论文解读|Memanto:你的 Agent 交了多少记忆税?

论文信息
- 标题:Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents
- 作者:Seyed Moein Abtahi 等
- 时间:2026 年 4 月 23 日提交 arXiv | arXiv: 2604.22085
- 对比论文:Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory | arXiv: 2504.19413
TL;DR
过去一年,agent memory 的主流升级路线越来越重:向量库不够就加图数据库,单路检索不够就上多查询 + 反思循环。Memanto 逆向而行——不上知识图谱、不做写入时 LLM 抽取、不走多查询检索,只靠类型化语义记忆 + 冲突检测 + 信息论检索引擎,在 LongMemEval 和 LoCoMo 上拿到了 89.8% 和 87.1%。
论文最有价值的不是分数,而是一个核心判断:智能体 memory layer 的瓶颈,可能不在"结构不够复杂",而在"写入太慢、检索太重、系统太脆"。 论文把这笔隐性开销叫作 Memory Tax——你为记忆能力所支付的延迟、成本和运维复杂度的总和。
一、它到底在反驳什么
这篇论文的靶子不是"向量检索"本身,而是过去一年 agent memory 的主流升级路线。
这条路线你很熟:先把对话切块写入向量库;想做得更好,加实体抽取、关系边、图数据库;还嫌不够,再加多路 query、parallel retrieval、reflection。逻辑很自然——长期任务、多轮对话、多跳推理,听起来确实是知识图谱的强项。
下图把这条"越堆越重"的路线画了出来。从基础向量 RAG(Level 1),到加上实体抽取和图数据库(Level 2),再到多查询并发 + 图遍历 + 反思循环(Level 3),每一层都在加功能——但延迟、基础设施数量和运维成本也一路往上走:
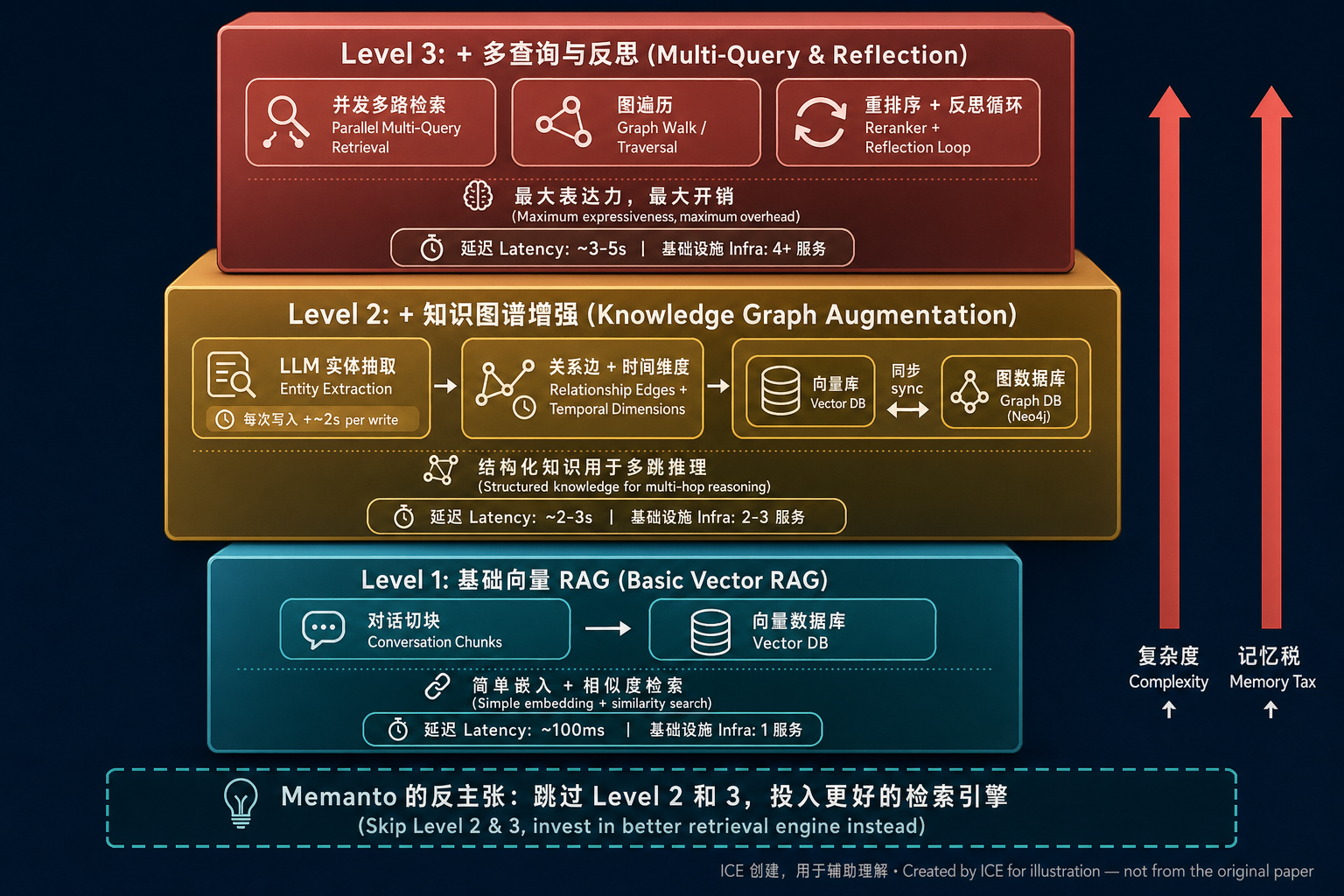
Memanto 的作者说,问题在于:你把一部分"本应在推理时发生的工作",提前挪到了写入时和基础设施层。 代价一层层叠上来:
| 路径 | 典型代价 |
|---|---|
| 写入时 LLM 抽取实体/关系 | 每次写记忆都多一次 LLM 推理,延迟和 token 成本直接上涨 |
| 向量库 + 图数据库双存储 | 运维翻倍,索引同步、数据一致性、扩缩容都更麻烦 |
| 多查询 / 递归检索 | 尾延迟(最慢那条链路的响应时间)更高,链路更脆弱 |
| 动态 schema 或人工图谱维护 | 研发和标注成本持续累积 |
论文把这四类额外负担统称为 Memory Tax(记忆税)。打个比方:就像你为了"住得更好"不断加装修,到最后发现每月维护费已经超过了房租本身。
从 2024 年的 Mem0(向量 + 图)、Letta/MemGPT(分层),到 2025 年的 Zep(图 KG)、A-MEM(Zettelkasten)、Supermemory(图 + 向量),整个赛道越来越重。今天很多 Agent 系统的真实处境是:demo 阶段什么都能跑通,一旦上线到真实业务,"记忆"不是能力问题,而是 SLO(Service Level Objective,服务等级目标)问题——写入够不够快、检索够不够稳、系统够不够可用。
Memanto 在 2026 年逆向而行,用向量单体 + 类型化 + 信息论检索拿到了 89.8%。接下来看它具体怎么做。
二、Memanto 怎么做:把 memory layer 做轻,而不是做薄
Memanto 不是简单地"砍功能"。它做的是另一种取舍:把复杂性压缩在检索质量和记忆语义里,而不是压在基础设施编排里。
整体架构
Memanto 本身是一个本地运行的 FastAPI 服务,作为其他 AI Agent 的"专属记忆代理"。整个系统分三层:顶层是各类 Agent 客户端(IDE 插件、CLI 工具、自定义 Agent、Web Dashboard),中间层是 Memanto 网关 + 9 个核心服务模块(写入、检索、RAG 问答、冲突检测、每日摘要等),底层是 Moorcheh 云端检索引擎(零索引语义数据库 + Agent 优化 RAG 管线 + 原生 LLM 访问)。对外只暴露三个端点:/remember(写入)、/recall(检索)、/answer(问答)。
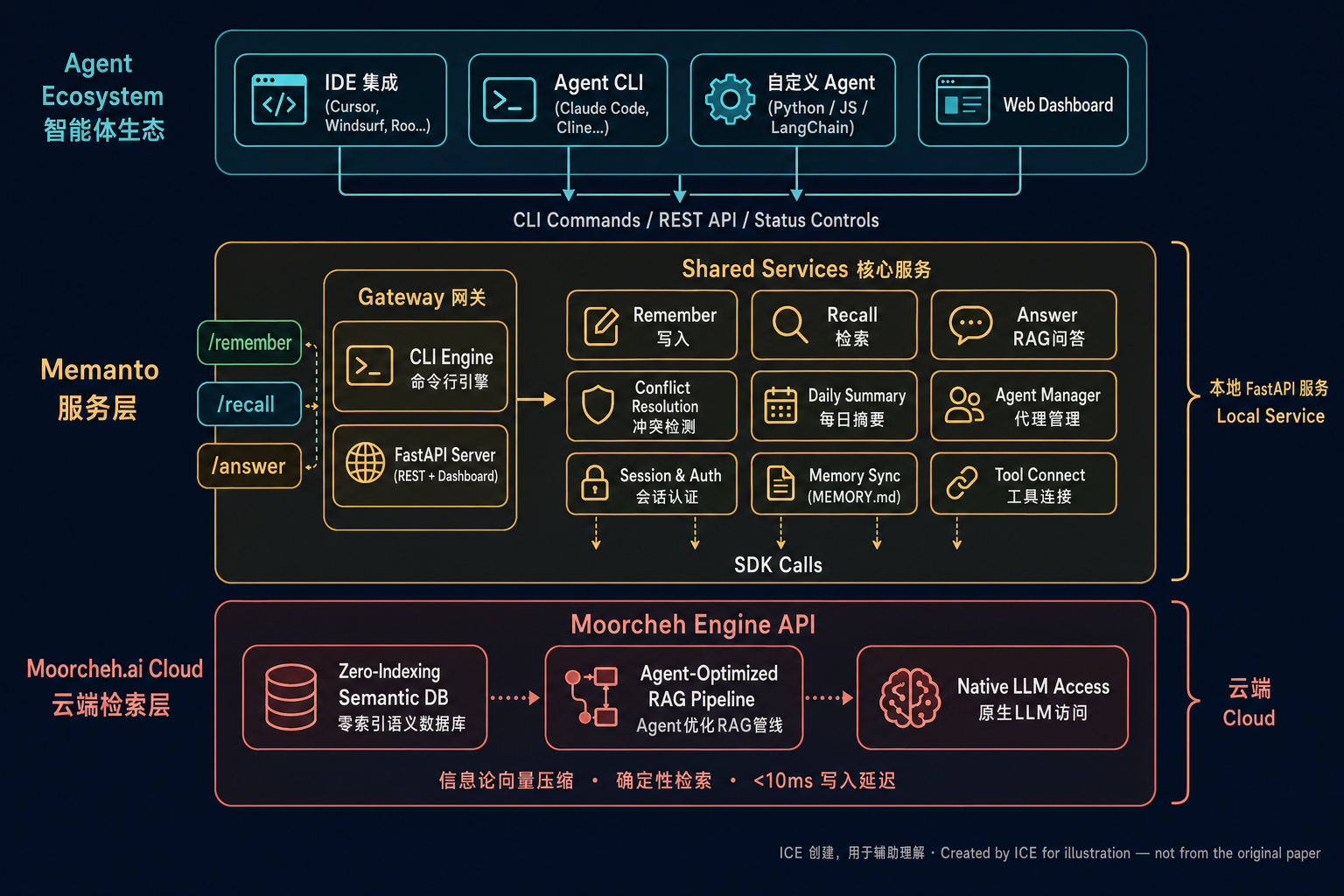
它和知识图谱方案的本质区别
Memanto 有类型、有关系、有冲突检测,看起来很像知识图谱?其实不是。它背后没有图数据库,只有向量数据库。
| 知识图谱方案(如 Mem0g, Zep) | Memanto | |
|---|---|---|
| 存储结构 | 向量库 + 图数据库(如 Neo4j) | 只有向量库(Moorcheh) |
| "关系"怎么存 | 图数据库里的节点 + 边 | 带 relationship 类型标签的文本条目 |
| 写入时做什么 | LLM 抽取实体 → 构建节点和边 → 同步两套存储 | 直接写入带类型标签的向量,不调 LLM |
| 检索时做什么 | 向量检索 + 图遍历 + 多路合并 | 单次向量检索 + 类型过滤 |
Memanto 的 13 个类型不是图谱的节点和边,而是向量条目上的元数据标签。一条 relationship 类型的记忆"Alice 管理 Bob",在 Moorcheh 里就是一条带标签的文本向量——不会生成 Alice 节点、Bob 节点和 manages 边。这也是论文最具争议的赌注:用类型标签 + 更强的检索引擎,能不能替代知识图谱的结构化表达力?
理解了这个前提,我们来拆它的三个核心设计。
1. 13 类类型化记忆
论文没有回到"无结构文本块"的起点,而是给记忆定义了 13 个内建类型:
fact / preference / decision / commitment / goal / event / instruction / relationship / context / learning / observation / error / artifact
这 13 个类型不是凭直觉拍的,背后有三层依据:
认知科学基础。 论文引用了认知心理学家 Tulving 的经典记忆三分法:
- 情景记忆(episodic)——带时间和情境的具体事件,如"上周三的那次会议"
- 语义记忆(semantic)——不依赖具体事件的通用知识,如"用户在太平洋时区"
- 程序记忆(procedural)——技能和行为规则,如"遇到超时先重试三次"
Memanto 的 13 类是这三大类在 Agent 场景下的细粒度展开。event / commitment / context 对应情景记忆,fact / relationship / observation 对应语义记忆,instruction / error / decision 对应程序记忆。
先行实验验证。 ENGRAM(即 Hindsight)只用了 3 种记忆类型,就在 benchmark 上显著优于不分类型的存储。这说明光是"分类"本身就能带来明显的性能提升。Memanto 把这个原则推到了 13 类粒度。
工程双重目的。 这套类型系统服务于两件事:一是类型过滤检索——Agent 可以只查 commitment 类记忆,不被无关的 observation 污染结果集;二是隐式优先级与衰减信号——检索引擎根据类型自动调整权重,不需要额外的排序模型。
每种类型的"存活策略"不同:
fact(事实)——稳定、高置信,如"用户在太平洋时区"preference(偏好)——中等衰减,如"用户偏好深色模式"commitment(承诺)——时间敏感,如"周五前交付报告"error(错误)——持久守护,如"不要再调用废弃 API"goal(目标)——驱动性,如"本季度完成用户增长 20%"relationship(关系)——结构性,仍保留"谁管理谁、谁依赖谁"这类语义
核心判断:不是所有记忆都该用同一种优先级和召回方式。 与其用图数据库来表达复杂关系,不如先在记忆本身上打类型标签——成本更低、收益更直接。
2. 冲突检测:比"记住更多"更重要
很多 memory 系统默认把新事实直接写进去,最多做 merge 或 overwrite。但生产里的真实问题是:用户偏好会变、项目 deadline 会改、系统配置会调。
如果没有冲突检测,Agent 用久了就会积累一堆互相矛盾的记忆。结果不是"记不住",而是更隐蔽的问题:每条记忆单独看都对,拼在一起世界模型已经不一致了。
Memanto 在写入时会检查同类型记忆中的语义冲突,走三种决策之一:
supersede:新事实替换旧事实retain:保留旧事实annotate:两条都保留,标记冲突,等待人工裁决
这个机制听起来很"工程",但我认为它比 benchmark 分数更重要。长期 Agent 真正的崩溃方式,往往不是"检索不到",而是检索到了互相打架的上下文。
3. 时间版本化:让记忆能"回放"
Memanto 支持三种时间查询:
as-of:查某个时间点当时的记忆快照changed-since:查某段时间内发生的变化current-only:只看当前有效的真值
这让它不只是一个"会记事的 RAG",而更像一个可审计的状态层。对企业 Agent 尤其关键,因为很多线上问题最终都会变成一个追溯题:"它当时为什么这么回答?看到的是哪版记忆?"
三、论文最值得关注的三个工程发现
成绩当然亮眼:LongMemEval 89.8%,LoCoMo 87.1%。但比分数更重要的,是论文从消融实验(ablation study——逐一改变系统组件,看哪个环节真正起作用)里得出的三个结论。
发现一:Recall 比 Precision 更重要
论文做了五阶段消融。最关键的一步不是加新结构,而是把检索候选数量从 10 拉到 40,并放宽相似度阈值。
| 阶段 | LongMemEval | LoCoMo | 关键变化 |
|---|---|---|---|
| Stage 1 | 56.6% | 76.2% | 基线:取 top-10,阈值 0.15 |
| Stage 2 | 77.0% | 82.8% | 扩大召回:取 top-40,阈值 0.10 |
| Stage 4 | 85.0% | 86.3% | 最大召回:动态上限 100,阈值 0.05 |
| Stage 5 | 89.8% | 87.1% | 换用更强推理模型 Gemini 3 |
仅 Stage 2 一步,LongMemEval 就跳涨了 20.4 个百分点——远超其他所有阶段的贡献:
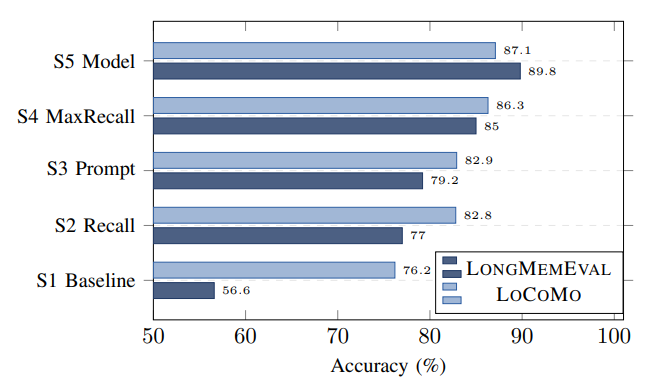
作者的判断:在 agent memory 里,宁可多给一点噪声上下文,也不要过早把关键碎片滤掉。 过去大家太关注"怎么把检索做精"(图遍历、多跳路由、复杂重排),但更大的提升可能来自一件更朴素的事——别漏掉关键片段。
发现二:图结构的收益,可能没有想象中大
Memanto 反复拿 Mem0 做对照。关键论据:Mem0 的图增强版 Mem0g,相比基础版只提升了 1.5 个百分点,但写入延迟从 500ms 涨到 2s,还多了一套 Neo4j 要维护。
| 系统 | LoCoMo | LongMemEval | 架构 | 查询策略 |
|---|---|---|---|---|
| Memanto | 87.1% | 89.8% | 向量单体 | 单查询 |
| Mem0 | 66.9% | — | 向量 | 单查询 |
| Mem0g | 68.4% | — | 图 + 向量 | 单查询 |
| Zep | 75.1% | 71.2% | 图 + 向量 | 单查询 |
| Hindsight | 89.6% | 91.4% | 反思 + 向量混合 | 多查询 |
注意,Hindsight 的分数其实更高。但关键在于:Hindsight 代价是最高复杂度,而 Mem0g 虽然更重,却只比 Mem0 小幅提升。 对大多数团队来说,不是图结构没价值,而是它未必值回票价。
下图的散点图把这个关系画得很清楚——横轴架构复杂度,纵轴 benchmark 精度,Memanto 独占左上角"理想区"(高精度、低复杂度):
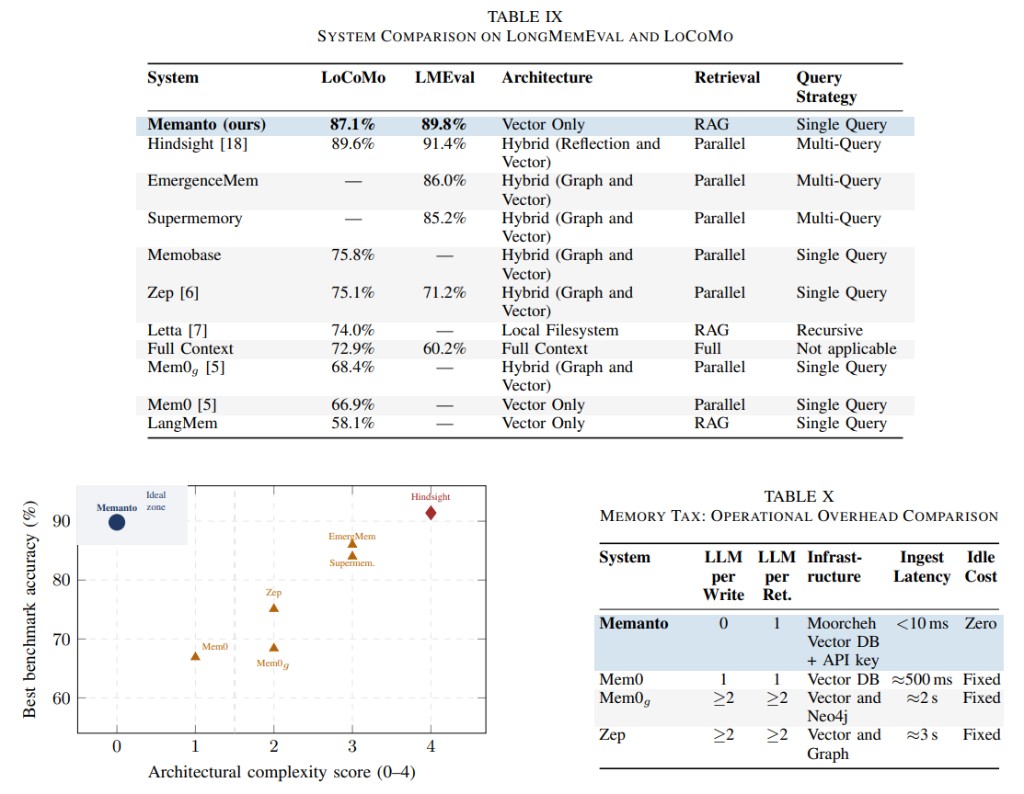
发现三:写入零延迟是硬指标
Memanto 最强的工程主张:写入后必须几乎立刻可检索。
| 系统 | 每次写入 LLM 调用 | 写入延迟 | 额外基础设施 |
|---|---|---|---|
| Memanto | 0 | <10ms | 单一检索后端 |
| Mem0 | 1 | ~500ms | 向量库 |
| Mem0g | ≥2 | ~2s | 向量库 + Neo4j |
| Zep | ≥2 | ~3s | 向量库 + 图数据库 |
如果你的 Agent 是研究助手,2 秒延迟也许能忍。但如果是客服、销售、IDE Copilot 这类高频交互场景,2 秒级写入延迟意味着 Agent 刚"学到"的事,下一个动作还用不上。 这点中了 production agent memory 的本质:memory layer 不是离线分析系统,而是在线状态系统。
四、也别神化:三层保留意见
论文很有启发,但远没到"范式已定"的程度。
最终成绩混入了模型升级红利。 最后一个阶段把推理模型从 Claude Sonnet 4 换成 Gemini 3,LongMemEval 又涨了 4.8 个百分点。最终高分不完全来自 memory architecture,也吃了模型变强的红利。
评测场景偏对话型。 作者自己也承认,目前 benchmark 主要覆盖对话记忆。研究型 Agent、代码 Agent、多 Agent 协作——这些更贴近实际生产的场景,还缺乏验证。
核心能力绑定专有检索引擎。 Memanto 的很多优势——无索引写入、确定性返回、亚 90ms 检索——建立在其自研的 Moorcheh 信息论检索后端之上。换一个通用向量数据库,未必能直接复现这些能力。
所以更稳妥的结论不是"以后都用 Memanto",而是:它证明了另一条路线是成立的——用更强的检索后端 + 更清晰的记忆语义,可能比堆更多图结构更划算。
五、对做智能体的人,这篇论文意味着什么
先换一种提问方式
很多团队讨论 agent memory 时,默认问题是"选哪个向量库?要不要加图数据库?"Memanto 让问题换了个方向:
- 写入后多久能查到?
- 同样的 query,能否每次返回同样的结果?
- 新旧事实冲突了怎么办?
- 记忆是按类型管理,还是全混在一池文本块里?
- 系统复杂度换来的精度提升,值不值?
这比"选 Pinecone 还是 Qdrant"高一个层级。对编排层来说,memory 不是存储插件,而是影响 agent 行为稳定性、可调试性、成本结构和可运维性的系统部件。
三个落地建议
先类型化,再图谱化。 很多团队还没把"事实、偏好、承诺、错误"分开管理,就直接上 graph memory。这个顺序大概率是反的。先做 typed memory,马上就能改善召回质量、衰减策略和调试能力;图谱只有在你真的需要稳定的多跳关系推理时才值得上。
把冲突检测当成一等公民。 如果你的 Agent 跨天、跨周、跨 session 运行,冲突记忆不是边角问题,而是主流程问题。缺了这一层,系统迟早从"偶尔答错"演化成"整体人格和状态漂移"。
用记忆税审视每个新组件。 以后再有人说"加一层图谱、加一个写入抽取器、加一个 reranker",追问一句:它提升了多少准确率?又多交了多少 Memory Tax?
行业判断
技术上, memory layer 正在从"外挂 RAG"变成"状态基础设施"。过去是"多一层检索,把上下文塞回 prompt";现在更像是在做一个可查询、可冲突管理、可时间回放的状态层。谁先把这层做好,谁就更接近真正稳定的长程 Agent。
商业上, memory layer 很可能成为 Agent 平台的下一个战场。模型越来越强,工具调用越来越标准化,真正拉开差距的,会是 Agent 在跨天、跨周、跨任务场景中的状态连续性。谁能把这层做得更低延迟、更低成本、更可解释,谁就更有机会成为编排平台的底座。
结论
Memanto 这篇论文最值得记住的,不是"又一个框架拿了更高分",而是一个尖锐的工程判断:
长期智能体记忆的关键,不一定是把结构做得更复杂,而是把写入做得更即时、把检索做得更确定、把记忆语义做得更清楚。
它把 memory 从"数据库选型题"重新变成了"系统架构题"。一旦问题被重新定义,很多默认动作都该重算一遍。
如果你正在设计 Agent memory layer,先别急着问"要不要上知识图谱",而先问:
你的 memory layer,究竟是在帮 Agent 记住事情,还是在给系统交记忆税?
参考资料
- Seyed Moein Abtahi et al. Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents. arXiv, 2026-04-23. https://arxiv.org/abs/2604.22085
- Prateek Chhikara et al. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv, 2025-04-28. https://arxiv.org/abs/2504.19413
- Seyed Moein Abtahi et al. From HNSW to Information-Theoretic Binarization: Rethinking the Architecture of Scalable Vector Search. arXiv, 2026. https://arxiv.org/abs/2601.11557
- Alexandra Maharana et al. Evaluating Very Long-Term Conversational Memory of LLM Agents (LoCoMo). ACL, 2024. https://arxiv.org/abs/2402.17753
- Diyi Wu et al. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. ICLR, 2025. https://arxiv.org/abs/2410.10813