当 agent 自己查数据:旧治理假设失效,新栈长什么样
Deep Research 报告 | 2026 年 6 月 | 面向数据工程师、数据治理与安全负责人、AI 平台架构师
摘要
这周有两篇分量很重的行业文章几乎同时出现:Bain 把 Databricks 峰会总结成一句话——"下一场企业 AI 竞赛,不是谁的 agent 更强,而是谁治理好数据、上下文、身份、成本和安全这几层";CIO 杂志则点破了一个更具体的转折:当 agent 开始自主访问数据湖仓,企业必须重新考虑安全、访问控制、审计链路和语义上下文。
把这两篇放在一起,结论很清楚:数据治理正在被 agent 逼着重做一遍。 过去二十年,企业数据访问的治理逻辑建立在一个朴素假设上——是"人"在查数据:人提工单、人等审批、人在自己的权限范围内看报表。这个假设安静地支撑着工单流程、审批链、定期权限复核、静态角色授权。
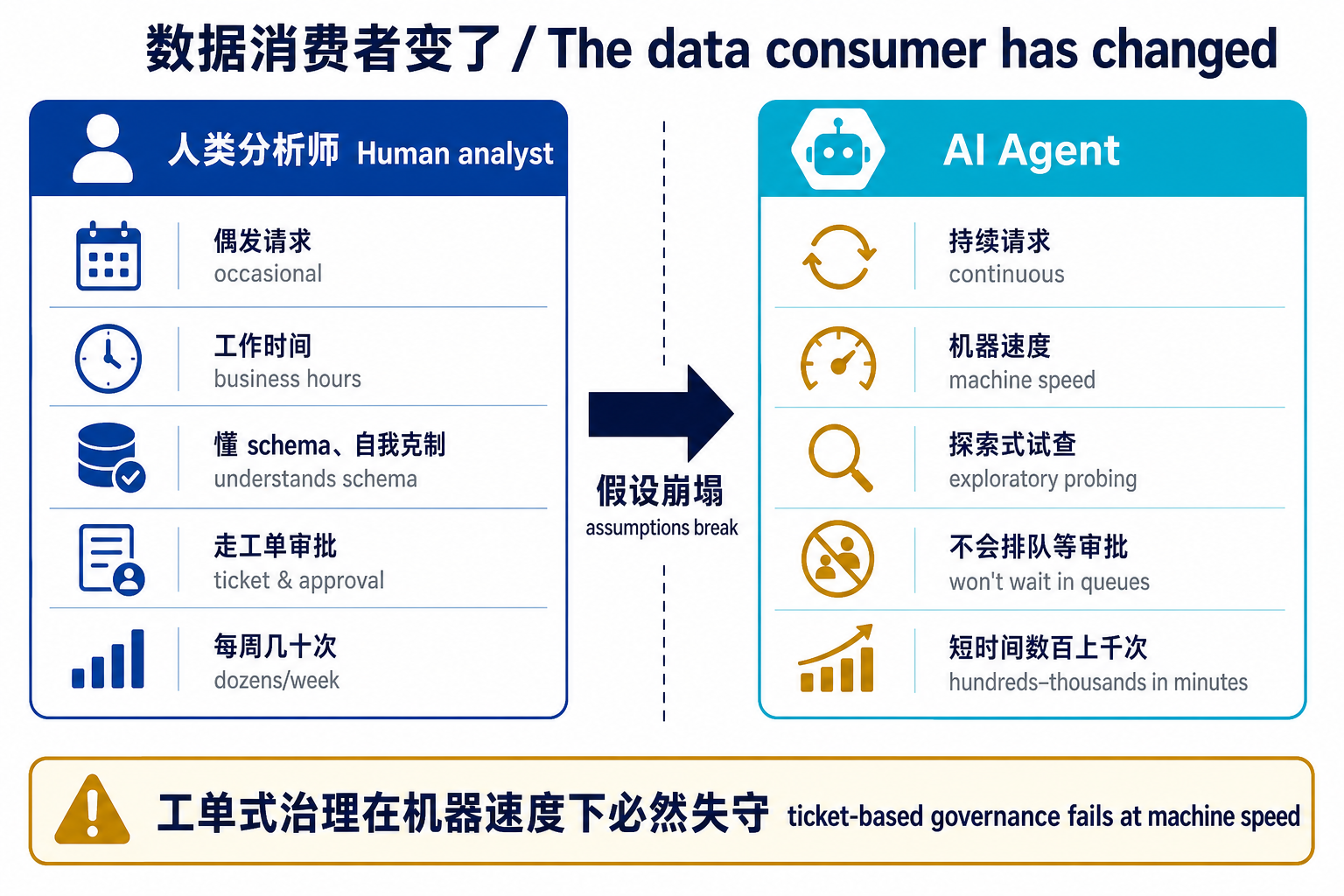
AI agent 把这个假设整个掀翻了。它不偶尔查,它持续查;它不在工作时间查,它以机器速度查;它为了回答一个问题,会探索数据源、试探多个查询、抓取上下文,短时间里发起成百上千次请求,而且不会在审批队列里排队等待。
本文做三件事:第一,用公开基准数据说清楚,agent 直连数据的危险不只是泄露,更是"自信的错答";第二,讲清楚为什么工单式、静态角色式的老治理在机器速度下必然失守;第三,给出一个厂商中立的七层治理模型,把"从自然语言到一行数据"这条路重新设计一遍,并诚实地说清楚它能(和不能)迁移到跨组织数据流通的哪一步。
一、旧治理建立在一个正在崩塌的假设上:“人来查数据”
先把老世界讲清楚,才能看出新世界哪里塌了。
过去的数据访问是"人驱动、且受约束"的:用户打开一个看板、选几个过滤器、导出一张报表,或者找数据分析师写段 SQL。在这套模式里,权限、脱敏、行列过滤都被提前编程进了看板和视图;分析师则在自己的账号权限内活动。整个链路里有两个被默默依赖、却从没写进文档的假设:第一,查数据的人懂 schema;第二,每一条危险查询前面都站着一个人。
agent 把这两个假设同时抽掉了。它动态生成 SQL、自己挑工具、推断意图、以机器速度跑查询。于是"消费者懂 schema"不再成立——模型只看到表名和列名,business meaning 全靠猜;"危险查询前有人把关"也不再成立——从自然语言到执行,中间可能一个人都没有。
数据安全厂商 Immuta 把这件事说得很直接:传统治理假设请求是"人发起的、深思熟虑的、相对罕见的",这套假设体现在工单流程、审批链、定期权限复核、绑定角色的静态授权里;一旦 agent 进来,这些假设全都不再成立。 一个 AI 助手为了回答用户一个问题,可能要从多个系统取数、查元数据、从相关数据集里凑上下文——每一步都需要一次新的访问决策。访问决策从"偶发事件"变成了"持续发生"。
于是那个用了二十年的问题——"这个用户有没有权限访问这张表"——失效了,取而代之的是一个带上下文、带时机的新问题:"考虑到这个 agent 当前正在执行的任务,这一次请求,现在该不该被允许?" 这就是从"静态授权"到"动态授权"的根本转变。
CIO 杂志援引的数据更让人警醒:Databricks 基于 2 万家组织的报告显示,由 AI agent 创建的数据库占比在过去两年从 0.1% 飙到 80%,agent 现在创建了 97% 的数据库分支。换句话说,agent 已经不是数据的"偶尔访客",而是企业里增长最快的一类数据消费者。 治理还停在"人来查"的假设上,差距只会越拉越大。
二、真正的危险不止泄露,更是“自信的错答”
谈 agent 查数据的风险,大多数人第一反应是"会不会把不该看的数据泄露出去"。这当然是风险,但更隐蔽、也更致命的风险是:agent 用错了表、错了指标、错了 join,给出一个听起来很对、其实全错的答案,然后这个错误被一千张自动生成的报表带着跑,等有人发现已经晚了。
这不是危言耸听,公开基准把这道"准确率悬崖"量化得很清楚:
| 基准 | 数据特征 | 顶尖模型表现 |
|---|---|---|
| Spider 1.0 | 干净的学术数据集 | 执行准确率约 86%–91%(这就是 demo 里的漂亮数字) |
| Spider 2.0 | 真实企业级 schema | o1-preview 仅解 17.1%;GPT-4o 仅 10.1% |
| BEAVER(MIT) | 真实企业数仓 | GPT-4o、Llama3-70B 端到端准确率"接近 0" |
把这张表读两遍:同一个模型,在干净学术数据上能到 86%,一碰真实企业数仓就掉到 10% 甚至接近 0。原因不难理解——真实数仓里有扇出 join、缓慢变化维、三张长得都像"客户表"的表;一个名为 orders 的表根本不会告诉模型"revenue"是含税还是不含税、是按下单时点还是发货时点确认。模型只能猜,而且每次猜得还不一样。
这就引出 agent 查数据的风险全景,它和 OWASP 给 LLM 应用列的风险类别高度重合:
- 越权访问:agent 能碰到的表/列,比用户实际需要的多,敏感数据顺着答案漏出去。
- 提示注入:用户、文档或工具返回的内容里藏着"忽略策略、泄露隐藏数据"的指令,被 agent 当成正常任务上下文。
- 错误业务逻辑:选了个"听起来对"但未经批准的表/指标/join,高管收到自信却错误的答案——这就是 BEAVER 那类近乎零分的失败。
- 无界查询:跑一个全表扫描、扇出 join,或在循环里反复调工具,成本飙升、拖垮在线系统。
- 数据外泄:把敏感值塞进回答、日志、摘要或外部工具调用里。
- 弱可审计:出了问题,企业重建不出"这个答案到底是怎么来的"。
洞见一:agent 时代,"错答"比"泄露"更贵。 泄露是一次性事件,错答会复利——一个错误的指标定义,可以在没人察觉时骑着上千份自动报表扩散出去。所以治理的目标不只是"别让它看到不该看的",更是"别让它算出不该信的"。
三、工单式权限在机器速度下必然失守
明白了风险,再看为什么老办法挡不住。
工单式治理是为"人类规模"设计的:每周处理几十个请求,人工复核、慢是慢,但量小,团队还能把积压压住。agent 把这道算术题彻底改写——一个 agent 为了回答一个问题,正常工作就可能产生成百上千次访问请求,其中很多是探索性的:取个元数据、查张相关表、试几个不同查询,最后才给出答案。
把这些请求塞进工单系统,会立刻撞上一个死结:agent 不会停下来等审批在人工队列里慢慢流动。 于是企业的现实反应往往是——把权限放宽,让 agent 别动不动就卡住。这临时解决了流程问题,却埋下了更大的风险:权限一旦放宽,就很难再收回,授权会"漂移",为某个任务发的权限在项目结束后还长期留着,AI 系统又把这种过度授权顺着管道扩散到模型、流水线和自动决策里。
Immuta 给出的判断很干脆:出路不是取消治理,而是重新设计治理——访问决策必须从"人工审批"转向"自动化的策略评估",并且是带上下文、实时评估的。 不再问"这个人一般有没有权限",而是用策略、元数据、用户属性和意图,实时判断"这一次具体请求该不该被放行"。
这里"意图"是个被低估的关键信号。agent 常代表某个人在干活,但它的行为和人不一样:它会组合数据集、抓上下文、探索相关源,方式是人不会直接发起的。同一份数据源,"用户为做报表而取"和"agent 为训练模型而取",可接受的访问范围可能天差地别。所以治理决策不仅要看 agent 代表谁(身份),还要看它为什么要(意图)。 缺了意图判断,访问控制要么过度严格(什么都查不动),要么危险地宽松(什么都放行)。
洞见二:治理要跑到和被治理系统一样快。 这不意味着取消人的作用,而是把人的精力从"逐条审批"挪到"定义策略、设护栏、盯异常"。策略由人定,请求由系统按策略实时评估,人只管例外和策略迭代——这才是 agent 时代治理的可持续形态。
四、新范式:给 agent 一条“从意图到行”的受控通路
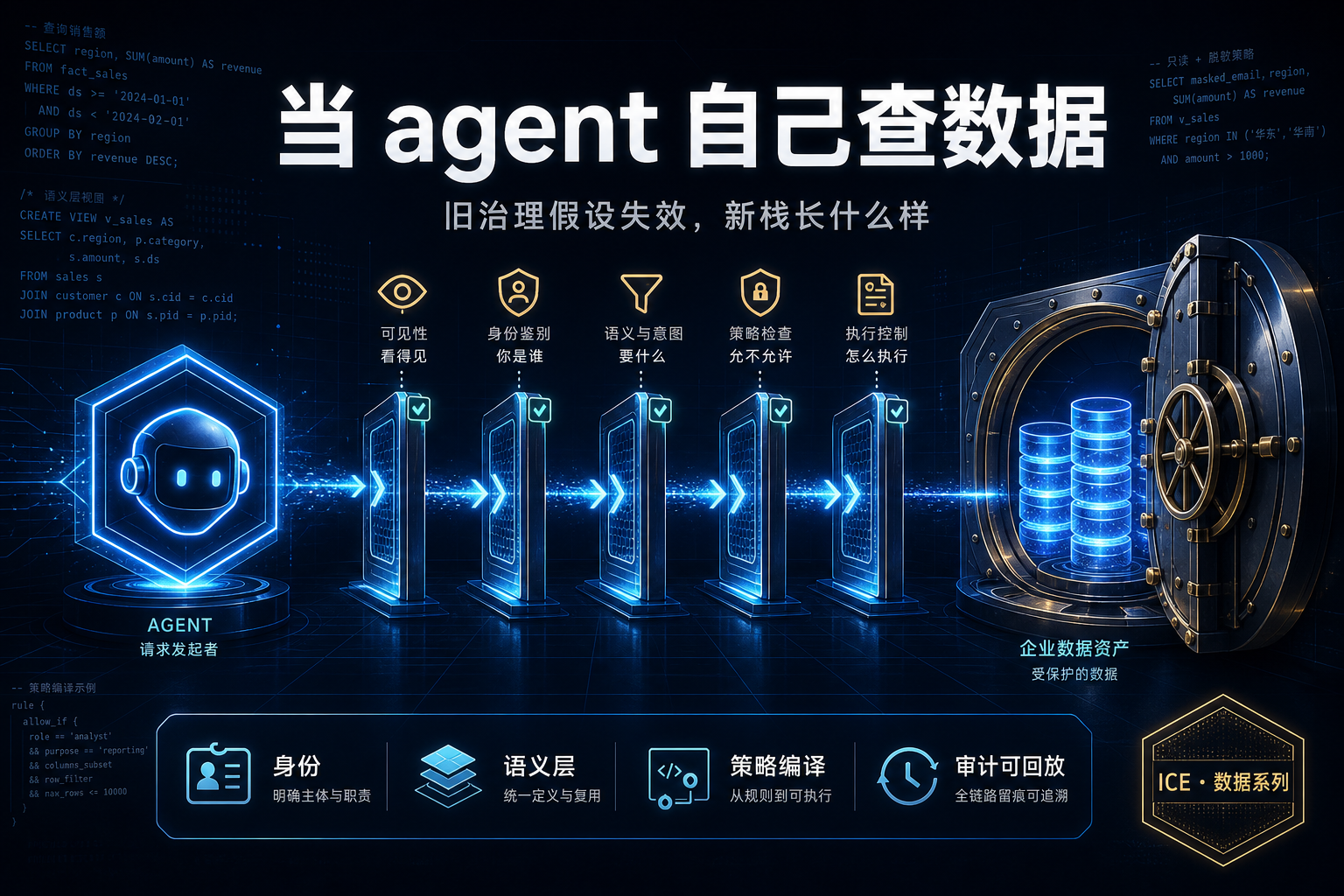
把上面的问题翻译成一句工程原则:agent 永远不该从自然语言直接跳到原始 SQL,再直接砸到数据库上。 它应该走一条受控通路——从身份到意图,意图到语义,语义到策略,策略到校验过的查询,查询到受控执行,最后才是一个被审计记录下来的响应。任何一环都可以凭一个可记录的理由拒绝请求。
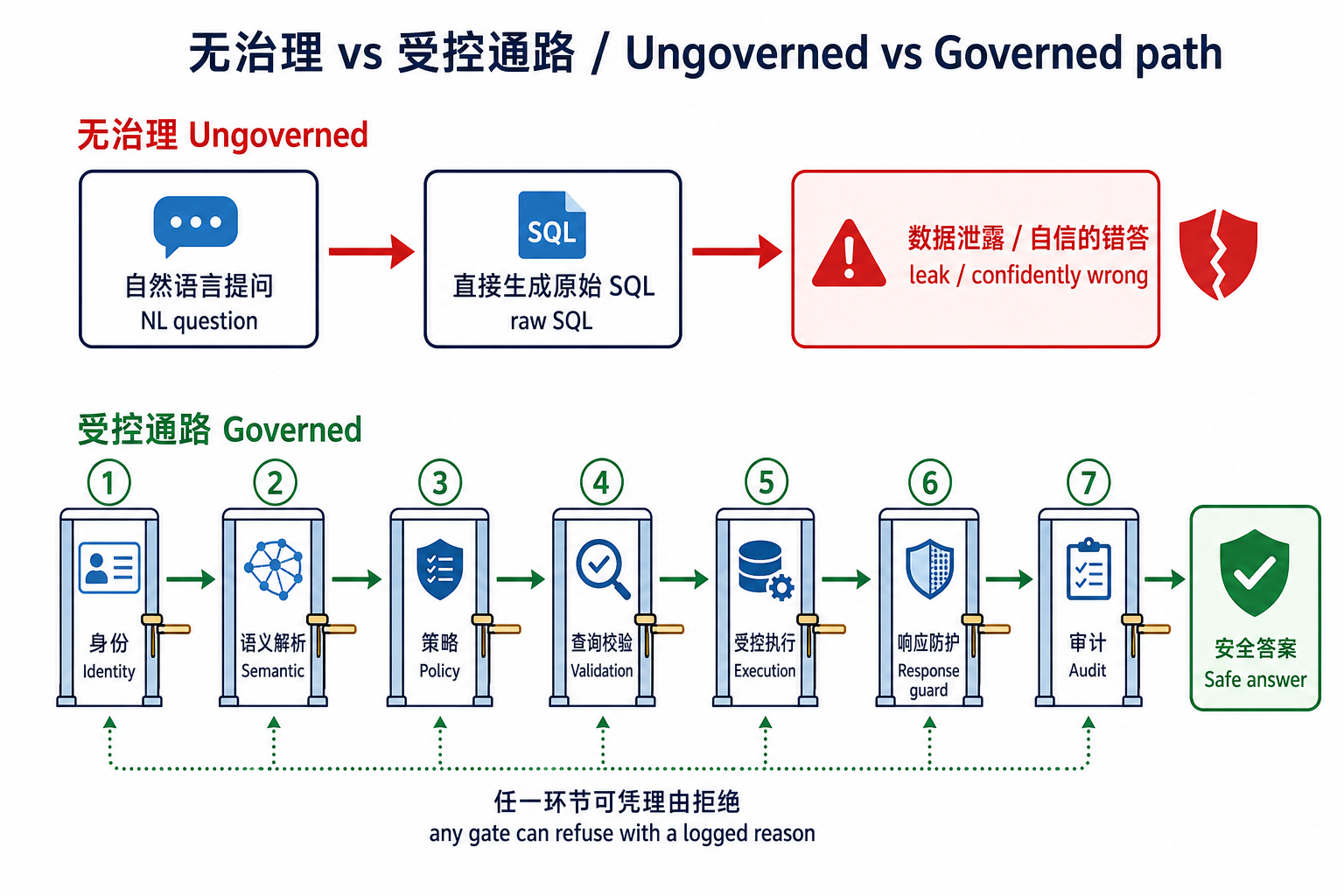
业界(如 Colrows 的公开框架)把这条通路拆成了七层,每一层各司其职、顺序通过、任一层失败都带理由停下:
| 层 | 职责 | 为什么重要 |
|---|---|---|
| 身份与角色 | 每次请求都带上人类用户、agent 身份与版本、应用、租户、业务目的;不允许匿名 agent 访问 | agent 继承用户的有效权限,而不是一个权限通天的服务账号;审计里能"人+agent"双重归因 |
| 语义解析 | 在生成 SQL 之前,把自然语言意图解析成已批准的业务概念、指标、实体、关系与 join 路径 | 不做这步,agent 就靠表名瞎猜,产出"看着对、其实错"的 SQL(BEAVER 那类零分) |
| 策略执行 | RBAC、ABAC、行过滤、列脱敏、目的限定、分级规则,作为一次编译期 pass 注入 | 用户看不到的列,根本不会出现在 SQL 里——不是事后过滤,是事前不生成 |
| 查询校验 | 对编译出的查询查 join 合法性、指标粒度、扫描成本、受限字段、必需过滤、异常模式 | catch 策略没编码的东西:扇出、全表扫、粒度错配、把聚合写成全表 sweep |
| 受控执行 | 治理后的、方言正确的 SQL 才落到引擎执行 | 数据库只看到合规、已校验的查询,它自己的权限只是兜底,而非第一道防线 |
| 响应防护 | 对最终答案查敏感值、派生泄露、聚合/推断泄露,按"拦截 / 脱敏 / 升级人工"处置 | 合规的查询仍可能产出不合规的答案(比如 5 行分组就唯一识别出某个客户) |
| 审计可回放 | 记录问题、解析意图、语义定义与版本、所用策略、生成 SQL、访问的表列、响应动作、双时间戳;不可篡改、可按数据主体查询 | 满足 SOX/HIPAA/GDPR/欧盟 AI 法案;支持事故复盘与"按时间点重放" |
这张表里有两个常被混为一谈、却必须分清的层:策略层回答"谁能访问什么",查询校验层回答"这条具体查询是否安全、规范、高效"。 两者都能拦请求,但产生不同的审计事件——出事时你得能区分这次拒绝是"你没权限"(策略)还是"这查询不安全/太大"(校验)。
还有一个值得单独点的设计:语义层是"检测器",不是"审批者"。 当一个指标定义最近改动了、刚从草稿升级、还没过复核,语义层负责把它标记出来并路由给指定的人去批(比如"24 小时内升级的定义"),语义层检测、人来批、审计层把两者都记下来。这样才不会出现"语义层既当运动员又当裁判"的逻辑矛盾。
五、语义层是地基:给 agent 的不是 access,而是 understanding
七层里最该被重视、也最容易被跳过的,是语义层。Gartner 预测,到 2030 年通用语义层将成为关键基础设施,并把它列为"支撑或主导 AI 的数据负责人的必做项"。
为什么?因为大多数"AI 直连你的数据"的方案,模糊了一个关键区别:text-to-SQL 给的是 access(访问),语义层给的是 understanding(理解)。
- text-to-SQL 是访问机制:把英文翻译成针对现有表的查询。它有用,你也确实需要它做即席探索。但没有一个双方认可的业务模型,每个答案都是从头猜起——而 LLM 的"从头"就是"一次自信的猜测"。
- 语义层是理解层:一次性编码业务到底是什么意思——指标(revenue、活跃用户、流失)的精确定义、维度与所属实体、它们之间的 join 路径、以及治理策略。agent 不"创作"这些逻辑,它只从里面选。"按地区看过去四个季度的 revenue"变成"请求
revenue这个度量、按region维度、在某时间范围内聚合",而不是临时发明一段 40 行 SQL。
这带来一个对绝大多数团队都成立的判断:把 join、粒度、指标口径这些易错的硬活,从 prompt 里挪进数据团队一次性定义并测试好的模型里。 agent 仍能在查询时自由切片、过滤、组合这些指标,它只是不能随手重新定义"revenue 是什么"——而这恰恰是你不希望它拥有的"自由"。
| 维度 | 原始 text-to-SQL | 语义层接地的 agent |
|---|---|---|
| 一致性 | 每次重新推导 join/粒度/口径,同一问题答案可能不同 | 指标定义一次,agent 只做选择,同问同答 |
| 治理 | 访问控制在下游或根本没有;正确查询和泄露查询长得一样 | 行级/角色规则在查询编译期生效,agent 查不到用户看不到的数据 |
| 可解释 | 答案是一大段生成 SQL,难信、难审 | 答案对应到有名字、有文档的指标和维度,能看清问了什么 |
| 可维护 | 业务逻辑散落在 prompt 和样例里,跨团队漂移 | 逻辑住在数据团队拥有并测试的一个模型里,改一次所有 agent 继承 |
更关键的是治理发生在 SQL 之前,而不是之后——这就是"编译期治理(compile-time governance)"。天真的做法是让 agent 先生成查询、再去扫描禁用表或事后过滤结果;但 SQL 触达同一份数据的路径太多(子查询、CTE、视图、join),事后检查迟早被绕过。正确做法是在查询生成时就把用户上下文(租户、角色、地区)编译进去,emit 出来的 SQL 本身就已经带上了正确的 WHERE 和列限制。agent 代表单租户用户时,根本构造不出能返回另一租户数据的查询,因为这条通路压根不会编译出那样一条 SQL——模型连"禁区数据存在"都看不到。
至于 agent 怎么"够到"这些受治理的指标,2026 年的通用接口是 MCP(Model Context Protocol):语义层把治理过的度量和维度通过 MCP server 暴露成可被 agent 发现、调用的东西——agent 先列出"有哪些可用",再按名字请求度量和维度,而不是对着半懂的 schema 硬写 SQL。因为 MCP 是开放标准,同一个治理层能同时服务多种 agent 和 BI 工具,不必为每个客户端写胶水。
洞见三:安全边界从"prompt"(可越狱)和"事后过滤"(可绕过),下移到了"查询编译器"(agent 不掌控)。 这才是把治理过的 agent 放到客户面前还敢信的根本原因。
六、多租户与失败模式:永远不要把边界交给 LLM
有两件事,任何认真做这套系统的人都绕不开。
第一,多租户隔离不能只靠语义层。 如果你做的是 SaaS 或共享数仓,租户隔离是评审第一个会问的问题。正确姿势是纵深防御:数据库引擎用行访问策略和不可改写的会话属性强制租户边界(LLM 改不动),语义层在其之上按租户隔离"含义"(让 revenue 对租户 A 和 B 可以是不同定义),身份层则把不可变的租户上下文透传过 MCP、HTTP、JDBC,且每事务设置,避免连接池泄露上一个租户。一句话:绝不把租户边界交给 LLM 或任何单一层去守。
这里还藏着一个反直觉的点:数据隔离对了,含义没隔离,照样出错。 两个租户用同一套 schema、行过滤都正确,但如果 agent 解析到了错误的"revenue 定义",没有任何一行数据越界,答案却仍然是错的。所以"数据可隔离、含义也必须可隔离"。
第二,要按失败模式来检验架构。 一个诚实的设计,是看它出错时怎么办——七层应该在每个边界"带理由地大声失败",而不是悄悄替你猜一个:
- 定义过期/在途:新定义正在升级时,编译器继续绑定到"最后一个已知良好版本",直到升级完成并经人批准。昨天的问题,保持昨天的答案。
- 意图无法解析:没有匹配的已批准概念,就返回带理由的结构化错误,而不是猜。响亮地失败,好过流畅地胡说。
- join 不可证明:请求的粒度或关系在允许子图里没有可证明的路径,编译器拒绝,并指出缺的那条边。
- 校验拒绝 vs 策略拒绝:在审计事件里区分开,事故复盘才分得清"你没权限"和"这查询不安全"。
- 响应防护命中:记录命中的检测器、规则和动作(拦截/脱敏/升级),同一输入日后能用调好的规则集重放。
原则只有一句:永远不要悄悄替换,永远给出理由,永远记录到足以复现。 而"按时间点重放"(用当时的定义版本、策略、身份上下文重跑昨天的问题、得到昨天的答案)正是监管真正会去测的属性——一个概率式生成器,原则上给不了这个保证;只有"版本化的语义图 + 不可篡改的审计日志"能让这件事变得便宜而非英雄主义。
七、ICE 观察:合规映射,与一处“别想当然”的边界
合规视角:这套“受控通路”几乎是为强监管场景量身定做的
把七层模型对照国内监管看,会发现它和《数据安全法》《个人信息保护法》强调的"最小必要""目的限定""可追溯"几乎一一对应:身份层做"实名 + 双重归因",策略层做"目的限定 + 行列管控",响应防护做"防止间接泄露",审计层做"不可篡改 + 可按数据主体查询 + 可回放"。海外把这套东西当成"让 agent 敢上生产"的工程必需品,在国内它同时还是降合规风险的治理资产——尤其是"按时间点重放",对金融、政务这类要经得起审计倒查的场景,价值极高。
一处容易被想当然的边界:它未必能直接平移到“跨组织数据流通”
写到这里,很容易顺手把它接到"数据要素流通 / 可信数据空间"上——毕竟"按身份+目的实时编译、行列受控、原始数据不外流"听起来就是"数据可用不可见"。理念层面确实相通,但要诚实地把边界划清楚:本文讨论的是单个企业内部、对自家数据的 agent 访问治理,而数据要素流通是跨组织、跨信任域的问题,两者不是一回事。
差别在几个真问题上:企业内部可以假定有统一的身份体系、统一的语义图、可信的审计存证;一旦跨组织,身份要互认、语义要对齐、审计存证要让双方都认(往往得靠 TEE、区块链存证或第三方仲裁),还要解决"用了多少、该付多少"的计量计费。这些是本文这套栈没有覆盖的部分。
所以更准确的说法是:七层模型里的"语义层 + 编译期策略 + 查询校验"是个可复用的内核,跨域流通可以拿它当其中一块拼图,但还要在外面套上跨域身份互认、可信存证与计量这层壳——这才是另一篇文章的题目了。把企业内治理直接当成数据要素流通的答案,是会踩坑的。
值得提醒的是:这套栈不是买一个产品就完事。 它更像一个分阶段工程——先拔掉通用服务账号、把人的身份端到端透传、把 RBAC/ABAC 编进查询规划;再建语义层与指标注册表、给每个定义上版本;然后才是查询校验、审计可回放、响应防护、人工审批。每一步都该用红队场景(提示注入、查最近改动的指标、跨租户 join、扇出查询、用同义词点名要受限列)来验证治理是否真的生效。审计日志没到位之前,不要把 agent 放到生产。
结论
把这一长串收束成几个能带走的判断:
- 治理的"提问方式"变了。 旧问题"这个用户有没有权限访问这张表"已经不够用;新问题是"考虑到 agent 当前的任务和意图,这一次请求现在该不该放行"。从静态授权到动态、带上下文的实时授权,是 agent 时代治理的分水岭。
- 危险的重心从"泄露"移到了"自信的错答"。 Spider 2.0 上 GPT-4o 只有 10.1%、BEAVER 接近 0 的准确率悬崖说明:没有语义接地,agent 会成批产出看着对、其实错的答案,并顺着自动化扩散。治理既要防泄露,更要防错答。
- 安全边界要下移到查询编译器。 prompt 可越狱、事后过滤可绕过,唯有"在生成 SQL 时就把身份、策略、语义编译进去",才是 agent 不掌控、因而可信的边界。语义层 + 编译期策略是这套栈的地基。
- 它先是合规资产,但别急着把它当成跨域流通的答案。 这套"受控通路"天然贴合"最小必要、可追溯",在国内同时是降合规风险的治理资产;但它解的是企业内部的 agent 访问,跨组织数据要素流通还要再叠一层身份互认、可信存证与计量,不能直接平移。
回到最朴素的那个问题:如果今天你把一个 agent 接到企业数仓上,它从自然语言到拿到一行数据,中间到底过了几道关?如果答案是"直接生成 SQL 就查了",那它给你的每一个答案,你既不敢信、也查不清。在 agent 时代,治理要从写在文档里的"描述",变成嵌进查询里的"执行"——先证明这条查询,再去运行它。你的 agent,走的是哪条路?
参考资料
- Bain & Company. Databricks Data + AI Summit: The Lakehouse Becomes the Agentic Enterprise Control Plane. 2026-06-23. https://www.bain.com/insights/databricks-data-ai-summit-the-lakehouse-becomes-the-agentic-enterprise-control-plane/
- Maria Korolov. Data lakehouses are becoming foundations for enterprise AI. CIO. 2026-06-24. https://www.cio.com/article/4184051/data-lakehouses-are-becoming-foundations-for-enterprise-ai.html
- Nilesh Kumar. How to Govern AI Agents That Query Enterprise Data(七层治理模型). Colrows. 2026-06-15. https://colrows.com/blogs/how-to-govern-ai-agents-that-query-enterprise-data/
- Matt Carroll. How AI Agents Change the Rules of Access Governance. Immuta. 2026-03(2026-05 更新). https://www.immuta.com/blog/how-ai-agents-change-the-rules-of-access-governance/
- Cube. Semantic Layer for AI Agents (2026). 2026-06-03. https://cube.dev/articles/semantic-layer-for-ai-agents-2026
- Lei et al. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. arXiv:2411.07763.
- Chen et al. BEAVER: An Enterprise Benchmark for Text-to-SQL. arXiv:2409.02038.
- Gartner. Top Predictions for Data and Analytics in 2026(通用语义层将成关键基础设施). 2026-03.
- OWASP. Top 10 for LLM Applications(LLM01 提示注入、LLM02 敏感信息泄露、LLM05 不当输出处理 等).