小型语言模型 SLM:企业 AI 大规模落地的新范式
Deep Research 报告 | 2026 年 5 月 | 面向企业技术决策者、IT 架构师、AI 基础设施负责人
摘要
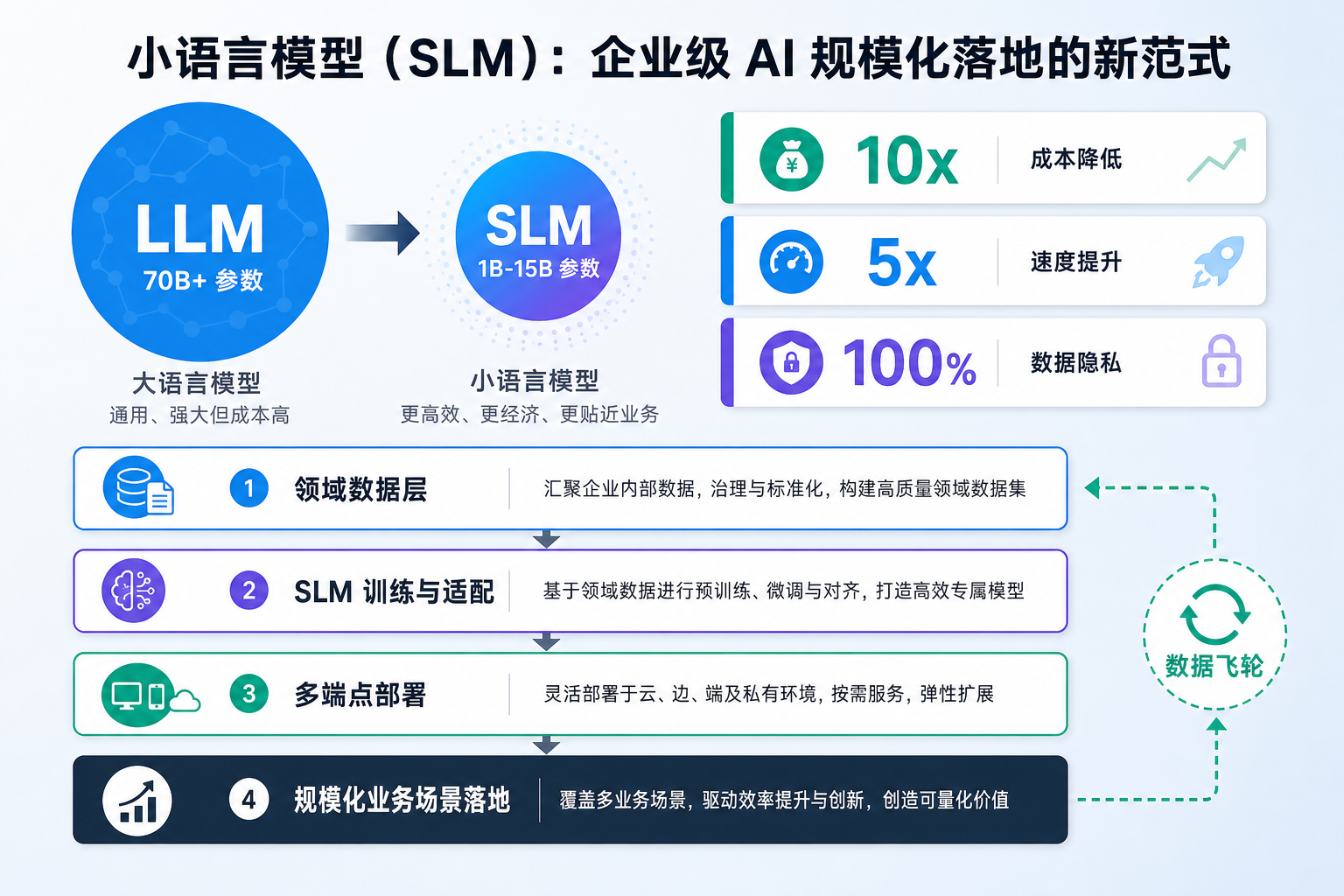
企业 AI 部署正面临三重瓶颈:推理成本居高不下、数据合规日趋严格、实时响应要求持续攀升。小型语言模型(Small Language Models, SLMs) ——参数规模在 1B–15B 之间的轻量级模型——正在成为突破这一困局的核心技术路径。
本文从 SLM 的演进脉络出发,逐层展开其技术架构、产业实践、行业影响与未来趋势。通过分析 AI21、微软、英伟达等厂商的实践以及制造、金融、医疗等行业的真实案例,我们得出结论:SLM 能够以 10–100 倍的成本优势覆盖 40%–70% 的企业 AI 任务,其毫秒级延迟、数据不出域的隐私保障和离线运行能力,构成了云端大模型无法替代的差异化价值。
这场变革不仅关乎技术选型,更关乎企业在 AI 产业化浪潮中能否建立可持续的竞争优势。
一、从"越大越好"到"小即是美"——SLM 的演进脉络
语言模型的发展经历了三次清晰的范式转变:
- 2018–2022 · 规模竞赛时代 — GPT-3(175B)、PaLM(540B)等模型验证了"规模定律":参数越多,能力越强。行业共识是"大力出奇迹"。
- 2023–2024 · 开源追赶时代 — Llama、Mistral 等开源模型证明 7B–70B 参数也能逼近闭源模型的表现,模型能力不再是巨头的专利。
- 2025 至今 · SLM 崛起 — 行业开始反思:大多数企业任务真的需要百亿级参数吗?答案是否定的。小模型在特定场景下不仅"够用",而且"更优"。
"我们相信 AI 的未来更加去中心化——不是所有事情都在庞大的数据中心运行。大模型仍将发挥作用,但在设备上运行的小而强大的模型将对 AI 的未来和经济产生重大影响。" — Ori Goshen, AI21 联合 CEO
这一转变并非偶然,而是四股力量共同推动的结果(如上图下半部分所示):
- 经济压力倒逼:云端推理成本持续高企,大量潜在 AI 应用因投入产出比不达标而搁浅
- 合规要求收紧:各国数据保护法规趋严,数据不出境从"加分项"变为"硬约束"
- 硬件能力跃升:边缘算力大幅提升,单台企业级服务器已足以流畅运行 3B–15B 参数模型
- 架构创新突破:Mamba 等新型状态空间模型架构,使小参数量模型也能高效处理长上下文
二、定义与边界——SLM 到底是什么
正式定义
SLM 指参数规模在 10 亿至 150 亿 之间的轻量级语言模型,其核心特征是能够在企业级服务器甚至边缘设备上本地运行,无需依赖第三方云端 API。
SLM 与 LLM 的关键差异
| 维度 | SLM(1B–15B) | LLM(70B+) |
|---|---|---|
| 部署方式 | 企业私有部署 / 边缘设备 | 云端数据中心 |
| 推理成本 | $0.01–$0.1 / 百万 token | $1–$10 / 百万 token |
| 响应延迟 | 毫秒级 | 秒级 |
| 数据隐私 | 数据不出企业内网 | 数据上传至云端 |
| 能力定位 | 垂直领域专精 | 通用任务广覆盖 |
| 离线可用 | 支持 | 不支持 |
三个常见误区
误区一:SLM 只是大模型的"缩水版"
SLM 并非简单地砍掉参数。以 AI21 的 Jamba 架构为例,它通过引入 Mamba 状态空间层替代部分 Transformer 层,在小参数量下实现了架构层面的效率最优化——这是一条完全不同的技术路线。
误区二:SLM 只能做简单任务
Jamba Reasoning 3B 仅 30 亿参数,却在指令遵循(IFBench)、通用知识(MMLU-Pro)等基准测试中超越了多个 7B 甚至 14B 级别的模型。小不等于弱。
误区三:企业必须在 SLM 和 LLM 之间二选一
最佳实践恰恰是混合架构——简单任务由 SLM 本地处理,复杂任务路由到云端 LLM,兼顾成本与效果。后文将详细展开这一架构设计。
三、技术架构——为什么小模型也能这么强
理解了 SLM 是什么之后,一个自然的追问是:为什么 3B 参数就能达到甚至超越 7B–14B 模型的表现?答案在于架构层面的根本性创新。
纯 Transformer 在小规模下的瓶颈
传统 Transformer 架构以自注意力机制为核心,计算和内存开销随上下文长度呈二次方增长。当模型参数被压缩到 3B–15B 时,这一瓶颈变得尤为突出:
- 长上下文性能急剧下降:超过 32K token 后推理速度大幅减慢
- KV 缓存内存占用过高:键值缓存随上下文线性增长,很快吃满有限的设备内存
混合架构的破局思路:以 Jamba 为例
AI21 提出的 Jamba 架构,将 Transformer 层和 Mamba 层交替堆叠,让两种机制各展所长:
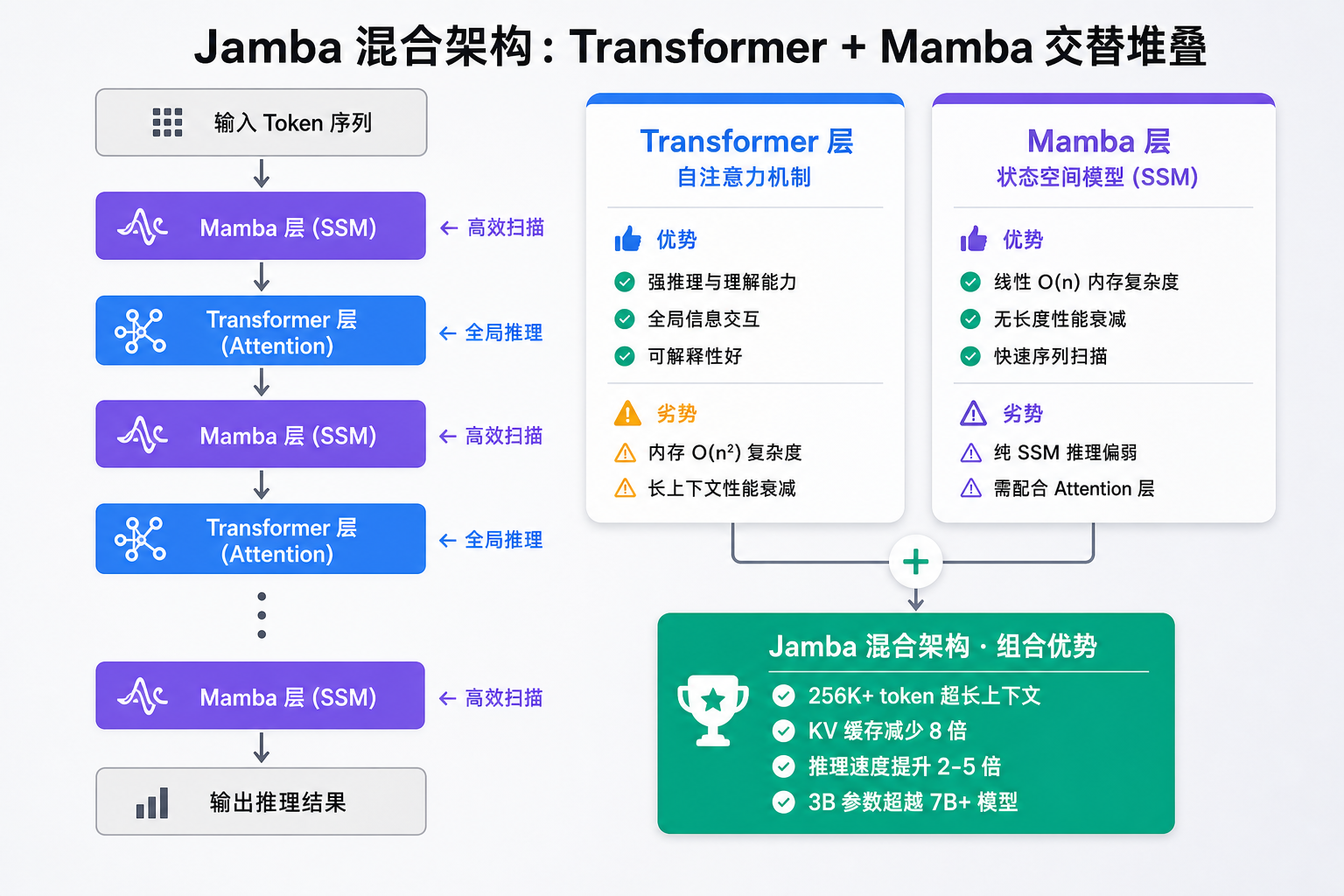
如上图所示,左侧是 Jamba 的层交替堆叠结构,右侧展示了两种机制的分工互补:
- Mamba 层(基于状态空间模型 SSM)以线性复杂度处理长序列,不会因上下文变长而减速
- Transformer 层保留了自注意力的强推理能力,用于需要全局信息交互的关键位置
- KV 缓存优化:混合设计将内存占用降至纯 Transformer 架构的 1/8
实际效果:Jamba Reasoning 3B 在处理 256K token 超长上下文时,仍可保持 40 token/s 的推理速度——在单台普通服务器上即可实现。
性能实测对比
| 模型 | 参数 | 最大上下文 | 32K 上下文推理速度 |
|---|---|---|---|
| Jamba Reasoning 3B | 3B | 256K | 40 token/s |
| Llama 3.2 3B | 3B | 128K | 20 token/s |
| DeepSeek R1 7B | 7B | 128K | 15 token/s |
| Phi-4 Mini 14B | 14B | 128K | 10 token/s |
可以看到,架构创新带来的效率提升远超参数数量增加带来的收益。这正是 SLM "以小博大"的技术根基。
四、产业实践——谁在推动,效果如何
技术上的可行性需要产业实践来验证。以下三个案例从不同角度展示了 SLM 的实战表现。
AI21:开源 SLM 的标杆制造者
以色列 AI 创业公司 AI21 是 SLM 去中心化浪潮的旗手,其 Jamba Reasoning 3B 是当前最具代表性的开源 SLM。
| 指标 | 数据 |
|---|---|
| 参数规模 | 30 亿 |
| 上下文窗口 | 256K(实验性支持 1M) |
| 开源协议 | Apache 2.0 |
| 推理速度提升 | 同量级模型的 2–5 倍 |
| 内存占用 | 同量级纯 Transformer 模型的 1/8 |
在多项基准测试中,这个仅 3B 参数的模型超越了多个更大的竞争对手——指令遵循(IFBench)、通用知识(MMLU-Pro)、长上下文推理等维度均处于同量级领先。
"缩小规模实现了去中心化、个性化和成本效率。个人和企业可以在设备上运行自己的模型,而不必依赖数据中心昂贵的 GPU。" — AI21 官方博客
微软:垂直领域微调的有效性验证
微软研究团队在云供应链履约场景中对 SLM 进行了系统性测试。核心发现是:在特定领域任务中,经过少量数据微调的 SLM,其准确率可超越通用大模型,同时运行速度大幅领先。
这一结论具有普遍意义——对于边界清晰、模式稳定的业务任务,"小模型 + 领域数据"的组合往往比"大模型 + 通用能力"更具性价比。
英伟达:SLM 是多智能体系统的理想单元
英伟达的研究则从另一个维度揭示了 SLM 的价值——多智能体(Agentic AI)系统。
在多 Agent 协作架构中,每个 Agent 只需专注自身的特定任务,不需要通用大模型的全栈能力。SLM 的轻量特性使其成为理想的 Agent 运行时:
- 同一台服务器可并行运行多个 SLM Agent,总成本远低于多次调用云端 LLM
- Agent 间通信延迟极低,支撑复杂的多步协作流程
- 每个 Agent 可独立微调,实现"专人专事"
五、行业影响——从试点到规模化落地
从实验室到生产环境,SLM 在企业中的落地正沿着清晰的梯度推进。
落地现状
| 阶段 | 行业 | 典型应用 | 成熟度 |
|---|---|---|---|
| 大规模落地 | 金融、法律 | 合同条款比对、文档审查、数据脱敏 | 🟢 已成熟 |
| 快速普及 | 制造、能源 | 产线实时质检、设备异常诊断、现场技术手册检索 | 🟡 增长中 |
| 试点验证 | 医疗、政府 | 电子病历本地分析、内网知识库问答、敏感公文处理 | 🟠 起步期 |
对不同角色的影响
企业 IT 决策者:需要重新评估 AI 预算分配——将高频简单任务迁移至本地 SLM,可释放 70% 以上的云端推理开支,同时解决敏感数据上云的合规隐患。
应用开发者:可以在应用中直接内置 AI 能力,无需依赖外部 API。这意味着离线场景、弱网环境、边缘设备上的 AI 功能首次变得切实可行。
AI 基础设施厂商:市场需求正从"云端 GPU 算力"向"边缘 AI 推理算力"迁移,混合云架构、SLM 优化工具链将成为新的增长极。
业务部门负责人:当 AI 工具成本降低 1–2 个数量级、数据无需离开内网,原本因预算或合规受阻的业务场景将被批量激活。
四个结构性变革
- AI 算力从集中走向分布:企业数据中心、产线设备、门店终端都将具备本地推理能力,形成"端-边-云"混合算力网络
- 数据主权回归企业:敏感数据不再需要上传第三方云端,合规成本与数据泄露风险同步降低
- AI 从"部门级工具"变为"全员级基础设施":成本下降 100 倍后,AI 不再是少数高价值岗位的专属,而是全员生产力底座
- 垂直行业模型成为新赛道:竞争焦点从"参数谁多"转向"谁更懂行业",Know-How 的封装能力比模型规模更关键
六、核心洞见与未来趋势
三大核心洞见
洞见一:经济性是最大的颠覆力量
当前企业 AI 部署的首要瓶颈不是技术能力,而是经济可行性。云端大模型的推理成本使大量应用场景在投入产出比上无法自洽。SLM 将单位推理成本压缩 1–2 个数量级,将释放大批因成本受阻的长尾应用。
这类似于从大型机到 PC 的转变——大型机并未消失,但计算变得足够便宜,让每一个组织都能负担。
洞见二:混合架构是企业部署的最优解
没有任何单一模型能在所有任务上都是最优的。智能路由架构将成为企业 AI 基础设施的标配:
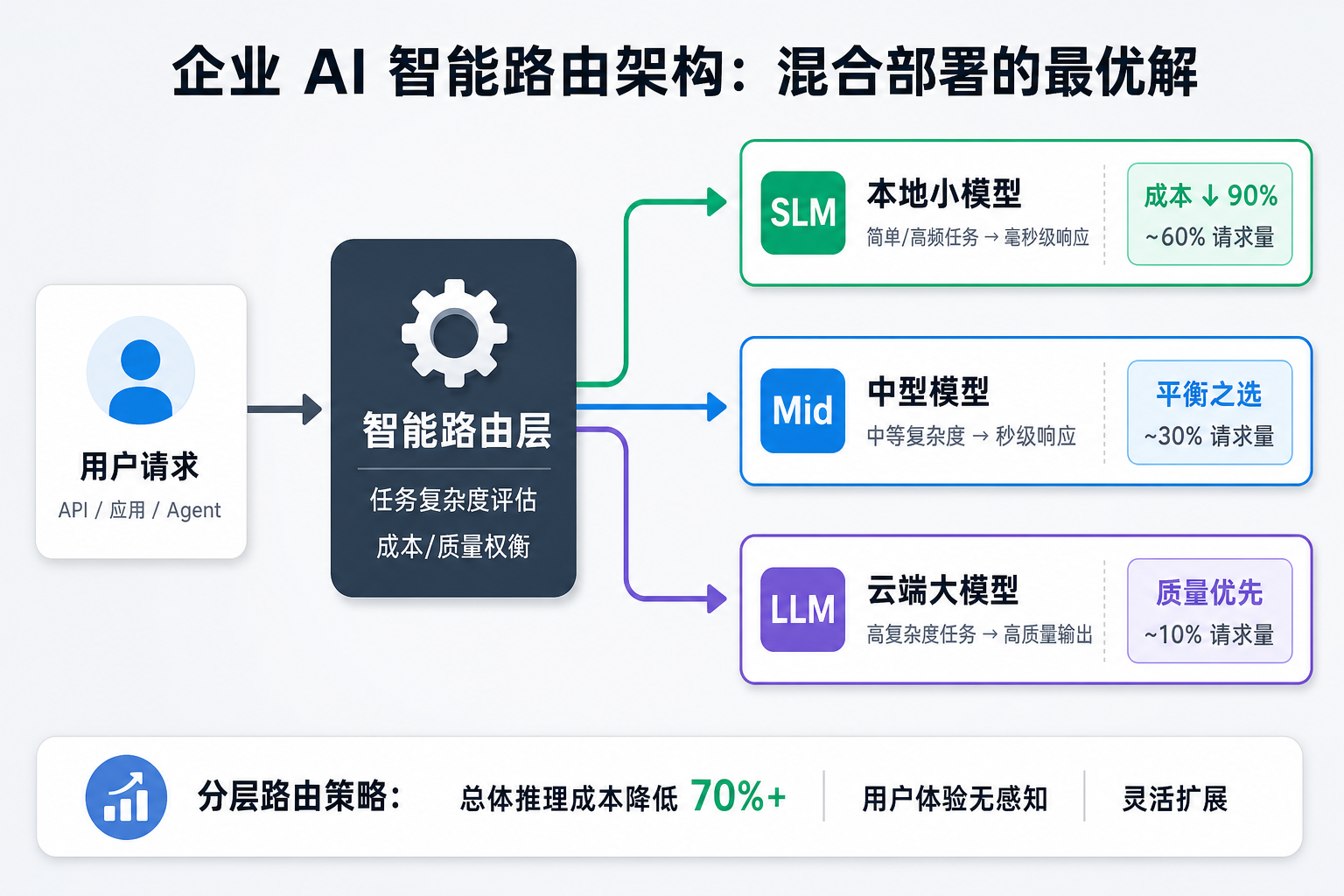
如图所示,约 60% 的简单/高频请求由本地 SLM 处理(成本降低 90%),30% 的中等任务由中型模型承接,仅 10% 的高复杂度任务路由至云端 LLM。这种分层架构在保持用户体验的同时,可将总体 AI 推理成本降低 70% 以上。
洞见三:SLM 开启了真正的企业级私有 AI
云端大模型提供的是"千人一面"的通用能力,而部署在企业内部的 SLM 可以完全基于私有数据微调、深度适配专有业务流程、7×24 小时稳定运行且不依赖外网。这不是第三方 API 服务,而是企业数字化底座的有机组成部分——尤其对金融、医疗、政府等强合规行业而言,这一点至关重要。
三大未来趋势
趋势一:参数持续缩小,能力逆势提升
预计到 2027 年:1B 参数模型将达到今天 7B 模型的能力水平;单台企业服务器流畅运行 7B–15B 模型将成为标配;垂直领域 SLM 在各自赛道上超越通用大模型。
趋势二:端云协同成为主流部署范式
未来的企业 AI 不会是纯云端或纯本地,而是三层协同:

- 感知层(产线、门店、终端设备):运行 SLM 进行实时数据处理与即时响应,承载约 60% 的日常任务
- 决策层(企业数据中心):智能路由引擎 + SLM 训练微调中心,承载约 30% 的任务
- 增强层(公有云):处理少量需要顶级模型能力的复杂任务,仅约 10%
趋势三:行业专用模型成为竞争制高点
"模型小型化 + 行业专业化"将催生新一代垂直 AI 产品:基于特定行业数据训练的 3B–7B 模型,效果超越通用大模型;行业 Know-How 被封装进模型权重,成为可复用的智能资产;预训练 + 微调 + 部署工具链一体化,让普通企业也能快速落地。
这类似于工业软件的演进轨迹——从通用 ERP 到行业垂直解决方案,SLM 将沿着同样的路径成为各产业的"智能基础设施"。
七、量化总览与实践指南
核心数据一览
| 维度 | 核心数据 | 商业意义 |
|---|---|---|
| 成本降低 | 10–100 倍 | AI 从高成本项目变为常规运营工具 |
| 任务覆盖 | 40%–70% 企业任务 | 大多数日常 AI 需求无需大模型 |
| 延迟改善 | 秒级 → 毫秒级 | 实时交互与边缘场景得以解锁 |
| 隐私保障 | 数据不出企业内网 | 满足金融、医疗等强合规要求 |
| 离线能力 | 100% 离线可用 | 弱网与无网场景全覆盖 |
企业落地成熟度模型
| 级别 | 描述 | 适用场景 |
|---|---|---|
| L1 · 基础试用 | 使用现成量化模型进行简单推理 | 文本摘要、分类、信息提取 |
| L2 · 混合部署 | SLM + LLM 智能路由 | 企业通用 AI 服务平台 |
| L3 · 领域微调 | 基于业务数据微调 SLM | 垂直领域专用 AI |
| L4 · 多 Agent 协作 | 多个 SLM 组成智能体系统 | 复杂业务流程自动化 |
| L5 · SLM 原生架构 | 全部 AI 能力基于 SLM 构建 | 新一代 AI 原生应用 |
常见误区与避坑指南
| 误区 | 正确做法 |
|---|---|
| "所有任务都用大模型最保险" | 先按复杂度分级,能用 SLM 处理的任务优先降级 |
| "SLM 是 LLM 的替代品" | SLM 是补充而非替代,混合架构才是最优解 |
| "小模型开箱即用不需要优化" | 量化、蒸馏、上下文裁剪等优化对 SLM 同样关键 |
| "开源模型可以直接上生产" | 生产环境必须经过安全审计、合规测试和压力测试 |
入门资源
| 资源 | 链接 | 说明 |
|---|---|---|
| Jamba Reasoning 3B | Hugging Face | 当前最强开源 3B 推理模型 |
| Llama 3.2 | Meta | 最成熟的小模型开源生态 |
| LM Studio | lmstudio.ai | 桌面端一键运行 SLM |
| llama.cpp | GitHub | 轻量级边缘设备推理框架 |
| VERL | GitHub | 开源强化学习微调平台 |
结语
小型语言模型不只是一项技术改进,更是 AI 产业的一次范式迁移。
正如 1980 年代个人电脑的普及并非为了取代大型机,而是让计算能力渗透到每一张办公桌一样——SLM 的崛起不是要取代大模型,而是要让 AI 能力真正下沉到每一条生产线、每一个业务流程、每一台边缘设备。
这场变革的核心不在于"小",而在于**"可控"**——成本可控、数据可控、延迟可控、部署可控。SLM 回答的不是"企业能不能用 AI"这个已经过时的问题,而是"企业能不能大规模、可持续、安全地用 AI"这个真正的产业命题。
当推理成本下降 100 倍,当数据终于可以留在自己的安全边界内,当实时响应不再依赖云端——你所在的行业,会发生什么?
参考资料
- AI21 Labs. (2026). "Introducing Jamba Reasoning 3B: Tiny Model, Huge Possibilities". ai21.com/blog
- IEEE Spectrum. (2026). "Small Language Models: Edge AI Innovation From AI21". spectrum.ieee.org
- Microsoft Research. (2025). "Small Language Models for Application Interactions: A Case Study". microsoft.com/en-us/research
- NVIDIA Research. (2025). "Small Language Models Are the Future of Agentic AI". arXiv:2506.02153
- Team, J. et al. (2024). "Jamba: A Hybrid Transformer-Mamba Language Model". arXiv:2403.19887