论文解读|SOAR:当模型学会自己教自己

论文信息
- 标题:Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
- 作者:Shobhita Sundaram (MIT), John Quan, Ariel Kwiatkowski, Kartik Ahuja, Yann Ollivier (Meta FAIR), Julia Kempe (NYU)
- 发表时间:2026 年 1 月 | arXiv: 2601.18778
- 项目主页:https://ssundaram21.github.io/soar/
TL;DR
现在训练 AI 做推理题的思路是"做对了就奖励"。但如果一道题太难,模型连蒙 128 次都蒙不对,那它永远拿不到奖励,也就永远学不会——就像一个没学过微积分的学生被直接扔进竞赛考场,连题意都看不懂,靠考试本身是不可能进步的。
这篇论文的做法是:把同一个模型复制两份,一份当"老师"、一份当"学生"。老师的任务是出题,但它的考核标准不是"出的题答案对不对",而是"学生做完这些题之后,在真正的难题上有没有进步"。进步了,老师就得到奖励;没进步,老师就得换出题策略。这样老师慢慢学会了出那种"刚好能帮学生往前走一步"的题——类似一个好的辅导老师,知道该从哪些基础练习讲起。
结果是:论文从数学竞赛题库中筛出了最难的一批题——模型连续采样 128 次全部失败(fail@128)。在这批题上直接做 RL 训练(Hard-Only),pass@32(对同一道题采样 32 次,至少答对 1 次即算通过)只能达到 9.6%;而用 SOAR 生成的题目辅助训练后,pass@32 提升到 18.9%(+9.3%,约 2 倍)。哪怕给 Hard-Only 堆 4 倍算力,也只多涨了 2.8%,远不如 SOAR。
一个反直觉的细节:老师出的题有约 2/3 的答案是错的,但学生依然在进步。不过这不是"错误让模型变强"——真正起作用的是题目本身的结构和概念多样性。论文中另一种答案正确率更高(55%)的方法反而效果更差,因为它生成的题目千篇一律,丧失了约 70% 的多样性。比起"答案对不对","题目出得好不好、够不够多样"才是关键。
一、问题背景
当前,基于可验证奖励的强化学习(RLVR)已成为提升大语言模型(LLM)推理能力的主流方法,DeepSeek-R1、Kimi 等模型均受益于此。但 RLVR 有一个根本性缺陷:模型无法从它完全做不出的题目中学习。
原因很直接——RLVR 依赖"正确输出"来强化有用的推理轨迹。如果模型对某类问题的初始成功率接近于零,那么它几乎得不到任何正向奖励信号,梯度稀疏到无法驱动有意义的参数更新,学习曲线就此停滞。论文将这种现象称为 稀疏奖励高原(Sparse Reward Plateau)。
传统的解决方案是课程学习(Curriculum Learning)——先让模型在简单题上训练,再逐步过渡到难题。但这需要人类事先准备好一套难度分层的标注数据集,成本高昂且不总是可行。
论文提出的核心问题是:模型能否自己生成一套"垫脚石"课程,打破自身的推理瓶颈?
二、核心假说:潜在的「教学能力」
论文提出了一个关键假说:即使一个模型做不出某道难题,它也可能拥有生成与该难题相关的中等难度题目的能力。
打个比方:一个模型可能做不出一道复杂的微积分证明题,但它在预训练阶段已经见过大量基础的链式法则练习题,因此有能力生成类似的简单练习。这些简单练习可以从两个维度帮助模型:
- 提供梯度信号:在简单题上获得非零奖励,强化相关的推理轨迹
- 推动可学习前沿:解决子任务使模型的策略进入一个新的区域,在该区域中原本不可解的难题变得"可学习"
由此引出两个关键疑问:
- 这种潜在知识是否真的存在?
- 能否在不依赖人工干预的情况下提取出来?
三、方法:SOAR 框架设计
为了验证上述假说,论文提出了 SOAR(Self-Optimization with Asymmetric RL) 框架。其核心是一个非对称的 教师-学生双层元强化学习(Bilevel Meta-RL) 结构。
整体架构
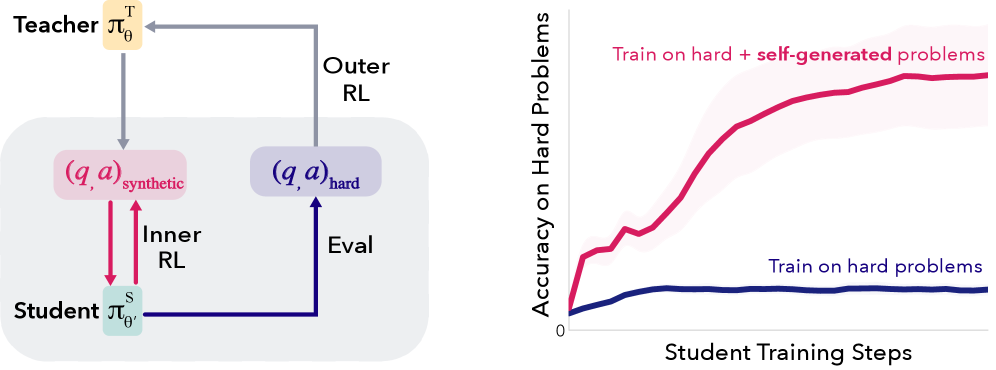 图 1(论文 Figure 1):SOAR 框架概览。左侧:从同一个基础模型初始化教师和学生两个副本。教师生成合成问题供学生训练,并以学生在真实难题上的进步作为奖励。右侧:使用 SOAR 生成的问题进行 RL 训练,显著优于仅在难题上直接训练,使学生成功突破性能瓶颈。
图 1(论文 Figure 1):SOAR 框架概览。左侧:从同一个基础模型初始化教师和学生两个副本。教师生成合成问题供学生训练,并以学生在真实难题上的进步作为奖励。右侧:使用 SOAR 生成的问题进行 RL 训练,显著优于仅在难题上直接训练,使学生成功突破性能瓶颈。
框架由同一个基础模型(Llama-3.2-3B-Instruct)的两个副本组成:
- 教师模型
:负责生成合成的(问题, 答案)对 - 学生模型
:在教师生成的合成数据上进行 RL 训练
初始时两者参数完全相同:
双层优化目标
论文将问题形式化为一个双层优化(Bilevel Optimization):
其中
目标是:找到一组教师生成的合成题目,使得学生在这些题目上训练后,能在原本做不出的难题上取得可测量的进步。
元 RL 循环
传统的双层优化需要对内层循环做反向传播,计算代价极高。论文的巧妙之处在于:用 RL(RLOO 算法)替代梯度穿透,将整个系统实例化为嵌套的元 RL 循环。
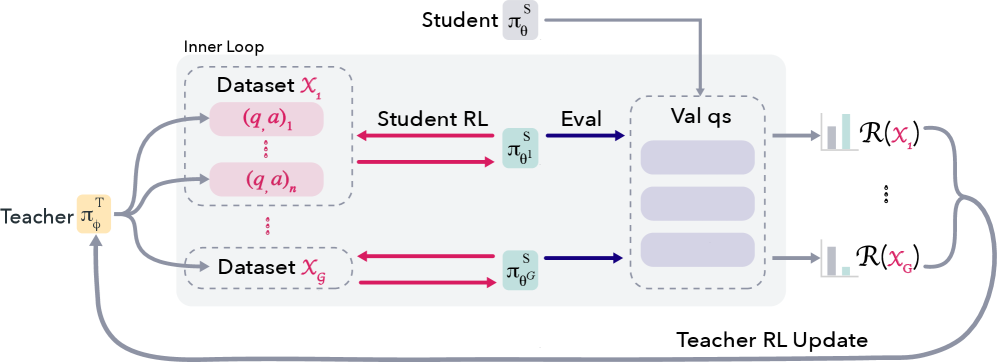 图 2(论文 Figure 2):SOAR 的元 RL 循环。在外层循环中,教师生成候选问答对并分组为数据集。在内层循环中,学生在候选问题上训练 10 步,然后在采样的难题上评估。教师根据学生相对于基线的进步获得奖励,将合成课程锚定在真实学习进度上。
图 2(论文 Figure 2):SOAR 的元 RL 循环。在外层循环中,教师生成候选问答对并分组为数据集。在内层循环中,学生在候选问题上训练 10 步,然后在采样的难题上评估。教师根据学生相对于基线的进步获得奖励,将合成课程锚定在真实学习进度上。
具体流程:
- 外层循环(教师训练):教师使用 RLOO 算法生成候选问答对,每次采样 64 个问题,分为多组数据集
- 内层循环(学生训练):对每组数据集,学生进行 10 步 RL 训练(RLOO,batch size=8),然后在从
中采样的 64 个真实难题上评估 - 奖励计算:教师的奖励 = 训练后学生的准确率 - 训练前学生的准确率
- 教师更新:使用该奖励对教师进行 RLOO 更新
学生晋升机制(Promotion Mechanism)
为了让教师能适应不断进步的学生,论文设计了一个"晋升"机制:
- 跟踪教师奖励的 3 步移动平均值
- 当移动平均值超过阈值
时,将当前最佳训练后的学生设为新的基线 - 导致晋升的那组合成题目被记录为 Promotion Questions (PQ)
这意味着:随着学生逐步进步,教师需要生成越来越难的"垫脚石"题目,形成一个动态演进的课程。
Grounded Reward vs. Intrinsic Reward
论文的一个核心设计决策是使用 Grounded Reward(锚定奖励) 而非 Intrinsic Reward(内在奖励):
| Grounded Reward(本文) | Intrinsic Reward(先前工作) | |
|---|---|---|
| 奖励信号 | 学生在真实难题上的进步 | 学生的通过率 ≈ 50%(可学习性) |
| 锚定方式 | 黑盒方式锚定在实际学习进度上 | 作为实际目标的代理 |
| 风险 | 计算成本较高 | 奖励黑客攻击、多样性坍塌 |
先前的 LLM 自博弈方法(如 Absolute Zero、R-Zero 等)普遍使用内在奖励,即让教师生成学生"刚好能做出一半"的题目。论文指出,这种代理目标容易导致奖励黑客攻击(reward hacking),教师可能学到生成看起来难但实际无用的题目。
四、实验设置
模型与数据集
- 基础模型:Llama-3.2-3B-Instruct
- 数据集:MATH、HARP、OlympiadBench(覆盖 AMC、AIME、USA(J)MO、国际奥赛等竞赛题)
- 难度筛选:对每道题采样 128 次,保留成功率为 0/128 的题目,称为 fail@128 数据集
- 训练集/测试集:50-50 随机划分
SOAR 在 MATH 和 HARP 上训练,OlympiadBench 保留作为分布外(OOD)测试集。
基线方法
| 方法 | 描述 |
|---|---|
| Hard-Only | 直接在 fail@128 训练集上用标准 RLVR 训练(group size=32) |
| Hard-Only (g=128) | 同上,但 group size 增至 128(4× 计算量) |
| Intrinsic-T | 使用内在可学习性奖励训练的教师,采样 128 题训练学生 |
| Upper Bound | 使用完整的 MATH 官方训练集(6750 题)+ fail@128 训练集 |
评估指标
- pass@k 准确率(k ∈ {1, 4, 8, 16, 32}):在 fail@128 测试集上评估
- 每个实验运行 6-12 个种子,报告中位数和标准差
五、核心发现
论文给出了三个核心实验发现。
发现一:Meta-RL 能发现有效的"垫脚石"问题
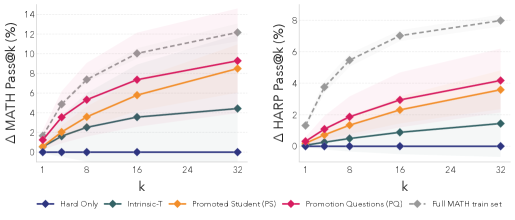 图 3(论文 Figure 3):在 MATH 和 HARP 的 fail@128 子集上的性能表现(相对于 Hard-Only 的提升幅度)。SOAR 生成的 Promotion Questions(PQ)和晋升后的学生(PS)均显著优于直接在 fail@128 上训练(Hard-Only)以及使用内在奖励训练的教师(Intrinsic-T)。阴影区域为 ± 1 标准差。
图 3(论文 Figure 3):在 MATH 和 HARP 的 fail@128 子集上的性能表现(相对于 Hard-Only 的提升幅度)。SOAR 生成的 Promotion Questions(PQ)和晋升后的学生(PS)均显著优于直接在 fail@128 上训练(Hard-Only)以及使用内在奖励训练的教师(Intrinsic-T)。阴影区域为 ± 1 标准差。
关键数据:
- 在 MATH fail@128 上:PQ 实现了 +9.3% pass@32 的提升(从 9.6% 到 18.9%,约 2× 改进);PS 实现了 +8.5% pass@32
- 在 HARP fail@128 上:PQ 实现了 +4.2% pass@32 的提升(约 1.5× 改进);PS 实现了 +3.6% pass@32
- PQ 的表现优于 PS,说明性能增益来自合成题目本身,而非某次特定的训练轨迹
- Intrinsic-T 在所有指标上均低于 PQ 和 PS,验证了 grounded reward 的必要性
- Hard-Only (g=128) 即使使用 4× 计算量,也仅实现了 +2.8% pass@32,远低于 SOAR 的 +9.3%
论文还发现一个有趣的现象:用训练好的教师模型直接做 fail@128 测试题,表现并没有优于基础模型。 这表明"生成垫脚石题目"和"解决难题"是两种不同的能力——教师学到的是如何出好题,而不是如何解题。
发现一(续):跨数据集迁移能力
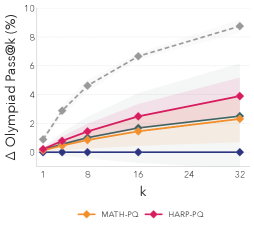 图 4(论文 Figure 4):在 OlympiadBench fail@128 子集上的迁移性能(相对于 Hard-Only 的提升)。在 MATH 和 HARP 上优化的合成问题能迁移到一个从未优化过的 OOD 数据集。
图 4(论文 Figure 4):在 OlympiadBench fail@128 子集上的迁移性能(相对于 Hard-Only 的提升)。在 MATH 和 HARP 上优化的合成问题能迁移到一个从未优化过的 OOD 数据集。
PQ-MATH 和 PQ-HARP 在 OlympiadBench(一个完全未参与优化的 OOD 数据集)上分别实现了约 +6% 和 +3% 的 pass@32 提升。这表明合成课程捕获了可泛化的推理路径,而非仅仅过拟合到训练分布。
与人工标注数据的对比:
- PQ-MATH 恢复了完整 MATH 训练集(6750 题)带来性能增益的 75%
- PQ-HARP 恢复了 50%
- HARP-PQ(仅 128/192 道合成题)甚至优于 128 道真实的 HARP 题目
发现二:Grounded Reward 产生更稳定、多样的教师策略
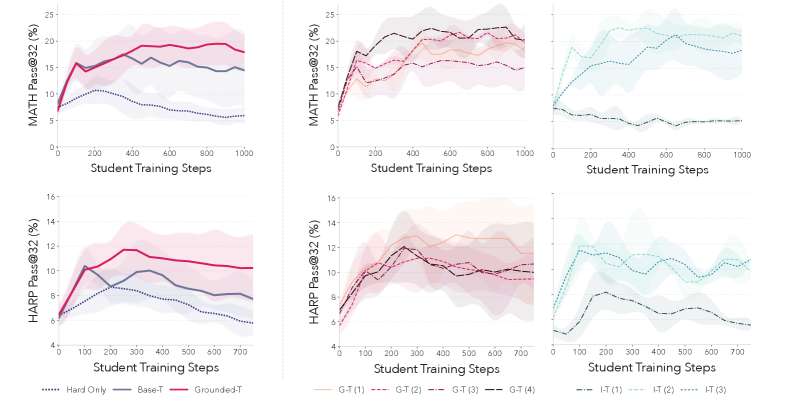 图 5(论文 Figure 5):Grounded Reward 带来更稳定的教师策略。左图:使用 Grounded-T 和 Base-T(基础模型直接生成)的问题训练新学生的 pass@32 对比。Grounded-T 显著优于 Base-T 且轨迹更稳定。右图:不同 Grounded-T(红色)和 Intrinsic-T(绿色)教师种子训练的学生 pass@32 轨迹。Grounded-T 的不同种子表现高度一致,而 Intrinsic-T 各种子间差异极大,其中一个种子甚至导致学生性能坍塌。
图 5(论文 Figure 5):Grounded Reward 带来更稳定的教师策略。左图:使用 Grounded-T 和 Base-T(基础模型直接生成)的问题训练新学生的 pass@32 对比。Grounded-T 显著优于 Base-T 且轨迹更稳定。右图:不同 Grounded-T(红色)和 Intrinsic-T(绿色)教师种子训练的学生 pass@32 轨迹。Grounded-T 的不同种子表现高度一致,而 Intrinsic-T 各种子间差异极大,其中一个种子甚至导致学生性能坍塌。
论文通过对比三类教师(Grounded-T、Intrinsic-T、Base-T)揭示了 grounded reward 的优势:
1. Meta-RL 锐化了题目分布
Base-T(基础模型直接生成题目)的学生训练曲线非常嘈杂,但其中确实存在成功的运行。这证明"有用的垫脚石题目"潜藏在基础模型的分布中。Grounded-T 的作用是锐化这个分布,使教师更可靠地输出提供有用梯度信号的题目。
2. Intrinsic Reward 的脆弱性
不同 Grounded-T 种子训练出的学生表现高度一致(图 5 右图红色曲线)。相比之下,不同 Intrinsic-T 种子的表现差异巨大:一些种子产生优秀的课程,但有 1/3 的种子导致学生性能坍塌(图 5 右图绿色曲线中的 I-T(1))。
3. Grounded Reward 保持了生成多样性
论文使用 Vendi Score(VS)衡量合成数据集的语义多样性:
| 方法 | Vendi Score (VS) | 标准差 |
|---|---|---|
| Base-T(基础模型) | 34.91 | 1.74 |
| Grounded-T (HARP) | 34.66 | 1.74 |
| Grounded-T (MATH) | 31.99 | 1.54 |
| PQ | 28.33 | 1.55 |
| Intrinsic-T | 10.82 | 1.01 |
表 1(论文 Table 1):使用 Vendi Score 衡量的合成数据集语义多样性分析。所有指标通过 bootstrap 子采样标准化为 128 题(k=100 次迭代)。VS 代表有效的独立语义概念数量。
Grounded-T 基本保持了与基础模型相当的多样性(VS ≈ 31-35),而 Intrinsic-T 的多样性坍塌至仅约 10.82——损失了约 70% 的多样性。这为 Intrinsic-T 的不稳定性提供了直接解释。
发现三:题目结构比答案正确性更重要
 图 6(论文 Figure 6):生成题目的定性演化。左图:一次 SOAR 在 HARP 上运行过程中学生基线的性能变化。右图:不同晋升阶段的教师生成题目样例。内容和风格从应用题与基础公式(阶段 1)转向简洁的代数与微积分方程题(阶段 2)。许多有效的"垫脚石"包含错误的解答,表明结构和概念内容提供了足够的学习信号。
图 6(论文 Figure 6):生成题目的定性演化。左图:一次 SOAR 在 HARP 上运行过程中学生基线的性能变化。右图:不同晋升阶段的教师生成题目样例。内容和风格从应用题与基础公式(阶段 1)转向简洁的代数与微积分方程题(阶段 2)。许多有效的"垫脚石"包含错误的解答,表明结构和概念内容提供了足够的学习信号。
论文使用 Claude-4.5-Sonnet 作为评判模型,对合成题目进行了标注分析:
| 指标 | Base-T | Intrinsic-T | Grounded-T | PQ |
|---|---|---|---|---|
| 题目数学上合理且结构良好 | 53.6% | 63.5% | 70.0% | 64.6% |
| 答案完全正确 | 23.2% | 55.5% | 36.5% | 32.8% |
| 错误类型分布 | ||||
| 算术错误 | 23.7% | 5.7% | 29.0% | 25.0% |
| 逻辑错误 | 5.7% | 2.3% | 6.9% | 6.5% |
| 不可能性错误 | 4.7% | 2.9% | 8.2% | 4.7% |
| 歧义性错误 | 42.4% | 33.6% | 21.3% | 31.3% |
表 2(论文 Table 7):合成题目的正确性分析与错误分类(由 Claude-4.5-Sonnet 评估)。
核心发现:
- PQ(Promotion Questions)只有 32.8% 的答案是正确的,但有 64.6% 的题目在数学上是合理且结构良好的
- Intrinsic-T 的答案正确率更高(55.5%),但其学生表现反而更差——可能因为多样性坍塌
- 相比 Base-T,Meta-RL 训练后的 Grounded-T 和 PQ 显著降低了歧义性错误(从 42.4% 降至 21.3%/31.3%),说明 meta-RL 更重视题目的清晰度和连贯性
这意味着:对于处于学习瓶颈的模型而言,题目的概念多样性和结构清晰度,比答案是否正确更加重要。 答案的正确性既非充分条件也非必要条件——Intrinsic-T 的正确率更高但表现更差(因为多样性坍塌),PQ 的正确率较低但表现最好(因为题目结构好且多样)。模型在尝试解答这些结构合理的题目时,构建推理路径的过程本身就提供了有价值的训练信号,与最终答案是否正确无关。
六、教师训练动态
论文附录中展示了 SOAR 训练过程中教师奖励的动态变化。
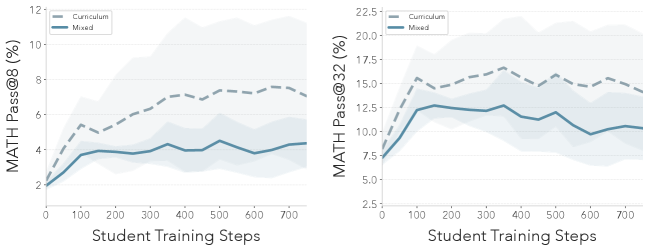 图 7(论文 Figure 16):SOAR 在 HARP 上训练时的教师奖励动态。教师遵循"搜索-利用"的周期性模式。学生晋升(将学生基线更新为训练后的学生)在 3 步移动平均奖励超过 τ=0.01 时触发。每次晋升后,改进后的学生基线使先前的课程变得不够有用,奖励下降,随后教师适应并发现适合改进后学生的新题目,奖励再次回升。
图 7(论文 Figure 16):SOAR 在 HARP 上训练时的教师奖励动态。教师遵循"搜索-利用"的周期性模式。学生晋升(将学生基线更新为训练后的学生)在 3 步移动平均奖励超过 τ=0.01 时触发。每次晋升后,改进后的学生基线使先前的课程变得不够有用,奖励下降,随后教师适应并发现适合改进后学生的新题目,奖励再次回升。
教师的训练呈现明显的**"搜索-利用"周期模式**:
- 搜索阶段:奖励波动,教师探索不同的题目策略
- 利用阶段:奖励稳步上升,教师收敛到有效的题目分布
- 晋升触发:学生基线更新后,奖励下降
- 重新适应:教师探索新的、适合更强学生的题目
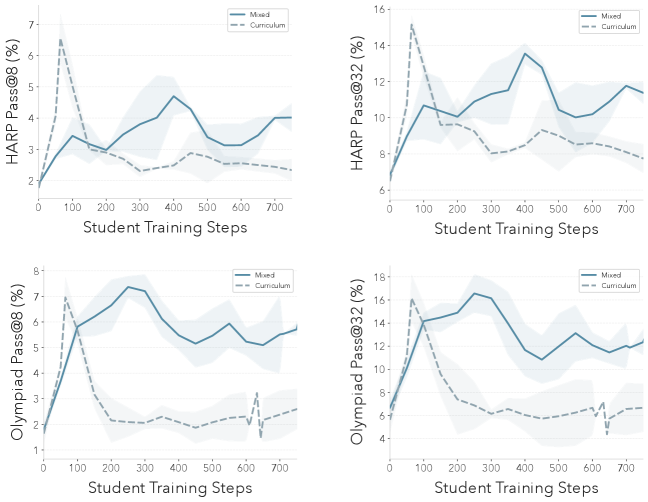 图 8(论文 Figure 17):左图:Intrinsic-T 的教师训练动态(3 个独立训练的均值 ± 1 标准差)。右图:Intrinsic 和 Grounded 奖励训练时教师生成内容的多样性变化。Grounded Reward 在整个训练过程中保持多样性,而 Intrinsic 教师随着收敛逐渐丧失多样性。
图 8(论文 Figure 17):左图:Intrinsic-T 的教师训练动态(3 个独立训练的均值 ± 1 标准差)。右图:Intrinsic 和 Grounded 奖励训练时教师生成内容的多样性变化。Grounded Reward 在整个训练过程中保持多样性,而 Intrinsic 教师随着收敛逐渐丧失多样性。
七、与现有方法的关系
论文将 SOAR 置于以下几个研究脉络中:
| 研究方向 | 代表方法 | 与 SOAR 的区别 |
|---|---|---|
| 课程学习 | Kimi, DAPO, SEC | 需要人工标注的分级数据集;SOAR 自动生成课程 |
| 自博弈 | AlphaZero, Absolute Zero, R-Zero, LSP | 使用内在/代理奖励;SOAR 使用 grounded reward |
| 数据集蒸馏 | Dataset Distillation | 需要通过梯度下降反向传播;SOAR 用 RL 避免内层展开 |
| 元学习 | MAML, Reptile | 需要 BPTT;SOAR 的"双层 meta-RL"结构是 LLM 自博弈中的首例 |
论文特别指出,SOAR 是第一个在 LLM 自博弈场景中实现真正的双层 meta-RL 循环 的工作。通过在外层循环使用 RLOO,将学生的进步作为奖励信号来强化教师的输出,避免了对内层循环进行梯度展开的高昂计算成本。
八、局限性
论文明确指出的主要局限包括:
计算成本高:双层 RL 循环需要为每组教师生成的数据集训练多个并行学生来计算稳定的奖励。虽然内层训练较短(10-20 步),但整体计算量仍然可观。
模型规模有限:所有实验均在 Llama-3.2-3B-Instruct 上进行,尚未验证在更大模型上的效果。
领域限制:仅在数学推理任务上进行了实验,其他领域(如代码生成、自然语言推理)的适用性未知。
效率提升空间:论文强调这是一个"概念验证"(proof of concept),更高效的奖励代理或规模化方案是未来工作的重要方向。
不过论文也通过消融实验表明,将等量的额外计算投入到直接训练(Hard-Only g=128)中,无法复现 SOAR 的改进幅度,证明收益确实来自双层框架本身而非简单的计算量堆叠。
九、总结
SOAR 这篇论文的核心贡献可以概括为:
证明了"教学能力"与"解题能力"可以解耦:一个模型不需要会解某道难题,就能生成帮助自己(的副本)学会解这道题的"垫脚石"题目。
提供了 Grounded Reward 优于 Intrinsic Reward 的实证:锚定在真实学习进度上的奖励,比基于可学习性的代理奖励更稳定、更不易坍塌。
揭示了"题目结构 > 答案正确性"的反直觉现象:合成题目中约 2/3 的答案是错的,但模型依然取得了进步——因为真正驱动学习的是题目的结构清晰度和概念多样性,而非答案本身的正确与否。答案正确率更高的对比方法反而因多样性坍塌而表现更差。
实现了 LLM 自博弈中首个真正的双层 meta-RL 循环:通过 RLOO 避免了对内层循环的梯度展开,在计算上具有可行性。
论文最后提出了一个发人深思的"北极星"思想实验:假设未来的模型已经在全部数学文献上完成预训练,那么千禧年问题(如黎曼猜想)的证明可能已经"潜藏"在预训练分布中。成功学习的关键,将在于恢复正确的中间引理和定理序列——这正是 SOAR 所展示的能力的极致延伸。
本文基于论文原文进行客观解读,图表均来自论文。论文引用:Sundaram et al., "Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability", arXiv:2601.18778, 2026.