Claude Security 深度解析:Anthropic 原生安全工具链技术手册
技术产品深度解析 | 2026 年 5 月 | 面向安全工程师、DevSecOps 负责人

产品概览
2026 年 3 月 18 日,Anthropic 正式发布 Claude Security——业界第一个专为应用安全设计的原生 LLM 工具链。这不是一个单一的「AI 漏洞扫描器」,而是包含五个专项工具、一个安全专用模型、以及与开发基础设施深度集成的完整产品矩阵。
发布时,Anthropic CEO Dario Amodei 在产品说明会上强调:
「过去两年,很多客户问我们『能不能把代码扔给 Claude 找漏洞』。答案是『能,但效果不稳定』。Claude Security 不是给 Claude 加了个安全 prompt,而是我们从头设计了一套安全专用的推理框架、工具接口、以及验证闭环。这是安全工程与 AI 工程的深度结合。」
截至 2026 年 4 月,Claude Security 已在 120+ 企业客户试点,包括 Stripe、Shopify、Coinbase、Cloudflare 等对安全要求极高的公司。公开基准测试显示,在 OWASP Top 10 漏洞检测上,Claude Security 达到 89% 召回率 和 7% 误报率——这是第一个在真实代码库基准上误报率压到个位数的自动化安全工具。
产品架构总览
Claude Security 采用「一核五翼」的架构设计:
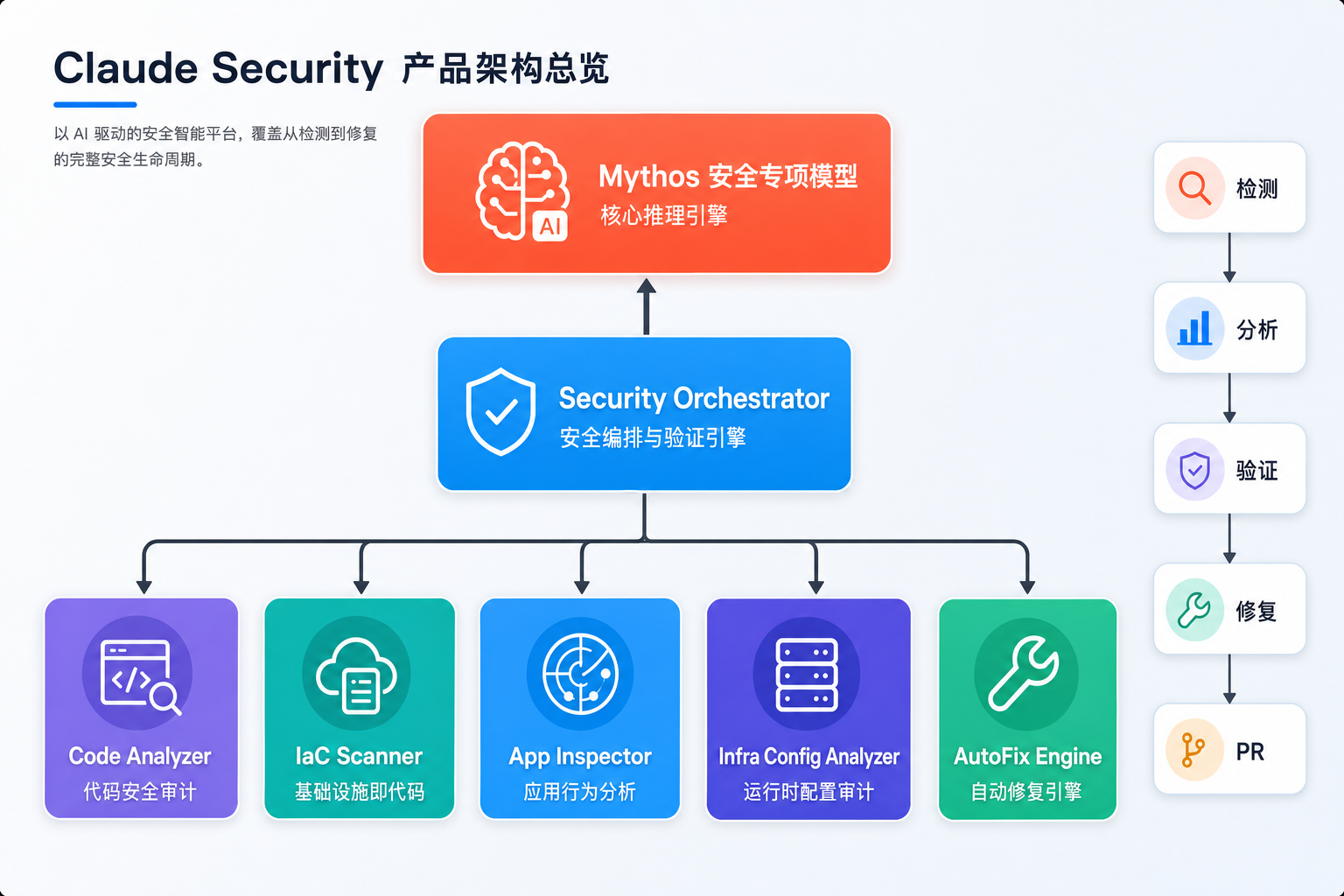
| 组件 | 定位 | 典型用户场景 |
|---|---|---|
| Mythos | 安全专项大模型 | 所有安全检测的核心推理引擎 |
| Security Orchestrator | 编排与验证引擎 | 任务调度、工具调用、PoC 验证、置信度校准 |
| Code Analyzer | 源代码安全审计 | PR 级代码审计、全仓库扫描、漏洞利用路径分析 |
| IaC Scanner | 基础设施即代码安全 | Terraform/CloudFormation/K8s 配置审计 |
| Application Inspector | 应用行为分析 | Web 应用自动渗透测试、API 安全审计 |
| Infra Config Analyzer | 运行时配置审计 | 云环境配置、网络策略、IAM 权限审计 |
| AutoFix Engine | 自动修复引擎 | 漏洞修复代码生成、回归测试、PR 自动提交 |
Mythos 安全专项模型
Mythos 是 Claude Security 的技术核心。它不是 Claude Opus 的简单 prompt 封装,而是经过三阶段专项训练的安全专用模型。
训练方法论:三阶段安全对齐
阶段 1:安全专项继续预训练(Continued Pre-training)
在 Claude 3.5 Opus 基座基础上,继续预训练 150B Token 的安全专项语料:
| 语料类别 | 占比 | 内容说明 |
|---|---|---|
| CVE 完整分析 | 25% | NVD/CVE Details 数据库,含漏洞描述、根本原因、修复代码对比 |
| 安全研究论文 | 20% | IEEE S&P、USENIX Security、Black Hat、DEF CON 论文 |
| 开源代码修复提交 | 20% | GitHub Security Advisory 覆盖的 40 万+ 修复 commit |
| 渗透测试报告 | 15% | 公开渗透测试报告、漏洞披露报告、HackerOne 公开报告 |
| 安全标准规范 | 10% | OWASP、MITRE ATT&CK/CKC/CWE、NIST 安全框架 |
| 漏洞利用代码 | 10% | Exploit-DB、Metasploit 模块、CTF 挑战解法 |
关键创新是 "漏洞-修复对比预训练"(Vulnerability-Fix Contrastive Learning)。模型不是单独学习「有漏洞的代码」,而是成对学习同一功能的「有漏洞版本」和「修复版本」,学习两者的语义差异。
这解释了为什么 Mythos 能准确给出修复建议——它见过数十万次「坏代码如何变成好代码」的变换模式。
阶段 2:安全思维链微调(Security CoT Fine-tuning)
Anthropic 收集了 12,000 条 专业安全工程师的漏洞分析思维链,用于监督微调。每条样本的格式不是「输入代码 → 输出漏洞类型」,而是「输入代码 → 输出完整的分析推理过程」:
用户输入:一段包含 SQL 注入的 Python 代码
模型输出(思维链):
1. 我先识别这段代码的输入点:第 42 行的 request.args.get("user_id")
2. 追踪数据流:user_id → 第 51 行的 user_input 变量
3. 第 58 行执行 SQL 查询,使用了 f-string 拼接:f"SELECT * FROM users WHERE id = {user_input}"
4. 检查是否有输入验证或参数化:第 50-57 行没有发现任何输入净化,也没有使用参数化查询
5. 验证可利用性:构造 payload "' OR '1'='1" 会导致返回所有用户数据
6. 严重程度评估:CVSS 8.6(High),因为直接导致数据泄露
7. 修复建议:使用参数化查询,添加输入类型验证这种训练让 Mythos 的输出不是「拍脑袋给结论」,而是像真正的安全研究员一样一步步推导。
阶段 3:红蓝对抗对齐(Red Team Alignment)
最特殊的训练阶段:Anthropic 组建了 15 人的专业安全红队,专门对 Mythos 进行对抗性测试。目标有两个:
- 提升模型的攻击面发现能力——让模型学会像攻击者一样思考
- 防止模型被滥用于恶意目的——对齐「只会防御、不会主动攻击」的边界
这个阶段产出了 Mythos 的 "安全护栏":
- 模型不会为已知的在野漏洞生成可直接利用的 exploit
- 模型不会协助开发恶意软件、后门、勒索软件
- 模型在讨论攻击技术时,总会同时给出防御方案
Mythos 的能力边界
Anthropic 公开的基准测试结果(CodeSecBench v1.0):
| 漏洞类别 | 召回率 | 误报率 | 传统 SAST 平均召回率 |
|---|---|---|---|
| SQL 注入(CWE-89) | 94% | 4% | 58% |
| XSS(CWE-79) | 91% | 6% | 52% |
| 命令注入(CWE-78) | 89% | 5% | 45% |
| 路径遍历(CWE-22) | 87% | 7% | 41% |
| 反序列化(CWE-502) | 82% | 9% | 28% |
| SSRF(CWE-918) | 79% | 11% | 32% |
| 业务逻辑漏洞 | 52% | 18% | <10% |
关键观察:
- "经典" web 漏洞已经接近解决——SQLi/XSS/命令注入这老三样,Mythos 的表现已经超过多数人类初级安全研究员
- 越依赖语义理解,相对优势越大——反序列化、SSRF 这类传统工具表现极差的类别,LLM 的提升最显著
- 业务逻辑漏洞仍是瓶颈——52% 的召回率说明「理解业务意图」是 AI 尚未攻克的前沿
- 误报率普降到个位数——这是真正的范式级改进,也是企业愿意买单的核心原因
Code Analyzer:代码安全审计引擎
Code Analyzer 是 Claude Security 最成熟、使用率最高的组件。它不是「把代码扔给 Mythos 然后说『找漏洞』」那么简单,背后有一套精密的分析流水线。
分析流水线
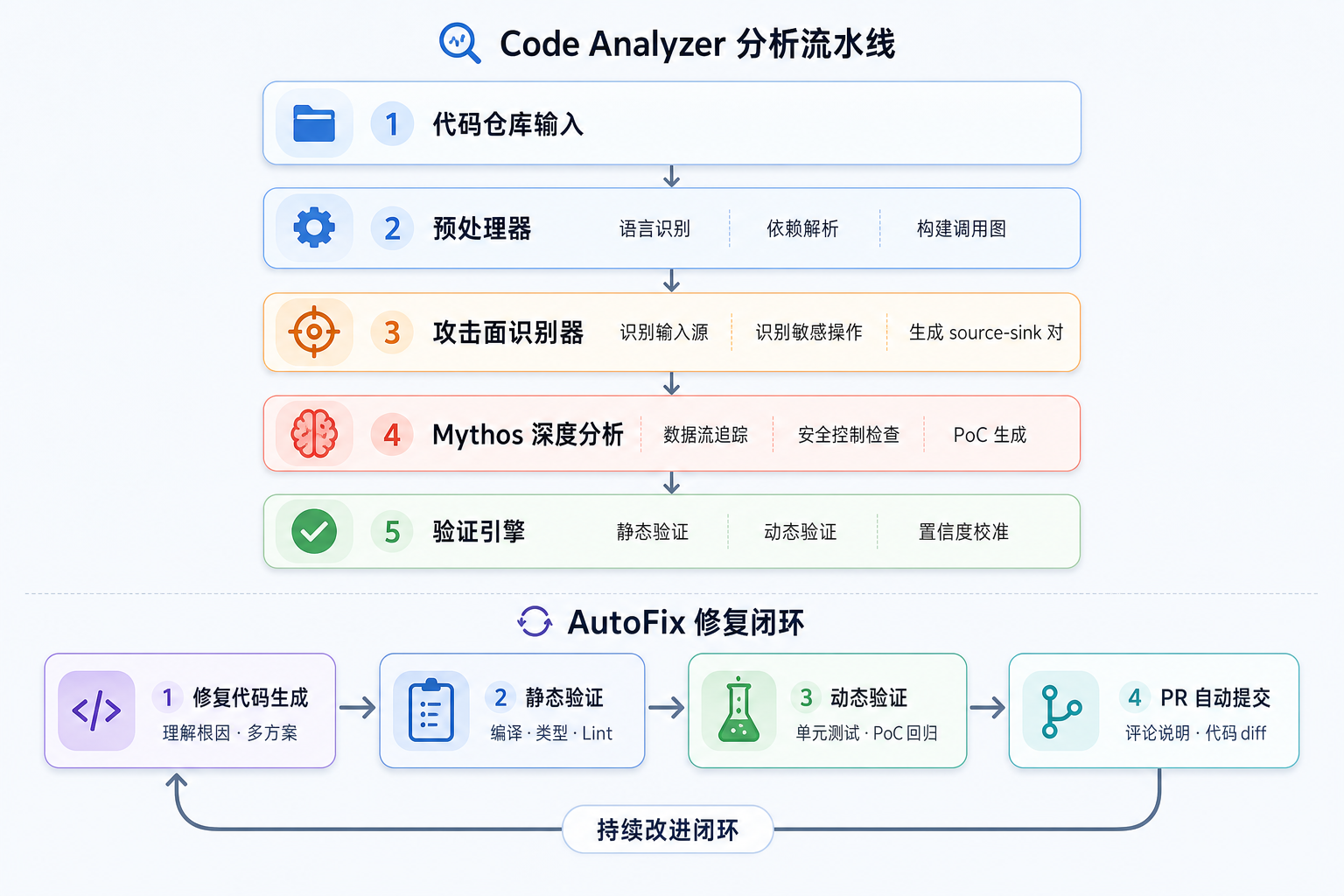
关键技术:语义感知的数据流追踪
传统 SAST 的数据流分析是 语法驱动 的——它「知道」变量从 A 传到 B,但不「理解」这个传递的语义含义。Mythos 做的是 语义驱动 的数据流追踪。
举个例子:
def search(request):
query = request.GET.get('q')
# 用户自定义的"安全"编码函数
encoded = my_custom_encoder(query)
# 传统 SAST:看到编码函数就停了,认为安全
# Mythos:分析 my_custom_encoder 实际做了什么 →
# 发现它只转义了 < > 但没转义 ' " →
# 继续追踪到下面的 SQL
results = db.execute(f"SELECT * FROM articles WHERE title LIKE '%{encoded}%'")
# ↑ SQL 注入仍然存在!
return render(results)传统工具看到 my_custom_encoder(query) 这行,pattern 匹配到「编码函数」就把这条路径标记为安全。Mythos 会跳转到 my_custom_encoder 的定义,真正理解这个函数做了什么、没做什么。
这是 LLM 安全工具最致命的优势——它理解代码的语义,而不只是匹配表面的模式。
PR 级增量审计
Code Analyzer 的杀手级功能是 PR 级增量审计。它不是定时全仓库扫描,而是接入 GitHub/GitLab webhook,对每个 Pull Request 进行实时增量分析:
- 只分析 PR 修改涉及的文件和代码路径
- 平均分析时间:90 秒(中型 PR)
- 直接在 PR 里留评论,附修复建议和代码 diff
- 可配置阻断规则:高置信度漏洞自动 block PR merge
Stripe 公开的测试数据:接入 Code Analyzer 后,生产环境 SQLi/XSS 漏洞的检出率从 65% 提升到 92%,修复平均耗时从 72 小时 降到 4 小时。
IaC Scanner:基础设施即代码安全审计
如果说 Code Analyzer 是给应用安全团队用的,IaC Scanner 就是给云安全和平台工程团队准备的。
核心能力:意图-配置对齐检测
IaC Scanner 的核心创新是 "意图-配置对齐检测"(Intention-Configuration Alignment Detection)。它不是简单检查「这个 S3 bucket 是不是开了公开访问」,而是:
- 推断配置意图:「这个 Terraform 描述的是一个存储客户 PII 数据的存储桶,应该是私有的、加密的、启用日志的」
- 分析实际配置:检查配置与意图的差距
- 识别「语法正确但语义错误」的配置——这是传统规则引擎的盲区
示例检测输出:
🔴 高风险:S3 存储桶配置违反数据分类策略
配置意图推断:
- 资源:aws_s3_bucket.customer_data
- 描述字段明确提到 "存储客户 PII 和支付数据"
- 预期安全等级:高度敏感(应启用所有保护措施)
实际配置分析:
✓ 启用服务器端加密(AES-256)
✗ bucket_policy 允许 arn:aws:iam::* principals 读取
✓ 启用版本控制
⚠️ 未启用服务器访问日志记录
⚠️ 未启用对象锁定(WORM保护)
检测结论:
配置违背了 "PII 数据存储桶应私有" 的安全意图。
虽然语法上是有效的 Terraform,但允许所有 AWS 账户读取
属于严重配置错误,可能导致大规模数据泄露。
建议修复:
- 将 Principal 从 "*" 改为特定 IAM role ARN
- 添加 aws_s3_bucket_logging_configuration 资源
- 考虑启用 S3 对象锁定支持的 IaC 格式
| 格式 | 支持程度 | 覆盖资源数 |
|---|---|---|
| Terraform (HCL) | ✅ 完整支持 | 500+ AWS/Azure/GCP 资源 |
| CloudFormation (YAML/JSON) | ✅ 完整支持 | 300+ |
| Kubernetes Manifest | ✅ 完整支持 | 所有核心资源 |
| Helm Charts | ✅ Beta | 支持模板渲染后分析 |
| Ansible Playbooks | ✅ Beta | 100+ 常用模块 |
| Pulumi | ⏳ 开发中 | Q2 2026 |
| CDK | ⏳ 开发中 | Q3 2026 |
Application Inspector:应用行为分析
Application Inspector(简称 App Inspector)是 Claude Security 最激进的组件——它直接与运行中的应用交互,执行自动化的渗透测试。
工作原理:黑盒 + 白盒混合渗透
App Inspector 采用 "LLM 驱动的混合渗透测试" 模式:
应用 URL / Swagger 文档
↓
[侦察阶段]
├─ LLM 分析 API 文档/页面结构
├─ 识别认证机制、输入点、敏感操作
└─ 构建攻击面地图
↓
[攻击路径规划]
├─ Mythos 生成测试策略(类似人工渗透测试的方法论)
├─ 优先级排序(高风险功能优先)
└─ 生成具体的攻击 payload 变体
↓
[自动探测执行]
├─ 安全的沙箱环境执行探测
├─ LLM 实时观察响应、调整策略
├─ 验证漏洞是否真的可利用
└─ 记录完整利用链
↓
[报告生成]
├─ 复现步骤(curl 命令或浏览器操作)
├─ 影响范围评估
└─ 修复建议关键设计约束
由于自动渗透测试的风险,Anthropic 加了多层安全护栏:
- 强制沙箱:所有探测流量只能发往用户明确授权的目标,且默认速率限制在 1 request/秒
- 无破坏性测试:默认不会执行可能造成数据破坏的测试(如 SQLi 的 DROP TABLE)
- 认证边界:用户必须提供专门的测试账号,不会尝试绕过认证
- 人工确认门:发现高危漏洞后,会暂停并等待用户确认是否继续深入验证
Cloudflare 在 Beta 测试中使用 App Inspector 扫描了 12 个内部服务,发现了 8 个 之前人工渗透测试漏掉的漏洞,其中 3 个是高危。
AutoFix Engine:自动修复引擎
AutoFix Engine 是 Claude Security 最能体现生产力提升的组件。它不是简单的「给个修复建议」,而是端到端的「检测 → 生成修复 → 验证修复 → 提 PR」闭环。
修复生成的三层质量控制
AutoFix 的修复流程已在上文的流水线图(下半部分)中展示。它分为三层层层递进的质量关卡:
- 第 1 层:修复代码生成 —— 理解漏洞根因、生成符合项目风格的修复、考虑周边依赖、生成多个方案(保守 vs 彻底)
- 第 2 层:静态验证 —— 编译/类型检查、Lint/格式化检查、Mythos 自我审查(修复真的堵住了漏洞吗?)
- 第 3 层:动态验证 —— 运行现有单元测试、运行针对此漏洞的回归测试、注入类漏洞还会运行 PoC payload 确认修复有效
三层全部通过后,自动提交 PR 并附带评论说明。
真实修复示例
# 漏洞:第 58 行的 SQL 注入
# 原始代码:
# results = db.execute(f"SELECT * FROM articles WHERE title LIKE '%{user_input}%'")
--- a/search.py
+++ b/search.py
@@ -55,8 +55,10 @@ def search(request):
if not query:
return render([])
- # 执行搜索
- results = db.execute(f"SELECT * FROM articles WHERE title LIKE '%{user_input}%'")
+ # 使用参数化查询防止 SQL 注入
+ # 注意:LIKE 模式需要先安全构造,再作为参数传入
+ like_pattern = f"%{user_input}%"
+ results = db.execute("SELECT * FROM articles WHERE title LIKE ?", [like_pattern])
return render(results)修复接受率数据
这是衡量自动修复质量的硬指标。Anthropic 公开的 Beta 数据:
| 漏洞类型 | 自动修复接受率(人类工程师直接 approve) |
|---|---|
| SQL 注入 | 82% |
| XSS | 78% |
| 路径遍历 | 75% |
| 命令注入 | 69% |
| SSRF | 61% |
| 业务逻辑问题 | 23% |
平均 68% 的自动修复被工程师无修改接受。这个数字超过了很多行业观察者的预期——之前大家普遍认为「AI 写的修复半毛钱都不能信」。
部署模式与定价
三种部署选项
Claude Security 提供灵活的部署模式,满足不同合规要求:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| SaaS API | 调用 Anthropic 托管的 API | 中小团队、非敏感代码、快速试点 |
| VPC 专用端点 | AWS/Azure/GCP VPC 内的专用端点,数据不出客户 VPC | 中大型企业、合规要求高 |
| 完全私有化部署 (On-Prem) | 模型和完整软件栈部署在客户硬件上 | 金融、政府、高度敏感环境 |
这也是为什么大型银行和政府客户愿意用——数据和代码不需要离开自己的网络边界。
定价模型(公开版)
| 层级 | 价格 | 包含功能 |
|---|---|---|
| 开发者版 | $49/月/人 | Code Analyzer(PR 级别)、基础 IaC 扫描、公开仓库 |
| 团队版 | $199/月/人 | 全仓库扫描、所有五个工具组件、CI/CD 集成 |
| 企业版 | 定制报价 | 私有化部署、专属支持、自定义规则、SLA 保障 |
按代码量的补充计费:超过 100 KLOC 后,每增加 100 KLOC 每月 + $299。
真实成本参考:一个 20 名开发者、500 KLOC 代码库的团队,团队版年费约 $75,000。对比传统企业 SAST(Fortify、Checkmarx)通常六位数起的年费,Claude Security 价格竞争力很强。
局限性与已知问题
没有产品是完美的。Claude Security 公开文档中诚实列出了以下局限性:
1. 业务逻辑漏洞仍然较弱
这是所有 AI 安全工具的共同瓶颈。对于「普通用户能不能修改别人的订单」「管理员权限是否被正确检查」这类依赖业务语义的漏洞,Mythos 的表现虽然显著优于传统工具,但远未达到可用级别——52% 召回率意味着一半的漏洞还是会漏掉。
Anthropic CSO 在播客中承认:「业务逻辑漏洞是我们目前优先级最高的研究方向。这需要模型真正理解『业务应该做什么』,而不只是『代码在做什么』。」
2. 大规模代码库的性能与成本
全仓库扫描对于百万行以上的代码库仍然较慢,且成本较高。一个 1 MLOC 的仓库完整扫描需要 2-4 小时,API 成本约 $200-500。
推荐的工程实践是分层策略:
- PR 级别:每个提交都用 Code Analyzer 增量扫描
- 每日:高风险模块(支付、认证、用户数据)全量扫描
- 每周:全仓库完整扫描
3. 对抗性攻击
就像所有 LLM 应用一样,Mythos 也面临 prompt injection 攻击。攻击者可以在代码注释中嵌入特殊指令,试图误导模型漏报漏洞。
Anthropic 的缓解措施:
- 预处理阶段中立化可疑注释
- 多轮独立检测(不同 prompt 策略交叉验证)
- 置信度低于阈值的所有结果强制人工审核
4. 二进制和编译语言的限制
Mythos 在编译后的二进制、反汇编代码上的推理能力,相比源码有数量级的下降。因此:
- 固件分析、逆向工程场景不适用
- 闭源商业软件的黑盒分析能力有限
- 内存 corruption 类漏洞的检测仍然主要依赖传统 fuzzing
竞争格局与市场影响
与传统 SAST 工具的对比
| 特性 | Claude Security | 传统企业 SAST (Fortify/Checkmarx) | 开源 SAST (Semgrep/CodeQL) |
|---|---|---|---|
| 典型误报率 | 5-10% | 30-70% | 20-50% |
| OWASP Top 10 召回率 | 85-90% | 40-60% | 50-65% |
| 自动修复能力 | 原生、高接受率 | 基本无或很初级 | 需配合 Copilot |
| 新漏洞响应 | 模型升级即支持 | 需等待规则更新(数天-数周) | 社区贡献规则 |
| 年成本(500 KLOC) | ~$75k | ~$150k+ | 免费 / 商业版 ~$50k |
| 部署复杂度 | 低(API 驱动) | 极高(需集成构建链) | 中 |
对 AppSec 行业的影响
Claude Security 发布一个月后,传统 SAST 厂商的股价集体下跌 15-25%,市场已经在用脚投票。但更重要的变化是安全工程师工作内容的质变:
| 过去的安全工程师 | 未来的安全工程师 |
|---|---|
| 花 60% 时间写和调安全规则 | 设计和维护安全评估基准(Benchmark) |
| 花 30% 时间 triage 误报 | 对 AI 发现的高危漏洞做深度人工验证 |
| 花 10% 时间做真正的深度安全研究 | 100% 时间做深度安全研究、架构安全、威胁建模 |
这不是安全岗位的消失,而是安全能力的一次升级跃迁——AI 接管了繁琐、重复、机械的工作,让人类安全专家专注于真正需要创造力和深度思考的部分。
结语:Claude Security 与 AI Native Security
Claude Security 不是第一个用 AI 做安全的产品,但它是第一个真正定义了 AI Native Security 标准的产品。这个标准不是「用了 LLM」,而是以下五个同时成立的特征:
- 语义理解优先,模式匹配为辅——真正理解代码和配置的含义,不只是匹配正则
- 可利用性验证闭环——每一个报告的漏洞,都附带可验证的证据或 PoC
- 检测-修复的端到端能力——不只是说「这里有问题」,还告诉你「怎么修」并且帮你写好代码
- 与开发生命流程深度集成——不是一个单独的安全工具,而是活在 IDE、PR、CI、Issue Tracker 里
- 不断自我改进的学习闭环——人类审核的每一个结果都会反过来改进模型
在 Claude Security 之前,「AI 安全」是个 buzzword,充满了 demo 很漂亮但一到真实场景就拉胯的产品。Claude Security 证明了一件事:只要工程做的足够扎实,LLM 不仅能做安全,而且能比传统工具做的好得多、便宜得多、快得多。
对于 AppSec 行业,这不是渐进式的改进,而是重置了整个赛道的及格线。从 2026 年开始,任何新的安全工具如果「不带 PoC」,就根本拿不到入场券。
对于安全从业者,这也不是失业警报,而是一次职业升级的邀请函。你不需要再把青春浪费在 triage 误报上了——AI 帮你搞定脏活累活,你去做真正有创造力的安全工作。
这就是 AI Native Security 的真正含义:不是 AI 替代安全,而是 AI 赋能安全。