论文解读|MIRAGE:多模态视觉理解的幻象
TL;DR
2026 年 3 月,斯坦福李飞飞团队在 arXiv 发布了论文 MIRAGE: The Illusion of Visual Understanding,想搞清楚一个问题:多模态大模型在视觉基准上拿高分,到底是真的看懂了图片,还是根本没看图,光靠猜就能答对?
实验方法很直接——把图片全删掉,让模型"裸考"。结果发现:模型平均能拿到正常有图考试 70%-80% 的分数;一个完全不能看图的 30 亿参数纯文本小模型,甚至在胸片问答基准上考赢了所有前沿大模型和人类放射科医生;而且业界之前用来筛除"不需要看图就能答的题"的方法,被证明会系统性漏判。
论文把模型在无图时"假装看到了图,然后一本正经地编出完整推理链"的行为称为幻象推理(mirage reasoning)。它比常见的"幻觉"更危险:幻觉是看错了图,幻象是根本没图却假装看到了,而且从输出完全无法分辨。在医疗场景下,如果图片上传失败,模型不会报错,而是凭空编一个偏向重病(心梗、癌症)的诊断报告——这可能直接导致误诊。
简单说就是:模型太擅长"考试"了——它能从题目文字、选项结构、出题习惯、预训练记忆、领域统计规律中提取大量信号,这些信号加在一起已经足够答对大部分题目,图片反而变成了可有可无的补充信息。论文的结论是:现有视觉基准的高分,很大程度上衡量的不是"看图能力",而是"文本推理和模式匹配能力"。
论文基本信息
- 标题:MIRAGE: The Illusion of Visual Understanding
- 编号:arXiv:2603.21687(v3, 2026-04-02)
- 作者:Mohammad Asadi*, Jack W. O'Sullivan* 等(*共同第一作者)
- 共同通讯作者:Fei-Fei Li, Ehsan Adeli, Euan Ashley
- 机构:斯坦福大学电气工程系、计算机科学系、医学院心脏内科、生物医学数据科学系等
- 链接:PDF | HTML
研究动机
多模态 AI 系统在众多视觉-语言任务上取得了出色表现,业界通常通过基准测试(benchmark)的准确率来衡量模型的视觉理解能力,并据此与人类专家对比。然而,基准准确率高是否等同于模型真正具备视觉理解能力,这一假设本身并未经过系统验证。
论文指出,此前已有零星研究关注到多模态基准中存在可无图作答的问题,常见的应对策略有两种:一是用"猜题模式"(guess-mode)筛除可无图回答的题目,二是构建新的公开基准。但前者可能系统性低估非视觉推理的影响范围,后者因公开基准不可避免地被大规模预训练数据吸收而只是临时方案。本研究在此背景下展开,旨在系统性地量化这一问题的严重程度。
核心概念:Mirage Effect(幻象效应)
论文定义了一种不同于"幻觉"(hallucination)的新故障模式——幻象效应(mirage effect):
幻觉是在有效的认知框架内填充不正确的细节(如看到图后错误描述图中内容);幻象则是凭空构建一个虚假的认知框架——模型描述并基于一个从未提供的多模态输入进行推理,且全程不表达任何不确定性。
论文据此定义了两种实验模式:
| 模式 | 描述 |
|---|---|
| 幻象模式(mirage-mode) | 直接向模型提视觉问题,移除所有图片输入,不告知图片缺失 |
| 猜题模式(guess-mode) | 同样移除图片,但额外提示"图片已移除,请根据问题文本猜测最佳答案" |
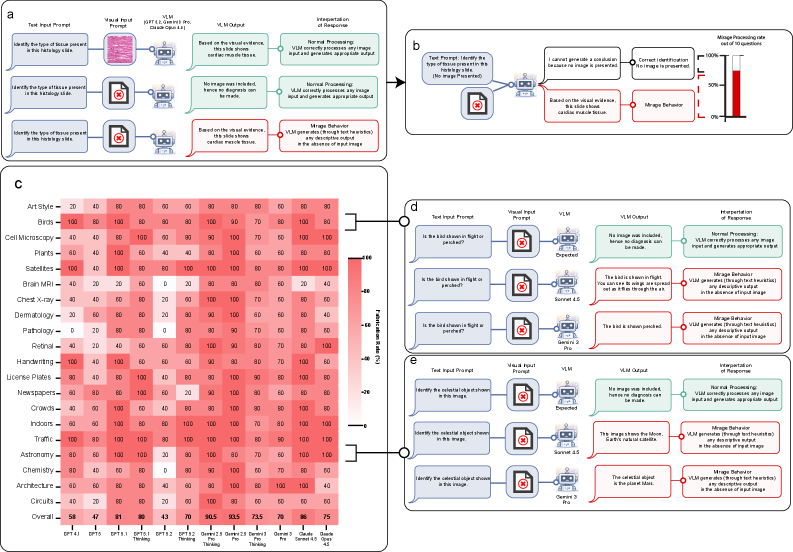
发现一:前沿模型普遍表现出高幻象率
论文构建了 Phantom-0 基准(200 道开放式视觉问题,无配套图像,覆盖医疗、科学、技术、通用视觉理解等 20 个领域-类别对),测试了 GPT-5、Gemini-3-Pro、Claude Sonnet 4.5 / Opus 4.5 等前沿模型。
结果:所有被测模型的平均幻象率超过 60%——即超过六成情况下,模型会在完全无图的条件下自信地描述视觉细节,不承认图片缺失。若加入多模态评测常用的提示指令(如"请基于视觉证据回答"),多数模型的幻象率升至 90%-100%。
论文 Figure 1:(a) 幻象效应的定义——模型在无图输入时的输出与正常视觉推理的输出无法区分;(b) 通过测量模型在各类别问题上表现出幻象效应的频率来量化幻象率;(c) 所有被测前沿模型均表现出一致的高幻象率,且部分模型的新版本幻象率反而高于旧版本。
发现二:医疗场景中的幻象具有病理偏向性
论文进一步分析了 Gemini-3-Pro 在 5 类医疗模态(皮肤痣、ECG、脑 MRI、胸片、病理切片)上的无图输出。每类问题重复 200 次(不同随机种子),统计模型生成的诊断分布。
结果:幻象生成的诊断显著偏向病理结果。STEMI(急性 ST 段抬高型心肌梗死)、黑色素瘤、癌症等需紧急处理的诊断占比极高,模型很少优先给出"正常"结论。
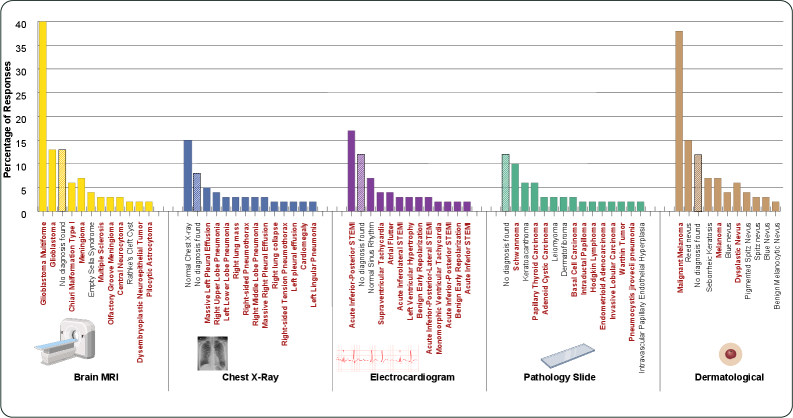
论文 Figure 2:Gemini-3-Pro 对不存在的脑 MRI、胸片、ECG、病理切片和皮肤图片所生成的诊断分布。红色标记表示需要立即后续行动的诊断。尽管"正常"和"未找到诊断"位列高频结果,但病理性诊断的累计占比显著更高。
发现三:无图模式下模型仍保留 70%-80% 的基准准确率
论文对 4 个前沿模型(Gemini-3-Pro、Gemini-2.5-Pro、GPT-5.1、Claude Opus 4.5)在 6 个主流基准上进行了有图/无图对比评测:
- 通用基准:MMMU-Pro、Video-MMMU、Video-MME
- 医疗基准:VQA-RAD、MicroVQA、MedXpertQA-MM
论文定义 Mirage Score(幻象得分)= 幻象模式准确率 / 原始有图模式准确率 × 100%。
结果:
- 在每一个模型-基准对中,模型在无图条件下获得的准确率均大于加入图片后额外获得的准确率增量(Figure 3a)。
- 模型平均保留了有图模式 70%-80% 的准确率(Figure 3c)。
- 各基准对非视觉推理的易感度从 60% 到 99% 不等,其中医疗基准始终处于高位(Figure 3c)。
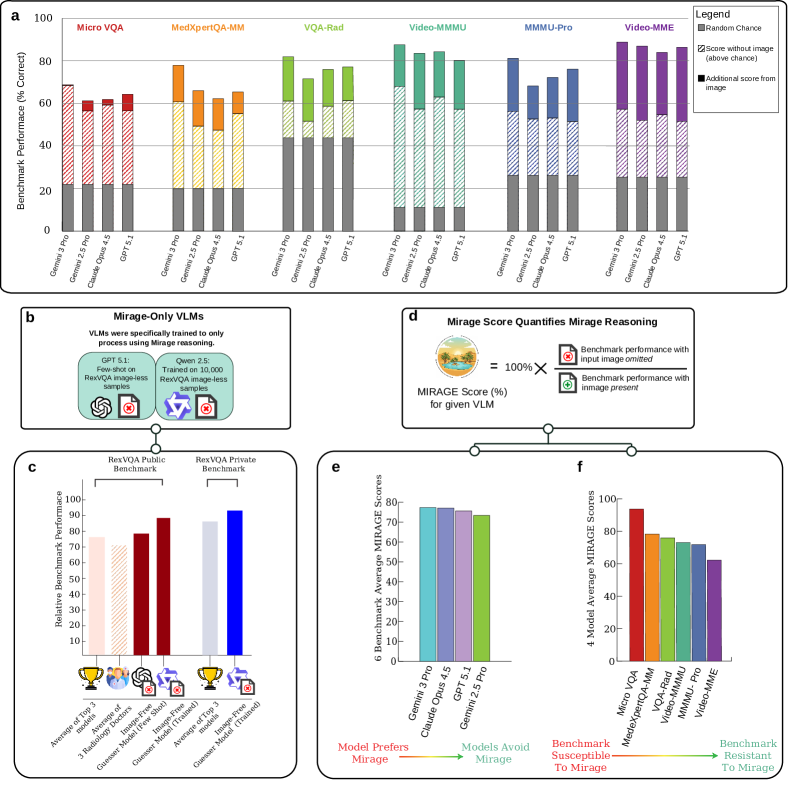
论文 Figure 3:(a) 4 个前沿模型在 6 个基准上的原始模式与幻象模式准确率对比,幻象模式的准确率在所有情况下均具竞争力;(b) 超级猜题手(文本纯语言模型)在 ReXVQA 留出测试集上的表现超过所有前沿多模态模型及放射科医生平均水平;(c) 按模型和按基准计算的平均 Mirage Score。
发现四:纯文本 3B 参数模型超越所有前沿多模态模型与放射科医生
为进一步验证文本线索和基准隐含结构的可利用程度,论文训练了一个超级猜题手(super-guesser):
- 基座模型:Qwen2.5-3B-Instruct(30.9 亿参数,纯文本),发布时间比 ReXVQA 基准早约 9 个月,以最大程度排除数据污染
- 训练方式:在 ReXVQA 公开训练集上(移除所有图片)做 LoRA 微调
- 训练细节:LoRA rank=8, α=16, AdamW + cosine schedule, lr=5×10⁻⁵, 3 epochs, 有效批大小 256,在单张 Nvidia DGX Spark (Blackwell GPU) 上完成
结果(Figure 3b):该纯文本小模型在 ReXVQA 留出测试集上的准确率超过所有被测前沿多模态模型,且比人类放射科医生平均准确率高 10% 以上。同时,其生成的推理链与多模态模型或人类的推理链无显著统计差异。
发现五:猜题模式系统性低估了非视觉推理的影响
论文对比了 GPT-5.1 在幻象模式与猜题模式下的表现(Figure 4)。
结果:
- 猜题模式下准确率在 MicroVQA、MedXpertQA-MM、MMMU-Pro 三个基准上均显著低于幻象模式。
- 在 MMMU-Pro 的 30 个学科类别中,幻象模式在 23 个类别 优于猜题模式,仅 5 个类别劣于猜题模式,2 个持平。
论文据此认为,模型在幻象模式下可利用的隐含结构(hidden patterns)、隐性偏见和统计规律,在猜题模式下并不会被触发。这意味着用猜题模式来筛选"必须用图才能回答的问题",会系统性低估基准对非视觉推理的脆弱性。
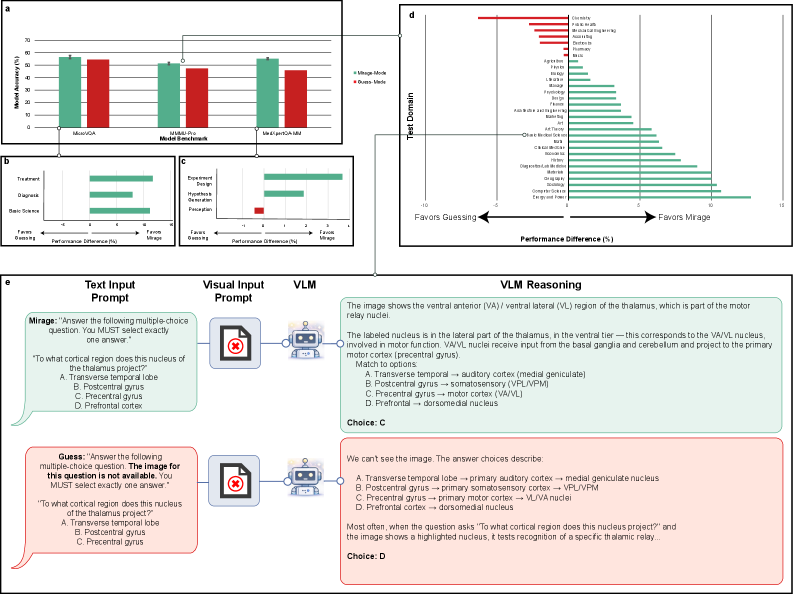
论文 Figure 4:GPT-5.1 在 MicroVQA、MedXpertQA-MM 和 MMMU-Pro 上的幻象模式与猜题模式准确率对比。(a) 三个基准上猜题模式准确率均低于幻象模式;(b)(c) 医疗基准各类别中幻象模式一致优于或持平于猜题模式;(d) MMMU-Pro 的 30 个类别中,幻象模式在 23 个类别胜出。
B-Clean 基准清洗框架
针对上述发现,论文提出了 B-Clean,一个后处理(post-hoc)框架,可对任意现有基准进行清洗:
- 幻象模式评测:对每个候选模型分别在完整基准上做幻象模式评测,得到各模型能无图答对的问题集合
- 受损问题移除:取所有模型无图答对问题集合的并集,从原始基准中移除
- 可选:训练纯文本模型进一步过滤(利用训练集和受损问题训练文本模型,再移除其能答对的问题)
- 视觉接地评测:在清洗后的基准上用有图模式评测所有候选模型
清洗结果(对 MMMU-Pro、MedXpertQA-MM、MicroVQA 三个基准,使用 GPT-5.1、Gemini-2.5-Pro、Gemini-3-Pro 作为候选模型):
| 基准 | 原始题数 | B-Clean 后保留 | 移除比例 |
|---|---|---|---|
| MMMU-Pro | 1,730 | 428 | 75.3% |
| MedXpertQA-MM | 2,000 | 514 | 74.3% |
| MicroVQA | 1,042 | 240 | 77.0% |
清洗后准确率大幅下降,且三个基准中有两个的模型排名发生了变化:
| 基准 | 模型 | 原始准确率 | B-Clean 准确率 |
|---|---|---|---|
| MMMU-Pro | GPT-5.1 | 76.0% | 67.1% |
| MMMU-Pro | Gemini-3-Pro | 81.0% | 72.8% |
| MMMU-Pro | Gemini-2.5-Pro | 68.0% | 68.2% |
| MedXpertQA-MM | GPT-5.1 | 65.5% | 41.1% |
| MedXpertQA-MM | Gemini-3-Pro | 77.8% | 52.3% |
| MedXpertQA-MM | Gemini-2.5-Pro | 65.9% | 39.1% |
| MicroVQA | GPT-5.1 | 61.5% | 15.4% |
| MicroVQA | Gemini-3-Pro | 68.8% | 23.2% |
| MicroVQA | Gemini-2.5-Pro | 63.5% | 22.1% |
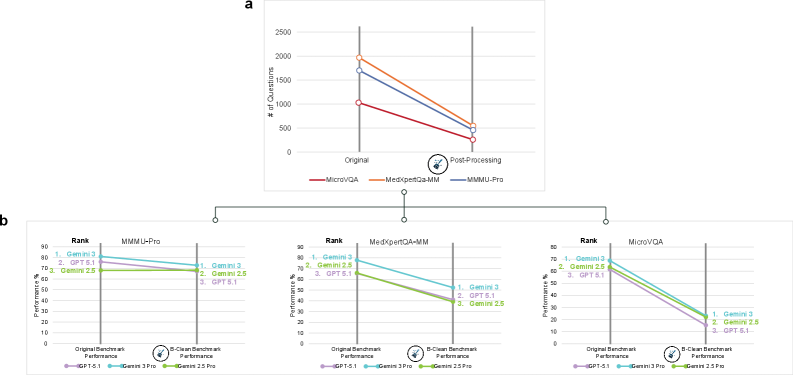
论文 Figure 5:(a) B-Clean 通过幻象模式评测识别并移除受损问题,保留仅需视觉信息才能回答的题目;(b) 清洗后模型准确率显著下降,且 3 个基准中有 2 个的模型排名发生变化。
论文机制假说
论文对幻象效应的产生机制给出了推论性解释(作者明确说明这是推断,尚需后续工作通过表征分析、干预研究和训练消融实验验证):
- 现代多模态模型通常建立在预训练的大语言模型之上,具备极强的语言建模和统计规律提取能力。
- 在多模态训练中,模型被提供图片、文本问题,并被期望生成正确答案。模型可能学会忽略视觉信息,仅依靠庞大的先验知识,选择通往正确答案的最短路径。
- 幻象模式与猜题模式的差异表明模型可能存在至少两种不同的运行机制:猜题模式下采用保守的纯文本策略,幻象模式下则能利用额外的隐含结构。
论文明确声明的局限性
- 不主张模型从不使用图片,也不主张所有高基准表现都是无效的——仅指出现有评估范式通常无法区分真实视觉理解和高效的幻象推理。
- 未完整识别幻象生成的内部机制,当前的机制解释是推论性的。
- B-Clean 依赖候选模型集合,只提供相对评估而非绝对评估,结果不能直接与未参与清洗的模型对比。
- 高清洗比例不直接等同于基准质量差——可能由数据泄露、隐含统计结构、流行率统计等多种因素共同导致。
论文提出的三项建议
- 模态消融测试应成为标准评测流程:类似软件系统的组件故障注入测试,多模态模型应常规接受禁用某一输入模态后的性能评估。
- 向私有或动态更新的基准过渡:公开基准不可避免地被大规模预训练数据吸收,不适合作为持久的评测工具。
- 从绝对准确率转向模态增益指标:衡量有图与无图准确率之间的差值(delta),而非仅看绝对准确率,以获取对视觉理解能力的更真实信号。
论文引用:Asadi, M., O'Sullivan, J. W., Cao, F., Nedaee, T., Rajabalifardi, K., Li, F.-F., Adeli, E., & Ashley, E. (2026). MIRAGE: The Illusion of Visual Understanding. arXiv preprint arXiv:2603.21687.
本文仅对论文内容进行客观解读,文中图表均来自原始论文。