可验证交互轨迹:训 Agent 的下一个瓶颈,不在模型在数据

Deep Research 报告 | 2026 年 7 月 | 面向关注 Agent 训练、数据工程与强化学习基础设施的从业者
摘要
有一个判断这半年被越来越多的实验证实:决定 Agent 强弱的,正在从"用了多大的模型"变成"喂了多少可验证的交互轨迹"。
先看一个反差。数学和代码这类"答案能被机器判对错"的任务上,一种叫 RLVR(可验证奖励强化学习,Reinforcement Learning from Verifiable Rewards) 的方法把模型能力拉到了新高度——DeepSeek-R1-Zero 只靠 GRPO + 可验证奖励、连监督微调都没做,就把 AIME 2024 数学题的准确率从 15.6% 一路推到 77.9%。但同样的方法一搬到 Agent(多步操作、调工具、改代码库)身上就失灵了:任务太长、失败率太高,绝大多数尝试都拿到 0 分,梯度里几乎没有信号。差别不在模型,在能不能给它一批"做对了能被验证、做错了也知道错在哪"的轨迹。
本文想把这件正在发生的事讲清楚:可验证交互轨迹到底是什么、一条轨迹从产生到变成一次梯度更新中间发生了什么、为什么这类数据这么难造这么贵,以及为什么 2026 年最值钱的工程能力之一,可能不是再训一个更大的模型,而是建一条能持续产出可验证轨迹的数据流水线。
一、瓶颈换位:从"模型多大"到"轨迹够不够"
过去两年提升模型能力的主线很清楚:更大的预训练语料、更大的参数量、更长的上下文。但这条线在 Agent 任务上很快见了底——因为 Agent 要学的不是"预测下一个词",而是"在一个真实环境里,连续做几十步操作、每步调用工具、根据反馈纠错,最后把事办成"。这种能力,预训练语料里几乎没有现成的示范。
RLVR 之所以在 2025 年成为主流,正是因为它绕开了"人来标注偏好"这个又慢又贵又主观的环节。它的逻辑朴素得近乎粗暴:让模型对同一个问题采样多条解法,用一个确定性的验证器(编译器、单元测试、数学求解器、规则校验)给每条解法打个分——对就是 1,错就是 0,然后用这个分去更新策略。配套的 GRPO(组相对策略优化) 更是把架构砍到极简:一次为同一个问题生成一组(通常 16 条)解法,在组内做归一化算出相对优势,连独立的价值网络都省了。可验证 + 无需人标 + 无需额外奖励模型,这套组合拳直接点燃了推理模型这一年的爆发。
问题是,数学题的"验证"太便宜了:一个标准答案、一次比对就完事。而 Agent 任务的验证要昂贵得多——你得真的把它写的代码跑起来、把测试套件执行一遍、把浏览器操作重放一次,才知道它到底有没有把事办成。更麻烦的是,长任务的奖励极其稀疏:一个需要 50 步、每步都可能出错的软件工程任务,前沿模型的单次成功率也常常只有个位数百分比,意味着你采样出来的一大批轨迹清一色是 0 分,模型学不到任何"往哪个方向改"的信息。
于是瓶颈就这么换了位置。不再是"模型不够聪明",而是"没有足够多、足够干净、能被自动验证的轨迹去喂它"。 而造这种轨迹,本质上是一个数据工程问题。
二、拆解"可验证交互轨迹":三个定语,三道门槛
"可验证交互轨迹"这个词有点绕,拆成三段就清楚了。
"轨迹(trajectory)" 是训练的基本单位。它不是一问一答,而是 Agent 完成一个任务的完整操作流水:从初始的仓库状态或浏览器状态开始,中间每一步的工具调用参数、环境返回的观测、生成的文件、运行时报错、部分进度标记,一直到最后的终止决策。用一份公开工程资料的原话,一条轨迹里可能塞着"仓库状态、浏览器状态、图像、shell 记录、工具参数、观测、生成的文件、运行时失败、进度标记和一个终止决定"——它是一段有始有终、可回放的行为序列。
"交互(interactive)" 强调它来自 Agent 与环境的真实往返,而不是凭空编的对话。模型发起一个动作,环境(一个能跑代码的沙箱、一个真实的命令行、一个网页)给出真实反馈,模型据此决定下一步。没有这个环境闭环,就没有"交互",只有想象。
"可验证(verifiable)" 是最关键、也是最贵的那个定语。它要求这段轨迹的结果能被一个确定性的、自动的判据打分——单元测试通过了没、补丁修好了 bug 没、命令返回码是不是 0。正是这个"可自动判对错"的属性,让轨迹能直接接进 RLVR 的训练回路,不需要人来逐条标注。
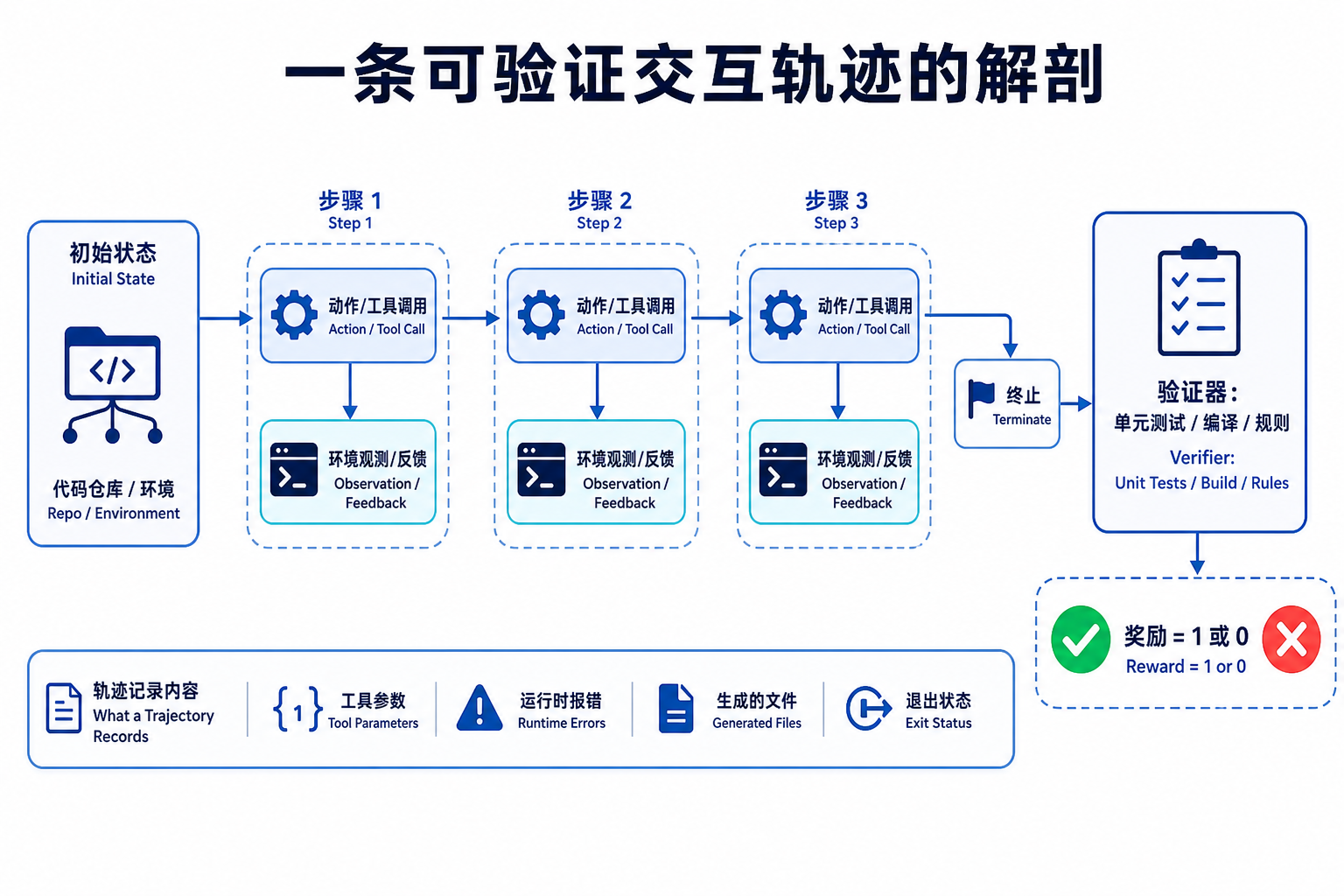
对照一下就更清楚它跟以往训练数据的区别:
| 数据类型 | 长什么样 | 谁来判对错 | 能否直接驱动 Agent RL |
|---|---|---|---|
| 预训练语料 | 网页 / 书 / 代码文本 | 无(只学分布) | 否,学不到"办事"能力 |
| 指令微调对 | 问题 → 参考答案 | 人工撰写答案 | 弱,只教格式与套路 |
| 人类偏好数据(RLHF) | 同一问的多个回答排序 | 人打分(主观、贵、慢) | 部分,但主观且难扩展 |
| 可验证交互轨迹 | 完整多步操作 + 执行结果 | 确定性验证器(测试/编译/规则) | 是,可直接算奖励做 RL |
一句话:前三种数据教模型"像人一样说话",可验证交互轨迹教模型"像工程师一样把事干成、并且干对"。
三、一条轨迹的一生:从采样到梯度更新
把训练回路拆开看,一条可验证轨迹的"生命周期"大致是这样的:
1. 采样任务:从任务池里取一个(如某 GitHub 仓库的一个待修 bug)
2. Agent 上场:模型在 harness(执行框架)里连续操作——读代码、改文件、跑测试
3. 环境反馈:沙箱真实执行,返回报错、测试结果、运行时状态
4. 记录轨迹:harness 存下完整序列 + 输出补丁 + 退出原因 + 超时状态 + 奖励
5. 验证打分:单元测试全过 → reward=1,否则 0(或按里程碑给稠密分)
6. 过滤:丢掉不可用/未终止的轨迹,只留成功或有信息量的
7. 更新策略:用 GRPO 等算法,按组内相对优势更新模型参数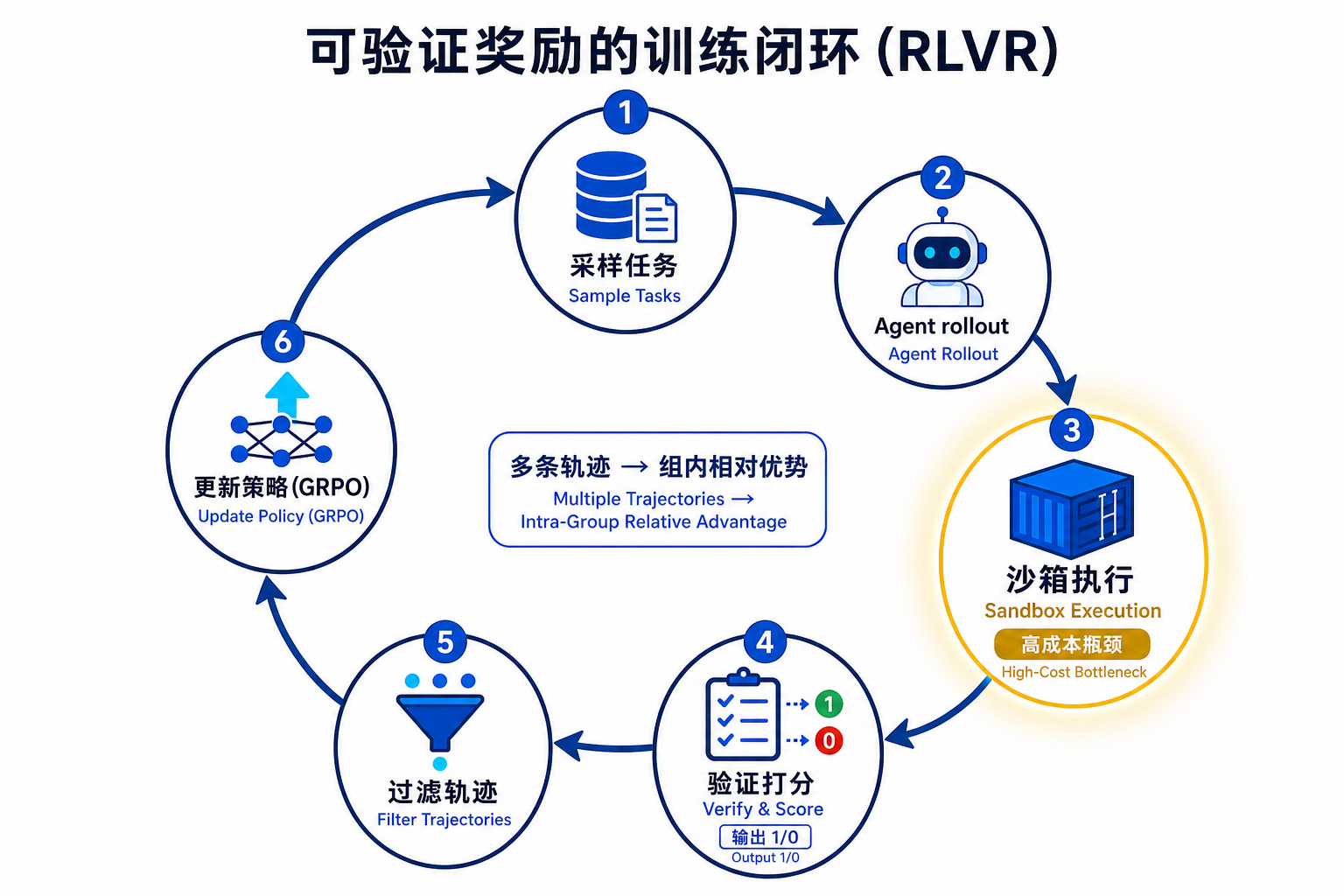
这里有两个常被忽略、却决定成败的工程细节。
第一,"环境"本身就是数据资产的一部分。 你不能只有一句"修好这个 bug"的任务描述,还必须配一个能把这个 bug 的测试真实跑起来的运行时——一个装好依赖、能编译、能执行单测的容器镜像。这也是为什么造这类数据这么重:公开研究里,配套的执行环境动辄要占好几个 TB 的存储。任务描述是纸面,可执行环境才是让轨迹"可验证"的那台机器。
第二,稀疏奖励是 Agent RL 的头号敌人。 长任务几乎每次都失败,轨迹大面积塌缩到同一个 0 分,模型收不到有效梯度。业界给出的解法基本是两条腿:一是稠密化奖励,除了最终成败,再加上格式奖励、里程碑奖励,让模型在半路就能收到"你走对了一小步"的反馈;二是引导(guidance)——先让 Agent 自己试一遍,用测试判分,再把"高层计划、错误信息、环境观测"这些线索回灌进上下文,让它带着提示重做一遍,再用这条"被引导出来的成功轨迹"去更新模型。Scale Labs 的 Agent-RLVR 就是后者的代表:靠这套引导,把 Qwen-2.5-72B 在 SWE-Bench Verified 上的单次通过率从 9.4% 抬到 22.4%,再叠加测试期奖励模型进一步到 27.8%。
四、把"轨迹供应链"往前推的几股力量
这条"轨迹供应链"上,几股力量在同时往前拱:把数据规模做大、把环境造出来、把稀疏奖励治住、把验证成本压下去、把基础设施标准化。逐个看。
规模:一条还没见顶的 scaling law
最有说服力的证据来自软件工程方向。研究者构建了一个约 1 万个可执行验证的真实 Python 任务(来自 2531 个 GitHub 仓库,每个任务都配了专门的运行时镜像用于自动跑单测),从中筛出 8000 多条经运行时验证的成功轨迹用来微调。结果发现一个很提气的现象:模型的软件工程能力随轨迹数据量持续上涨,一直到实验规模上限都没有饱和的迹象。 最终这个 32B 模型在 SWE-bench Verified 上拿到 38.0% 单次通过率(不用任何验证器、不做多次采样),叠加测试期扩展后到 47.0%,刷新了同规模模型的纪录。
洞见一:轨迹数据的边际收益还没到头。
在代码这类可验证性最强的领域,"多喂一批高质量轨迹"目前仍能稳定换来能力提升,且呈现近似"准确率随数据量对数线性增长"的规律。这跟预训练早已进入"边际递减"形成鲜明对比——当下最划算的投入,可能不是更大的模型,而是更多可验证的轨迹。
造环境:从人肉攒数据到程序化流水线
轨迹的上游是任务 + 可执行环境,而这一直是最卡脖子的环节:传统做法要人工筛代码、手动搭运行时、配单元测试,几百小时人力才能攒出几千条,早期公开数据集大多卡在"几千个实例、十来个仓库"的天花板。
破局的方向是程序化生成。一类做法(SWE-smith 路线)是:给定任意一个 Python 代码库,自动为它构造出可执行环境,再自动合成成百上千个"会破坏现有测试"的任务实例——相当于给每个仓库开了一条造题流水线。靠这套方法,有团队一口气造出 5 万个实例(来自 128 个仓库),比以往工作大了一个数量级,用采集到的专家轨迹微调出的 32B 模型在 SWE-bench Verified 上达到 40.2%。另一类做法(SWE-Gym 路线)则是把 2438 个带可执行运行时和单测的真实任务打包成一个"训练场",直接带来最高 19 个百分点的通过率绝对提升。
洞见二:造数据的方式,正在从"手工艺"变成"工业化"。
谁能把"任务 + 环境 + 验证"的生产自动化、规模化,谁就掌握了 Agent 能力的上游供给。这本质上是一个数据工程与基础设施的竞赛,而不是模型架构的竞赛。
降本:把环境做小,把测试做没
规模化立刻撞上第二堵墙:验证太慢太贵。真实沙箱又重又脆,跑一次完整测试动辄几分钟,在线强化学习需要成千上万次这样的 rollout,算力和时间根本扛不住。这里有两个很聪明的降本思路。
一是把环境做"微型化"。有研究发现,机器学习工程(MLE)任务的执行耗时几乎全被数据集大小拖累——原始基准任务平均每个带着约 409 万条样本,跑一步慢得离谱。于是他们造了微型合成沙箱,把每个任务的数据刻意压到 50–200 条样本,在保留问题结构和隐藏规律的前提下,把单步执行时间压到 15 秒以内、提速 13 倍以上,让原本只能跑几十次的在线 rollout 变成可以跑几千次。
二是干脆把"跑测试"这一步换掉。既然搭沙箱、跑单测又重又脆、还容易被"钻测试空子",那能不能训一个会看补丁做推理的验证器模型来直接判对错?有工作正是这么做的:这个"补丁审查器"在 SWE-bench-verified 上验证补丁的准确率达到 72.2%,超过了 OpenAI o3;用它当唯一奖励来源训出来的轻量 Agent,单次通过率比基座提升 10 个百分点,测试期扩展后到 33.8%。相当于用"AI 当评委"替代"跑真实测试",把验证从重资产变成可扩展的模型调用。
中间件:轨迹平面(trajectory plane)正在成型
当"采样—执行—验证—记录—训练"成为标准回路,一个新的基础设施层就冒出来了:介于 RL 训练器和 Agent 执行环境之间的轨迹平面(trajectory plane)。它专门负责代理模型的每次调用、按 token 记录轨迹、管理沙箱执行、把验证从 Agent 逻辑里解耦出来,产出"训练级"的结构化轨迹数据。
已经有多个开源项目在做这件事:有的把系统拆成"rollout 服务器 + 网关节点",由网关把一次会话的所有模型调用捕获、拼装成含 prompt/response token、loss mask、工具定义、log 概率、奖励和元数据的完整 Trajectory;有的直接把自己定位成"RL 训练器与执行环境之间缺失的那层基础设施",提供受控 rollout、沙箱执行、解耦验证和只追加的轨迹存储四个平面。
洞见三:轨迹正在被当成"一等公民"来做基础设施。
就像十年前数据仓库把"表和查询"变成一等公民一样,现在这一批工具在把"轨迹和奖励"变成一等公民——可采集、可回放、可审计、可复用。这层中间件的成熟度,会直接决定一个团队造轨迹的效率上限。
五、把数字摆在一起:轨迹经济学的轮廓
把散落的数据汇成一张表,"轨迹经济学"的轮廓就出来了:
| 维度 | 关键事实 / 数字 | 说明 |
|---|---|---|
| RLVR 的威力 | DeepSeek-R1-Zero:AIME 15.6% → 77.9% | 可验证奖励在数学/代码上极其有效 |
| Agent 领域的失灵 | 长任务单次成功率常为个位数,轨迹大面积 0 分 | 稀疏奖励是 Agent RL 头号难题 |
| 引导的价值 | SWE-Bench Verified:9.4% → 22.4% → 27.8% | 用线索回灌 + 重试造出有信息量的轨迹 |
| 数据 scaling law | 1 万任务 / 8000 轨迹 → 38.0%(→47.0%),不见饱和 | 轨迹的边际收益仍在 |
| 程序化造数据 | 5 万实例 / 128 仓库,大一个数量级 → 40.2% | 造数据从手工艺走向工业化 |
| 微型沙箱降本 | 每任务样本压到 50–200,提速 13×+、单步 <15 秒 | 让在线 rollout 变得可行 |
| 免测试验证 | 补丁审查器 72.2% 准确率(>o3) | 用模型当评委替代跑真实测试 |
| 验证器带来的提升 | DeepSWE:Pass@1 42.2% → 用验证器选优 59.2% | 验证器同时服务训练与推理期 |
这张表想说的其实是一句话:这一轮 Agent 能力的提升,几乎每一格都对应着"轨迹供应链"上某个环节的工程突破,而不是模型本身变聪明了。
值得单独点出的是环境模拟这条更激进的路线。已经有工作把"环境"本身也做成一个模型——用超过 1000 万条跨 MCP、搜索、终端、软件工程、网页、操作系统、安卓七大领域的真实交互轨迹,训出一个"语言世界模型",让它当 Agent 强化学习的可控模拟环境。思路很清楚:真实环境又慢又难扩展,那就让模型学会模拟环境,在模拟里低成本、可控地生成海量轨迹。 这等于把"造轨迹"这件事又往上游推了一层。
六、四道硬骨头:为什么"可验证 ≠ 高质量"
把话说圆,也得把坑标出来。可验证轨迹不是免费午餐,它有四个绕不开的硬骨头。
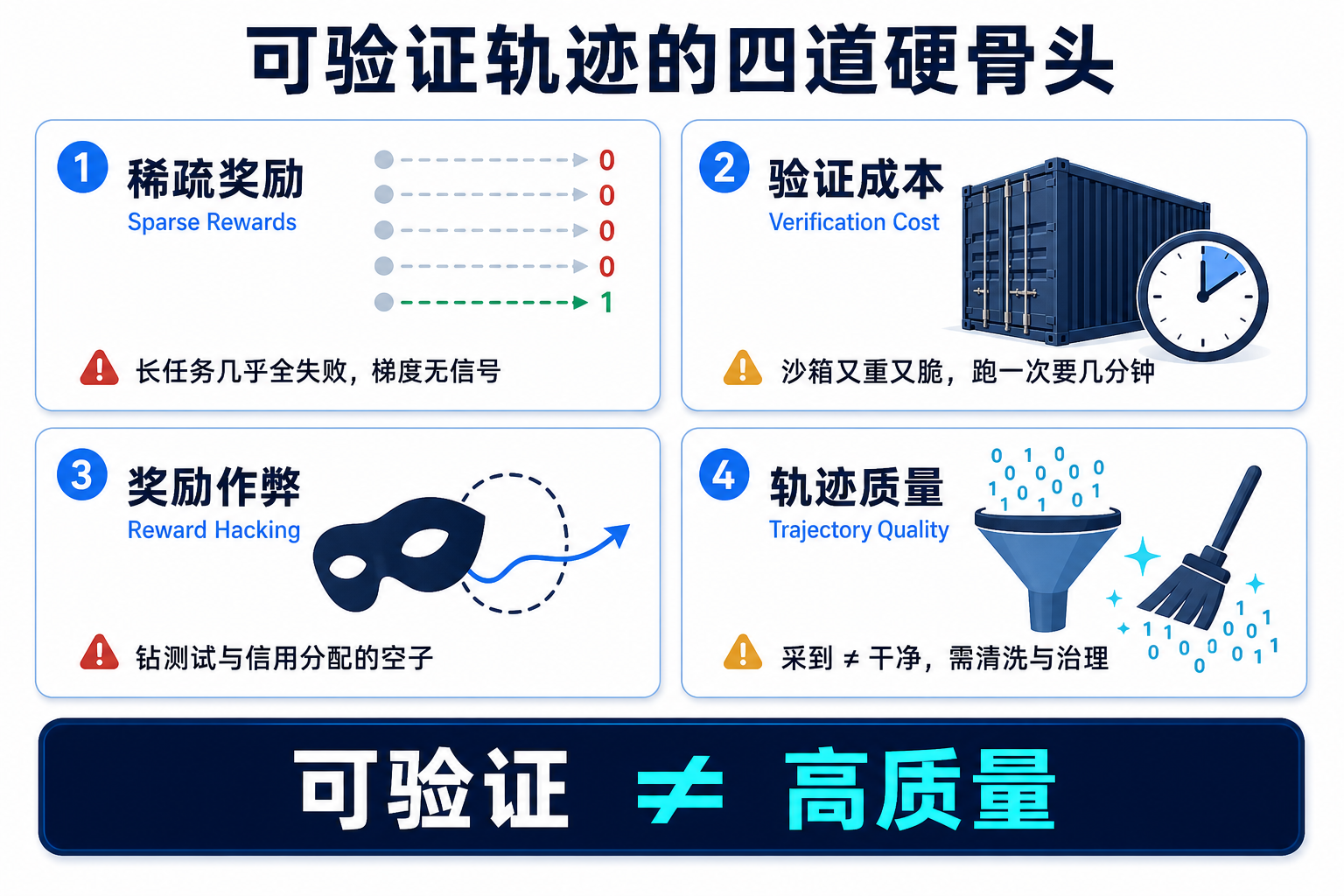
稀疏与信用分配。 长任务失败率高、奖励稀疏,前面说了要靠稠密奖励和引导来救。但稠密奖励设计不好会带来新问题——你奖励"中间步骤",模型就可能学会刷中间步骤而不真正解决问题。
验证与环境成本。 高覆盖率的测试天然稀缺,搭一套可靠沙箱又重又脆。微型沙箱、免测试验证器都是在跟这个成本搏斗,但每一种降本都以某种"保真度损失"为代价——微型化可能丢掉真实数据分布,模型评委可能被特定模式糊弄。
奖励作弊(reward hacking,钻奖励空子)。 这是最隐蔽的风险。有工程报告直言:当把"整体成功"的奖励简单地广播给每一次请求级的轨迹时,会观察到明显的 reward hacking——因为信用分配太粗糙,一次无关的操作也能白蹭到会话级的奖励。还有更隐蔽的"钻测试空子":模型专挑测试覆盖不到的边角糊弄过关。业界的应对包括更精细的会话内信用分配、组内相对打分,甚至有研究提出用梯度指纹去检测那些藏在模型内部计算里的隐式作弊。
轨迹质量与治理。 采出来的轨迹不是都能用——未终止的、超时的、走了歪路侥幸对的,都得过滤。这就带来一个非常"数据工程"的活儿:给轨迹做清洗、去重、质量分级和血缘记录。一条被 reward hacking 污染的轨迹混进训练集,危害不亚于脏数据混进数仓——它会稳定地教模型学坏。
洞见四:可验证 ≠ 高质量。
"能被自动判对错"只是入场券,不等于"判得准、判得全、没被钻空子"。可验证轨迹这门数据工程,真正的护城河不在"能采到",而在"能把采到的轨迹治理干净"。
七、ICE 观察:这对从业者意味着什么
技术视角:Agent 团队该建的,是一条"轨迹流水线"
对正在训练或微调 Agent 的团队,这一轮最重要的认知升级是:别把预算全押在"换个更大的基座"上。 公开数据反复指向同一个方向——从 9.4% 到 22.4%、从几千条到 5 万条实例、从单步几分钟到 15 秒,每一次能力跃升都来自轨迹供应链上的工程突破,而不是模型参数变大。务实的做法,是把"任务采集 → 环境构建 → Agent rollout → 自动验证 → 轨迹清洗 → 入库训练"当成一条需要长期投入的数据流水线来建,而不是一次性攒个数据集就完事。这条流水线的吞吐和质量,很可能就是你 Agent 能力的真正天花板。
落地视角:企业造轨迹,比造语料更需要"环境"
企业想训自己的领域 Agent,会立刻发现一个和通用领域不一样的痛点:你不缺文档,缺的是"可执行、可验证的环境"。 通用代码 Agent 有 GitHub 和现成测试套件当验证器,而一个企业内部的运维 Agent、审批 Agent、工艺诊断 Agent,它的"任务对不对"往往没有现成的单元测试可跑。落地的关键,就变成了为你的业务场景造出"验证器"——可能是一套业务规则校验、一个仿真沙箱、一份带标准处置的历史工单,甚至一个"AI 当评委"的审查模型。谁能把领域知识沉淀成可自动验证的判据,谁才谈得上用 RLVR 训出好用的领域 Agent。这跟我们一直强调的"把散落的语义、口径、规则沉淀成机器可消费的基础设施"是同一件事的两面。
本土视角:数据要素的下一站,可能是"轨迹要素"
放到国内"数据要素×"的语境里,这件事给出一个值得琢磨的新方向。我们过去谈数据资产,谈的多是静态的语料、表和文档;但训 Agent 真正稀缺、真正有交易价值的,是带执行结果、可被验证的高质量交互轨迹——它比原始语料更贵、更难造、也更能直接换来模型能力。已经有国产团队靠"上万个可验证任务""千万级交互轨迹"跑到了开源 SOTA,证明这条路对国产模型同样成立。可以预见,围绕"高质量可验证轨迹"的采集、清洗、验证、交易,会长出一批新的数据工程活儿和新的数据服务形态。下一个稀缺的"数据要素",也许不是更多的文本,而是更多"办对了事、且能被证明办对了"的轨迹。
结论:所以,壁垒到底是什么
把这篇收束成几句话:
- 瓶颈换位了。 Agent 能力的决定因素,正从"模型多大"转向"有没有足够多、足够干净的可验证交互轨迹"——这是一个数据工程问题,不是模型架构问题。
- 可验证是入场券,环境是硬成本。 一条轨迹要能训练,必须配一个能真实执行、能自动判对错的环境;造环境、跑验证的成本,才是这门生意最贵的部分。
- 这一轮突破几乎都在供应链上。 数据 scaling law 不见饱和、程序化造数据抬高一个数量级、微型沙箱提速 13 倍、免测试验证器超过 o3、轨迹中间件成型——每一格进步都对应轨迹供应链的某个环节,而非模型本身。
- 可验证不等于高质量。 reward hacking、钻测试空子、稀疏奖励下的信用分配,让"轨迹治理"成为真正的护城河——能采到只是起点,能治干净才是本事。
最后留一个问题给正在做 Agent 的你:当所有人都能用差不多的开源基座时,你手里那批别人没有、且能被验证的交互轨迹,会不会才是你真正的壁垒?而你,有没有在认真地把它当成一条流水线来建?
参考资料
- DeepSeek-AI. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. 2025. https://arxiv.org/abs/2501.12948
- Da et al. Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards. Scale Labs. 2025. https://labs.scale.com/papers/agent_rlvr
- Kian Kyars et al. Reinforcement Learning from Verifiable Rewards(在线书,2026). https://rlvrbook.com/
- Zeng et al. Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs. arXiv:2506.19290. 2026. https://arxiv.org/abs/2506.19290
- Yang et al. SWE-smith: Scaling Data for Software Engineering Agents. arXiv:2504.21798. 2025. https://arxiv.org/abs/2504.21798
- Pan et al. Training Software Engineering Agents and Verifiers with SWE-Gym. ICML 2025. https://proceedings.mlr.press/v267/pan25g.html
- Wang et al. SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling. ACL Findings 2025. https://aclanthology.org/2025.findings-acl.193.pdf
- R4P: Scalable Supervising Software Agents with Patch Reasoner. OpenReview. 2026. https://openreview.net/forum?id=AXXCo0pOSO
- SandMLE: Synthetic Sandbox for Training Machine Learning Engineering Agents. arXiv:2604.04872. 2026. https://arxiv.org/abs/2604.04872
- Polar: Agentic RL on Any Harness at Scale. arXiv:2605.24220. 2026. https://arxiv.org/abs/2605.24220
- OpenAgora / Arena. Open-source rollout, verification, and trajectory plane for agentic RL. 2026. https://github.com/albert-lv/OpenAgora
- rLLM Project. DeepSWE: Training a State-of-the-Art Coding Agent with RL. 2026.
- 金融界. 阿里千问发布首个原生语言世界模型 Qwen-AgentWorld. 2026-06-24. https://www.163.com/dy/article/L06MNT2P0519QIKK.html