Agent 打破了 20 年数据治理:策略该放在库里,还是库外?

Deep Research 报告 | 2026 年 7 月 | 面向数据平台、数据治理与 AI 应用负责人,关注 Agent 查数与数据安全的从业者
摘要
过去二十年,企业数据治理建立在一个几乎没人质疑的前提上:数据的消费者,是人或应用,而且它们走的是预先定义好的流程。 你在 BI 里点一个报表、在业务系统里提交一笔单,背后调用的是开发者写死的、经过评审的查询路径;权限、脱敏、口径这些护栏,绝大多数就贴在这条应用流程上。
Agent 把这个前提掀翻了。它能直接认证到数据库、自己读 schema、自己生成 SQL、以机器速度发起成百上千次探索性查询——而且完全不走应用那条被治理过的路。theCUBE 在 7 月初一篇文章里把这件事说得很直白:agentic AI 打破了 20 年的数据治理。 一份面向 750 位技术高管的调查给了佐证——企业的 Agent 数量四个月翻了一倍,但48% 的生产 Agent 处于"无监控"状态,54% 的组织已经发生过至少一次安全事件。
问题摆上桌之后,行业迅速分成了两派打法。一派主张把安全 enforcement 下沉进数据库引擎:不管请求来自人、应用、MCP 服务器还是自主 Agent,每一条 SQL 在执行前都先过一遍库内的行级/列级/单元级授权(Oracle AI Database 26ai 的 Deep Data Security 是代表)。另一派则在数据库之外的目录/治理层建统一的策略、语义与血缘,让治理跨越多个数据源保持一致(Snowflake Horizon、Databricks Unity Catalog 是代表)。
本文想把这场分裂讲透:两派各自在解决什么、命门在哪、为什么最后大概率会收敛到"治理与执行分离"的混合架构——以及为什么这件事,本质上又是我们反复讲的那条主线——"把治理从查询之后,挪到执行/编译之前"——的一次新印证。
一、被打破的那个前提:治理一直贴在"应用"上
要理解 Agent 为什么是"破坏者",得先看清过去二十年的治理是怎么搭起来的。
传统企业数据栈里,数据的访问路径是收敛的:用户不直接碰数据库,而是通过应用——ERP、CRM、BI 工具——去访问。开发者在应用层写好查询,安全团队在这条路径上层层设卡:谁能进这个页面、这个接口返回哪些字段、导出要不要审批。数据库自己往往只握着一个"高权限共享账号",反正真正的过滤在上面做完了。这套模式在"人和应用是主要消费者"的世界里,运转得相当好——因为访问路径是可预测的、被治理过的。
Agent 把这套假设连根拔了。用 Oracle 官方文档里的话说,agentic 系统常常通过 MCP(模型上下文协议)去检查数据库结构、识别相关数据、自主构造并执行查询——它可以直接执行 SQL,完全绕过应用层的保护。这带来一个很尴尬的局面:你过去二十年精心建立的护栏,大部分都装在 Agent 根本不走的那条路上。
更麻烦的是几个叠加特性:
- 绕过路径:Agent 直连数据库/MCP,应用层的行列过滤、审批、审计统统失效。
- 不可预测:SQL 是大模型概率式生成的,同一个问题不同时刻可能选不同的表、不同口径、不同 join,没有"预定义查询"可言。
- 机器速度 + 探索式:为回答一个问题发起成百上千次查询,不排队、不等审批。
- 过度授权(excessive agency):为了"能干活",Agent 常被挂上一个权限过大的共享账号,一旦跑偏,破坏面极大。
theCUBE 那句"打破 20 年治理"不是标题党。它精确地指出:治理假设的地基——"消费者可预测、路径被治理"——塌了。 而地基一塌,上面盖的所有护栏都得重新审视:它们到底装在哪一层?Agent 会不会绕过去?
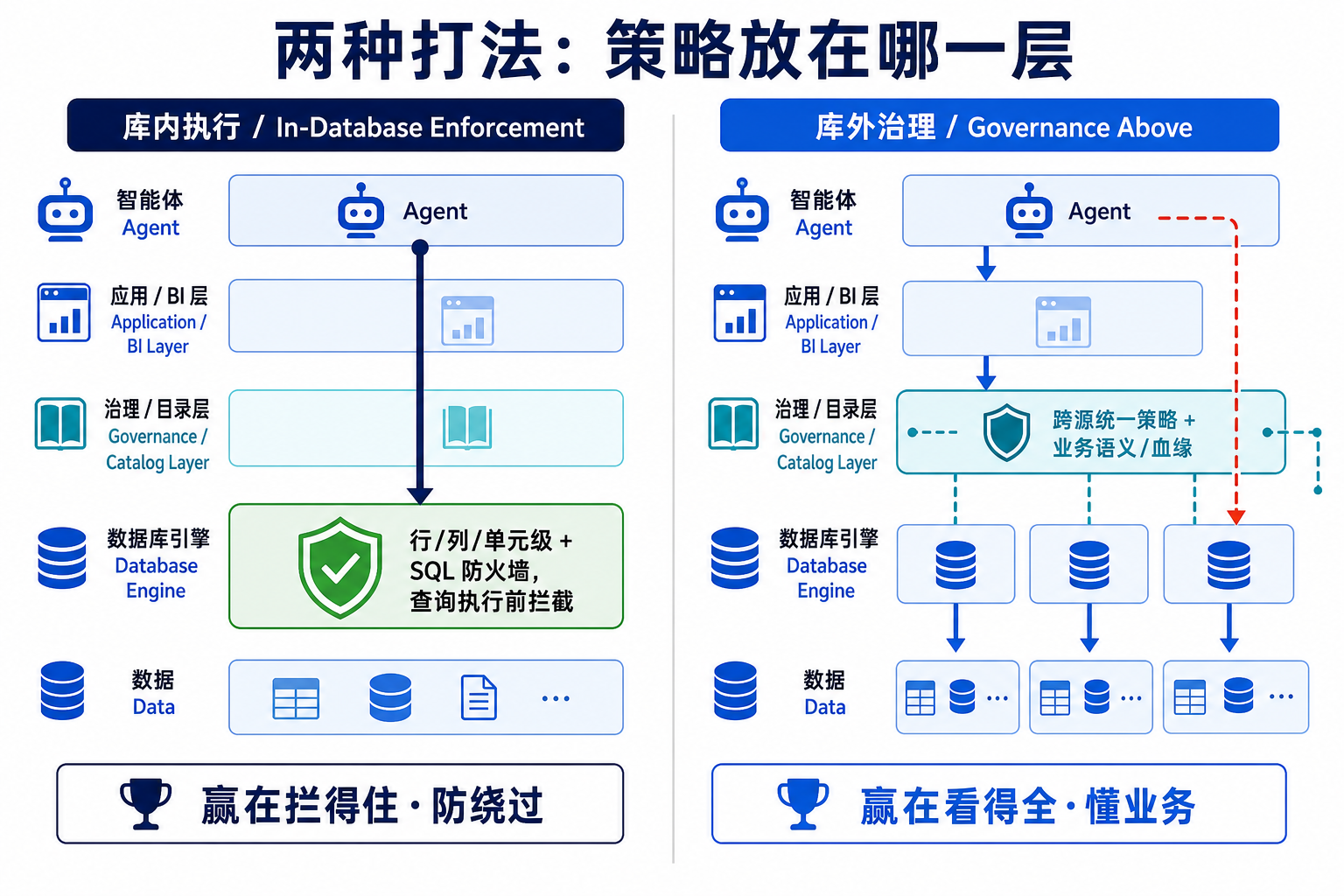
二、两大阵营:库内 enforcement vs 库外治理
地基塌了,重建的方向出现了分野。theCUBE 把它概括为两大阵营,未来五年企业数据平台会越来越明显地分成这两个架构取向。
阵营一:把 enforcement 放进数据库引擎。 代表是 Oracle AI Database 26ai。它的赌注很明确——安全 enforcement 属于数据库引擎本身,而不是围绕它的外层。 每一条 SQL,无论来自人、应用、MCP 服务器、编排平台还是自主 Agent,都在执行前被库内策略评估一遍:行级安全、列级安全、数据脱敏、透明加密、Database Vault、统一审计、身份感知授权,全都在"查询真正执行的地方"生效。
阵营二:在库外的目录/治理层做统一治理。 代表是各大平台厂商的治理套件——Snowflake 的 Horizon、Databricks 的 Unity Catalog、微软的 Purview + Fabric、AWS 的 Lake Formation、Google 的 Dataplex、IBM 的 Watsonx governance。它们的价值在于跨系统、跨平台地定义策略、沉淀业务语义与血缘,让治理在一个碎片化的数据版图上保持一致。
把两派摆到一张表上看差异:
| 维度 | 库内 enforcement(如 Oracle 26ai) | 库外治理(如 Horizon / Unity Catalog / Purview) |
|---|---|---|
| enforcement 位置 | 数据库执行引擎内,查询执行前 | 目录层 / 应用层 / 查询引擎层 |
| 能否被 Agent 绕过 | 难——直连 SQL 也被拦 | 取决于是否所有引擎都走这个治理层 |
| 覆盖范围 | 单库内一致,跨库弱 | 跨平台、跨源统一,业务语义/血缘强 |
| 粒度 | 行 / 列 / 单元级 + SQL Firewall | RBAC / 列脱敏 / 行级策略 / 语义定义 |
| 命门 | 多数据源时要每个库各配一遍,易被厂商锁定 | 若有引擎不走治理层,就出现"旁路" |
| 擅长的事 | 强 enforcement、防绕过、审计在源头 | 发现、血缘、业务术语、跨系统一致性 |
一句话概括这张表:库内那派赢在"拦得住",库外这派赢在"看得全"。 而 Agent 时代的残酷之处在于——你两样都需要。
三、库内派在赌什么:谁绕过应用,就在源头拦谁
先看库内这派的逻辑,因为它直接冲着 Agent 的"绕过"特性去。
Oracle 把这套能力叫 Deep Data Security(深度数据安全),核心思路可以拆成三步。
第一步,把身份"传"到数据库里。 过去数据库只认那个高权限共享账号,根本不知道背后是谁。Deep Data Security 支持身份传播:外部 IAM(如 Entra ID、OCI IAM)认证终端用户后,把用户与 Agent 的身份、角色、属性通过安全上下文令牌(如 OBO 令牌)带到数据库运行时。于是数据库第一次知道"这条 Agent 发来的查询,究竟是替谁在问"——授权据此按发起任务的真人来判,而不是按那个大权限账号。这一步直接掐掉了"过度授权"。
第二步,用声明式 SQL 写策略,在执行时按行/列/单元级过滤。 授权规则不再散落在各个应用的代码里,而是用 SQL 声明式地表达、集中存在库内。关键在于执行时机:哪怕 Agent 生成了一条"把整张表都 select 出来"的宽查询,数据库也只会把该用户有权看到的行、列、甚至具体单元格返回。用 Oracle 的话说,这是"security at the source(安全在源头)"——不靠应用层事后过滤,而是在数据被取出的那一刻就按策略裁剪。
第三步,SQL Firewall 兜底。 26ai 把 SQL Firewall 内建进了数据库:它检查所有进来的 SQL 语句,只放行显式授权的语句,异常的记录并拦截。因为它长在引擎里,没法被绕过——无论本地还是网络、加密还是明文,顶层 SQL、存储过程、相关对象都要过一遍。这对"概率式生成、路径不可预测"的 Agent 尤其对症:你没法预测它会写出什么 SQL,那就干脆在执行入口设一道allowlist。
Oracle 文档里点破了库外派的一个尴尬:想在库外拦住 MCP Agent 的直连 SQL,要么自己嵌一个 SQL 解析器(复杂到不现实),要么把所有访问都包成 REST/MCP 工具、在 API 逻辑里设权限(接口爆炸、性能还差)。只要 Agent 能直连 SQL,库外的很多护栏就形同虚设。 这就是库内派最有力的论点:enforcement 必须待在查询无法绕过的那一层。
四、库外派在赌什么:Agent 猜错口径,比看错数据更可怕
但如果你据此以为"那把治理全塞进数据库就行了",就掉进了另一个坑。库外这派解决的是一个同样致命、却完全不同的问题:Agent 不光可能看到不该看的数据,更可能用错误的语义去理解数据。
想象一个跨了 Snowflake、Databricks、若干业务库的数据版图。库内 enforcement 能保证"在 Oracle 这一个库里,越权的行列出不去"——可它管不了另外几个库,更管不了一个更隐蔽的问题:"营收"到底指哪个口径?"活跃用户"怎么定义?"上季度"是自然季还是财季? 这些语义不在任何一个库的 schema 里,散落在 BI 定义、文档和老分析师的脑子里。Agent 看不到这些,就只能猜;而猜错口径时,它不会报错,会流畅地给你一个能跑、看着对、其实错的数字。
这正是库外/目录层治理的主战场。以 Snowflake 的 Horizon Context 为例,它的定位不是"再加一个第三方语义层",而是把业务语义直接做进治理引擎:从整个数据版图收集元数据,附上业务定义与关系,再激活它,让 Agent、BI、应用都能自动发现并套用可信的口径。它强调一个关键差别——语义活在治理引擎内部、在查询时 enforcement,而不是外挂一层再去两边对账。 因为"外挂在治理引擎之上的语义层,每次查询都要调和两套系统;一旦定义漂移,Agent 就跟着用错那个"。
Databricks 的 Unity Catalog 则代表目录层治理的另一条路:策略写在目录元数据里,任何走这个目录的查询引擎都统一生效——一次编写、处处 enforcement。它的好处是跨引擎一致,代价是把治理绑定到了特定目录/厂商;如果你当初选了 Polaris、Nessie 这类中立目录来避免锁定,就得在查询引擎层(Trino/Dremio/OPA)自己补一套等价治理,代价是每个引擎重复配策略、查询开销上升。
所以库外派的核心主张是:光"拦得住"不够,Agent 还得"懂业务"。 一个只做了库内 enforcement、却没有统一语义与跨源治理的组织,让 Agent 直接对着原始库自然语言查数,大概率是在批量生产"权限没错、口径全错"的结论——这在董事会 PPT、监管报表里,是比数据泄露更难被发现的雷。
五、为什么终局是"治理与执行分离"的混合架构
两派各有一个绕不开的命门,摆在一起看就清楚了:
- 库内 enforcement 的命门:跨库难。你的数据不可能只在一个厂商的库里,每个数据源都各配一套、还容易被单一厂商锁定;而且它天生不擅长"业务语义、跨源血缘"。
- 库外治理的命门:只要有一个引擎不走这个治理层,就出现"旁路"——而 Agent 恰恰最擅长找那条阻力最小的路径直连数据。
于是行业正在收敛到一个并不新鲜、却被 Agent 逼到台前的答案——把"治理"和"执行"分开。theCUBE 的判断很精炼:真正能定义未来十年企业 AI 基础设施的厂商,是那些成功把 governance 与 enforcement 分离的——用治理工具去定义策略,用数据库原生控制去一致地执行策略。 Atlan 的行业观察给了个量化落点:约 70% 的成熟企业最终运行在这种混合模型上——平台原生控制(RBAC、动态脱敏、行级策略)负责"在数据所在处实时、权威地 enforcement",第三方/目录层治理负责"跨平台的发现、业务术语、血缘和语义一致"。
用一句话给这套分工定调:策略在哪里"定义"可以灵活,但策略在哪里"执行"必须离数据足够近、近到 Agent 绕不过去。 定义层要广(跨源、含语义、给业务人看),执行层要深(在引擎内、查询前、拦得住)。
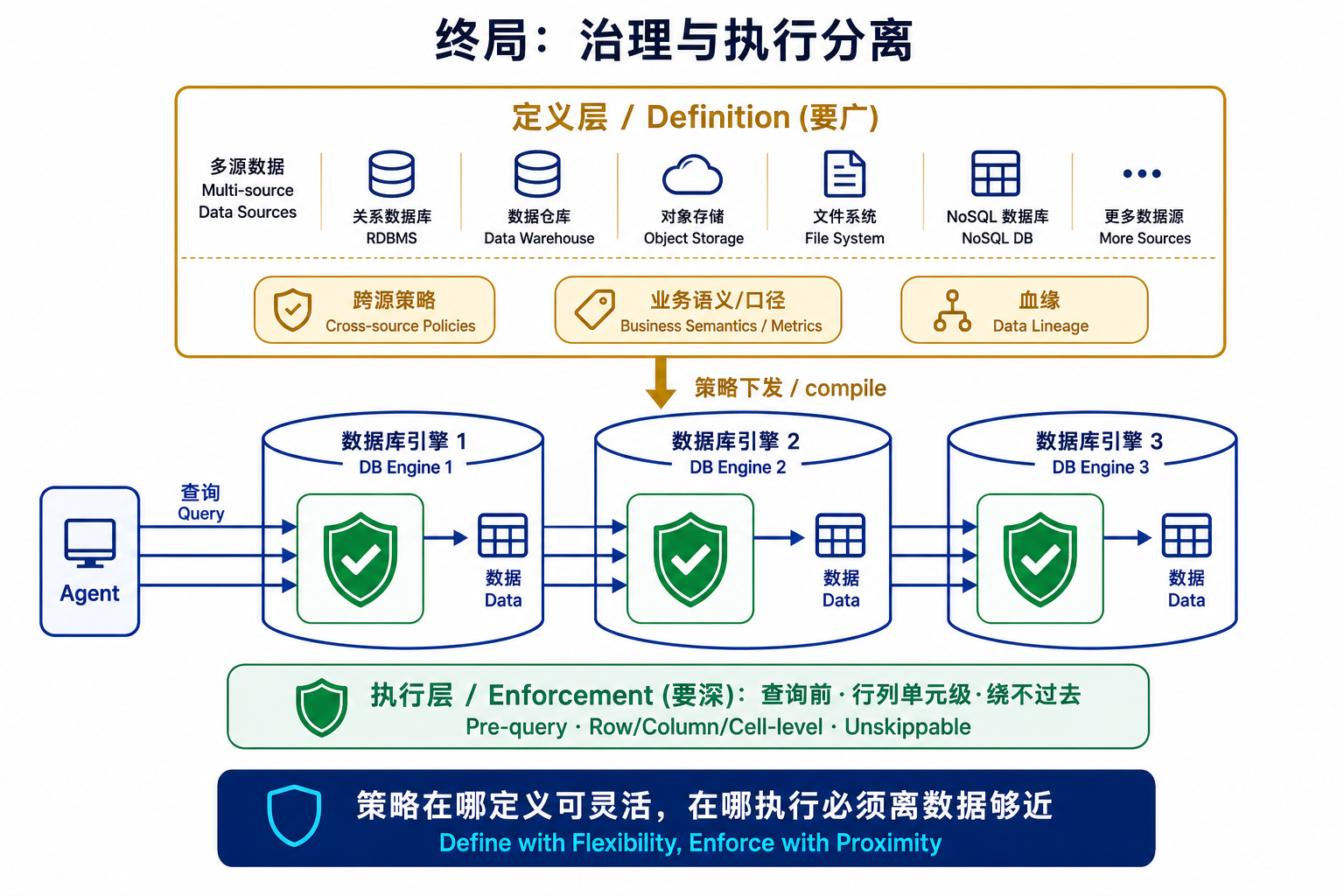
这也顺带回答了"库内还是库外"这个问法本身的问题——它其实是个伪二选一。 正确的问题不是"策略放哪儿",而是拆成两个:策略在哪儿定义(答案:一个能跨源、含业务语义的治理层),以及策略在哪儿 enforcement(答案:尽可能下沉到查询无法绕过的执行引擎)。把这两件事混为一谈,才会陷入无谓的阵营之争。
值得给国内团队提个醒:如果你现在正在选型,别只看"哪个治理平台功能全",要多问一句——"当一个 Agent 拿着直连凭证、绕过我所有应用和 BI 时,谁来拦它?" 如果这个问题的答案是"没有人"或"靠 Agent 自觉",那么无论上层治理做得多漂亮,你的 enforcement 都还站在被 Agent 掀翻的那个旧地基上。
六、ICE 观察
技术视角:这是"编译期治理"主线的又一次印证
熟悉本博客的读者会发现,这件事和我们此前几篇是一条线。从《语义层 vs Text-to-SQL》里讲的"在编译期注入策略、确定性编译",到《当 agent 自己查数据》里的七层治理栈,再到今天的"库内 enforcement vs 库外治理",指向的是同一个技术判断:治理必须从"查询之后的人工复核",前移到"查询执行前、在一个绕不过去的位置自动生效"。 库内 enforcement 是这条主线在数据库引擎层的落地,语义层是它在口径层的落地,可重放审计是它在时间维度的落地。对数据工程师最实际的提醒是:评估任何一套 Agent 数据方案,先问 enforcement 在第几层、能不能被直连绕过,再谈功能丰富度。
落地视角:先盘"绕过路径",再谈"治理平台"
对正在让 Agent 接入数据的团队,最该先做的不是选治理平台,而是画一张"访问路径图":列出 Agent 可能直连数据的所有入口(数据库账号、MCP 服务器、直连驱动、导出接口),逐条问"这条路上,谁在 enforcement?"。48% 的生产 Agent 无监控、54% 已出过事,说明大多数组织连这张图都还没画清。务实的顺序是:先用库内/引擎级控制堵住"绕过路径"(身份传播 + 行列级 enforcement + SQL allowlist),再用目录/语义层补齐"跨源一致 + 业务口径"。 反过来先铺上层治理、却留着直连后门,等于给正门装了防盗门、后门大敞。
本土视角:可信数据空间的"敢不敢用",卡在同一道题
放到国内的语境,这里其实有两层,得分开说。"数据要素×"回答的是"为什么要用"——政策要数据流通起来、发挥要素价值;"可信数据空间"回答的是"凭什么敢用"——它是一套让数据在多主体之间"可用不可见、不出域、按约束用"的技术—制度机制。前者是动机,后者是让动机能落地的地基。而 Agent 的出现,恰恰把可信数据空间从"合规话术"逼成了"必须现在解决的工程题"。
因为可信数据空间的几条核心原则,和本文"治理与执行分离 + 执行下沉"是同一套骨架,可以逐条对上:
- 使用控制 / 用途合约(usage control) → 这是"定义层要广":跨主体约定这份数据能用于什么用途、什么口径、留存多久,写在合约里。
- 数据不出域、可用不可见 → 这是"执行层要深":约束不能只写在合约上,必须在数据侧强制生效——数据方看不到你计算了什么,你也拿不走原始数据。
- 最小必要 + 按身份/用途裁剪 → 正是库内那套"身份传播 + 行列单元级 enforcement"在跨域场景的翻版。
而 Agent 恰好会把这套地基里最脆弱的一环——"约束到底在哪一层强制"——直接踩爆:它以机器速度、探索式访问,谁能保证它只看到该看的、只按约定的用途和口径用?如果你的可信数据空间只是在"入场协议/管理平台"这一层谈用途合约,enforcement 却还留在应用侧,那么一个直连的 Agent 就能像绕过应用护栏一样,绕过你的"可信"承诺。换句话说,可信数据空间要真的可信,enforcement 必须落到离数据最近、Agent 绕不过去的那一层——国产数据库引擎内、TEE 内、或数据网关内,而不是停在合约文本和管理台上。
对国产数据库、隐私计算与数据空间基础设施厂商而言,这是一个清晰的机会窗口:谁能把 Agent 时代的"用途合约(定义)+ 库内/域内 enforcement + 身份传播 + 可审计"这条链路打通,谁就握住了强监管客户"敢让 AI 用核心数据"的那把钥匙。
结论
把这篇收束成几句话:
- Agent 打破的是"路径可预测"这个地基。 它直连数据库、自己生成 SQL、绕过应用层护栏——过去二十年贴在应用上的治理,大部分装在了 Agent 不走的那条路上。
- 两派各解一半的问题。 库内 enforcement(Oracle 26ai)赢在"拦得住、防绕过、审计在源头";库外治理(Horizon / Unity Catalog)赢在"跨源一致、业务语义、血缘"。Agent 时代两样都要。
- "库内还是库外"是伪二选一。 正确的拆法是:策略在哪儿定义(跨源、含语义的治理层)vs 策略在哪儿执行(下沉到绕不过去的引擎)——终局是"治理与执行分离"的混合架构,约 70% 成熟企业已在此。
- 这是"编译期治理"主线的延伸。 把 enforcement 前移到查询执行前、绕不过去的位置,是从语义层、七层治理到库内安全一以贯之的判断。
最后留一个问题给正在给 Agent 开数据权限的你:当一个 Agent 拿着直连凭证、绕过你所有的应用和 BI 时,究竟是谁、在哪一层,把它拦下来的? 如果你一时答不上来,那可能就是接下来最该补的那块地基。
参考资料
- theCUBE Research. Agentic AI Just Broke 20 Years of Data Governance. 2026-07-01. https://thecuberesearch.com/agentic-ai-just-broke-20-years-of-data-governance/
- Oracle. Introducing Oracle Deep Data Security: Identity-Aware Data Access Control for Agentic AI in Oracle AI Database 26ai. 2026. https://blogs.oracle.com/database/introducing-oracle-deep-data-security-identity-aware-data-access-control-for-agentic-ai-in-oracle-ai-database-26ai
- Oracle. Why Choose Oracle Deep Data Security(26ai 文档). https://docs.oracle.com/en/database/oracle/oracle-database/26/ddscg/why-choose-oracle-deep-data-security.html
- Oracle. Oracle SQL Firewall is Now Built into Oracle AI Database(26ai 安全指南). https://docs.oracle.com/en/database/oracle/oracle-database/26/dbseg/release-changes.html
- Snowflake. Horizon Context: The Governed Context Layer for AI, BI and Apps. 2026. https://www.snowflake.com/en/blog/horizon-context-governed-context/
- Security Data Works. Catalog Governance Without Native Support(Unity Catalog / Trino / OPA 对比). 2026. https://securitydataworks.com/writing/catalogs/catalog-governance/
- Atlan. Snowflake Governance vs Third-Party Tools: What To Use in 2026(混合模型 ~70%). 2026. https://atlan.com/know/snowflake/governance-vs-third-party-tools/
- Unite.AI. AI Governance Isn't a C-Suite Problem. It's a Database Problem. 2026. https://www.unite.ai/enterprise-ai-governance-database-infrastructure/
- Gravitee. State of AI Agent Security 2026(n=750;48% 无监控、54% 已出事). 2026-06. https://www.gravitee.io/state-of-ai-agent-security