数据即智力:数字化下半场的内核重写
产业洞察 · 数据要素 × AI 原生 × 范式转移 | 2026 年 5 月 | 约 10 分钟阅读

引子:一句话击中的内核
"数据即智力"——这个说法很难归功于某一个人,它更像是 2026 年这个时间节点上,行业里不同角色几乎同时摸到的同一块石头。
传统认知里,数据是死的:
数据是被动的资产,需要通过人的解读才能变成知识,再通过人的判断才能变成决策。
但 AI 原生时代的真实情况是——数据正在反过来"解读"自己。它喂进模型、模型吐出能力、能力又生成新的数据,新的数据再回喂模型。数据不再是被处理的客体,而是 具备推理能力的智力实体。
如果这件事成立,整个数据工程、数据治理、数据资产的逻辑都要被重写。这篇文章只做一件事:把"数据即智力"这句话拆成 可被讨论、可被验证、可被落地 的三个命题。
一、数据价值的四次跃迁
要理解"数据即智力"为什么是今天才出现,先看一眼数据角色在过去三十年的爬升轨迹。
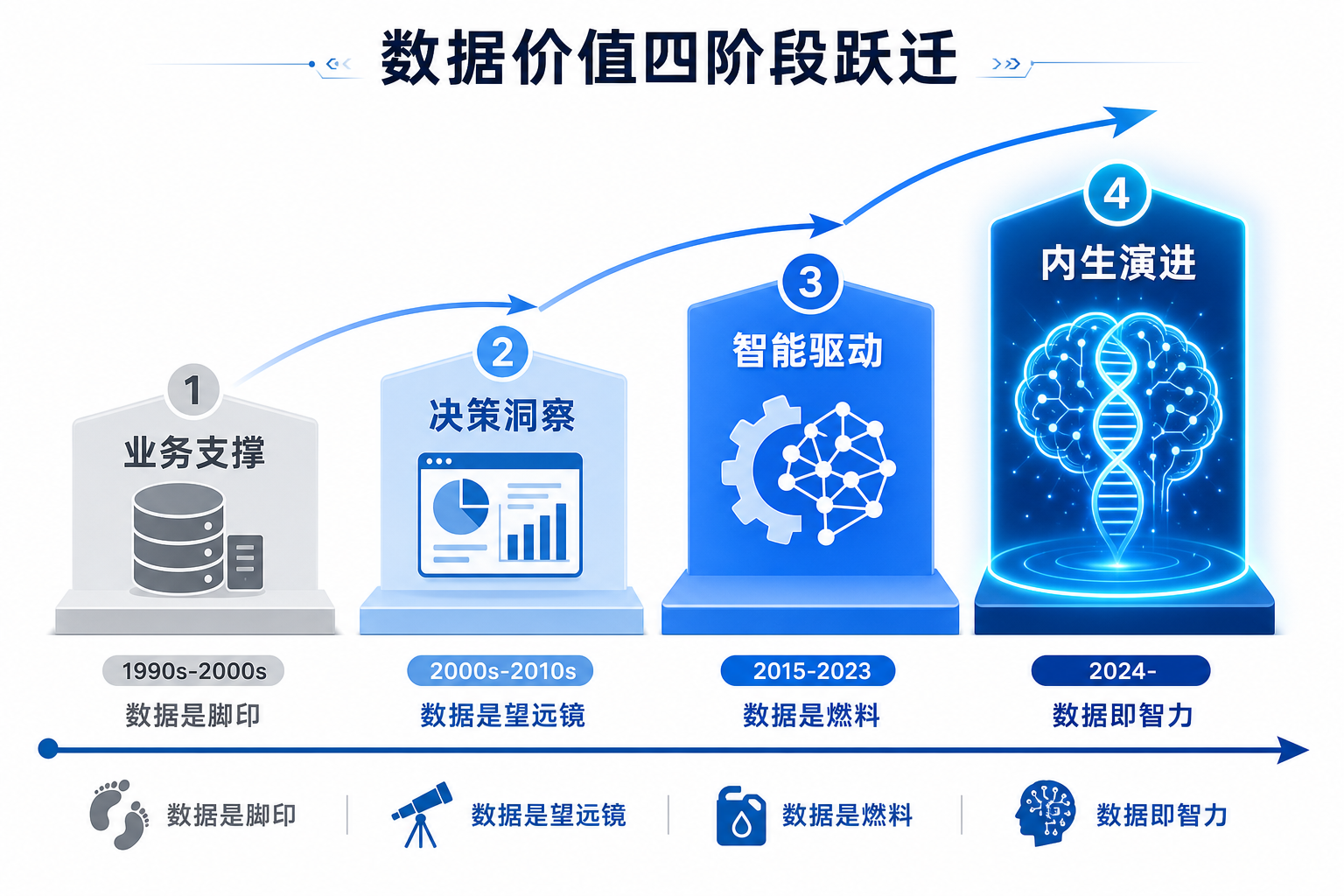
| 阶段 | 时代 | 数据的角色 | 价值兑现方式 |
|---|---|---|---|
| 业务支撑 | 1990s—2000s | 业务的"留痕" | 让业务系统能跑通 |
| 决策洞察 | 2000s—2010s | 决策的"望远镜" | 让管理者看见趋势 |
| 智能驱动 | 2015—2023 | AI 的"燃料" | 让算法做出预测 |
| 内生演进 | 2024— | 智力的"载体" | 让系统自己学习、自己演化 |
前三个阶段,数据始终是 被动的:被记录、被分析、被喂进模型。它的价值需要通过外部(人、BI、算法)才能兑现。
第四个阶段开始变了。大模型把数据 直接溶进了权重;Agent 在运行中产生的反馈数据被实时回吸;数据自带元数据、契约、权限,走到哪里规则就跟到哪里。
业务支撑阶段,数据 支撑业务;决策洞察阶段,数据 服务管理;智能驱动阶段,数据 驱动算法;内生演进阶段,数据就是智力。
这是"数据即智力"的产业语境。下面把它拆成三个命题。
二、命题一:密度决定深度
智力不再是算法的专利,而是隐藏在数据的逻辑密度里。
同样是 1B 参数的模型,喂给它地摊文学,和喂给它哈佛法学院的教材,最终表现出的"智力"完全不在一个层级。这个直觉在 2024—2026 年被反复验证:
- 小模型阵营 反复证明:"小参数 + 高质量数据" 可以打败 "大参数 + 通用语料";
- LLM4OR 等垂直能力研究 明确表明,决定模型天花板的不是规模,而是数据中的逻辑因果密度;
- 业内反复强调:最贵的不是算力,是高质量数据。
一句话——数据质量就是智力等级。
这对企业意味着,数据工程的 KPI 要换,从"把数据搬进来"变成 "把数据的信息熵搬上去":
| 旧的数据工程目标 | 新的数据工程目标 |
|---|---|
| 数据完整性(行数、字段、覆盖率) | 信息熵密度(每比特数据能贡献多少推理价值) |
| 数据准确性(无错误、无重复) | 逻辑因果性(是否包含可被推理利用的因果链条) |
| 数据时效性(实时、准实时) | 语义稳定性(同一概念在不同时间是否一致表达) |
| 数据可用性(接口、权限) | 可学习性(是否便于被模型吸收为能力) |
剔除业务噪音、提炼出 具有逻辑因果关系的"高智力数据"——这件事过去叫"数据治理",今天可以叫 "智力数据工程"。
三、命题二:共振实现自生
智力不是静态的存储,而是数据与模型在闭环中的持续进化。
命题一讲的是"静态质量"。但智力真正不可复制的部分,恰恰在动态的 模型-数据共振(Model-Data Resonance) 上:
高质量数据 → 训练 / 微调 → 更强模型
↑ ↓
└───── 反馈数据 ←────── Agent 执行任务 ─────┘当 AI Agent 在真实业务里执行任务时——读邮件、写代码、跑流程、答客服——它产生的 反馈数据(成功率、用户修正、纠错轨迹、人工审批)被重新吸收,数据就从"过往记录"变成了"学习经验",模型也从"训练完即锁死"变成了"边跑边长"。
《Agentic Data Engineering》 里讨论过的 ADE 架构,本质上就是为这层"共振"准备的基础设施:
| 旧范式 | 新范式 |
|---|---|
| 数据是 训练前 的输入 | 数据是 训练 / 推理 / 反馈中 持续流动的载体 |
| 模型一次训练,长期使用 | 模型在数据共振中 持续微调、持续演化 |
| Agent 是数据的消费者 | Agent 既是消费者,也是生产者 |
| "数据驱动 AI" | "AI 也在驱动数据" |
静态数据决定智力的"起点",动态共振决定智力的"上限"。
《AI 生产悖论》 里讲到 74% 的企业 AI 代理上线后被迫回滚——回滚的真正原因之一,就是企业没有跑通这个共振闭环:模型一旦放进真实业务,立刻和数据脱节、和反馈脱节、和场景脱节。
没有共振,就只有"一次性智力";有了共振,才有"持续生长的智力"。
四、命题三:封装决定边界
数据本身带有逻辑约束,它是带着"说明书"的智力块。
前两个命题在讲"智力怎么来"。第三个命题讲一个被严重低估的问题——智力怎么不失控。
过去的数据是"裸数据":一个 CSV、一张表、一个 JSON。它没有自带任何关于"能被谁用、被怎么用、用了之后该承担什么后果"的信息,规则全部依赖外部系统维护。
但 AI 原生时代的数据必须 自带说明书。原因很简单:
- 数据喂进模型后,溶进了权重,找不回来;
- Agent 跨系统调用数据时,控制权一旦失去就再难夺回;
- 一份数据可能被几十个 Agent、几百个 MCP Tool 消费——没有自描述的契约,根本无法做边界管理。
这就是 MCP(Model Context Protocol) 在 2025—2026 年迅速成为事实标准的深层原因:它本质上是给数据和工具加上一层"说明书",让智力的契约跟着数据走。
| 维度 | 裸数据时代 | 封装数据时代 |
|---|---|---|
| 使用权限 | 外部 ACL 控制 | 权限嵌入数据本身(签名、凭证、时效令牌) |
| 使用规则 | 外部合同约定 | 逻辑约束随数据传播(字段不可下推、计算不可越界) |
| 可追溯性 | 靠日志事后审计 | 每一次消费自动留痕(数据溯源、Membership Inference) |
| 失控风险 | 数据复制即失控 | 数据走到哪儿,契约跟到哪儿 |
就像基因里封装了进化逻辑,未来的数据将自带元数据、权限、合规、契约——数据走到哪里,智力的边界就跟到哪里。
工程上至少有三个抓手:
- AI Guardrails(护栏)——拆解过 这件事,护栏不是限制能力,而是兜住边界;
- Trusted Data Service(可信数据服务)——参考 《告别"物理占有欲"》 里的"可用不可见"思路,使用规则始终随数据本身传播;
- MCP 与数据契约——让协作走标准化协议,权限、Schema、版本、配额嵌在协议里,而不是写死在集成代码中。
这三件事拼起来,本质上是给"智力"装上了边界系统——既不让能力被滥用,也不让能力被泄漏,更不让能力溢出失控。
五、三命题合一:智力的三维度
把三个命题画在一张图上:
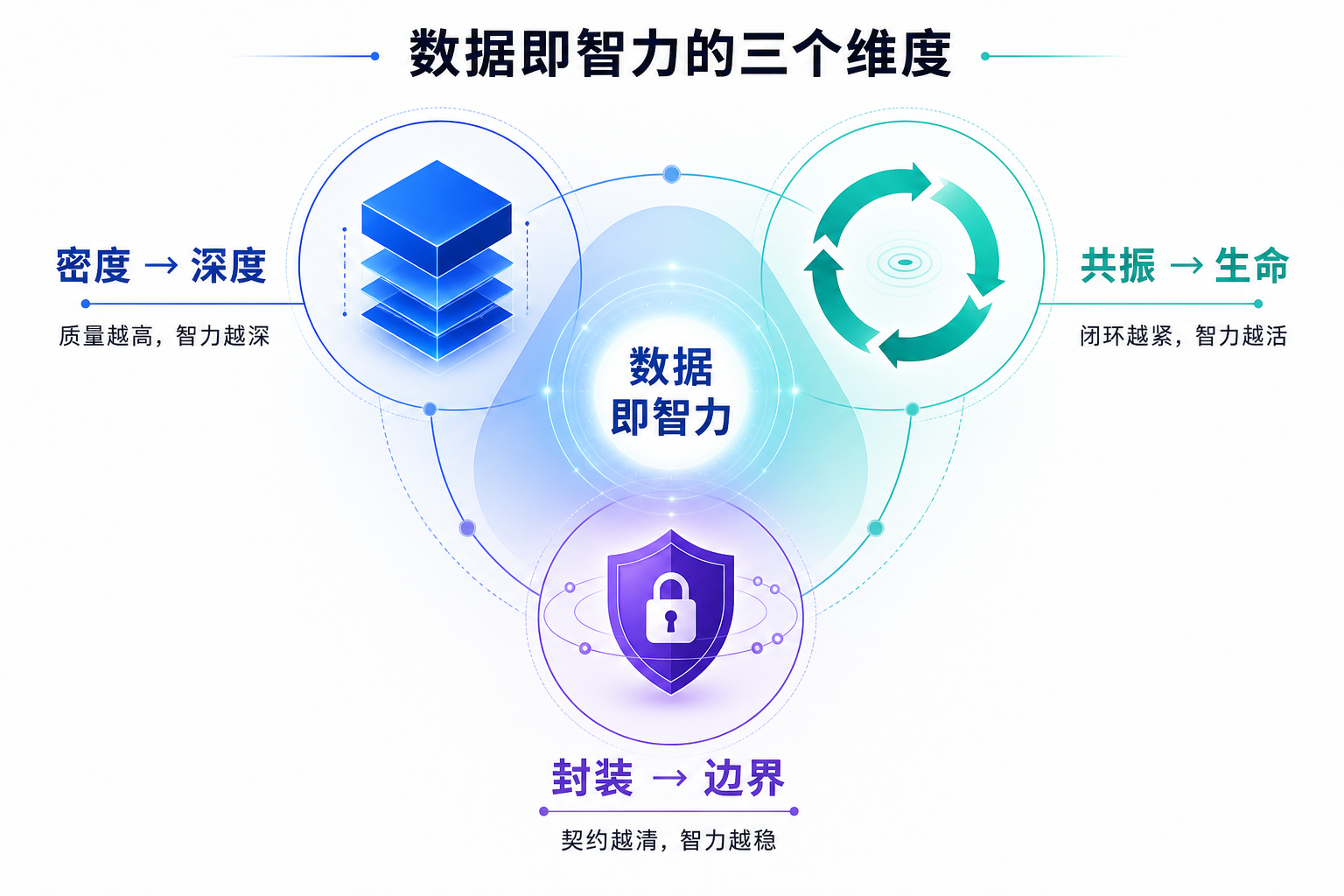
- 密度 决定智力的 深度:质量越高,智力越深;
- 共振 决定智力的 生命:闭环越紧,智力越活;
- 封装 决定智力的 边界:契约越清,智力越稳。
三者缺一不可:
| 缺哪个 | 结果 | 现实里的尴尬 |
|---|---|---|
| 缺密度 | 智力浅薄——参数再大、闭环再紧,也只是"复读机" | 花大钱买数据,模型怎么训都达不到预期 |
| 缺共振 | 智力僵化——再好的初始数据,半年后就和真实业务脱节 | 花大钱训模型,上线即衰退 |
| 缺封装 | 智力失控——能力越强越危险,没人敢把核心场景交给它 | 花大钱做应用,但不敢上规模 |
三件事必须同时做,才能跑通"数据即智力"的完整链条。
六、对企业意味着什么?
把三命题翻译成可执行的判断,大概是这四条:
1. 数据治理的 KPI 要换。 从"数据量、覆盖率、准确率"转到"信息熵密度、逻辑因果密度、可学习性"。一份高密度数据的价值,可能抵一万份低密度数据。
2. 数据团队和 AI 团队要并岗。 不能再让数据团队只管"建仓、跑表、出报表",必须和 AI / Agent 团队深度共建反馈闭环。ADE 不是两个团队之间的接力,而是一个共同岗位。
3. 数据资产的估值要重写。 资产负债表上的"数据资产"今天大多按"行数 × 单价"估值;但在"数据即智力"语境下,真正值钱的是 "数据 × 反馈闭环 × 契约系统" 的三元组。光有数据,估值会被严重低估。
4. 制度层和工具层同步升级。 数据三权分置、数据产权登记、MCP 协议、AI 护栏、可信数据空间——这些在 《当知识溶进权重》 里讨论过的"制度层重构",本质上都是在为"数据即智力"准备基础设施。
写在最后:上半场看足迹,下半场看灵魂
回到最开始那句话:
在数字化上半场,数据是业务的"足迹";在智能化下半场,数据是机器的"灵魂"。
数据不再是被处理的客体,而是具备推理能力的智力实体。
这不只是一句修辞。它意味着——
- 过去 30 年,我们把数据当 原料:挖矿、加工、出库;
- 未来 30 年,我们要把数据当 生命:孕育、培养、传承。
原料和生命的差别在于:原料用完就没了,生命会自己生长。
如果"数据即智力"是真的(我倾向于认为它是真的),那当下做数字化转型的人,要回答的第一个问题就不再是 "我有多少数据",而是——
我的数据,在长成智力吗?
本文是产业观察笔记,不构成投资或决策建议。相关论述参见本站 《Agentic Data Engineering》、《小型语言模型 SLM》、《AI 生产悖论》、《AI 护栏》、《当知识溶进权重》、《告别物理占有欲》。欢迎讨论。