Agentic Design Patterns 实战速查:21 个模式与最小可读实现
实战速查 · 智能体工程 × 21 个可复用模式 × Python 最小示例 | 2026 年 5 月 | 约 18 分钟阅读

写在前面
"Agent 设计模式" 这个词最早系统地出现在 Andrew Ng 2024 年的 The Batch 专栏(4 个模式),随后 CSIRO/Data61 的研究者 在 arXiv 上把它扩展到 18 个学术架构模式,再到 2025 年由 Google 工程总监 Antonio Gullí 在 Springer 出版的《Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems》,把工程化经验沉淀为 21 个可复用模式。
这篇文章不讲行业趋势、不堆案例数据,只做一件事:把这 21 个模式按 4 大类逐一过一遍,每个模式配一段简短说明和一段最小可读的 Python 示例。代码示例追求"看得懂、能拷走、能改",所以省略错误处理、日志、配置等次要细节,专注表达模式本身。
按下面 4 部分组织:
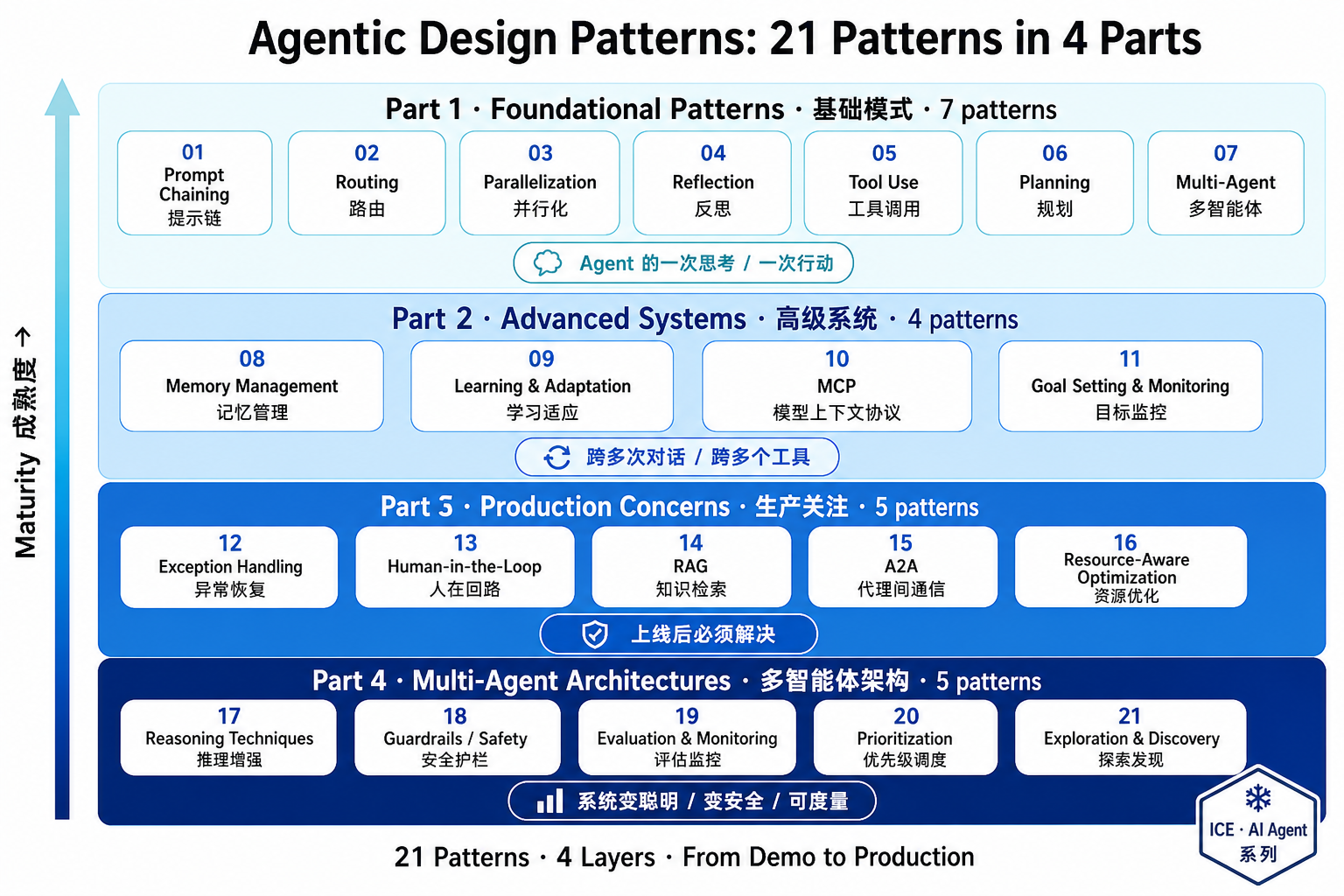
全文示例统一假设你有一个
llm(prompt) -> str的同步 LLM 调用函数,以及chat(messages, tools=None)这种 OpenAI 风格的接口。换成 Claude、Gemini、Qwen 都不影响模式本身。
Part 1 · 基础模式(Foundational Patterns)
7 个模式回答的是 "Agent 的一次思考 / 一次行动" 这个层面的问题。掌握这 7 个就能搭出像样的 demo。
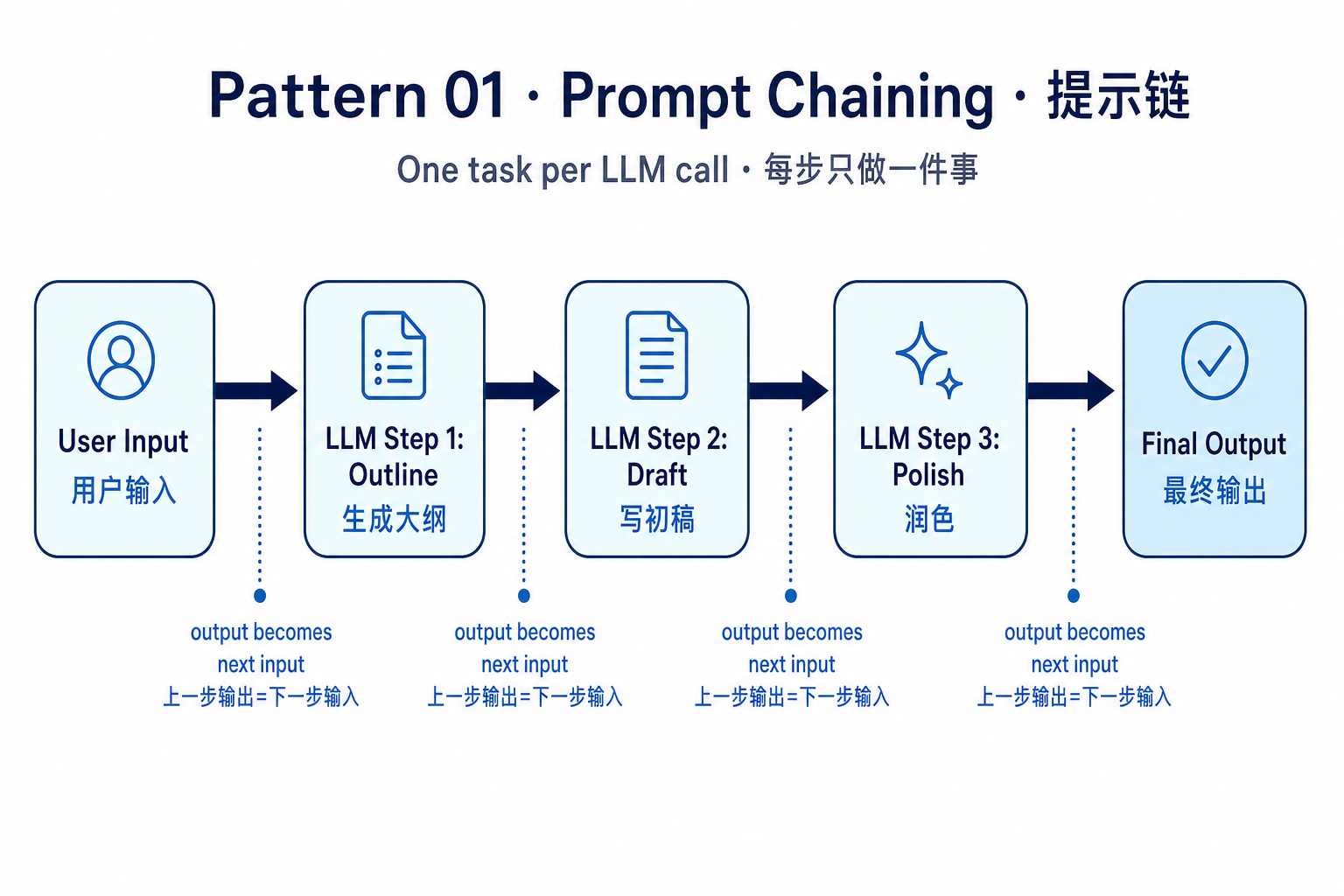
1. Prompt Chaining(提示链)
问题:一次 LLM 调用做不完的复杂任务(写长文、多步推导),硬塞进一个 prompt 会让模型遗漏细节、降低质量。
做法:把任务拆成几个串行的子调用,每一步的输出是下一步的输入。每一步只让 LLM 做一件事,更可控、更可观测。
def write_blog(topic: str) -> str:
# 模式核心:串行多步,上一步输出 = 下一步输入
outline = llm(f"为主题《{topic}》生成 5 节大纲,每节一句标题")
draft = llm(f"基于以下大纲写 1500 字初稿:\n{outline}")
polished = llm(f"以下文章请润色,加强逻辑与示例:\n{draft}")
return polished陷阱:链路越长,错误越累积。超过 4–5 步就该考虑加 Reflection 或换 Planning 模式。
2. Routing(路由)
问题:用户输入差异很大,用同一个 Agent / 同一段 prompt 处理所有请求会"啥都会但啥都不精"。
做法:先用一个轻量分类器(小模型或几行规则)判断意图,再把请求分发给对应的专用 Agent / 工具链。
# 意图标签 → 专用 Agent 实例
ROUTES = {
"refund": refund_agent,
"tech_support": tech_agent,
"sales": sales_agent,
}
def route(query: str):
# 轻量分类:只让模型返回标签,不直接回答问题
intent = llm(
f"将以下问题归类为 {list(ROUTES)} 之一,只返回标签:\n{query}"
).strip().lower()
agent = ROUTES.get(intent, general_agent) # 未知意图走兜底
return agent.run(query)陷阱:分类器本身也会错。准备一个 general_agent 兜底,或对低置信度结果触发 Human-in-the-Loop。
3. Parallelization(并行化)
问题:多个互不依赖的子任务串行执行白白浪费时间,比如同时查新闻、查论文、查社交媒体。
做法:用 asyncio 或线程池并发触发所有独立调用,最后合并结果。
import asyncio
async def research(topic: str) -> str:
# gather:三路检索互不依赖,并发执行以压缩总耗时
news, papers, social = await asyncio.gather(
search_news(topic),
search_arxiv(topic),
search_twitter(topic),
)
# 合并阶段再调一次 LLM,把多源结果压成统一摘要
return llm(
f"综合以下三类信息写一份 300 字摘要:\n"
f"新闻:{news}\n论文:{papers}\n社交:{social}"
)陷阱:识别"真独立"是关键。如果步骤 B 需要步骤 A 的结果,强行并行只会拿到错误答案。
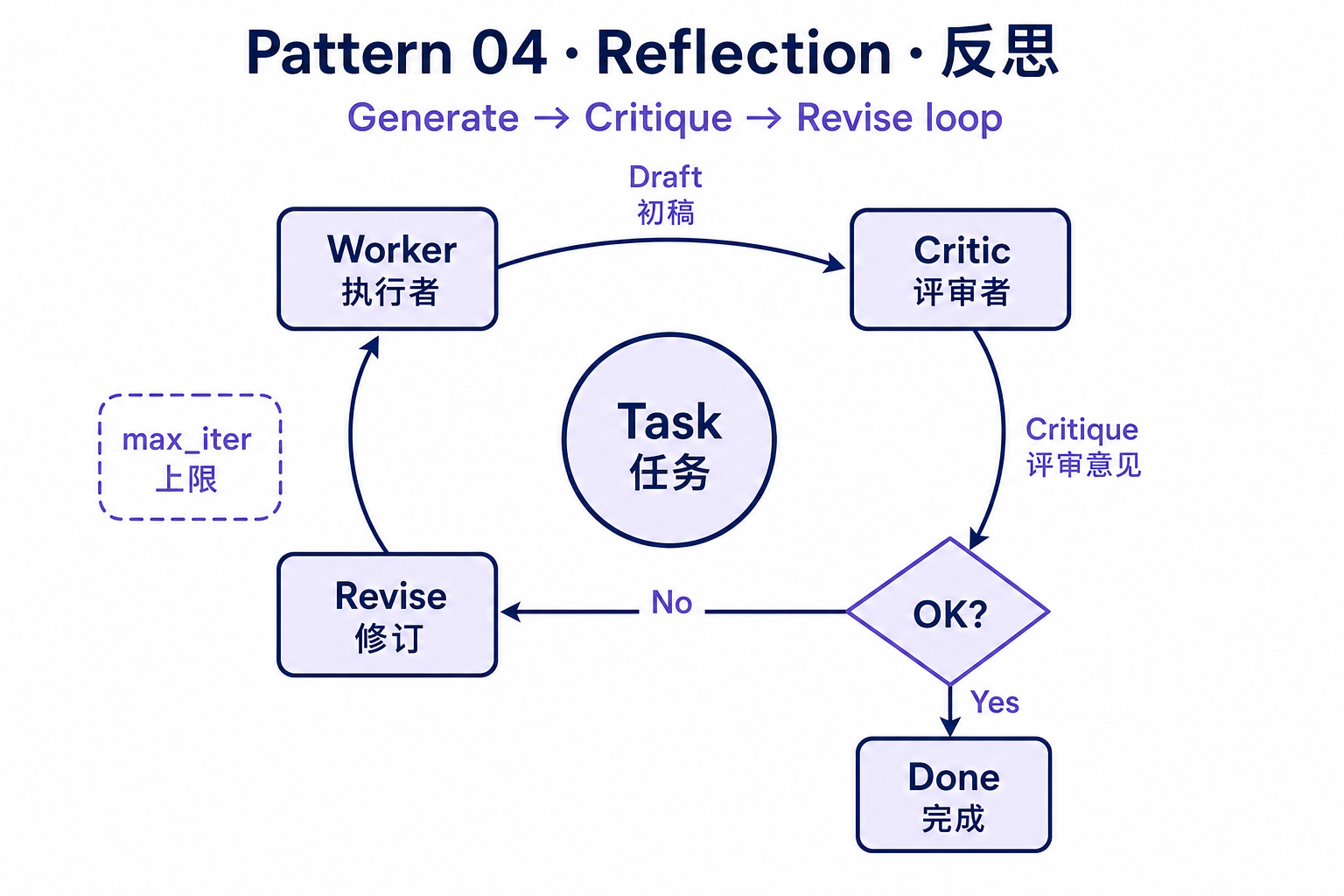
4. Reflection(反思)
问题:LLM 一次性输出往往有逻辑漏洞或事实错误,但它常常能在被指出后自己修正。
做法:让一个 Critic(评审者) Agent 评审 Worker(执行者) Agent 的输出,循环 N 轮直到通过或达到上限。Reflexion 论文用这个方法把 GPT-4 在 HumanEval 上的通过率从 80% 提到 91%。
def reflect_and_revise(task: str, max_iter: int = 3) -> str:
draft = llm(f"完成任务:{task}") # Worker:先出一版
for _ in range(max_iter):
# Critic:评审当前稿;通过则提前退出
critique = llm(
f"请严格评审以下输出,列出问题;若无问题回复 'OK':\n{draft}"
)
if critique.strip().startswith("OK"):
break
# 把评审意见写回上下文,再生成修订版
draft = llm(f"根据以下评审意见修改:\n{critique}\n---原文---\n{draft}")
return draft陷阱:评审超过 5 轮基本无效,且每一轮都是全量成本。务必加 max_iter 硬上限。
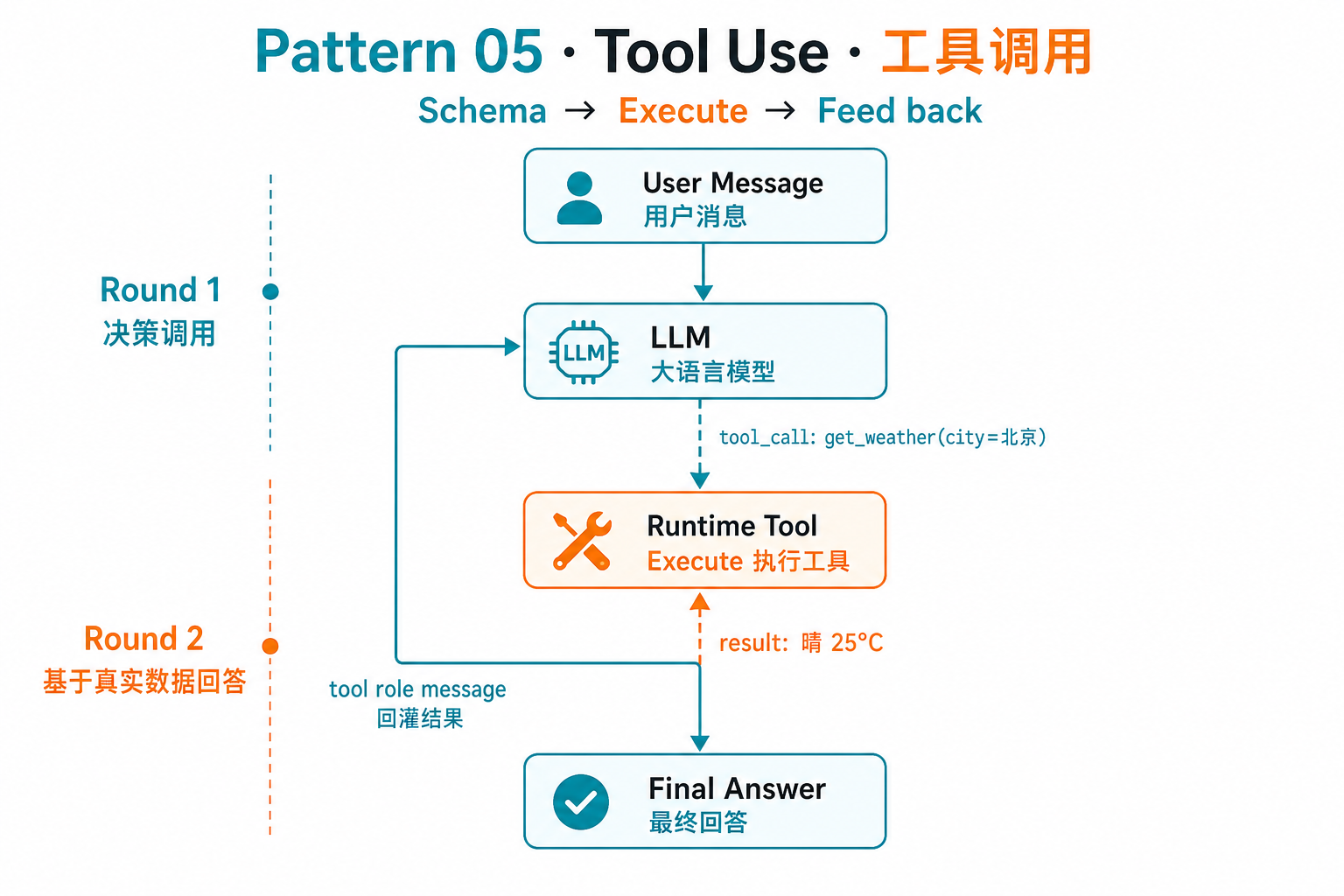
5. Tool Use(工具调用 / Function Calling)
问题:纯文本生成的 LLM 不能查数据库、不能调 API、不能算账。
做法:把外部能力声明成工具 schema 交给模型,模型决定何时调用,运行时执行并把结果回灌给模型。
# 工具 schema:模型靠 description + parameters 决定何时、如何调用
tools = [{
"name": "get_weather",
"description": "查询某城市当前天气",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
}]
resp = chat(
messages=[{"role": "user", "content": "明天去北京要带伞吗?"}],
tools=tools,
)
if resp.tool_call:
result = get_weather(**resp.tool_call.args) # 运行时真正执行工具
# 把工具结果以 tool 角色回灌,模型才能基于真实数据作答
final = chat(messages=[
*resp.messages,
{"role": "tool", "name": "get_weather", "content": str(result)},
])
print(final.content)陷阱:工具描述写不清楚比没工具更糟——模型会乱调。每个工具都该有 1–2 个示例参数。
6. Planning(规划)
问题:任务结构固定但步骤多(生成周报、跑 ETL 流水线),用 ReAct 让 Agent 边走边想会浪费 token 还可能迷路。
做法:先生成完整计划再执行。Planner 输出一个结构化的 DAG,Executor 按顺序(或并行)执行每一步,最后 Solver 汇总。
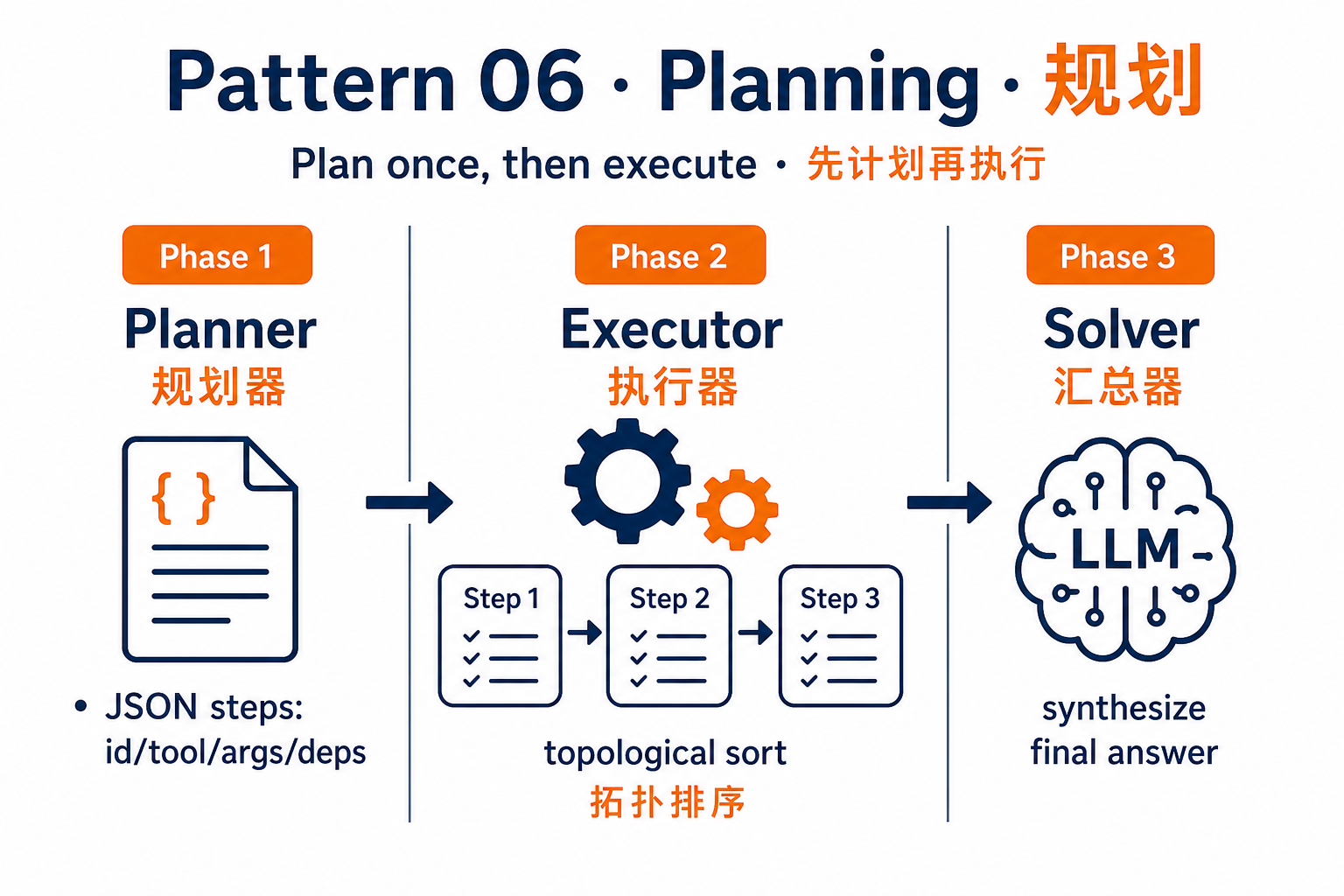
import json
def plan_and_execute(goal: str):
# Planner:一次性产出结构化计划(非边走边想)
plan_json = llm(
f"把目标拆成 JSON 步骤数组,每步包含 id/tool/args/deps:\n{goal}"
)
steps = json.loads(plan_json)
results = {}
for step in steps: # Executor:按步执行;生产环境应对 deps 做拓扑排序
args = resolve_deps(step["args"], step["deps"], results)
results[step["id"]] = TOOLS[step["tool"]](**args)
# Solver:把各步中间结果汇总成用户可读答案
return llm(f"基于以下结果合成最终回答:\n{results}")陷阱:计划错了,执行越快错得越彻底。生产代码要在 Plan 之后插一道 LLM 自检或人审。
7. Multi-Agent Collaboration(多智能体协作)
问题:一个 prompt 让一个模型同时扮演研究员 / 作家 / 编辑 → 角色会"漏戏",输出风格混乱。
做法:每个角色一个独立 Agent,用各自的系统提示词和工具集,按流水线或讨论形式协作。
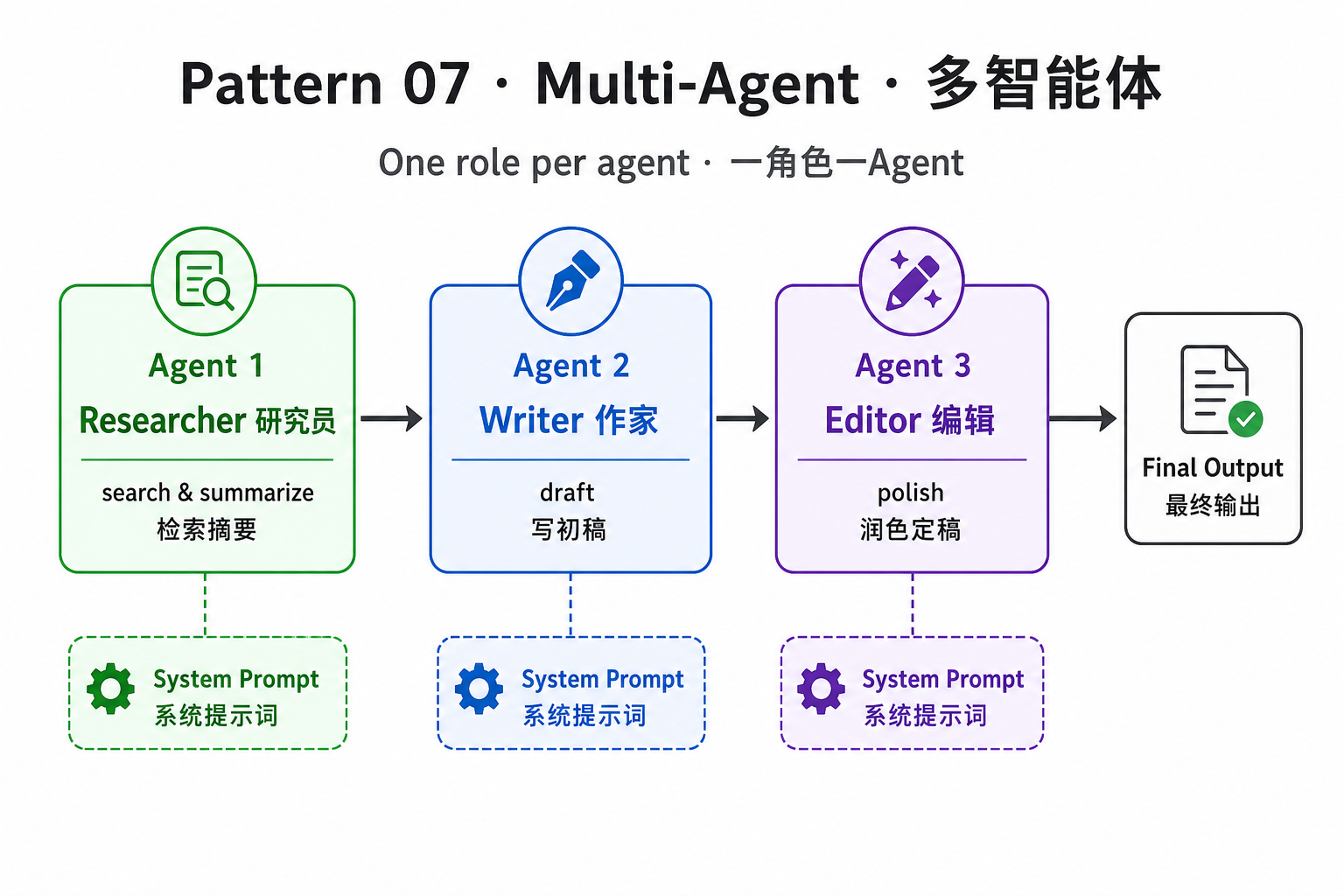
# 每个 Agent 独立 system prompt + 工具集,避免单 prompt 多角色串戏
researcher = Agent("研究员",
system="只做事实检索与摘要,不要润色。",
tools=[search_web, browse_url])
writer = Agent("作家",
system="基于研究员的资料写引人入胜的初稿。")
editor = Agent("编辑",
system="检查事实、压缩冗余、统一风格。")
def write_with_team(topic: str) -> str:
# 流水线协作:上游输出作为下游输入
facts = researcher.run(topic)
draft = writer.run(f"基于以下资料写文章:\n{facts}")
final = editor.run(f"以下文章请编辑:\n{draft}")
return final陷阱:角色越多越难调。先用 2 个 Agent 跑通再加第 3 个,避免"会议爆炸"。
Part 2 · 高级系统(Advanced Systems)
4 个模式回答的是 "Agent 跨多次对话、跨多个工具时" 需要的能力——开始有了"系统感"。
8. Memory Management(记忆管理)
问题:把整段对话塞进上下文,几十轮以后既贵又慢,模型还会"遗忘中间"。
做法:分层记忆——短期对话 buffer(最近 N 轮原文)+ 长期向量记忆(按需检索)+ 用户画像(结构化字段)。三者用不同策略写入与读取。
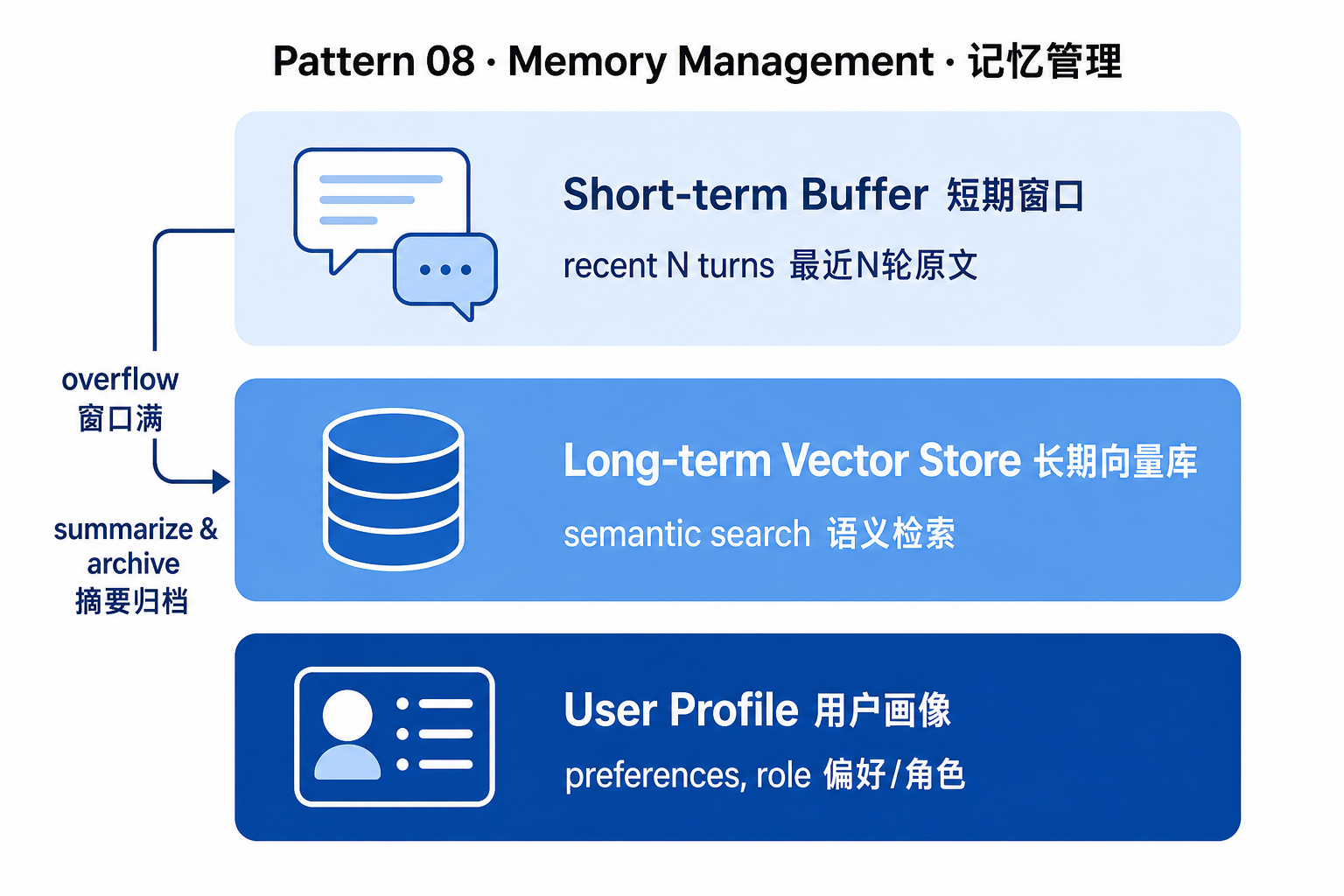
class TieredMemory:
def __init__(self, vector_store, short_window: int = 10):
self.short = [] # 短期:最近 N 轮原文,保细节
self.long = vector_store # 长期:向量库,按语义检索历史
self.profile = {} # 画像:结构化字段(偏好、角色等)
def remember(self, msg: dict):
self.short.append(msg)
if len(self.short) > 20:
# 窗口满则压缩旧对话为摘要,写入长期记忆以省 token
old = self.short[:10]
summary = llm(f"用 1 句话摘要:{old}")
self.long.add(summary)
self.short = self.short[10:]
def recall(self, query: str) -> str:
relevant = self.long.search(query, k=3)
# 拼装三层上下文:画像 + 检索到的历史 + 最近对话
return f"画像:{self.profile}\n历史摘要:{relevant}\n最近:{self.short}"陷阱:摘要也会丢信息。重要决策、用户偏好等强信号建议直接进 profile 结构化存储,不要只依赖向量检索。
9. Learning and Adaptation(学习与适应)
问题:Agent 每次会话都从零开始,犯过的错下次还会犯。
做法:维护一个"经验库",每次任务结束把"任务-策略-结果-评分"写回去;新任务先检索相似经验作为额外上下文。本质是在外部存储上做 in-context learning,不动模型权重。
class AdaptiveAgent:
def __init__(self, experience_store):
self.exp = experience_store # 外部经验库,不改模型权重
def run(self, task: str) -> str:
similar = self.exp.search(task, k=3) # 检索相似历史任务
lessons = llm(f"从以下相似任务提炼教训:\n{similar}")
result = llm(f"任务:{task}\n注意以下教训:\n{lessons}")
score = self_evaluate(task, result) # 自评后写回,供下次检索
self.exp.add({"task": task, "result": result, "score": score})
return result陷阱:经验库要去重、淘汰低分案例,否则坏经验会污染未来回答。
10. Model Context Protocol(MCP,模型上下文协议)
问题:每个 Agent 框架都自己造工具接口(LangChain Tool、OpenAI Function、Claude Tool…),同一个内部 API 要写 N 套适配。
做法:用 MCP 协议统一描述工具/数据源。把内部 API 包装成一个 MCP Server,所有兼容 MCP 的 Agent(Claude Desktop、Cursor、Cline、ADK Agent…)都能直接接上。
from mcp.server import Server
server = Server("crm-tools") # 对外暴露统一 MCP 服务名
@server.tool() # 装饰器自动生成工具 schema,供任意 MCP 客户端发现
def get_customer(customer_id: str) -> dict:
"""根据 ID 查询客户档案"""
return db.query("SELECT * FROM customers WHERE id=?", customer_id)
@server.tool()
def add_note(customer_id: str, note: str) -> bool:
"""给客户档案追加备注"""
db.exec("INSERT INTO notes VALUES (?, ?)", customer_id, note)
return True
# streamable-http:单端点同时支持同步响应与 SSE 流
server.run(transport="streamable-http", port=3000)陷阱:MCP Server 有状态(session、sse 流),别按无状态 REST 思路部署。需要会话粘性或外部 session store。
11. Goal Setting and Monitoring(目标设定与监控)
问题:Agent "走着走着忘了为啥出门"——开始查文档,最后陷在某个工具调用循环里。
做法:把目标显式化为一组可验证的子条件,每步执行后由一个 Monitor Agent 检查"是否离目标更近",未达成则继续 / 调整 / 终止。
class GoalTracker:
def __init__(self, goal: str, criteria: list[str]):
self.goal = goal
self.criteria = criteria # 子目标宜写成可 yes/no 判定的断言
self.done = set()
def step(self, observation: str) -> str:
# 每步根据最新观察,检查还有哪些子目标未达成
for c in self.criteria:
if c in self.done:
continue
verdict = llm(f"子目标 '{c}' 是否已完成?只答 yes/no\n观察:{observation}")
if verdict.strip().lower().startswith("yes"):
self.done.add(c)
if len(self.done) == len(self.criteria):
return "GOAL_REACHED"
return f"CONTINUE,剩余 {len(self.criteria) - len(self.done)} 项"陷阱:criteria 设计得太模糊("用户满意")就退化成"另一种 prompt"。写得越像单元测试断言越好。
Part 3 · 生产关注(Production Concerns)
5 个模式回答的是 "Agent 上线后" 必须解决的问题:稳定、安全、可控、可扩展。
12. Exception Handling and Recovery(异常处理与恢复)
问题:工具调用会失败、超时、返回奇怪结构,幻觉的参数会让 API 直接 4xx。
做法:分层防御——重试 + 参数修复 + 降级回答。把每种异常映射到不同恢复策略。
import time, json
def robust_call(tool, args: dict, max_retry: int = 3):
for attempt in range(max_retry):
try:
return tool(**args)
except RateLimitError:
time.sleep(2 ** attempt) # 限流:指数退避再重试
except ValidationError as e:
# 参数幻觉:让 LLM 根据错误信息修正 args 后重试
args = json.loads(llm(
f"参数校验失败: {e}\n请修正后返回 JSON:\n{args}"))
except ToolUnavailable:
# 降级:工具挂了仍给用户一个基于模型的兜底回答
return llm(f"工具不可用,用你的知识给出参考答案:{args}")
except Exception:
if attempt == max_retry - 1:
return llm(f"工具反复失败,请告知用户并给出替代方案。")陷阱:自动重试别裸跑——总要有总预算上限,否则一次失败可能炸出几百次 LLM 调用账单。
13. Human-in-the-Loop(人在回路)
问题:高风险操作(删数据、发邮件、提交代码)让 Agent 自动做,错一次代价太大。
做法:在关键决策点暂停 Agent,把方案交给人审批,根据回执决定继续 / 修改 / 取消。
async def hitl_execute(plan):
if plan.risk_score < 0.3: # 阈值以下自动放行,避免事事打扰人
return execute(plan)
# 高风险:暂停 Agent,等人审批(approve / modify / reject)
approval = await ask_human({
"summary": plan.summary,
"actions": plan.actions,
"risk": plan.risk_score,
"options": ["approve", "modify", "reject"],
})
if approval.choice == "reject":
return "用户拒绝执行"
if approval.choice == "modify":
return execute(plan.merge(approval.changes)) # 按人改过的方案执行
return execute(plan)陷阱:审批节点太多 → Agent 退化成表单。打分 + 阈值机制让"只有需要人审的才弹给人"。
14. Knowledge Retrieval(RAG,知识检索增强)
问题:模型的训练数据有截止日期、不包含你的私有知识,直接回答会编。
做法:把私有知识切块 + 向量化 + 索引;提问时先检索 top-k 段落作为上下文,模型答题时强制引用来源。
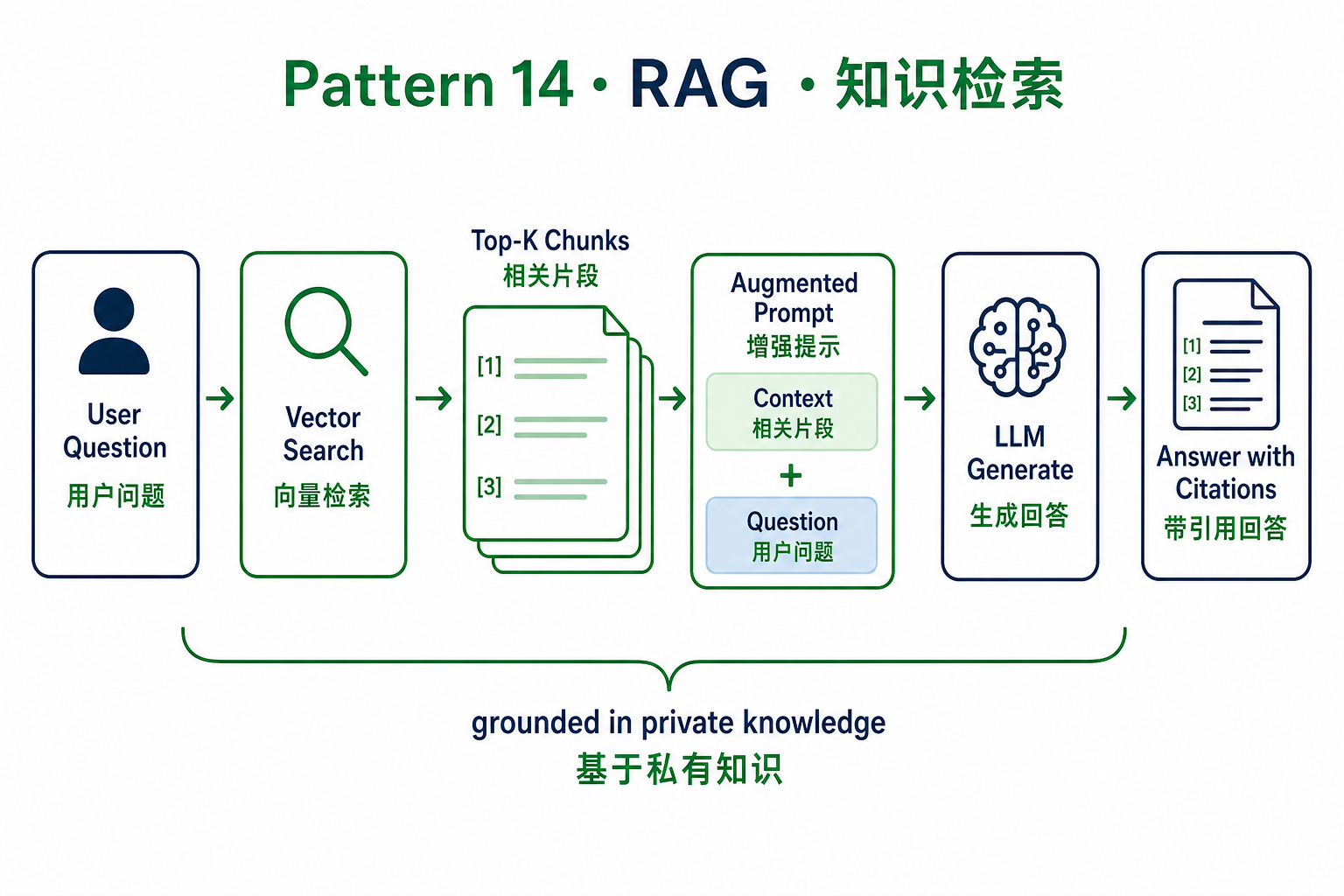
def rag_answer(question: str, k: int = 5) -> str:
chunks = vector_store.search(question, k=k) # 检索 top-k 相关片段
# 带来源编号,便于模型引用、也便于人核对
context = "\n\n".join(
f"[{i+1}] {c.source}\n{c.text}" for i, c in enumerate(chunks))
return llm(
f"仅基于以下资料回答;每个论点末尾用 [编号] 标注来源。\n\n"
f"--- 资料 ---\n{context}\n\n问题:{question}"
)陷阱:检索质量决定回答质量。先优化 chunk 切分、embedding 模型、rerank,再去调 prompt。
15. Inter-Agent Communication(A2A,代理间通信)
问题:你家的 Agent 想调对方公司的 Agent,没有统一的网络协议就得每家定制集成。
做法:用 Google 的 A2A 协议——每个 Agent 暴露一个 Agent Card(描述自己能做什么)和一组 Task 端点,调用方按统一接口创建任务、轮询/订阅结果。
import time
import httpx
class A2AClient:
def call(self, agent_url: str, task: dict) -> dict:
# 1. 发现:读 Agent Card,确认对方是否支持本任务
card = httpx.get(f"{agent_url}/.well-known/agent.json").json()
if not capable(card, task):
raise ValueError("对方不支持该任务类型")
# 2. 委派:创建远程任务
resp = httpx.post(f"{agent_url}/tasks", json=task).json()
task_id = resp["id"]
# 3. 轮询任务状态(生产环境可改用 SSE 推送)
while True:
status = httpx.get(f"{agent_url}/tasks/{task_id}").json()
if status["state"] in ("completed", "failed"):
return status["result"]
time.sleep(1)陷阱:跨信任域调用必须配 OAuth/mTLS 鉴权;调用对方 Agent ≠ 信任对方 Agent,输出仍要走自己的 Guardrails。
16. Resource-Aware Optimization(资源感知优化)
问题:每个请求都用最贵的大模型 → 月底账单爆表;每个请求都塞满上下文 → 延迟无法接受。
做法:分级路由 + 预算控制。先用便宜小模型试一次,置信度不够再升级;上下文做相关性截断而不是塞满。
def cost_aware_answer(query: str, budget_tokens: int = 2000) -> str:
cheap = small_llm(query)
if confidence(cheap) > 0.8:
return cheap # 高置信:小模型够用,省 token 与延迟
# 低置信:截断上下文后升级到大模型
context = truncate_by_relevance(query, max_tokens=budget_tokens)
return big_llm(f"{context}\n\n{query}")陷阱:confidence 不能用模型自己说"我有 0.9 把握"——它会乱说。用 logprob、self-consistency 投票方差等外部信号估算置信度。
Part 4 · 多智能体架构(Multi-Agent Architectures)
5 个模式回答的是 "Agent 系统怎么变聪明、变安全、可被度量" 这种更高阶问题。
17. Reasoning Techniques(推理增强)
问题:复杂数学/逻辑题,直接问 → 模型一拍脑袋错了。
做法:常用三种增强——Chain-of-Thought(让它写步骤)、Self-Consistency(多次采样取多数)、Tree-of-Thoughts(分支搜索后剪枝)。下面是最简单的 Self-Consistency:
from collections import Counter
def self_consistent(question: str, n: int = 5) -> str:
# 同一问题采样 n 次(temperature>0 引入随机性)
samples = [
llm(f"请逐步推理后给出最终答案,格式:'答案: X'\n{question}",
temperature=0.7)
for _ in range(n)
]
answers = [s.rsplit("答案:", 1)[-1].strip() for s in samples]
# 多数投票:取出现次数最多的最终答案
return Counter(answers).most_common(1)[0][0]陷阱:n 越大越准但越贵。简单问题别上 Self-Consistency,浪费钱;难题再考虑 n=5–10。
18. Guardrails / Safety Patterns(安全护栏)
问题:用户可能 prompt injection、可能输入 PII、模型可能输出违禁内容、可能调危险工具。
做法:在输入 / 输出 / 工具调用三个位置各设一道护栏,分别处理。可以用规则、正则、专门的小模型或服务(Llama Guard、Azure Content Safety 等)。
def safe_pipeline(user_input: str) -> str:
# 护栏 1:入站——PII、越狱注入等
if detect_pii(user_input) or detect_jailbreak(user_input):
return "请求被拒绝:含敏感内容或可疑指令"
plan = agent.plan(user_input)
# 护栏 2:工具调用前——危险操作需权限
for tool_call in plan.tool_calls:
if tool_call.name in DANGEROUS_TOOLS and not has_permission(tool_call):
return f"工具 {tool_call.name} 需要更高权限,已拦截"
response = agent.execute(plan)
# 护栏 3:出站——违禁内容过滤
if contains_prohibited(response):
return "回答被过滤"
return response陷阱:护栏会带来 false positive,把合法请求误杀。要有 bypass 通道(人审申诉)和 metric 监控误杀率。
19. Evaluation and Monitoring(评估与监控)
问题:改了 prompt 不知道有没有变好、上线后不知道哪类请求在退化。
做法:维护金标评估集(50–500 例),每次改动跑一遍打分;线上同时记录请求/响应/工具调用/延迟/成本到追踪系统,用 LLM-as-a-Judge 抽样打分。
class AgentEval:
def __init__(self, golden_set: list[tuple[str, str]]):
self.golden = golden_set # (问题, 期望答案或评分 rubric)
def run(self, agent) -> dict:
scores = []
for query, expected in self.golden:
actual = agent.run(query)
score = llm_judge(query, actual, expected) # 0~1,可用 rubric 细化
scores.append({"q": query, "score": score})
return {
"avg": sum(s["score"] for s in scores) / len(scores),
"fail": [s for s in scores if s["score"] < 0.6], # 便于回归排查
}陷阱:没有 golden set 之前别动 prompt——你只是在"听感觉"。先花一天建 50 例,长期 ROI 远超之后任何调优。
20. Prioritization(优先级调度)
问题:多任务/多请求同时进来,FIFO 会让紧急请求等死。
做法:把任务放进优先级队列,按 priority = f(deadline, value, cost) 排序;高优先级抢占 LLM 调用配额。
import heapq, itertools, time
class TaskQueue:
def __init__(self):
self.q = []
# 同 priority 时按插入顺序 FIFO,避免 heap 比较 task 对象
self.counter = itertools.count()
def push(self, task, *, deadline: float, value: float):
urgency = 1 / max(deadline - time.time(), 1) # 越临近 deadline 越大
priority = -(value * urgency) # 负号:heapq 默认最小堆,取负实现最大优先
heapq.heappush(self.q, (priority, next(self.counter), task))
def pop(self):
return heapq.heappop(self.q)[-1] if self.q else None陷阱:低优先级任务可能"饥饿"。加入老化机制——等得越久优先级线性上升。
21. Exploration and Discovery(探索与发现)
问题:Agent 只会用见过的工具 / 走过的路径,遇到新环境就抓瞎。
做法:在主任务流之外,让 Agent 周期性地主动尝试新工具组合 / 新查询方式,把成功经验回写到记忆里——本质是把强化学习里 explore-exploit 平衡迁移到 LLM Agent。
def explore_environment(env, steps: int = 20):
tried = set()
discoveries = []
for _ in range(steps):
# 让模型在已知动作之外提议新探索
action = llm(
f"环境描述:{env.describe()}\n"
f"已尝试动作:{sorted(tried)}\n"
f"请提出一个尚未尝试且可能有价值的动作(一行):"
).strip()
if action in tried:
continue
tried.add(action)
outcome = env.try_action(action)
if outcome.is_useful(): # 只保留有价值的发现,写回记忆/工具库
discoveries.append((action, outcome))
return discoveries陷阱:探索 = 烧钱。务必加 budget 和 step cap,并把探索单独跑在低优先级队列。
后记:21 个模式怎么组合?
现实中没有人只用一个模式。一个像样的"现代编程 Agent"通常是这样的配方:
用户请求
└─ Routing ── 判定是问答 / 修 bug / 写新功能
└─ Planning ── 拆成 5–8 步
├─ Tool Use ── 调编辑器、文件系统、终端、git
├─ RAG ── 检索仓库历史 / 文档
├─ Reflection ── 跑测试,失败就让自己评审并修改
└─ Memory ── 记下用户偏好与项目惯例
└─ Guardrails ── 写文件、跑 shell、推 git 前过滤危险操作
└─ Human-in-the-Loop ── 高风险动作弹审批
└─ Evaluation ── 离线金标 + 在线采样打分类似地:
- 生产级 RAG = Hybrid Search + RAG + Reflection + Guardrails + Evaluation
- 客服系统 = Routing + RAG + Memory + Multi-Agent + Human-in-the-Loop
- 数据流水线 Agent = Planning + Tool Use + Exception Handling + Prioritization + Monitoring
把这些模式当成乐高积木:先确认任务需要哪几块,再选框架把它们拼起来——而不是反过来"我有 LangGraph 我能干嘛"。
最后一句:模式是给团队的共同词汇。今天就挑你最熟的 Agent 项目,试着用上面 21 个名字里的几个去描述它——能说清楚的就是你已经在用的,说不清楚的就是接下来该补的功课。
参考资料
- Antonio Gullí. Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems. Springer Nature, 2025. ISBN 978-3-032-01402-3. https://link.springer.com/book/10.1007/978-3-032-01402-3
- Andrew Ng. Agentic Design Patterns (Series). The Batch / DeepLearning.AI, 2024-03. https://www.deeplearning.ai/the-batch/agentic-design-patterns/
- Yue Liu et al. Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents. Journal of Systems and Software, Vol. 220, Feb 2025. arXiv:2405.10467.
- Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1994.
- Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS 2023.
- Binfeng Xu et al. ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models. arXiv:2305.18323, 2023.
- Anthropic. Model Context Protocol Specification. https://modelcontextprotocol.io/
- Google. Agent-to-Agent (A2A) Protocol. https://a2aprotocol.org/
- Mathews Tom (compiler). Agentic Design Patterns – Community Compiled Edition. https://github.com/Mathews-Tom/Agentic-Design-Patterns