Data Contracts:当 AI Agent 把脏数据的代价放大 10 倍

调研报告 | 2026 年 4 月 | 面向数据工程师、平台架构师与 AI 应用团队
摘要
Data Contracts(数据合同)这个概念,Andrew Jones 在 GoCardless 2020 年就提出来了,Chad Sanderson 也写了一整本 O'Reilly 的书。但过去五年它一直停留在 LinkedIn 长文和会议 PPT 阶段——真正在生产里落地的公司寥寥无几。
2026 年它突然被推到拐点,根本原因不是"理论成熟了",而是 AI Agent 把脏数据的代价从'报表错'放大到了'决策错'。BI 报表错一个数字,分析师能看出来;Agent 拿着脏数据做推理、调工具、写决策,它会自信地胡说,没人发现。一份 2026 年 3 月的复盘把这件事称为 "believable answers built on broken calls"。
本文按下面这条主线展开:
- 为什么 2026 年是拐点 —— 三股推力把 Data Contracts 从 PPT 推进生产
- Data Contract 到底约束什么 —— 7 类约束与失守后果
- 生产化的工程姿势 —— Self-Enforcing + Shift-Left 的两道门禁
- AI Agent 时代的特殊性 —— 从 Data Contract 到 Tool Contract
- 采纳真相 —— 50 个生产案例揭示的代价
- 工具与标准生态速览 —— ODCS、Soda、ADRI 这一票
- ICE 观察 —— API 治理范式迁移、落地路径、本土机会
一、为什么 2026 年是拐点
先把背景说透:Data Contracts 这个概念早就有了,也没有任何"突破性的技术发明"。它现在火,是因为下面三件事在 2026 年同时发生。

| 推力 | 具体表现 |
|---|---|
| AI Agent 把脏数据代价放大 | Agent 不会像 BI 报表那样"红字告警",它会基于脏数据自信地胡说——"believable answers built on broken calls"。一个上游字段漂移就能让整条 Agent 链路静默退化。 |
| 企业实测数据出来了 | Reliable Data Engineering 在 2026 年 2 月汇总了 50 个生产实施案例:12-18 个月内数据事故下降 40-60%——第一次有公开的"投入产出比"数据。 |
| 标准 + 工具栈成熟 | PayPal 把 data contract 模板捐给了 Linux Foundation,演化成 ODCS(Open Data Contract Standard),2025 年 12 月发到 v3.1.0;Soda、Great Expectations、dbt 全部原生支持。 |
一个值得记住的成本数字:poor data quality 给企业造成的年均损失是 1290 万美元(Ampcome, 2026),其中"slow, invisible accumulation of stale records, inconsistent fields, duplicate entries"这部分,过去靠人工巡检勉强压住,现在被 Agent 接管以后开始指数级累积。
上面这张对比图说的是范式差别:传统反应式治理是"等下游告警 → 事后排查",MTTR 按小时甚至天算;Shift-Left 数据合同是"在 Producer 写入时就拒绝、在 Consumer 读出时就 assert、在 Agent 调用前就 guard",MTTR 压到分钟级,关键是脏数据根本没机会污染下游。
理解了这个差别,再看下面的具体技术就有方向了。
二、Data Contract 到底约束什么
按 ODCS v3.1.0 的标准定义,一份数据合同至少包括 7 个块。问题里提到的 schema / 时效性 / 体积只是其中三块——它们是技术上最容易自动化的,但不是全部。
| 约束类型 | 内容 | 失守后的典型后果 |
|---|---|---|
| Schema | 列名、类型、可空、枚举范围 | 上游加列 / 改类型 → 下游 Agent SQL 报错或返回错答 |
| Freshness(时效) | 最大延迟(如 ≤30min)、更新频率 | Agent 用昨日数据答今日问题(最常见的"看似对实际错") |
| Volume(体积) | 行数范围、增长率 | 上游漏批 / 多批 → 下游统计被悄悄拉偏 |
| Quality(质量规则) | 完整性、唯一性、有效性、零值率 | 主键漏 → join 爆炸;空值激增 → 模型权重失衡 |
| Ownership | 数据 owner、SRE on-call | 出问题没人接,数据债越滚越大 |
| SLA | 可用性、延迟 | 影响 Agent 实时决策类应用 |
| Privacy / 安全 | PII 标签、访问控制、匿名化策略 | 数据泄露、合规事故 |
要点是:Schema、Freshness、Volume 这三块的执行是工程问题——可以直接生成 SQL 或 assertion 代码塞进管线;Ownership、SLA、Privacy 是组织和流程问题,难度大得多。这也是为什么 50 个案例的实测数据是"3-6 个月超期、组织阻力大于技术阻力"。
三、生产化的工程姿势:Self-Enforcing + Shift-Left
2026 年生产实施的两个共识词:self-enforcing(自校验)+ shift-left(左移)。
Self-enforcing 的意思是"契约不能只是文档"。Nimisha Vernekar 在 Data Engineer Things 上有句话很狠:没有自动执行的契约会变成 "wishes that nobody reads until something breaks"。所以 2026 年的生产实施都是 YAML-first,写在版本控制里,CI 自动渲染、自动校验。
Shift-left 的意思是"在数据产出前校验,而不是流到下游再发现"。这对应了一个非常清晰的双门禁架构:
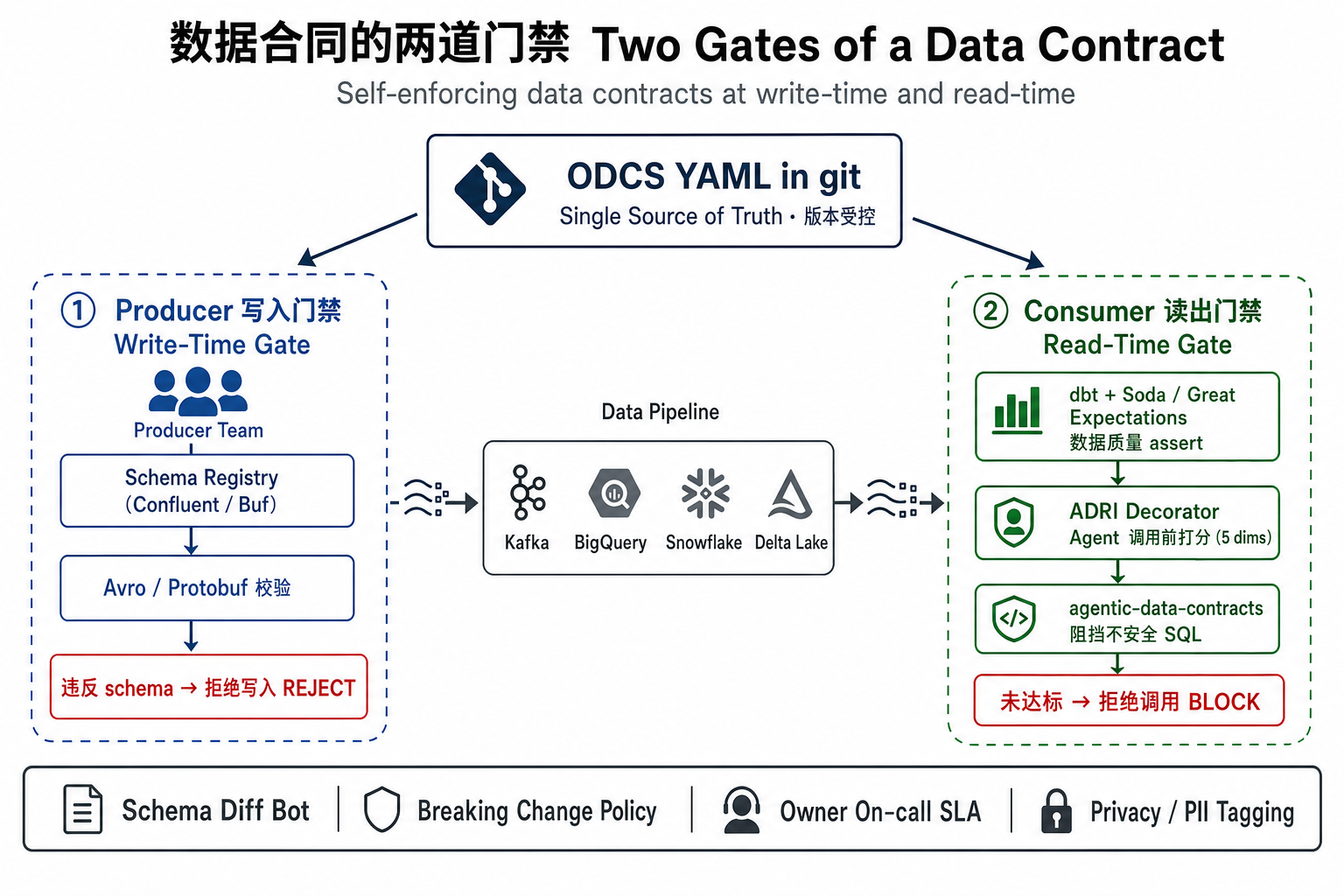
整个工作流分七步:
- ODCS YAML 进 git —— Single Source of Truth,所有契约都在版本控制里。
- CI 渲染 schema —— 把 YAML 编译成 Avro / Protobuf schema,注册到 Schema Registry。
- Producer 写入门禁 —— 数据写入 Kafka / BigQuery / Snowflake 时,违反 schema 的写入被直接拒绝。
- 数据流过管线 —— Pipeline 本身保持"哑管道",不做业务校验。
- Consumer 读出校验 —— dbt build 阶段 Soda / GX 自动跑契约里的 quality 规则。
- Agent 调用前 guard —— ADRI 这类 decorator 给数据打分,低于阈值直接拒绝调用;agentic-data-contracts 阻挡 Agent 发出的不安全 SQL。
- Schema diff bot 把关 PR —— breaking change(重命名 / 删字段 / 不兼容类型)告警,non-breaking change(加可空列 / 扩枚举)放行。
GoCardless 在 6 个月复盘里讲过一个细节:他们发现最难的不是写 YAML,是说服 producer 团队接受"我提交一行代码要被另一个团队的契约门禁卡住"。这件事在工程上 1 周能搞定,在组织上要 6 个月。
四、AI Agent 时代的特殊性:从 Data Contract 到 Tool Contract
这是 2026 年最值得单独拎出来的演化方向。传统 data contract 管的是"表与表之间的边界";AI Agent 时代多了一个新边界——Agent 与工具之间。
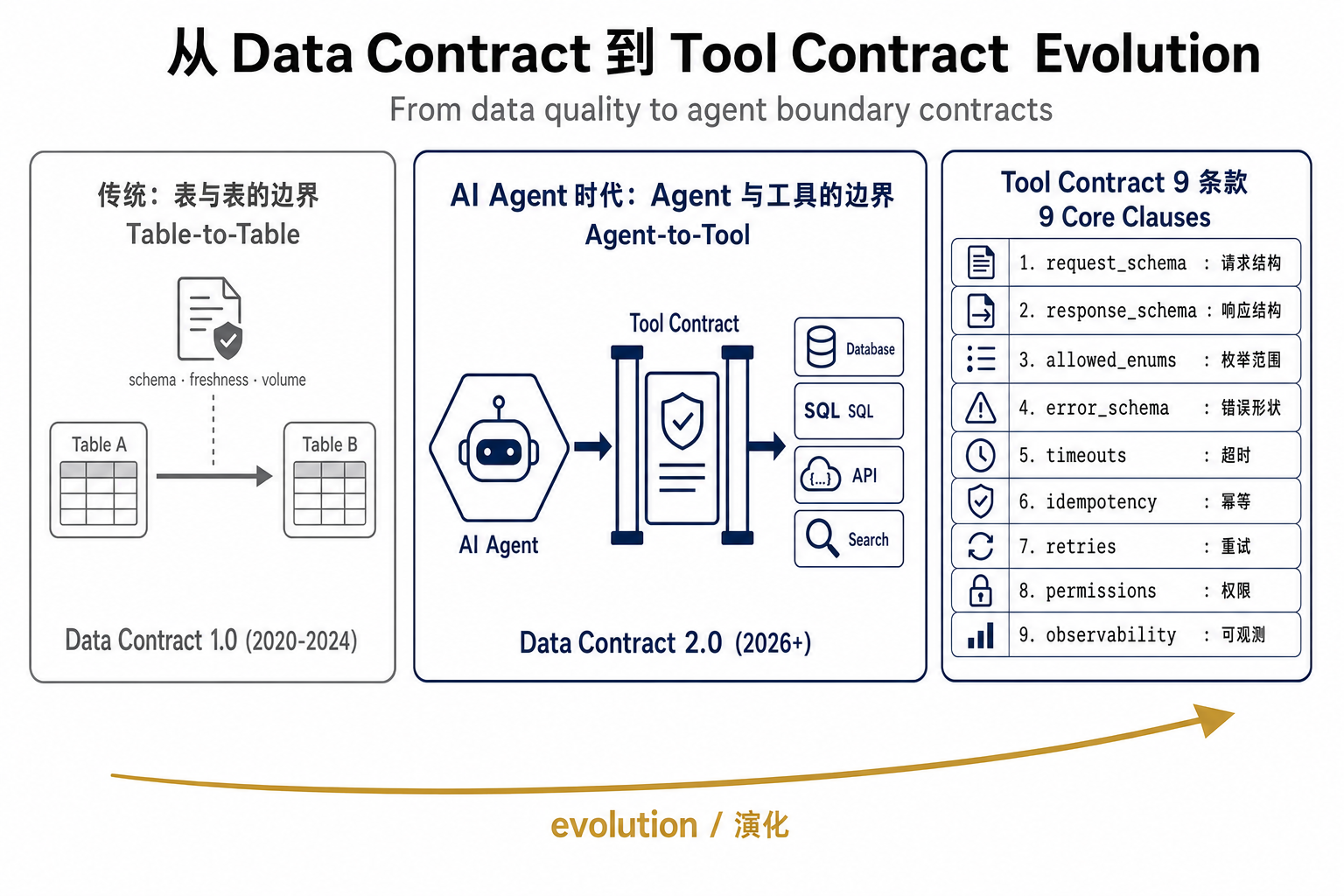
Sopan Deole 在 Medium 上提出了 "data contracts for agents" 的概念,把契约从数据扩展到工具调用。一份 Tool Contract 至少包括:
tool_name: get_user_invoices
contract_version: 2.1.0
request_schema: {...} # Agent 怎么调
response_schema: {...} # 工具返回什么形状
allowed_enums: [...] # 参数允许的值
error_schema: {...} # 错误怎么表达
owner: payments-team
last_reviewed: 2026-04-01Nexumo 在 2026 年 3 月总结了 "防止 Agent 静默误触发的 9 条款":schemas、timeouts、idempotency、retries、observability、permissions、rollback、allowed_enums、error_schema。核心思想是把 Agent 和工具的边界变得无聊——所有变更都是 explicit + versioned + testable,没有"惊喜"。
更具体的工具:
agentic-data-contracts(PyPI):YAML-first,挡住 Agent 发出的不安全 SQL——禁SELECT *、强制tenant_id过滤、禁DELETE / DROP / TRUNCATE,已支持 Claude Agent SDK + DuckDB / BigQuery / Snowflake / Postgres。- ADRI(Agent Data Readiness Index):用 Python decorator 把数据质量评分嵌入 Agent function,从五个维度打分,不达标直接拒绝调用。
- Soda for AI Agents:把数据质量校验包装成 Agent 可以调用的 tool,让 Agent 自己感知"我用的数据可不可信"。
这套东西本质上是把传统 SaaS API 治理(OpenAPI、Schema Registry、Backstage 这套)搬到 Agent 与数据 / Agent 与工具之间——只不过承载体从 REST 变成了 LLM tool calling。理解了这个映射,整个赛道的脉络就清楚了。
五、采纳真相:被低估的组织代价
在写计划书之前,必须看一组冷数据。Reliable Data Engineering 那篇 50 个案例的复盘里,有几个关键发现:
| 维度 | 实际数据 | 含义 |
|---|---|---|
| 数据事故下降 | 12-18 个月 40-60% | 显著但不归零 |
| 实施周期超期 | 比计划长 3-6 个月 | 几乎所有项目 |
| 主要阻力 | 组织阻力 > 技术难度 | producer 不愿意被门禁 |
| 失败模式 #1 | 契约只写了不执行 | 文档化幻觉 |
| 失败模式 #2 | 一上来就推全公司 | 应该先选 1-2 条关键数据流 |
| 成功模式 | 1 个 evangelist + 数据 owner 实名制 | 文化变革 > 技术变革 |
Data Contract 不是技术问题,而是"承诺工程"问题。 一旦你写下"这个表 99.9% 时间内行数在 [10K, 50K] 之间,最大延迟 30 分钟",你就是在用工程语言对下游做承诺——这个承诺会反过来约束你的发版节奏、值班机制、甚至组织绩效。这就是为什么 GoCardless 反复强调"文化变革"比工具更难。
实操上有一条几乎被所有成功案例验证过的路径:先选 1-2 条业务最痛的数据流(通常是给 Agent 或核心模型供数的那条),用 ODCS YAML 写一份契约,配 Soda / GX 做校验,拿到 6 个月的事故下降数据,再说服第二批 producer。试图"全公司一次推开"的项目,几乎全部失败。
六、工具与标准生态速览
把 2026 年值得记住的几家工具按层整理一下:
| 层 | 代表 | 备注 |
|---|---|---|
| 标准 | ODCS v3.1.0(Bitol / Linux Foundation) | PayPal 捐赠演化而来,事实标准 |
| 思想领袖 | Chad Sanderson(Gable,O'Reilly 书)、Andrew Jones(GoCardless) | 必读:《Data Contracts: Developing Production-Grade Pipelines at Scale》 |
| schema 注册 | Confluent Schema Registry、Buf Schema Registry | Producer 端门禁 |
| 质量校验 | Soda、Great Expectations、dbt tests | Consumer 端校验 |
| dbt 集成 | DataVow CLI(ODCS v3.1) | YAML → dbt test 自动同步 |
| 数据目录 | Dataplex、Unity Catalog、Snowflake Horizon、IBM watsonx、Witboost | 平台原生 |
| AI Agent 专用 | agentic-data-contracts、ADRI、Soda for AI | 2026 年新涌现的赛道 |
| 协作平台 | Soda Collaborative Data Contracts、Gable | Producer-Consumer 协商工作流 |
如果只能选三个起点,我的建议是:ODCS(学标准)+ Soda(做校验)+ ADRI(接 Agent)。这是 2026 年最低门槛、最容易拿到结果的组合。
七、ICE 观察:技术、落地、本土
技术视角:Data Contract 是"API 治理范式"向数据世界的迁移
Data Contract 本质上是把微服务 10 年验证过的 API 治理那套(OpenAPI + Schema Registry + Versioning + Breaking Change Policy)搬到数据世界。理解了这一点,就知道它一定会成——因为 SaaS API 治理花了 10 年从 PPT 走到生产,数据世界没理由不重走一遍。
AI Agent 的爆发只是把这件事的紧迫性提前了 3 年。在没有 Agent 的世界里,脏数据的代价是分析师多花两小时核对;在 Agent 的世界里,脏数据的代价是 CEO 看到一份"自信的胡说"做出错误决策。后者的成本足以推动 CTO 立项。
落地视角:数据团队应该立的 3 个 KPI
跟上一篇 AI-Ready Assets 一样,与其讨论"用哪家工具",不如直接立 3 个可量化的 KPI:
- 关键数据流契约覆盖率 = 已签署 ODCS 契约的数据流 / 全部给 Agent 与核心模型供数的数据流。先做到 30%,再谈 100%。
- 门禁拦截率 = Producer 写入门禁拦截的违规事件 / 全部潜在违规事件。如果这个数字接近 0,说明你的契约写得太松或没在 CI 里执行。
- MTTR(Mean Time To Repair) = 从契约违规告警到修复的平均时间。Shift-Left 落地有效的标志是这个数字从"小时-天级"压到"分钟级"。
这三个 KPI 的好处是完全可观测、可拉时间序列、可绑定到 OKR——它把"Data Contract"这件抽象的事,变成了团队每周看的看板数据。
本土视角:国内市场几乎是空白
国内 Data Contract 实践基本停留在零起点。DataPipeline、FineData、九章云极、袋鼠云这些数据治理厂商都还停留在"数据血缘 + 质量监控"的传统范式(其实就是 reactive legacy 那一侧),没有人把 ODCS 标准、shift-left 执行、Agent 边界契约整合成产品。
这是一个能复制 dbt 在中国市场早期路径的窗口——dbt 当年也是用"在 SQL 里写 test"这个简单到不能再简单的想法吃掉了一个百亿美元市场。谁先做出"中国版 ODCS + Soda + AI Agent 友好"的工具,谁就占住企业数据治理的下一代入口。
国内大厂里最有机会的是阿里 DataWorks、腾讯云数据智能、华为 DataArts 这三家,但目前都没有把"契约自校验"作为一等公民。这是一个值得关注的卡位时刻。
结论
留给读者三个判断:
- Data Contracts 不是新概念,但 2026 年才真正进入实操期——因为 AI Agent 把脏数据的代价放大了一个数量级,CTO 终于愿意立项了。
- 真正落地的关键不是工具,是双门禁架构(Producer 写入门禁 + Consumer 读出门禁 + Agent 调用前 guard)+ ODCS 标准化 + git 版本控制这套组合拳。
- Data Contract 2.0 的方向是 Tool Contract——把契约从数据边界扩展到 Agent 与工具的边界,这是 2026 年值得最早押注的细分赛道。
执行上有一条已经被 50 个生产案例验证过的路径:先选 1-2 条业务最痛的数据流(通常是给 Agent 或核心模型供数的那条),用 ODCS YAML 写契约,配 Soda 校验,拿到 6 个月的事故下降数据,再说服第二批 producer。试图"全公司一次推开"的,几乎全部失败。
你团队当下给 Agent 供数的那条管线,有没有一份写在 git 里、能在 CI 里 fail 的契约?如果没有,那 "believable answers built on broken calls" 这件事,未来某一天会让你的 CEO 给你打电话。
参考资料
- Bitol. Open Data Contract Standard (ODCS) v3.1.0. Linux Foundation, 2025-12.
- Reliable Data Engineering. Data Contracts in Practice: What 50 Production Implementations Actually Look Like. Medium, 2026-02.
- Nimisha Vernekar. Everyone Is Talking About Data Contracts. Nobody Is Showing You What One Actually Looks Like in Production. Data Engineer Things, 2026-03.
- Sopan Deole. Data Contracts for Agents: Keep Tools and Schemas Stable as Systems Evolve. Medium, 2026.
- Modexa. When One Field Drift Breaks the Agent. Medium, 2026-03.
- Nexumo. Agent Tool Contracts: 9 Clauses That Stop Silent Misfires. Medium, 2026-03.
- Chad Sanderson, Mark Freeman, B.E. Schmidt. Data Contracts: Developing Production-Grade Pipelines at Scale. O'Reilly, 2025.
- Andrew Jones. Data Contracts at GoCardless — 6 Months On. GoCardless Tech Blog.
- Ampcome. AI Agents for Data Quality Checks: Enterprise Guide 2026. 2026.
- Data Flakes. Data Governance 2.0: Shift-Left with Data Contracts and Schema Governance. 2026.
- flyersworder. agentic-data-contracts v0.1.0. PyPI / GitHub, 2026.
- ADRI Standard. Agent Data Readiness Index. GitHub adri-standard/adri.