工业数据“采、汇、用”瓶颈:政策解码,难在‘用’

政策解码 | 2026 年 6 月 | 面向工业数据从业者、制造业数字化负责人、数据要素与工业 AI 关注者
摘要
新华社《瞭望》6 月 23 日刊出一篇政策解码——《突破工业数据采集用瓶颈》。背后是工信部今年 2 月印发的《关于启动工业数据筑基行动开展面向人工智能赋能的高质量行业数据集建设先行先试的通知》(工信厅信发函〔2026〕64 号),并已公布先行先试联合体名单。这份文件把工业数据的难题,精准地切成了三个字:采、汇、用。
政策原文把三段短板概括得很直白:采不全、集不拢、用不好。 但如果只是平均介绍这三段,就把这篇文件读浅了。本文想强调一个判断:采和汇是入场券,"用"才是终局——而且是三段里最难、最容易被低估、最考验真功夫的一环。
理由很简单:采集解决"有没有数据",汇集解决"数据通不通",这两件事砸钱、上设备、建平台,在工程上是有解的;而"用"解决的是"数据能不能变成钱、变成产线上的一个更优参数、变成一次提前预警"——它要求数据质量、领域知识、AI 能力、安全合规四者同时到位,任何一环掉链子,前面采集汇集的投入就全部沉没。
本文三步走:第一,快速过一遍"采、汇、用"三段瓶颈和政策给的"1+4+N"框架;第二,重点深挖"用不好"的三层病灶;第三,把工业数据"从静态资源到动态生产力"的路径,拆成一个可落地的应用阶梯。
一、政策在解一道老题:采、汇、用三段卡点
先把背景交代清楚。这次政策的逻辑起点,是一组"硬件底座已经不差"的事实:截至 2025 年末,我国重点工业企业关键工序数控化率达 68.6%,5G 全连接工厂建成超 8000 家。设备联网、产线数字化、园区智能化,把工业数据采集、汇聚、应用的硬件基础铺得相当扎实。
但"底座好"不等于"用得好"。政策直接点出三大短板——采不全、集不拢、用不好,并指出一个扎心的现状:大量工业数据处于"沉睡状态",存在数据孤岛、数据闲置、数据低效利用。
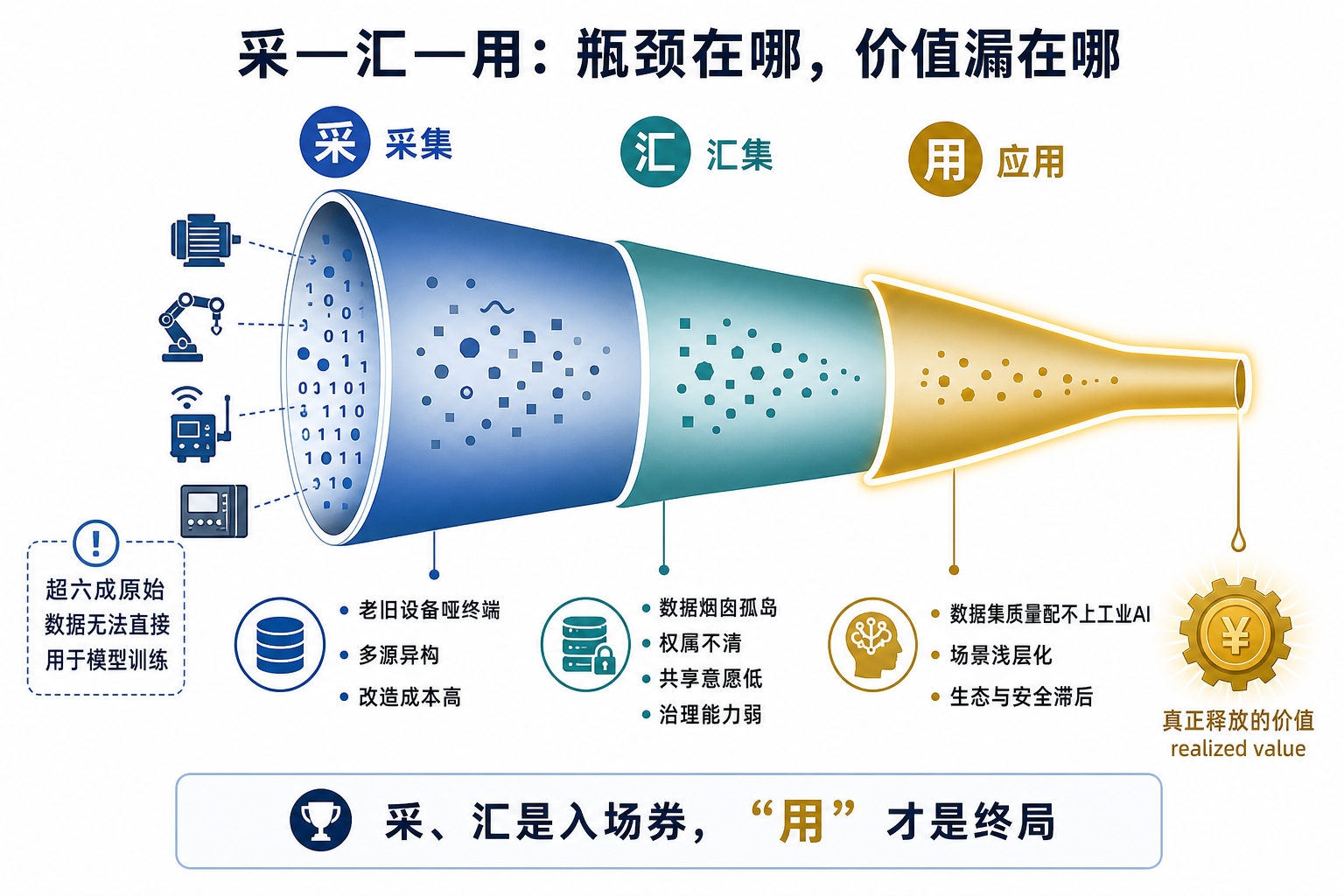
三段卡点各有各的难,可以先列个全景:
| 环节 | 主要卡点 | 政策抓手 |
|---|---|---|
| 采(采集) | 老旧设备"哑终端"多、高端装备协议封闭;多源异构无统一规范,超六成原始数据无法直接用于模型训练;单条产线改造动辄数十万元,中小企业意愿弱 | 标准筑基(采集字典/采样频率/精度分级)、设备联通(通用采集网关、开源协议转换)、降本赋能(纳入中小企业数字化补贴) |
| 汇(汇集) | 企业内系统烟囱割裂、口径各异;上下游因保密与竞争不愿共享;权属不清、价值评估空白、收益分配缺失;专业数据治理能力弱 | 联合体牵引、可信互联平台(脱敏/隐私计算/区块链存证,做到"可用不可见、可控可溯源")、确权与收益分配试点 |
| 用(应用) | 数据集质量配不上工业 AI;应用停在监控/报表浅层;标准与安全体系滞后 | 规模化建设高质量行业数据集、典型场景标杆应用、政策/技术/人才全维度保障 |
为了把这套打法系统化,通知设计了一个 "1+4+N" 体系:1 个重点行业数据可信互联平台,4 大资源库(行业数据资源库、数据技术攻关库、工业数据标准库、高质量行业数据集库),落地 N 个工业数据赋能行业大模型、工业智能体的应用场景。先行先试联合体覆盖钢铁、有色、汽车、化工、能源装备、人形机器人,以及中小企业数字化转型城市试点,目标是到 2026 年底跑出一套"可复制、可推广"的路径。
这套框架很完整。但请注意它的重心落点——四大资源库的终点是"高质量行业数据集库",而所有库的存在意义,都是为了最后那个 N 个应用场景。换句话说,采、汇、四大库都是手段,"用"才是目的。 接下来这篇就把笔墨重重压在"用"上。
二、采与汇是入场券,“用”才是终局
为什么说"用"是三段里最难的?因为采集和汇集的难,本质是工程难——难,但路径清楚:缺接口就上网关,协议封闭就做转换,烟囱割裂就建可信互联平台,权属不清就搞确权试点。这些事砸资源、定标准、建机制,时间到了就能见底。
"用"的难是另一种性质——它是价值难。同样一批已经采上来、也汇拢了的数据,能不能在产线上换出一个更优的工艺参数、提前一小时预警一次设备故障、把一次研发试错从三个月压到三周,取决于数据质量、领域知识、AI 能力、安全合规四者同时在线。少一样,数据就只是躺在库里的"资产负债表数字",不是生产力。
这就解释了政策里那句很重的话:大量工业数据处于"沉睡状态"。它们不是没被采、没被汇,而是被采上来、汇拢了,却没被用起来。 投入已经花了(传感器、网关、平台、治理),价值却没回收——这才是最贵的浪费。
有两个数字能把这种落差量化出来:
- 入口端:超六成原始工业数据无法直接用于模型训练。也就是说,哪怕你把数据都采上来了,六成以上在喂给 AI 之前还得返工。
- 出口端:多数企业的数据应用仍停留在设备监控、报表统计、简单能耗分析这类基础层面,在研发仿真、质量溯源、工艺参数优化、低碳排程、供应链智能协同等高阶场景的渗透率很低。
一进一出对照着看,结论很清楚:工业数据的价值,绝大部分漏在了"用"这一段。 前面采集、汇集做得再好,如果出口只接到"看个监控、出张报表",那这条链路的投入产出比一定难看。所以这次政策真正的胜负手,不在于又建了多少平台、汇了多少数据,而在于最后那滴"价值"能不能真的滴出来。
三、“用不好、用不深、用不久”的三层病灶
政策把"用"的短板拆成了三句话:用不好、用不深、用不久。这三句不是同义反复,而是三层递进的病灶——一层比一层更难治。
病灶一:数据集质量配不上工业 AI(用不好)
工业大模型、智能质检、工艺优化这类应用,对数据的完整性、标注精准度、工况覆盖度要求极高——比消费互联网数据苛刻得多。现实却是:样本不均衡、极端故障工况数据缺失、多模态融合不足。
这里藏着一个工业数据特有的、几乎无法用"多采点数据"来解决的死结:最有价值的数据,恰恰最稀缺。 一条产线绝大多数时间在正常运行,正常工况的数据多到溢出;可真正决定智能质检、故障预测成败的,是那些极端工况、罕见故障的样本——而这些样本天然就少,有些甚至"不敢实测"(你不能为了采数据故意把锅炉烧到爆)。结果就是政策点出的那个结构性矛盾:算法在等优质数据,数据又适配不了场景。
政策给的解法很对路:支持联合体用数字孪生、仿真建模、生成式 AI 去合成、扩充故障场景和极限工况的数据。换句话说,既然真实世界采不到,就用仿真和生成"造"出足量多元的样本——这是工业 AI 区别于互联网 AI 的一条关键技术路线。
病灶二:应用场景浅层化(用不深)
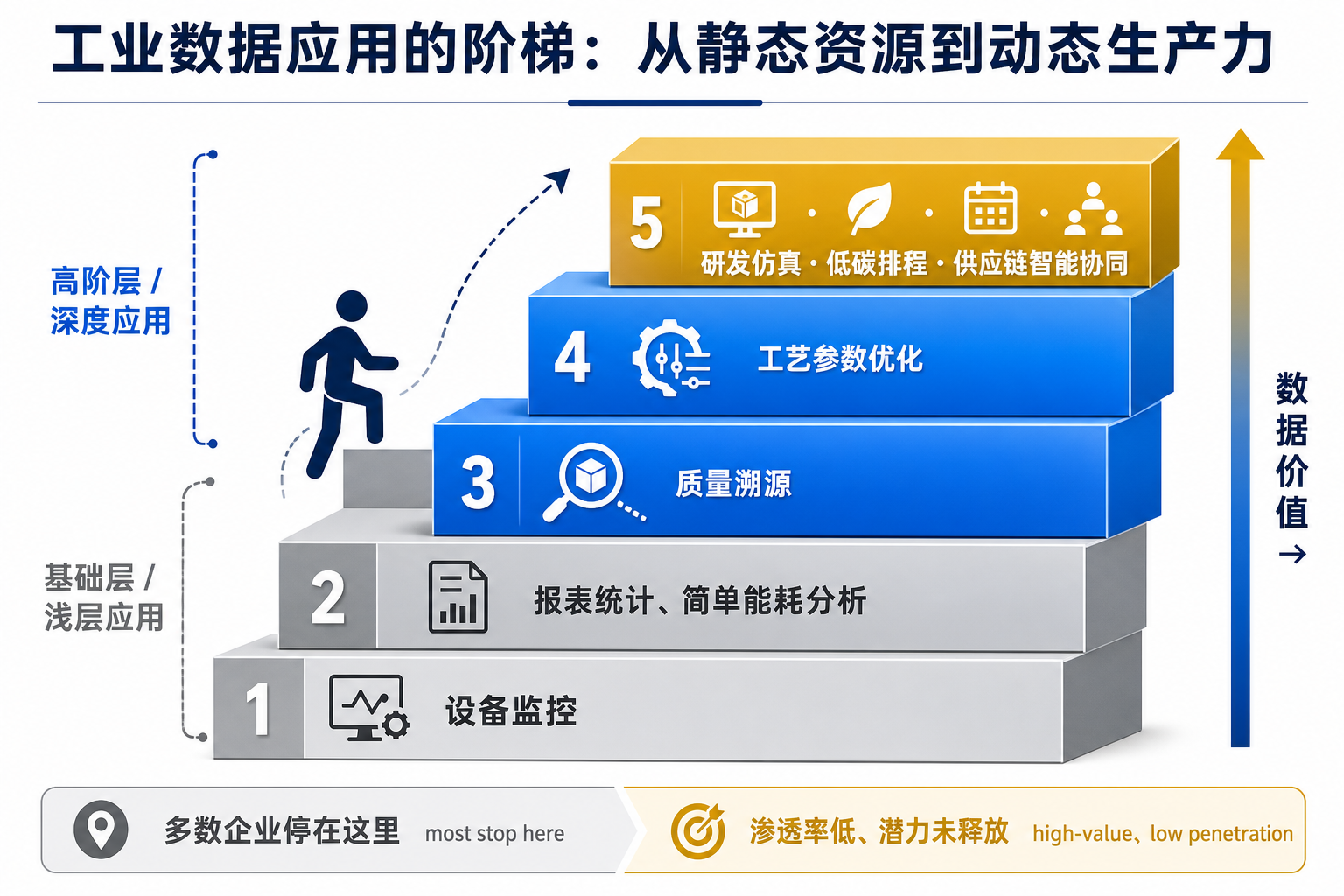
第二层病灶不是数据不够好,而是用得太浅。多数企业的数据应用还停在"设备监控、报表统计、简单能耗分析"——这些当然有用,但它们只是把数据当"后视镜",看看刚才发生了什么。
真正能把数据变成生产力的,是更上面那几级台阶:质量溯源、工艺参数优化、研发仿真、低碳排程、供应链智能协同。这些场景把数据从"记录过去"变成"优化未来"——同样一批工艺数据,浅层用法是出张能耗报表,深层用法是反推出一组让单吨能耗下降的最优参数。价值差着数量级,难度也差着数量级。
爬不上这几级台阶,原因往往不在数据本身,而在于:缺懂行业又懂数据的复合型人才、缺把领域机理沉淀进模型的能力、缺愿意为"不确定收益"买单的决心。这也是为什么政策特别强调要打造标杆应用——在钢铁冶炼、汽车制造、化工流程、装备运维这些领域先树几个看得见摸得着的样板,让后来者知道"上面几级台阶长什么样、怎么爬"。
病灶三:标准与安全保障体系滞后(用不久)
第三层最隐蔽,却决定能不能"持续用"。工业数据采集规范、数据集质量评级、流通交易规则、安全防护细则都还不完善,行业缺少统一遵循;数据泄露、篡改、非法流转的风险又很现实,隐私计算、区块链可信共享这些技术落地普及还不够。
"用不久"的本质是:没有标准,复用就无从谈起;没有安全,共享就没人敢碰。 一个数据集如果没有质量评级,别的企业凭什么信它、敢用它?一份核心工艺数据如果流通过程不可控、不可溯源,持有方凭什么放出来?所以政策把"标准库"单列为四大资源库之一,又反复强调可信互联平台要做到"可用不可见、可控可溯源"——这不是锦上添花,而是让"用"能够可持续、可规模化的地基。
四、把“用”盘活,政策押注三件事
对着三层病灶,政策在"用"这一端的药方可以归纳成三件事:
- 把数据集做成标准化的"数据燃料"。 分类建设设备故障、工艺优化、质量检测、能耗管控、供应链协同等行业数据集,建目录、做质量评级、定共享复用机制。逻辑很直接:工业大模型、行业智能体要落地,先得有"标准化的油"可烧;没有高质量数据集,再强的模型在工业现场也跑不动。
- 用标杆场景把"深度应用"演示出来。 推动数据集与工业大模型、数字孪生、智能质检深度融合,在钢铁、汽车、化工、装备运维等领域打造标杆——核心目的是让"数据由静态资源向动态生产力转变"这句话,变成看得见的案例,降低全行业爬台阶的心理门槛。
- 用确权与收益分配,让数据"愿意被用"。 这是最容易被忽略、却最关键的一招。数据沉睡,很多时候不是技术问题,而是激励问题——持有方放出来没好处、甚至有风险,自然宁可锁着。政策鼓励开展确权、价值评估、流通分配试点,建立"数据贡献与收益挂钩"机制,让供给方、治理方、应用方都能合理分钱。把账算清楚了,数据才会从"沉睡"走向"流动和被用"。
三件事环环相扣:数据集是弹药,标杆是示范,确权分配是让弹药持续供给的发动机。任何一件单独做都不够。
五、ICE 观察:技术、落地与本土视角
技术视角:工业数据的“用”,难点和互联网 AI 不在一个量级
把工业数据的"用"和互联网数据对比,会看到几个本质差异,也正是它更难的原因:一是长尾稀缺——最值钱的是极端工况和罕见故障样本,越值钱越稀缺,逼着行业走"仿真 + 生成式 AI 造数据"的路;二是强机理——工业场景背后是物理、化学、材料的硬约束,纯数据驱动的模型若不融入领域机理,现场泛化能力很差;三是多模态强耦合——时序传感、图像、三维模型、工艺文本、运维日志要融合对齐,难度远高于纯文本或纯图像。这三点决定了:工业数据的"用"不能照搬互联网那套"大力出奇迹",它更吃领域知识和数据工程的细活。
落地视角:先行先试是务实的“小切口”打法
值得肯定的是,这次政策没有追求"一步到位建大平台",而是用联合体、"小切口"、季度调度、年度评估的方式滚动推进,覆盖钢铁、汽车、有色、化工、能源装备、人形机器人和中小企业试点。这种"边试点、边总结、边固化"的打法,对工业数据这种行业差异极大、没法一刀切的领域是务实的——钢铁的工艺数据集和人形机器人的具身智能数据集,本来就不该用同一套模板。对企业的启示也朴素:别等大平台,先从一个能算清 ROI 的小场景把"用"跑通。
本土视角:从“制造大国”的数据,到“制造强国”的数据生产力
这件事的本土意义在于:中国有全球规模最大、门类最全的制造业体系,工业数据的体量优势是天然的;但体量不等于能力,"采上来、汇拢了、用不好"恰恰说明,规模优势还没转化成生产力优势。工业数据筑基行动想做的,正是把"数据资源大国"往"数据生产力强国"推一步。
这里也要诚实地留一句保留意见:政策框架很完整,但"用"这一端的成败,最终不取决于发了多少文件、建了多少平台,而取决于企业端能不能真的爬上那几级高阶台阶。复合型人才缺口、中小企业投入意愿、确权收益机制能否真正跑通,这些都是文件之外、要靠时间和市场去验证的硬骨头。政策能搭台、能补贴、能立标杆,但最后那滴价值,还得靠产线上的人把它挤出来。
结论
把这篇政策解码收束成几句话:
- 三段瓶颈,重心在"用"。 采、汇是入场券,解决"有没有数据""通不通";用是终局,解决"能不能变成生产力"。前者是工程难,后者是价值难,后者更难。
- 价值漏在出口。 入口端超六成原始数据无法直接训练,出口端多数应用停在监控报表——工业数据的价值,绝大部分漏在了"用"这一段。
- "用不好"有三层病灶。 数据集质量配不上工业 AI(靠仿真+生成式 AI 补样本)、应用场景浅层化(靠标杆应用爬台阶)、标准与安全滞后(靠标准库+可信互联平台筑地基)。
- 盘活"用"靠三件事。 标准化数据集(燃料)、标杆场景(示范)、确权与收益分配(让数据愿意被用)。
回到最朴素的那句话:衡量工业数据筑基行动成不成,不要只看汇了多少 PB、建了多少平台,要看产线上有没有因为这些数据,多出了一个更优的参数、一次更早的预警、一条更快的研发路径。数据躺在库里是成本,跑到产线上才是资产。工业数据这道题,难,最难在"用"。
参考资料
- 杨晓明. 瞭望·政策解码 | 突破工业数据采集用瓶颈. 新华社《瞭望》. 2026-06-23. https://lw.xinhuanet.com/20260623/8844bb68707049249f3cf476ed4747c5/c.html
- 工业和信息化部办公厅. 关于启动工业数据筑基行动开展面向人工智能赋能的高质量行业数据集建设先行先试的通知(工信厅信发函〔2026〕64 号). 2026-02-12. https://hunan.gov.cn/zqt/zcsd/202603/t20260312_33931928.html
- 新华网. 工业和信息化部启动工业数据筑基行动. 2026-03-10. https://www.news.cn/politics/20260310/3cbdf8fcea814ff39a954bf7cee137e3/c.html
- 中国电子技术标准化研究院(CICS-CERT). 推动工业数据"采、集、用" 为数据要素赋能新型工业化注入强劲动能. https://www.cics-cert.org.cn/
- 国家发改委等十七部门. "数据要素×"三年行动计划(2024—2026 年).