论文解读|DeepSeek-V4:百万 token 上下文的效率革命

论文信息
- 标题:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
- 团队:深度求索(DeepSeek)
- 发布时间:2026 年 4 月 24 日
- 模型权重:Hugging Face 开源
- API:chat.deepseek.com 同步上线(Expert Mode = V4-Pro,Instant Mode = V4-Flash)
TL;DR
大模型上下文窗口冲到百万 token 已经不算新闻了。但"能声称支持"和"能经济地跑起来"之间,差着一道工程鸿沟——标准注意力的平方复杂度让 KV cache 和 FLOPs 在百万级直接爆炸,真实部署下谁也用不起。
DeepSeek-V4 的核心贡献不是"更大的模型",而是用更少的钱跑更长的上下文。一组数据足以说明问题:在 1M token 场景下,V4-Pro(1.6T 总参 / 49B 激活)的单 token 推理 FLOPs 仅为上一代 V3.2 的 27%,KV cache 仅为 10%。注意——V4-Pro 的激活参数量是 V3.2 的 1.3 倍。参数翻了,推理成本反降 3.7 倍。
这不是靠堆卡砸钱换来的,而是三个架构级创新的叠加效应:CSA + HCA 混合注意力重写了长上下文的成本函数;流形约束超连接 mHC 让 61 层 1.6T 参数的模型稳定训练;Muon 优化器替代 AdamW 拿到更快收敛。再加上一套"领域专家专精 + 在策略蒸馏"的全新后训练范式,V4-Pro-Max 在 LiveCodeBench 拿到 93.5,Codeforces 排到人类第 23 名,Putnam-2025 数学竞赛满分——开源模型首次在竞赛级推理上追平闭源前沿。
一、V4 到底在解决什么问题
从 8K 到 128K 再到 1M,上下文窗口的数字一路飙升,但绝大多数模型都困在同一个死结里:长度上去了,成本爆了,精度掉了。
原生注意力的复杂度是 O(n²)。一百万 token 意味着一万亿次注意力比较。KV cache 线性增长,在 1M 下单条请求的显存占用就足以打满整卡。这不是一个"加硬件就能解决"的问题——上一代 V3.2 跑 1M token 时,推理成本已经让大部分工业负载望而却步。
同时,深层 MoE 模型的训练稳定性是另一条暗线。万亿参数模型的 loss spike 频发,简单回滚无法阻止下一次尖峰;残差连接在深层堆叠时信号衰减严重;传统 AdamW 优化器在这个尺度上的收敛效率已经触顶。
V4 的论点非常明确:百万 token 上下文不再是能力问题,而是效率问题。它不是在"能不能跑"上做文章,而是把"跑多少钱"降到了工业可接受区间。
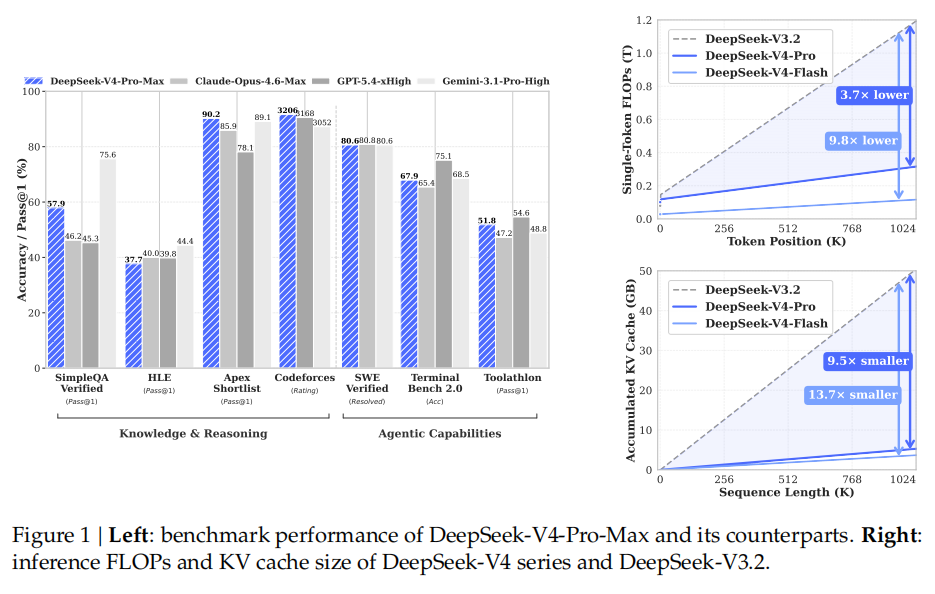
Figure 1:左图为 V4-Pro-Max 与闭源前沿模型的 benchmark 对比;右图为单 token 推理 FLOPs 和累积 KV cache 随序列长度的增长曲线——V4 系列在 1M token 处的优势一目了然。(图片来源:DeepSeek-V4 技术报告)
二、两款模型:旗舰与高效
V4 发布两个 MoE 变体,定位清晰。
| 维度 | V4-Pro | V4-Flash | V3.2(基线) |
|---|---|---|---|
| 总参数 | 1.6T | 284B | 671B |
| 激活参数 / token | 49B | 13B | 37B |
| Transformer 层数 | 61 | 43 | — |
| 路由专家数 / 层 | 384 | 256 | — |
| 激活路由专家 / token | 6 | 6 | — |
| 预训练数据 | 33T tokens | 32T tokens | — |
| 上下文长度 | 1M | 1M | 128K |
| 1M 推理 FLOPs(vs V3.2) | 27% | 10% | 100% |
| 1M KV cache(vs V3.2) | 10% | 7% | 100% |
关于 1.6T 参数量的行业定位:截至 2026 年 5 月,V4-Pro 的 1.6T 总参数是开源模型中最大的。同期可比的开源 MoE 模型包括:Kimi K2.5(1T / 32B 激活)、Hunter Alpha(1T / 32B 激活)、GLM-5(744B / 40B 激活)、Mistral Large 3(675B / 41B 激活)、Llama 4 Maverick(400B / 17B 激活)。V4-Pro 在总参数和激活参数两个维度上都显著领先。当然,MoE 模型的"总参数"更多决定显存下限,真正影响推理成本的是"激活参数"——V4-Pro 的 49B 激活参数同样是开源最高的。
V4-Flash 的总参数仅为 V3.2 的 42%,但 Flash-Base 已在大多数基准上超越 V3.2-Base。参数少一半,效果更好——这就是架构升级的杠杆。
三、核心创新一:CSA + HCA 混合注意力
这是 V4 最重要的架构变更,也是效率增益的主要来源。V3 系列的 Multi-head Latent Attention(MLA,多头潜在注意力)在 V4 中被完全替换。
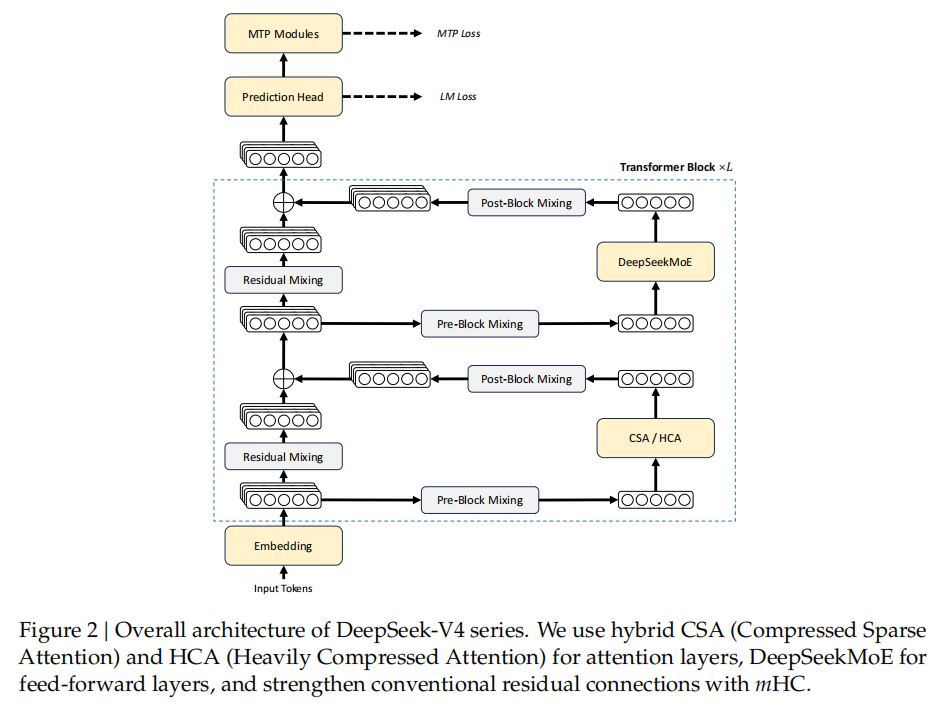
Figure 2:V4 整体架构。注意力层在 CSA 和 HCA 之间交替排布,前馈层使用 DeepSeekMoE,传统残差连接被替换为流形约束超连接 mHC。(图片来源:DeepSeek-V4 技术报告)
3.1 压缩稀疏注意力——先压后挑
CSA(Compressed Sparse Attention,压缩稀疏注意力)做两步削减:
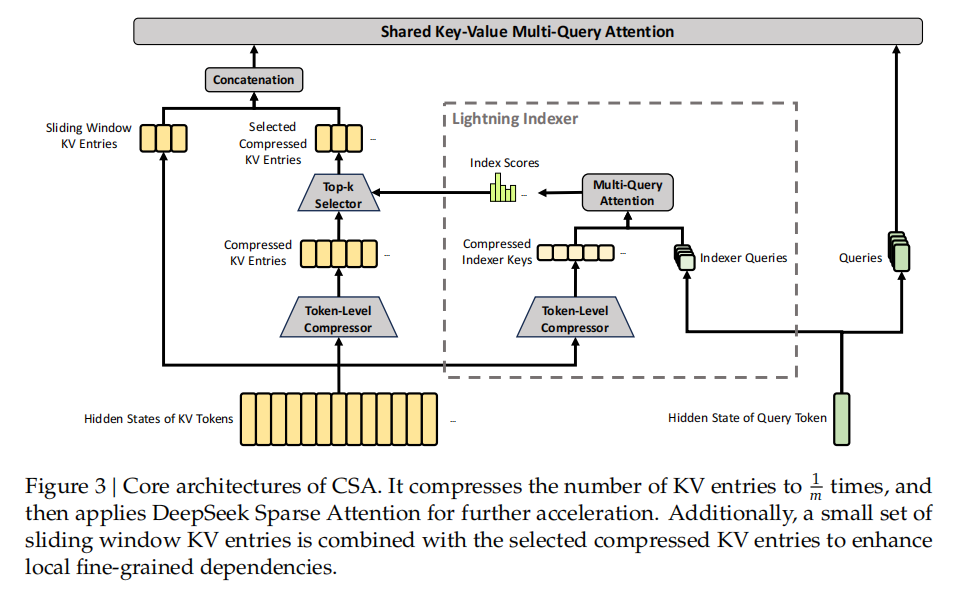
Figure 3:CSA 工作流程。压缩器每 4 个 token 合并为 1 个压缩 KV 条目 → Lightning Indexer 对压缩块打分并选取 top-k → 滑动窗口分支保留最近未压缩的 token。(图片来源:DeepSeek-V4 技术报告)
第一步,KV 压缩。 每 m=4 个连续 token 的 KV 通过 softmax-gated pooling 合并为 1 个条目。100 万个 KV 条目直接压缩成 25 万个。这不是简单平均——学习的位置偏置让压缩保留关键信息。举个例子:
原始 token: [t1] [t2] [t3] [t4] | [t5] [t6] [t7] [t8] | ...
|_______________| |_______________|
group 1 group 2
↓ ↓
压缩后 KV: [C1] [C2] [C3] ...每 4 个 token 的 KV 信息被加权合并成一个压缩条目,序列长度直接缩短到 1/4。
第二步,稀疏选择。 25 万个压缩条目仍然太多。CSA 引入 Lightning Indexer——一个轻量级的 FP4 精度多头点积评分器,对当前 query 快速给所有压缩块打分,然后只选 top-k 个(V4-Pro 取 k=1024,V4-Flash 取 k=512)进入真正的注意力计算。
两重削减叠加:先 4 倍压缩序列长度,再只看最相关的千分之几。绝大多数上下文被彻底跳过。
3.2 重度压缩注意力——重压不挑
HCA(Heavily Compressed Attention,重度压缩注意力)走另一个极端:每 m'=128 个 token 压缩为 1 个 KV 条目。100 万 token 变成约 7800 个条目——序列已经够短了,直接做 dense attention,不做稀疏选择。
这是一个有意识的设计互补:CSA 追求精细检索(compress + sparse select),适合"从百万 token 里捞一根针"的场景;HCA 追求全局概览(heavy compress + dense),适合"整体把握长文脉络"的场景。
3.3 交替使用 + 滑动窗口
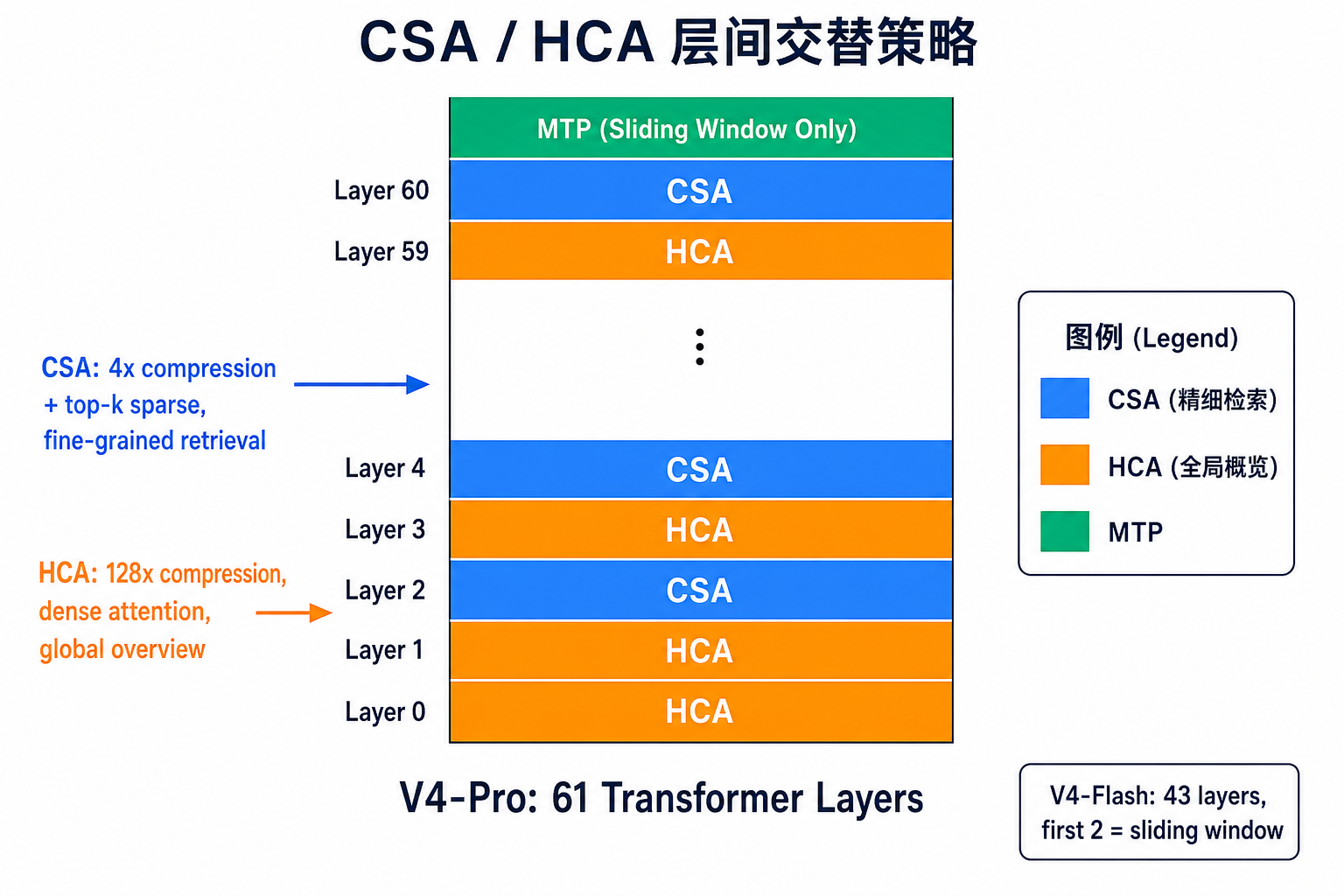
Figure 4:CSA / HCA 层间交替策略。V4-Pro 前 2 层用 HCA 做全局概览,后续层 CSA(精细检索)与 HCA(全局概览)交替排布,最顶层 MTP 仅用滑动窗口。(图片由 ICE 数字实验室绘制)
V4-Pro 前 2 层用 HCA,后续层 CSA 与 HCA 交替;V4-Flash 前 2 层用纯滑动窗口,后续交替。不同层用不同的"看文档方式"——有的层做精确查找,有的层做粗粒度扫描。
两种注意力都附带一个 窗口大小 128 的滑动窗口分支,保留最近 128 个未压缩 token 的原始 KV。逻辑很朴素:压缩再好,最近刚读过的内容不应该被模糊化。再加上可学习的 Attention Sink(允许注意力分数之和小于 1),模型可以表达"当前没有值得关注的内容"。
论文的消融实验给出了关键结论:单独用 CSA 或 HCA 都无法同时保住质量和效率,交替混合才是最优解。 这是整篇论文最核心的架构洞见。
四、核心创新二:mHC 流形约束超连接
标准残差连接是 Transformer 的生命线,但在 61 层、1.6T 参数的尺度下,它的表达能力已经见顶。
V4 的做法是把单通道残差流扩展为 n_hc=4 条并行流(Hyper-Connections),通过三组学习矩阵 (A, B, C) 在每层混合。但原始 HC 在深层堆叠时数值不稳——混合矩阵的谱范数不受约束,信号可能逐层放大直到训练崩溃。
mHC 的核心思路:将混合矩阵约束在 Birkhoff 多面体(双随机矩阵流形)上。双随机矩阵的每行之和和每列之和都恰好为 1,这保证了谱范数 ≤ 1——信号传播天然具有非扩张性。具体通过 Sinkhorn-Knopp 迭代(20 次)将参数投影到该流形上实现。
打个比方:标准残差连接是"单车道窄路",HC 是"多车道高速",mHC 是"多车道高速 + 智能限速器"——既拓宽了信息带宽,又确保不超速翻车。
整体墙时(wall-clock time)开销仅 6.7%,但它使 61 层 1.6T 的 V4-Pro 稳定训练成为可能。这不是一个可选的优化——没有 mHC,V4-Pro 这个规模的模型根本训不出来。
五、核心创新三:Muon 优化器
V4 将大部分参数的优化器从 AdamW 切换为 Muon。AdamW 对每个权重独立维护动量和方差估计;Muon 则对完整梯度矩阵进行正交化——通过 Newton-Schulz 迭代将更新方向的所有奇异值归一化到接近 1,确保没有单一方向主导更新。
V4 设计了混合迭代策略:前 8 步用快速收敛系数,后 2 步用精确稳定系数。优化器分工明确:
| 参数组 | 优化器 |
|---|---|
| 主体参数(注意力、MoE、MLP 等) | Muon |
| Embedding 层、预测头 | AdamW |
| 所有 RMSNorm 权重 | AdamW |
| mHC 静态部分 | AdamW |
一个值得注意的简化:由于 V4 的注意力架构已经对 query 和 KV 条目做了 RMSNorm 归一化,不需要额外的 QK-Norm 来防止注意力数值爆炸。这让 Muon 的集成更干净。
六、训练稳定性:两个工程级 trick
万亿参数 MoE 的训练稳定性是这类工作的真正硬骨头。V4 报告了两个经验性但有效的解决方案。
预期路由(Anticipatory Routing)
核心发现:loss spike 始终与 MoE 层中的异常值有关,路由机制会放大这些异常值,形成"坏路由 → 异常值 → 更坏路由"的正反馈循环。
解决方案是解耦路由网络与主干网络的参数同步——用稍微旧的参数 θ_{t-Δt} 计算路由决策,当前参数 θ_t 用于主干计算。工程实现上采用自动检测:仅在 loss spike 触发时短暂回滚并激活预期路由,运行一段时间后恢复标准训练。额外开销约 20%。
SwiGLU 钳位
对 SwiGLU 的线性分量 clamp 到 [-10, 10],门控分量上限为 10。简单粗暴,但有效消除异常值且不损害模型性能。这提醒我们:在这个规模下,很多 trick 的价值不在于理论优雅,而在于工程上管用。
七、后训练范式:领域专家 + 在策略蒸馏
V4 的后训练流程做了一个大的方向切换:完全抛弃 V3.2 的混合 RL 阶段,改用两阶段范式。
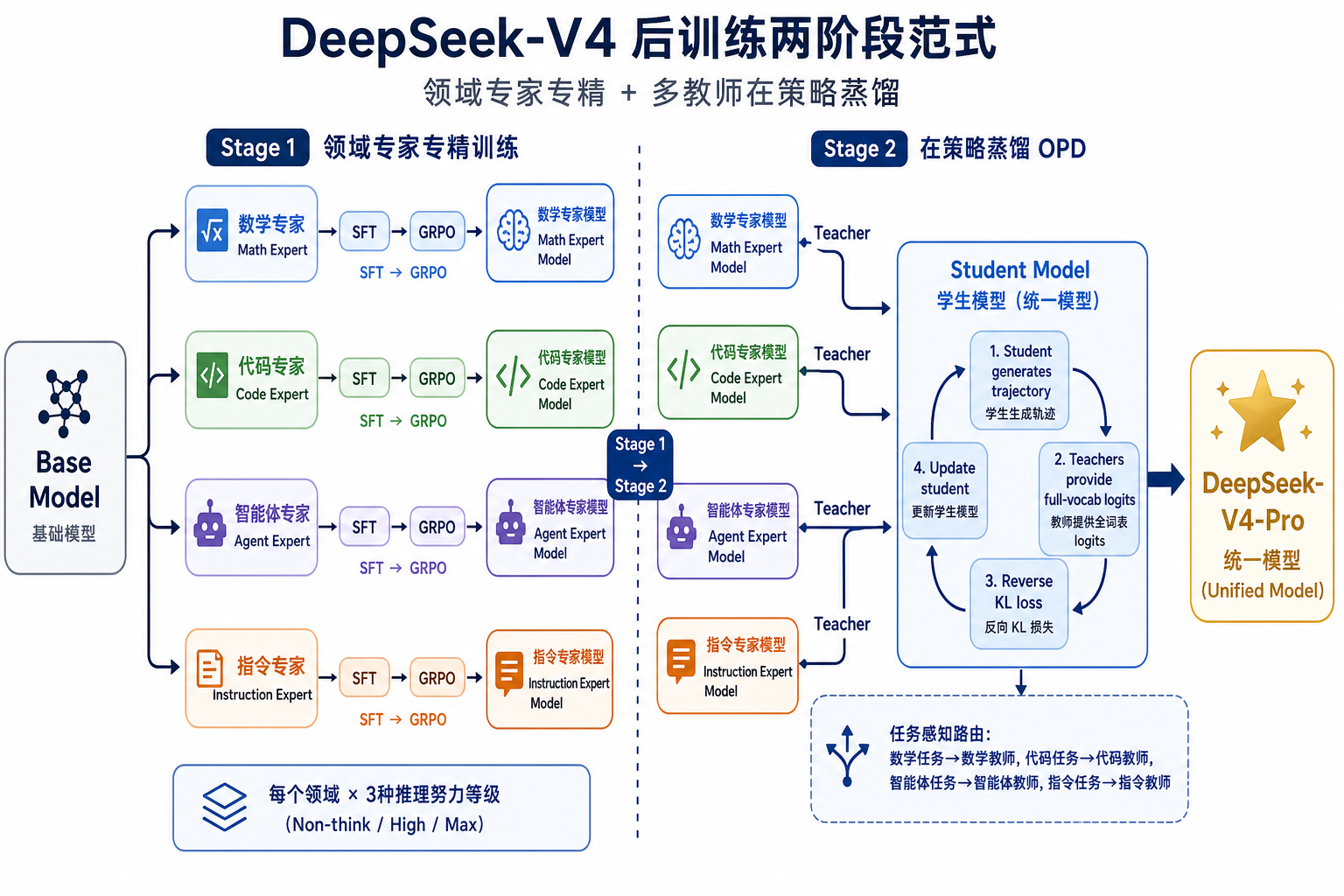
Figure 5:V4 后训练两阶段范式。Stage 1 将基础模型分别训练为数学、代码、智能体、指令等领域专家(SFT → GRPO);Stage 2 通过在策略蒸馏(OPD),学生模型生成自己的轨迹,多教师提供 full-vocab logits 监督,经 reverse KL 损失合并为统一模型。(图片由 ICE 数字实验室绘制)
第一阶段:专家专精训练
针对数学、代码、智能体、指令跟随等领域,分别训练垂直专家。每个专家经历 SFT(监督微调)→ GRPO(Group Relative Policy Optimization,强化学习),把单项能力拉到最强。不同推理努力等级(Non-think / Think High / Think Max)的专家用不同的长度惩罚和上下文窗口训练。
一个有趣的设计是 生成式奖励模型(GRM):对于难以规则验证的任务,V4 不训练独立的奖励模型,而是让模型自身同时充当生成者和评估者——用带评分准则的 RL 数据训练,实现生成能力与评估能力的联合优化。
第二阶段:在策略蒸馏(OPD)
将十余个领域专家合并为一个统一模型。与离线蒸馏不同,OPD 是在策略的——学生模型生成自己的轨迹,教师在学生轨迹上提供完整词汇表的概率分布作为监督。损失函数用 reverse KL(mode-seeking),推动学生在教师的高概率区域集中概率质量,产出更决断的输出。
OPD 的核心优势:在 logits 级对齐上整合知识,规避了传统权重合并或混合 RL 中常见的性能退化。论文特别强调使用完整词汇表 logit 蒸馏而非 per-token 估计,以降低梯度方差。
八、基础设施层面的工程亮点
论文用了相当大的篇幅讲基础设施优化,这在技术报告中不算常见。几个值得关注的点:
| 优化 | 效果 |
|---|---|
| 细粒度专家并行重叠 | 通信隐藏在计算中,1.5-2x 加速 |
| TileLang 内核开发 + Z3 求解器 | CPU 验证开销从百微秒降至 <1μs |
| FP4 QAT(量化感知训练) | 无损 FP4→FP8 反量化,复用 FP8 训练管线 |
| 批次不变确定性内核 | 训练/微调/推理全链路比特级一致 |
| DeepGEMM 替代 cuBLAS | 端到端批次不变矩阵乘法 |
其中 FP4 QAT 的设计尤其巧妙。FP4(E2M1) 到 FP8(E4M3) 的反量化是无损的(FP8 动态范围更大,FP4 的 block scale factor 可被完全吸收),这意味着整个 FP4 训练流程无需修改现有 FP8 管线——一个纯工程的洞见,但极大降低了落地门槛。
论文还提到,当前硬件上 FP4×FP8 的峰值吞吐与 FP8×FP8 相同,但专用硬件可以让 FP4 比 FP8 快约 1.33 倍——这为未来留了一条开放车道。
九、评测:开源天花板,距闭源前沿 3-6 个月
V4-Pro-Max 的评测数据很有意思,不是全面碾压,而是结构性领先 + 结构性落后。
V4 领先的领域
| Benchmark | V4-Pro-Max | 对比 |
|---|---|---|
| LiveCodeBench Pass@1 | 93.5 | Gemini-3.1-Pro: 91.7 |
| Codeforces Rating | 3206 | GPT-5.4: 3168 |
| Putnam-2025 | 120/120(满分) | — |
| 中文功能性写作胜率 | 62.7% | vs Gemini-3.1-Pro: 34.1% |
| 白领任务(vs Opus 4.6) | 非失败率 63% | 在分析/生成/编辑中一致领先 |
Codeforces 3206 分排在人类选手第 23 名,Putnam-2025 满分是形式化证明级别的——每道题都是可验证的完整证明,不是猜答案。这是开源模型首次在竞赛级推理上实质匹配闭源前沿。
V4 落后的领域
| Benchmark | V4-Pro-Max | 领先者 |
|---|---|---|
| MMLU-Pro | 87.5 | Gemini-3.1-Pro: 91.0 |
| SimpleQA-Verified | 57.9 | Gemini-3.1-Pro: 75.6 |
| GPQA Diamond | 90.1 | Gemini-3.1-Pro: 94.3 |
| MRCR 1M 检索 | 83.5 | Claude Opus 4.6: 92.9 |
规律很清晰:推理和代码领先,通用知识和极长上下文检索落后。知识密度的差距反映的是数据质量和训练数据规模的差异,而 MRCR 1M 的落后则是压缩注意力不可避免的精度代价——把 KV 压缩到 10%,检索精度必然会有损失。
DeepSeek 自己的定位也很诚实:落后绝对前沿约 3-6 个月。但考虑到这是开源模型,这个差距已经是历史最小。
十、三种推理模式:成本-质量的显式旋钮
V4 提供三种推理模式,让用户根据任务难度显式控制成本-质量平衡:
| 模式 | 适用场景 | 机制 |
|---|---|---|
| Non-Think | 日常问答、常规编辑 | 无推理链,直觉式直出 |
| Think High | 代码审查、多步分析 | 生成 <think> 推理链后给出答案 |
| Think Max | 竞赛级推理、极限求解 | 注入"absolute maximum"系统提示,扩大 token 预算,要求穷举分解与对抗性压测 |
Think Max 是产出最强 benchmark 数据的模式。它在系统提示中显式要求模型"禁止任何捷径、分解到根因、对所有边界情况做对抗性压测"——用更多 token 换更高准确率,这个取舍交给用户决定。
结语
V4 技术报告最有价值的信息不是某个 benchmark 又刷了几个点,而是一个架构层面的判断:大模型的下一个竞争维度不是"谁更聪明",而是"谁更便宜"。当 V4-Pro 用 27% 的 FLOPs 跑出更强的推理能力,当 V4-Flash 用不到 V3.2 一半的参数在大多数基准上反超——效率,而非规模,正在成为新一代模型的主战场。
这对从业者意味着什么?如果你还在用"参数量"作为评估模型的第一指标,该换个思路了。关注激活参数、关注每百万 token 的推理成本、关注 KV cache 的压缩比——这些才是决定一个模型能不能在你的业务里真正跑起来的硬指标。
百万 token 的效率拐点已经到了。你的业务场景里,最先因此变可能的是什么?
参考资料
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. 技术报告, 2026 年 4 月. Hugging Face
- 乔木博客. DeepSeek-V4 论文解析:百万上下文、水平接近闭源模型是如何做到的? 2026 年 4 月. blog.qiaomu.ai
- 智能计算芯世界. DeepSeek-V4 技术报告全面分析. 电子工程专辑, 2026 年 4 月 29 日. eet-china.com
- Amit Shekhar. Decoding DeepSeek-V4. Outcome School, 2026 年 4 月 24 日. outcomeschool.com
- Digital Applied Team. DeepSeek V4 Launches: 1.6T MoE, 1M Context, 10% KV. 2026 年 4 月 24 日. digitalapplied.com
- DeepSeek-V4 Benchmarks 2026. V4-Pro & V4-Flash Results. deepseekai.guide