Agent Harness 全景综述:谁在定义 AI Agent 的操作系统层
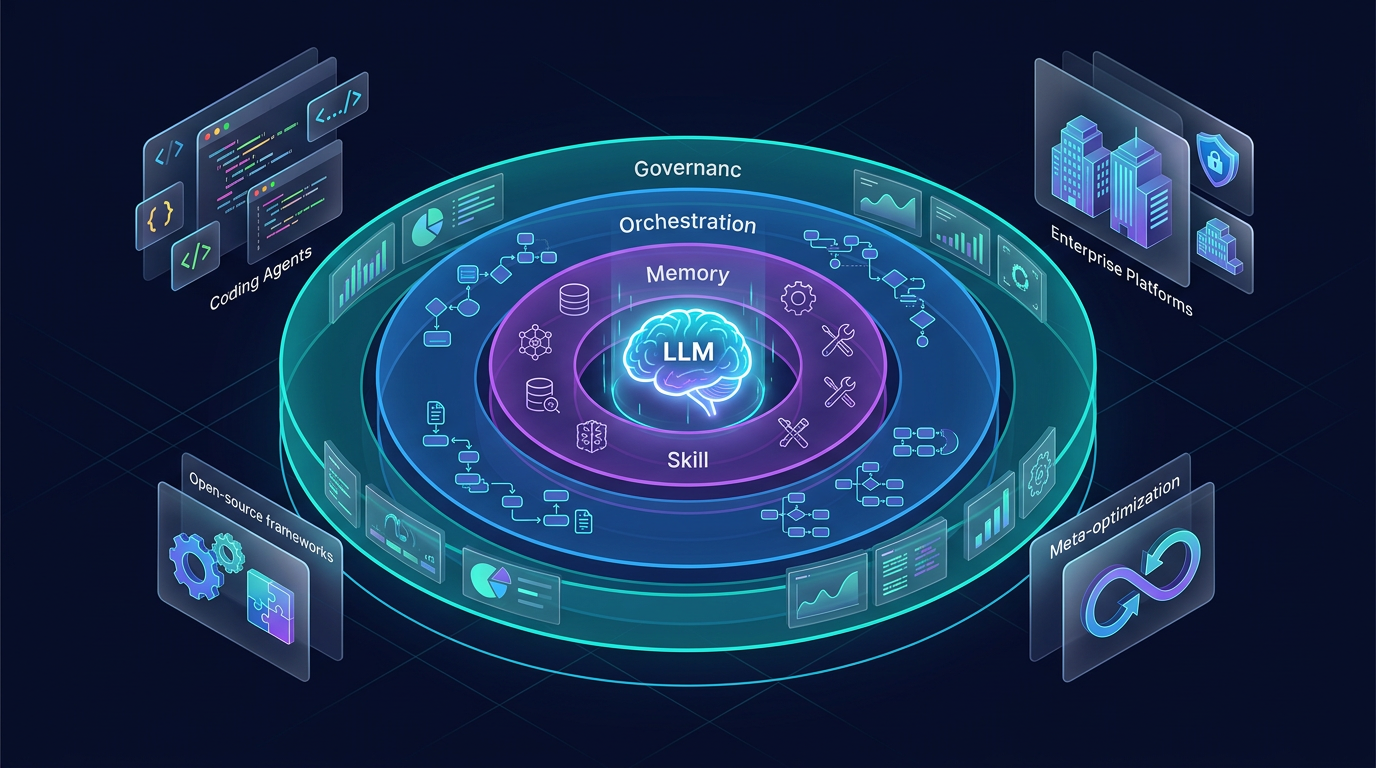
TL;DR — Harness 是围绕 LLM 的那层代码——决定存储什么、检索什么、呈现给模型什么。Stanford 实验证明同一个模型换 Harness 性能差 6 倍。2026 年 Q1,从 Claude Code 到 Databricks Agent Bricks,从 OpenClaw 到 Meta-Harness,Harness 已经从"胶水代码"进化为 Agent 产业的核心架构层。本文按四个梯队梳理全景。
一、Harness 不是新概念,但正在被重新定义
Harness 在软件工程中由来已久——test harness、evaluation harness 都是老概念。在 LLM/Agent 领域,harness 泛指模型周围的那层代码。
2026 年 3 月,Stanford 联合 KRAFTON、MIT 发表的 Meta-Harness 论文(arXiv:2603.28052)给出了迄今最精确的形式化定义:
LLM 系统的性能不仅取决于模型权重,还取决于 harness——决定存储什么、检索什么、呈现给模型什么的那层代码。
论文的核心实验发现震动了业界:
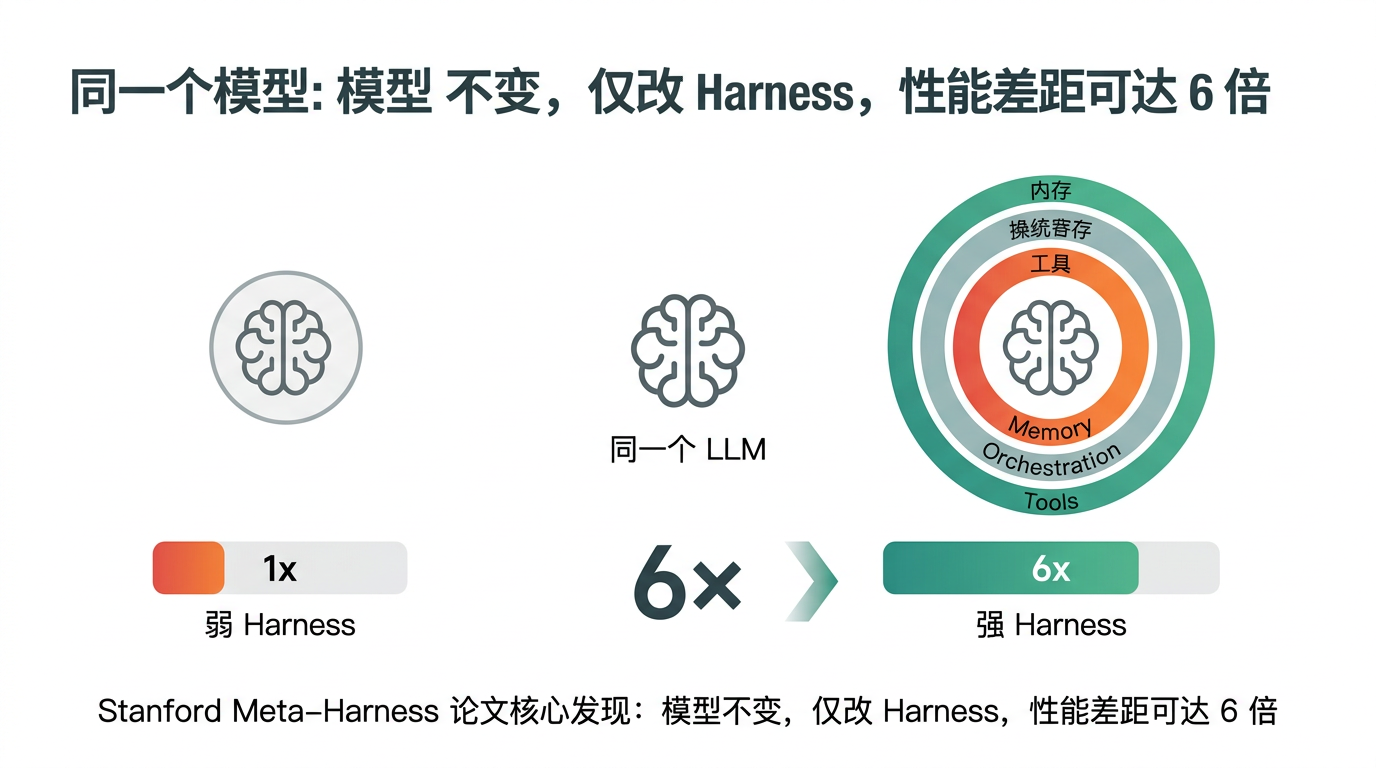
同一个 LLM,仅更换 Harness,性能差距可达 6 倍。 这打破了"模型决定一切"的迷思——如果你只关注选哪个模型,却忽视 Harness 设计,你可能连模型能力的 1/6 都没发挥出来。
详细论文解读见 👉 Meta-Harness:让 AI 自动优化 AI 的"外壳"
Y Combinator CEO Garry Tan 将这种认知浓缩为一个公式:Thin Harness, Fat Skills——Harness 层要薄,让模型能力穿透;Skills 要厚,让领域知识沉淀。但"薄"不等于"简单"。我们接下来会看到,最成功的 Harness 实现恰恰在"看起来薄"的背后,藏着极其精密的工程设计。
那么,2026 年的 Harness 生态究竟长什么样?谁在领跑?
二、四大梯队全景
2026 年 Q1,Harness 生态分化出四个清晰的梯队。我们用两个维度来定位——纵轴是产品化程度(框架还是开箱即用产品),横轴是 Harness 深度(轻量编排还是深度 Agent 原生集成):
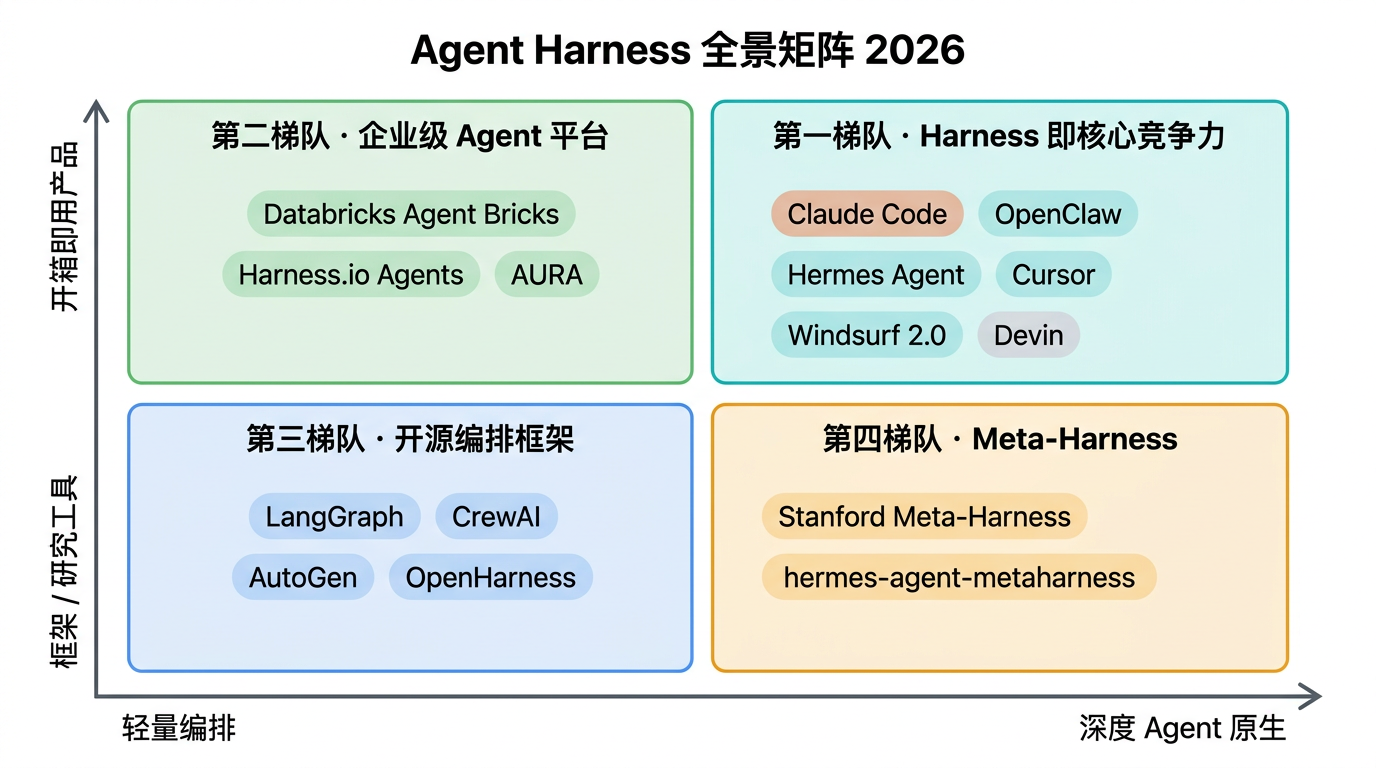
右上角是领导者——Harness 层做得最深、产品化程度最高的一批。左下角是构建积木——框架级工具,需要自行组装。下面逐一展开。
第一梯队:Harness 即核心竞争力
这些产品的胜负手不在模型,而在 Harness。模型可以换,Harness 不能弱。
Claude Code 拥有当前业界最成熟的 Harness 架构。核心文件 QueryEngine.ts 达 46,000 行,Agent 循环遵循 TAOR 模式(Think → Act → Observe → Repeat),每个工具调用流经三级权限检查(静默放行 / 提示用户 / 阻止)。四层 Harness 结构清晰:
| 层 | 职责 | 特征 |
|---|---|---|
| CLAUDE.md | 跨会话长期记忆 | 技术栈、代码规范、禁止操作、架构概览 |
| Skills | 领域专长与流程自动化 | 按需调用,封装可复用的任务解决方案 |
| Hooks | 确定性执行门控 | 事件匹配触发,不经过模型判断 |
| Subagents | 隔离并行执行 | 独立上下文,并行处理子任务 |
Vercel 重构 Agent 的 Harness 后——模型没换——成功率从 80% 跳到 100%,速度提升 3 倍,Token 消耗降低 37%。
OpenClaw(TypeScript,361K+ stars)走了另一条路:把 Harness 收窄为接口极窄的可插拔执行器。三层分离——Gateway(控制平面)→ Agent Loop(认知层)→ Harness Plugin(执行层),注册一个 Harness 只需 supports() + runAttempt() 两个方法。代价是 Harness 层没有学习能力,智能完全依赖上游模型和人工配置。
Hermes Agent(Python,95K+ stars)完整接受 Meta-Harness 论文的定义并扩展——Harness 不仅是围绕模型的代码,还应在使用中自我改进。AIAgent 类(~10,700 行)集编排与执行于一体,三层记忆(Session / Persistent / Skill)构成闭环学习飞轮。Nous Research 报告:拥有 20+ 自创 Skills 的 Agent 完成研究任务快 40%。
OpenClaw 与 Hermes 的深度架构对比见 👉 OpenClaw vs Hermes Agent:两种 Harness 哲学的深度对比
Cursor / Windsurf 2.0 / Devin 代表了 IDE 级 Harness 竞赛的三种姿态:Cursor 是"人在回路中"——增强工作流但方向盘在你手里;Devin 是"全自主"——给定目标后完全接管(40 模型 ORM 迁移 4 小时 vs 人工 2 天);Windsurf 2.0(2026-04 发布)试图兼得——日常编码用 IDE Agent,后台任务丢给 Devin。
梯队小结:第一梯队的共同特征是 Harness 层拥有独立的工程投入——不是模型的附属品,而是独立的架构层。分歧在于 Harness 是"可替换的引擎"(OpenClaw)还是"可进化的有机体"(Hermes),但胜负手都在 Harness。
第二梯队:企业级 Agent 平台
如果说第一梯队回答的是"如何让 Agent 更智能",第二梯队回答的是"如何让 Agent 在企业里安全、合规、大规模地跑起来"。
Databricks Agent Bricks(2026 年 GA)是这个梯队的标杆。核心能力三板斧:模型抽象层(可切换模型而无需重建系统)、统一治理(访问 / 执行 / 上下文 / 权限一平台管控)、生产级可观测性(全链路追踪和审计)。已有金融、零售、医疗、科技等行业千家企业生产部署。战略意图清晰——做 Agent 时代的数据平台,就像 Databricks 做了大数据时代的 Lakehouse。
Harness.io Agents(Limited Preview)从 DevOps 切入:AI Agent 作为 Pipeline 一等公民,继承上下文 / 权限 / 密钥 / 治理控制,内置覆盖 pipeline 和基础设施的 Knowledge Graph,预置 CI 自动修复、CD 补救、代码审查等 System Agents。
AURA(Mezmo,Rust 开源)面向生产级 AI 基础设施:声明式 TOML 配置、DAG 多 Agent 编排、依赖感知的并行执行、深度可观测性。设计哲学是"Harness 即基础设施"——与全文主线"Harness 下沉为 Agent OS"高度吻合。
梯队小结:第二梯队的共同特征是从已有的基础设施"向上长"出 Agent 能力——Databricks 从数据平台长、Harness.io 从 DevOps 长、AURA 从可观测性基础设施长。它们天然拥有治理能力,这是第一梯队需要补课的地方。
第三梯队:开源编排框架
第三梯队提供 Harness 的构建积木。它们是许多 Agent 项目的起点,但要走进生产环境,都需要在上面再叠一层"产品级 Harness"。
| 框架 | 核心抽象 | 2026 关键数据 |
|---|---|---|
| LangGraph | 显式状态机,控制力最强 | 任务完成率 87%,Token 开销 +9%,生产部署占比约 40% |
| CrewAI | 角色化 Crew,上手最快 | 首个原型约 25 分钟,45,900+ stars,长流程弱 |
| AutoGen | 会话式多 Agent 消息传递 | 研究密集型任务最佳,Token 开销 +31% |
| OpenHarness | 基于 Vercel AI SDK 的通用框架 | 无状态 Agent + 子 Agent 委托 + MCP 集成 |
三大主流框架的 Benchmark 对比:
| 指标 | CrewAI | LangGraph | AutoGen |
|---|---|---|---|
| 研究综合任务(中位耗时) | 18.4s | 14.1s | 22.7s |
| 代码审查任务(中位耗时) | 9.1s | 8.3s | 11.6s |
| 每千次研究任务成本 | $48.20 | $41.70 | $67.40 |
| Token 开销 | +18% | +9% | +31% |
LangGraph 在控制力和成本效率上领先,但学习曲线最陡(6.8/10)。CrewAI 最易上手(3.5/10),但复杂长流程力不从心。AutoGen 擅长研究密集型任务,但 Token 开销最高。
梯队小结:三个框架都需要额外的"harness work"才能进入生产环境——没有一个开箱即用。 这正是第一、二梯队产品级 Harness 的存在价值:你可以把它们理解为"已经做完了 harness work 的框架"。
第四梯队:Meta-Harness — Harness 的 Harness
最后这个梯队最前沿,也最"meta"——用 AI 自动优化 Harness 本身。
Stanford 的 Meta-Harness 把"如何优化 Harness"交给 Coding Agent。Proposer(Claude Code Opus 4.6)读取文件系统中所有历史候选方案的源码、得分和执行 trace(每步高达 10M tokens 的诊断上下文),然后自动写出更好的 Harness。
| 场景 | 提升 |
|---|---|
| 在线文本分类 | 超 SOTA +7.7 分,同时省 4× context tokens |
| 数学推理(200 道 IMO 级) | 跨 5 个未见模型平均 +4.7 分 |
| Agentic Coding(TerminalBench-2) | 76.4% pass rate(Opus 4.6 #2),Haiku 4.5 #1 |
Proposer 的搜索轨迹尤为精彩——7 轮迭代完成了发现混淆变量→控制变量验证→确认修改脆弱区域风险高→转向安全的加性修改的完整工程推理闭环。只给分数做不到这种推理,正是因为能访问完整的历史代码和执行日志,Coding Agent 才能像人类工程师一样做因果分析。
目前 Hermes Agent 在独立仓库 hermes-agent-metaharness 中实现了 Meta-Harness 搜索循环,是唯一将其集成到产品中的开源项目。
梯队小结:第四梯队目前还是"远见者"——研究属性强、尚未产品化。但它指明了方向:当 Coding Agent 足够强时,"优化 Harness"本身就成为一个可以自动化的搜索问题。 这是一个正反馈循环——Coding Agent 越强,发现的 Harness 越好,Agent 整体越强。
三、三种核心架构模式
四个梯队的产品各异,但纵观之下,可以提炼出三种底层的 Harness 架构模式:
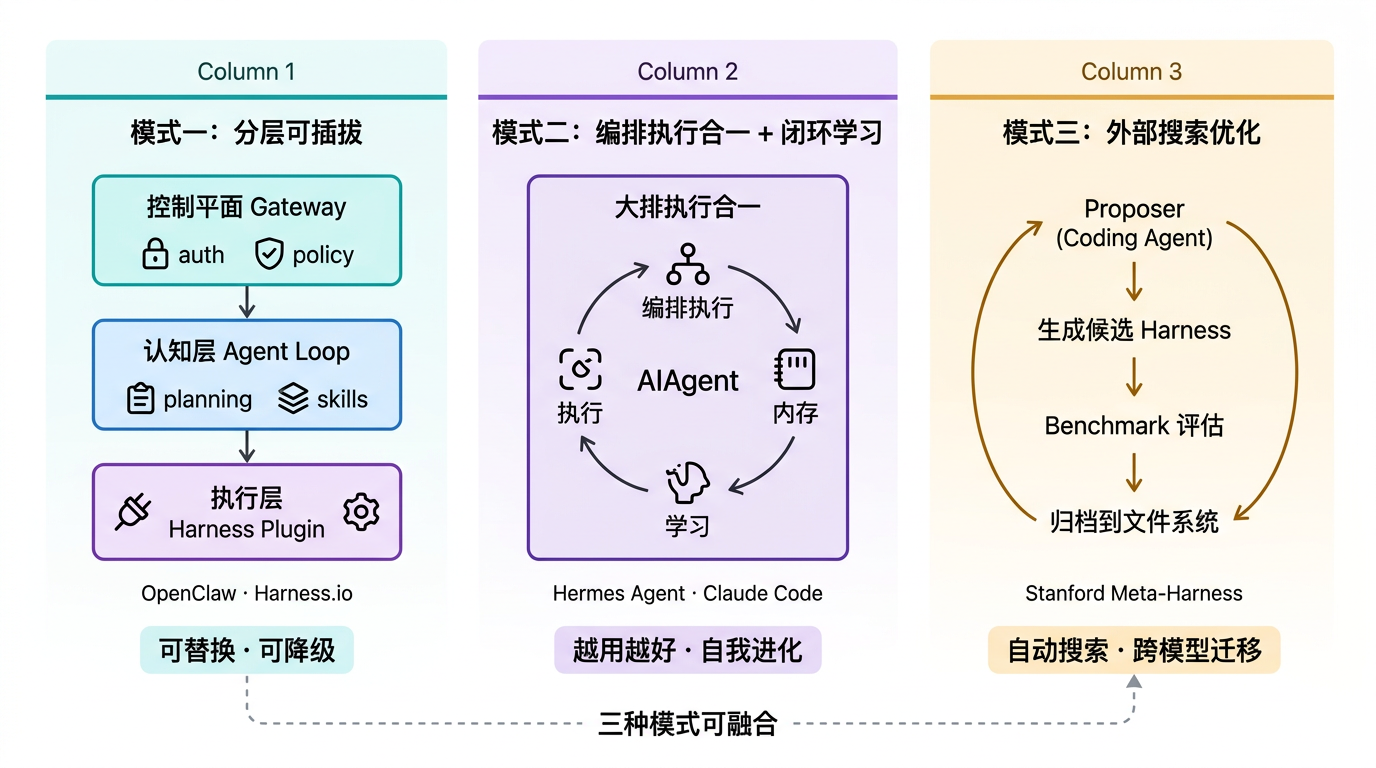
模式一:分层可插拔(代表:OpenClaw、Harness.io)
控制平面 → 认知层 → 执行层,三层分离。Harness 是窄接口插件,可替换、可 fallback。控制权在上层,Harness 只管"跑这一个 turn"。优势是可组合性高、责任边界清晰、出错可降级;代价是 Harness 层无学习能力。
模式二:编排执行合一 + 闭环学习(代表:Hermes Agent、Claude Code)
编排与执行不分层,Harness 能直接感知上下文压力和记忆状态,内置学习循环,在使用中自我改进。优势是支持自我进化,垂直场景越用越好;代价是系统复杂度高、定制门槛高。
模式三:外部搜索优化(代表:Meta-Harness)
不改模型,不改数据,只改 Harness 代码。Proposer 拥有完整历史的源码、分数和执行 trace,自动搜索最优配置。优势是发现的策略可读、可迁移、跨模型有效;代价是需要清晰的评估基准和结构化日志体系。
三种模式不互斥。 Hermes Agent 同时实现了模式二和三;Claude Code 以模式二为主,但 Skills 和 Hooks 带有模式一的可组合特征。未来最强的 Harness 系统很可能是三种模式的融合——可插拔的执行层 + 闭环学习的认知层 + 外部搜索的优化层。
四、五个核心战场
架构模式决定了"怎么建 Harness",而真正决定产品胜负的,是以下五个维度上的工程深度。
| 战场 | 核心问题 | 当前最佳实践 |
|---|---|---|
| 可观测性 | 黑盒 Agent 不可能进入生产环境 | Claude Code 19-40 个权限门控工具每步可追溯;Databricks 全链路追踪审计;AURA 为复杂推理工作流设计深度可观测 |
| 记忆管理 | 没有记忆的 Agent 只是高级 Prompt | Hermes 三层记忆(Session / Persistent / Skill)+ FTS5 索引;Claude Code CLAUDE.md 跨会话记忆 + Skills |
| 模型抽象 | 好的 Harness 不应绑死一个模型 | Databricks 可切换模型无需重建系统;OpenClaw 两方法极简抽象接口;Meta-Harness 发现的策略跨 5 个未见模型有效 |
| 安全治理 | Agent 替人操作系统,数据边界更模糊 | OpenClaw 独立 Gateway 控制平面;Harness.io 继承 Pipeline 权限密钥;Claude Code 三级权限体系 |
| Token 效率 | Harness 引入额外开销,但好 Harness 能省出来 | Meta-Harness 准确率超 SOTA 7.7 分且 Token 仅 1/4;80 行环境引导省 2-4 轮探索;Vercel 重构 Harness Token 降 37% |
一个值得关注的规律:第一梯队在记忆管理和 Token 效率上领先,第二梯队在安全治理和可观测性上领先,模型抽象是双方都在发力的交叉地带。这也解释了为什么两个梯队正在相向而行——第一梯队补治理短板(Claude Code 加了三级权限),第二梯队补 Agent 原生深度(Databricks 接入 LangGraph)。
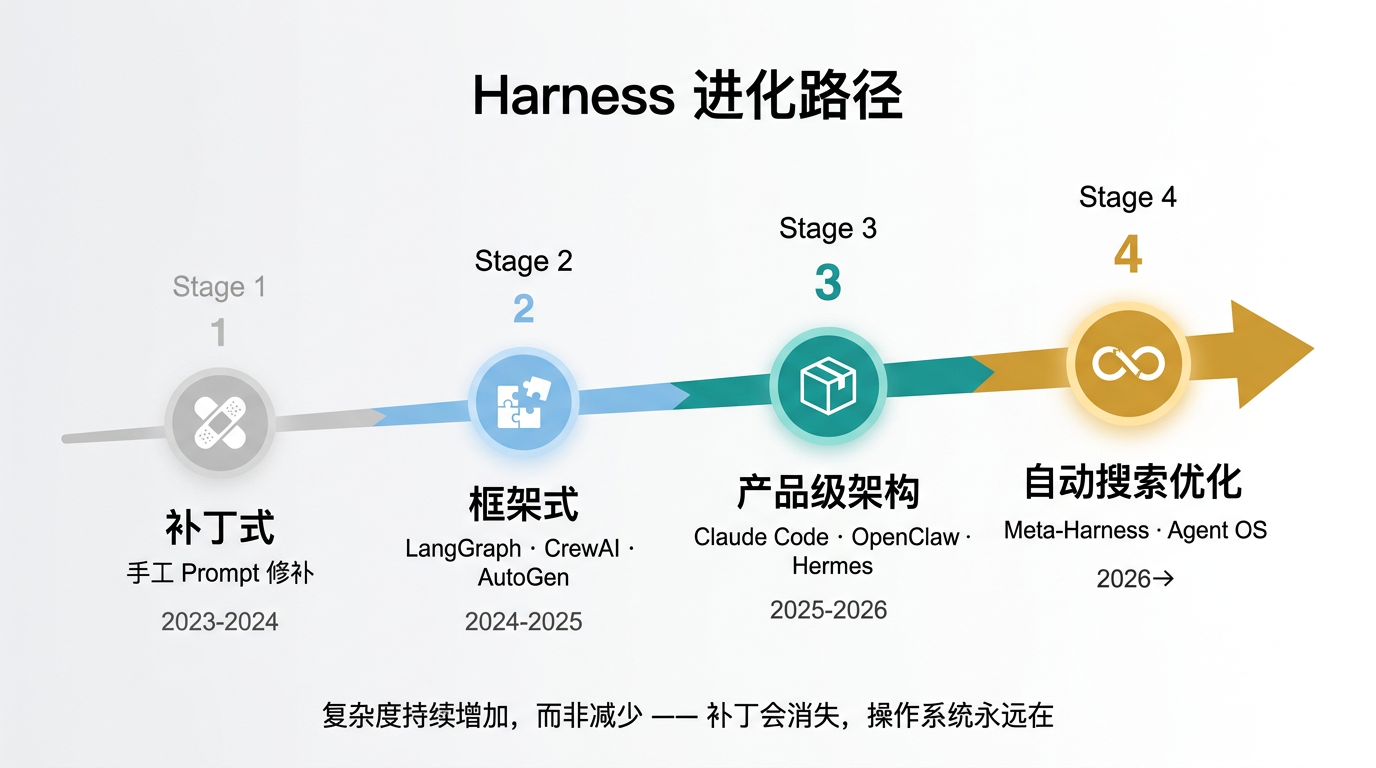
五、终局:Harness 的进化路径与 Agent OS
Gartner 预测:到 2026 年底,40% 的企业应用将包含任务专用 AI Agent(2025 年不到 5%)。但同一份报告指出:80% 的实施时间消耗在数据工程和治理上,而非框架配置。 Harness 的核心价值不在于提供又一个编排框架,而在于解决这"80%"的痛点。
回顾 2026 年 Q1 的全景,四个趋势已经清晰:
1. Harness 不会消失,正在加速进化。 从手工 Prompt 修补(补丁式)→ 框架化编排(LangGraph、CrewAI)→ 产品级架构(Claude Code、OpenClaw)→ 自动搜索优化(Meta-Harness),复杂度在持续增加,而非减少。
2. 架构,而非模型质量,决定了生产 Agent 的成败。 Vercel 的案例(同模型换 Harness:成功率 80%→100%)、Meta-Harness 的实验(同模型换 Harness:性能差 6 倍)、Nous Research 的数据(有 Skills 的 Agent 快 40%)——都指向同一个结论。
3. Harness 正在下沉为基础设施层。 就像容器编排从应用关注点变成了 Kubernetes,Agent Harness 正在从应用层下沉为 Agent OS。AURA 的"Harness 即基础设施"定位、Databricks 的平台化策略、OpenClaw 的三层分离设计,都是这个趋势的体现。
4. 三种架构模式正在融合。 可插拔的执行层 + 闭环学习的认知层 + 外部搜索的优化层——未来最强的 Agent 系统很可能同时具备这三种能力。
补丁会消失,但操作系统永远在。Harness 的终局是 Agent OS。
附录:Harness 系列文章导航
本文是 Harness 系列的综述篇。如果你对某个方向感兴趣,可以深入阅读:
| 文章 | 聚焦点 |
|---|---|
| Thin Harness, Fat Skills:YC CEO 的架构心法 | Garry Tan 的 Harness 设计哲学 |
| OpenClaw vs Hermes Agent:两种 Harness 哲学的深度对比 | 可插拔引擎 vs 可进化有机体的架构拆解 |
| Meta-Harness:让 AI 自动优化 AI 的"外壳" | Stanford 论文深度解读 |
参考资料