ODCS v3.1 场景演练:把数据合同从 PDF 变成凌晨 02:34 的电话

调研报告 | 2026 年 4 月 | 面向数据工程师与平台架构师
摘要
上一篇 Data Contracts:当 AI Agent 把脏数据的代价放大 10 倍 讲了为什么 Data Contract 在 2026 进入实操期。但读完之后真到工程师手上,仍然有个问题没答:这东西在生产里到底长什么样?
这一篇就回答这个问题。我用一个虚构的电商订单事故场景为引子(公司、字段、事故经过都是为演示设计的,但每一段技术细节、命令、告警样本都按 ODCS v3.1 真实工具链能跑通的形态写),把 ODCS v3.1(Open Data Contract Standard 开放数据合同标准,2025-12 发布的最新稳定版)端到端走一遍:从一份订单合同的 YAML 怎么写、怎么接进 CI(Continuous Integration 持续集成流水线)、怎么调度凌晨的检查、怎么喂给推荐 Agent、再到事故发生时凌晨 02:34 那个真的会响的告警长什么样。
如果你只想带走一句话:ODCS 不是文档标准,是 cron(定时任务调度)标准——一份合同的真正价值,不在它写得多漂亮,而在它每天凌晨能不能在数据进生产表之前把脏数据拦下来。
一、一次推荐系统翻车
先把场景放清楚,后面所有 YAML 才有意义。
假设有一家虚构的电商"快电",订单团队每日凌晨 02:00 在 Snowflake 产出一张事实表 analytics.orders_daily,三个下游消费:BI 团队的"日 GMV 大盘"、营销团队的"复购预测模型"(每日重训)、推荐系统的"用户购买力特征"(每日离线派生 → 在线特征库 → Agent 实时拉取作为推荐上下文)。
4 月 10 日,订单团队上线"信用分期"功能,给 payment_method(支付方式)字段加了一个新枚举值 installment(分期付款)。没人通知下游——因为这件事在每个 producer(数据生产方)心里都是"小改动"。
三个下游的反应非常有代表性:
| 下游 | 表现 | 业务损失 |
|---|---|---|
| BI 大盘 | installment 落进 unknown 桶,分期 GMV 凭空消失 | 周报数据错 3 天才被发现 |
| 复购模型 | installment 被当 NULL,触发空值兜底分支 | 给分期用户推全价券,亏损 12 万 |
| 推荐 Agent | LLM 看到陌生值,自由发挥:"installment 用户偏好高客单"——其实正相反 | 推荐 CTR 跌 18% |
复盘会上得出的唯一结论是"以后要通知下游"——这种话写一万次都不会有人执行。真正能阻断这种事故的,是把"通知"翻译成代码、把代码挂进调度。
这就是 ODCS 要解决的事:把"小改动"变成显性的、版本化的、可被 CI 拒绝的合同变更。下面把这件事一步步做出来。
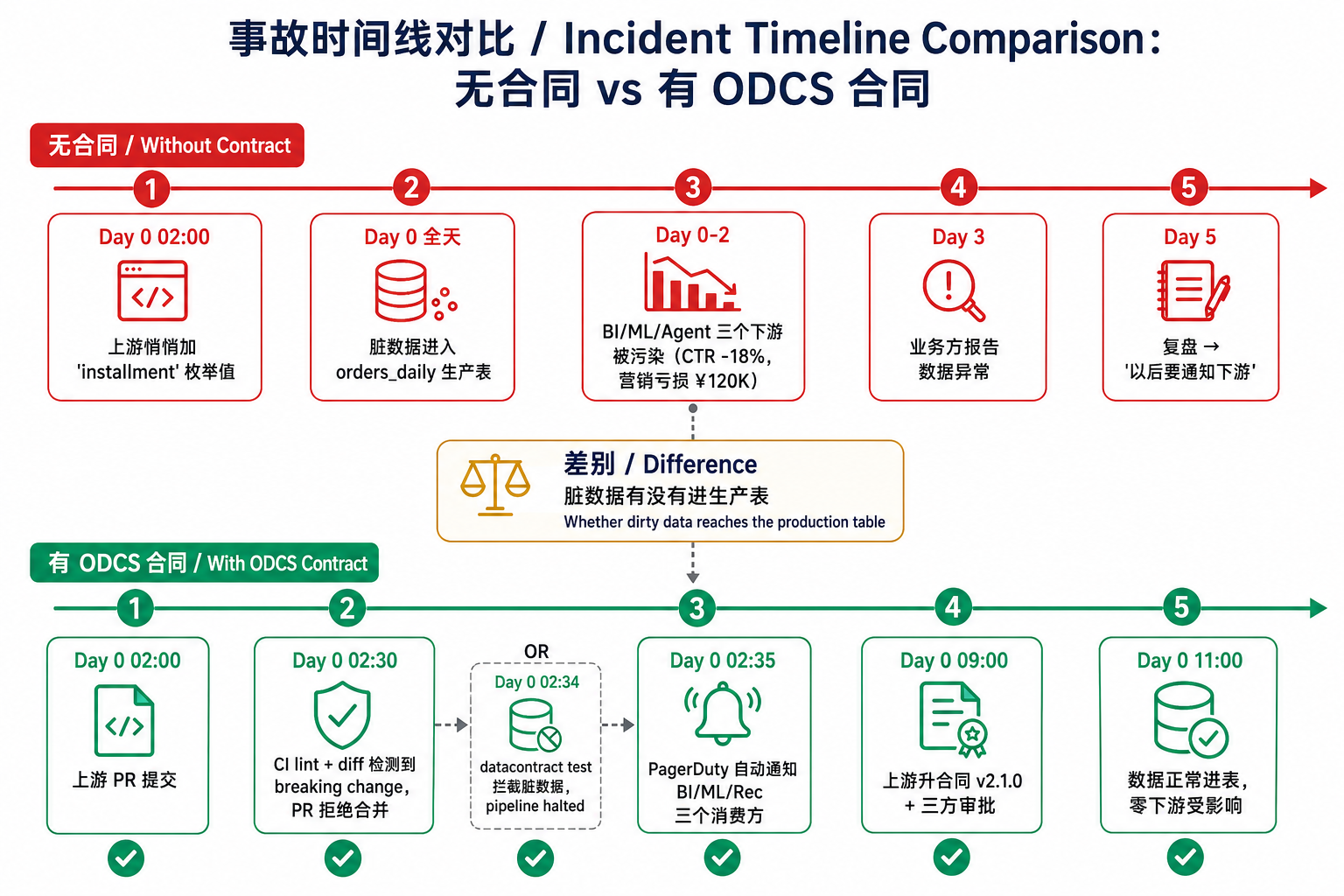
上图是这次事故在两种范式下的时间轴对比。差别不在"有没有数据治理工具"——快电的 Snowflake 上 Soda 也跑着、DataHub 也接着——差别在契约有没有挂在调度里。前者是"事后 3 天被业务发现",后者是"02:34 在数据进生产表之前直接拦下来"。
二、把这张表写成 ODCS v3.1 合同
合同放在新建仓库 data-contracts/ 里,按 domain 分目录。先看完整文件,再讲为什么这么写。
# contracts/sales/orders_daily.odcs.yaml
# ─── 元信息 ─────────────────────────────────────
kind: DataContract
apiVersion: v3.1.0
id: 7f8a4e2c-3b15-4a89-9c2d-12c8f7a1b5d3
version: 2.0.0 # 上次因 payment_method 加值已经升过 major
status: active
domain: sales
tenant: KuaidianRetail
description:
purpose: 每日订单事实表,是 GMV 报表与所有下游营销 / 推荐模型的唯一事实源
limitations: T+1 数据,不含退款修正(退款见 orders_refund_daily)
usage: 仅用于聚合分析与离线模型;实时场景请订阅 orders_stream
# ─── 物理位置 ───────────────────────────────────
servers:
- server: snowflake-prod
type: snowflake
account: kuaidian.us-east-1
database: ANALYTICS
schema: SALES
# ─── Schema + 关系 + 质量 ───────────────────────
schema:
- id: orders_daily_obj
name: orders_daily
physicalName: ORDERS_DAILY
physicalType: table
businessName: 每日订单事实表
description: 按 order_id 粒度的当日订单快照
tags: [finance, sales, t-plus-1]
dataGranularityDescription: 1 行 = 1 笔订单(order_id 唯一)
# 跨表外键(v3.1 新增)
relationships:
- type: foreignKey
from: [orders_daily.customer_id]
to: [customers_dim.customer_id]
- type: foreignKey
from: [orders_daily.sku_id]
to: [products_dim.sku_id]
properties:
- id: order_id_prop
name: order_id
primaryKey: true
primaryKeyPosition: 1
logicalType: string
physicalType: VARCHAR(32)
required: true
unique: true
classification: internal
description: 订单唯一标识,雪花算法生成
examples: ["ORD20260410001234"]
quality:
- type: library
metric: nullValues
mustBe: 0
severity: error
schedule: 0 30 2 * * * # 02:30 跑(数据 02:00 落地)
scheduler: cron
- type: library
metric: duplicateValues
mustBe: 0
severity: error
schedule: 0 30 2 * * *
scheduler: cron
- id: order_date_prop
name: order_date
logicalType: date
physicalType: DATE
logicalTypeOptions:
format: yyyy-MM-dd
timezone: Asia/Shanghai
required: true
partitioned: true
partitionKeyPosition: 1
- id: customer_id_prop
name: customer_id
logicalType: string
physicalType: VARCHAR(20)
required: true
classification: restricted # PII
relationships:
- to: customers_dim.customer_id
type: foreignKey
- id: gross_amount_prop
name: gross_amount
logicalType: number
physicalType: NUMBER(12,2)
required: true
description: 订单总额(分期视为全额计入)
quality:
- type: sql # 复杂逻辑用 SQL 回退
description: 金额必须 > 0 且 < 单笔上限
query: |
SELECT COUNT(*) FROM ANALYTICS.SALES.ORDERS_DAILY
WHERE gross_amount <= 0 OR gross_amount > 1000000
mustBe: 0
severity: error
schedule: 0 30 2 * * *
scheduler: cron
- id: payment_method_prop
name: payment_method
logicalType: string
physicalType: VARCHAR(32)
required: true
description: 支付方式枚举,新增需升 minor 版本并 PR 通知所有消费方
examples: [mobile_wallet, qr_pay, card, installment] # 关键护栏
quality:
- type: sql
description: 不允许出现枚举外的值
query: |
SELECT COUNT(*) FROM ANALYTICS.SALES.ORDERS_DAILY
WHERE payment_method NOT IN
('mobile_wallet','qr_pay','card','installment')
mustBe: 0
severity: error
schedule: 0 30 2 * * *
scheduler: cron
# 表级质量:体积异常
quality:
- type: library
metric: rowCount
mustBeBetween: [50000, 500000]
description: 日订单量正常区间,超出就是埋点出问题或服务挂了
severity: error
schedule: 0 35 2 * * *
scheduler: cron
# ─── SLA:可执行的服务承诺(v3.1 新增 scheduler)─
slaProperties:
- property: latency
value: 3
unit: h
element: orders_daily.order_date
driver: operational
description: 数据落地时间不晚于次日 03:00
scheduler: cron
schedule: 0 5 3 * * * # 03:05 检查昨天数据是否到位
- property: frequency
value: 1
unit: d
- property: retention
value: 5
unit: y
driver: regulatory # 财务监管要求
# ─── 谁负责 / 谁能找谁 ───────────────────────────
team: # v3.1 改对象
name: order-platform
description: 订单中台团队,是本合同的 Data Producer
members:
- username: liwei
role: Data Product Owner
- username: zhang.yi
role: Tech Lead
roles:
- role: bi_reader
access: read
firstLevelApprovers: bi-lead@kuaidian.com
- role: ml_reader
access: read
firstLevelApprovers: ml-lead@kuaidian.com
support:
- channel: '#data-orders'
tool: slack
scope: interactive
- channel: orders-incidents
tool: pagerduty
scope: notifications
tags: [tier-1, gmv-source]
contractCreatedTs: "2025-08-12T03:00:00+08:00"这份文件看着长,骨架其实只有七块——这是 v3.1 标准合同的固定结构:
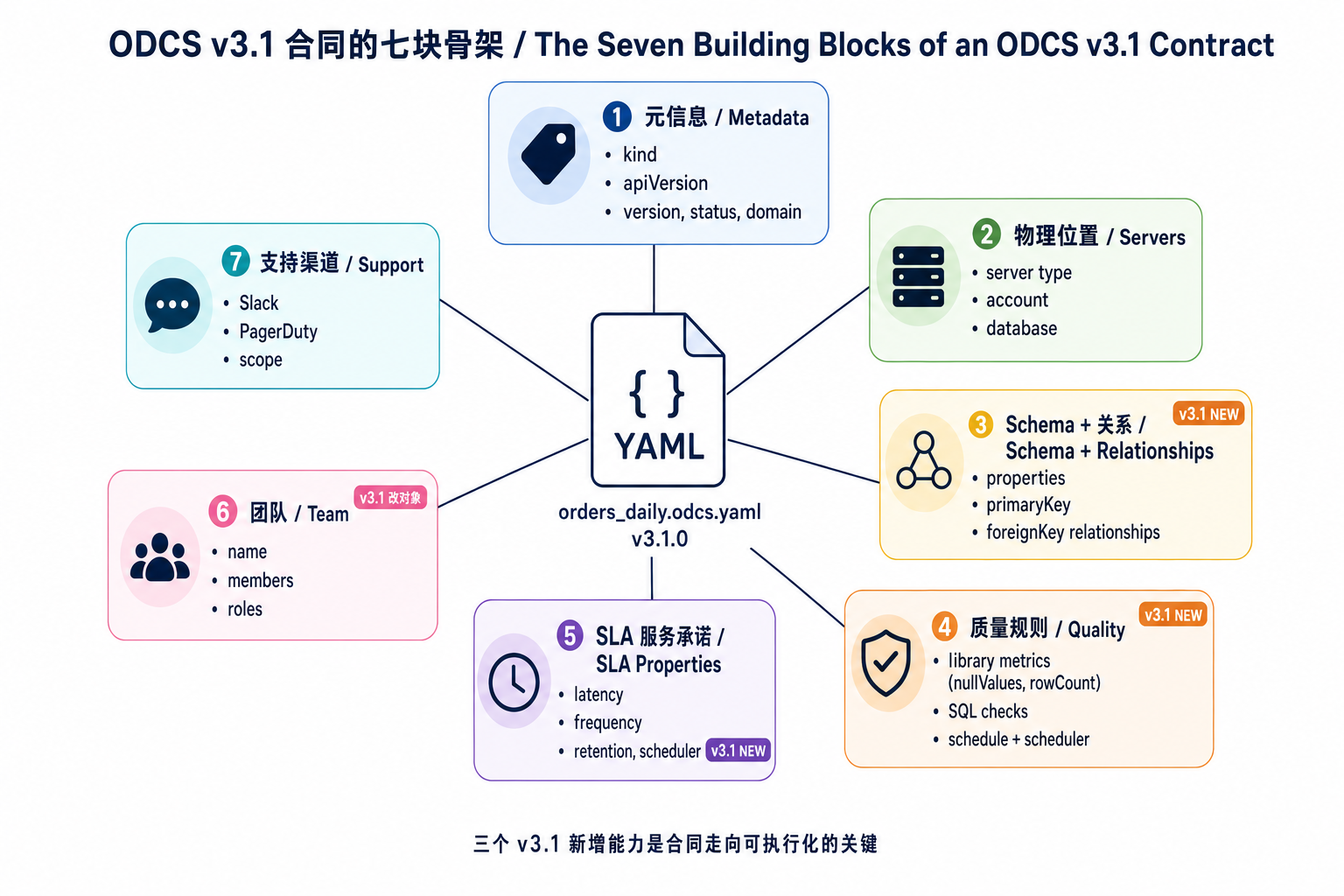
需要在这份合同里特别注意的几个 v3.1 用法:
第一是 payment_method.examples 配 SQL quality 规则。examples(示例值列表)表面上是"示例",实际被消费方工具当事实上的枚举字典使用——下面的 SQL 检查 + severity: error(违规级别为错误)把它变成硬护栏。下次再有人偷加 credit_installment(信用分期)之类的值,CI 直接红,无法蒙混过关。这一条规则就是上次事故的真正护栏。
第二是 relationships 把外键写进合同。物理 Snowflake 表本身没有 FK 约束(数仓常态),但合同里写明 customer_id → customers_dim.customer_id 后,下游 dbt 模型可以从合同生成 join 提示,下游 RAG Agent 也能直接读到表与表的关系(这个稍后会用上)。
第三是 每条 quality 规则都内嵌 schedule + scheduler。v3.0 时代要把检查写在 Soda 配置里另外维护一份,合同和检查会逐渐脱节;v3.1 把它们合并到一处,凌晨什么时候跑、跑哪些规则,全在合同里说清楚。
第四是 version: 2.0.0 和显式 examples 列表的组合。这两件事一起意味着:合同有真实演化轨迹(上次加 installment 已经升过 major),加新支付方式必须升版本 + 走 PR 评审 + 通知三个消费方——把"通知下游"这件事变成了版本号变更的副产物,而不是依赖人的自觉。
第五是 team 改为对象(v3.1 RFC-0016)。看起来是细节,但意味着合同有了"第一负责人"语义,而不是"一群人都能改"。出问题时 PagerDuty 知道把电话打给谁。
三、把合同接进 CI——让它真的会拦人
合同写完只是文档,真正的护栏是它在 PR 流水线里能 fail 谁。CI 配置长这样:
# .github/workflows/data-contract.yml
name: Data Contract CI
on:
pull_request:
paths: ['contracts/**/*.odcs.yaml']
schedule:
- cron: '30 2 * * *' # 每天 02:30 自动跑质量检查
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install datacontract-cli
run: pip install 'datacontract-cli[snowflake]'
# ① strict schema 校验(v3.1 起强制)
- name: Lint contract
run: |
for f in contracts/**/*.odcs.yaml; do
datacontract lint "$f" --schema odcs-v3.1.0-strict
done
# ② breaking change 检测(删字段、改类型必须升 major)
- name: Detect breaking changes
if: github.event_name == 'pull_request'
run: |
datacontract diff \
--base origin/main \
--head HEAD \
--fail-on breaking
# ③ 真的连 Snowflake 跑一次质量规则
- name: Run quality checks
env:
SNOWFLAKE_PASSWORD: ${{ secrets.SF_PWD }}
run: |
for f in contracts/**/*.odcs.yaml; do
datacontract test "$f" --output junit > result.xml
done
# ④ 自动把合同里的消费方拉进 PR review
- name: Request reviews from consumers
if: github.event_name == 'pull_request'
uses: ./.github/actions/contract-reviewers这套 CI 由四条防线组成,每一条对应一类失败:
Lint 用的是 v3.1 新引入的 strict JSON Schema,过去 ODCS 容忍多余字段——这是大家把奇怪东西塞进 customProperties 的根源——v3.1 起任何未定义字段直接拒绝。这是合同语法层面的护栏。
Diff 是逻辑层面的护栏。datacontract diff --fail-on breaking 会自动识别四类破坏性变更:删字段、改 physicalType、把 required 从 false 改成 true、缩小 examples 枚举集合。开发者只能"改合同 + 升 major 版本"才能让 PR 绿。这一条才真正逼大家面对"小改动其实是大改动"的现实。
Test 是数据层面的护栏。datacontract test 把合同里的 quality 段实时翻译成 Snowflake 查询去跑——内置的 library 规则有原生实现,自定义 SQL 直接执行。这是 ODCS 工具链最甜的一段:你写一份合同,它自动生成 Soda check / dbt test / 直接 SQL 三种产出物,下游想用哪种都行。
Reviewers 是组织层面的护栏。从合同的 roles 段读到所有有 read 权限的角色,自动把对应团队的代表拉进 PR——绕过这一步要在 GitHub branch protection 里 override,会留审计日志。
四条防线叠在一起的效果是:"小改动悄悄上线"在工程上变得不可能。要么显式升版本走流程,要么 PR 红着合不了。
四、合同也要管 Agent——把它喂给推荐系统
走到这里 ODCS 解决的还只是传统数据治理。但合同还有一个被低估的副产品:RAG/Agent 直接消费它,不再需要人工写"系统提示词"。
import yaml, json
contract = yaml.safe_load(open('contracts/sales/orders_daily.odcs.yaml'))
table = contract['schema'][0]
tool_schema = {
"name": "query_orders",
"description": contract['description']['purpose'],
"table": f"{contract['servers'][0]['database']}.SALES.{table['physicalName']}",
"columns": [
{
"name": p['name'],
"type": p['physicalType'],
"enum": p.get('examples'), # 枚举值
"pii": p.get('classification') == 'restricted',
"required": p.get('required', False),
}
for p in table['properties']
],
"relationships": table['relationships'], # join 提示
"freshness_hours": next(
s['value'] for s in contract['slaProperties']
if s['property'] == 'latency'
),
}
system_prompt = f"""
你只能查询以下表,列定义、枚举值、外键关系如下:
{json.dumps(tool_schema, ensure_ascii=False, indent=2)}
注意:payment_method 只能取 {tool_schema['columns'][4]['enum']},
出现其他值视为脏数据,必须告警而非自由解读。
PII 字段(标记 pii: true 的列)输出前必须脱敏。
数据时效不超过 {tool_schema['freshness_hours']} 小时。
"""这一段才是真正闭环。合同不仅约束 ETL(数据抽取-转换-加载管线),也约束 LLM。Agent 看到 installment 时知道"这是合法枚举";看到 BNPL(Buy Now Pay Later,先买后付的英文缩写)时知道"这是脏数据,立刻告警";看到 customer_id(用户标识)时知道"这是 PII(个人身份信息),要脱敏"——再也不会"自由发挥"。
更进一步的版本:把整个合同 YAML 哈希后嵌入 Agent 的工具调用请求里,下游服务用这个哈希校验"我现在用的合同版本和 Agent 期望的是不是同一个"。版本不一致直接拒绝调用。这就是 上一篇 提到的 Tool Contract 在 ODCS 里的最简实现——不需要新标准,只需要把 ODCS 用得更狠一点。
五、凌晨 02:34 的告警长什么样
合同接进调度器后,4 月 23 日凌晨真的有人偷偷上了新支付方式 credit_installment(觉得跟原有的 installment 一样、也是分期,不用通知)。这是 PagerDuty 凌晨收到的告警:
🔴 [DATA-CONTRACT-VIOLATION] orders_daily v2.0.0 · 02:34 CST
Contract: contracts/sales/orders_daily.odcs.yaml
Owner: @liwei (order-platform team)
Severity: error · Driver: operational
✗ Quality check FAILED: payment_method_enum_check
Rule: payment_method NOT IN
('mobile_wallet','qr_pay','card','installment')
Found: 1,247 rows with value 'credit_installment'
First: ORD20260423000412
Action: Pipeline halted. orders_daily NOT promoted to consumers.
✓ Affected consumers (auto-notified via #data-orders):
- bi-team (GMV dashboard)
- ml-team (repurchase model)
- rec-team (recommendation agent)
Next steps:
1. Either revert the upstream change, OR
2. Bump contract to v2.1.0 adding 'credit_installment' to examples,
get approval from 3 consumer teams, then re-run pipeline.这条告警的关键不是"它告警了"——任何监控工具都能告警。关键在 Pipeline halted. orders_daily NOT promoted to consumers. 这一句:脏数据根本没进生产表。
下游的 BI、ML、推荐 Agent 早上起来打开看板,看到的要么是昨日数据(如果 SLA 允许),要么是"数据未就绪 - 等待上游修复"的占位——但绝对不会是被污染的指标。这是 Self-Enforcing + Shift-Left 在生产里的真正姿势。
把这次事故和 4 月 10 日那次拉同一张时间线对比就能看出价值差:
| 维度 | 4 月 10 日(无合同) | 4 月 23 日(有合同) |
|---|---|---|
| 脏数据进生产表 | 是 | 否 |
| 发现时间 | 业务方 3 天后报告 | 凌晨 02:34 自动告警 |
| 影响范围 | 三个下游全部受污染 | 零下游受影响 |
| 复盘结论 | "以后要通知下游" | "上游升合同 v2.1.0,自动通知三个消费方" |
| 业务损失 | 营销端 12 万 + 推荐 CTR -18% | 零 |
| 工程修复时间 | 半天 | 凌晨值班 + 正常工作时间审核 |
差别不在"用没用 ODCS",而在 ODCS 的合同有没有挂在 cron 里。一份只在 git 里躺着的 YAML,和一份每天凌晨 02:30 真的会跑、违约会切断管线、违约会自动通知下游的 YAML,是两件根本不同的东西。
六、落地工时与避坑
按我看到的几个团队(订单中台规模),从零落地这套东西的参考工时:
| 阶段 | 工时 | 产出 |
|---|---|---|
| 选第 1 张表、写第一份合同 | 2-3 天 | YAML + 团队 review 通过 |
| 接 datacontract-cli + Snowflake | 1 天 | datacontract test 能跑通 |
| 写 GitHub Action(lint + diff + test) | 0.5 天 | PR 流水线生效 |
| 调度 cron 跑 SLA 与凌晨质量检查 | 0.5 天 | 告警接到 PagerDuty/Slack |
| 首张表全链路上线 | ~5 个工作日 | 1 个产品级合同跑在生产 |
| 之后每张表平摊 | 0.5-1 天 | 模板化复制 |
工时不是难点,选错第一张表才是。看到太多团队踩过同样的坑,归纳几个:
坑 1:第一张表选最复杂的。某团队上来就选用户行为流水(字段五十多、消费方七八个、SLA 苛刻),三个月后所有人都精疲力尽,制度被搁置。第一张合同要选"重要但简单"的——订单聚合、客户维表、商品维表都比行为流水适合。先把流程跑顺,让团队感觉到"这事是能做成的",再扩规模。
坑 2:把所有表都写合同。合同是给"被消费的、跨边界的"数据集用的。中间临时表、单团队内部表不要写。判断标准只有一个:这个数据集有没有外部消费者?没有就不写。强行覆盖只会让维护成本反噬。
坑 3:合同里塞实现细节。常见反例是把 ETL 调度时间、Spark 集群名、转换 SQL 都塞进 customProperties。ODCS 的边界是对消费者承诺什么,不是怎么实现。实现属于 dbt / Airflow / Terraform。混进来后合同会变得不稳定,每次实现重构合同都要改,最后没人维护。
坑 4:用 customProperties 走捷径。strict schema 出来之后,把奇怪字段塞 customProperties 仍然能跑——但这是反模式。customProperties 是规范没覆盖时的逃生通道,不是默认抽屉。塞进去的字段对其它工具不可见,等于把"私有协议"伪装成"标准合同"。
坑 5:SLA 只写不调度。v3.1 已经支持 scheduler + schedule,没理由再把 latency: 3h 当文档摆设。没有自动校验的 SLA 等于没有 SLA——只有当合同检查任务在凌晨跑、违约会触发告警,承诺才有意义。
七、ICE 观察
技术视角:合同的真正护栏在 cron 里,不在 YAML 里
把合同写得多漂亮其实不重要。同一份合同,挂在 git 里就是 PDF,挂在 cron 里就是凌晨 02:34 的电话——后者才有真正的工程价值。
这给数据团队提了一个反直觉的工作排序:先想清楚"违约时谁会被叫醒",再去写 YAML 字段。如果你的合同没有 PagerDuty 接口、没有 Slack 通道、没有自动 PR review,写得再细都是装饰。
ODCS v3.1 把 scheduler + schedule 内嵌进 quality 和 SLA,本质就是在用工具机制逼大家把"承诺"和"执行"放在一处——这是过去最容易脱节的一段。
落地视角:第一张表选什么决定生死
这件事我说了三遍是因为它真的重要。我看到的所有 Data Contract 落地失败案例里,70% 的根因是第一张表选错了——要么太复杂、要么消费方太多、要么 producer 团队没意愿。
正确顺序是:找一条"业务方天天抱怨数据不准"的中等复杂度数据流(订单、库存、用户基础信息这类),让上下游各派一个对接人,3 周内把合同 + CI + 调度跑通,拿到一个具体的"被拦下来的告警案例",再用这个案例去说服第二张表的 producer。
这是 product-led 而不是 governance-led 的推法——governance-led 的"一次推全公司"几乎全部失败,product-led 的"案例驱动"几乎全部成功。
本土视角:基础设施层有真实空白
国内目前这一层基本是空白:阿里 DataWorks、腾讯云数据智能、华为 DataArts 这三家做得最重,但都还停留在"数据血缘 + 质量监控"的传统范式,没有人把 ODCS 标准、shift-left 执行、Agent 边界契约整合成一等公民产品。
更具体的机会在两层:
一层是 datacontract-cli 的中文化 + 国产数仓适配。现有的开源 CLI 对 Snowflake / BigQuery / Postgres 支持完善,但 MaxCompute、StarRocks、Doris、Hologres 还是空白。把这套适配做扎实,就是中国版 dbt 的入场券。
另一层是 AI Agent 友好的合同 IDE。给 ODCS YAML 做可视化编辑器、breaking change 实时提示、自动生成 system prompt——这是把数据合同从"工程师内部工具"推到"产品经理也能看懂"的关键一步。这一步走通,整个采纳曲线才能起来。
结论
留给读者三个判断:
- ODCS v3.1 不是文档标准,是 cron 标准——合同的真正价值不在 YAML 写得多漂亮,而在它每天凌晨能不能在数据进生产表之前把脏数据拦下来。
- 落地最大的风险不是工具不成熟,是第一张表选错——选"重要但简单"的,3 周跑通一个完整案例,再扩规模。
- 国内基础设施层有真实空白:把 ODCS + 国产数仓 + Agent 友好 IDE 整合成产品,是下一代企业数据治理入口的卡位窗口。
执行上有一条已经被多个生产案例验证过的路径:写一份合同 → 接进 CI 三道防线 → 挂上凌晨调度 → 把它喂给 Agent。每一步都不超过 1 天工时,五天内能拿到第一个可上线的告警链路。
你团队凌晨 02:34 的那个告警,是合同发的,还是用户第二天发的?
参考资料
- Bitol. Open Data Contract Standard (ODCS) v3.1.0 Specification. Linux Foundation, 2025-12-08.
- Jean-Georges Perrin. ODCS v3.1.0 is Here: Relationships, Richer Metadata, and Stricter Validation. jgp.ai, 2025-12-11.
- datacontract-cli. ODCS Import / Export / Test. DeepWiki, 2026-01.
- Bitol Roadmap. ODPS, ODMS, OORS, OOCS Standards. bitol.io, 2026.
- ICE 系列前文:AI-Ready Assets:把 92% 的非结构化数据点亮 · Data Contracts:当 AI Agent 把脏数据的代价放大 10 倍