Loop Engineering 实战:从写 Prompt 到设计循环,附一个可运行的自纠错示例
实战导向 · 循环工程 × 六要素拆解 × 100 行可运行 Python | 2026 年 6 月 | 约 14 分钟阅读
写在前面
2026 年 6 月 7 日,OpenClaw 作者 Peter Steinberger 在社交平台上甩出一句话,迅速在 AI coding 圈刷屏:
"You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
几乎同一时间,Anthropic 的 Claude Code 负责人 Boris Cherny 在台上说了几乎一模一样的意思:"我已经不亲自 prompt Claude 了,我有一堆循环在跑、它们负责 prompt Claude 并决定下一步做什么;我的工作是写循环。"随后 Google Chrome 的工程负责人 Addy Osmani 把这件事系统化,给了它一个名字——Loop Engineering(循环工程)。
这不是又一个营销词。它描述的是一个真实发生的工作方式迁移:当模型已经能连续自主跑几个小时,瓶颈就从"模型能力"挪到了"编排设计"。还在一条一条手敲 prompt 的人,等于把 90% 的杠杆扔在地上。
把它放进谱系里看更清楚——三层抽象是叠加关系,不是替代:
| 范式 | 你优化的对象 | 自治程度 | 适合 |
|---|---|---|---|
| Prompt Engineering | 单轮的那句话 | 无,人在椅子上 | 一次性任务 |
| Context Engineering | 喂进上下文窗口的内容 | 中,预设步骤 | 已知形状的流水线 |
| Loop Engineering | 循环结构 + 内部评判标准 | 高,按条件自停 | 路径未知的开放式迭代 |
Prompt Engineering 优化一次输入输出;Context Engineering 塑造那次调用周围的上下文;Loop Engineering 把这两者包进一个自治控制结构里,由它决定该 prompt 什么、什么时候 prompt、结果能不能收货。 关键认知是:杠杆点从"措辞"移到了"系统架构"。这恰恰让循环设计比写 prompt 更难,而不是更简单——Cherny 的原意从来不是"活变轻松了",而是"发力点变了"。
这篇文章不停在嘴上。下面先把一个生产级循环拆成可落地的六个要素,再用约 100 行零依赖 Python 把它写出来跑给你看,最后接上 Cursor 的 /loop 做定时触发。
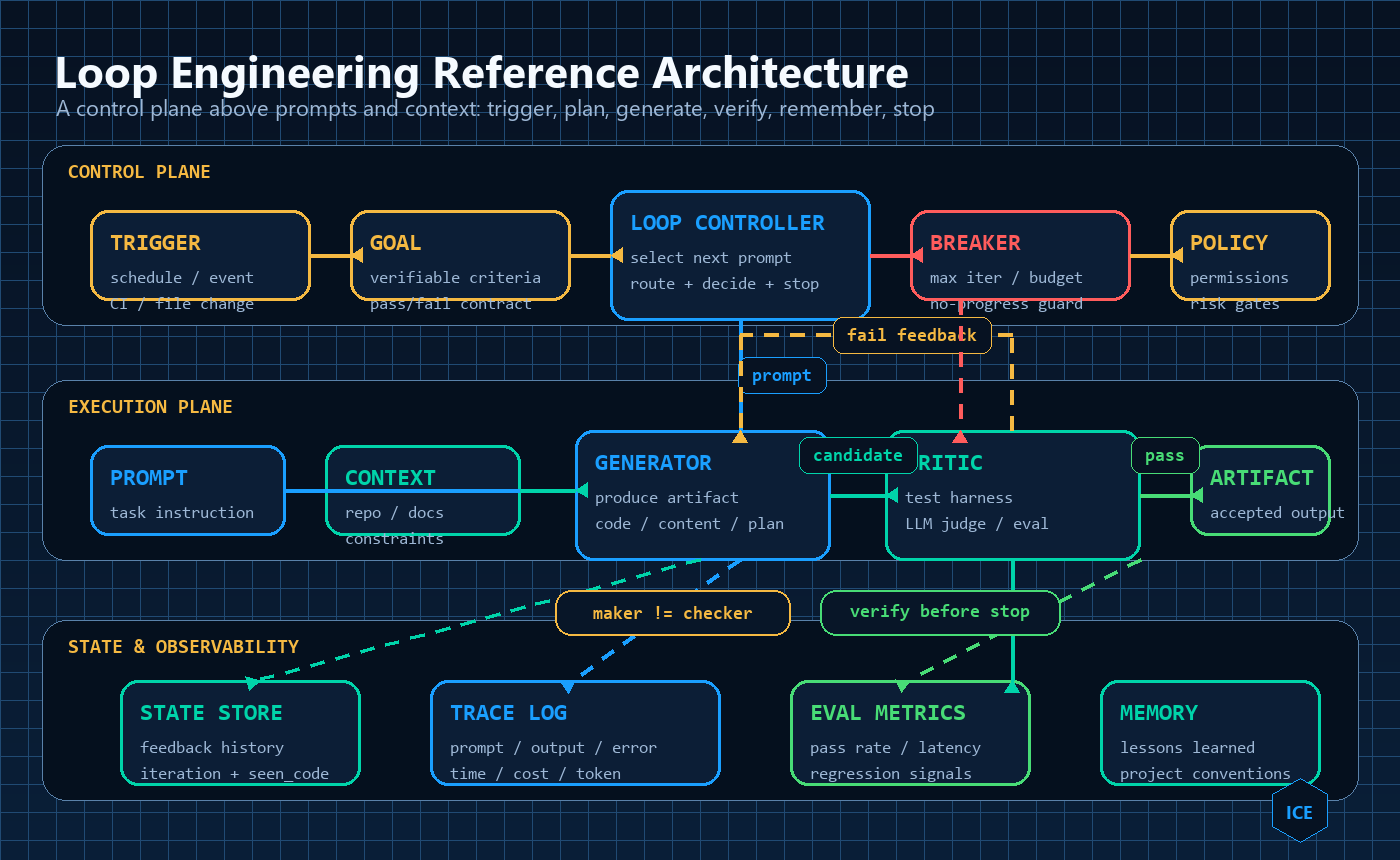
一个循环到底由什么组成
把各家实践合到一起,一个能上生产的循环至少要有六个部件。它们不是可选项,缺一个循环就会以某种方式失控。
1. 触发器(Trigger)——让循环"自己跑起来"的东西。可以是定时(cron、CI、Cursor 的 /loop),也可以是事件驱动(git ref 前进、CI 跑完、文件变更)。没有触发器,你还是那个按回车的人。
2. 可验证的停止条件(Goal)——这是 /goal 命令的内核。你必须能用机器判定"完成"长什么样,否则循环不知道何时该停。模糊的目标("让用户满意")等于没有目标。
3. Generator-Critic 分离——写东西的 Agent 不能给自己打分,它太宽容了。必须有一个独立的验证者:另一个 Agent、另一个模型,或者一段确定性的测试 / 评测器。这是整套里收益最高的一招,下文专门展开。
4. 共享状态(State)——跨轮次累积历史、反馈、进度,让上下文在循环里滚动。第 N 轮要能看到前 N-1 轮踩过的坑,循环才会"越跑越对"而不是原地打转。
5. 熔断器(Circuit Breaker)——最大轮数、成本上限、"无进展"检测。这是基础设施层的硬约束,专门用来防止无限循环、防止跑飞的账单、防止模型一遍遍自我说服。
6. 可观测性(Observability)——记录每一轮的 trace。循环卡住时,你得能回答"它在第几轮、为什么没收敛",否则自我改进的链条会在最关键的验证环节断掉。
记住这一句就够了:maker ≠ checker。其余五点都是为了让这条原则能稳定、安全、自动地反复执行。
把循环写出来:一个会自我纠错的代码生成器
光说不练没意思。我们挑一个最经典、最能体现循环精髓的任务:让 Agent 自动写代码,直到通过测试。Critic 用确定性的测试执行器,带状态累积和熔断器。为了让你不配任何 API key 也能看到它收敛,我内置了一个"脚本化模型"模拟"被反馈逐步纠正"的过程,同时保留接入真实模型的接口。
第一步:把目标和验证分开
循环的灵魂是"目标"和"怎么算完成"是两样东西。前者喂给 Generator,后者交给机器判定:
import dataclasses
@dataclasses.dataclass
class Task:
name: str
spec: str # 自然语言目标,喂给 Generator
test_source: str # Critic 用来判定"完成"的确定性测试
TASK = Task(
name="fizzbuzz",
spec="实现 solve(n): 能被3整除返回'Fizz',能被5整除返回'Buzz',"
"同时能被3和5整除返回'FizzBuzz',否则返回 str(n)。",
test_source=(
"from solution import solve\n"
"cases = {1:'1', 3:'Fizz', 5:'Buzz', 15:'FizzBuzz', 7:'7'}\n"
"for k, v in cases.items():\n"
" assert solve(k) == v, f'solve({k}) wrong'\n"
"print('ALL_TESTS_PASSED')"
),
)spec 是给"人/模型"看的,test_source 是给"机器"跑的——这就是要素 2(可验证目标)落地的样子。
第二步:可插拔的 Generator
写代码的角色定义成一个协议,离线用脚本模型,线上换成真实 LLM,循环结构一行不用改:
from typing import Protocol
class LLMClient(Protocol):
def generate(self, prompt: str) -> str: ...
class ScriptedClient:
"""离线演示:模拟一个会被反馈逐步纠正的模型。
第 1 轮故意交一个把判断顺序写反的 bug 版本(先判 3,导致 15 被错判成 Fizz),
收到测试反馈后第 2 轮修正。体现'循环让差模型也能收敛'。"""
def __init__(self): self._calls = 0
def generate(self, prompt: str) -> str:
self._calls += 1
if self._calls == 1:
return "```python\ndef solve(n):\n" \
" if n%3==0: return 'Fizz'\n" \
" if n%5==0: return 'Buzz'\n" \
" if n%15==0: return 'FizzBuzz'\n" \
" return str(n)\n```"
return "```python\ndef solve(n):\n" \
" if n%15==0: return 'FizzBuzz'\n" \
" if n%3==0: return 'Fizz'\n" \
" if n%5==0: return 'Buzz'\n" \
" return str(n)\n```"真实模型版本就是把这个类换成调用 OpenAI / Claude / Qwen 的实现,接口完全一致。注意第 1 轮的 bug 很真实:把 n%15 放在 n%3 后面,15 永远先命中 Fizz 分支——这是人和模型都常犯的顺序错误。
第三步:独立的 Critic(验证者)
Critic 在一个隔离的临时目录里跑测试,返回"过没过 + 反馈"。它不读 Generator 的"自我评价",只看代码的真实行为:
import os, subprocess, sys, tempfile
def verify(code: str, task: Task) -> tuple[bool, str]:
with tempfile.TemporaryDirectory() as d:
open(os.path.join(d, "solution.py"), "w").write(code)
open(os.path.join(d, "t.py"), "w").write(task.test_source)
proc = subprocess.run([sys.executable, "t.py"], cwd=d,
capture_output=True, text=True, timeout=10)
out = (proc.stdout + proc.stderr).strip()
passed = proc.returncode == 0 and "ALL_TESTS_PASSED" in out
return passed, out临时目录这一步顺手实现了环境隔离——多个任务并行时不会互相污染文件,这也是 worktree 思想的雏形。
第四步:循环本体——生成、验证、决策、熔断
把前面几块串成循环。状态用一个 LoopState 累积,熔断靠"最大轮数"加"无进展检测"(连续两轮交了一模一样的代码就提前停):
@dataclasses.dataclass
class LoopState:
iteration: int = 0
last_code: str = ""
last_feedback: str = ""
passed: bool = False
def run_loop(task: Task, client: LLMClient, max_iterations: int = 5) -> LoopState:
state = LoopState()
seen = set()
while state.iteration < max_iterations: # 熔断器①:轮数上限
state.iteration += 1
# Generator:把上一轮失败反馈拼进 prompt(要素④共享状态)
prompt = task.spec
if state.last_feedback:
prompt += f"\n上一版没通过,反馈:\n{state.last_feedback}\n请修复后重新输出。"
code = extract_code(client.generate(prompt))
if code in seen: # 熔断器②:无进展检测
break
seen.add(code)
state.last_code = code
# Critic:独立判定(maker != checker)
passed, feedback = verify(code, task)
state.last_feedback = "" if passed else feedback
print(f"[轮 {state.iteration}] {'PASS' if passed else 'FAIL'}")
if passed: # 要素②:可验证停止条件
state.passed = True
break
return stateextract_code 只是把 ```python 代码块里的内容抠出来,省略不表。整个循环的骨架就这么点——真正难的不是代码量,而是想清楚"目标怎么验证、谁来验证、什么时候停"。从系统视角看,Loop Engineering 不是在代码里多写一个 while,而是在 Prompt / Context 之上加了一层控制平面:它负责触发、设目标、调用生成者、调用验证者、回写状态、记录 trace,并在满足条件或触发熔断时停止。
跑起来看
python loop_demo.py=== Loop Engineering Demo | task=fizzbuzz | max_iter=5 ===
[轮 1] FAIL :: AssertionError: solve(15) -> 'Fizz', expected 'FizzBuzz'
[轮 2] PASS :: ALL_TESTS_PASSED
------------------------------------------------------------
✅ 循环在第 2 轮自我收敛,验证通过。把这两轮交互拆开看,关键不是"模型又想了一遍",而是生成者和验证者被硬性分开:左边的 Generator 只负责产出工件,右边的 Critic 在独立沙箱里跑评测;失败不是一句口头批评,而是一份结构化反馈,再通过回路写回下一轮。
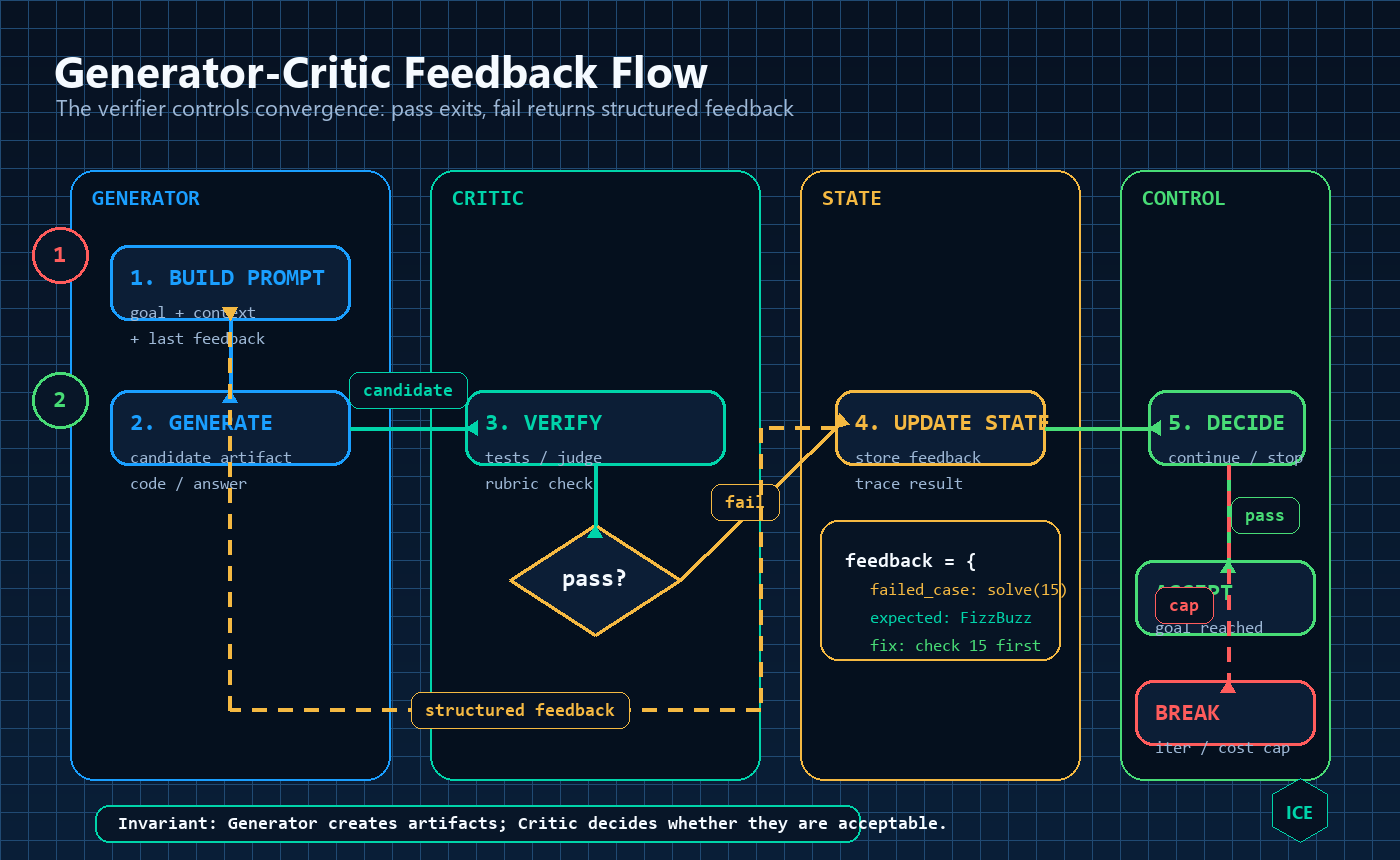
第 1 轮交出有 bug 的版本,Critic 给出精确反馈(solve(15) 应为 FizzBuzz),第 2 轮模型据此调整判断顺序、通过。注意演示用的"模型"本身很笨——它只是按脚本返回,但因为循环把测试反馈喂了回去,它依然收敛了。这正是 Loop Engineering 反复强调的那句话:把标准 codify 进循环里,哪怕是笨模型也会一直试到达标为止,而不是指望你在一个 prompt 里把所有要求都写全。
maker ≠ checker:为什么验证者必须独立
这是六要素里最值得单拎出来讲的一条。
问题:让写代码的模型给自己的代码打分,它会过度自信。它刚刚说服自己"这段逻辑是对的",你再问它"对不对",它大概率继续说服你。自评本质上是在用同一套有偏的推理去检查那套推理的产物。
做法:让一个独立的角色来判定。独立体现在三个层次,由弱到强:
- 最弱也最实用——用确定性的程序当 Critic(就像上面的
verify()跑测试)。它不讲情面、不会被说服,能 100% 复现。 - 中等——用一个不同 system prompt 的 Agent 当评审,专门挑刺。
- 最强——直接换一个不同的模型来评审,连模型的系统性偏见都能错开。
Cursor / Claude Code 的 /goal 命令底层就是这个套路:写代码的不是判定"循环是否完成"的那一个,完成与否由一个独立的、通常更小的验证模型说了算。
陷阱:很多人把循环写成"模型生成 → 模型自评 → 模型修改",看起来也在迭代,实则是同一个脑子左右互搏,常常几轮后一起跑偏还互相点头。只要 maker 和 checker 是同一个,循环的纠错能力就是假的。 哪怕你的 checker 只是几行 assert,也比一个会自我表扬的大模型强。
给循环装上触发器:接入 Cursor /loop
到这里循环还缺最外面那一层——触发器。我们用 Cursor 的 /loop 来补。
先纠正一个常见误解:/loop 不是云端 cron,而是会话级机制。它在后台起一个 shell 循环,按间隔吐出一行带哨兵前缀的文本,并通过 notify_on_output 在每个 tick 唤醒 Agent;唤醒后由 Agent 执行 tick 携带的 prompt。换句话说,它把"按回车"这件事自动化了,正好充当要素 1(触发器),套在我们前面那个 Generator-Critic 内循环之外。
整体结构长这样:
/loop (每 2 分钟 tick) → 唤醒 Agent → tick_runner.py
├→ run_loop() 生成→验证→自纠错(内循环)
└→ 追加一行到 runs.log(审计轨迹)外层是定时触发的"元循环",内层是自纠错的"工作循环"。每个 tick 跑一遍内循环,并把 时间 | 任务 | 状态 | 轮数 追加进 runs.log——这顺手补齐了要素 6(可观测性)。
后台循环在 Windows 上用 PowerShell 写(bash 同理):
while ($true) {
Start-Sleep -Seconds 120
Write-Output 'AGENT_LOOP_TICK_loopdemo {"prompt":"run tick_runner.py and report convergence"}'
}配合监听 ^AGENT_LOOP_TICK_loopdemo 这个唯一哨兵唤醒 Agent。接入时有几个工程细节值得照做:用唯一哨兵 + 锚定正则避免误触发;启动后先手动跑一次 prompt(首个哨兵只在第一个 sleep 之后才到,避免启动就双触发);记录 PID 以便随时停止;循环体里只放最小命令(睡眠 + 吐哨兵),真正的活在唤醒后做。
跑起来后 runs.log 会持续累积,形成可审计的轨迹:
2026-06-16 10:01:55 | task=fizzbuzz | PASS | iters=2
2026-06-16 10:07:47 | task=fizzbuzz | PASS | iters=2需要注意 /loop 依赖聊天会话保持活跃——关了会话循环就停了。要做到"关机也能跑",把 tick_runner.py 挂到操作系统的计划任务或 GitHub Actions 上触发即可,逻辑完全复用。
从 demo 到生产:五个升级方向
上面那个 demo 麻雀虽小五脏俱全,但离生产还有距离。按下面五个方向加料,它就能长成真正干活的系统。
1. Critic 升级成 LLM-judge。 跑测试只能查"对不对",查不了"好不好"。再加一个 LLM 评审,把"风格 / 安全 / 性能 / 是否符合规范"这些软标准 codify 成可返回的反馈。生成内容场景尤其需要——比如判定"有没有钩子、是不是太啰嗦、语气对不对",这些塞进一个 prompt 里大模型都会漏,做成循环里的 judge 反而稳。
2. 触发器从定时升级到事件驱动。 定时只是起步。更聪明的触发是"有变化才醒":git ref 前进了、CI 跑完了、某个文件改了才唤醒循环,空闲时不烧钱。
3. 拆出 Sub-agents 分工。 把"探索 → 实现 → 验证"拆成不同的 Agent,甚至用不同的模型。这既强化了 maker≠checker,也对应 /goal 的底层结构:干活的和判定完成的天然分离。
4. 隔离环境用上 worktree。 demo 里 verify() 的临时目录是雏形。多个循环并行跑时,用 git worktree 给每个任务独立的工作区,避免文件冲突。
5. 可观测性做成结构化 trace。 把 runs.log 从一行文本升级成结构化记录:每轮的 prompt、输出、成本、耗时、失败原因都留痕。循环跑飞或停滞时,你要能一眼看出卡在哪。
还有一条贯穿性的原则——让循环"有活才干"。最成熟的形态不是定时无脑重跑,而是 tick 醒来先探测"有没有新任务",有才启动内循环。这才是 Steinberger 那句话的完整含义:你设计的是一个会自己找活、分活、验活、决定下一步的系统。
结论
如果只带走几句话:
- Loop Engineering 是叠加在 Prompt / Context Engineering 之上的第三层,不是替代。底下两层依然是基本功,但杠杆已经上移到"系统架构"。
- 一个能用的循环 = 触发器 + 可验证目标 + Generator-Critic 分离 + 共享状态 + 熔断器 + 可观测性,缺一不可;其中 maker≠checker 是收益最高的一条。
- 循环的难点不在代码量——骨架 100 行就能写完——而在于想清楚"目标怎么被机器验证、谁来验证、什么时候停"。把这三件事定义好,笨模型也能在循环里收敛到达标。
- 它让设计变难了,不是变简单了。 两个人搭一模一样的循环,一个用它在自己吃透的领域上提速,另一个用它逃避理解工作本身——循环不知道区别,你知道。
下一步建议:挑一个你已经在反复手动 prompt 的小任务(自动修 lint、生成周报、跑回归测试),先给它配一个确定性的 Critic,再套一层定时触发。能跑通这一个,你就已经从"prompt 的人"变成"写循环的人"了。
本文配套的可运行项目(约 100 行,零依赖)见 github.com/B16g-maker/loop-engineering-demo,
python loop_demo.py即可复现上面的收敛过程。
参考资料
- Addy Osmani. Loop Engineering. Substack / Elevate, 2026-06. https://addyo.substack.com/p/loop-engineering
- Firecrawl. Loop Engineering: Should You Stop Prompting Agents and Start Designing Loops. 2026. https://www.firecrawl.dev/blog/loop-engineering
- explainx.ai. What Is Loop Engineering? Beyond Prompt Engineering in 2026. 2026.
- ActiveWizards. LangGraph Tutorial: Self-Correcting AI Agents and Agent Loops. 2026.
- Data Science Dojo. Agentic Loops: From ReAct to Loop Engineering (2026 Guide). 2026.
- Cursor
/loopSkill 规范文档。