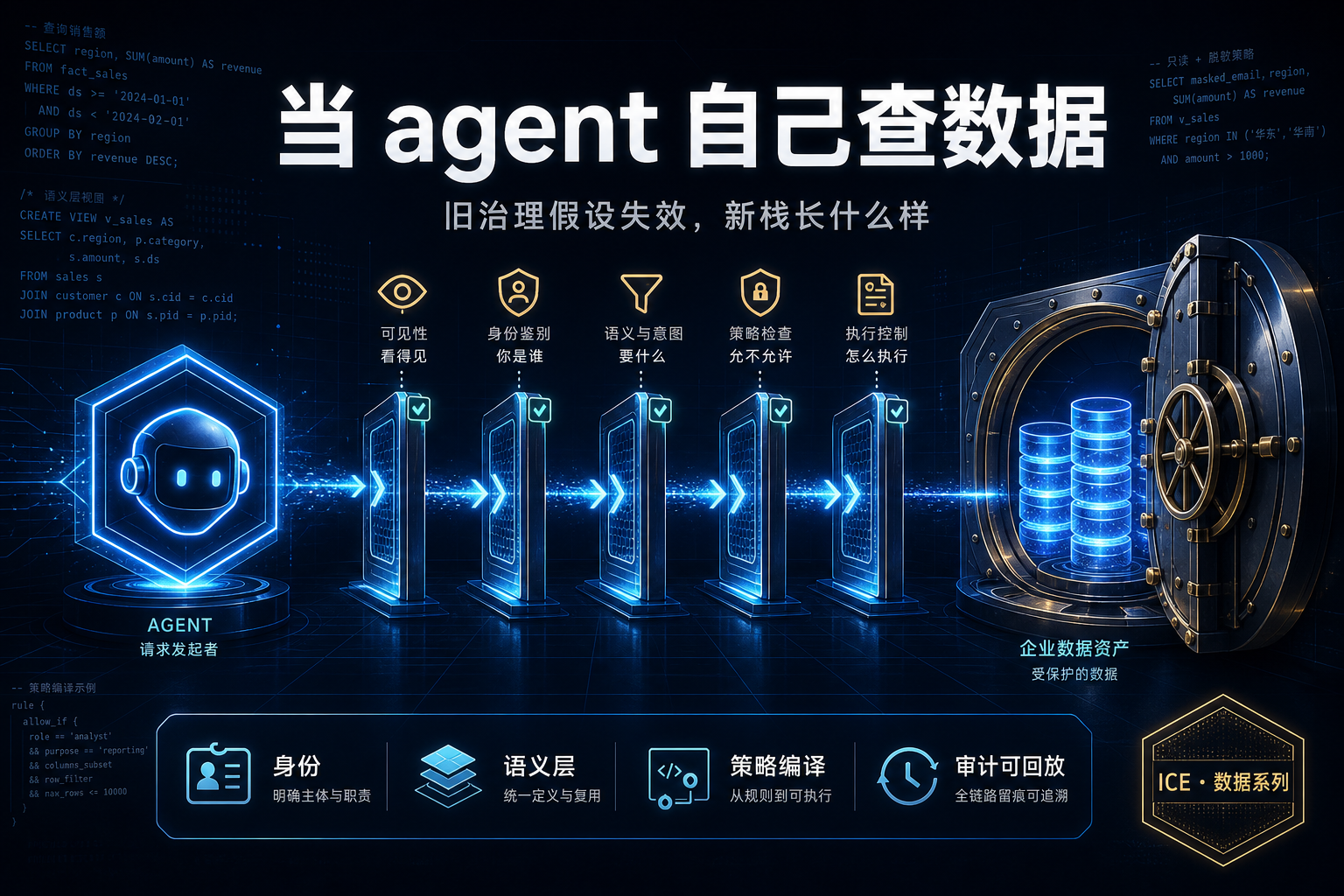
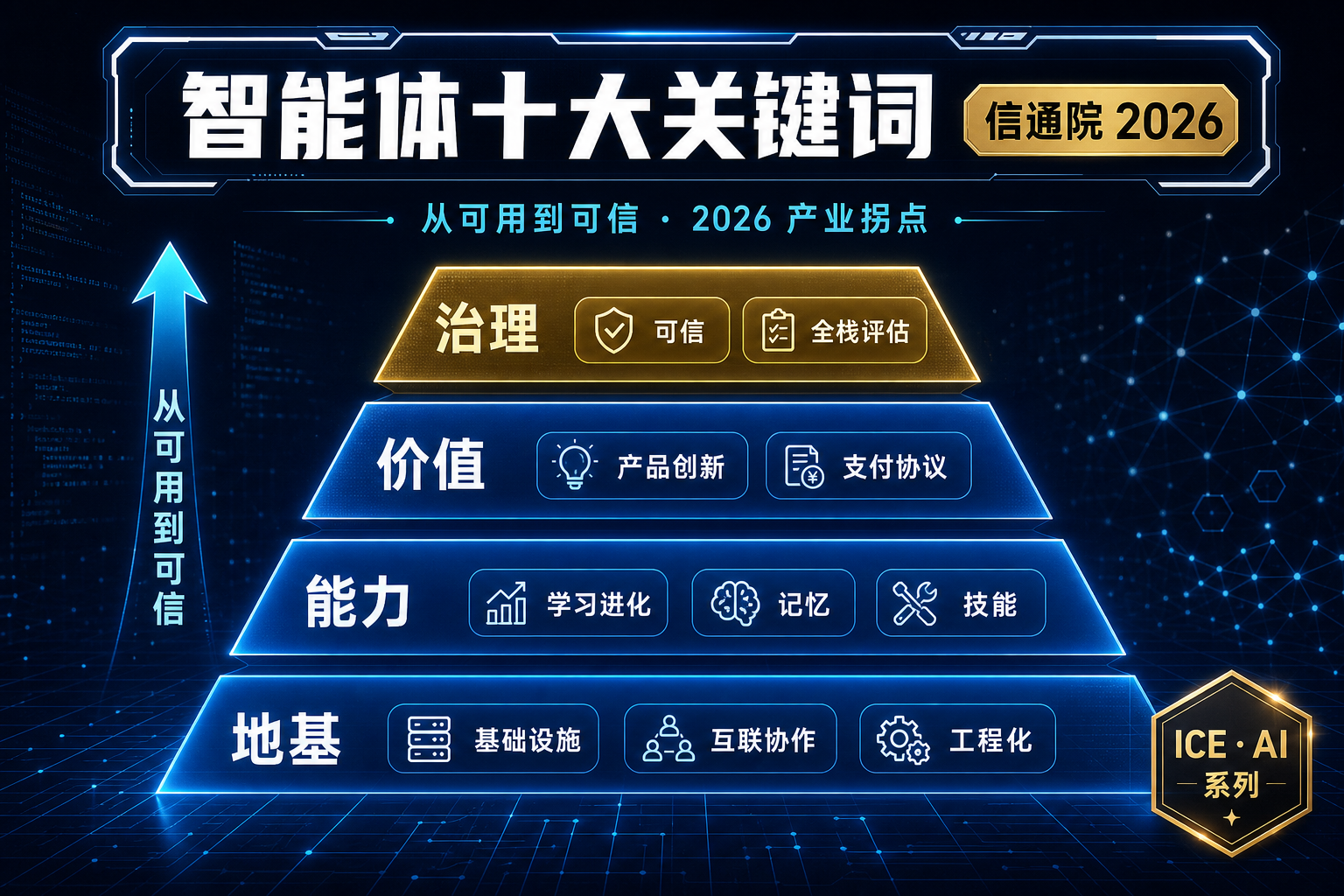
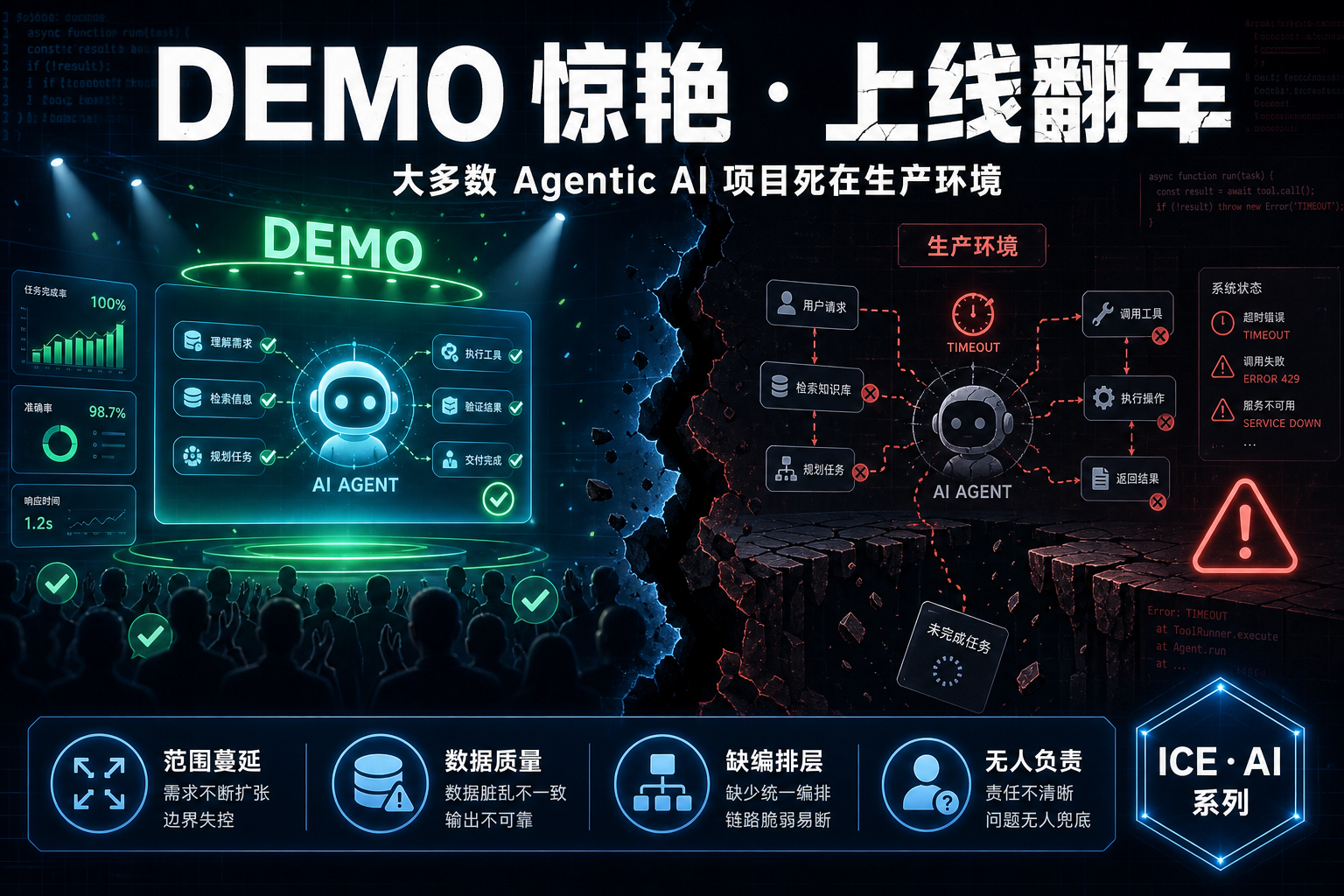
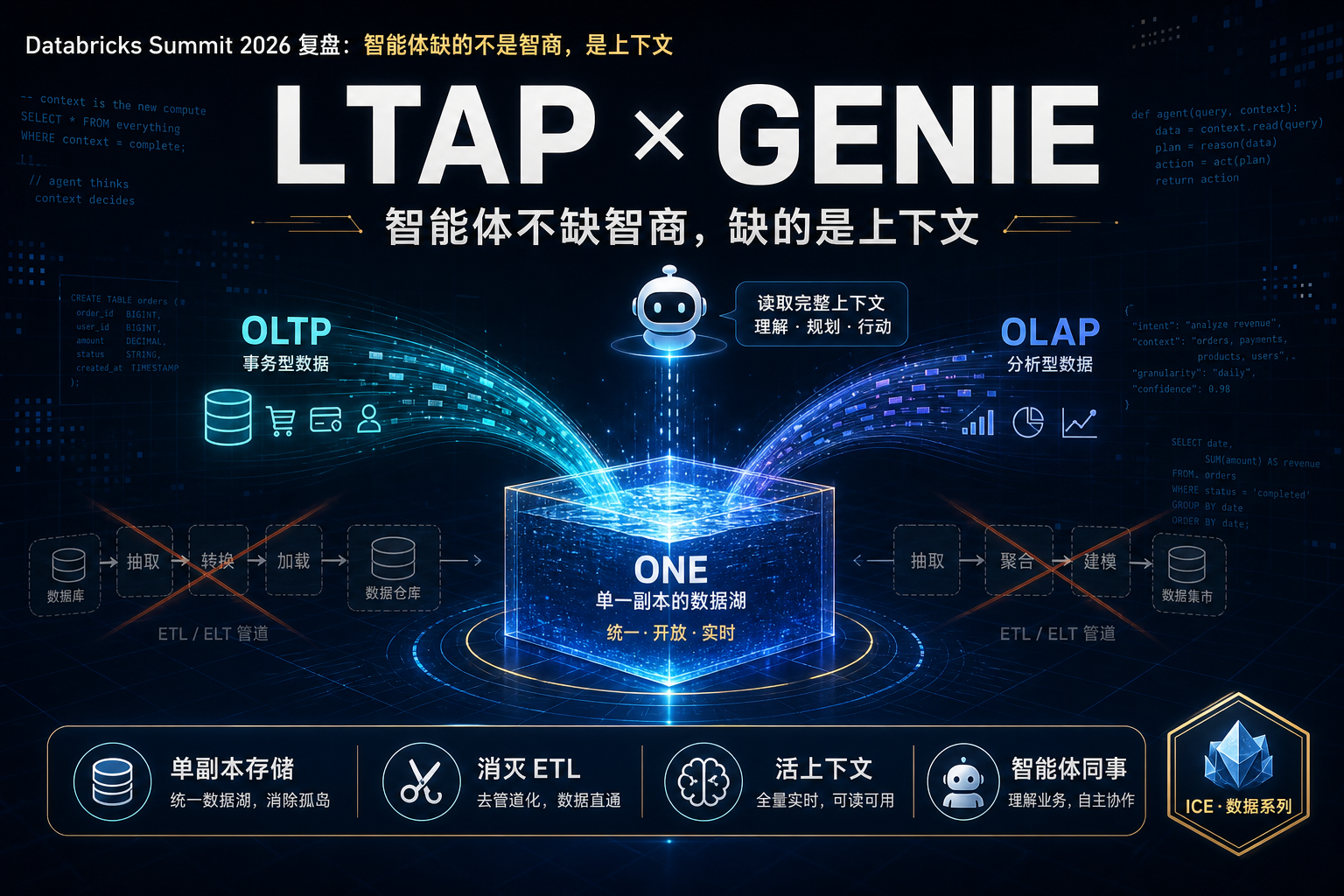
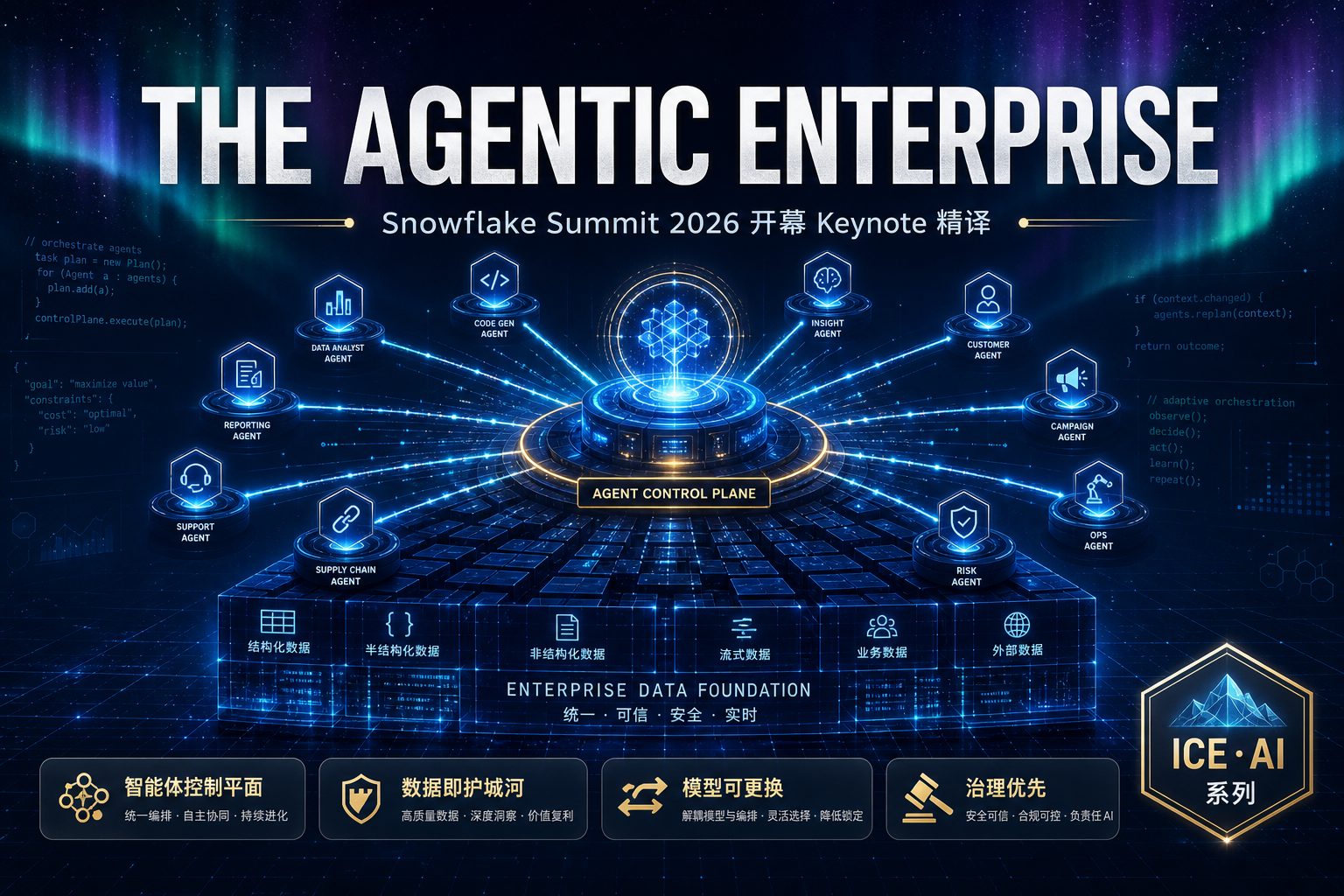
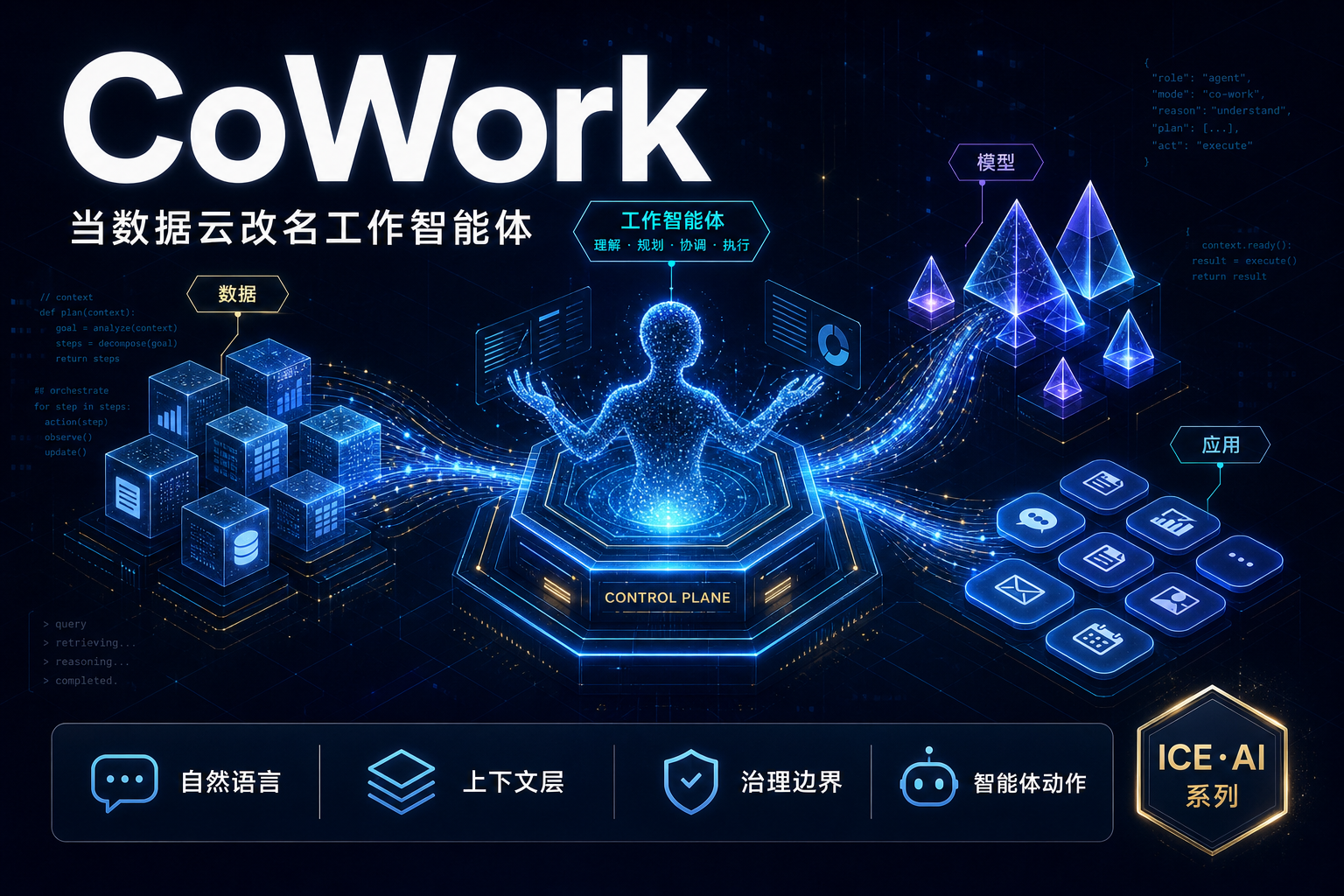
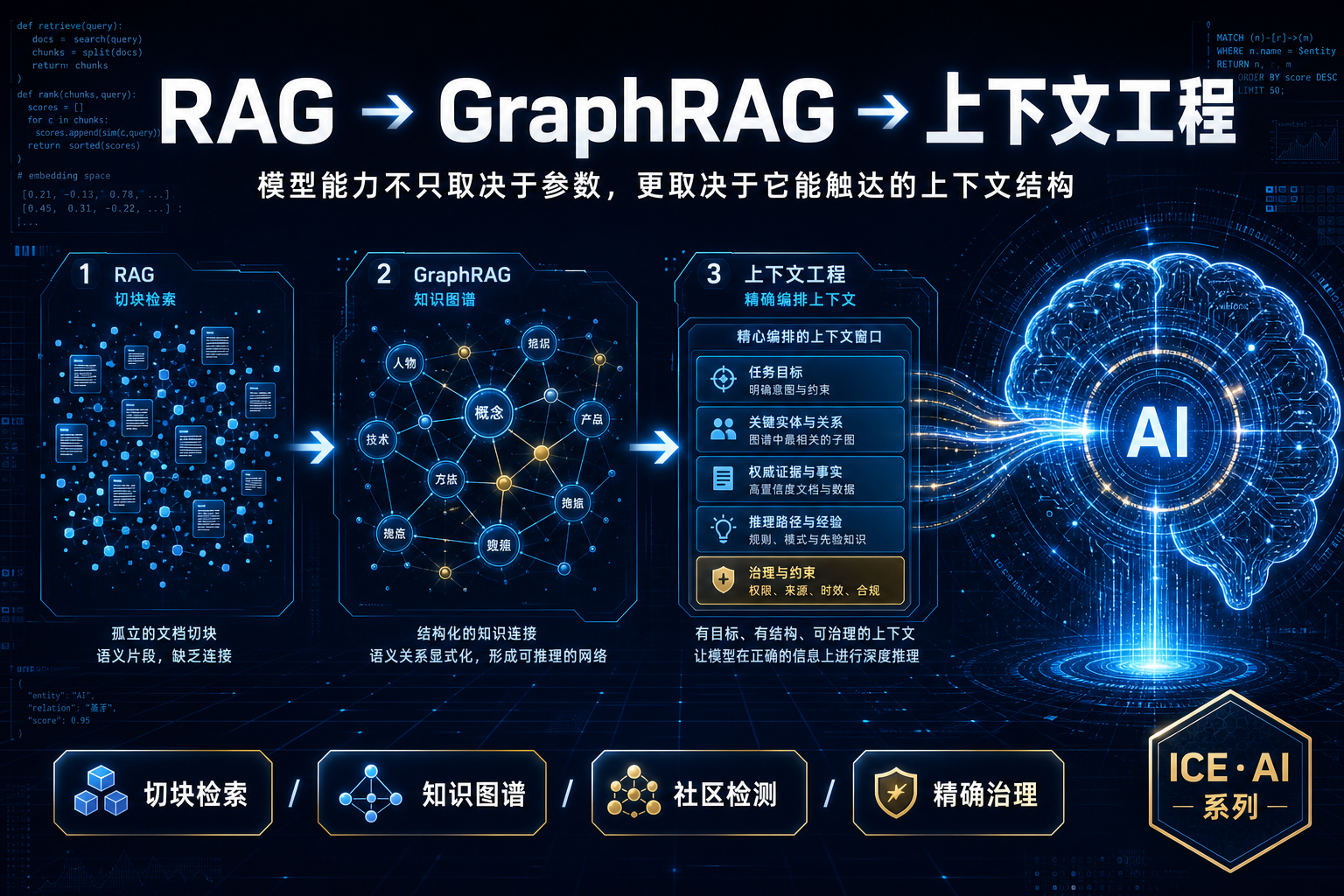
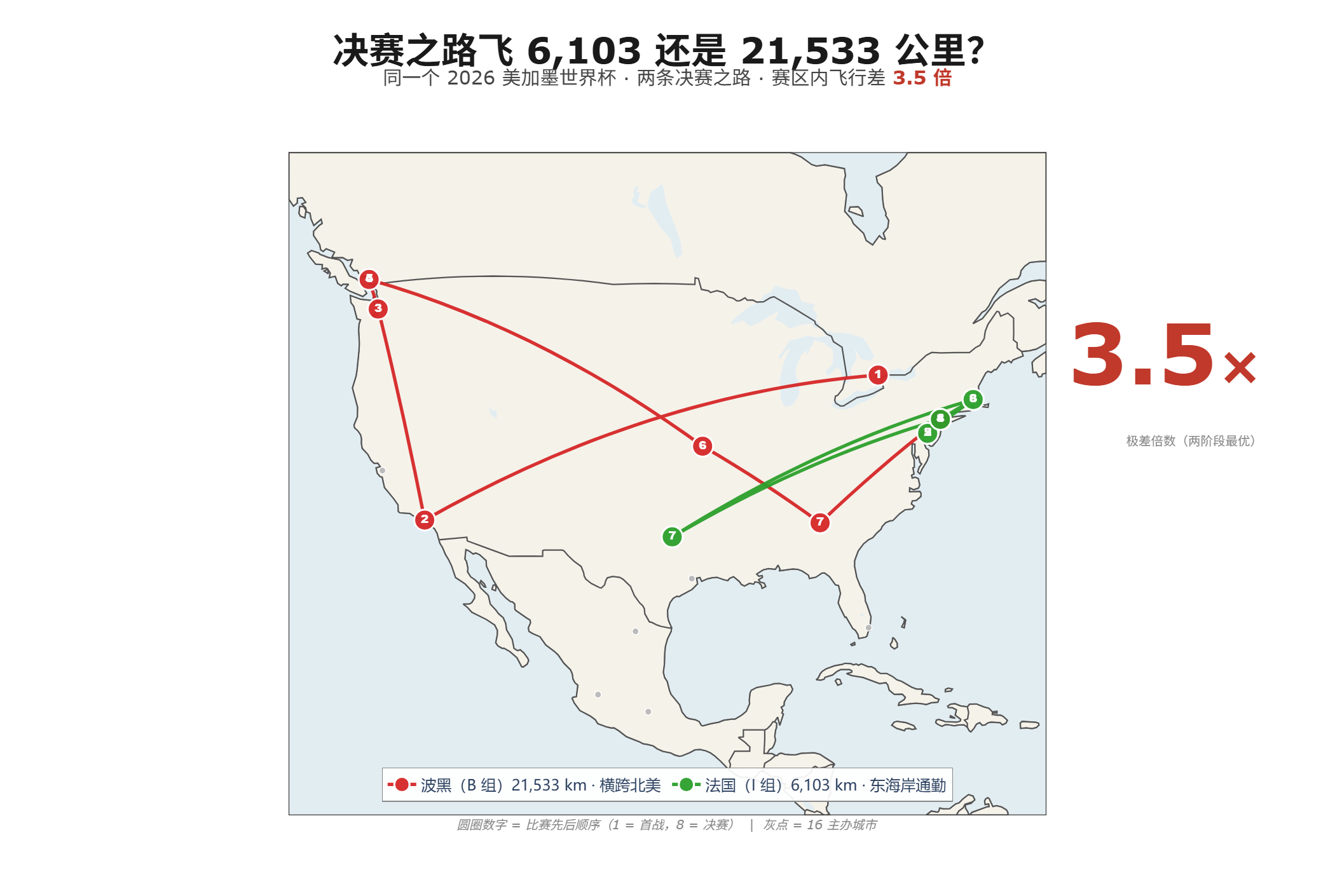
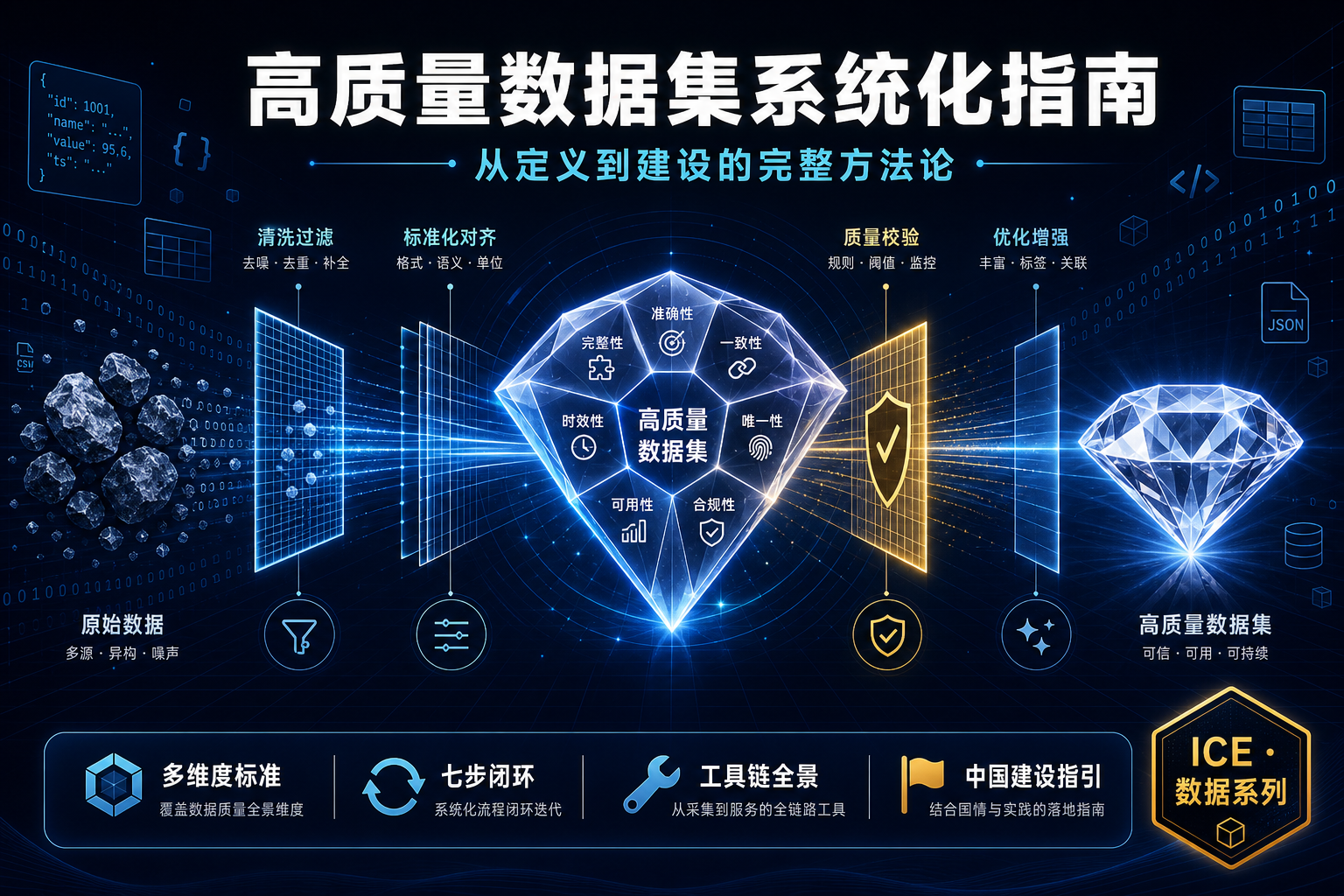
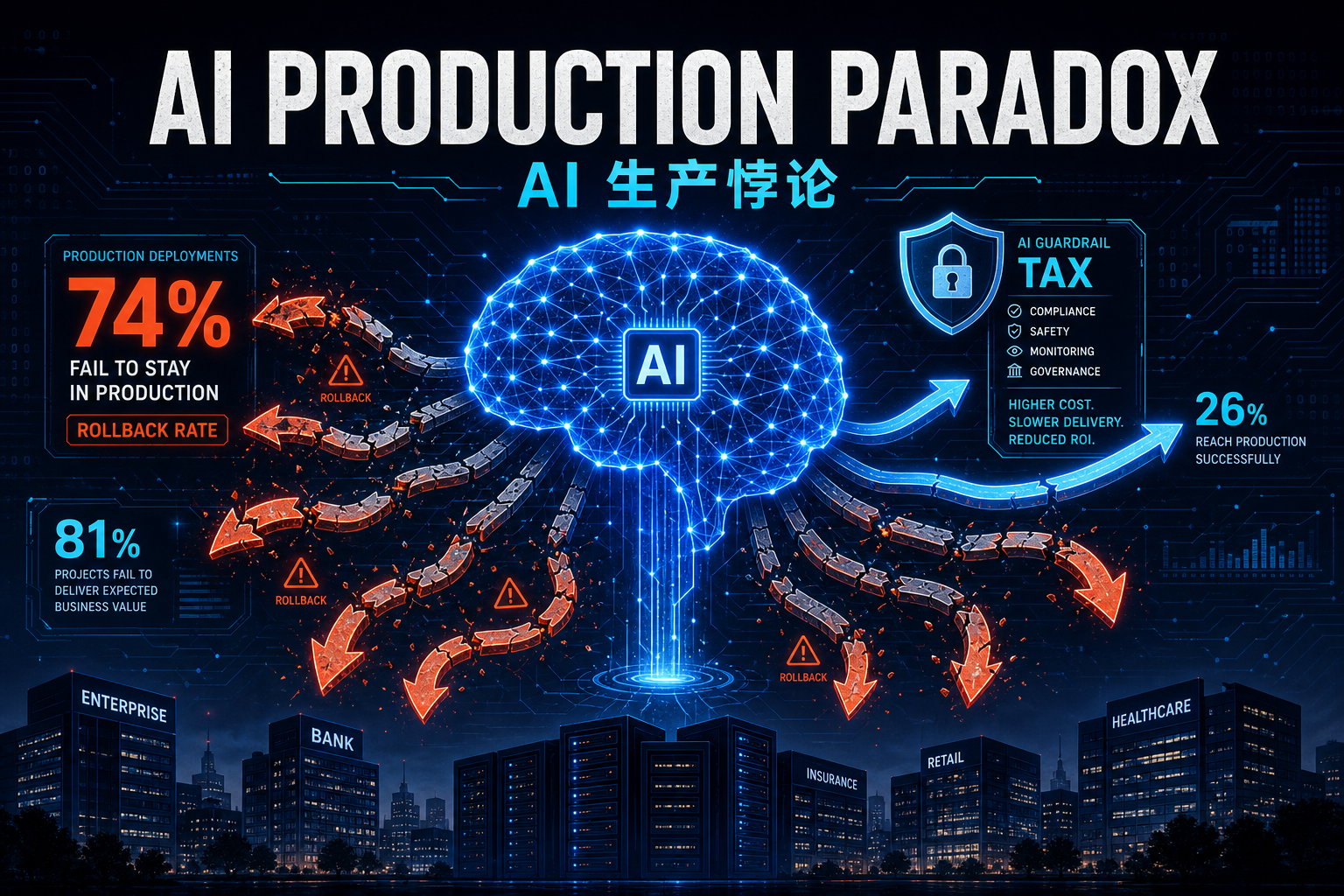
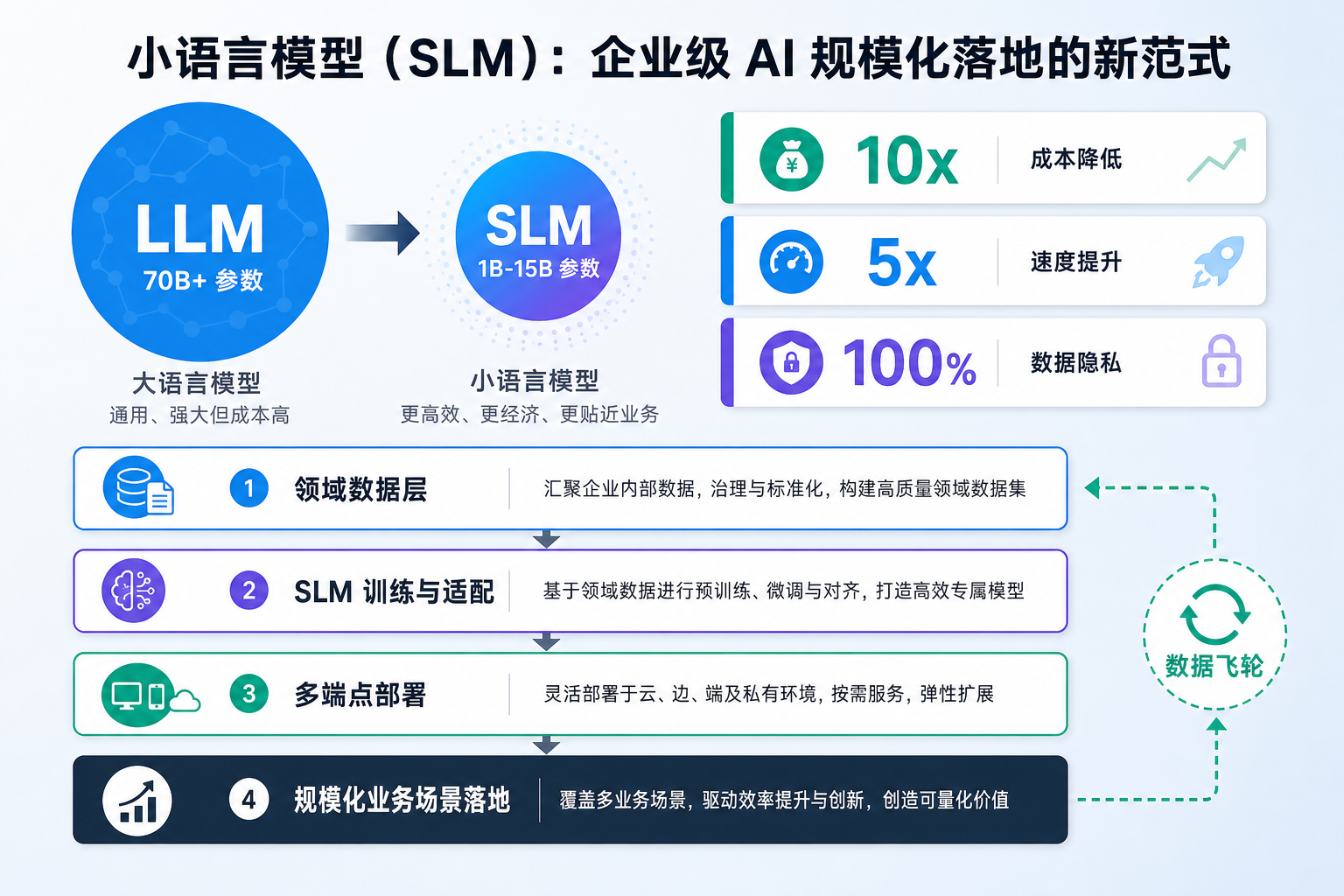
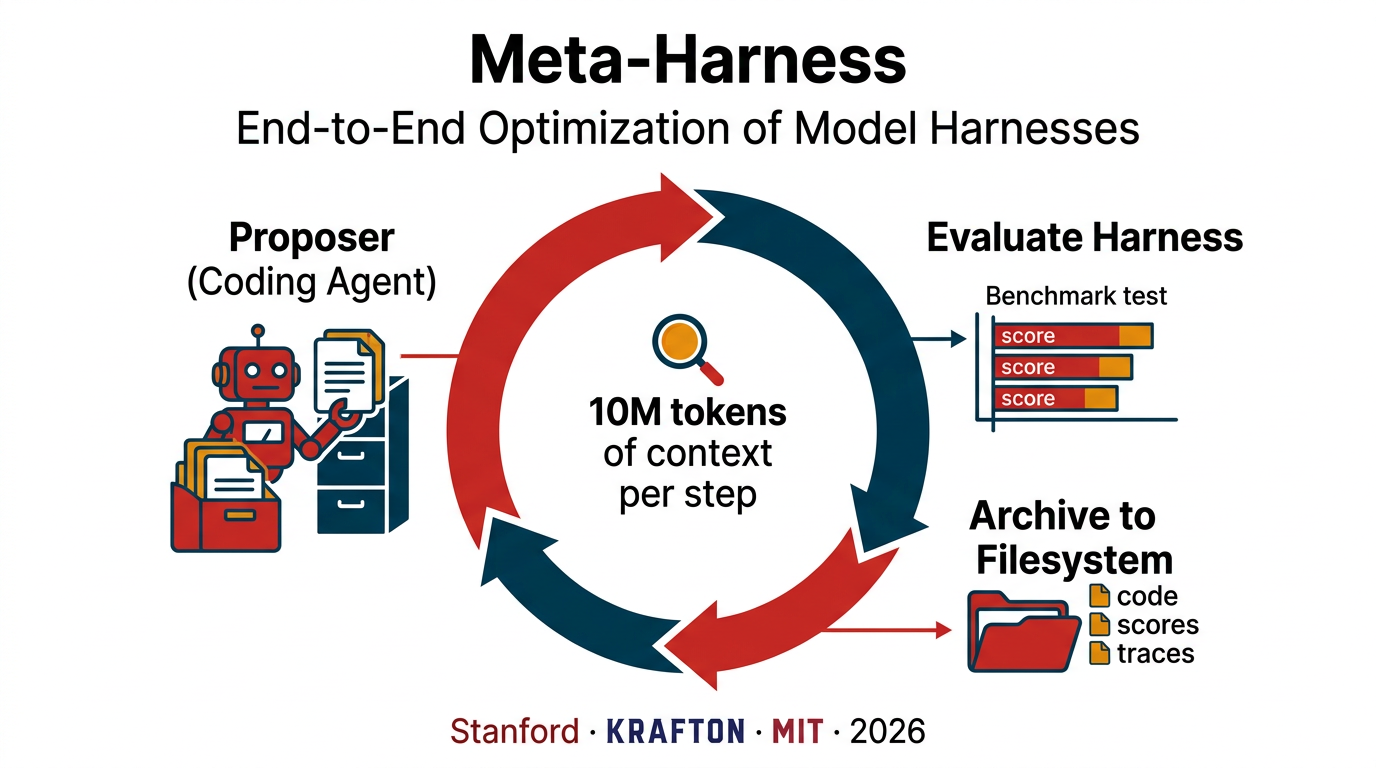
Agent 查数的准确率悬崖:语义层 vs Text-to-SQL
2023 到 2026,大模型写 SQL 的能力翻了一倍(dbt 实测 32.7%→64.5%)。但在真实企业库上,同一批模型从 86% 跌到 10%——这就是‘准确率悬崖’。本文用 dbt、Spider 2.0、BEAVER、Snowflake、Atlan 五组一手基准,拆清楚 Agent 查数到底卡在哪:不是模型不够聪明,而是决定答案对错的语义、口径、权限,根本不在数据库的 schema 里。结论是行业已经收敛的同一个答案——把缺失的上下文做成基础设施(语义层),让查询在编译期被治理,而不是事后补救。