零基思维:AI 时代的架构决策原则
架构思考 · 零基思维 × AI-Native × Strangler × 研发工作流 | 2026 年 5 月 | 约 14 分钟阅读

TL;DR · 4 句话核心
- 零基思维是一种架构决策原则——要求每个关键架构决定从 0 论证合理性。它作用于决策、不作用于代码——论证后保留旧代码也是零基。
- AI 没有吃掉所有中间层——已吃掉 BFF / 轻量 ETL / 文档处理 / 报表生成器;正在改造消息队列 / API 网关 / 工作流引擎 / RPA / BI;不会替代 OLTP 数据库 / 底层存储 / 网络 / 安全;同时催生了向量存储 / Agent 路由 / Token 计量 / 模型评测四个新中间层。
- 零基 vs 打补丁的分界取决于两个变量:业务上 AI 的核心程度 × 技术上的存量约束。4 个象限对应 4 种完全不同的动作,只有一个象限(业务核心 + 技术轻量)才是真正的"全力零基"场景。
- AI-Native 架构有 6 个不可妥协的特征:流式优先、Agent 编排一等公民、Token 经济底层化、概率性输出处理、人机协作 UX、持续学习数据回流。不满足这 6 条,所谓的"AI 重写"还是打补丁。
序:M4 + Cursor 进入研发——为什么"零基"突然可行了
2026 年春天,端侧 AI 突然从"演示级"变成"真的能用":
- Apple M4 Pro / Max 系列:32GB - 128GB 统一内存,本地能跑 Qwen2.5-Coder 32B / Llama 3.1 70B / Phi-4 全量推理,单 token 延迟稳定在 20-50ms,已经能支撑真实研发场景
- Cursor / Claude Code / Windsurf:从"代码补全"进化到"项目级 Agent"——能读懂整个仓库、跨文件重构、自主跑测试、识别 PR 风险、Plan-Edit-Verify 闭环成型
- MCP(Model Context Protocol):让 AI Agent 能稳定调用工具、数据库、第三方 API——从"会写代码的实习生"升级为"能上手系统的工程师"
这些不是单点变化。它们叠加起来意味着一件事:研发工作流第一次真正进入了"AI Agent 协同"阶段——不再是"工程师写代码 + AI 给点提示"的辅助阶段。
当工作流变了,架构就会变。
过去半年,越来越多产品架构师在做同一件事:抛开历史技术债,从底层 API 和业务逻辑开始,完全围绕"流式交互 + Agent 编排"重新设计产品架构。这种做法被冠以一个名字——零基思维(Zero-Base Thinking)。
本文要做的,是把"零基思维"作为一个可被严肃使用的架构方法论系统讲一遍——它的精确定义、它对应的 AI-Native 架构是什么样、什么场景该零基、什么场景该打补丁、怎么落地不翻车。
一、先把"零基思维"讲清楚:一个借自预算管理的架构决策原则
本节要点:零基思维不是软件工程概念,是从预算管理领域借来的决策原则。它要求每个关键架构决定都从 0 论证合理性——这是一个作用于决策、可保留代码、可灵活规模的方法论。先把它的定义讲准确,后面的所有判断才有依据。
1.1 概念起源:从零基预算(1970s)到零基架构(2026)
"零基"(Zero-Base)这个词最早出现在 1970 年代的预算管理领域。Texas Instruments 的 Peter Pyhrr 提出了 零基预算(Zero-Base Budgeting, ZBB):
每一笔预算从 0 开始证明合理性,而不是沿用上一年的基数 + 增量调整。
这与传统"基数预算法"形成鲜明对比——后者的逻辑是"去年这块花了 100 万,今年涨 5% 给 105 万"。零基预算的逻辑是"这 100 万去年花了,今年从 0 开始问:这件事还需要做吗?还需要花多少?为什么是这个数?"
ZBB 在 1970-2010 年代被大量使用——尤其在战略转型、成本结构重塑、并购整合等需要"摆脱历史惯性"的场景下。它的核心精神不是"省钱",而是 "每一笔花费都要重新证明其存在的合理性"。
借用到软件架构里:每个架构决定(用什么数据库、怎么设计 API、怎么处理状态、怎么部署、怎么定价)都要重新论证其合理性——不能用"原来就是这么做的"或"行业惯例"来代替论证。
在 AI 时代,这件事变得格外重要——因为前 AI 时代的"行业惯例"很多都需要重新论证:
- RESTful API 是不是还适合流式输出?
- ORM 是不是还适合 LLM 调用为主的应用?
- 同步请求-响应是不是还适合 Agent 编排?
- DDD 的领域模型是不是还能描述"非确定性的 AI 输出"?
- 按席位 / 月费定价是不是还适合 token 成本结构的产品?
这些问题,每一个都需要"从 0 论证"——而不是"我们一直这么做"。
1.2 一个可工作的定义
把上面的精神归并到软件架构语境,给一个可执行的定义:
零基架构(Zero-Base Architecture):一种架构决策原则,要求每个关键决策(API 范式、数据模型、交互模式、部署形态、用户体验、商业模式)从 0 开始论证其在当下技术与业务环境下的合理性,而不是基于历史架构的惯性继承。论证后可以选择保留、改造或重新设计——但必须经过论证。
三个关键词:关键决策、从 0 论证、保留 / 改造 / 重新设计皆可。
这个定义有三层必须讲清的含义:
- 零基作用于决策,不作用于代码——它要求你重新论证"为什么用 PostgreSQL""为什么是 REST""为什么按席位定价"。但论证后完全可以决定"保留 PostgreSQL,因为它依然是最优解"——这也是零基。
- 零基是审视假设,不是删除既有方案——你不是先把代码扔掉再从头写,而是把所有"我们一直这么做"的假设逐一摘下来过审。审完之后大部分代码可能照旧,少部分需要改造,极少部分要新建。它的真正动作是扔掉假设,不是扔掉代码。
- 零基是决策标准,不是改造规模——一个团队可以"零基地"决定保留 90% 的旧系统,也可以"零基地"决定重新设计某个核心模块。改不改、改多少,是论证的结果,不是零基的前提。
记住这三层含义。下一节用一张"AI 中间层消化地图"回答一个具体问题:在 AI 时代,前 AI 时代的架构里,哪些层真的需要被重新论证、哪些可以放心保留?——这张地图,就是零基思维落到具体动作时的第一张坐标系。
二、AI 吃掉了哪些中间层:一张消化路线图
本节要点:"AI 吃掉中间层"不是营销口号——它有明确的边界。哪些层被吃掉、哪些正在被改造、哪些不会被替代、哪些是新生的——必须区分清楚。这张地图直接决定零基的边界。
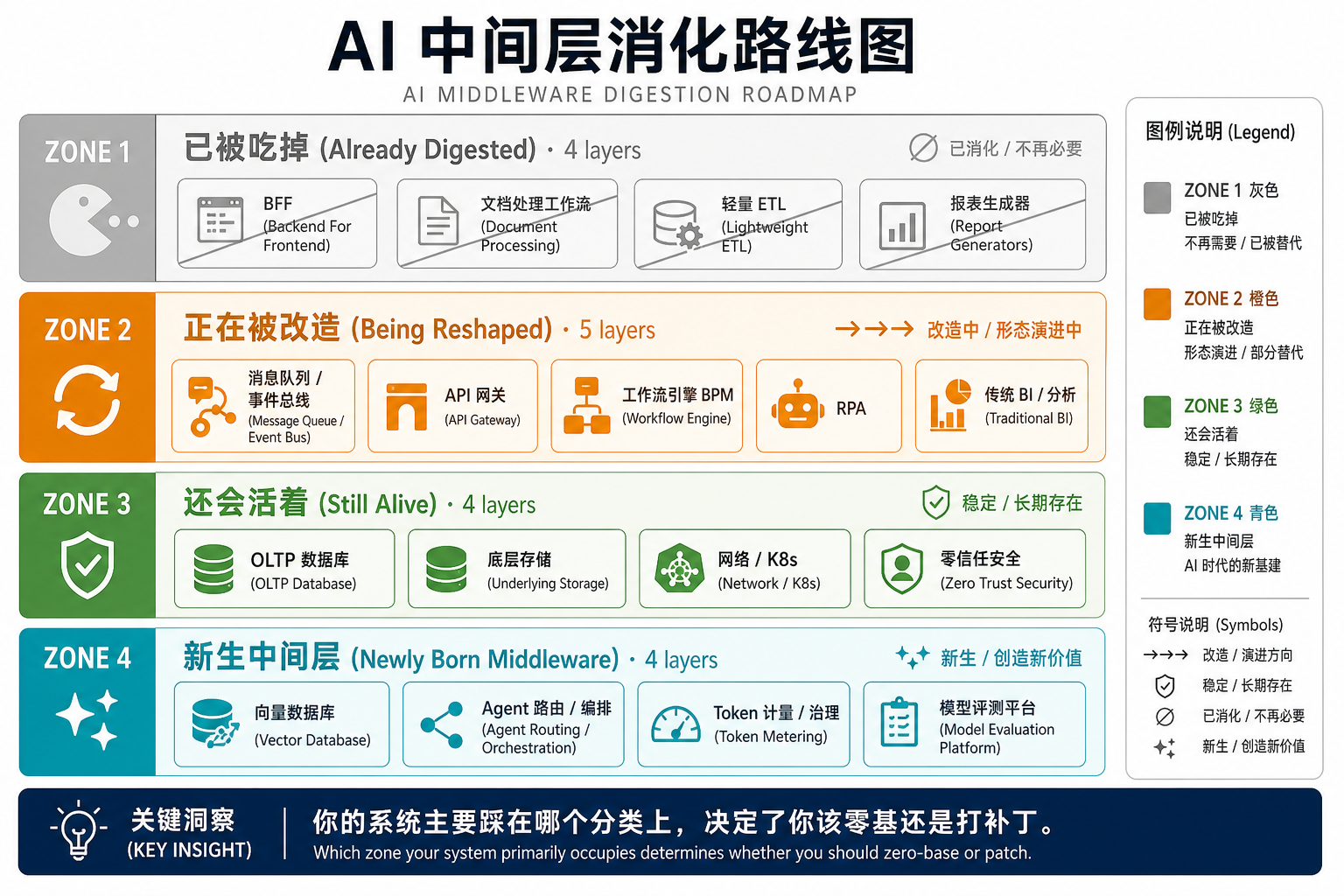
2.1 已经被吃掉的:4 个明确死亡的中间层
下面这 4 个中间层,在 2026 年已经被 AI / LLM 大幅替代——还在专门做这些的产品,主营市场会持续萎缩:
| 中间层 | 死亡方式 | 替代品 |
|---|---|---|
| BFF(Backend For Frontend) | LLM Agent 直接根据用户意图聚合后端数据 | Agent + Function Calling |
| 文档处理工作流 | LLM 直接 OCR + 信息抽取 + 结构化输出 | LLM + Schema 输出 |
| 轻量 ETL | LLM 处理半结构化数据清洗、转换、规则推断 | LLM + Code Interpreter |
| 报表生成器 | "对话式 BI" 直接根据自然语言问题生成图表 | LLM + Data API |
共同特点:这些层的本质都是"把人类意图翻译成系统行为的胶水代码"——LLM 在做这件事上有结构性优势,因为它原生处理"意图 → 行为"的映射,而不需要工程师手写规则。
2.2 正在被改造的:5 个被重塑的中间层
这些中间层不会死,但形态会大幅变化——还在用 2020 年的方式做这些事的团队,需要重新设计:
| 中间层 | 改造方向 |
|---|---|
| 消息队列 / 事件总线 | 从"事件 schema 驱动"转向"事件语义驱动"——AI 能理解事件意图,不再强依赖结构化 schema |
| API 网关 | 从"路由 + 限流"转向"意图识别 + Agent 路由"——根据请求语义选择后端 Agent |
| 工作流引擎(BPM) | 从"流程节点固化"转向"Agent 节点动态编排"——节点可以是 AI 也可以是人 |
| RPA | 从"录制式自动化"转向"目标式自动化"——告诉 AI 要做什么,AI 自己拆解步骤 |
| 传统 BI / 分析平台 | 从"仪表盘 + SQL 编辑器"转向"对话式分析 + 自然语言洞察解释" |
共同特点:这些层不会消失——它们的"基础设施身份"仍然需要——但API 形态、内部数据结构、用户交互模式都要重新设计。这正是零基思维该用的地方——既不能扔掉,也不能原样保留。
2.3 还会活着的:4 个 AI 不替代的底层
不是所有中间层都被吃。这 4 个层在 2026-2030 年仍是确定的活水:
| 中间层 | 为什么活 |
|---|---|
| OLTP 数据库 | AI 应用还要读写数据库;事务一致性是 LLM 给不了的 |
| 底层存储 / 文件系统 | 物理读写、合规归档、灾备——AI 无法替代物理性能 |
| 网络 / 容器编排(K8s) | 基础设施层——AI 跑在它上面,不会替代它 |
| 零信任安全 / 加密 | AI 反而让安全更重要(提示注入、模型逃逸、数据泄露、Agent 越权) |
共同特点:这些层是 AI 的"基座"——AI 必须依赖它们才能运行,不存在替代关系。在零基审视下,这些层往往的结论就是"保留"。
2.4 新生的中间层:4 个 AI 时代催生的新角色
AI 不只是吃,也在创造。下面这 4 个中间层在 2023-2026 年从 0 长出来,并且会成为新的基础设施:
| 新中间层 | 解决什么 | 代表产品 |
|---|---|---|
| 向量数据库 / Embedding 存储 | LLM 的长期记忆和语义检索 | Pinecone、Milvus、Qdrant、PGVector |
| Agent 路由 / 编排层 | 多 Agent、多模型、多工具的调度 | LangGraph、CrewAI、AutoGen |
| Token 计量 / 成本治理 | LLM 调用的成本、配额、限流、归因 | LiteLLM、Helicone、Portkey |
| 模型评测 / 可观测平台 | 概率性输出的质量监控、A/B、回归测试 | LangSmith、Arize、Phoenix |
共同特点:这 4 层在前 AI 时代根本没有对应物——它们是 AI-Native 架构新长出来的器官。零基重构最容易看到的"增量",就是把这 4 个新层引入架构。
2.5 把这张地图合在一起
四类层加起来,给出 2026 年的 AI 中间层消化地图:
- 死了的(4 层):BFF、轻量 ETL、文档处理、报表生成器
- 被改造的(5 层):消息队列、API 网关、工作流引擎、RPA、传统 BI
- 活着的(4 层):OLTP DB、底层存储、网络 / K8s、零信任安全
- 新生的(4 层):向量数据库、Agent 编排、Token 计量、模型评测
这张地图直接决定了零基思维的边界——你的系统主要踩在哪个分类上,决定了你该零基还是打补丁。死了的层 = 直接砍;被改造的层 = 零基重新设计;活着的层 = 保留 + AI 嵌入;新生的层 = 从 0 引入。
三、分界线:零基 vs 打补丁的决策框架
本节要点:零基不是绝对正确,打补丁不是绝对错误。两个变量决定你的选择:业务上 AI 是不是核心 × 技术上存量约束有多重。

3.1 4 个"必须零基"的信号
满足任意 2 个就值得严肃考虑零基:
- AI 是商业模式核心,不是体验增强:产品定价、用户付费意愿、护城河都建立在 AI 能力上——比如 AI Copilot、AI 编辑器、AI Agent SaaS
- 流式交互是用户主要交互方式:用户期待 token-by-token 反馈,而不是请求-响应——比如对话式产品、AI 写作工具、AI 编程工具
- Agent 编排是核心业务逻辑:业务流程本质是多个 AI Agent + 工具的协作,而不是确定的步骤链
- 存量系统的约束足够轻:刚起步的新项目、刚成立的团队、新设的产品线——没有历史包袱
3.2 4 个"必须打补丁"的信号
满足任意 2 个就老实打补丁、别动零基的念头:
- AI 是体验增强,不是商业模式核心:产品主体不靠 AI 收费——比如在 CRM 里加 AI 起草、在 ERP 里加 AI 数据洞察、在 IDE 里加 AI 补全
- 存量系统沉淀深、客户依赖重:数百 / 数千客户在用、合规审计已通过、业务连续性优先级 P0
- 业务流程是确定性、强合规、强一致的:核心账务、清结算、医疗诊断、工业控制——这些场景的"概率性输出"是 bug 不是 feature
- 团队没有 AI-Native 工程经验:没人写过流式 API、没人调过 Agent 编排、没人做过 LLM Eval——强行零基等于在火上学游泳
3.3 一个 2×2 决策矩阵
把上面 8 个信号归并成两个维度:
- X 轴:业务上 AI 的核心程度(边缘功能 ↔ 核心商业模式)
- Y 轴:技术上的存量约束(轻量 ↔ 重量)
| 业务边缘 + 技术轻量 | 业务核心 + 技术轻量 | 业务边缘 + 技术重量 | 业务核心 + 技术重量 | |
|---|---|---|---|---|
| 动作 | 最小化打补丁 | 全力零基重新设计 | 不动,或仅 AI 嵌入 | Strangler 渐进式零基 |
| 节奏 | 1-2 周加个 AI 入口即可 | 3-6 个月新建 AI-Native 模块 | 不投入主架构,仅做边缘点缀 | 12-24 个月用 Strangler 模式逐步替换 |
| 代价 | 极低 | 中 | 极低 | 高 |
| 典型场景 | 在内部工具里加 AI 翻译 | 新做 AI Copilot 产品 | 老 ERP 加 AI 报表 | 银行核心系统的渐进 AI-Native 化 |
这是本文最关键的一张图——所有零基讨论都应该回到这个矩阵。
关键认识:4 个象限里只有 1 个(业务核心 + 技术轻量)才是"全力零基"的真实场景。其他 3 个象限,贸然零基都是错的——要么用力过猛(左上、左下),要么忽视约束(右下)。
很多公司搞砸 AI 转型,根本不是零基思维错了,而是把自己错位到了"全力零基"象限里——明明在右下角(业务核心 + 技术重量),却以为自己在右上角(业务核心 + 技术轻量),用 Big Bang 重写的姿势去做 Strangler 才该做的事。
四、AI-Native 架构的 6 个不可妥协特征
本节要点:如果决定零基了,结果必须长成什么样?给出 6 个特征——不满足任何一个,零基都没做到位。
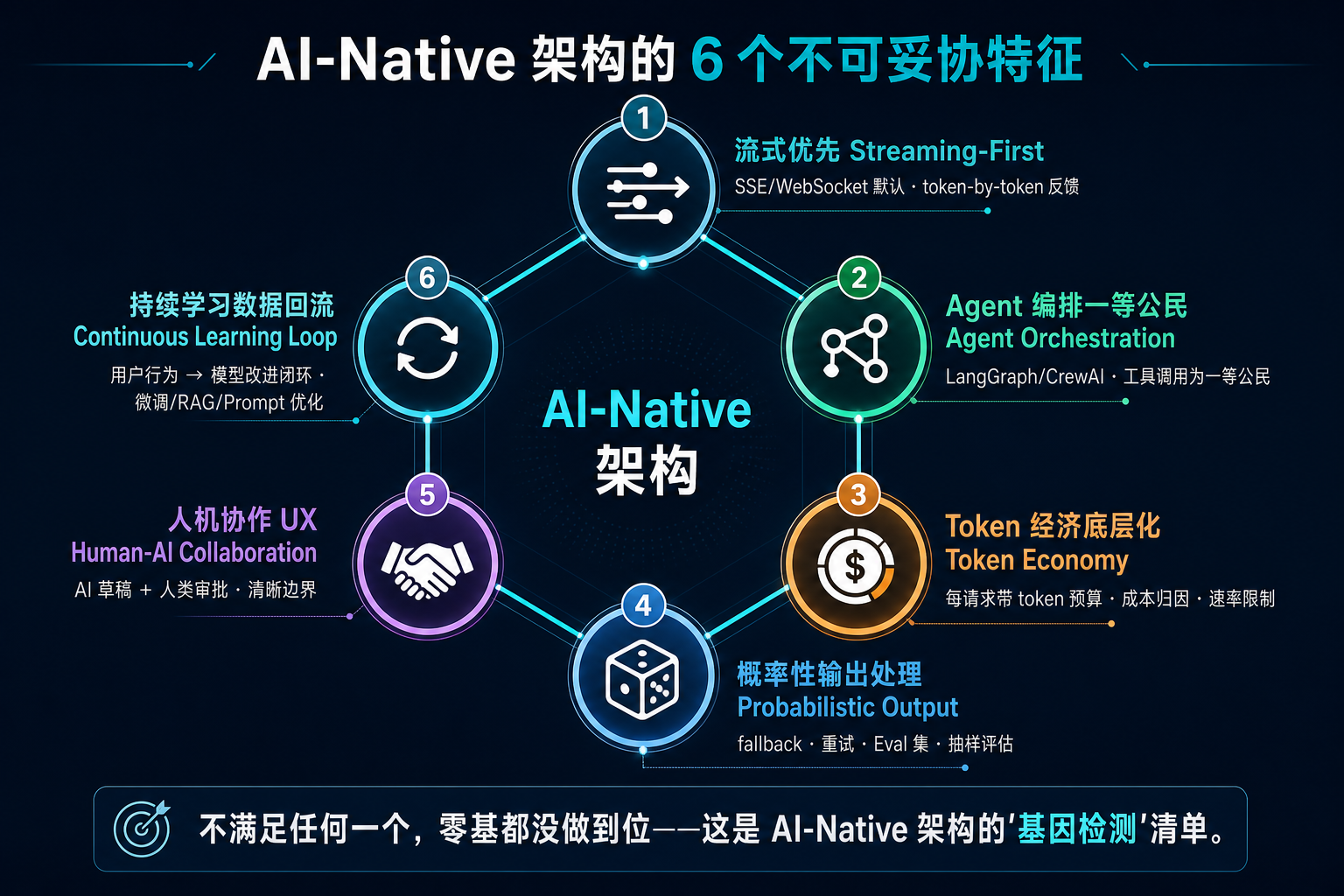
零基不是目的,目的是 AI-Native。下面 6 个特征是判断"你零基出来的架构是不是真的 AI-Native"的检验单:
4.1 流式优先(Streaming-First)
- API 默认是 SSE / WebSocket,而不是 REST 同步
- 前端默认能处理"边到达边渲染"
- 后端默认能处理"被中途取消的请求"
- 检验:用户能不能看到 token-by-token 的反馈?关键路径有没有"等 30 秒才返回"的同步阻塞?
4.2 Agent 编排为一等公民
- 业务逻辑用 LangGraph / CrewAI / 自研 Agent 框架描述,而非传统状态机 + if/else
- Agent 可以调用工具、可以调用其他 Agent、可以等待人类
- 检验:你的业务流程里有多少节点是"Agent + 工具",而不是"硬编码逻辑分支"?
4.3 Token 经济作为底层度量
- 每个请求都要带 token 预算 / 成本归因 / 速率限制
- 监控不只是 QPS / 延迟,更是 token 用量 / 模型成本 / 缓存命中率
- 检验:你能不能回答"这个客户上个月在我们系统里花了多少 token / 美元,每一笔归因到哪个 Agent"?
4.4 概率性输出处理
- 所有 AI 输出都要假定可能错、可能拒绝、可能不一致
- 关键路径必须有 fallback / 重试 / 人工 review 机制
- 测试体系要有 Eval(不是单元测试,是分布式抽样评估)
- 检验:你的代码里有没有"AI 输出无效时的 graceful degradation"?有没有 Eval 集 + 回归测试?
4.5 人机协作 UX
- UX 默认是"AI 草稿 + 人类审批 / 修订"
- 不是"AI 替代人",而是"AI 帮人提速 + 人保留最终决策权"
- 检验:你的产品里有没有清晰的"AI 输出"和"人类决策"边界?用户能不能干预、回退、纠错?
4.6 持续学习数据回流
- 用户每一次"接受 / 拒绝 / 修订"AI 输出都被结构化记录
- 这些数据回流到模型微调 / RAG 优化 / Prompt 优化
- 检验:你的系统有没有"用户行为 → 模型改进"的闭环管道?还是模型每天都是同一个?
这 6 条加起来构成 AI-Native 架构的"基因检测"。如果你的"零基重构"只是把 REST 改成 OpenAI API 调用、没有这 6 条——那不是 AI-Native,是穿了 AI 外套的前 AI 时代架构。
五、零基重构的落地节奏:不是 Big Bang,是 Strangler
本节要点:决定零基了,怎么落地?答案不是 Big Bang 重写,而是 Strangler Fig 模式的渐进替换。
5.1 Big Bang 为什么必败
任何形式的 Big Bang 重写都会失败——这不是 AI 时代独有的教训,而是软件工程史反复验证过的:Netscape 6 重写引擎花 18 个月、市场被 IE 抢走;Quark XPress 拒绝零基重新设计、被 Adobe InDesign 取代;Visual Basic 6 → VB.NET 强制重构让大量老客户出走。失败原因高度雷同:
- 客户不等你:18 个月没有新功能 = 客户流失给竞品
- 新系统的 bug 没被生产环境压过:旧系统积累的 bug fix 在新系统里要重走一遍
- 组织疲劳:连续 12+ 月的"重写攻坚战" = 核心团队流失
- 现金流压力:营收支撑不了开发投入,融资也变难
更危险的是:把零基等同于 Big Bang 重写,会让团队在错误的执行路径上消耗"零基"应有的战略红利——本来是审视假设的好机会,被异化为一场注定难产的代码迁移战。
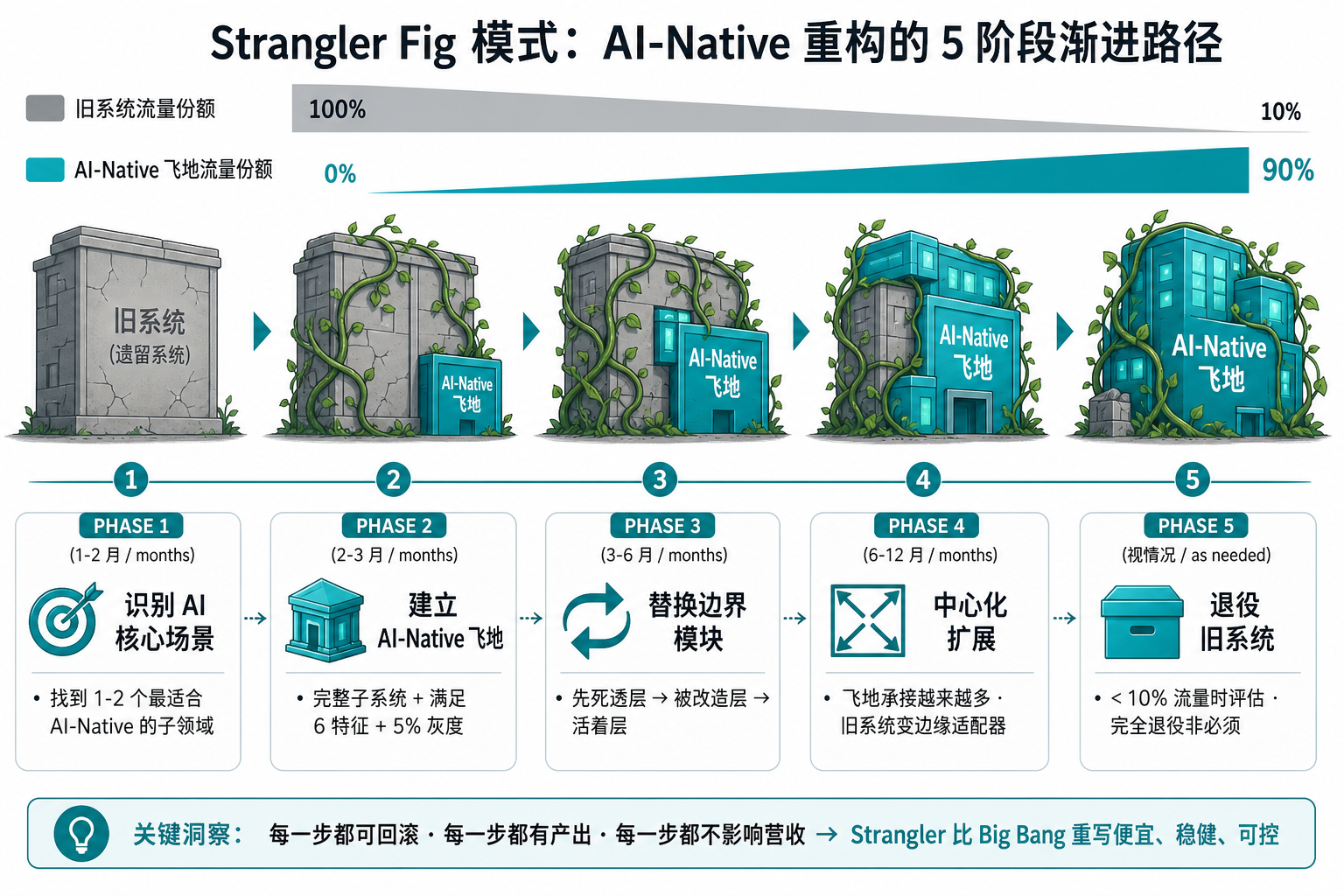
5.2 Strangler Fig 模式:Martin Fowler 给的答案
Strangler Fig(绞杀者榕树) 是 Martin Fowler 2004 年给出的渐进迁移模式——名字来自一种榕树,它会缠绕在老树上慢慢长大,最终取代老树。
应用到 AI-Native 重构,5 个阶段:
阶段 1:识别 AI 核心场景(1-2 个月)
- 找到 1-2 个最适合 AI-Native 的子领域(参考 §3.3 矩阵右上象限)
- 判断标准:用户付费意愿强 + 流式交互更优 + 数据回流容易
阶段 2:建立 AI-Native 飞地(2-3 个月)
- 在旧系统旁边新建一个完整的 AI-Native 子系统,承接核心场景
- 必须满足 §4 的 6 个特征(流式优先 / Agent 编排 / Token 经济 / 概率处理 / 人机协作 / 数据回流)
- 通过 API 网关把部分流量导过去(先 5%,逐步加大)
阶段 3:替换边界模块(3-6 个月)
- 把旧系统的边界模块(§2.1 已死的中间层:BFF、文档处理、轻量 ETL、报表)逐个迁到 AI-Native 飞地
- 每替换一个,旧系统就少一块
- 关键原则:先死透的层、再被改造的层、最后是活着的层
阶段 4:中心化扩展(6-12 个月)
- AI-Native 飞地承接的功能越来越多、流量越来越大
- 旧系统逐渐变成"边缘适配器"
- 此时可以开始扩展到 §3.3 矩阵的右下象限(业务核心 + 技术重量)
阶段 5:退役旧系统(视情况)
- 当旧系统只剩 < 10% 流量时,评估是否完全退役
- 完全退役不是必须的——很多公司会保留旧系统服务特定客户群(合规、本地化部署、长期合同)
Strangler 的关键优势:每一步都可回滚、每一步都有产出、每一步都不影响营收。
5.3 一个真实的节奏样本
以一个中型 SaaS 公司(年营收 1-3 亿)做 AI-Native 重构为例:
| 时间 | 动作 | 投入 | 风险 |
|---|---|---|---|
| 0-2 月 | 选定 1 个 AI 核心场景(如"对话式 BI"),招 3-5 人 AI 团队 | 团队 +200 万 / 年 | 低 |
| 2-5 月 | 建 AI-Native 飞地,跑通流式 API + Agent 编排 + Token 计量 | 工程投入 ~500 万 | 中 |
| 5-12 月 | 灰度发布、迁移核心功能、建 Eval 体系 | 工程 + 数据 ~800 万 | 中 |
| 12-24 月 | 扩展到 3-5 个 AI 核心场景,旧系统逐步边缘化 | ~1500 万 | 中 |
总投入 1500-3000 万 / 2 年——对比 Big Bang 重写(通常 3000-5000 万 / 18-24 月、且 50%+ 失败率),Strangler 模式便宜、稳健、可控。
六、三个最常见的失败模式
本节要点:零基重构有 3 种典型死法。每一种都源于把"零基"等同于"全部重写"或"贴 AI 标签"。
6.1 失败模式一:把零基当借口做 Big Bang 重写
症状:CTO 说"我们要零基重构整个系统"——18 个月不发新功能,全力重写。组织进入"AI-Native 重构大会战"模式,所有新需求被冻结。
为什么失败:见 §5.1。本质上是把"零基"的决策原则异化为"全部重写"的代码动作。
纠正姿态:零基是决策原则不是全部重写。用 Strangler 模式渐进落地——把 24 个月的 Big Bang 拆成 5 个阶段,每个阶段都有可上线的产出。
6.2 失败模式二:贴 AI 补丁但号称"AI-Native 重构"
症状:在老 SaaS 产品上加几个 LLM 调用、改两个按钮叫"AI 工作流"、招几个算法工程师——号称完成"AI-Native 转型"。对外讲故事、对内冻结预算转型。
为什么失败:
- 客户感受不到差别——因为本质是补丁
- 融资讲不动 AI 故事——投资人看技术 due diligence,§4 的 6 个特征一项不满足,估值不会因此提升
- 更危险的是:组织内开始按"AI 公司"的标准搞资源配置(招算法、买 GPU、讲大模型故事),反而把基本盘弄丢
纠正姿态:要么诚实承认是"AI 嵌入"(参考上一篇 §3.3 路径三:AI 嵌入),要么真做零基(满足 §4 的 6 个特征)。最忌讳的是"AI 补丁 + AI-Native 营销"的双重欺诈——欺骗客户、欺骗投资人、最终欺骗自己。
6.3 失败模式三:技术零基,业务不零基
症状:技术架构全部重新设计,用了 LangGraph、向量数据库、流式 API。但产品的商业模式、定价方式、用户交互模式还是 2020 年那一套——SaaS 月费、按席位定价、请求-响应交互、销售按 KA 关系拉单。
为什么失败:技术零基的成本被付了,但商业价值没释放。客户用着"AI 加持"的产品、付着"老 SaaS"的价钱——你的 token 成本暴涨、营收没变、毛利率反而下降。
纠正姿态:零基不能只在技术层做——必须同时审视:
- 商业模式:按 token / 按使用 / 按结果定价是不是比按席位更合理?(参考《FPT Flezi Foundry 发布:当 IT 外包行业第一次把"按结果付费"写进合同》)
- 用户交互:流式优先、Agent 编排能不能直接传导到 UX 层?
- 组织结构:要不要建 AI Eval 团队、Prompt Engineer 团队、Data Flywheel 团队?
零基是全栈的,不是技术单层的。
七、回到产业:零基思维如何重塑数据基础设施
本节要点:把视角拉回产业层——AI-Native 零基重构对中间件 / 数据基础设施意味着什么?这一节是上一篇《传统数据公司怎么活》的姊妹篇。
在《星环与易华录的冷启示:前 AI 时代的数据公司怎么活》里,我们从公司视角讨论了传统数据技术公司在 AI 时代的 5 条生存路径。
这一篇是它的对偶——从架构师视角看同一现象:
| 角度 | 上一篇视角 | 本篇视角 |
|---|---|---|
| 谁在变 | 数据公司 | 研发工作流 / 系统架构 |
| 变化推动力 | 客户预算结构位移 + 价值锚点位移 | 端侧硬件 + AI 工具链 + Agent 编排成熟 |
| 核心论断 | AI 没有杀死中间层公司,但要求它们重新定位 | AI 没有吃掉所有中间层,但要求重新设计 |
| 行动框架 | 5 种生存路径(公司视角) | 4 象限决策矩阵 + Strangler 落地(架构视角) |
两篇的共同骨架是 "分层 + 区分 + 分类 + 分动作"——拒绝 "AI 替代一切" 或 "AI 不影响任何事" 的极端叙事,要求把变化映射到具体子领域 / 具体场景。
给数据基础设施公司的一个延伸推论:
如果你是做 数据库 / 数据治理 / 数据集成 工具的——本文 §2.5 的消化地图直接告诉你:
- 你产品里属于"被吃掉的中间层"的子模块 → 现金流上要做减法(参考上一篇路径五:战略收缩)
- 属于"被改造的中间层"的子模块 → 必须零基重新设计(本文 §3 路径推荐:右上象限"全力零基")
- 属于"还活着的底层"的子模块 → 保持本分、AI 嵌入即可(上一篇路径三:AI 嵌入)
- 是否要进入"新生的中间层" → 考虑通过新产品线 / 战略并购进入(上一篇路径二 + 路径四)
上一篇的 5 条公司路径在产品架构层的对应:
| 上一篇路径 | 本篇对应动作 |
|---|---|
| 路径一(专精化) | 聚焦"活着的底层"+ 选 1 个"新生中间层"深耕 |
| 路径二(价值上移) | 在"被改造层"做零基重新设计,从工具上移到服务 |
| 路径三(AI 嵌入) | 不动主架构,在"活着的底层"上做 AI 补丁(左下 / 左上象限) |
| 路径四(生态切换) | 把自己定位为"新生中间层"的"行业接口"或上游 |
| 路径五(战略收缩) | 把"被吃掉的中间层"业务线剥离、并购退出 |
两篇文章合起来就是一份完整的产业 + 架构地图——产业视角告诉公司"该走哪条路",架构视角告诉团队"该怎么走"。
结语:零基思维的本质是"重新论证",不是"重新写"
回到本文开头。
零基思维(Zero-Base Thinking)的本质,是要求决策者重新论证每一个架构选择的合理性——一种作用于决策、不规定代码命运的方法论。论证后保留 90% 的旧代码、或新建一个 AI-Native 飞地,都是它合法的产物。
要把这个方法论真正落地,记住三件事:
从 0 论证每一个决策,论证后保留每一段值得保留的代码;用 Strangler 模式渐进落地,让每一步都有可上线的产出;让零基同时发生在技术层、商业模式层、组织层——不要只在技术单层用力。
最后 4 句话给所有在做 AI-Native 重构的架构师 / CTO:
零基是一种作用于决策的原则——论证后保留旧代码,也是零基。
AI 吃掉的中间层是有边界的,区分清楚再动手。
零基 vs 打补丁的分界,取决于"业务 AI 核心程度 × 技术存量约束"。
零基出来的架构,必须同时满足 6 个特征——这是 AI-Native 的"基因检测"。
参考资料
- Peter A. Pyhrr, Zero-Base Budgeting: A Practical Management Tool for Evaluating Expenses, Wiley, 1973.
- Joel Spolsky, Things You Should Never Do, Part I, 2000-04-06.
- Martin Fowler, StranglerFigApplication, 2004.
- Anthropic, Building effective agents, 2024-12.
- Model Context Protocol Specification, https://modelcontextprotocol.io, 2024-2026.
- Apple, M4 Family Architecture & Apple Intelligence Technical Documentation, 2025-2026.
- Ice,《星环与易华录的冷启示:前 AI 时代的数据公司怎么活》,2026-05-23. 本文的"产业视角"姊妹篇。
- Ice,《FPT Flezi Foundry 发布:当 IT 外包行业第一次把"按结果付费"写进合同》,2026-05-22. 商业模式零基的对照案例。
- Ice,《AI 时代的商业模式:从数据视角出发》,2026-05-21. 商业模式三轮齿合框架。