Databricks Summit 2026 复盘:智能体缺的不是智商,是上下文
现场实录 · 复盘分析 · Databricks Data + AI Summit 2026 Day-1 Keynote | 2026 年 6 月 | 约 16 分钟阅读
导语:两周内的第二场"智能体企业"宣言
2026 年 6 月 16 日上午,旧金山 Moscone Center South。Databricks 把它一年一度的 Data + AI Summit 开成了一场近三小时的 Day-1 Keynote——联合创始人兼 CEO Ali Ghodsi 开场,Reynold Xin、Patrick Wendell 等几位联合创始人轮番上阵,台上还请来了 OpenAI 总裁 Greg Brockman、Mastercard 与 PepsiCo 的数据负责人。
如果你看过本站两周前那篇 Snowflake Summit 2026 开幕 Keynote 精译,会有种强烈的既视感:又是"欢迎来到智能体企业",又是"你的数据才是护城河",又是一堆叫 Co-something 的智能体。两家数据平台巨头,在同一个六月,喊着几乎一样的口号。
但这届 Databricks Summit 真正值得拆开看的,不是口号的重合,而是它把口号落到了哪一层。Ghodsi 把全场定调成一句很锋利的话:
"AI doesn't have an intelligence problem, it has a context problem."
"AI 不是不够聪明,它是缺上下文。"
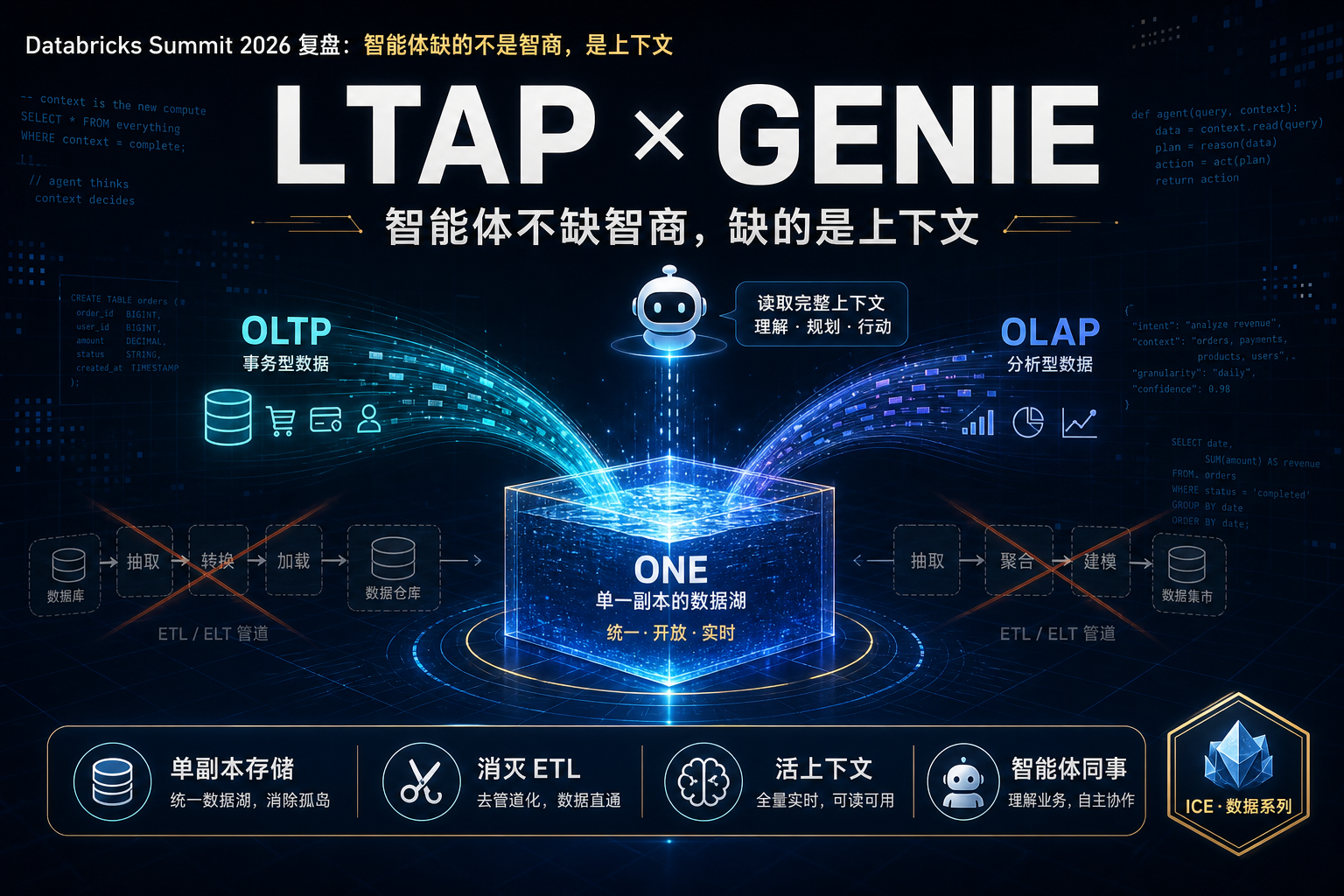
围绕这句判断,Databricks 这届甩出了两手棋:底层用一个新架构 LTAP 把数据底座重做了一遍,上层用 Genie Ontology + Genie One 给智能体补上"活的上下文"。本文按 Day-1 Keynote 的实际章节顺序,把这两手棋以及配套的实时引擎、治理网关、安全与营销动作逐一复盘,最后和 Snowflake 做一次"殊途同归"的对照。
先把这场 Keynote 的章节地图和发布清单放在这里(时间为官方录像的大致时间戳):
| 时间 | 章节 | 一句话 |
|---|---|---|
| 7:59 | Is AGI here today? | 用"AGI 是否已来"破题 |
| 10:12 | AI 的"上下文问题" | 全场题眼:不缺智商,缺上下文 |
| 21:58 | The agentic data foundation | 面向智能体的数据底座 |
| 31:16 | Unity AI Gateway | 多模型治理与花费上限 |
| 38:50 | Genie Ontology | 给业务建一张"活的上下文图" |
| 43:16 | Genie One | 数据智能型 AI 同事,GA |
| 45:02 | Genie Agents / App Builder | 可复用智能体 + vibe coding 造应用 |
| 54:09 | Lakewatch + 收购 Panther | 安全湖仓与 AI SOC |
| 57:05 | CustomerLake | 建在湖仓上的智能体 CDP |
| 1:57:37 | Reyden 引擎 / Lakehouse//RT | 实时性能突破 |
| 2:47:45 | LTAP | 把事务与分析统一在一份存储上 |
整届最重的两个产品级动作,一个排在最前(Genie 系列),一个压在最后(LTAP)——一头一尾,正好对应"上层补上下文、底层重做架构"这两手棋。
一、定调:智能体不缺智商,缺的是上下文
Ghodsi 开场没有从产品讲起,而是先抛了个略带挑衅的问题——"AGI 是否已经来了?"然后顺势把话锋拐到企业现实:模型已经足够聪明,可大多数企业的 AI 还是不好用。 为什么?因为它在"瞎猜"。
他在 Genie One 的发布稿里把这事说得更直白:
"Most enterprise AI today is just guessing with false confidence. That is not good enough for business. If you're a CFO and AI can't tell you why margins changed, or you're a sales leader, and it can't find your next upsell, that's not an AI problem, that's a context problem."
"今天大多数企业 AI 只是在'自信地瞎猜'。这对业务来说远远不够。如果你是 CFO,AI 答不出毛利率为什么变了;你是销售负责人,它找不到下一个增购机会——那不是 AI 的问题,是上下文的问题。"
这套论证的支点,是一个很多人都忽略的对比:为什么软件工程是第一个被 AI 大规模改造的领域? Databricks 给的答案是——因为工程师需要的上下文,恰好集中在一个地方:源代码。它完整、结构化、机器易读,Agent 一读就懂。可企业里其余 90% 的工作不是这样:上下文散落在数据库、文档、工单、聊天、会议纪要里,还有很多只存在于某个老员工的脑子里。上下文一旦残缺,模型就用"猜"来补,而在财务、运营、销售场景里,一个自信的错误答案,往往比"我不知道"更糟。
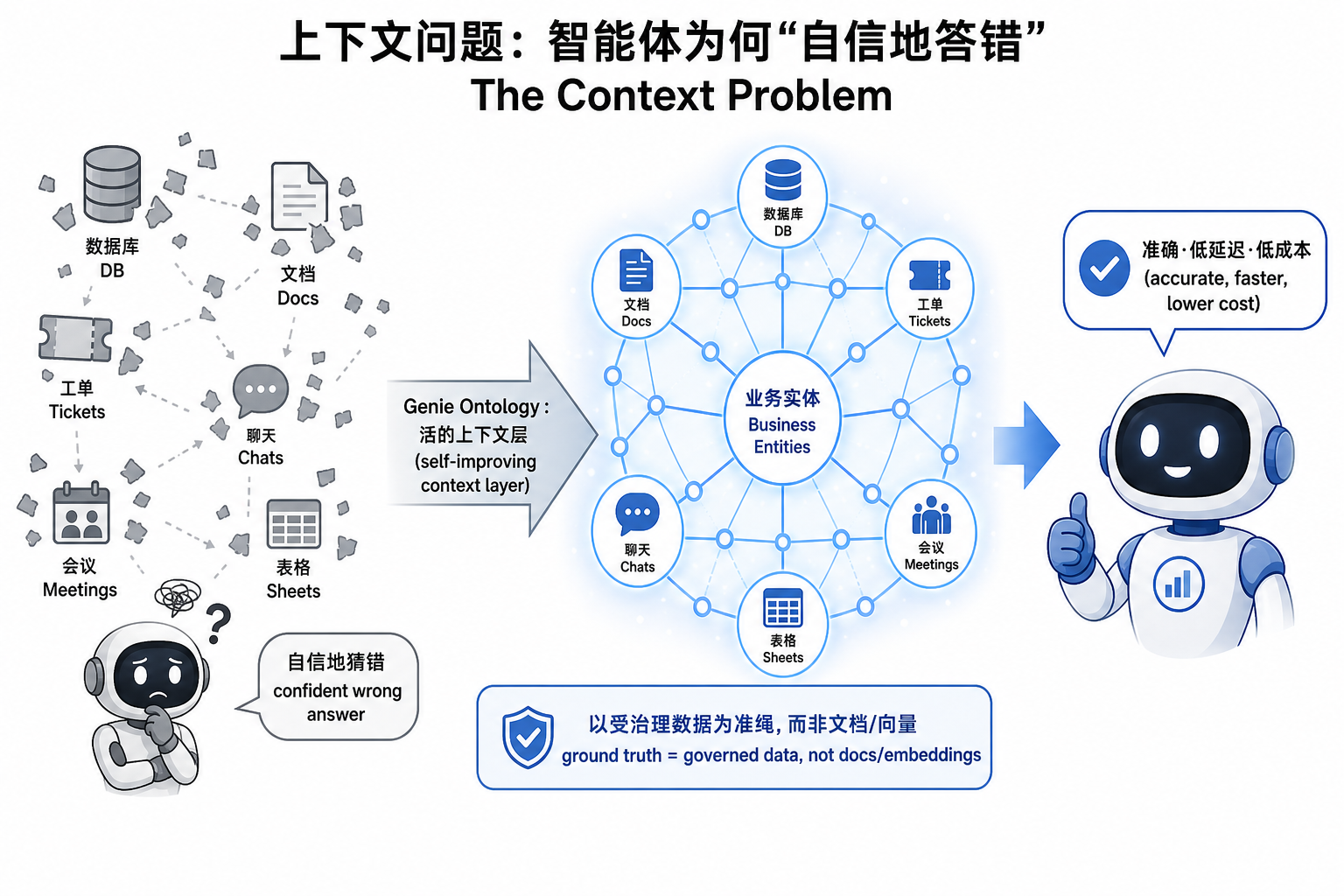 ▲ 左边是散落、彼此孤立的企业上下文,智能体只能自信地猜错;中间靠 Genie Ontology 把碎片连成一张活的上下文图,并以"受治理数据"而非文档/向量为准绳;右边才是能给出准确答案的智能体同事
▲ 左边是散落、彼此孤立的企业上下文,智能体只能自信地猜错;中间靠 Genie Ontology 把碎片连成一张活的上下文图,并以"受治理数据"而非文档/向量为准绳;右边才是能给出准确答案的智能体同事
把"AI 不好用"重新定义成"上下文不到位",这一步定调很关键:它直接决定了 Databricks 这届所有发布的指向——不是去训一个更聪明的模型,而是把企业数据和上下文重做成"智能体能直接读、能信、能据此行动"的样子。 两手棋由此展开。
二、底层那一手:LTAP,把 ETL 连根拔起
压轴出场的 LTAP(Lake Transactional/Analytical Processing,湖上事务/分析处理),是这届技术含量最高、也最该被数据工程师重视的一个动作。它要解决的,是一个已经困扰行业四十年的老问题。
过去几十年,事务型负载(OLTP,应用在用的操作型数据库)和分析型负载(OLAP,数仓里跑的分析)一直活在两套独立系统里。要把两边对上,就得搭 CDC(变更数据捕获)管道,把操作库的数据一刻不停地搬进分析库。这套做法在"人类按人类速度写软件"的年代还能忍,但 Ghodsi 的判断是——智能体时代,这套架构彻底不够用了:
"For decades, complicated data infrastructure was a tax that teams were forced to pay. Then agents arrived. In a matter of months, organizations effectively doubled their workforce, just not with humans. Agents write code, make calls, and run loops at a pace human teams never could. The infrastructure that powered the last era of computing is now the bottleneck that no one can afford. LTAP removes it."
"几十年来,复杂的数据基础设施是团队被迫缴的一笔'税'。然后智能体来了。短短几个月,组织等于把员工数量翻了一倍——只不过翻出来的不是人。智能体写代码、发调用、跑循环,速度是人类团队永远做不到的。那个支撑上一个计算时代的基础设施,如今成了谁都付不起的瓶颈。LTAP 把它拿掉。"
Databricks 产品负责人 Brian Clark 把痛点讲得很具体:当 Agent 把开发速度拉快之后,schema 在变、管道在断,而且断得比以前更快——因为数据要在操作库、湖仓、ML 系统之间来回搬,每多一条链路就多一个会崩的点。他们给出的目标很激进:"默认模式就不需要管道"(default patterns that don't require pipelines)。
那 LTAP 到底新在哪?关键要和它的两个前辈划清界限——这也是理解这次发布的核心:
| 方案 | 思路 | 留下的问题 |
|---|---|---|
| HTAP | 把事务和分析塞进同一个引擎 | 牺牲了负载隔离,两边性能都被拖累,还锁进一套昂贵的专有系统 |
| Zero ETL | 把 CDC 管道藏起来,让你看不见 | 管道还在,底层架构问题原封不动 |
| LTAP | 在存储层统一:一份数据,两类引擎各取所需 | —— 不合并引擎、不藏管道,而是干掉"搬运"本身 |
LTAP 的做法是:所有操作型、分析型、流式数据都以开放格式(Delta、Iceberg)落在同一份开放对象存储上,由 Unity Catalog 用单一的身份、权限、审计模型统一治理;事务负载在标准 Postgres 里跑、保留完整 ACID,分析负载在整个湖仓上跑、任意规模与并发,两者各自独立伸缩,但读的是同一份数据,中间没有任何同步管道、副本或连接器。
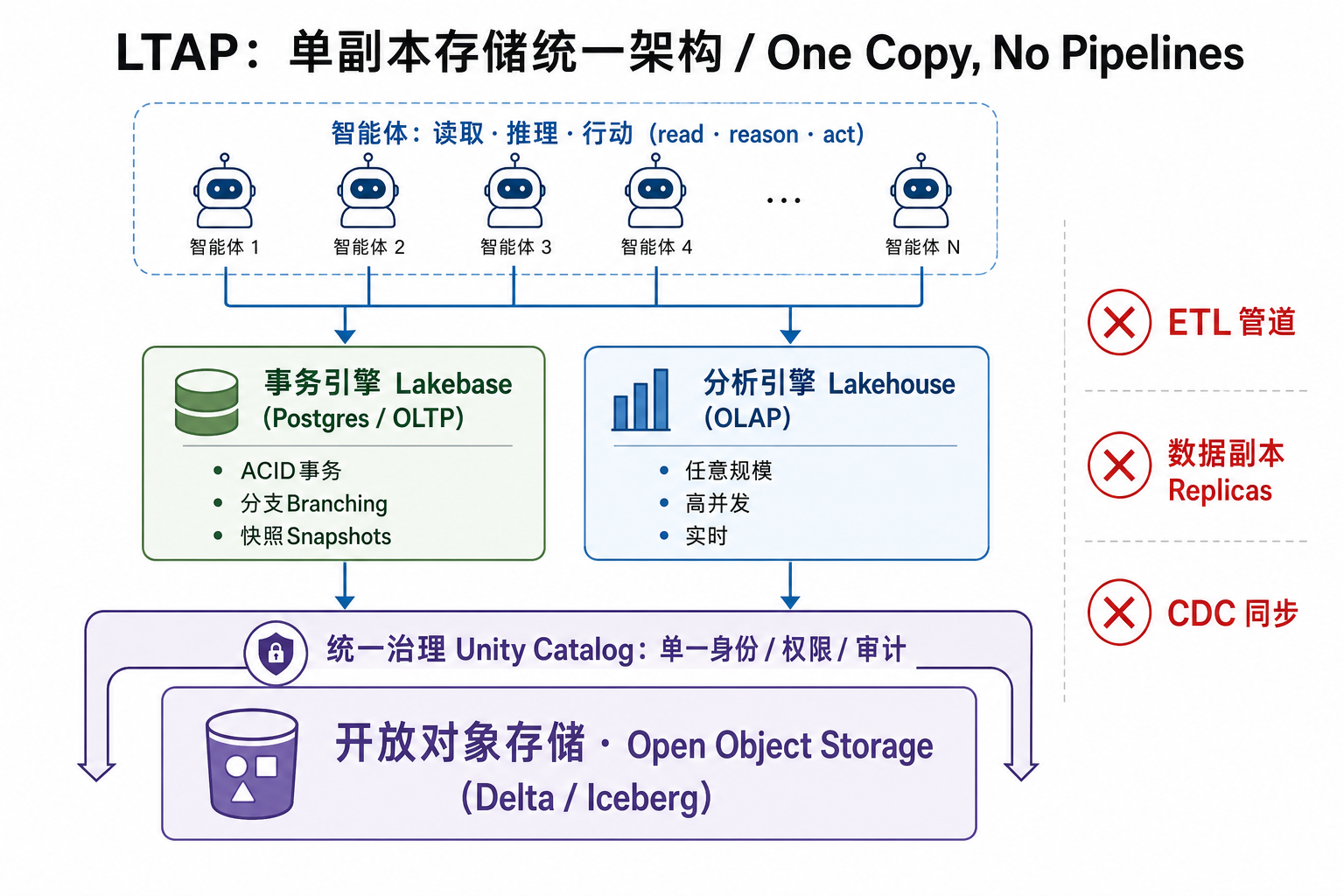 ▲ LTAP 的三条性质:单一治理与单一事实源、对任意负载都不牺牲性能、彻底没有 ETL 管道(连藏起来的也没有)。事务引擎 Lakebase 与分析引擎 Lakehouse 直接读写同一份存储
▲ LTAP 的三条性质:单一治理与单一事实源、对任意负载都不牺牲性能、彻底没有 ETL 管道(连藏起来的也没有)。事务引擎 Lakebase 与分析引擎 Lakehouse 直接读写同一份存储
撑起这套架构的地基,是去年才发布的 Lakebase——一个把 Postgres 事务能力搬到对象存储上的 Serverless Postgres,因为存算分离,它能用很低的成本同时跑成千上万个应用和 Agent。一组数字能说明它已经不是 PPT 产品:Lakebase 上线一年,已服务数千客户(Block、Superhuman、Zillow 等),每天处理 1200 万次数据库启动(database launches)。 这届还给它加了三件直接服务于 Agent 的能力:
- 跨云、跨区域容灾——当 Agent 开始扛关键业务,韧性变成刚需。Clark 还提到一个意外用法:有客户想用它"把数据库搬到 GPU 便宜的云上去",因为哪片云的 GPU 便宜且可用是会变的。
- Git 式分支与快照——可以对生产库瞬间拉一个"完整副本"的分支,在隔离环境里安全试验。Clark 一句话点破了它为什么对 Agent 友好:"Agents love branching, because it's essentially an isolated environment(智能体偏爱分支,因为那本质上就是个隔离环境)。" Agent 可以在分支上随便试错、复现 bug,而不碰生产。
- 自治数据库运维——让 Agent 自己监控健康度、发现变慢、建议索引、协助恢复。
把 LTAP 这手棋翻译成数据工程师听得懂的话:它在赌"未来主要的数据消费者不是人,而是 Agent",而 Agent 需要的是"读一份、就地推理、就地行动",受不了你在它面前架一堆会断的管道。 这是一个架构层面的豪赌,赌注是整个企业数据底座的重做。
三、上层那一手:Genie Ontology + Genie One,给智能体喂"活的上下文"
如果说 LTAP 是把"数据能不能被一份地读到"解决掉,那 Genie 这条线,解决的是"读到了,Agent 懂不懂这是什么业务含义"。这正是开篇"上下文问题"的正面回答。
这一手的地基叫 Genie Ontology——Databricks 把它描述成一张"组织里所有知识织成的网":数据、文档、标签、内容、应用、人,全连进来。它是一个会自我改进的上下文层,自动从 Databricks 内部以及 50+ 连接的工作应用(Google Drive、Jira、Slack、Confluence、SharePoint 等)里持续抽取并更新业务知识。它最关键的一个设计选择是:以"受治理的数据"作为 ground truth,而不是文档或 embedding。 换句话说,Genie 回答问题时不是去一堆文档碎片里做 RAG 式的"语义联想",而是通过 SQL 到那张权威的、被治理的数据里查出真实答案——所以它能解释"毛利率为什么变了"、能在销售管道里翻出增购机会,因为它用的就是业务实际运转所依赖的那份数据。
地基之上,是一整套"Genie 全家桶"。它们对应着从业务用户到数据工程师的不同人群:
- Genie One——面向所有业务团队的"数据智能型 AI 同事",已 GA,提供 Web、iOS、Android 三端。它不只是回答问题,还能产出文档、报告、图表,设告警、排任务、沉淀可复用的"技能",并通过 MCP 在别处采取行动。定价也很有攻击性:没有按席位收费,每个用户每月送最多 10 美元额度,只为真正用掉的 AI 付费。
- Genie Agents——把任意一段 Genie 对话存成可复用的 Agent,它会继承这段对话的记忆、数据源、指令和行为,团队成员可以"点名"调用,把可信的工作流在组织里复制。
- Genie App Builder——一个面向企业的托管式 vibe coding 环境:上传业务上下文,它生成可运行的应用预览,且从第一天起就受 Unity Catalog 的权限与成本管控。
- Genie Code——面向数据团队的自治 Agent,帮你规划、构建、运行数据工程 / ML / 分析工作流。
- Genie ZeroOps——一个常驻后台的 Agent,自主监控、排查并提出修复建议,对象是管道、作业、表、ML 模型等数据与 AI 资产,相当于把运维"上自动驾驶"。
Keynote 上还闪过两个更"前瞻"的名字:Omnigent(被称为"AI 智能体的元 harness(meta-harness)",即编排一群 Agent 的更上层结构)和 "agent system of record"(智能体的记录系统)——后者透露出 Databricks 对未来软件栈的想象:当 Agent 成为主要的工作执行者,企业需要一个新的"系统记录"来沉淀它们的行为与状态。
客户背书也不含糊。Foot Locker 用 Genie Agents 给高管和业务团队搭了一个统一的洞察入口;Albertsons 用 Genie + 湖仓做"商品智能",让买手用自然语言探索复杂的商品数据;Uplight 则把它当成"数据民主化"的引擎。这些案例的共同点是:让不懂 SQL 的业务人,直接对着受治理的数据提问并据此行动。
这一手和上一手是咬合的:Genie Ontology 要回答得准,前提是底下有一份干净、统一、被治理的数据——而那正是 LTAP 想交付的东西。 上层的"上下文",长在底层的"单副本架构"之上。
四、配套棋子:实时引擎、治理网关、安全与营销
两手主棋之外,这届还有几枚配套棋子,凑齐了"智能体企业"的拼图。
实时引擎 Reyden 与 Lakehouse//RT。 智能体要"就地行动",就受不了分析查询慢吞吞。Databricks 发布了向量化的新引擎 Reyden,并基于它推出 Lakehouse//RT,号称在湖仓上直接做到亚秒级、毫秒级的高并发响应。客户 PointClickCare 给的数字是:在其医疗数据集上,平均比原有数仓快三分之一,查询快 10 倍,而且省掉了原本要单独再上一套实时系统的打算。这块补的是"实时性"这条历来被认为是湖仓短板的腿。
Unity AI Gateway:多模型治理 + 花费上限。 当企业同时接入多个模型,治理和成本就成了大问题。Unity AI Gateway 把它做成 Unity Catalog 里的一个中心化运行时注册表,提供实时的速率限制、内容过滤和硬性花费上限(hard spend caps),保证"tokenomics(token 经济学)"可预测。值得一提的是,这种"开放接入多模型"的姿态在本届很明确——除了台上请来 OpenAI 总裁 Greg Brockman 站台,xAI 的 Grok 模型也已原生上架 Agent Bricks。这与 Snowflake "随时换模型、不锁死"的开放叙事如出一辙。
安全湖仓:收购 Panther + Lakewatch。 Databricks 宣布收购 AI SOC 平台 Panther,并发布建在"安全湖仓"上的智能体 SIEM Lakewatch,把安全运营也纳入同一套数据与治理底座,开辟"security lakehouse"这个新品类。
CustomerLake:建在湖仓上的智能体 CDP。 这是 Databricks 头一回正面踏进营销(MarTech)地盘——一个直接长在湖仓里的"智能体客户数据平台",用 Profile Agents 把碎片数据拼成 Customer 360 画像,用 Campaign Agents 做分群、推荐下一步动作、跨渠道触达。它的卖点是"数据、模型、治理都已经在这里了,CDP 不必再单独搬一份数据出去",被外界解读为对独立 CDP 市场的一次正面冲击。
把这几枚棋子串起来看,逻辑是一致的:凡是过去要"把数据搬出去再单独建一套系统"的场景(实时、安全、营销),Databricks 都想把它收回到同一份湖仓数据 + 同一套 Unity Catalog 治理之上。 这和 LTAP "消灭搬运"的主张,是同一个哲学的不同侧面。
五、和 Snowflake 殊途同归?两套打法的对照
把这届 Databricks 和两周前的 Snowflake 摆在一起看,最有意思的发现是:两家在'诊断'上高度一致,在'药方'上各走各路。
诊断都指向同一句话——瓶颈不在模型智商,而在数据/上下文。 Snowflake 的说法是"模型是大路货,你的数据才是护城河";Databricks 的说法是"AI 不缺智商,缺上下文"。一个硬币的两面。
但落到怎么解,两家的发力层完全不同:
| 维度 | Snowflake Summit(6/1) | Databricks Summit(6/16) |
|---|---|---|
| 核心叙事 | 欢迎来到"智能体企业" | AI 缺的是上下文,不是智商 |
| 主攻层 | 自上而下:智能体控制平面 | 自下而上:重做数据底座架构 |
| 旗舰动作 | CoWork / CoCo(控制平面)、Horizon Context(语义治理)、Datastream | LTAP / Lakebase(架构)、Genie Ontology + Genie One(上下文) |
| 对"上下文"的解法 | Horizon Context 语义层,统一口径 | Genie Ontology 活的上下文图,以受治理数据为准绳 |
| 对"数据搬运"的态度 | 简化摄取(Datastream) | 干掉管道(LTAP 单副本) |
| 共同姿态 | 开放换模型、MCP 连一切、治理优先 | 开放接多模型(含 Grok)、Unity 治理、收购补全 |
一句话概括差异:Snowflake 更像是在数据平台之上加盖一层"指挥所"(控制平面),让 Agent 协同;Databricks 则索性下到地基,把"事务 + 分析"两套地基浇成一块,让 Agent 能在一份数据上直接读、推、做。 前者赌的是编排,后者赌的是架构。
当然,热闹背后也有冷静的声音。Keynote 直播弹幕里就有人犀利吐槽:"一边喊着'别被厂商锁定、拥抱开放格式',一边把一套专有锁轻轻扣到你整个数据栈上。" 这话不无道理:开放表格式(Delta/Iceberg)确实降低了存储层锁定,但 Lakebase、Genie、Agent Bricks 这些上层能力,本质上仍是把你更深地绑进一个"端到端集成生态"。开放与锁定的张力,在这届被产品力暂时盖过,但并没有消失。 这也是评估任何一家平台"智能体叙事"时该留的一份清醒。
六、对我们意味着什么(ICE 观察)
把发布会的热闹剥掉,这届 Summit 对不同人有不同的信号。
🔧 技术视角:数据工程师该重新想想"管道"这件事。 LTAP 最直接的潜台词,是"ETL / CDC 管道"这个数据工程的核心工种正在被重新定义。如果"单副本、无管道"真能在生产里成立,那大量"搬数据、对账、修断裂管道"的工作会被压缩;与此同时,配合 Genie Code / ZeroOps / Lakeflow 的"agentic data engineering(智能体化数据工程)",工程师的角色会从"手写管道"上移到"定义契约、设治理、给 Agent 当 reviewer"。值得追问的是:这套"无管道"在你自己的负载下到底有没有隐藏代价(强一致、跨区域延迟、成本),别只信发布会的理想曲线。
🏢 落地视角:"自信地答错"是真问题,但解药是工程而非魔法。 Ghodsi 把"上下文问题"摆上台面,戳中了无数企业 AI 试点失败的真实原因——不是模型不行,是它读不到、读不准企业自己的数据与口径。但要注意:Genie Ontology 这类"活的上下文层"能不能成,取决于你底下的数据治理是否扎实。上下文是被治理的数据'长'出来的,不是一个开关。 没有干净的数据底座,再花哨的 Ontology 也只是把"自信地答错"包装得更漂亮。
🇨🇳 本土视角:湖仓一体与"一份数据多引擎"并不陌生。 LTAP 的"单副本 + 多引擎 + 统一治理",对国内做湖仓一体、数据中台的团队来说是熟悉的方向——只是 Databricks 把它推到了"连 OLTP 也收进来、连管道都不要"的更激进位置。结合信通院刚发布的《2026 智能体十大关键词》,"上下文""数据底座""智能体编排"正在成为产业共识词;国内云厂商与数据平台大概率会在接下来给出自己的"LTAP 式"回应。对采购方而言,与其追新词,不如拿"我的 Agent 能不能在一份受治理的数据上直接读、推、做"这把尺子去量每一家。
结论
如果这届 Summit 只让你记三件事:
- 诊断已成共识:制约企业 AI 的不是模型智商,而是上下文与数据底座——Databricks 和 Snowflake 在这点上完全一致。
- Databricks 的解法是"两手棋":底层用 LTAP(基于 Lakebase)把 OLTP+OLAP 收进一份存储、连根拔掉 ETL 管道;上层用 Genie Ontology + Genie One 给智能体喂"以受治理数据为准绳"的活上下文。两手咬合:上层的准,依赖底层的统一。
- 它是一次架构层的豪赌:赌"未来主要的数据消费者是 Agent,而 Agent 受不了会断的管道"。赌对了,数据工程的形态会变;赌的过程里,"开放 vs 锁定"的老张力依然没消失。
最后留个问题给你:当 Databricks 说"消灭管道"、Snowflake 说"数据是护城河",你的组织真正缺的,到底是一套更聪明的智能体,还是一份'所有人和所有 Agent 都认、都对得齐口径、且能被直接读写的数据'? 想清楚这个,你才知道这两场 Summit 的喧嚣,对你是机会还是噪音。
参考资料
- Databricks, "Databricks Launches LTAP: The First Lake Transactional/Analytical Processing Architecture", 2026-06-16, https://www.databricks.com/company/newsroom/press-releases/databricks-launches-ltap-first-lake-transactionalanalytical
- Databricks, "Databricks Launches Genie One: All-New Agentic Coworker for Every Team", 2026-06-16, https://www.databricks.com/company/newsroom/press-releases/databricks-launches-genie-one-all-new-agentic-coworker-every-team
- BigDATAwire(Ali Azhar), "AI Is Breaking Traditional Data Architectures. Databricks Thinks LTAP Is the Fix", 2026-06-17, https://www.hpcwire.com/bigdatawire/2026/06/17/ai-is-breaking-traditional-data-architectures-databricks-thinks-ltap-is-the-fix/
- BigDATAwire, "Ali Ghodsi's Keynote: AI Doesn't Have an Intelligence Problem, It Has a Context Problem", 2026-06-16, https://www.hpcwire.com/bigdatawire/2026/06/16/ali-ghodsis-keynote-ai-doesnt-have-an-intelligence-problem-it-has-a-context-problem/
- Databricks, "Unifying Data and Governance in the Agentic Era: What's New with Azure Databricks", 2026-06-16, https://www.databricks.com/blog/unifying-data-and-governance-agentic-era-whats-new-azure-databricks
- Databricks(YouTube), "Data + AI Summit Keynote 2026 | Day 1"(含完整章节时间戳与讲者名单), 2026-06-16, https://www.youtube.com/watch?v=Qux8E-L1mk8
- ICE's Tech Stack, "Snowflake Summit 2026 开幕 Keynote 精译:欢迎来到'智能体企业'", 2026-06-04, /posts/2026/06/260604-snowflake-summit26-opening-keynote