实强了。dbt 在 2026 年重跑了三年前的基准,同一套问题,Text-to-SQL 的准确率从 2023 年的 32.7% 涨到了 64.5%,几乎翻倍。但同一批前沿模型,换到真实企业数据库上测,准确率从学术基准的 86%~91% 一路跌到 10%~21%——data.world 的 Spider 2.0、MIT 的 BEAVER 三个独立基准,给出的数字高度一致。这道从"演示能用"到"生产不敢用"的断崖,被称为准确率悬崖(accuracy cliff)。
悬崖不是模型不够聪明造成的,再大的模型也补不平。它的结构是:决定一个答案对错的关键信息——指标口径、实体身份、财年定义、谁能看哪列——根本不在数据库的 schema 里。 它们躺在文档里、BI 定义里、分析师的脑子里。模型看不到这些,就只能猜;而猜错时,它不会报错,而是流畅地给你一个看起来对、其实错的数字。
本文用五组一手基准把这件事讲透,然后回答一个工程问题:既然行业已经收敛到同一个答案——语义层(semantic layer),那它到底解决了什么、解决不了什么,以及为什么"在编译期治理"比"事后补救"是架构上的根本差别。
一、好消息:模型真的会写 SQL 了
先把好消息讲清楚,否则后面容易被误读成"唱衰大模型"。
dbt 在 2026 年初做了一件很有意思的事:把他们 2023 年那套 Text-to-SQL vs 语义层的基准原样重跑了一遍。同样 11 个问题、每个跑 20 次,只换成最新一代模型(Sonnet 4.6、GPT-5.3 Codex)。结果很提气:
- Text-to-SQL 的整体准确率从 32.7% 涨到 64.5%——几乎翻倍。三年前给不出稳定结果的问题,现在很多都能 100% 答对了。
- 在需要"多跳关联"的复杂问题上,GPT-5.3 Codex 的 Text-to-SQL 甚至能打到 100%——这是 2023 年想都不敢想的。
所以"模型不行"这个判断是错的。问题不在生成 SQL 的能力。真正的麻烦,是当你把同一个模型从干净的学术基准,搬到一个一千多列、二十年命名history的真实数仓时,发生了什么。
二、坏消息:从 86% 到 10%,准确率悬崖
学术基准(Spider 1.0 那一类)是一道翻译题:schema 小到能整张读进上下文,列名见名知义,问题里几乎包含了写出查询所需的全部信息。在这种地形上,现代模型表现确实优秀——GPT-4o 在 Spider 1.0 上 86.6%,o1-preview 的 agent 框架 91.2%。这些数字是真的,但它们衡量的是"翻译",不是"理解"。
真实企业数据不是翻译题,是面对一座千列资产做解释题。三个独立基准先后把这第二个问题直接量了出来,彼此印证到令人不安的程度:
| 基准 | 数据特征 | 学术分(Spider 1.0 类) | 真实企业分 |
|---|---|---|---|
| Spider 2.0(data.world,ICLR 2025) | 632 个真实企业工作流任务,BigQuery/Snowflake 库常超 1000 列,解法 SQL 可超 100 行 | 91.2%(o1-preview agent)/ 86.6%(GPT-4o) | 21.3% / 10.1%,约 8.5× 塌缩 |
| BEAVER(MIT) | 首个用私有数仓查询日志构建的基准,模型无法靠"背过的网页"取巧 | — | GPT-4o 0%~2%:作者直言"没有一个现成 LLM 能答对任何一题" |
| BIRD | 大型、脏数据库的长期基准 | 最佳系统约 82% | 人类数据工程师 92.96%——这个两位数差距,熬过了每一代模型 |
同一个模型,跨过基准走进数仓,凭什么掉 70 分?dbt 在它的报告里点了最关键的一句话,值得抄下来贴在每个"我们 AI 准确率 95%"的 PPT 旁边:"Text-to-SQL 会高高兴兴地给你一个错误的数字(cheerfully give you a wrong number)。"
这就是悬崖最危险的地方——失败的样子,和成功一模一样。 语义层答不出时会报错;Text-to-SQL 答不出时,会给你一个能跑、能解释、就是不对的结果。送进董事会 PPT、监管报表、公司 KPI 看板的那一刻,没人知道它错了。
三、悬崖的成因:决定对错的东西,不在 schema 里
为什么是结构性的、模型补不平的?因为掉的那 70 分,藏在三道模型天然看不见的鸿沟里。
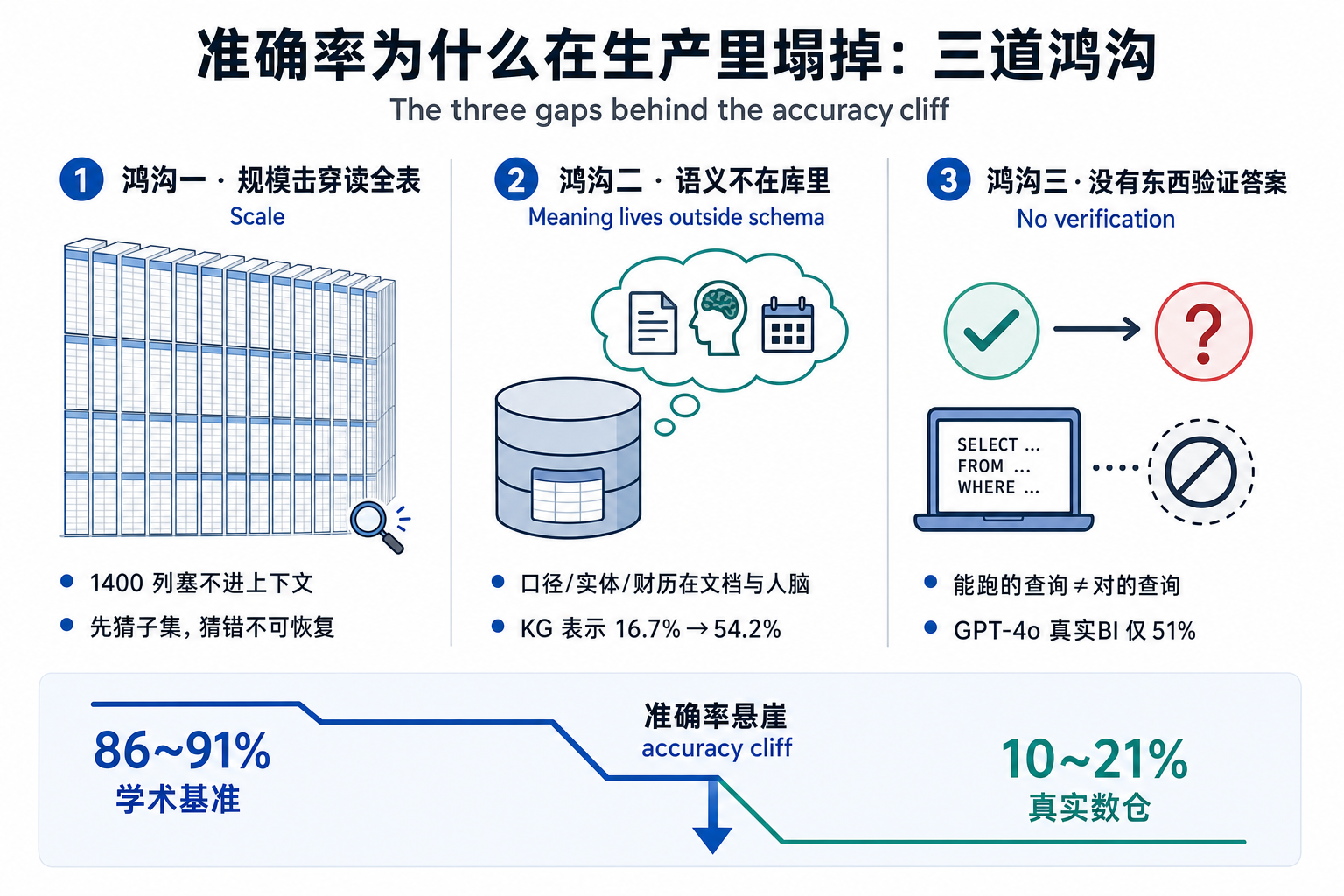
鸿沟一:规模击穿了"读全表"的策略。 30 列的库,模型把整张 schema 读进去、通盘推理。1400 列的资产,schema 要么塞不进上下文,要么塞进去了相关性也被稀释。模型必须先猜哪个子集相关,再动笔——而这一步猜错,是不可恢复的。Spider 2.0 最难的失败,不是语法错,是"建在错误的表上"。
鸿沟二:决定性的语义,根本不在数据库里。 四个带 "revenue" 的列,哪个是财务认账的那个?计费库里的 customer 和 CRM 里的 account 是同一个实体吗?"上季度"指的是自然季还是财季?没有任何 schema 编码这些答案——它们在文档里、BI 定义里、分析师脑子里。Sequeda 等人 2023 年把这个变量单独拎出来做了实验:GPT-4 零样本在一个保险企业 schema 上只有 16.7%,在高复杂度问题上是 0%;把同一个库换成知识图谱表示,同样的问题、同样的模型,跳到 54.2%。模型一个字没改,变的只是可见的语义。
鸿沟三:没有任何东西验证答案。 一个能解析、能执行的查询,长得和正确查询一模一样。运行时没有 ground truth,不会有人提示你"这个 join 悄悄把订阅数翻了倍"。Snowflake 工程团队在他们 150 道真实 BI 问题上实测 GPT-4o 51%——意味着差不多每两个答案就有一个是错的,而且错得很流畅。
这三道鸿沟落到生产里,会固化成一套可复现的失败清单。做过 Text-to-SQL 事故复盘的人,对这张表不会陌生:
| 失败模式 | 发生了什么 | 为什么危险 |
|---|---|---|
| 指标漂移 | 模型选了个听起来对、但不是认账口径的列 | 营收/流失/毛利各算各的,团队靠吵架对账 |
| 错误关联 | 用猜的键或残缺关系 join | 行悄悄重复、记录消失、总数虚高,全程无报错 |
| schema 瞎猜 | 凭命名习惯假设表的语义 | 跑在了错误的事实源上,结果看着合理直到财务来审 |
| 财历错配 | 该用财季时用了自然季 | 季报月报永远和财务对不上,董事会上爆雷 |
| 越权泄露 | 只为"答对"而带上了受限列 | PII/敏感字段从没人复核的 AI 查询里漏出去 |
| 无审计链 | 生成的 SQL 背后没有经批准的定义、没有版本 | 无法向监管证明"这个数字为什么是这么来的" |
每一行的根因都是同一个:决定对错的上下文在 schema 之外,而模型从没见过它。
四、唯一被反复验证的解法:把上下文做成基础设施
公开记录里,能把丢掉的准确率重新捞回来的,只有一个模式,而且被独立验证了至少四次:把缺失的上下文显式化,并强制生成过程经过它。
| 研究 / 系统 | 无结构 | 加了结构 | 加的是什么 |
|---|---|---|---|
| Sequeda et al.(2023) | 16.7% | 54.2% | 知识图谱表示 |
| Snowflake Cortex Analyst(2024) | 51% | 90%+ | 手工编写的语义模型(Semantic View) |
| dbt Labs(2026,11 题集) | 84%~90% | 98%~100% | 确定性语义层(MetricFlow) |
| Atlan AI Labs(2026,522 query / 13 表 94 列) | 基线 | 相对提升 38% | 富语义元数据 |
dbt 那组数字尤其干净:在做过建模的项目上,Text-to-SQL 是 84%~90%,而语义层覆盖到的问题逼近或就是 100%——因为语义层用 MetricFlow 确定性地生成查询,模型只负责把自然语言拆解成"选哪个指标、哪些维度",一旦选对,SQL 保证正确,且不会出现"跑两次数字略有不同"的诡异情况。
这里有个常被误解的点:语义层的价值不只是"更准",更是"失败方式不同"。 dbt 说得很直接——语义层覆盖不到的问题,它会告诉你它答不了,而不是编一个。对要送审计、送 KPI 看板的场景,"会报错"和"会编数"之间的差别,就是全部。
值得泼一盆冷水的是:现在 Spider 2.0 排行榜上把分数刷回 70%~96% 的系统,不是更强的裸模型,而是层层叠叠的 agent 脚手架——探索 schema、检索上下文、执行、自我纠错,每道题烧掉很多次模型调用。它们靠每次查询都临时重建一遍缺失结构来逼近,代价是延迟、token 和"两次跑结果不一定一致"。语义层是另一条路:把这套结构一次性建好、版本化,让每个查询都编译着穿过它。 同一个洞察,一个是一次性的、确定的,一个是每次重来的、概率的。
五、两种架构:概率式生成 vs 编译式治理
把上面这件事落到架构上,就是两条根本不同的路径。
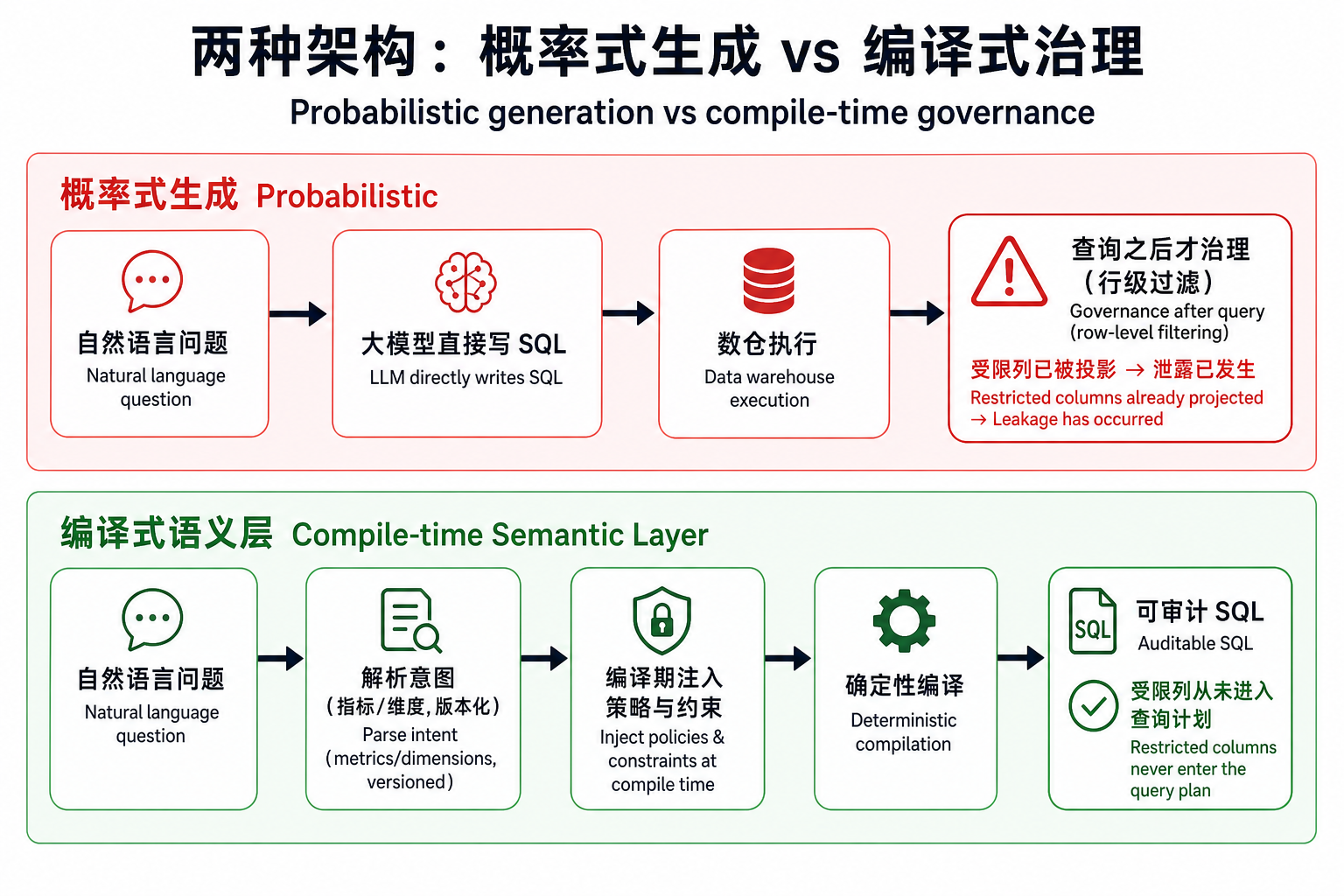
概率式生成:问题 + schema → 模型直接写 SQL → 丢给数仓执行。治理(行级/列级权限)发生在查询之后——数仓把行返回来,再过滤。问题在于:行级安全能挡住你不该看的行,却挡不住你不该投影的列。等答案上了屏幕,泄露已经发生。
编译式语义层:问题 → 解析意图(映射到版本化的指标/维度)→ 在生成 SQL 之前注入策略与约束 → 编译出确定性、方言正确、可审计的 SQL。治理发生在编译期,受限的列根本进不了查询计划。
用一个具体例子感受差别。业务问:"给我看高风险客户的逾期金额和联系方式。"
概率式生成会很"听话"地把所有相关字段都塞进 SELECT:
-- 无语义层:看着合理,敏感字段直接泄露
SELECT c.customer_name, c.mobile_number, c.email, c.pan_number,
r.risk_score, l.overdue_amount
FROM customers c
JOIN loans l ON l.customer_id = c.customer_id
JOIN risk_scores r ON r.customer_id = c.customer_id
WHERE r.risk_score > 80 AND l.overdue_amount > 0;模型没有恶意,它只是在"最大化答对这个问题"。手机号、邮箱、PAN 都和"联系方式"相关,于是全都进了结果。而编译式语义层会在生成 SQL 之前就按角色把策略应用上:
-- 有语义层:编译期执行策略,受限列从未进入查询计划
-- 角色: regional_manager
-- 允许: customer_name(脱敏), risk_band, overdue_amount_bucket
-- 编译期移除: mobile_number, email, pan_number
-- 行级策略: c.region_id = CURRENT_USER_REGION()
SELECT MASK(c.customer_name) AS customer_name,
r.risk_band, l.overdue_amount_bucket
FROM governed_customer c
JOIN governed_loan_exposure l ON l.customer_id = c.customer_id
JOIN governed_risk_profile r ON r.customer_id = c.customer_id
WHERE r.risk_band IN ('HIGH','CRITICAL')
AND l.has_overdue = TRUE
AND c.region_id = CURRENT_USER_REGION();第二段不是"更好的 SQL",它是从一个已解析、版本化的业务定义里编译出来的 SQL。监管下个季度可以重跑、拿到同一个数字;复核的人能指出每个子句来自哪条定义。第一段两样都没有。
顺带说一句很多人忽略的事实:"temperature=0 ≠ 确定性"。 浮点累加顺序、GPU 并行规约、请求批处理、MoE 路由都会引入跑与跑之间的差异——Anthropic 自己的文档都写明"即便 temperature 0.0,结果也不完全确定"。对一个要面对审计的受监管指标,"模型通常会给同样的答案"不是一个你能拿得出手的控制项。真正的确定性,得来自模型之外的编译期治理。
六、语义层不等于上下文层:行业收敛之后的下一道分水岭
到这里有个容易混淆的概念要厘清。语义层回答的是"这个指标是什么意思";但 Agent 要在企业里安全地跑起来,还需要回答"这个 Agent 有没有资格用它、它归谁管、血缘从哪来"——后者业界开始叫它上下文层(context layer)。Atlan 的提法很精炼:语义层管语义,上下文层管身份、权属与血缘。一个让 Agent 答得对,一个让 Agent 答得该。
更值得注意的是行业已经收敛:到 2026 年,几乎所有正经玩家都在把 LLM 接到某种语义层上,差别只剩四个维度——有多确定、治理多深、覆盖多广、是否锁定单一数仓。
| 系统 | 准确率信号 | 关键特征 |
|---|---|---|
| Snowflake Cortex Analyst | 51% → 90%+(Semantic Views) | 准确但锁 Snowflake |
| Databricks AI/BI Genie | 50% → 90%(语义curation后) | Unity Catalog 指标 + 验证步 |
| dbt 语义层 / MetricFlow | 覆盖问题逼近 100% | 确定性,但覆盖即上限、多跳仍会失败 |
| Looker 对话式分析 | 映射到治理度量 | 用 LookML 组合查询而非裸写 SQL |
| Cube / AtScale | AtScale 自报 NLQ <20% → 100% | 确定性编译,经 MCP 服务于 Agent |
收敛本身就是头条新闻:语义层不再是"可选的加分项",而是让 AI 在数据上可信的必备基础设施。 剩下的,都是工程取舍。
一个实用的副产品:当你下次看到任何厂商的"准确率 95%",可以用四个问题剥掉营销外衣——测的是谁的数据(Spider 1.0 类几乎预测不了千列数仓)、多少题多少次跑(小样本要披露)、单次还是带脚手架(带重试自纠的要问 token、延迟和一致性)、失败长什么样(会报错的系统在 90% 也安全,会编数的系统在 99% 也危险)。
七、ICE 观察
技术视角:准确率问题,本质是"上下文工程"问题
这一轮基准给数据工程师最重要的提醒是:别再把精力押在"换更大的模型"上。 从 16.7% 到 54.2%、从 51% 到 90%、从 84% 到 100%,每一次大跨越都来自给模型补结构,而不是换模型。这件事的工程重心,正在从"调 prompt、追新模型"迁移到一项更朴素也更难的活——把散落在文档、BI 工具、老分析师脑子里的语义,沉淀成版本化、可治理、机器可消费的元数据。这正是知识图谱、语义模型、指标层这些"老概念"在 Agent 时代被重新激活的原因。
也要诚实地标出边界:语义层不是银弹。它的命门是覆盖率——只能答建模覆盖到的问题,多跳、临时探索的长尾仍要回落到 Text-to-SQL。所以务实的架构不是"二选一",而是 dbt 给的那条分流规则:要准确(董事会、审计、KPI)走语义层;要灵活(一次性探索、原型)先问语义层能不能答,不能再回落到带尽量多 schema 上下文的 Text-to-SQL。
落地视角:把"治理"从查询之后挪到编译之前
对正在建 Agent 查数能力的团队,最该改的一个认知是治理的时机。把权限、脱敏、口径放在查询返回之后做过滤,是结构性地太晚了——列一旦被投影出来,泄露就已发生;数字一旦被算错,错的口径已经流进了下游。真正稳的做法,是让查询在编译期就穿过一层"自带规则"的治理:意图解析 → 策略与约束注入 → 确定性编译 → 可审计 SQL。这套"编译期治理"的思路,和我们在可信数据流转、数据自带规则跨域执行上的工作是同一条技术主线——让规则随数据/查询一起被携带和执行,而不是靠下游的人工复核去兜底。 区别只在边界:本文谈的是企业内一个数仓上的语义与权限,跨组织、跨域的数据流转还要额外解决信任与可见性问题,那是另一个更难的题。
本土视角:数据要素要"用得对",语义层是绕不开的一环
放到国内"数据要素×"和工业数据筑基的语境里,这件事的意义更直接。我们反复讲"让数据从沉睡走向流动和被用",但"被用"有一个隐含前提常被跳过——用出来的数字得是对的、可复现的、可追责的。 一个连"营收口径""活跃客户定义"都没有统一治理的组织,让 Agent 直接对着原始库自然语言查数,大概率是在批量生产"看着对、其实错"的结论。语义层/上下文层,恰恰是把"数据资源"变成"可信生产力"之间,那道最不显眼、却绕不开的工程地基。
结论
把这篇收束成几句话:
- 模型会写 SQL 了,但这不解决问题。 Text-to-SQL 三年翻倍到 64.5%,可一进真实数仓就从 86% 跌到 10%——准确率悬崖是结构性的,不是模型迭代能填平的。
- 悬崖的根因在 schema 之外。 决定对错的口径、实体、财历、权限,模型天生看不见;看不见就猜,猜错还不报错——这才是生产里最贵的失败。
- 唯一被反复验证的解法是给模型补结构。 知识图谱、语义模型、确定性语义层,四次独立实验都指向同一个方向:准确率在上下文里,不在模型里。
- 架构上的分水岭是"何时治理"。 编译期治理(生成前注入策略、确定性编译、可审计)对比事后过滤,是可信与不可信的分界线。
回到最朴素的那句话:衡量一套 Agent 查数系统好不好,不要只看 demo 里那个漂亮的准确率,要看它答不出来的时候做什么——是老老实实报错,还是流畅地编一个数字给你。前者在 90% 也能上生产,后者在 99% 也是一台"自信的错误生成器"。 你的系统,是哪一种?
参考资料
- dbt Labs. Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update. dbt Developer Blog. 2026-04-07. https://docs.getdbt.com/blog/semantic-layer-vs-text-to-sql-2026
- Lei et al. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. ICLR 2025. https://arxiv.org/abs/2411.07763
- MIT. BEAVER: An Enterprise Benchmark for Text-to-SQL. arXiv:2409.02038. https://arxiv.org/abs/2409.02038
- Sequeda, Allemang, Jacob. A Benchmark to Understand the Role of Knowledge Graphs on LLM's Accuracy for Q&A on Enterprise SQL Databases. 2023. https://arxiv.org/abs/2311.07509
- Snowflake Engineering. How Cortex Analyst Achieves High Text-to-SQL Accuracy for BI. 2024. https://www.snowflake.com/en/engineering-blog/cortex-analyst-text-to-sql-accuracy-bi/
- Atlan AI Labs. How Enhanced Metadata Delivers 38% Better AI Accuracy. 2026-06-17. https://atlan.com/know/enhanced-metadata-improves-query-accuracy/
- Atlan. Context Layer for AI Agents: Enterprise Guide 2026. 2026-05-08. https://atlan.com/know/context-layer-for-ai-agents/
- Colrows. The Text-to-SQL Accuracy Cliff: Why Deterministic Compilers Beat LLM Guessing. 2026-06-11. https://colrows.com/blogs/text-to-sql-accuracy-cliff/
- BIRD Benchmark. https://bird-bench.github.io/