论文解读|InterveneBench:评测大模型在社会科学中的因果干预推理能力
文献与研究动机
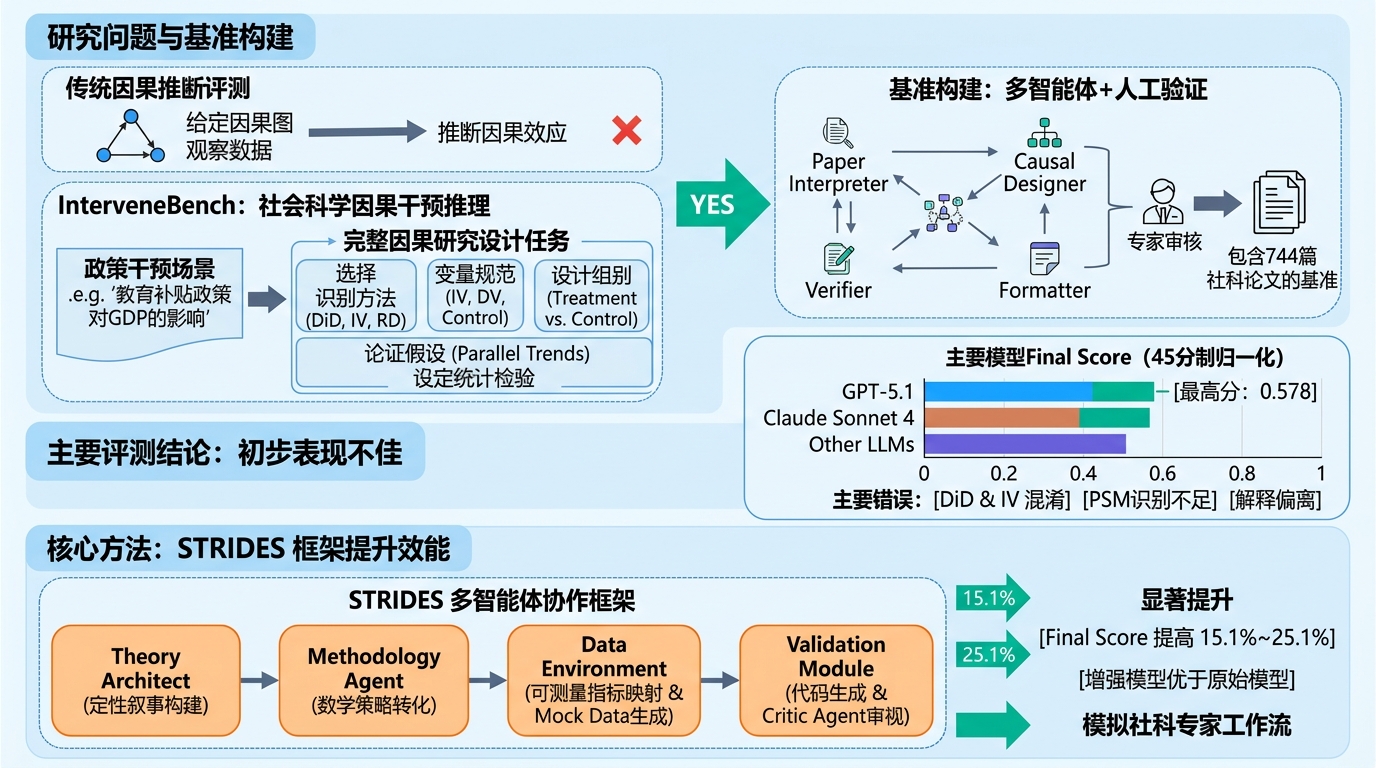
本文解读 2026 年发布在 arXiv 的论文 InterveneBench: Benchmarking LLMs for Intervention Reasoning and Causal Study Design in Real Social Systems。这篇工作很有意思 —— 它不是评测「大模型能不能做因果推断」,而是测试「大模型能否像社会科学家一样,设计出合理的因果研究方案」。
这个问题很重要:不少因果推断任务其实是开放式的研究设计问题,比如「某个税收政策如何影响 GDP」。我们不能预先给定一个固定的因果图,而是要根据政策背景、数据限制,先设计出一个可行的识别策略(比如用 DiD 还是 IV)。
评测任务:从政策到研究设计
InterveneBench 的核心任务是:给定一个政策干预(比如教育补贴、环境法规),模型要提出一个完整的因果研究设计。具体包括:
- 选择合适的因果识别方法(如 DiD、IV、RD)
- 明确变量规范(自变量、因变量、控制变量)
- 设计组别(实验组与对照组如何划分)
- 论证关键假设(比如 DiD 的平行趋势)
- 说明统计检验逻辑
这种任务比一般的因果推断要开放得多 —— 模型要像社科研究者一样,在没有预设因果图的情况下设计研究。
基准构建:人机协作的质控流程
为了构建高质量的基准,作者采用了多智能体 + 人工验证的方案:
多智能体自动提取:
- Paper Interpreter:解析论文元信息
- Causal Designer:重构因果设计逻辑
- Verifier:交叉检查一致性
- Formatter:标准化输出格式
人工专家审核:
- 4 位具备经济学和公共政策背景的专家独立审核
- 每个样本至少由 2 位专家交叉检查
- 低置信度样本(< 0.9)强制进入人工队列
基准最终包含 744 篇同行评议的社会科学研究论文,覆盖 9 个政策领域。
实验与结果:大模型表现欠佳
作者测试了 11 个最新的大模型,包括 GPT-5.1、Claude Sonnet 4 等。主要发现:
基本表现不理想:
- 即使最强的 GPT-5.1,在模型选择上准确率也只有 49.3%
- Final Score(45 分制归一化)最高也只有 0.578
主要错误类型:
- DiD 和 IV 混淆:在时序数据上容易混淆这两种方法
- PSM 识别不足:倾向于用 DiD/IV,很少考虑匹配方法
- 解释偏离:即使方法选对了,因果机制解释也可能不合理
STRIDES 框架:模拟专家协作
针对这些问题,作者提出了 STRIDES 框架,试图通过多智能体协作来模拟社科研究流程:
理论构建模块:
- Theory Architect:构建定性因果叙事
- Methodology Agent:转化为数学识别策略
数据环境模块:
- Data Retrieval:映射到可测量指标
- Simulation:生成 Mock Data 验证
验证模块:
- Code Agent:生成统计代码
- Critic Agent:审查结果一致性
这个框架带来了显著提升:
- Final Score 提高了 15.1%~25.1%
- 所有 STRIDES 增强的模型都优于对应的原始模型
- 在大多数子指标上都有改进(75/84)
局限与启示
尽管 STRIDES 取得了不错的效果,作者也指出了一些局限:
数据代表性:基准基于已发表论文构建,可能低估了实证覆盖有限的研究
评估维度:
- 主要评估研究设计推理,而非因果效应估计的数值准确性
- 将复杂的因果研究简化为离散标准,可能无法完全反映真实世界的复杂性
模拟限制:
- 模拟数据验证可能引入选择偏差
- 倾向于选择最小化、可测试的规范,可能影响协变量覆盖
这项工作的主要启示是:虽然大模型在封闭任务上表现不错,但在开放式的因果研究设计上仍有很大提升空间。通过多智能体协作模拟专家工作流是一个有前途的方向。
本文部分内容由 AI 辅助生成,经人工审校和补充后发布。