Meta 零停机迁移 PB 级数据摄取系统:影子、反向影子与 CDC 止血术
数据工程 · CDC × 系统迁移 × 可靠性 | 2026 年 6 月 | 约 13 分钟阅读

TL;DR · 4 句话核心
- Meta 把一条每天从 MySQL 增量搬运数 PB 社交图谱数据的摄取链路,从"各团队自管的分散管道"整体迁到"集中托管的数仓服务"——全程零停机,数万作业全量切换,旧系统彻底下线。
- 最关键的设计是"反向影子(Reverse Shadow)":切换上线后不是删掉旧作业,而是让新旧作业角色互换、继续并行比对,从而拿到"切换后还能持续校验 + 秒级回滚"两个好处。
- 数据质量靠"行数 + checksum 双校验 + Scuba 实时回环"闭环,每小时自动定位导致不一致的样本行,把排障从"等下游投诉"变成"上线前就发现"。
- 难点其实在 CDC 本身——变更数据捕获会让坏数据"自我繁殖",Meta 用分区级质量标记 + 停止落地 + 回填来快速止血;规模问题则用自动晋级/降级 + 批次规划 + 复用旧快照来压成本。
一、被迁移的是什么:每天数 PB 的数仓主动脉
要理解这次迁移的难度,先得知道被迁移的系统每天在做一件多大的事。
Meta 的社交图谱(social graph)——谁是谁的好友、谁点了什么赞、谁发了什么内容——背后是全球最大的 MySQL 集群之一。但 MySQL 是面向在线事务(OLTP)的,没法直接拿来跑分析、报表和模型训练。
于是 Meta 有一条数据摄取(Data Ingestion)链路:每天从这些 MySQL 实例里增量抓取数 PB 的社交图谱数据,灌进数据仓库。全公司的分析、报表、ML 训练和产品开发,都靠它供数。
换句话说,这条链路是连接"线上业务库"与"离线数仓"的主动脉。它一旦延迟或出错,公司里大量依赖"最新社交图谱快照"的团队都会被波及——从日常决策到模型训练。
先用一组数字感受下这次迁移的体量(数据来自 Meta 官方披露,官方仅给出量级、未公开精确值):
| 维度 | 规模 |
|---|---|
| 每日摄取数据量 | 数 PB(several petabytes / 天) |
| 数据源 | 全球最大的 MySQL 集群之一 |
| 待迁移摄取作业 | 数万个(tens of thousands) |
| 纳入迁移生命周期跟踪的作业 | 数千个(thousands) |
| 迁移期间停机 | 零(全程在线,下游无感知) |
| 最终结果 | 100% 工作负载切换完成,旧系统彻底下线 |
把这几个数字放一起就能看出难点:要搬的不是数据的物理位置——源头还是同一批 MySQL,终点还是同一个数据仓库;真正要搬的是每个摄取作业的归属与运行方式:从"各团队自管的分散管道(旧系统)"迁到"集中托管的数仓服务(新系统)"。而且这件事必须在"线上不停、下游不知"的前提下,把数万个各自为政的作业逐个、安全地切过去。
随着规模上涨,旧链路在越来越严苛的"数据落地时延(landing time)"要求下开始出现不稳定的信号。Meta 因此决定重构架构,并完成了一次堪称"在核心业务上做开胸手术"的全量迁移。
二、重构的根因:自管管道扛不住超大规模
旧架构的核心问题,不在某个技术组件,而在所有权(ownership)模型。
旧模式是客户自管管道(customer-owned pipelines):每个业务团队自己拥有、自己配置、自己运维各自的摄取管道。这种模式在小规模时很灵活——团队想怎么调就怎么调。但当管道数量涨到数万级,问题就暴露了:
- 碎片化:每条管道配置各异,没有统一的可靠性保障,任何一条出问题都要单独排查。
- 运维不可扩展:落地时延要求越来越严,但分散的管道无法统一调度资源、统一兜底。
- 可靠性天花板:单条管道在小规模有效,但整体在超大规模(hyperscale)下无法维持稳定。
新架构的方向因此非常明确:从"分散的自管管道"收敛到"集中的、自管理(self-managed)的数仓服务"。把可靠性、资源调度、数据质量校验都下沉到平台层,业务团队不再各自造轮子。
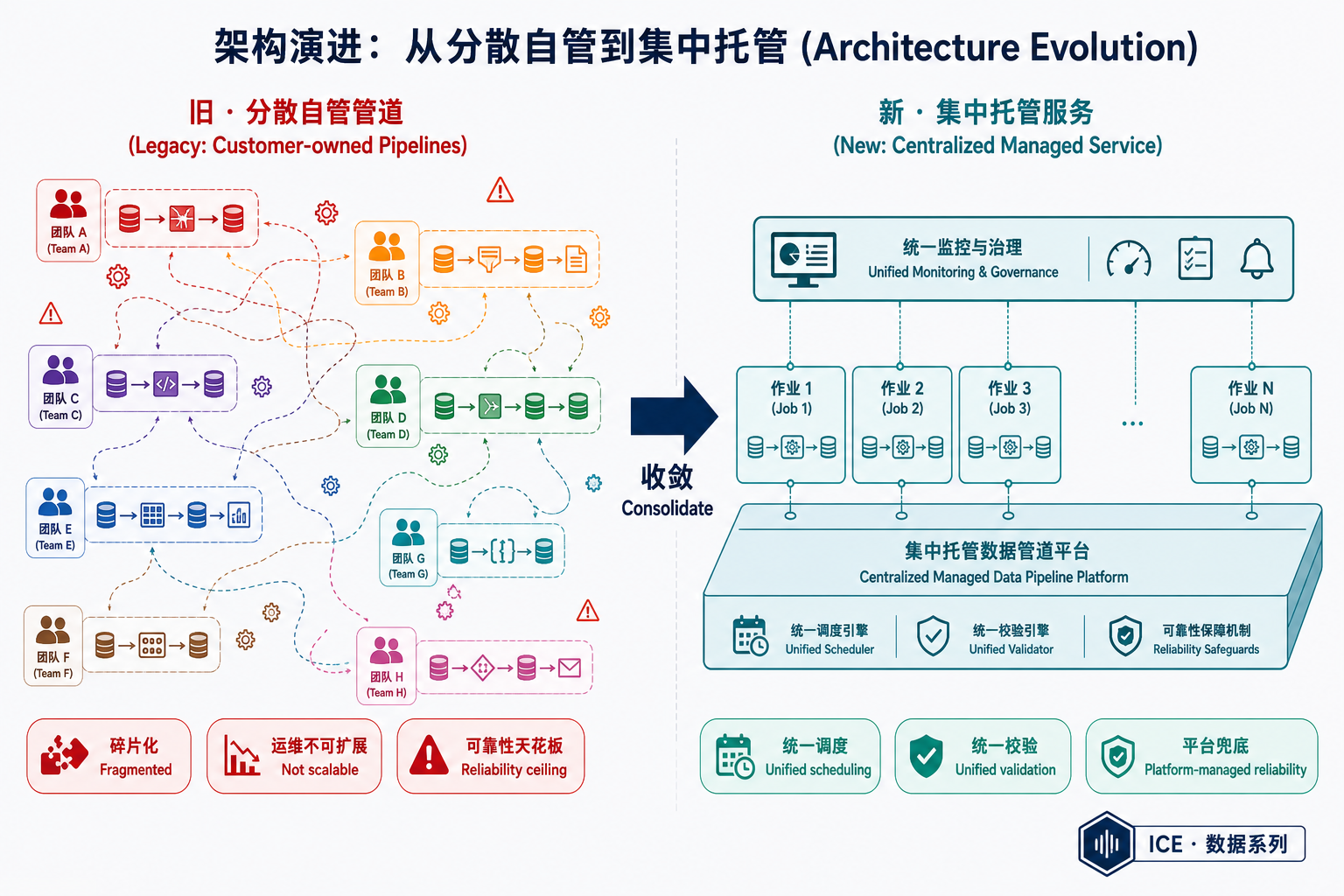
这其实是数据平台演进的一条通用规律:早期靠"给团队自由"换迭代速度,规模化之后必须靠"收敛到平台"换可靠性。Meta 这次只是把它做到了 PB / 数万作业的极端规模。
目前结果是:100% 工作负载已迁移完毕,旧系统完全下线。
三、技术底座:新旧系统都跑在 CDC 之上
新旧系统有一个共同的技术底座——CDC(Change Data Capture,变更数据捕获)。理解 CDC 是理解后面所有迁移技巧的前提。
每个摄取作业内部都有三张表:
| 表 | 作用 |
|---|---|
| Full Dump(全量表) | 源数据库的一次完整快照,是增量的起点 |
| Delta(变更表) | 持续捕获源库的增删改,记录"发生了什么变化" |
| Target(目标表) | 全量 + 增量合并后的结果,是下游数据消费者真正读取的表 |
所有作业实体的元信息(表名、表结构等)由一个中央管理服务统一保存和管理。
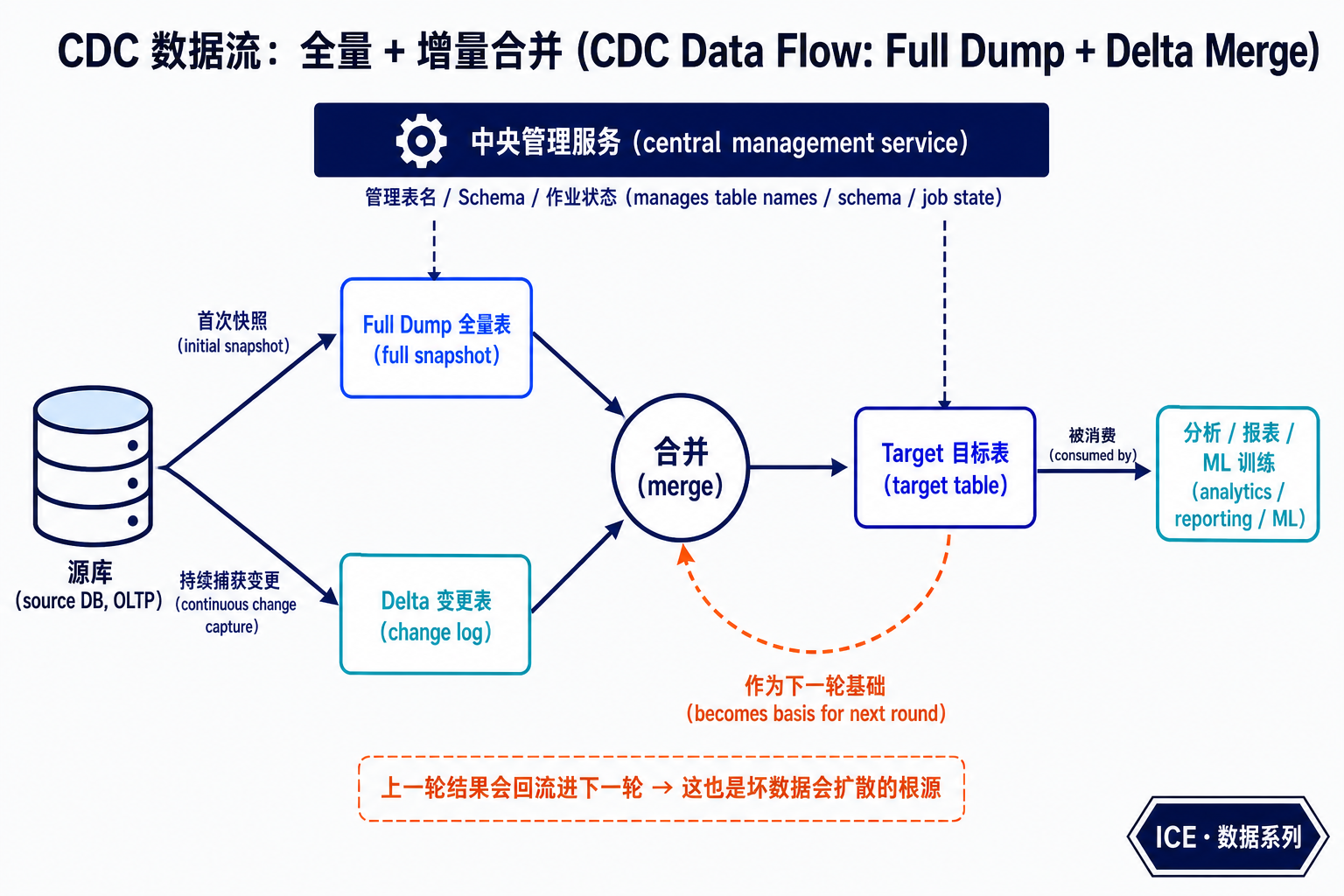
注意图里那条虚线回环:CDC 的本质是"用上一轮的落地数据,叠加新的 delta,生成下一轮的数据"。这意味着——如果上一轮落地的数据有问题,错误会顺着这条回环一路传给后面所有新数据。 记住这一点,它是第六节"止血术"要解决的核心矛盾。
四、迁移核心:影子、反向影子、清理三阶段
要把数万个作业从旧系统搬到新系统、还不能停机,Meta 设计了一套三阶段生命周期。每个作业必须逐个验证、达标才能进入下一阶段。
先说晋级标准(每一步都要满足):
- 零数据质量差异:新旧系统交付的数据完全一致——同时比对行数(row count)和校验和(checksum)。
- 落地时延不退化:新系统的落地时延应当更好,至少不差于旧系统。
- 资源占用不退化:计算与存储用量应当更优,至少与旧系统相当。
- 关键表额外加码:对被其他团队强依赖的关键表,还要和依赖方约定额外的迁移标准。
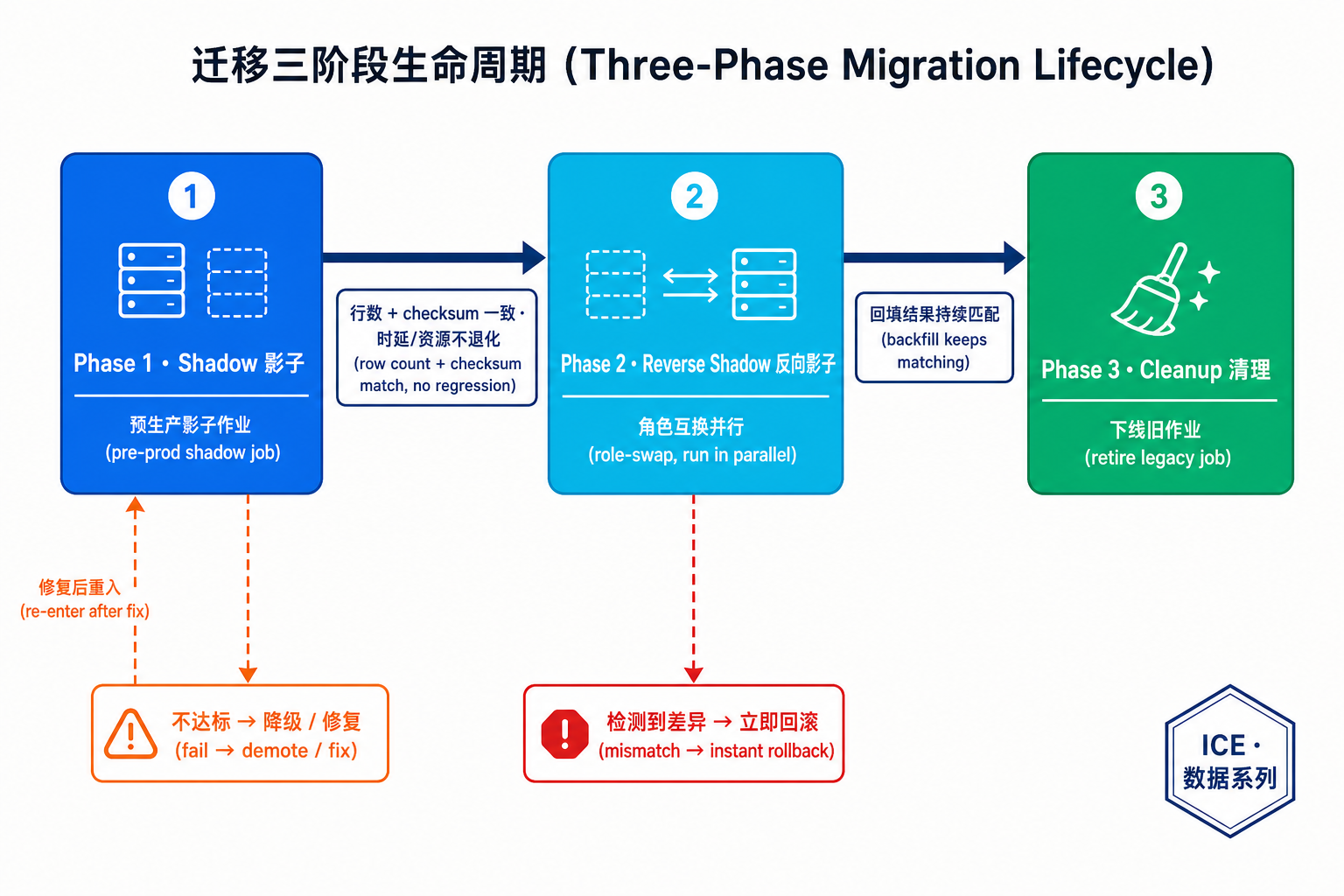
Phase 1:Shadow(影子阶段)
在预生产环境里,为每个作业建一个影子作业(shadow job):它消费和生产作业完全相同的源数据,但把结果写到一张独立的影子表里。
这是一种"生产级真实测试":既让新系统直面真实的生产数据和行为,又有一个隔离的观察区,可以检查结果、快速部署修复。
期间团队持续监控两者之间的行数 / checksum 差异。一旦出现 mismatch,就立刻定位根因,在预生产环境修复并验证。同时还会测量影子作业的计算与存储配额——确认生产环境资源够用,再往下走。
达标后,影子作业进入生产环境,确认能稳定运行,才进入下一阶段。
Phase 2:Reverse Shadow(反向影子)——整套设计的精髓
这一步是最值得学的。当生产作业和影子作业都在生产环境稳定运行后,Meta 做了一次角色互换:
- 让影子作业的数据写入生产表——影子作业事实上成了新的生产作业;
- 让原生产作业的数据写入影子表——原生产作业"降级"成了影子作业。
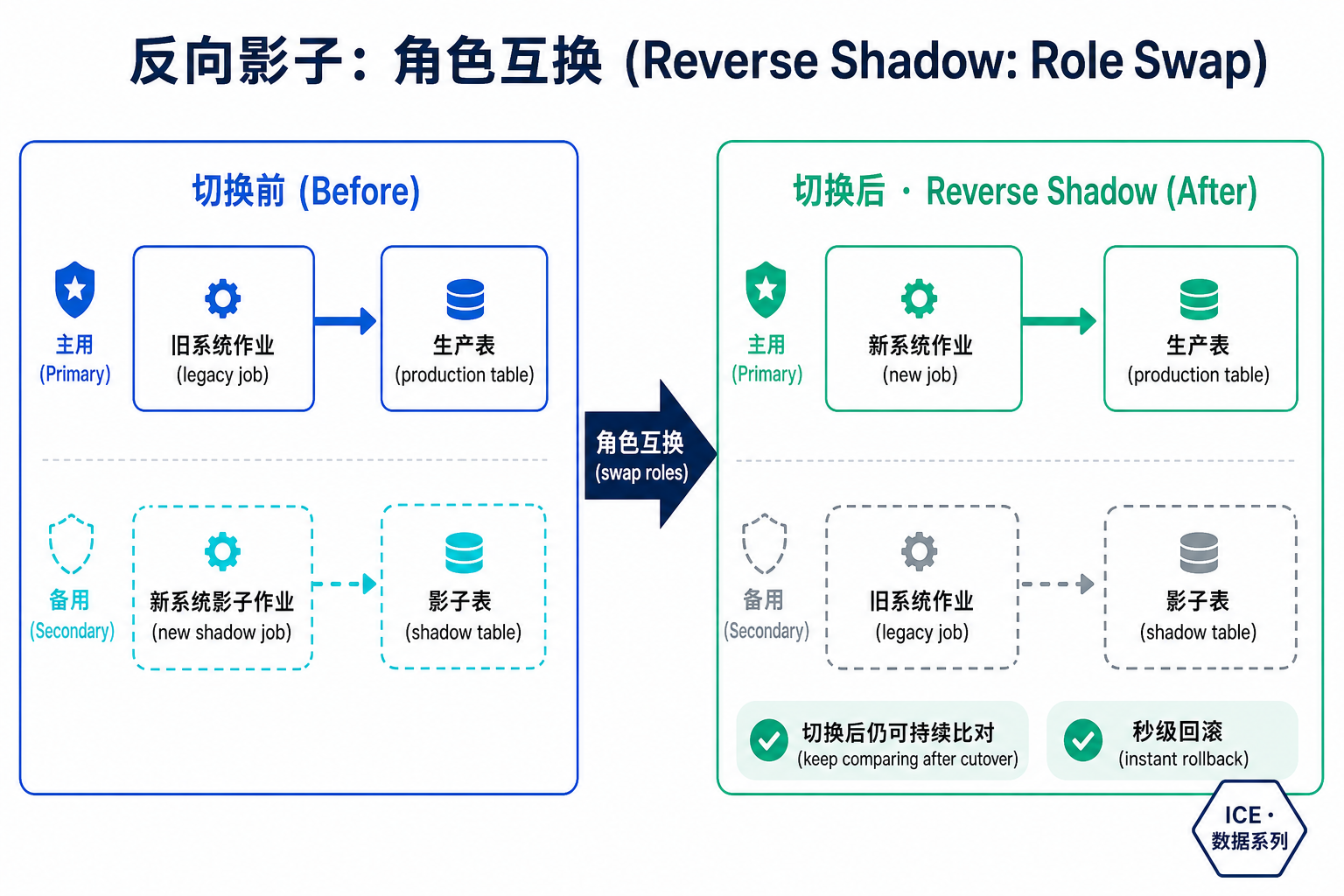
这样设计带来两个关键好处:
- 切换后还能继续拿到数据质量信号——因为旧系统作业还在跑、还在写影子表,可以继续和新系统的输出做比对。
- 可以秒级回滚——一旦发现新系统有问题,直接把写入目标换回去即可,不需要"重建 / 重新配置旧系统作业"。后者在数万作业规模下本身就是一场灾难。
普通的灰度发布通常是"切过去 → 旧的就停了"。反向影子的高明之处在于:它把"旧系统"当成一个随时待命的实时对照组留在原地,用一点额外的计算成本,换来了"上线后持续校验 + 零成本回滚"。在核心数据链路上,这笔买卖非常划算。
Phase 3:Cleanup(清理阶段)
继续监控、比对两个作业的输出。若一段时间内无差异,就删掉运行在旧系统上的那个影子作业。新系统正式接管,通过生产作业持续交付数据——迁移完成。
五、质量闭环:行数 + checksum 双校验,Scuba 实时定位
三阶段能跑通的前提,是有一套能自动发现并定位差异的数据质量工具。否则"对比新旧一致性"在数万作业规模下根本无法人肉完成。
Meta 自研了一套数据质量分析工具,工作方式是一个小时级的自动回环:
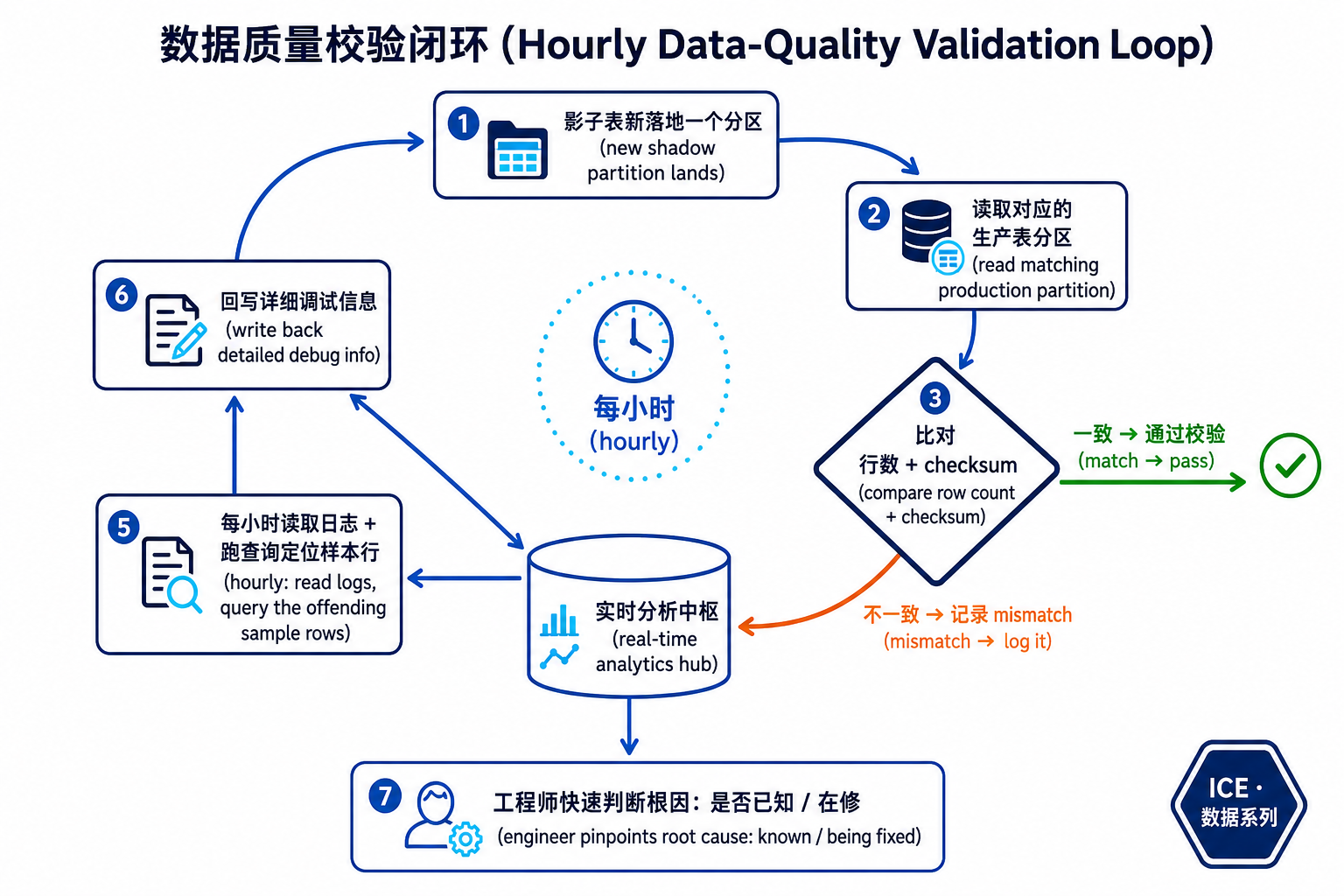
这里几个工程细节值得注意:
- 比对粒度是分区(partition):每落地一个影子表分区,就去读对应的生产表分区比对,而不是等整张表跑完。
- Scuba 作为实时分析中枢:所有 mismatch 先打到 Scuba(Meta 的实时数据分析系统),再由工具每小时回捞、定位样本行、回写调试信息。这一步把"知道有差异"升级成了"知道具体哪几行、为什么差"。
- 工具复用:这套工具在迁移完成后没有退役,而是留下来作为发布验证流程的常态化组件。迁移期建的能力,沉淀成了平台的长期资产。
六、CDC 的硬骨头:坏数据会自我繁殖,如何止血
回到第三节那条虚线回环。CDC 有一个棘手的本质:已经落地的数据,会被复用来生成新数据。
这意味着,一旦某一轮落地的数据出了问题,错误会顺着 delta 合并一路传播到后续所有新数据里。迁移期间真出了这种事,光"停下来"还不够——已经被污染的数据,也得修回去。
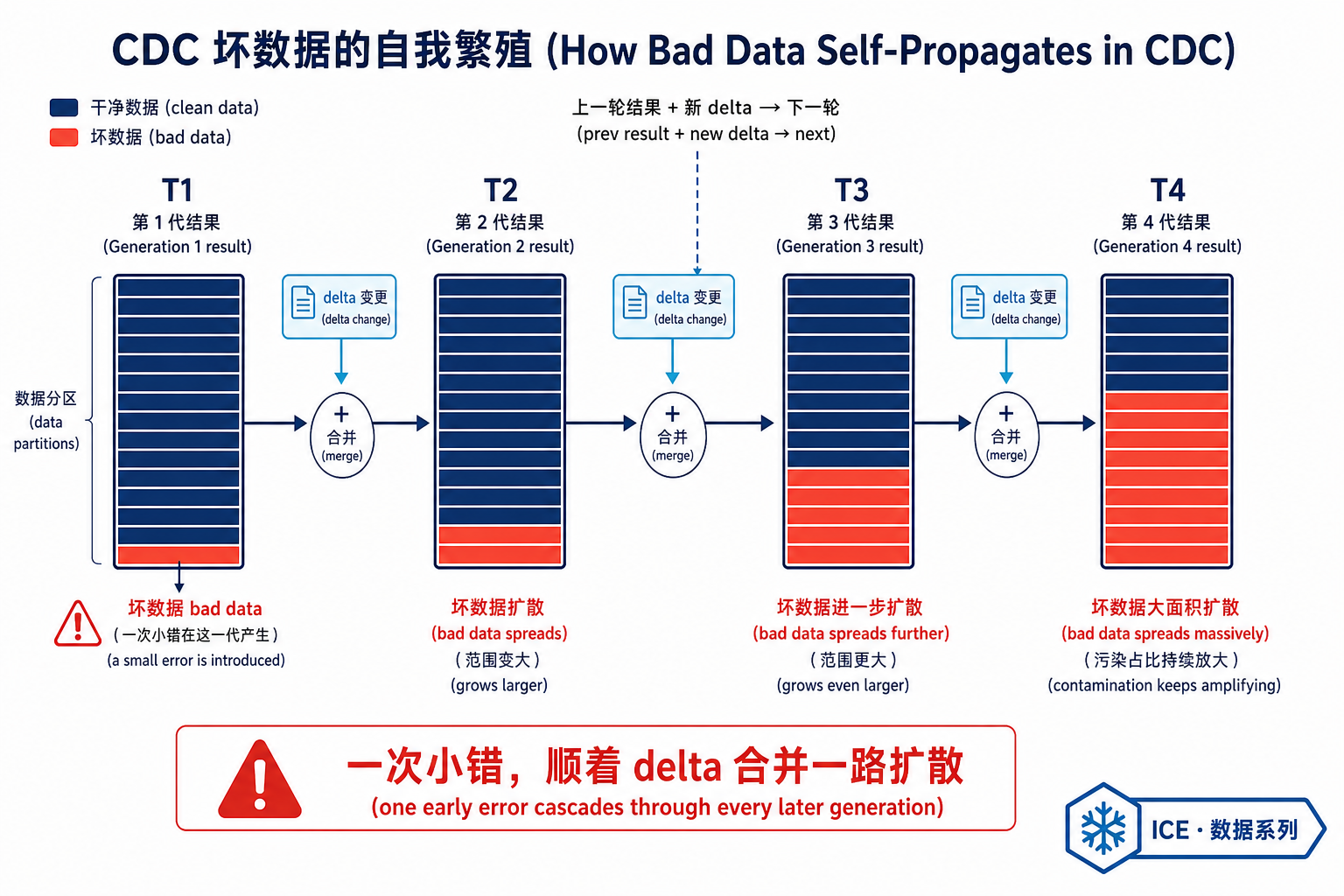
如上图,T1 的一小块坏数据,会在 T2、T3、T4 一代代合并中持续扩散、占比放大——这正是 CDC 链路最危险的地方。Meta 把这个问题拆成两个子问题来解:①坏数据落到下游之前就拿到早期信号;②真出事时如何快速止住扩散。
止血前提:上线后主动回填,抢在下游之前发现问题
与其等数据消费者发现问题,不如主动验证。在反向影子阶段(新旧作业并行写),Meta 会对生产作业和影子作业同时触发回填(backfill):
- 回填结果仍然匹配 → 说明迁移成功;
- 回填结果不匹配 → 立即回滚,数据消费者完全无感知。
止血手段:分区级标记 + 停止落地 + 定向回填
这是技术实现里最精巧的一段。一旦在反向影子阶段检测到某个分区有数据质量问题,系统会在该分区的元数据里打上"坏数据质量"标记,然后按分区类型分别处理:
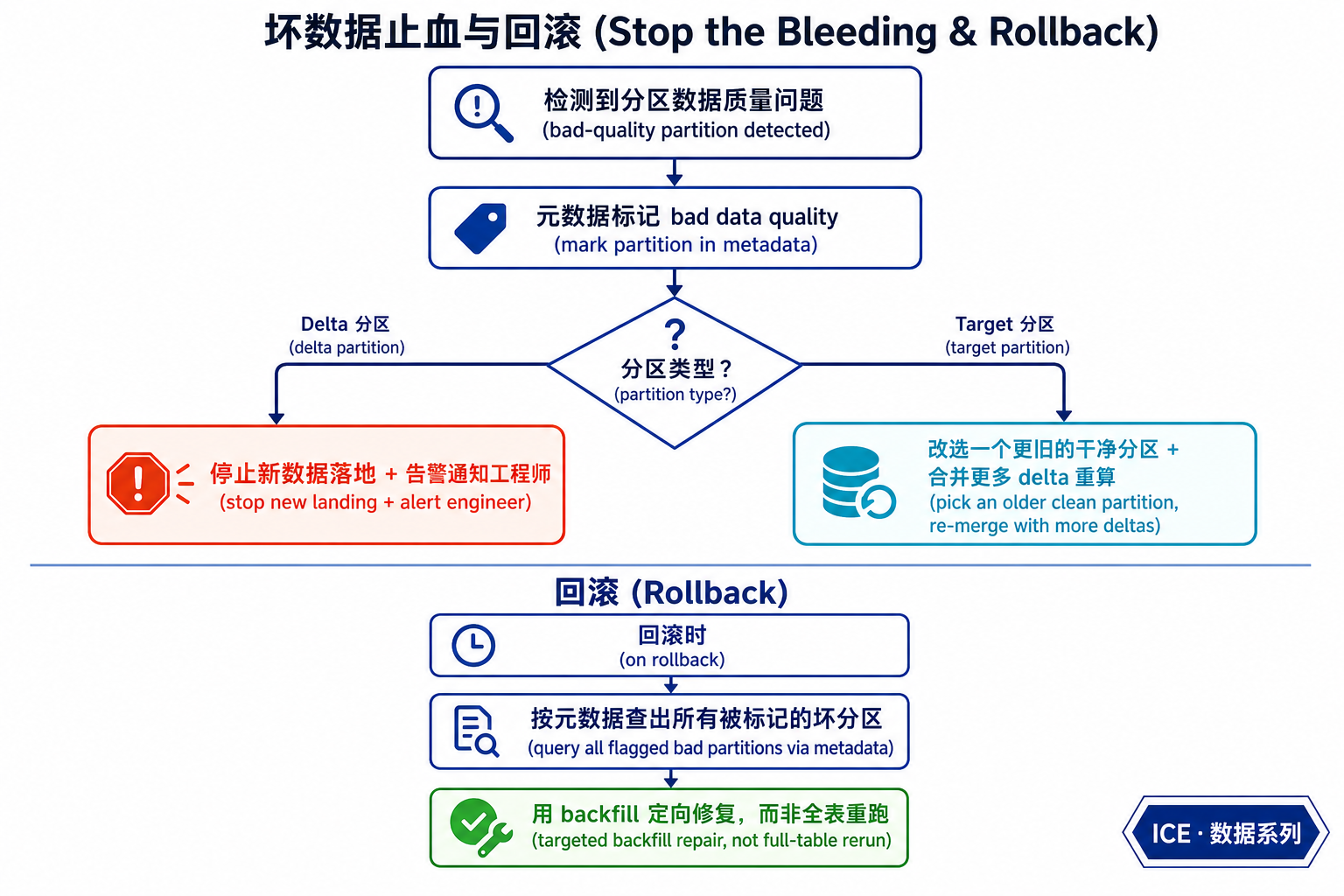
- 如果坏的是 delta 分区:直接停止新数据落地,并告警给工程师——掐断传播链。
- 如果坏的是 target 分区:系统改选一个更旧的、干净的分区,再合并更多 delta 重新算出正确结果——绕开被污染的那个版本。
- 回滚时:因为坏分区都在元数据里标记过,可以一次性查出所有坏分区,用 backfill 定向修复,而不是全表重跑。
这套机制的价值不止于迁移期——它让迁移完成后的日常可靠性也更高了:坏数据传播这个 CDC 的固有风险,被一套分区级的"标记—止血—回填"协议长期兜住了。
七、规模化执行:数万作业如何自动管、如何省钱
小批量验证跑通后,真正的挑战变成了两件事:①怎么自动监控并迁移海量作业;②容量有限时怎么安排影子测试。
自动编排:把三阶段生命周期变成状态机
数万作业不可能人肉推进。Meta 的做法是让每个作业持续把状态信号上报 Scuba——包括它当前处于生命周期哪一阶段、是否满足各项晋级标准。
然后用一套外部迁移工具持续监听这些信号,根据作业是否达标,自动在各阶段之间晋级或降级:达标就往前推,不再达标就退回去修。配套还有系统级和作业级的 dashboard,工程师既能看整体进度,也能下钻调试单个作业。
本质上,他们把"三阶段生命周期"实现成了一个由数据质量信号驱动的自动状态机——这是数万作业能跑通的关键。
批次规划:把最贵的 full dump 省下来
容量有限,没法一次性把所有影子作业跑起来,所以分批迁移,而批次怎么选直接决定效率:
- 按特征分类:按吞吐量、优先级、特殊情况给作业分类,按业务需要排优先级,并提前通知依赖方。
- 排除已知问题作业:建立筛选条件,把"仍在修已知问题"的作业先排除,避免重复噪音;检测到问题就把受影响作业从迁移列表里拿掉,等修复了再放回来。
最值钱的一条省钱技巧,和 CDC 特性直接相关:新作业的首次快照要走 full dump,而 full dump 又慢又贵。
问题在于:如果在已知 bug 还没修时就贸然建影子作业,一旦快照里带了问题,就得再触发一次 full dump 重新落正确快照——建作业时一次、修数据时又一次,全是重复的昂贵全量。所以 Meta 的策略是:
- 已知问题修复前,不创建对应的影子作业——避免大量不必要的 full dump。
- 复用旧系统已交付的快照分区作为新作业的初始快照——直接省掉一部分 full dump 负载。
这两招把"全量快照"这个最大的成本项压了下来,显著提升了整体迁移效率。
八、小结:5 条可复用的迁移经验
抛开 Meta 的体量,这次披露里真正可迁移到任何团队的,是一套在活体核心链路上"换引擎"的方法论。如果你也要做高风险的系统迁移,下面 5 条值得抄作业:
- 用"反向影子"代替"一刀切换"。切过去之后别急着拆旧系统——让它降级成实时对照组继续跑。你换来的是"上线后持续校验 + 零成本回滚",代价只是一点点额外算力。在核心链路上,这是最划算的保险。
- 把"一致性"定义成可机器判定的硬指标。行数 + checksum 双校验,按分区比对,差异自动定位到样本行。一句话:让"数据对不对"变成自动化信号,而不是靠人肉抽查或等下游投诉。
- 认清你的数据流是否会"自我繁殖"。CDC、物化视图、特征回填这类"用旧结果算新结果"的链路,坏数据会扩散。一定要有一套分区/批次级的"标记—止血—回填"协议,否则一次小错会滚成大故障。
- 把迁移生命周期实现成自动状态机。当对象有成千上万个时,靠人推进度不现实。用统一的晋级标准 + 状态信号上报 + 自动晋级/降级,把"流程"变成"系统"。
- 识别并提前规避最贵的操作。这次是 full dump:通过"修好再建作业"和"复用旧快照"两招绕开重复全量。每个系统都有自己的"full dump",迁移设计里要专门为它做规划。
最后留一个问题给正在做数据平台的你:
你手上那条最关键的数据链路,今天若要零停机换掉底层引擎,你有没有一个"反向影子"式的退路?有没有一套能机器判定一致性的校验闭环?
如果答案是"没有,全靠上线后盯监控"——那也许正是这篇 Meta 实践最该提醒你的地方。
参考资料
- Zihao Tao, Mohan Perumal Swamy, Grace Gong, et al., Migrating Data Ingestion Systems at Meta Scale, Engineering at Meta, 2026-05-12. engineering.fb.com.
- Renato Losio, How Meta Rebuilt Data Ingestion for Petabyte-Scale Reliability, InfoQ, 2026-05-30. infoq.com.
- Engineering at Meta, The History of MySQL at Meta, 2021-07-22. engineering.fb.com. 背景:Meta 的 MySQL 规模。
- Meta Research, Scuba: Diving into Data at Facebook, 2013. research.facebook.com. 文中实时分析中枢 Scuba 的原始论文。